Questo articolo descrive una soluzione per esportare le metriche di Cloud Monitoring per analisi a lungo termine. Cloud Monitoring fornisce una soluzione di monitoraggio per Google CloudGoogle Cloud e Amazon Web Services (AWS). Cloud Monitoring mantiene le metriche per sei settimane perché il valore nelle metriche di monitoraggio è spesso limitato nel tempo. Pertanto, il valore delle metriche storiche diminuisce nel tempo. Dopo il periodo di sei settimane, le metriche aggregate potrebbero essere ancora utili per l'analisi a lungo termine delle tendenze che potrebbero non essere evidenti con l'analisi a breve termine.
Questa soluzione fornisce una guida per comprendere i dettagli delle metriche per l'esportazione e un'implementazione di riferimento serverless per l'esportazione delle metriche in BigQuery.
I report State of DevOps hanno identificato le funzionalità che migliorano le prestazioni di distribuzione del software. Questa soluzione ti aiuterà con le seguenti funzionalità:
- Monitoraggio e osservabilità
- Monitoraggio dei sistemi per decisioni aziendali informate
- Funzionalità di gestione visiva
Casi d'uso per l'esportazione delle metriche
Cloud Monitoring raccoglie metriche e metadati da Google Cloud, AWS e dalla strumentazione delle app. Le metriche di monitoraggio forniscono un'osservabilità approfondita su prestazioni, tempo di attività e integrità complessiva delle app cloud tramite un'API, dashboard e un esploratore delle metriche. Questi strumenti consentono di esaminare i valori delle metriche delle 6 settimane precedenti per l'analisi. Se hai requisiti di analisi delle metriche a lungo termine, utilizza l'API Cloud Monitoring per esportare le metriche per lo stoccaggio a lungo termine.
Cloud Monitoring gestisce le metriche delle ultime 6 settimane. Viene spesso utilizzato per scopi operativi come il monitoraggio dell'infrastruttura delle macchine virtuali (metriche di CPU, memoria e rete) e delle metriche relative alle prestazioni delle applicazioni (latenza delle richieste o delle risposte). Quando queste metriche superano le soglie predefinite, viene attivata una procedura operativa tramite gli avvisi.
Le metriche acquisite potrebbero essere utili anche per l'analisi a lungo termine. Ad esempio, potresti voler confrontare le metriche sul rendimento dell'app del Cyber Monday o di altri eventi con traffico elevato con quelle dell'anno precedente per pianificare il prossimo evento con traffico elevato. Un altro caso d'uso è esaminare l' Google Cloud utilizzo del servizio su un trimestre o un anno per prevedere meglio il costo. Potrebbero anche essere presenti metriche sul rendimento dell'app che vuoi visualizzare su mesi o anni.
In questi esempi è necessario mantenere le metriche per l'analisi su un periodo di tempo di lungo termine. L'esportazione di queste metriche in BigQuery fornisce le funzionalità di analisi necessarie per gestire questi esempi.
Requisiti
Per eseguire analisi a lungo termine sui dati delle metriche di monitoraggio, esistono tre requisiti principali:
- Esporta i dati da Cloud Monitoring. Devi esportare
i dati delle metriche di Cloud Monitoring come valore aggregato della metrica.
L'aggregazione delle metriche è obbligatoria perché l'archiviazione dei punti dati
timeseriesnon elaborati, anche se tecnicamente fattibile, non aggiunge valore. La maggior parte delle analisi a lungo termine viene eseguita a livello aggregato in un periodo di tempo più lungo. La granularità dell'aggregazione è specifica per il tuo caso d'uso, ma consigliamo un'aggregazione minima di 1 ora. - Importa i dati per l'analisi. Devi importare le metriche di Cloud Monitoring esportate in un motore di analisi per l'analisi.
- Scrivi query e crea dashboard in base ai dati. Per eseguire query, analizzare e visualizzare i dati, hai bisogno di dashboard e accesso SQL standard.
Passaggi funzionali
- Crea un elenco di metriche da includere nell'esportazione.
- Leggi le metriche dall'API Monitoring.
- Mappa le metriche dall'output JSON esportato dall'API Monitoring al formato della tabella BigQuery.
- Scrivi le metriche in BigQuery.
- Crea una pianificazione programmatica per esportare regolarmente le metriche.
Architettura
Il design di questa architettura sfrutta i servizi gestiti per semplificare le operazioni e le attività di gestione, ridurre i costi e offrire la possibilità di eseguire la scalabilità in base alle esigenze.
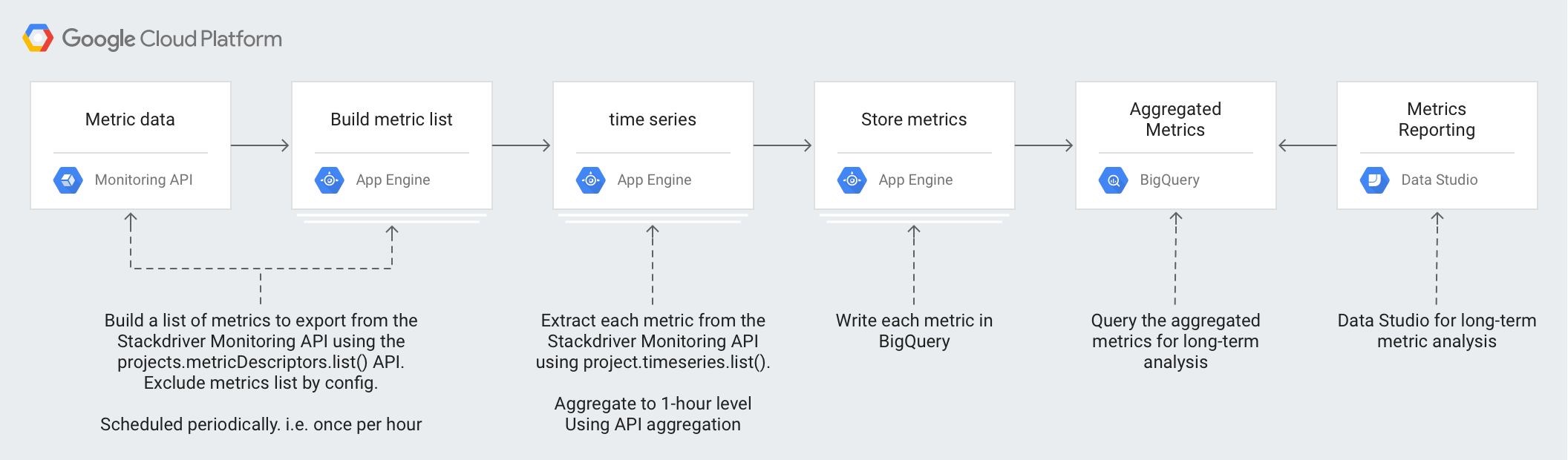
Nell'architettura vengono utilizzate le seguenti tecnologie:
- App Engine: soluzione PaaS (Platform as a Service) scalabile utilizzata per chiamare l'API Monitoring e scrivere in BigQuery.
- BigQuery: un motore di analisi completamente gestito utilizzato per caricare e analizzare i dati di
timeseries. - Pub/Sub: un servizio di messaggistica in tempo reale completamente gestito utilizzato per fornire un'elaborazione asincrona scalabile.
- Cloud Storage: un'archiviazione unificata di oggetti per sviluppatori e imprese utilizzata per archiviare i metadati relativi allo stato dell'esportazione.
- Cloud Scheduler: uno scheduler di tipo cron utilizzato per eseguire il processo di esportazione.
Informazioni sui dettagli delle metriche di Cloud Monitoring
Per capire come esportare al meglio le metriche da Cloud Monitoring, è importante comprendere in che modo vengono archiviate.
Tipi di metriche
In Cloud Monitoring puoi esportare quattro tipi principali di metriche.
- L'elenco delle metricheGoogle Cloud sono metriche dei Google Cloud servizi, come Compute Engine e BigQuery.
- L'elenco delle metriche dell'agente rappresenta le metriche delle istanze VM in cui sono in esecuzione gli agenti Cloud Monitoring.
- L'elenco delle metriche di AWS è costituito dalle metriche dei servizi AWS come Amazon Redshift e Amazon CloudFront.
- Le metriche provenienti da origini esterne sono le metriche di applicazioni di terze parti e le metriche definite dall'utente, incluse le metriche personalizzate.
Ognuno di questi tipi di metriche ha un
descrittore della metrica,
che include il tipo di metrica, nonché altri metadati delle metriche. La metrica riportata di seguito è un elenco di esempio dei descrittori delle metriche del metodo projects.metricDescriptors.list dell'API Monitoring.
{
"metricDescriptors": [
{
"name": "projects/sage-facet-201016/metricDescriptors/pubsub.googleapis.com/subscription/push_request_count",
"labels": [
{
"key": "response_class",
"description": "A classification group for the response code. It can be one of ['ack', 'deadline_exceeded', 'internal', 'invalid', 'remote_server_4xx', 'remote_server_5xx', 'unreachable']."
},
{
"key": "response_code",
"description": "Operation response code string, derived as a string representation of a status code (e.g., 'success', 'not_found', 'unavailable')."
},
{
"key": "delivery_type",
"description": "Push delivery mechanism."
}
],
"metricKind": "DELTA",
"valueType": "INT64",
"unit": "1",
"description": "Cumulative count of push attempts, grouped by result. Unlike pulls, the push server implementation does not batch user messages. So each request only contains one user message. The push server retries on errors, so a given user message can appear multiple times.",
"displayName": "Push requests",
"type": "pubsub.googleapis.com/subscription/push_request_count",
"metadata": {
"launchStage": "GA",
"samplePeriod": "60s",
"ingestDelay": "120s"
}
}
]
}
I valori importanti da comprendere dal descrittore della metrica sono i campi type,
valueType e metricKind. Questi campi identificano la metrica e influiscono sull'aggregazione possibile per un descrittore della metrica.
Tipi di metriche
Ogni metrica ha un tipo di metrica e un tipo di valore. Per ulteriori informazioni, consulta Tipi di valore e tipi di metriche. Il tipo di metrica e il tipo di valore associato sono importanti perché la loro combinazione influisce sul modo in cui le metriche vengono aggregate.
Nell'esempio precedente, il tipo di metrica pubsub.googleapis.com/subscription/push_request_count metric ha un tipo di metrica DELTA e un tipo di valore INT64.

In Cloud Monitoring, il tipo di metrica e i tipi di valore sono memorizzati in
metricsDescriptors, che sono disponibili nell'API Monitoring.
Timeseries
timeseries sono misurazioni regolari per ogni tipo di metrica archiviate nel tempo
che contengono il tipo di metrica, i metadati, le etichette e i singoli punti dati misurati. Le metriche raccolte automaticamente da Monitoring, come le metricheGoogle Cloud e AWS, vengono raccolte regolarmente. Ad esempio, la metrica
appengine.googleapis.com/http/server/response_latencies
viene raccolta ogni 60 secondi.
Un insieme di punti raccolti per un determinato timeseries potrebbe aumentare nel tempo, in base alla frequenza dei dati registrati e alle eventuali etichette associate al tipo di metrica. Se esporti i punti dati timeseries non elaborati, l'esportazione potrebbe essere di grandi dimensioni. Per ridurre il numero di punti dati timeseries restituiti, puoi aggregare le metriche in un determinato periodo di allineamento. Ad esempio, utilizzando
l'aggregazione puoi restituire un punto dati ogni ora per una determinata metrica
timeseries che ha un punto dati ogni minuto. In questo modo, si riduce il numero di punti dati esportati e l'elaborazione analitica richiesta nel motore di analisi. In questo articolo, vengono restituiti timeseries per ogni
tipo di metrica selezionato.
Aggregazione delle metriche
Puoi utilizzare l'aggregazione per combinare i dati di più timeseries in un unico
timeseries. L'API Monitoring fornisce potenti funzioni di allineamento e aggregazione in modo da non dover eseguire l'aggregazione manualmente, passando i parametri di allineamento e aggregazione alla chiamata dell'API. Per maggiori dettagli sul funzionamento dell'aggregazione per l'API Monitoring, consulta Filtri e aggregazione e questo post del blog.
Mappando metric typea aggregation type, ti assicuri che le metriche siano aliniate e che timeseries venga ridotto per soddisfare le tue esigenze di analisi.
Esistono elenchi di
allineatori
e
riduttoreni,
che puoi utilizzare per aggregare il timeseries. Gli allineatori e i riduttori hanno un insieme di metriche che puoi utilizzare per allineare o ridurre in base ai tipi di metriche e ai tipi di valore. Ad esempio, se esegui l'aggregazione per più di un'ora, il risultato dell'aggregazione è 1 punto restituito all'ora per il timeseries.
Un altro modo per perfezionare l'aggregazione è utilizzare la funzione Group By, che consente di raggruppare i valori aggregati in elenchi di Group By aggregati.timeseries Ad esempio, puoi scegliere di raggruppare le metriche di App Engine in base al modulo App Engine. Il raggruppamento per modulo App Engine in combinazione con gli allineatori e i riduttori che aggregano su 1 ora produce 1 punto dati per modulo App Engine all'ora.
L'aggregazione delle metriche bilancia l'aumento del costo della registrazione dei singoli punti di dati rispetto alla necessità di conservare dati sufficienti per un'analisi dettagliata a lungo termine.
Dettagli sull'implementazione di riferimento
L'implementazione di riferimento contiene gli stessi componenti descritti nel diagramma di progettazione dell'architettura. I dettagli di implementazione funzionali e pertinenti in ogni passaggio sono descritti di seguito.
Crea elenco di metriche
Cloud Monitoring definisce oltre mille tipi di metriche per aiutarti a monitorare Google Cloud, AWS e software di terze parti. L'API Monitoring fornisce il metodo projects.metricDescriptors.list, che restituisce un elenco delle metriche disponibili per un progetto Google Cloud. L'API Monitoring fornisce un meccanismo di filtro che consente di filtrare in base a un elenco di metriche da esportare per l'archiviazione e l'analisi a lungo termine.
L'implementazione di riferimento in GitHub utilizza un'app App Engine di Python per recuperare un elenco di metriche e poi scrivere ogni messaggio in un argomento Pub/Sub separatamente. L'esportazione viene avviata da un programma Cloud Scheduler che genera una notifica Pub/Sub per eseguire l'app.
Esistono molti modi per chiamare l'API Monitoring e, in questo caso, le API Cloud Monitoring e Pub/Sub vengono chiamate utilizzando la libreria client delle API di Google per Python per via del suo accesso flessibile alle API di Google.
Recuperare le serie temporali
Estrai il timeseries per la metrica e poi scrivi ogni timeseries in Pub/Sub. Con l'API Monitoring puoi aggregare i valori delle metriche in un determinato periodo di allineamento utilizzando il metodo project.timeseries.list. L'aggregazione dei dati riduce il carico di elaborazione, i requisiti di archiviazione, i tempi di query e i costi di analisi. L'aggregazione dei dati è una best practice per eseguire in modo efficiente l'analisi delle metriche a lungo termine.
L'implementazione di riferimento in GitHub utilizza un'app App Engine Python per abbonarsi all'argomento, in cui ogni metrica per l'esportazione viene inviata come messaggio distinto. Per ogni messaggio ricevuto, Pub/Sub lo invia all'app App Engine. L'app riceve il valore timeseries per una determinata metrica aggregata in base alla configurazione di input. In questo caso, le API Cloud Monitoring e Pub/Sub vengono chiamate utilizzando la libreria client delle API Google.
Ogni metrica può restituire 1 o più timeseries.. Ogni metrica viene inviata da un messaggio Pub/Sub separato da inserire in BigQuery. La mappatura della metrica type-to-aligner e della metrica type-to-reducer è integrata nell'implementazione di riferimento. La tabella seguente mostra la mappatura utilizzata nell'implementazione di riferimento in base alle classi di tipi di metriche e tipi di valori supportati dagli allineatori e dai riduttori.
| Tipo di valore | GAUGE |
Allineatore | Riduttore | DELTA |
Allineatore | Riduttore | CUMULATIVE2 |
Allineatore | Riduttore |
|---|---|---|---|---|---|---|---|---|---|
BOOL |
sì |
ALIGN_FRACTION_TRUE
|
nessuno | no | N/D | N/D | no | N/D | N/D |
INT64 |
sì |
ALIGN_SUM
|
nessuno | sì |
ALIGN_SUM
|
nessuno | sì | nessuno | nessuno |
DOUBLE |
sì |
ALIGN_SUM
|
nessuno | sì |
ALIGN_SUM
|
nessuno | sì | nessuno | nessuno |
STRING |
sì | esclusi | esclusi | no | N/D | N/D | no | N/D | N/D |
DISTRIBUTION |
sì |
ALIGN_SUM
|
nessuno | sì |
ALIGN_SUM
|
nessuno | sì | nessuno | nessuno |
MONEY |
no | N/D | N/D | no | N/D | N/D | no | N/D | N/D |
È importante considerare la mappatura di valueType ad allineatori e riduttori
perché l'aggregazione è possibile solo per valueTypes e metricKinds specifici
per ogni allineatore e riduttore.
Ad esempio, considera il tipo
pubsub.googleapis.com/subscription/push_request_count metric. In base al tipo di metrica DELTA e al tipo di valore INT64, un modo per aggregare la metrica è:
- Periodo di allineamento: 3600 secondi (1 ora)
Aligner = ALIGN_SUM: il punto dati risultante nel periodo di allineamento è la somma di tutti i punti dati nel periodo di allineamento.Reducer = REDUCE_SUM: riduci calcolando la somma su un valoretimeseriesper ogni periodo di allineamento.
Oltre ai valori del periodo di allineamento, dell'allineatore e del riduttore, il metodo
project.timeseries.list
richiede diversi altri input:
filter: seleziona la metrica da restituire.startTime- Seleziona il punto di partenza in tempo per cui tornaretimeseries.endTime: seleziona l'ultimo punto in tempo per cui restituire i datitimeseries.groupBy: inserisci i campi in base ai quali raggruppare la rispostatimeseries.alignmentPeriod: inserisci i periodi di tempo in cui vuoi allineare le metriche.perSeriesAligner: allinea i punti in intervalli di tempo pari definiti da unalignmentPeriod.crossSeriesReducer: combina più punti con valori di etichetta diversi fino a un punto per intervallo di tempo.
La richiesta GET all'API include tutti i parametri descritti nell'elenco precedente.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=START_TIME_VALUE&
interval.endTime=END_TIME_VALUE&
aggregation.alignmentPeriod=ALIGNMENT_VALUE&
aggregation.perSeriesAligner=ALIGNER_VALUE&
aggregation.crossSeriesReducer=REDUCER_VALUE&
filter=FILTER_VALUE&
aggregation.groupByFields=GROUP_BY_VALUE
Il seguente HTTP GET fornisce un esempio di chiamata al metodo API projects.timeseries.list utilizzando i parametri di input:
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z&
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
aggregation.crossSeriesReducer=REDUCE_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+&
aggregation.groupByFields=metric.labels.key
La chiamata all'API Monitoring precedente include un valore crossSeriesReducer=REDUCE_SUM, il che significa che le metriche vengono compresse e ridotte a una singola somma, come mostrato nell'esempio seguente.
{
"timeSeries": [
{
"metric": {
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"resource": {
"type": "pubsub_subscription",
"labels": {
"project_id": "sage-facet-201016"
}
},
"metricKind": "DELTA",
"valueType": "INT64",
"points": [
{
"interval": {
"startTime": "2019-02-08T14:00:00.311635Z",
"endTime": "2019-02-08T15:00:00.311635Z"
},
"value": {
"int64Value": "788"
}
}
]
}
]
}
Questo livello di aggregazione raggruppa i dati in un unico punto dati, il che lo rende una metrica ideale per il progetto Google Cloud complessivo. Tuttavia, non consente di visualizzare le risorse che hanno contribuito alla metrica. Nell'esempio precedente, non puoi sapere quale abbonamento Pub/Sub ha contribuito maggiormente al conteggio delle richieste.
Se vuoi esaminare i dettagli dei singoli componenti che generano il valore timeseries, puoi rimuovere il parametro timeseries.crossSeriesReducer
Senza crossSeriesReducer, l'API Monitoring non combina
i vari crossSeriesReducer per creare un singolo valore.timeseries
Il seguente HTTP GET fornisce un esempio di chiamata al metodo API projects.timeseries.list utilizzando i parametri di input. crossSeriesReducer non è incluso.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+
Nella seguente risposta JSON, i valori metric.labels.keys sono uguali in entrambi i risultati perché metric.labels.keys è raggruppato.timeseries Vengono restituiti punti distinti per ciascuno dei valori resource.labels.subscription_ids. Esamina i valori metric_export_init_pub e metrics_list nel seguente codice JSON. Questo livello di aggregazione è consigliato perché ti consente di utilizzare i prodottiGoogle Cloud , inclusi come etichette delle risorse, nelle query BigQuery.
{
"timeSeries": [
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "1"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metric_export_init_pub"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
},
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "803"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metrics_list"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
}
]
}
Ogni metrica nell'output JSON della chiamata all'API projects.timeseries.list viene scritta direttamente in Pub/Sub come messaggio separato. Esiste un potenziale fan-out in cui una metrica di input genera uno o più timeseries.
Pub/Sub offre la possibilità di gestire un fan-out potenzialmente elevato
senza superare i timeout.
Il periodo di allineamento fornito come input indica che i valori relativi a questo
periodo di tempo vengono aggregati in un unico valore, come mostrato nella risposta
dell'esempio precedente. Il periodo di allineamento definisce anche la frequenza di esecuzione dell'esportazione. Ad esempio, se il periodo di allineamento è 3600 secondi, ovvero 1 ora, l'esportazione viene eseguita ogni ora per esportare regolarmente il timeseries.
Metriche dei negozi
L'implementazione di riferimento in GitHub utilizza un'app App Engine Python per leggere ogni timeseries e poi inserire i record nella tabella BigQuery. Per ogni messaggio ricevuto,
Pub/Sub lo invia all'app App Engine. Il
messaggio Pub/Sub contiene i dati delle metriche esportati dall'
API Monitoring in formato JSON e deve essere mappato a una struttura
tabella in BigQuery. In questo caso, le API BigQuery vengono richiamate utilizzando la libreria client dell'API di Google.
Lo schema BigQuery è progettato per mapparsi strettamente al JSON esportato dall'API di monitoraggio. Quando crei lo schema della tabella BigQuery, devi considerare la scala delle dimensioni dei dati man mano che crescono nel tempo.
In BigQuery, ti consigliamo di partizionare la tabella in base a un campo data perché può rendere le query più efficienti selezionando intervalli di date senza eseguire una scansione completa della tabella. Se prevedi di eseguire l'esportazione regolarmente, puoi utilizzare in sicurezza la partizione predefinita in base alla data di importazione.
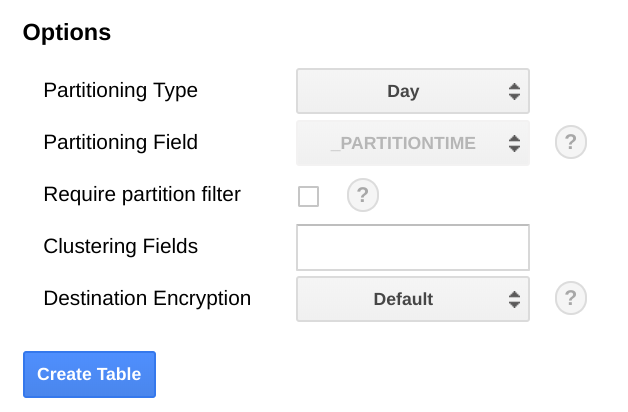
Se prevedi di caricare le metriche collettivamente o non esegui l'esportazione periodicamente,
esegui la partizione in base a end_time,, il che richiede modifiche allo schema
BigQuery. Puoi spostare end_time in un
campo di primo livello nello schema, dove puoi utilizzarlo per il partizionamento, oppure aggiungere un
nuovo campo allo schema. Lo spostamento del campo end_time è necessario perché il campo è contenuto in un record BigQuery e la suddivisione deve essere eseguita in un campo di primo livello. Per ulteriori informazioni, consulta la documentazione sul partizionamento di BigQuery.
BigQuery offre anche la possibilità di far scadere set di dati, tabelle e partizioni di tabelle dopo un determinato periodo di tempo.
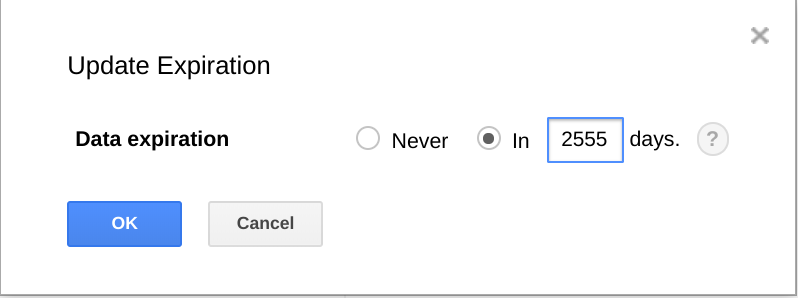
L'utilizzo di questa funzionalità è un modo utile per eliminare i dati meno recenti quando non sono più utili. Ad esempio, se la tua analisi copre un periodo di 3 anni, puoi aggiungere un criterio per eliminare i dati precedenti a 3 anni.
Pianifica esportazione
Cloud Scheduler è uno scheduler per cron job completamente gestito. Cloud Scheduler ti consente di utilizzare il formato della pianificazione cron standard per attivare un'app App Engine, inviare un messaggio utilizzando Pub/Sub o inviare un messaggio a un endpoint HTTP arbitrario.
Nell'implementazione di riferimento in GitHub, Cloud Scheduler attiva
l'app list-metrics App Engine ogni ora inviando un messaggio Pub/Sub con un token corrispondente alla configurazione di App Engine. Il periodo di aggregazione predefinito nella configurazione dell'app è 3600 secondi,
o 1 ora, che corrisponde alla frequenza con cui viene attivata l'app. Consigliamo un'aggregazione minima di un'ora perché offre un equilibrio tra la riduzione dei volumi di dati e il mantenimento di dati ad alta fedeltà. Se utilizzi un periodo di allineamento diverso, modifica la frequenza dell'esportazione in modo che corrisponda al periodo di allineamento. L'implementazione di riferimento memorizza l'ultimo valore end_time
in Cloud Storage e lo utilizza come start_time successivo
a meno che non venga passato un start_time come parametro.
Lo screenshot seguente di Cloud Scheduler mostra come puoi utilizzare la Google Cloud console per configurare Cloud Scheduler in modo da invocare l'app list-metrics App Engine ogni ora.
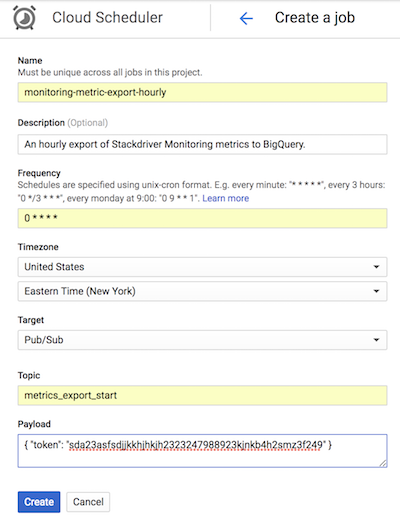
Il campo Frequenza utilizza la sintassi in stile cron per indicare a Cloud Scheduler la frequenza di esecuzione dell'app. Destinazione specifica un messaggio Pub/Sub generato e il campo Payload contiene i dati contenuti nel messaggio Pub/Sub.
Utilizzare le metriche esportate
Con i dati esportati in BigQuery, ora puoi utilizzare SQL standard per eseguire query sui dati o creare dashboard per visualizzare le tendenze delle metriche nel tempo.
Query di esempio: latenze di App Engine
La seguente query trova il minimo, il massimo e la media dei valori della metrica della latenza media per un'app App Engine. metric.type identifica la metrica di App Engine e le etichette identificano l'app App Engine in base al valore dell'etichetta project_id. point.value.distribution_value.mean viene utilizzato perché questa metrica è un valore DISTRIBUTION nell'API Monitoring, che è mappato all'oggetto campo distribution_value in BigQuery. Il campoend_time esamina i valori degli ultimi 30 giorni.
SELECT
metric.type AS metric_type,
EXTRACT(DATE FROM point.INTERVAL.start_time) AS extract_date,
MAX(point.value.distribution_value.mean) AS max_mean,
MIN(point.value.distribution_value.mean) AS min_mean,
AVG(point.value.distribution_value.mean) AS avg_mean
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'appengine.googleapis.com/http/server/response_latencies'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
GROUP BY
metric_type,
extract_date
ORDER BY
extract_date
Query di esempio: conteggi delle query BigQuery
La seguente query restituisce il numero di query eseguite su
BigQuery al giorno in un progetto. Il campo int64_value viene utilizzato
perché questa metrica è un valore INT64 nell'API Monitoring, che
viene mappato al campo int64_value in BigQuery. metric.typeidentifica la metrica BigQuery e le etichette identificano il progetto in base al valore dell'etichetta project_id. Il campo end_time esamina i valori degli ultimi 30 giorni.
SELECT
EXTRACT(DATE FROM point.interval.end_time) AS extract_date,
sum(point.value.int64_value) as query_cnt
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
and metric.type = 'bigquery.googleapis.com/query/count'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
group by extract_date
order by extract_date
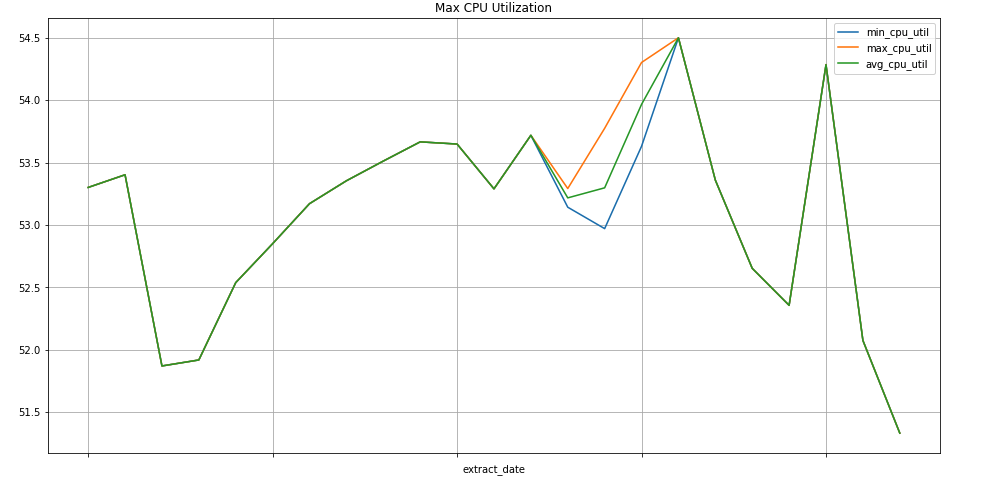
Query di esempio: istanze Compute Engine
La seguente query trova il valore minimo, massimo e medio settimanale della metrica di utilizzo della CPU per le istanze Compute Engine di un progetto. metric.type identifica la metrica Compute Engine e le etichette identificano le istanze in base al valore dell'etichetta project_id. Il campo end_time
esamina i valori degli ultimi 30 giorni.
SELECT
EXTRACT(WEEK FROM point.interval.end_time) AS extract_date,
min(point.value.double_value) as min_cpu_util,
max(point.value.double_value) as max_cpu_util,
avg(point.value.double_value) as avg_cpu_util
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'compute.googleapis.com/instance/cpu/utilization'
group by extract_date
order by extract_date
Visualizzazione dei dati
BigQuery è integrato con molti strumenti che puoi utilizzare per la visualizzazione dei dati.
Looker Studio
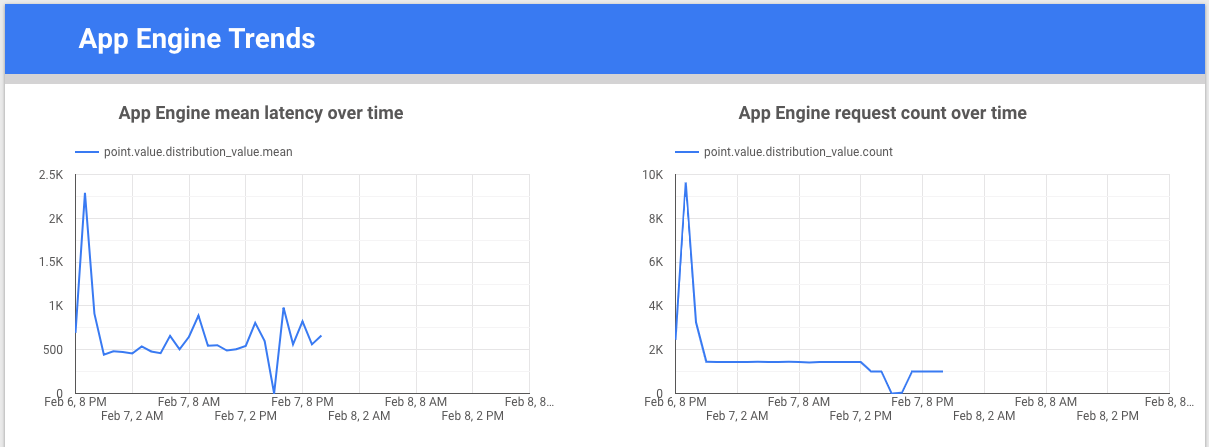
è uno strumento gratuito creato da Google che ti consente di creare grafici e dashboard dei dati per visualizzare i dati delle metriche e poi condividerli con il tuo team. L'esempio seguente mostra un grafico della linea di tendenza della latenza e del conteggio per la metrica appengine.googleapis.com/http/server/response_latencies nel tempo.
Colaboratory è uno strumento di ricerca per l'insegnamento e la ricerca nel machine learning. Si tratta di un ambiente di notebook Jupyter ospitato che non richiede configurazione per utilizzare e accedere ai dati in BigQuery. Utilizzando un notebook Colab, comandi Python e query SQL, puoi sviluppare analisi e visualizzazioni dettagliate.
Monitoraggio dell'implementazione del riferimento di esportazione
Quando l'esportazione è in esecuzione, devi monitorarla. Un modo per decidere quali metriche monitorare è impostare un obiettivo del livello di servizio (SLO). Uno SLO è un valore target o un intervallo di valori per un livello di servizio misurato da una metrica. Il libro Site Reliability Engineering descrive 4 aree principali per gli SLO: disponibilità, velocità effettiva, percentuale di errori e latenza. Per un'esportazione di dati, il throughput e il tasso di errore sono due aspetti fondamentali da tenere in considerazione e puoi monitorarli tramite le seguenti metriche:
- Velocità effettiva -
appengine.googleapis.com/http/server/response_count - Tasso di errore:
logging.googleapis.com/log_entry_count
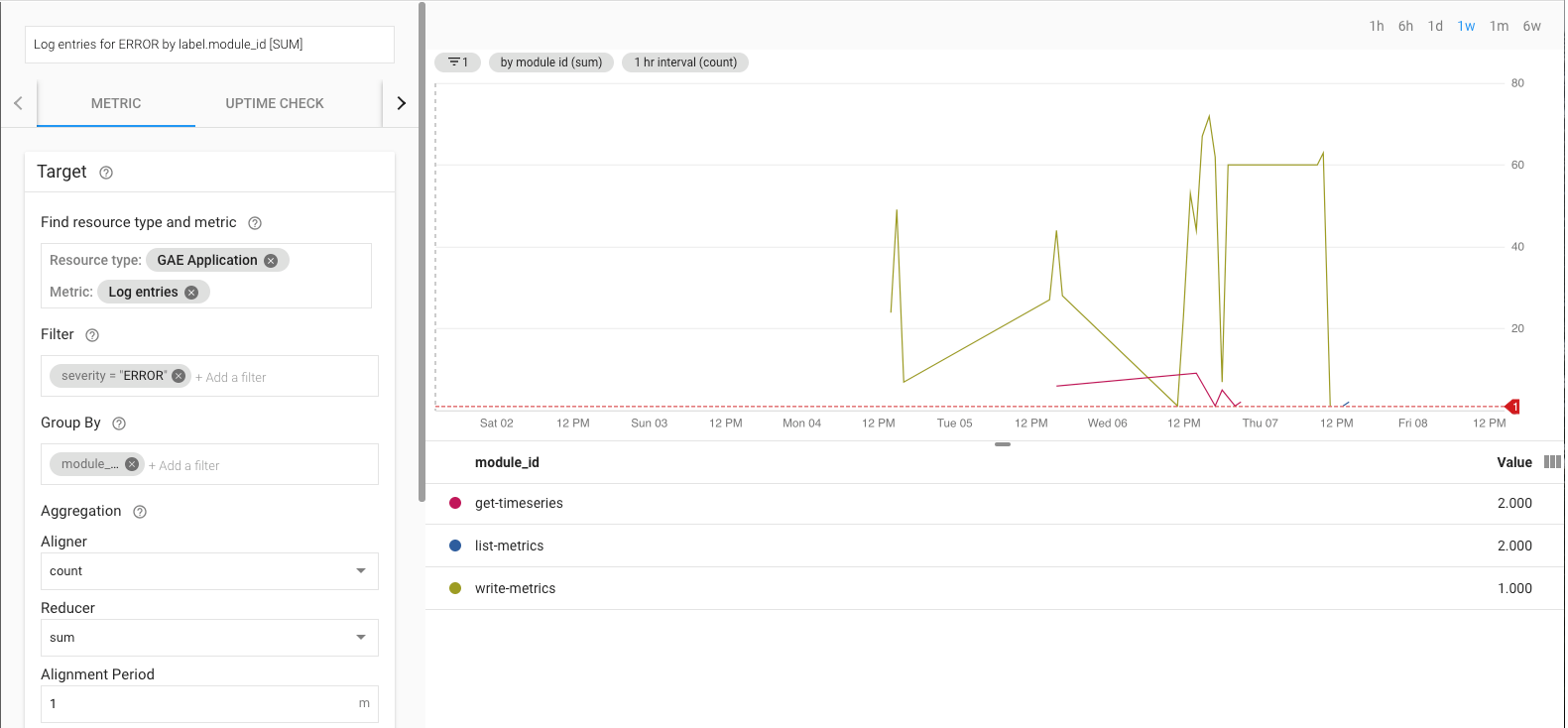
Ad esempio, puoi monitorare il tasso di errore utilizzando la metrica log_entry_count
e filtrandola per le app App Engine (list-metrics,
get-timeseries, write-metrics) con una gravità pari a ERROR. Puoi quindi utilizzare i criteri di avviso in Cloud Monitoring per ricevere avvisi sugli errori rilevati nell'app di esportazione.
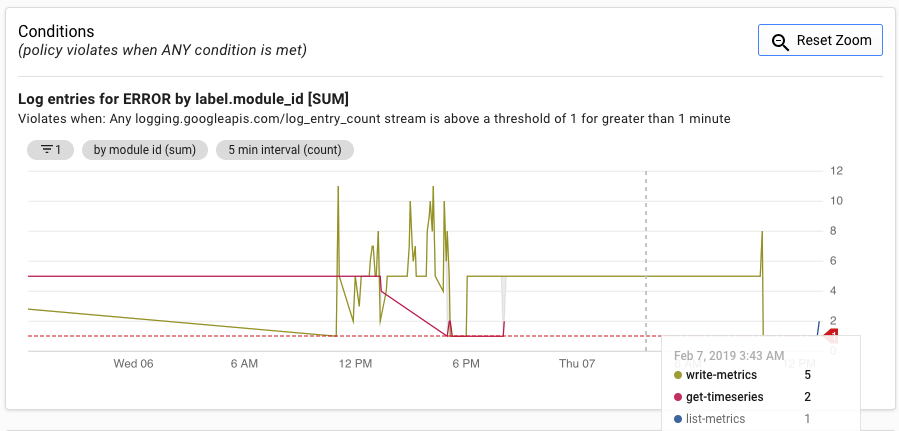
L'interfaccia utente di avviso mostra un grafico della metrica log_entry_count rispetto alla soglia per la generazione dell'avviso.
Passaggi successivi
- Visualizza l'implementazione di riferimento su GitHub.
- Leggi la documentazione di Cloud Monitoring.
- Consulta la documentazione dell'API Cloud Monitoring v3.
- Per altre architetture di riferimento, diagrammi e best practice, visita il Centro architetture di Google Cloud.
- Leggi le nostre risorse su DevOps.
Scopri di più sulle funzionalità DevOps correlate a questa soluzione:
Esegui il controllo rapido DevOps per capire dove ti trovi rispetto al resto del settore.