Eine abgeleitete Tabelle ist eine Abfrage, deren Ergebnisse wie eine physische Tabelle in der Datenbank verwendet werden. Eine native abgeleitete Tabelle basiert auf einer Abfrage, die Sie mit LookML-Begriffen definieren. Dies unterscheidet sich von einer SQL-basierten abgeleiteten Tabelle, die auf einer Abfrage basiert, die Sie mit SQL-Begriffen definieren. Im Vergleich zu SQL-basierten abgeleiteten Tabellen sind native abgeleitete Tabellen bei der Modellierung Ihrer Daten wesentlich leichter zu lesen und zu verstehen. Weitere Informationen finden Sie auf der Dokumentationsseite Abgeleitete Tabellen in Looker im Abschnitt Native abgeleitete Tabellen und SQL-basierte abgeleitete Tabellen.
Sowohl native als auch SQL-basierte abgeleitete Tabellen werden in LookML mit dem Parameter derived_table auf Ansichtsebene definiert. Bei nativen abgeleiteten Tabellen müssen Sie jedoch keine SQL-Abfrage erstellen. Stattdessen können Sie den Parameter explore_source verwenden, um die explorative Datenanalyse anzugeben, auf der die abgeleitete Tabelle basieren soll, sowie die gewünschten Spalten und andere gewünschte Eigenschaften.
Sie können auch mithilfe von Looker die abgeleitete Tabelle LookML aus einer SQL Runner-Abfrage erstellen lassen, wie auf der Dokumentationsseite Mit SQL Runner abgeleitete Tabellen erstellen beschrieben.
Native abgeleitete Tabellen auf der Grundlage eines Explores definieren
Ausgehend von einem Explore kann Looker LookML für die gesamte abgeleitete Tabelle oder einen großen Teil davon generieren. Erstellen Sie einfach ein Explore, und wählen Sie alle Felder aus, die in der abgeleiteten Tabelle enthalten sein sollen. Anschließend generieren Sie den LookML-Code für die native abgeleitete Tabelle wie folgt:
Klicken Sie auf das Zahnradmenü und dann auf LookML.
Klicken Sie auf den Tab Abgeleitete Tabelle, um die LookML zum Erstellen einer nativen abgeleiteten Tabelle für die Funktion „Erkunden“ aufzurufen.
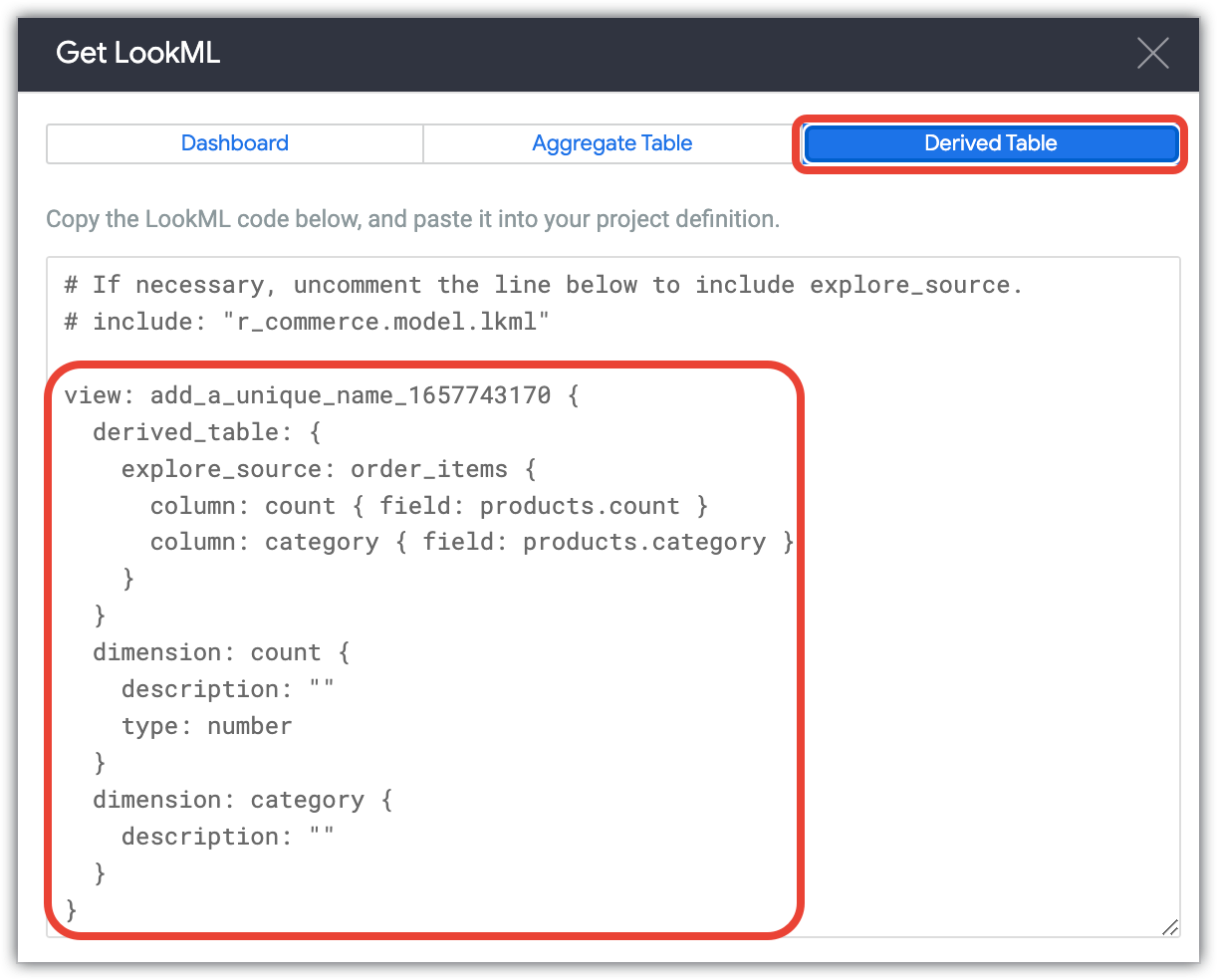
Kopieren Sie den LookML-Code.
Fügen Sie den kopierten LookML-Code in eine Ansichtsdatei ein:
Rufen Sie im Entwicklungsmodus Ihre Projektdateien auf.
Klicken Sie oben in der Projektdateiliste der Looker-IDE auf + und wählen Sie Datenansicht erstellen aus. Alternativ können Sie auf das Menü eines Ordners klicken und im Menü Ansicht erstellen auswählen, um die Datei im Ordner zu erstellen.
Geben Sie der Ansicht einen aussagekräftigen Namen.
Optional können Sie Spaltennamen ändern, abgeleitete Spalten festlegen und Filter hinzufügen.
Wenn Sie für ein exploratives Analysetool den Wert
type: countverwenden, werden die Ergebnisse in der Visualisierung anstelle des Worts Anzahl mit dem Namen der Ansicht gekennzeichnet. Um Verwechslungen zu vermeiden, empfehlen wir, Ihren Ansichtsnamen zu Pluralformen auszuwählen, unter Reihe in den Visualisierungseinstellungen Vollständigen Feldnamen anzeigen auszuwählen oder einview_labelmit einer Pluralform Ihres Ansichtsnamens zu verwenden.
Native abgeleitete Tabelle in LookML definieren
Unabhängig davon, ob Sie abgeleitete Tabellen in SQL oder nativem ML verwenden, ist die Ausgabe einer derived_table-Abfrage eine Tabelle mit mehreren Spalten. Wenn die abgeleitete Tabelle in SQL ausgedrückt wird, werden die Spaltennamen der Ausgabe durch die SQL-Abfrage impliziert. Die folgende SQL-Abfrage hat beispielsweise die Ausgabespalten user_id, lifetime_number_of_orders und lifetime_customer_value:
SELECT
user_id
, COUNT(DISTINCT order_id) as lifetime_number_of_orders
, SUM(sale_price) as lifetime_customer_value
FROM order_items
GROUP BY 1
In Looker beruht eine Abfrage auf einem Explore, enthält Felder für Messwerte und Dimensionen, fügt ggf. Filter hinzu und kann auch eine Sortierreihenfolge vorgeben. Eine native abgeleitete Tabelle enthält all diese Elemente plus die Ausgabenamen für die Spalten.
Im folgenden Beispiel wird eine abgeleitete Tabelle mit drei Spalten erstellt: user_id, lifetime_customer_value und lifetime_number_of_orders. Sie müssen die Abfrage nicht manuell in SQL schreiben. Stattdessen erstellt Looker die Abfrage mithilfe der angegebenen Felder vom Typ „Erkunden“ order_items und einigen der Felder in „Erkunden“ (order_items.user_id, order_items.total_revenue und order_items.order_count).
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: lifetime_number_of_orders {
field: order_items.order_count
}
column: lifetime_customer_value {
field: order_items.total_revenue
}
}
}
# Define the view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
}
include-Anweisungen zum Aktivieren von Referenzfeldern verwenden
In der nativen abgeleiteten Tabellenansicht verwenden Sie den Parameter explore_source, um auf einen Bericht zu verweisen und die gewünschten Spalten und anderen gewünschten Eigenschaften für die native abgeleitete Tabelle zu definieren. Weil Sie in der Ansichtsdatei der nativen abgeleiteten Tabelle auf einen Tab „Entdecken“ zeigen, müssen Sie auch die Datei mit einbeziehen, die die Definition „Erkunden“ enthält. Erkundungen werden normalerweise in einer Modelldatei definiert. Im Fall von abgeleiteten Tabellen ist es jedoch übersichtlicher, eine separate Datei für die Analyse mit der Dateiendung .explore.lkml zu erstellen, wie in der Dokumentation unter Erkundungsdateien erstellen beschrieben. Auf diese Weise können Sie in der Ansichtsdatei der nativen abgeleiteten Tabelle eine einzelne Explore-Datei hinzufügen und nicht die gesamte Modelldatei. In diesem Fall gilt Folgendes:
- Die Ansichtsdatei der nativen abgeleiteten Tabelle sollte die Datei „Erkunden“ enthalten. Beispiel:
include: "/explores/order_items.explore.lkml" - Die Datei „Erkunden“ sollte die erforderlichen Dateien enthalten. Beispiel:
include: "/views/order_items.view.lkml"
include: "/views/users.view.lkml" - Das Modell sollte die Datei „Erkunden“ enthalten. Beispiel:
include: "/explores/order_items.explore.lkml"
Dateien des Typs „Erkunden“ analysieren die Verbindung des Modells, in dem sie enthalten sind. Das ist wichtig, wenn Sie Dateien zum Erkunden in Modelle aufnehmen, die mit einer anderen Verbindung als dem übergeordneten Modell der Datei „Erkunden“ konfiguriert sind. Wenn sich das Schema für die Verbindung des einschließenden Modells vom Schema für die Verbindung des übergeordneten Modells unterscheidet, können Abfragefehler auftreten.
Spalten nativer abgeleiteter Tabellen definieren
Wie im Beispiel oben gezeigt, verwenden Sie column, um die Ausgabespalten der abgeleiteten Tabelle anzugeben.
Spaltennamen angeben
In der Spalte „user_id“ stimmt der Spaltenname mit dem Namen des angegebenen Felds im ursprünglichen „Erkunden“-Feld überein.
Es wird häufiger vorkommen, dass der Spaltenname in der Ausgabetabelle anders lauten soll als der Name der Felder im ursprünglichen Explore. Im Beispiel oben wird über die order_items-Funktion „Erkunden“ ein Lifetime-Wert berechnet. In der Ausgabetabelle ist total_revenue wirklich ein lifetime_customer_value des Kunden.
Die column-Deklaration unterstützt die Deklaration eines Ausgabenamens, der sich vom Eingabefeld unterscheidet. Im folgenden Code wird beispielsweise „&“ eine Ausgabespalte mit dem Namen „lifetime_value“ aus dem Feld „order_items.total_revenue"“ erstellen:
column: lifetime_value {
field: order_items.total_revenue
}
Implizierte Spaltennamen
Wenn der Parameter field in einer Spaltendeklaration weggelassen wird, wird von <explore_name>.<field_name> ausgegangen. Wenn Sie beispielsweise explore_source: order_items angegeben haben, dann
column: user_id {
field: order_items.user_id
}
gleichbedeutend mit
column: user_id {}
Abgeleitete Spalten für berechnete Werte erstellen
Sie können derived_column-Parameter hinzufügen, um Spalten anzugeben, die nicht im Parameter explore_source vorhanden sind. Jeder derived_column-Parameter hat einen sql-Parameter, der angibt, wie der Wert konstruiert wird.
Für die sql-Berechnung können alle Spalten verwendet werden, die Sie mit column-Parametern angegeben haben. Abgeleitete Spalten können zwar keine Summenfunktionen enthalten, aber Berechnungen, die an einer einzelnen Tabellenzeile durchgeführt werden können.
Im Beispiel unten wird dieselbe abgeleitete Tabelle wie im vorherigen Beispiel erstellt, mit der Ausnahme, dass die Spalte average_customer_order berechnet wird. Diese wird aus den Spalten lifetime_customer_value und lifetime_number_of_orders in der nativen abgeleiteten Tabelle berechnet.
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: lifetime_number_of_orders {
field: order_items.order_count
}
column: lifetime_customer_value {
field: order_items.total_revenue
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
# Define the view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
SQL-Fensterfunktionen verwenden
Einige Datenbankdialekte unterstützen Fensterfunktionen, insbesondere zum Erstellen von Sequenznummern, Primärschlüsseln, laufenden und kumulativen Gesamtwerten und anderen nützlichen Berechnungen für mehrere Zeilen. Nachdem die primäre Abfrage ausgeführt wurde, werden alle derived_column-Deklarationen in einem separaten Durchlauf ausgeführt.
Sofern Ihr Datenbankdialekt Fensterfunktionen unterstützt, können Sie diese in Ihrer nativen abgeleiteten Tabelle nutzen. Erstellen Sie einen derived_column-Parameter mit einem sql-Parameter, der die gewünschte Fensterfunktion enthält. Beim Verweisen auf Werte sollten Sie den Spaltennamen verwenden, der in Ihrer nativen abgeleiteten Tabelle definiert wurde.
Im folgenden Beispiel wird eine native abgeleitete Tabelle erstellt, die die Spalten user_id, order_id und created_time enthält. Anschließend wird anhand einer abgeleiteten Spalte mit einer SQL ROW_NUMBER()-Fensterfunktion eine Spalte berechnet, die die Sequenznummer der Bestellung eines Kunden enthält.
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
Filter zu einer nativen abgeleiteten Tabelle hinzufügen
Angenommen, wir wollten eine abgeleitete Tabelle mit dem Wert eines Kunden in den letzten 90 Tagen erstellen. Wir möchten dieselben Berechnungen wie oben verwenden, aber nur Käufe der letzten 90 Tage sollen berücksichtigt werden.
Wir fügen lediglich dem derived_table einen Filter hinzu, der nach Transaktionen in den letzten 90 Tagen filtert. Für den Parameter filters für eine abgeleitete Tabelle wird dieselbe Syntax wie zum Erstellen eines gefilterten Messwerts verwendet.
view: user_90_day_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: number_of_orders_90_day {
field: order_items.order_count
}
column: customer_value_90_day {
field: order_items.total_revenue
}
filters: [order_items.created_date: "90 days"]
}
}
# Add define view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: number_of_orders_90_day {
type: number
}
dimension: customer_value_90_day {
type: number
}
}
Filter werden der WHERE-Klausel hinzugefügt, wenn Looker den SQL-Code für die abgeleitete Tabelle schreibt.
Darüber hinaus können Sie den Unterparameter dev_filters von explore_source mit einer nativen abgeleiteten Tabelle verwenden. Mit dem Parameter dev_filters können Sie Filter angeben, die von Looker nur auf Entwicklungsversionen der abgeleiteten Tabelle angewendet werden. Dies bedeutet, dass Sie kleinere, gefilterte Versionen der Tabelle erstellen können, um sie zu testen und zu testen, ohne auf die vollständige Tabelle nach jeder Änderung warten zu müssen.
Der Parameter dev_filters wirkt in Verbindung mit dem Parameter filters, sodass alle Filter auf die Entwicklungsversion der Tabelle angewendet werden. Wenn sowohl dev_filters als auch filters Filter für dieselbe Spalte angeben, hat dev_filters Vorrang vor der Entwicklungsversion der Tabelle.
Weitere Informationen finden Sie unter Im Entwicklungsmodus schneller arbeiten.
Filtervorlagen verwenden
Mit bind_filters können Sie Vorlagenfilter einschließen:
bind_filters: {
to_field: users.created_date
from_field: filtered_lookml_dt.filter_date
}
Dies entspricht im Wesentlichen der Verwendung des folgenden Codes in einem sql-Block:
{% condition filtered_lookml_dt.filter_date %} users.created_date {% endcondition %}
to_field ist das Feld, auf das der Filter angewendet wird. to_field muss ein Feld aus der zugrunde liegenden explore_source sein.
from_field gibt das Feld an, von dem der Filter abgerufen werden soll, wenn zur Laufzeit ein Filter vorhanden ist.
Im Beispiel bind_filters verwendet Looker einen Filter, der auf das Feld filtered_lookml_dt.filter_date angewendet wird, und wendet den Filter auf das Feld users.created_date an.
Sie können auch den Unterparameter bind_all_filters von explore_source verwenden, um alle Laufzeitfilter von einem Explore an eine native abgeleitete Unterabfrage der Tabelle zu übergeben. Weitere Informationen finden Sie auf der Dokumentationsseite zum Parameter explore_source.
Native abgeleitete Tabellen sortieren und begrenzen
Sie können die abgeleiteten Tabellen bei Bedarf auch sortieren und begrenzen:
sorts: [order_items.count: desc]
limit: 10
Denken Sie daran, dass ein Explore die Zeilen möglicherweise in einer anderen Reihenfolge als die zugrunde liegende Sortierung anzeigt.
Native abgeleitete Tabellen in andere Zeitzonen konvertieren
Sie können die Zeitzone für die native abgeleitete Tabelle mit dem Unterparameter timezone angeben:
timezone: "America/Los_Angeles"
Wenn Sie den Unterparameter timezone verwenden, werden alle zeitbasierten Daten in der nativen abgeleiteten Tabelle in die von Ihnen angegebene Zeitzone umgewandelt. Auf der Dokumentationsseite zu timezone-Werten finden Sie eine Liste der unterstützten Zeitzonen.
Wenn Sie in der abgeleiteten Tabellendefinition keine Zeitzone angeben, führt die native abgeleitete Tabelle keine Zeitzonenkonvertierung für zeitbasierte Daten durch. Stattdessen werden zeitbasierte Daten standardmäßig auf Ihre Datenbankzeitzone eingestellt.
Wenn die native abgeleitete Tabelle nicht persistent ist, können Sie den Zeitzonenwert auf "query_timezone" festlegen, sodass automatisch die Zeitzone der aktuell ausgeführten Abfrage verwendet wird.