Questa guida fornisce una panoramica delle opzioni, dei consigli e dei concetti generali che devi conoscere prima di eseguire il deployment di un sistema SAP HANA ad alta disponibilità (HA) su Google Cloud.
Questa guida presuppone che tu abbia già familiarità con i concetti e le pratiche generalmente richiesti per implementare un sistema SAP HANA ad alta disponibilità. Pertanto, la guida si concentra principalmente su ciò che devi sapere per implementare un sistema di questo tipo Google Cloud.
Per saperne di più sui concetti e sulle pratiche generali necessari per implementare un sistema SAP HANA HA, consulta:
- Il documento sulle best practice di SAP Creazione di un'alta disponibilità per SAP NetWeaver e SAP HANA su Linux
- La documentazione di SAP HANA
Questa guida alla pianificazione si concentra esclusivamente sull'HA per SAP HANA e non copre l'HA per i sistemi di applicazioni. Per informazioni sull'HA per SAP NetWeaver, consulta la guida alla pianificazione dell'alta disponibilità per SAP NetWeaver su Google Cloud.
Questa guida non sostituisce la documentazione fornita da SAP.
Opzioni di alta disponibilità per SAP HANA su Google Cloud
Puoi utilizzare una combinazione di funzionalità Google Cloud e SAP per progettare una configurazione ad alta disponibilità per SAP HANA in grado di gestire gli errori sia a livello di infrastruttura che di software. La tabella seguente descrive le funzionalità SAP e Google Cloud utilizzate per garantire un'elevata disponibilità.
| Funzionalità | Descrizione |
|---|---|
| Migrazione in tempo reale di Compute Engine |
Compute Engine monitora lo stato dell'infrastruttura sottostante ed esegue automaticamente la migrazione dell'istanza da un evento di manutenzione dell'infrastruttura. Non è richiesto alcun intervento da parte dell'utente. Se possibile, Compute Engine mantiene l'istanza in esecuzione durante la migrazione. In caso di interruzioni gravi, potrebbe verificarsi un lieve ritardo tra il momento in cui l'istanza si arresta e quello in cui è disponibile. Nei sistemi multi-host, i volumi condivisi, come il volume "/hana/shared" usato nella guida all'implementazione, sono dischi permanenti collegati alla VM che ospita l'host master e sono montati NFS sugli host worker. Il volume NFS è inaccessibile per un massimo di alcuni secondi in caso di migrazione live dell'hosting master. Una volta riavviato l'host principale, il volume NFS funziona di nuovo su tutti gli host e il normale funzionamento riprende automaticamente. Un'istanza recuperata è identica all'istanza originale, inclusi l'ID istanza, l'indirizzo IP privato, tutti i metadati e lo spazio di archiviazione dell'istanza. Per impostazione predefinita, le istanze standard sono impostate per la migrazione live. Ti consigliamo di non modificare questa impostazione. Per ulteriori informazioni, consulta la sezione Eseguire la migrazione live. |
| Riavvio automatico di Compute Engine |
Se l'istanza è impostata per essere terminata in caso di evento di manutenzione o se si arresta in modo anomalo a causa di un problema hardware di base, puoi configurare Compute Engine in modo che riavvii automaticamente l'istanza. Per impostazione predefinita, le istanze sono impostate per il riavvio automatico. Ti consigliamo di non modificare questa impostazione. |
| Riavvio automatico del servizio SAP HANA |
Il riavvio automatico del servizio SAP HANA è una soluzione di recupero degli errori fornita da SAP. SAP HANA ha molti servizi configurati in esecuzione in continuazione per varie attività. Quando uno di questi servizi viene disattivato a causa di un guasto del software o di un errore umano, la funzione di watchdog di riavvio automatico del servizio SAP HANA lo riavvia automaticamente. Quando il servizio viene riavviato, carica di nuovo in memoria tutti i dati necessari e riprende il suo funzionamento. |
| Backup di SAP HANA |
I backup di SAP HANA creano copie dei dati del database che possono essere utilizzate per ricostruire il database in un determinato momento. Per ulteriori informazioni sull'utilizzo dei backup di SAP HANA su Google Cloud, consulta la guida alle operazioni di SAP HANA. |
| Replicazione dello spazio di archiviazione SAP HANA |
La replica dello spazio di archiviazione SAP HANA fornisce il supporto per il ripristino di emergenza a livello di archiviazione tramite determinati partner hardware. La replica dello spazio di archiviazione SAP HANA non è supportata su Google Cloud. Ti consigliamo di utilizzare gli snapshot disco permanente di Compute Engine. Per ulteriori informazioni sull'utilizzo degli snapshot disco permanente per eseguire il backup dei sistemi SAP HANA su Google Cloud, consulta la guida alle operazioni di SAP HANA. |
| Failover automatico dell'host SAP HANA |
Il failover automatico dell'host SAP HANA è una soluzione di recupero degli errori locali che richiede uno o più host SAP HANA di riserva in un sistema scalabile orizzontalmente. Se uno degli host principali non funziona, il failover automatico dell'host mette automaticamente online l'host di riserva e riavvia l'host che ha riscontrato un errore come host di riserva. Per ulteriori informazioni, vedi: |
| Replicazione di sistema SAP HANA |
La replica del sistema SAP HANA ti consente di configurare uno o più sistemi per sostituire il sistema principale in scenari di alta disponibilità o di ripristino di emergenza. Puoi ottimizzare la replica in base alle tue esigenze in termini di prestazioni e tempo di failover. |
| Opzione Fast Restart di SAP HANA (consigliata) |
Il riavvio rapido di SAP HANA riduce il tempo di riavvio nel caso in cui SAP HANA
venga terminato, ma il sistema operativo rimanga in esecuzione. SAP HANA riduce
il tempo di riavvio sfruttando la funzionalità della memoria permanente SAP HANA
per preservare i frammenti di dati MAIN delle tabelle del magazzino delle colonne
nella DRAM mappata al file system Per ulteriori informazioni sull'utilizzo dell'opzione di riavvio rapido di SAP HANA, consulta le guide al deployment ad alta disponibilità: |
| Hook del provider SAP HANA HA/RE (opzione consigliata) |
Gli hook del provider SAP HANA HA/RE consentono a SAP HANA di inviare notifiche per determinati eventi al cluster Pacemaker, migliorando così il rilevamento degli errori. Gli hook del provider SAP HANA HA/RE richiedono
Per ulteriori informazioni sull'utilizzo degli hook del provider SAP HANA HA/RE, consulta le guide al deployment ad alta disponibilità: |
Cluster HA nativi del sistema operativo per SAP HANA su Google Cloud
Il clustering del sistema operativo Linux fornisce consapevolezza delle applicazioni e degli ospiti per lo stato dell'applicazione e automatizza le azioni di recupero in caso di errore.
Sebbene i principi dei cluster ad alta disponibilità che si applicano in ambienti non cloud in genere si applichino anche a Google Cloud, esistono differenze nel modo in cui vengono implementati alcuni elementi, come il fencing e gli IP virtuali.
Puoi utilizzare distribuzioni Linux ad alta disponibilità Red Hat o SUSE per il tuo cluster HA per SAP HANA su Google Cloud.
Per istruzioni su come eseguire il deployment e configurare manualmente un cluster HA su Google Cloud per SAP HANA, consulta:
- Configurazione manuale del cluster ad alta disponibilità scalabile verticalmente su RHEL
- Configurazione manuale del cluster ad alta disponibilità su SLES:
Per le opzioni di deployment automatico fornite da Google Cloud, consulta Opzioni di deployment automatico per le configurazioni ad alta disponibilità di SAP HANA.
Agenti delle risorse del cluster
Sia Red Hat che SUSE forniscono agenti di risorse per Google Cloud con le loro implementazioni ad alta disponibilità del software del cluster Pacemaker. Gli agenti di risorse per la gestione di recinti, VIP implementati con route o IP alias e azioni di archiviazione. Google Cloud
Per fornire aggiornamenti non ancora inclusi negli agenti di risorse di sistema operativo di base, Google Cloud fornisce periodicamente agenti di risorse aggiuntivi per i cluster HA per SAP. Quando sono necessari questi agenti di risorse aggiuntivi, le procedure diGoogle Cloud implementazione includono un passaggio per scaricarli.
Agenti di recinzione
La recinzione, nel contesto del Google Cloud clustering del sistema operativo Compute Engine, assume la forma di STONITH, che fornisce a ogni membro di un cluster di due nodi la possibilità di riavviare l'altro nodo.
Google Cloud fornisce due agenti di recinzione da utilizzare con SAP sui sistemi operativi Linux: l'agente fence_gce incluso nelle distribuzioni Red Hat e SUSE Linux certificate e l'agente gcpstonith precedente, che puoi anche scaricare per utilizzarlo con le distribuzioni Linux che non includono l'agente fence_gce. Ti consigliamo di utilizzare l'agente fence_gce, se disponibile.
Autorizzazioni IAM richieste per gli agenti di recinzione
Gli agenti di isolamento riavviano le VM effettuando una chiamata di reimpostazione all'API Compute Engine. Per l'autenticazione e l'autorizzazione per accedere all'API, gli agenti di recinzione utilizzano l'account di servizio della VM. All'account di servizio utilizzato da un agente di recinzione deve essere concesso un ruolo che includa le seguenti autorizzazioni:
- compute.instances.get
- compute.instances.list
- compute.instances.reset
- compute.instances.start
- compute.instances.stop
- compute.zoneOperations.get
- logging.logEntries.create
- compute.zoneOperations.list
Il ruolo Amministratore istanze Compute predefinito contiene tutte le autorizzazioni richieste.
Per limitare l'ambito dell'autorizzazione di riavvio dell'agente al nodo di destinazione, puoi configurare l'accesso basato sulle risorse. Per ulteriori informazioni, consulta la pagina Configurazione dell'accesso basato sulle risorse.
Indirizzo IP virtuale
I cluster ad alta disponibilità per SAP su Google Cloud utilizzano un indirizzo IP virtuale o variabile (VIP) per reindirizzare il traffico di rete da un host all'altro in caso di failover.
I tipici implementazioni non cloud utilizzano una richiesta di protocollo ARP (Address Resolution Protocol) gratuita per annunciare il movimento e la riassegnazione di un VIP a un nuovo indirizzo MAC.
Su Google Cloud, anziché utilizzare richieste ARP gratuite, puoi utilizzare uno di diversi metodi per spostare e riallocare un VIP in un cluster HA. Il metodo consigliato è utilizzare un bilanciatore del carico TCP/UDP interno, ma, a seconda delle tue esigenze, puoi anche utilizzare un'implementazione VIP basata su route o un'implementazione VIP basata su IP alias.
Per ulteriori informazioni sull'implementazione dell'IP virtuale su Google Cloud, consulta Implementazione dell'IP virtuale su Google Cloud.
Archiviazione e replica
Una configurazione del cluster SAP HANA HA utilizza la replica di sistema SAP HANA sincrona per mantenere sincronizzati i database SAP HANA principali e secondari. Gli agenti di risorse standard forniti dal sistema operativo per SAP HANA gestiscono la replica di sistema durante un failover, avviando e arrestando la replica e cambiando le istanze che fungono da istanze attive e di standby nel processo di replica.
Se hai bisogno di archiviazione file condivisa, i filer basati su NFS o SMB possono fornire la funzionalità richiesta.
Per una soluzione di archiviazione condivisa ad alta disponibilità, puoi utilizzare Filestore, il livello di servizio Premium o Extreme di Google Cloud NetApp Volumes, o una soluzione di condivisione di file di terze parti. Il livello di servizio regionale (in precedenza Enterprise) di Filestore può essere utilizzato per i deployment multizona, mentre il livello di base di Filestore può essere utilizzato per i deployment monozona.
I dischi permanenti regionali di Compute Engine offrono archiviazione a blocchi con replica sincrona tra le zone. Sebbene i dischi persistenti regionali non siano supportati per lo spazio di archiviazione del database nei sistemi SAP HA, puoi utilizzarli con i file server NFS.
Per saperne di più sulle opzioni di archiviazione su Google Cloud, consulta:
Impostazioni di configurazione per i cluster ad alta disponibilità su Google Cloud
Google Cloud consiglia di modificare i valori predefiniti di determinati parametri di configurazione del cluster in valori più adatti per i sistemi SAP nell' Google Cloud ambiente. Se utilizzi gli script di automazione forniti da Google Cloud, i valori consigliati vengono impostati automaticamente.
Considera i valori consigliati come punto di partenza per ottimizzare le impostazioni di Corosync nel cluster HA. Devi verificare che la sensibilità del rilevamento degli errori e l'attivazione del failover siano appropriate per i tuoi sistemi e workload nell' Google Cloud ambiente.
Valori dei parametri di configurazione di Corosync
Nelle guide alla configurazione del cluster HA per SAP HANA, Google Cloud
si consigliano valori per diversi parametri
nella sezione totem del file di configurazione corosync.conf che sono
diversi dai valori predefiniti impostati da Corosync o dal tuo fornitore di Linux.
totem per i quali Google Cloud
viene consigliato di impostare dei valori, nonché l'impatto della modifica dei valori. Per i valori predefiniti
di questi parametri, che possono variare da una distribuzione Linux all'altra, consulta la documentazione
della tua distribuzione Linux.
| Parametro | Valore consigliato | Impatto della modifica del valore |
|---|---|---|
secauth |
off |
Disattiva l'autenticazione e la crittografia di tutti i messaggi totem. |
join |
60 (ms) | Aumenta il tempo di attesa del nodo per i messaggi join
nel protocollo di adesione. |
max_messages |
20 | Aumenta il numero massimo di messaggi che possono essere inviati dal nodo dopo aver ricevuto il token. |
token |
20000 (ms) |
Aumenta il tempo di attesa del nodo per un token di protocollo
L'aumento del valore del parametro
Il valore del parametro |
consensus |
N/D | Specifica, in millisecondi, il tempo di attesa per il raggiungimento del consenso prima di iniziare un nuovo ciclo di configurazione dell'appartenenza.
Ti consigliamo di omettere questo parametro. Quando il parametro consensus,
assicurati che sia 24000 o
1.2*token, a seconda del valore maggiore.
|
token_retransmits_before_loss_const |
10 | Aumenta il numero di ritrasmissioni del token tentate dal nodo prima di concludere che il nodo destinatario ha avuto un errore e di intervenire. |
transport |
|
Specifica il meccanismo di trasporto utilizzato da corosync. |
Per ulteriori informazioni sulla configurazione del file corosync.conf, consulta la guida alla configurazione della tua distribuzione Linux:
- RHEL: Modifica le impostazioni predefinite di corosync.conf
- SLES: crea i file di configurazione di Corosync
Impostazioni di timeout e intervallo per le risorse del cluster
Quando definisci una risorsa del cluster, imposti i valori interval
e timeout, in secondi, per varie operazioni sulle risorse (op).
Ad esempio:
primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations \$id="rsc_sap2_HA1_HDB00-operations" \ op monitor interval="10" timeout="600" \ op start interval="0" timeout="600" \ op stop interval="0" timeout="300" \ params SID="HA1" InstanceNumber="00" clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta is-managed="true" clone-node-max="1" target-role="Started" interleave="true"
I valori timeout influiscono su ciascuna delle operazioni sulle risorse in modo diverso, come spiegato nella tabella seguente.
| Operazione della risorsa | Azione di timeout |
|---|---|
monitor |
Se il timeout viene superato, lo stato del monitoraggio viene solitamente riportato come non riuscito e la risorsa associata è considerata in stato di errore. Il cluster tenta le opzioni di recupero, che possono includere un failover. Il cluster non riprova un'operazione di monitoraggio non riuscita. |
start |
Se non riesce ad avviarsi prima del raggiungimento del timeout, il cluster tenta di riavviare la risorsa. Il comportamento è dettato dall'azione in caso di errore associata a una risorsa. |
stop |
Se una risorsa non risponde a un'operazione di arresto prima del raggiungimento del timeout, viene attivato un evento di recinzione. |
Insieme ad altre impostazioni di configurazione del cluster, le impostazioni interval e timeout
delle risorse del cluster influiscono sulla rapidità con cui il software del cluster
rileva un errore e attiva un failover.
I valori timeout e interval suggeriti da Google Cloud nelle
guide alla configurazione del cluster per l'account SAP HANA per gli eventi di manutenzione della
migrazione live di Compute Engine.
Indipendentemente dai valori timeout e interval che utilizzi, devi valutare i valori quando testi il cluster, in particolare durante i test di migrazione live, perché la durata degli eventi di migrazione live può variare leggermente a seconda del tipo di macchina in uso e di altri fattori, come l'utilizzo del sistema.
Impostazioni della risorsa recinzione
Nelle guide alla configurazione del cluster ad alta disponibilità per SAP HANA, Google Cloud vengono consigliati diversi parametri durante la configurazione delle risorse di recinzione del cluster ad alta disponibilità. I valori consigliati sono diversi da quelli predefiniti impostati da Corosync o dal tuo distributore Linux.
La tabella seguente mostra i parametri di recinzione consigliati da Google Cloudinsieme ai valori consigliati e ai dettagli dei parametri. Per i valori predefiniti dei parametri, che possono variare tra le distribuzioni Linux, consulta la documentazione della tua distribuzione Linux.
| Parametro | Valore consigliato | Dettagli |
|---|---|---|
pcmk_reboot_timeout |
300 (secondi) | Specifica il valore del timeout da utilizzare per le azioni di riavvio.
Il valore
|
pcmk_monitor_retries |
4 | Specifica il numero massimo di volte per riprovare a eseguire il comando monitor entro il periodo di timeout. |
pcmk_delay_max |
30 (secondi) | Specifica un ritardo casuale per le azioni di recinzione per impedire ai nodi del cluster di recintarsi contemporaneamente. Per evitare una gara di recinzione assicurandoti che solo a un'istanza venga assegnato un ritardo casuale, questo parametro deve essere attivato solo su una delle risorse di recinzione in un cluster HANA HA a due nodi (scalabilità verticale). In un cluster HANA HA scalabile, questo parametro deve essere attivato su tutti i nodi che fanno parte di un sito (principale o secondario) |
Test del cluster ad alta disponibilità su Google Cloud
Dopo aver configurato il cluster e aver eseguito il deployment dei sistemi SAP HANA e del cluster nell'ambiente di test, devi testare il cluster per verificare che il sistema HA sia configurato correttamente e funzioni come previsto.
Per verificare che il failover funzioni come previsto, simula vari scenari di errore con le seguenti azioni:
- Arresta la VM
- Creare un kernel panic
- Arresta l'applicazione
- Interrompere la rete tra le istanze
Inoltre, simula un evento di migrazione live di Compute Engine sull'host primario per verificare che non venga attivato un failover. Puoi simulare un
evento di manutenzione utilizzando il comando Google Cloud CLI gcloud compute instances
simulate-maintenance-event.
Logging e monitoraggio
Gli agenti delle risorse possono includere funzionalità di logging che propagano i log a Google Cloud Observability per l'analisi. Ogni agente delle risorse include informazioni di configurazione che identificano eventuali opzioni di registrazione. Nel caso di implementazioni di bash, l'opzione di logging è gcloud logging.
Puoi anche installare l'agente Cloud Logging per acquisire l'output dei log dai processi del sistema operativo e correlare l'utilizzo delle risorse agli eventi di sistema. L'agente Logging acquisisce i log di sistema predefiniti, che includono i dati dei log di Pacemaker e dei servizi di clustering. Per ulteriori informazioni, consulta Informazioni sull'agente di logging.
Per informazioni sull'utilizzo di Cloud Monitoring per configurare i controlli dei servizi che monitorano la disponibilità degli endpoint dei servizi, consulta Gestire i controlli di uptime.
Account di servizio e cluster HA
Le azioni che il software del cluster può eseguire nell'ambiente Google Cloud sono protette dalle autorizzazioni concesse all'account di servizio di ogni VM host. Per gli ambienti ad alta sicurezza, puoi limitare le autorizzazioni negli account di servizio delle VM host in conformità al principio del privilegio minimo.
Quando limiti le autorizzazioni del account di servizio, tieni presente che il tuo sistema potrebbe interagire con Google Cloud servizi, come Cloud Storage, pertanto potresti dover includere le autorizzazioni per queste interazioni nel account di servizio della VM host.
Per le autorizzazioni più restrittive, crea un ruolo personalizzato con le autorizzazioni minime richieste. Per informazioni sui ruoli personalizzati, consulta Creare e gestire i ruoli personalizzati. Puoi limitare ulteriormente le autorizzazioni limitandole solo a istanze specifiche di una risorsa, ad esempio le istanze VM nel cluster HA, aggiungendo condizioni nelle associazioni di ruolo dei criteri IAM di una risorsa.
Le autorizzazioni minime di cui hanno bisogno i tuoi sistemi dipendono dalleGoogle Cloud risorse a cui accedono e dalle azioni che eseguono. Di conseguenza, per determinare le autorizzazioni minime richieste per le VM host nel cluster HA potrebbe essere necessario esaminare esattamente a quali risorse accedono i sistemi sulla VM host e le azioni che questi sistemi eseguono con queste risorse.
Come punto di partenza, il seguente elenco mostra alcune risorse del cluster HA e le autorizzazioni associate richieste:
- Recinzione
- compute.instances.list
- compute.instances.get
- compute.instances.reset
- compute.instances.stop
- compute.instances.start
- logging.logEntries.create
- compute.zones.list
- VIP implementato utilizzando un IP alias
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.instances.updateNetworkInterface
- compute.zoneOperations.get
- logging.logEntries.create
- VIP implementato utilizzando route statiche
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.routes.get
- compute.routes.create
- compute.routes.delete
- compute.routes.update
- compute.routes.list
- compute.networks.updatePolicy
- compute.networks.get
- compute.globalOperations.get
- logging.logEntries.create
- VIP implementato utilizzando un bilanciatore del carico interno
- Non sono richieste autorizzazioni specifiche: il bilanciatore del carico opera su stati controllo di integrità che non richiedono l'interazione del cluster con le risorse o la loro modifica in Google Cloud
Implementazione di IP virtuale su Google Cloud
Un cluster ad alta disponibilità utilizza un indirizzo IP (VIP) virtuale o mobile per spostare il proprio carico di lavoro da un nodo del cluster all'altro in caso di guasto imprevisto o per la manutenzione pianificata. L'indirizzo IP del VIP non cambia, pertanto le applicazioni client non sanno che il lavoro viene eseguito da un altro nodo.
Un VIP è noto anche come indirizzo IP dinamico.
In Google Cloud, i VIP vengono implementati in modo leggermente diverso rispetto alle installazioni on-premise, in quanto, quando si verifica un failover, non è possibile utilizzare richieste ARP gratuite per annunciare la modifica. In alternativa, puoi implementare un indirizzo VIP per un cluster SAP HA utilizzando uno dei seguenti metodi:
- Supporto del failover del bilanciatore del carico di rete passthrough interno (consigliato).
- Google Cloud Percorsi statici.
- IndirizziGoogle Cloud IP alias.
Implementazioni di VIP del bilanciatore del carico di rete passthrough interno
In genere, un bilanciatore del carico distribuisce il traffico degli utenti su più istanze delle tue applicazioni, sia per distribuire il carico di lavoro su più sistemi attivi sia per proteggerti da un rallentamento o da un errore di elaborazione su una singola istanza.
Il bilanciatore del carico di rete passthrough interno fornisce anche il supporto del failover che puoi utilizzare con i controlli di integrità di Compute Engine per rilevare gli errori, attivare il failover e reindirizzare il traffico a un nuovo sistema SAP principale in un cluster HA nativo del sistema operativo.
Il supporto del failover è l'implementazione VIP consigliata per una serie di motivi, tra cui:
- Il bilanciamento del carico su Compute Engine offre uno SLA (accordo sul livello del servizio) con disponibilità del 99,99%.
- Il bilanciamento del carico supporta i cluster multi-zona ad alta disponibilità, che proteggono dai guasti delle zone con tempi di failover tra zone prevedibili.
- L'utilizzo del bilanciamento del carico riduce il tempo necessario per rilevare e attivare un failover, in genere entro pochi secondi dall'errore. I tempi di failover complessivi dipendono dai tempi di failover di ciascun componente del sistema HA, che può includere host, sistemi di database, sistemi di applicazioni e altro ancora.
- L'utilizzo del bilanciamento del carico semplifica la configurazione del cluster e riduce le dipendenze.
- A differenza di un'implementazione VIP che utilizza le route, con il bilanciamento del carico puoi utilizzare intervalli IP della tua rete VPC, consentendoti di prenotarli e configurarli in base alle tue esigenze.
- Il bilanciamento del carico può essere facilmente utilizzato per reindirizzare il traffico a un sistema secondario per interruzioni pianificate per la manutenzione.
Quando crei un controllo di integrità per un'implementazione di un bilanciatore del carico di un VIP, specifica la porta dell'host che il controllo di integrità esegue per determinare l'integrità dell'host. Per un cluster SAP HA, specifica una porta host di destinazione che rientri nell'intervallo privato 49152-65535 per evitare conflitti con altri servizi. Nella VM host, configura la porta di destinazione con un servizio di assistenza secondario, ad esempio l'utilità socat o HAProxy.
Per i cluster di database in cui il sistema di riserva secondario rimane online, il servizio di controllo di integrità e di assistenza consente al bilanciamento del carico di indirizzare il traffico al sistema online che attualmente funge da sistema principale nel cluster.
Utilizzando il servizio di assistenza e il reindirizzamento delle porte, puoi attivare un failover per la manutenzione pianificata del software sui tuoi sistemi SAP.
Per ulteriori informazioni sul supporto del failover, consulta Configurare il failover per i bilanciatori del carico di rete passthrough interni.
Per eseguire il deployment di un cluster HA con un'implementazione VIP del bilanciatore del carico, consulta:
- Terraform: guida alla configurazione del cluster SAP HANA ad alta disponibilità
- Guida alla configurazione del cluster ad alta disponibilità per SAP HANA su RHEL
- Guida alla configurazione del cluster ad alta disponibilità per SAP HANA su SLES
Implementazioni VIP con route statiche
L'implementazione della route statica fornisce anche protezione contro i guasti delle zone, ma richiede l'utilizzo di un VIP al di fuori degli intervalli IP delle subnet VPC esistenti in cui si trovano le VM. Di conseguenza, devi anche assicurarti che il VIP non entri in conflitto con gli indirizzi IP esterni nella rete estesa.
Le implementazioni delle route statiche possono anche introdurre complessità se utilizzate con configurazioni VPC condivise, che hanno lo scopo di separare la configurazione di rete in un progetto host.
Se utilizzi un'implementazione di route statica per il VIP, rivolgiti all'amministratore di rete per determinare un indirizzo IP adatto per un'implementazione di route statica.
Implementazioni VIP IP alias
Le implementazioni VIP IP alias non sono consigliate per i deployment HA multi-zona perché, se una zona non funziona, la riallocazione dell'IP alias a un nodo in un'altra zona può essere ritardata. Implementa il VIP con un bilanciatore del carico di rete passthrough interno con supporto del failover.
Se esegui il deployment di tutti i nodi del cluster SAP HA nella stessa zona, puoi utilizzare un alias IP per implementare un VIP per il cluster HA.
Se disponi di cluster SAP HA multizona esistenti che utilizzano un'implementazione di IP alias per l'IP virtuale, puoi eseguire la migrazione a un'implementazione di bilanciatore del carico di rete passthrough interno senza modificare l'indirizzo IP virtuale. Sia gli indirizzi IP alias sia i bilanciatori del carico di rete passthrough interni utilizzano intervalli IP della rete VPC.
Sebbene gli indirizzi IP alias non siano consigliati per le implementazioni VIP nei cluster HA multizona, hanno altri casi d'uso nei deployment SAP. Ad esempio, possono essere utilizzati per fornire un nome host logico e le assegnazioni IP per deployment SAP flessibili, come quelli gestiti da SAP Landscape Management.
Best practice generali per i VIP su Google Cloud
Per saperne di più sugli IP virtuali su Google Cloud, consulta Best practice per gli indirizzi IP mobili.
Failover automatico dell'host SAP HANA attivo Google Cloud
Google Cloud supporta il failover automatico dell'host SAP HANA, la soluzione di recupero dei guasti locale fornita da SAP HANA. La soluzione di failover automatico dell'host utilizza uno o più host di riserva che vengono tenuti in riserva per assumere il lavoro dall'host principale o da un host di lavoro in caso di guasto dell'host. Gli host di riserva non contengono dati né elaborano alcun lavoro.
Al termine di un failover, l'host con problemi viene riavviato come host di riserva.
SAP supporta fino a tre host di riserva nei sistemi di scale out su Google Cloud. Gli host di riserva non vengono conteggiati nel numero massimo di 16 host attivi supportati da SAP nei sistemi di scale out suGoogle Cloud.
Per ulteriori informazioni di SAP sulla soluzione di failover automatico dell'host, consulta Failover automatico dell'host.
Quando utilizzare il failover automatico dell'host SAP HANA Google Cloud
Il failover automatico dell'host SAP HANA protegge dai guasti che interessano un singolo node in un sistema SAP HANA scalabile orizzontalmente, inclusi i guasti di:
- L'istanza SAP HANA
- Il sistema operativo host
- La VM host
Per quanto riguarda gli errori della VM host, il riavvio automatico Google Cloud, che in genere ripristina la VM host SAP HANA più velocemente del failover automatico dell'host, e migrazione live proteggono insieme dai guasti pianificati e non pianificati della VM. Pertanto, per la protezione delle VM, la soluzione di failover automatico dell'host SAP HANA non è necessaria.
Il failover automatico dell'host SAP HANA non protegge dagli errori zonali, perché tutti i nodi di un sistema SAP HANA scalabile orizzontalmente vengono di solito implementati in un'unica zona.
Il failover automatico dell'host SAP HANA non precarica i dati SAP HANA nella memoria dei nodi di standby, pertanto quando un nodo di standby prende il controllo, il tempo di recupero complessivo del nodo è determinato principalmente dal tempo necessario per caricare i dati nella memoria del nodo di standby.
Valuta la possibilità di utilizzare il failover automatico dell'host SAP HANA per i seguenti scenari:
- Errori nel software o nel sistema operativo host di un nodo SAP HANA che potrebbero non essere rilevati da Google Cloud.
- Migrazioni lift and shift, in cui devi riprodurre la configurazione di SAP HANA on-premise finché non puoi ottimizzare SAP HANA perGoogle Cloud.
- Quando una configurazione di alta disponibilità completamente replicata e tra zone è proibitiva in termini di costi e la tua attività può tollerare:
- Un tempo di recupero del nodo più lungo dovuto alla necessità di caricare i dati SAP HANA nella memoria di un nodo di standby.
- Il rischio di errori a livello di zona.
Il Gestione archiviazione per SAP HANA
I volumi /hana/data e /hana/log vengono montati solo sugli host master e worker. Quando si verifica un takeover, la soluzione di failover automatico dell'host
utilizza l'API SAP HANA Storage Connector e il
Google Cloud gestore dello spazio di archiviazione per i nodi di standby SAP HANA per spostare i mount dei volumi dall'Google Cloud host in cui si è verificato l'errore all'host di standby.
Su Google Cloud, lo Gestione archiviazione per SAP HANA è obbligatorio per i sistemi SAP HANA che utilizzano il failover automatico dell'host SAP HANA.
Versioni supportate del Gestione archiviazione per SAP HANA
Sono supportate le versioni 2.0 e successive dello Gestione archiviazione per SAP HANA. Tutte le versioni precedenti alla 2.0 sono ritirate e non supportate. Se utilizzi una versione precedente, aggiorna il sistema SAP HANA in modo da utilizzare la versione più recente dello Gestione archiviazione per SAP HANA. Consulta Aggiornamento di Gestione archiviazione per SAP HANA.
Per determinare se la tua versione è deprecata, apri il file gceStorageClient.py.
La directory di installazione predefinita è /hana/shared/gceStorageClient.
A partire dalla versione 2.0, il numero di versione è indicato nei commenti nella parte superiore del file gceStorageClient.py, come mostrato nell'esempio seguente. Se il numero di versione è mancante, significa che stai utilizzando una versione ritirata del Gestione archiviazione per SAP HANA.
"""Google Cloud Storage Manager for SAP HANA Standby Nodes. The Storage Manager for SAP HANA implements the API from the SAP provided StorageConnectorClient to allow attaching and detaching of disks when running in Compute Engine. Build Date: Wed Jan 27 06:39:49 PST 2021 Version: 2.0.20210127.00-00 """
Installazione di Gestione archiviazione per SAP HANA
Il metodo consigliato per installare lo Gestione archiviazione per SAP HANA è utilizzare un metodo di deployment automatico per eseguire il deployment di un sistema SAP HANA scalabile orizzontalmente che includa lo Gestione archiviazione più recente per SAP HANA.
Se devi aggiungere il failover automatico dell'host SAP HANA a un sistema SAP HANA scalabile orizzontalmente esistente su Google Cloud, l'approccio consigliato è simile: utilizza il file di configurazione Terraform fornito da Google Cloud per eseguire il deployment di un nuovo sistema SAP HANA scalabile orizzontalmente e poi carica i dati nel nuovo sistema dal sistema esistente. Per caricare i dati, puoi utilizzare le procedure di backup e recupero standard di SAP HANA o la replica del sistema SAP HANA, che può limitare il tempo di riposo. Per ulteriori informazioni sulla replica di sistema, consulta la nota SAP 2473002 - Utilizzo della replica di sistema HANA per eseguire la migrazione di un sistema di scalabilità orizzontale.
Se non puoi utilizzare un metodo di deployment automatico, ti consigliamo di contattare un consulente SAP, come quelli disponibili tramite i Google Cloud servizi di consulenza, per ricevere assistenza per l'installazione manuale dello Gestione archiviazione per SAP HANA.
Al momento non è documentata l'installazione manuale dello Gestione archiviazione per SAP HANA in un sistema SAP HANA scale-out esistente o nuovo.
Per ulteriori informazioni sulle opzioni di deployment automatico per il failover automatico dell'host SAP HANA, consulta Deployment automatico di sistemi SAP HANA scalabili orizzontalmente con il failover automatico dell'host SAP HANA.
Aggiornamento di Gestione archiviazione per SAP HANA
Aggiorna lo Gestione archiviazione per SAP HANA scaricando prima il pacchetto di installazione e poi eseguendo uno script di installazione, che aggiorna lo Gestione archiviazione per l'eseguibile SAP HANA nel drive /shared SAP HANA.
La procedura riportata di seguito è valida solo per la versione 2 dello Gestione archiviazione per SAP HANA. Se utilizzi una versione di Gestione archiviazione per SAP HANA scaricata prima del 1° febbraio 2021, installa la versione 2 prima di tentare di aggiornare Gestione archiviazione per SAP HANA.
Per aggiornare lo Gestione archiviazione per SAP HANA:
Controlla la versione del tuo attuale Gestione archiviazione per SAP HANA:
RHEL
sudo yum check-update google-sapgcestorageclient
SLES
sudo zypper list-updates -r google-sapgcestorageclient
Se è disponibile un aggiornamento, installalo:
RHEL
sudo yum update google-sapgcestorageclient
SLES
sudo zypper update
Lo Gestione archiviazione aggiornato per SAP HANA è installato in
/usr/sap/google-sapgcestorageclient/gceStorageClient.py.Sostituisci l'ontologia
gceStorageClient.pyesistente con il filegceStorageClient.pyaggiornato:Se il file
gceStorageClient.pyesistente si trova in/hana/shared/gceStorageClient, la posizione di installazione predefinita, utilizza lo script di installazione per aggiornarlo:sudo /usr/sap/google-sapgcestorageclient/install.sh
Se il file
gceStorageClient.pyesistente non si trova in/hana/shared/gceStorageClient, copia il file aggiornato nella stessa posizione del file esistente, sostituendolo.
Parametri di configurazione nel file global.ini
Alcuni parametri di configurazione per lo Gestione archiviazione di SAP HANA, tra cui l'attivazione o la disattivazione del fencing, sono memorizzati nella sezione dello spazio di archiviazione del file global.ini di SAP HANA. Quando utilizzi il file di configurazione Terraform fornito da Google Cloud per eseguire il deployment di un sistema SAP HANA con la funzione di failover automatico dell'host, la procedura di deployment aggiunge automaticamente i parametri di configurazione al file global.ini.
L'esempio seguente mostra i contenuti di un global.ini creato per lo Gestione archiviazione per SAP HANA:
[persistence] basepath_datavolumes = %BASEPATH_DATAVOLUMES% basepath_logvolumes = %BASEPATH_LOGVOLUMES% use_mountpoints = %USE_MOUNTPOINTS% basepath_shared = %BASEPATH_SHARED% [storage] ha_provider = gceStorageClient ha_provider_path = %STORAGE_CONNECTOR_PATH% # # Example configuration for 2+1 setup # # partition_1_*__pd = node-mnt00001 # partition_2_*__pd = node-mnt00002 # partition_3_*__pd = node-mnt00003 # partition_*_data__dev = /dev/hana/data # partition_*_log__dev = /dev/hana/log # partition_*_*__gcloudAccount = svc-acct-name@project-id. # partition_*_data__mountOptions = -t xfs -o logbsize=256k # partition_*_log__mountOptions = -t xfs -o logbsize=256k # partition_*_*__fencing = disabled [trace] ha_gcestorageclient = info
Accesso sudo per lo Gestione archiviazione per SAP HANA
Per gestire i servizi e lo spazio di archiviazione SAP HANA, il Gestione archiviazione per SAP HANA utilizza l'account utente SID_LCadm e richiede l'accesso sudo a determinati file binari di sistema.
Se utilizzi gli script di automazione forniti da Google Cloud per eseguire il deployment di SAP HANA con il failover automatico dell'host, l'accesso sudo richiesto viene configurato per te.
Se installi manualmente lo Gestione archiviazione per SAP HANA, utilizza il comando visudo per modificare il file /etc/sudoers in modo da concedere all'account utente SID_LCadm l'accesso sudo ai seguenti binari richiesti.
Fai clic sulla scheda del tuo sistema operativo:
RHEL
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof /usr/sbin/xfs_repair
SLES
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /sbin/xfs_repair /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof
L'esempio seguente mostra una voce nel file /etc/sudoers. Nell'esempio, l'ID sistema per il sistema SAP HANA associato viene sostituito con SID_LC. La voce di esempio è stata creata dalla configurazione Terraform fornita da Google Cloud per il scaling out di SAP HANA con failover automatico dell'host.
La voce creata dalla configurazione di Terraform include i binari non più richiesti, ma mantenuti per la compatibilità con le versioni precedenti. Devi includere solo i binari elencati sopra.
SID_LCadm ALL=NOPASSWD: /sbin/multipath,/sbin/multipathd,/etc/init.d/multipathd,/usr/bin/sg_persist,/bin/mount,/bin/umount,/bin/kill,/usr/bin/lsof,/usr/bin/systemctl,/usr/sbin/lsof,/usr/sbin/xfs_repair,/sbin/xfs_repair,/usr/bin/mkdir,/sbin/vgscan,/sbin/pvscan,/sbin/lvscan,/sbin/vgchange,/sbin/lvdisplay,/usr/bin/gcloud,/sbin/dmsetup
Configurazione del account di servizio per lo Gestione archiviazione per SAP HANA
Per attivare il failover automatico dell'host per il sistema SAP HANA scalabile orizzontalmente su Google Cloud, lo Gestione archiviazione per SAP HANA richiede un account di servizio. Puoi creare un account di servizio dedicato e concedergli le autorizzazioni necessarie per eseguire azioni sulle VM SAP HANA, ad esempio scollegare e collegare i dischi durante un failover. Per informazioni su come creare un account di servizio, consulta Creare un account di servizio.
Autorizzazioni IAM richieste
Per l'account di servizio utilizzato dal Gestione archiviazione per SAP HANA, devi concedere un ruolo che includa le seguenti autorizzazioni IAM:
Per reimpostare un'istanza VM utilizzando il comando
gcloud compute instances reset, concedi l'autorizzazionecompute.instances.reset.Per ottenere informazioni su un volume di Persistent Disk o Hyperdisk utilizzando il comando
gcloud compute disks describe, concedi l'autorizzazionecompute.disks.get.Per collegare un disco a un'istanza VM utilizzando il comando
gcloud compute instances attach-disk, concedi l'autorizzazionecompute.instances.attachDisk.Per scollegare un disco da un'istanza VM utilizzando il comando
gcloud compute instances detach-disk, concedi l'autorizzazionecompute.instances.detachDisk.Per elencare le istanze VM utilizzando il comando
gcloud compute instances list, concedi l'autorizzazionecompute.instances.list.Per elencare i volumi di Persistent Disk o Hyperdisk utilizzando il comando
gcloud compute disks list, concedi l'autorizzazionecompute.disks.list.
Puoi concedere le autorizzazioni richieste tramite ruoli personalizzati o altri ruoli predefiniti.
Imposta inoltre l'ambito di accesso della VM su cloud-platform in modo che le autorizzazioni IAM della VM siano completamente determinate dai ruoli IAM che concedi all'account di servizio.
Per impostazione predefinita, lo Gestione archiviazione per SAP HANA utilizza l'account di servizio o utente attivo che gcloud CLI è autorizzato a utilizzare sugli host del sistema SAP HANA scalabile.
Per controllare l'account attivo utilizzato dal Gestione archiviazione per SAP HANA, utilizza il seguente comando:
gcloud auth list
Per informazioni su questo comando, consulta gcloud auth list.
Per modificare l'account utilizzato dal Gestione archiviazione per SAP HANA:
Assicurati che l'account di servizio sia disponibile su ogni host nel sistema SAP HANA scalabile orizzontalmente:
gcloud auth listNel file
global.ini, aggiorna la sezione[storage]con l'account di servizio:[storage] ha_provider = gceStorageClient ... partition_*_*__gcloudAccount = SERVICE_ACCOUNTSostituisci
SERVICE_ACCOUNTcon il nome dell'account di servizio, in formato indirizzo email, utilizzato dallo Gestione archiviazione per SAP HANA. Questo account di servizio viene utilizzato quando vengono emessi comandigclouddal Gestione archiviazione per SAP HANA.
Spazio di archiviazione NFS per il failover automatico dell'host SAP HANA
Un sistema SAP HANA scalabile orizzontalmente con failover automatico dell'host richiede una soluzione NFS, come Filestore, per condividere i volumi /hana/shared e /hanabackup tra tutti gli host. Devi configurare la soluzione NFS autonomamente.
Quando utilizzi un metodo di deployment automatico, fornisci informazioni sul server NFS nel file di deployment per montare le directory NFS durante il deployment.
Il volume NFS che utilizzi deve essere vuoto. Eventuali file esistenti possono entrare in conflitto con il processo di implementazione, in particolare se i file o le cartelle fanno riferimento all'ID sistema SAP (SID). Il processo di deployment non può determinare se i file possono essere sovrascritti.
Il processo di deployment memorizza i volumi /hana/shared e /hanabackup sul server NFS e lo monta su tutti gli host, inclusi gli host di standby. L'host principale gestisce quindi il server NFS.
Se stai implementando una soluzione di backup, come l'agente Backint di Cloud Storage per SAP HANA, puoi rimuovere il volume /hanabackup dal server NFS al termine del deployment.
Per saperne di più sulle soluzioni di condivisione dei file disponibili su Google Cloud, consulta Soluzioni di condivisione dei file per SAP su Google Cloud.
Supporto del sistema operativo
Google Cloud supporta il failover automatico dell'host SAP HANA solo su i seguenti sistemi operativi:
- RHEL for SAP 7.7 o versioni successive
- RHEL for SAP 8.1 o versioni successive
- RHEL for SAP 9.0 o versioni successive
-
Prima di installare qualsiasi software SAP su RHEL per SAP 9.x, è necessario installare pacchetti aggiuntivi sulle tue macchine host, in particolare
chkconfigecompat-openssl11. Se utilizzi un'immagine fornita da Compute Engine, questi pacchetti vengono installati automaticamente. Per ulteriori informazioni di SAP, consulta Nota SAP 3108316 - Red Hat Enterprise Linux 9.x: installazione e configurazione .
-
Prima di installare qualsiasi software SAP su RHEL per SAP 9.x, è necessario installare pacchetti aggiuntivi sulle tue macchine host, in particolare
- SLES for SAP 12 SP5
- SLES for SAP 15 SP1 o versioni successive
Per visualizzare le immagini pubbliche disponibili in Compute Engine, consulta Immagini.
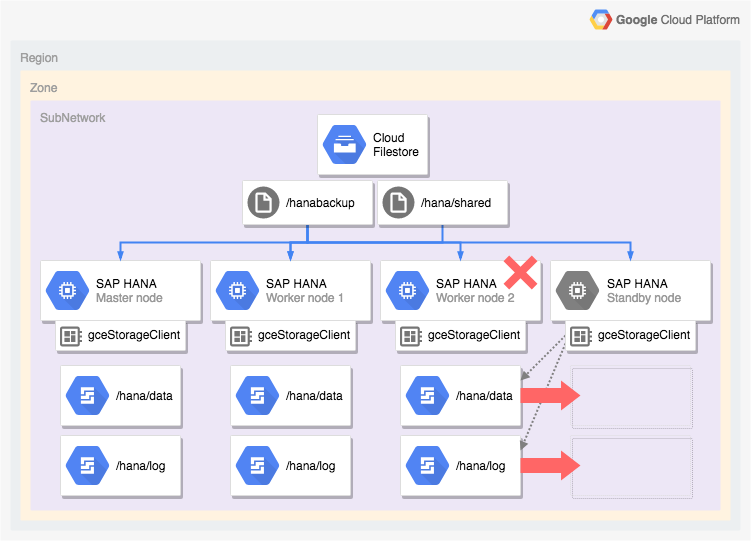
Architettura di un sistema SAP HANA con failover automatico dell'host
Il seguente diagramma mostra un'architettura scalabile su Google Cloud che include la funzionalità di failover automatico dell'host SAP HANA. Nel diagramma,
lo Gestione archiviazione per SAP HANA è rappresentato dal nome
del relativo file eseguibile, gceStorageClient.
Il diagramma mostra l'errore del nodo worker 2 e il passaggio del controllo al nodo di riserva.
Lo Gestione archiviazione per SAP HANA funziona con l'API SAP Storage Connector (non mostrata) per scollegare i dischi che contengono i volumi /hana/data e /hana/logs dal nodo worker in cui si è verificato l'errore e per rimontarla sul nodo di standby, che diventa il nodo worker 2 mentre il nodo in cui si è verificato l'errore diventa il nodo di standby.
Opzioni di deployment automatico per le configurazioni ad alta disponibilità di SAP HANA
Google Cloud fornisce configurazioni Terraform che puoi utilizzare per automatizzare il deployment dei sistemi SAP HANA HA o per eseguire il deployment e la configurazione manuale dei sistemi SAP HANA HA.
Google Cloud fornisce file di configurazione Terraform specifici per il deployment che devi completare. Utilizza i comandi Terraform standard per inizializzare la directory di lavoro corrente e scaricare i file del plug-in e del modulo del provider Terraform per Google Cloud, quindi applica la configurazione per eseguire il deployment di un sistema SAP HANA.
Questo metodo di deployment automatico consente di eseguire il deployment di un sistema SAP HANA completamente supportato da SAP e conforme alle best practice sia di SAP sia diGoogle Cloud.
Deployment automatico di cluster Linux ad alta disponibilità per SAP HANA
Per SAP HANA, il metodo di deployment automatico consente di eseguire il deployment di un cluster Linux ad alta disponibilità ottimizzato per le prestazioni che include:
- Failover automatico.
- Riavvio automatico.
- Una prenotazione dell'indirizzo IP virtuale (VIP) specificato.
- Supporto del failover fornito dal bilanciamento del carico TCP/UDP interno, che gestisce il routing dall'indirizzo IP virtuale (VIP) ai nodi del cluster HA.
- Una regola firewall che consenta ai controlli di integrità di Compute Engine di monitorare le istanze VM nel cluster.
- Il gestore delle risorse del cluster ad alta disponibilità Pacemaker.
- Un Google Cloud meccanismo di recinzione.
- Una VM con i dischi permanenti richiesti per ogni istanza SAP HANA.
- Facoltativamente, un nodo single-tenant.
- Istanze SAP HANA configurate per la replica sincrona e il pre-caricamento della memoria.
Per utilizzare Terraform per automatizzare il deployment di un cluster ad alta disponibilità per SAP HANA, consulta:
- Terraform: guida alla configurazione del cluster ad alta disponibilità SAP HANA scalabile verticalmente.
- Terraform: guida alla configurazione di cluster SAP HANA scalabili e ad alta disponibilità.
Deployment automatico di sistemi SAP HANA scalabili orizzontalmente con failover automatico dell'host SAP HANA
Puoi utilizzare Terraform per automatizzare il deployment di un sistema scalabile con host di riserva. Per ulteriori informazioni, consulta Terraform: guida al deployment di un sistema SAP HANA scalabile orizzontalmente con failover automatico dell'host.
Per un sistema SAP HANA scalabile orizzontalmente che include la funzionalità di failover automatico dell'host SAP HANA, la configurazione Terraform fornita da Google Cloud esegue il deployment di quanto segue:
- Un'istanza SAP HANA principale
- Da 1 a 15 host worker
- Da 1 a 3 host di riserva
- Una VM per ogni host SAP HANA
- Volumi Hyperdisk o Persistent Disk basati su SSD per gli host master e worker
- Il Google Cloud gestore dello spazio di archiviazione per i nodi di standby SAP HANA
Un sistema SAP HANA scalabile orizzontalmente con failover automatico dell'host richiede una soluzione NFS, come Filestore, per condividere i volumi /hana/shared e /hanabackup tra tutti gli host. Affinché Terraform possa montare le directory NFS durante il deployment, devi configurare la soluzione NFS autonomamente prima di eseguire il deployment del sistema SAP HANA.
Puoi configurare rapidamente le istanze del server NFS Filestore seguendo le istruzioni riportate in Creazione di istanze.
Opzione Active/Active (lettura abilitata) per SAP HANA
A partire da SAP HANA 2.0 SPS1, SAP fornisce la configurazione Active/Active (lettura abilitata) per gli scenari di replica di sistema SAP HANA. In un sistema di replica configurato per Active/Active (lettura abilitata), le porte SQL sul sistema secondario sono aperte per l'accesso in lettura. In questo modo, puoi utilizzare il sistema secondario per attività che richiedono molte letture e avere un migliore bilanciamento dei carichi di lavoro tra le risorse di calcolo, migliorando le prestazioni complessive del database SAP HANA. Per ulteriori informazioni sulla funzionalità Active/Active (lettura abilitata), consulta la Guida all'amministrazione di SAP HANA specifica per la tua versione di SAP HANA e la nota SAP 1999880.
Per configurare una replica di sistema che consenta l'accesso in lettura sul sistema secondario, devi utilizzare la modalità di operazione logreplay_readaccess. Tuttavia, per utilizzare questa modalità di operazione, i sistemi principali e secondari devono eseguire la stessa versione di SAP HANA. Di conseguenza, l'accesso in sola lettura al sistema secondario non è possibile durante un upgrade graduale finché entrambi i sistemi non eseguono la stessa versione di SAP HANA.
Per connettersi a un sistema secondario Active/Active (abilitato alla lettura), SAP supporta le seguenti opzioni:
- Collegarti direttamente aprendo una connessione esplicita al sistema secondario.
- Esegui una connessione indiretta eseguendo un'istruzione SQL sul sistema principale con un suggerimento, che al momento della valutazione reindirizza la query al sistema secondario.
Il seguente diagramma mostra la prima opzione, in cui le applicazioni accedono al sistema secondario direttamente in un cluster Pacemaker di cui è stato eseguito il deployment in Google Cloud. Un indirizzo IP virtuale o mobile (VIP) aggiuntivo viene utilizzato come target per l'istanza VM che funge da sistema secondario all'interno del cluster SAP HANA Pacemaker. L'IP pubblico virtuale segue il sistema secondario e può spostare il proprio carico di lavoro di lettura da un nodo del cluster all'altro in caso di guasto imprevisto o per la manutenzione pianificata. Per informazioni sui metodi di implementazione degli IP virtuali disponibili, consulta Implementazione dell'IP virtuale su Google Cloud.

Per istruzioni su come configurare la replica del sistema SAP HANA con Active/Active (lettura abilitata) in un cluster Pacemaker:
- Configurare HANA Active/Active (lettura abilitata) in un cluster SUSE Pacemaker
- Configurare HANA Active/Active (lettura abilitata) in un cluster Red Hat Pacemaker
Passaggi successivi
Sia Google Cloud che SAP forniscono ulteriori informazioni sull'alta disponibilità.
Scopri di più sull' Google Cloud alta disponibilità
Per ulteriori informazioni sull'alta disponibilità per SAP HANA su Google Cloud, consulta la Guida alle operazioni di SAP HANA.
Per informazioni generali sulla protezione dei sistemi su Google Cloud da vari scenari di errore, consulta Progettare sistemi solidi.
Ulteriori informazioni da SAP sulle funzionalità di alta disponibilità di SAP HANA
Per ulteriori informazioni di SAP sulle funzionalità di alta disponibilità di SAP HANA, consulta i seguenti documenti:
- Alta disponibilità per SAP HANA
- Nota SAP 2057595 - Domande frequenti: alta disponibilità SAP HANA
- Come eseguire la replica di sistema per SAP HANA 2.0
- Consigli sulla rete per la replica del sistema SAP HANA