データベースを保護して構成したら、データベースを Looker に接続する準備が整います。
新規データベース接続の作成
[管理] パネルの [データベース] セクションで [接続] を選択します。[Connections] ページで、[Add Connection] ボタンをクリックします。Looker に [Connection Settings] ページが表示されます。[接続設定] ページに表示されるフィールドは、言語の設定によって異なります。
接続設定にユーザー属性を適用する方法について詳しくは、ユーザー属性に関するドキュメント ページの接続セクションをご覧ください。
[PDT オーバーライド] 列を使用して PDT プロセスに個別のログイン認証情報を設定する方法については、PDT プロセス用の個別のログイン認証情報の構成セクションをご覧ください。
たとえば、Looker を Amazon Redshift に接続する場合は、次のオプションを構成できます。
名前
参照する接続の名前。フォルダの名前は使用しないでください。この値はデータベース内のものと一致する必要はなく、割り当てるラベルにすぎません。これは、LookML モデルの connection パラメータで使用します。
方言
接続に一致する SQL 言語。適切な接続オプションが表示され、Looker が LookML を SQL に正しく変換できるように、正しい値を選択することが重要です。
SSHサーバー
[SSH Server] オプションは、インスタンスが Kubernetes インフラストラクチャにデプロイされ、Looker インスタンスに構成する情報を Looker インスタンスに追加する機能が有効になっている場合にのみ使用できます。Looker インスタンスでこのオプションが有効になっていない場合、有効にするには、Looker アカウント マネージャーにお問い合わせいただくか、Looker のヘルプセンターでサポート リクエストを開いてください。
SSH サーバーが自動的にローカルホストのポートを選択するため、現時点ではローカルホストのポートを指定できません。ローカルホストのポートを指定する必要がある SSH 接続を作成する必要がある場合は、Looker アカウント マネージャーにお問い合わせいただくか、Looker のヘルプセンターでサポート リクエストを開いてください。
SSH トンネルを使用してデータベースに接続するには、切り替えボタンをオンにして、プルダウン リストから [SSH サーバーの構成] を選択します。
Remote Host:Port
データベースのホスト名と、Lookerがデータベースホストへの接続に使用するポートです。
Looker アナリストと協力してデータベースへの SSH トンネルを構成した場合は、[ホスト] フィールドに「"localhost"」と入力し、[ポート] フィールドに、データベースにリダイレクトするポート番号(Looker アナリストから提供されたもの)を入力します。
[ホスト] フィールドにユーザー属性を適用する場合、そのユーザー属性のユーザー アクセスレベルを [編集可能] に設定することはできません。
データベースに接続するために SSH トンネルを構成した場合、[Remote Host:Port] フィールドにユーザー属性を適用できません。
Database
ホスト上のデータベースの名前。たとえば、my-instance.us-east-1.redshift.amazonaws.com というホスト名があり、その中に sales_info という名前のデータベースがあるとします。このフィールドに「sales_info」と入力します。同じホスト上に複数のデータベースがある場合、それらを使用するために複数の接続の作成が必要になる場合があります(ただし、MySQL ではほとんどのデータベース言語とは少し異なる意味になります)。
Use OAuth
Snowflake 接続と Google BigQuery 接続では、OAuth を使用できます。この場合、ユーザーがLookerからクエリを発行するにはSnowflakeまたはGoogleへのログインがそれぞれ必要です。
[OAuth を使用する] を選択すると、[OAuth クライアント ID] と [OAuth クライアント シークレット] が表示されます。
これらの値は、Snowflake データベースまたは Google から生成されます。詳細な手順については、Snowflake OAuth 構成または Google BigQuery OAuth 構成に関するドキュメント ページをご覧ください。
ユーザー名
Looker がデータベースに接続するために使用するユーザー名。Google のデータベース設定手順に沿って、事前にユーザーを設定してください。
パスワード
Looker がデータベースに接続するために使用するパスワード。Google のデータベース設定手順に沿って、前もってパスワードを設定する必要があります。
スキーマ
スキーマが指定されていない場合に Looker が使用するデフォルトのスキーマ。これは、SQL Runner の使用時、LookML プロジェクトの生成時、テーブルのクエリ時に適用されます。
Persistent Derived Tables
永続的な派生テーブルを有効にするには、このチェックボックスをオンにします。追加の PDT フィールドと [PDT Override] 列が表示されます。Looker では、データベース言語が PDT の使用をサポートしている場合にのみ、このオプションが表示されます。
PDTについて、次の点に注意してください。
- PDT は、OAuth を使用する Snowflake 接続ではサポートされていません。
- 接続で PDT を無効にしても、PDT に関連付けられているデータグループが無効になることはありません。PDT を無効にしても、既存のデータグループは引き続きデータベースに対して
sql_triggerクエリを実行します。データグループでのデータベースに対するsql_triggerクエリの実行を停止するには、LookML プロジェクトからdatagroupパラメータを削除またはコメントアウトするか、Looker が PDT とデータグループを頻繁に確認しないように、接続の PDT とデータグループのメンテナンス スケジュールの設定を更新します。 - Snowflake 接続の場合、Looker は
AUTOCOMMITパラメータの値をTRUE(Snowflake のデフォルト値)に設定します。Looker が PDT 登録システムを維持するために実行する SQL コマンドには、AUTOCOMMITが必要です。
Temp Database
これは「Temp Database」というラベルが付いていますが、SQL 言語に応じて、データベース名またはスキーマ名のいずれかを入力し、Looker が永続的な派生テーブルの作成に使用します。このデータベースまたはスキーマは、適切な書き込み権限を事前に構成しておく必要があります。データベース構成手順のドキュメント ページで、データベース言語を選択して、その言語の手順を確認します。
接続ごとに独自の一時データベースまたはスキーマが必要です。接続間で共有することはできません。
PDTビルダーの最大接続数
[Max PDT Builder Connections] 設定では、Looker リジェネレータがデータベース接続で開始できる同時テーブルビルドの数を指定できます。[Max PDT Builder Connections] 設定は、Looker リジェネレータが再ビルドを開始するテーブルの種類にのみ適用されます。
- トリガー永続テーブル(永続派生テーブルと永続性戦略
datagroup_triggerまたはsql_trigger_valueを使用する集約テーブル) persist_for戦略を使用する永続テーブル。ただし、persist_forテーブルが 派生テーブルのカスケードに含まれている場合で、datagroup_triggerまたはsql_trigger_value永続戦略を使用するテーブルに依存している場合に限ります。この場合、Looker リジェネレータによってpersist_forテーブルが再ビルドされます。これは、カスケード内の別のテーブルを再ビルドするためにテーブルが必要なためです。それ以外の場合、リジェネレータはpersist_forテーブルのビルドを開始しません。
[Max PDT Builder Connections] の設定は、デフォルトで [1] に設定されていますが、[10] に設定することもできます。ただし、[最大接続数] フィールドまたは Looker の起動オプションに設定されている per-user-query-limit よりも大きい値に設定することはできません。
この値を慎重に設定します。値が高すぎると、データベースに過剰な負荷がかかる可能性があります。値が低いと、長時間実行される PDT や集約テーブルによって、他の永続テーブルの作成が遅れたり、接続に対する他のクエリが遅くなったりする場合があります。マルチテナンシーをサポートするデータベース(BigQuery、Snowflake、Redshift など)は、並列クエリビルドの処理においてパフォーマンスが向上する場合があります。
[Max PDT Builder Connections] の設定を増加したい場合は、1 単位で増やすことをおすすめします。予期しない動作が発生した場合は、デフォルトの 1 に戻します。それ以外の場合は、クエリのパフォーマンスに影響が及ばない場合は、クエリを 1 つずつ段階的に上げていき、増分ごとにパフォーマンスを検証してから、設定をさらに増やすことができます。
[Max PDT Builder Connections] 設定について、次の点に注意してください。
- [Max PDT Builder Connections] 設定は、テーブルの再ビルドに必要な接続にのみ適用されます。トリガー チェックに必要な接続には適用されません。トリガー チェックとは、テーブルの永続化戦略がトリガーされるかどうかをチェックするクエリです。これらのトリガー チェック クエリは常に順番に実行されるため、[最大 PDT ビルダーの接続] 設定は適用されません。
- クラスタ化された Looker インスタンスでは、リジェネレータはメインノードでのみ実行されます。[Max PDT Builder Connections] 設定はメインノードにのみ適用されるため、クラスタ全体に対して制限が設定されます。
- [Max PDT Builder Connections] 設定は、次の種類のテーブルには適用されません。次の種類のテーブルは連続してビルドされます。
persist_forパラメータによって永続化されたテーブル(datagroup_trigger戦略またはsql_trigger_value戦略を使用するテーブルに依存していない場合)。- 開発モードのテーブル。
- [Rebuild Derived Tables & Run] オプションを使用して再構築されたテーブル。
- 依存関係がカスケードで依存するテーブル。テーブルは、依存するテーブルと同時にビルドすることはできません。たとえば、
table_Bがtable_Aに依存している場合、table_Aは、table_Bが再ビルドを開始する前に再構築を完了する必要があります。
PDTビルドが失敗したら必ず再試行する
[Always Retry Failed PDT Builds] 設定では、前の Looker 生成サイクルで失敗したトリガー永続テーブルの Looker リジェネレータの再構築方法を構成します。Looker の再生ツールは、PDT とデータグループのメンテナンス スケジュールの接続構成で構成された間隔に従って、トリガー永続テーブル(PDT と集約テーブル)を再作成するプロセスです。[Always Failed PDT Builds] 設定が有効になっている場合、Looker の再生成ツールは、PDT のトリガー条件が満たされていない場合でも、前回の再生成サイクルで失敗した PDT の再構築を試行します。この設定を無効にすると、Looker の再生成ツールは PDT のトリガー条件が満たされた場合にのみ、以前失敗した PDT の再構築を試みます。デフォルトでは、[常に失敗した PDT ビルドを再試行する] は無効になっています。
Looker の再生ツールの詳細については、Looker の派生テーブルをご覧ください。
PDT APIコントロールの有効化
[PDT API コントロールを有効にする] 設定は、この接続に start_pdt_build、check_pdt_build、stop_pdt_build API 呼び出しを使用できるかどうかを決定します。この設定を無効にすると、この接続で PDT を参照するとこれらの API 呼び出しが失敗します。[PDT API コントロールを有効にする] はデフォルトで無効になっています。
Additional Params
必要に応じて、ここでクエリにJava Database Connectivity(JDBC)パラメーターをさらに指定することができます。
JDBC パラメータでユーザー属性を参照するには、Liquid テンプレート テンプレートの構文(_user_attributes['name_of_attribute'])を使用します。例:
my_jdbc_param={{ _user_attributes['name_of_attribute'] }}
Looker の [Additional Params] フィールドに次のように表示されます。

追加のJDBCパラメーターは、Lookerではテストされておらず、意図しない動作を引き起こす可能性があります。
PDTとデータグループのメンテナンススケジュール
この設定では、Looker リジェネレータが sql_trigger_value に基づくデータグループと永続テーブル(集計テーブルと永続的な派生テーブル)をチェックし、再生成または削除するテーブルを示す cron 式を使用できます。
デフォルト値の */5 * * * * は、「5 分ごとにチェックする」という意味で、これはチェックの最大頻度です。cron 式は、より頻繁なチェックを示すため、5 分ごとにチェックが行われます。
PDT のビルド中は、Looker は追加のトリガー チェックを実行しません。最後のトリガーチェック以降のすべてのPDTがビルドされると、Lookerはデータグループのチェック、およびPDTとデータグループメンテナンススケジュールに基づくPDTトリガーを再開します。
データベースが 24 時間 365 日稼働していない場合、チェックはデータベースが稼働している時間までに制限することをおすすめします。以下に、その他の cron 式を示します。
cron 式 |
定義 |
|---|---|
*/5 8-17 * * MON-FRI |
データグループとPDTを、月曜から金曜の営業時間に5分ごとにチェック |
*/5 8-17 * * * |
データグループとPDTを、毎日、営業時間に5分ごとにチェック |
0 8-17 * * MON-FRI |
データグループとPDTを、月曜から金曜の営業時間に1時間ごとにチェック |
1 3 * * * |
データグループとPDTを、毎日午前3時01分にチェック |
cron 式を作成するときには、次の点に注意してください。
- Looker では parse-cron v0.1.3 を使用しますが、これは
cron式の?をサポートしていません。 cron式は、Looker アプリケーションのタイムゾーンを使用してチェックのタイミングを決定します。- PDT がビルドされない場合は、cron 文字列をデフォルトの
*/5 * * * *にリセットします。
cron 文字列の作成に役立つリソースを以下に示します。
- https://crontab.guru -
cron文字列の編集とテストに役立ちます。 - http://www.crontab-generator.org - 時間設定を選択すると、対応する
cron文字列が作成されます。
SSL
Looker とデータベース間でやり取りされるデータを SSL 暗号化で保護するかどうかを選択します。SSL はデータの保護に使用できるオプションの 1 つにすぎません。その他の安全なオプションについては、安全なデータベース アクセスを有効にするをご覧ください。
Verify SSL Cert
接続で使用する SSL 証明書の検証を要求するかどうかを選択します。検証が必要な場合は、SSL 証明書に署名した SSL 認証局(CA)が、クライアントの信頼できるソースのリストに含まれている必要があります。CAが信頼できるソースではない場合、データベース接続は確立されません。
このチェックボックスがオフの場合でも、接続で SSL 暗号化が使用されますが、SSL 接続の確認は不要なため、CA がクライアントの信頼できるソースのリストに含まれていない場合にも接続を確立できます。
最大接続数
ここでは、Looker がデータベースに対して確立できる接続の最大数を設定できます。たいていの場合、Looker がデータベースに対して実行できる同時クエリの数を設定します。また、Looker はクエリの強制終了用に最大 3 つの接続を予約します。接続プールが非常に小さい場合は、予約される接続数も少なくなります。
この値を慎重に設定します。値が高すぎると、データベースに過剰な負荷がかかる可能性があります。値が小さすぎる場合、クエリは少数の接続を共有する必要があります。クエリは、前のクエリが返されるのを待たなければならないため、ユーザーには遅く感じることがあります。
デフォルト値(SQL 言語によって異なります)は通常、妥当な出発点です。ほとんどのデータベースは、受け入れる接続の最大数を独自に設定しています。データベースの構成で接続が制限されている場合は、最大接続数がデータベースの上限以下であることを確認してください。
Connection Pool Timeout(接続プールタイムアウト)
ユーザーが [最大接続数] 設定より多くの接続をリクエストした場合、そのリクエストは他の実行が終了するまで待ってから実行されます。リクエストが待機する最長時間はここで構成されます。この値は慎重に設定する必要があります。クエリが少なすぎると、他のユーザーのクエリが完了するまでの時間が不十分なため、クエリがキャンセルされることがあります。多すぎると、クエリが大量に発生し、ユーザーが非常に長い時間待つ可能性があります。一般に、まずデフォルト値を使用することをお勧めします。
コスト見積もり
[費用の見積もり] チェックボックスは、次のデータベース接続にのみ適用されます。
- Snowflake
- Amazon Redshift
- Amazon Aurora
- PostgreSQL、Cloud SQL for PostgreSQL、Microsoft Azure PostgreSQL
[Cost Estimate] チェックボックスをオンにすると、接続で次の機能が有効になります。
BigQuery と MySQL の接続では、費用の見積もり機能もサポートされています。ただし、この機能は常に有効になっているため、BigQuery と MySQL の接続に対する [費用の見積もり] チェックボックスはありません。
詳細については、Looker でのデータ探索に関するドキュメント ページをご覧ください。
SQL Runner Precache
SQL Runner では、接続とスキーマを選択するとすぐに、すべてのテーブル情報がプリロードされます。これにより、SQL Runner では、テーブル名をクリックするとすぐにテーブル列を表示できます。ただし、多くのテーブルや大規模なテーブルが関係する接続とスキーマの場合は、SQL Runnerですべての情報を事前にロードしないようにすることをお勧めします。
テーブルが選択された場合にのみ SQL Runner がテーブル情報を読み込むようにするには、[SQL Runner Precache] オプションの選択を解除して、接続に対する SQL Runner のプリロードを無効にします。
SQL書き込み用のフェッチ情報スキーマ
集約テーブルの自動認識などの一部の SQL 書き込み機能については、Looker はデータベースの情報スキーマを使用して SQL 書き込みを最適化します。情報スキーマがキャッシュされていない場合、Looker は、情報スキーマを取得するために、データベースへの SQL の書き込みをブロックすることがあります。Hadoop 分散ファイル システム(HDFS)を使用する言語の場合、情報スキーマの取得に Looker クエリのパフォーマンスに大きな影響を与えるまでに十分な時間がかかることがあります。情報スキーマが遅いことがわかっている場合は、接続の [Fetch Information Schema For SQL Write] オプションを無効にできます。この機能を無効にすると、特定の機能に対する Looker の SQL 最適化ができなくなります。そのため、接続の情報スキーマが特に遅いことがわかっている場合を除き、[Fetch Information Schema For SQL Write] オプションを有効にする必要があります。
コンテキストコメントの無効化
[コンテキスト コメントを無効にする] オプションは、BigQuery の接続にのみ適用されます。Google BigQuery 接続のコンテキスト コメントは、デフォルトで無効になっています。これは、Google BigQuery のキャッシュ機能が無効になり、キャッシュのパフォーマンスに悪影響が及ぶ可能性があるためです。BigQuery 接続のコンテキスト コメントを有効にするには、接続の [接続設定] ページで [コンテキスト コメントを無効にする] 設定の選択を解除します。詳細については、Google BigQuery のドキュメント ページをご覧ください。
データベースのタイムゾーン
データベースが時間ベースの情報を保存するタイムゾーン。Looker はこれを使用してユーザーの時間値を変換し、時間ベースのデータを簡単に理解して使用できるようにする必要があります。詳しくは、タイムゾーンの設定の使用に関するドキュメントをご覧ください。
クエリのタイムゾーン
[クエリのタイムゾーン] オプションは、ユーザー固有のタイムゾーンを無効にしている場合にのみ表示されます。
ユーザー固有のタイムゾーンが無効になっている場合、クエリのタイムゾーンは、ユーザーが時間ベースのデータをクエリするときに表示されるタイムゾーンと、Looker がデータベースのタイムゾーンから時間ベースのデータを変換するタイムゾーンです。
詳しくは、タイムゾーンの設定の使用に関するドキュメントをご覧ください。
PDTプロセスに個別のログイン資格情報を設定する
データベースが永続的な派生テーブルをサポートしていて、接続設定の [永続的な派生テーブル] チェックボックスをオンにすると、Looker で [PDT のオーバーライド] 列が表示されます。[PDT Overrides] 列には、PDT プロセスに固有の個別の JDBC パラメータ(ホスト、ポート、データベース、ユーザー名、パスワード、スキーマ、追加パラメータ)を入力できます。これは次のような理由で非常に重要です。
- PDT プロセス用に別のデータベース ユーザーを作成することで、データベースのログイン認証情報にユーザー属性を割り当てた場合でも、モデルで PDT を使用できます。
- PDT プロセスは、優先度の高い別のデータベース ユーザーを介して認証できます。このようにして、データベースは重要度の低いユーザーのクエリよりも、PDTジョブを優先することができます。
- 書き込みアクセス権は、標準の Looker データベース接続では取り消すことができ、PDT プロセスが認証のために使用する特別なユーザーにのみ付与されます。ほとんどの組織で、これはより安全なセキュリティ戦略です。
- Snowflake などのデータベースでは、他の Looker ユーザーとは共有されない、さらに強力なハードウェアに PDT プロセスをルーティングできます。こうして、高コストなハードウェアをフルタイムで実行するコストを回避し、PDTをすばやく構築できます。
たとえば、次の構成は、ユーザー名とパスワードのフィールドがユーザー属性に設定されている接続を示しています。これにより、各ユーザーは個別の認証情報を使用してデータベースにアクセスできます。[PDT オーバーライド] 列で、独自のパスワードを持つ別個のユーザー(pdt_user)が作成されます。pdt_user アカウントはすべての PDT プロセスに使用され、PDT の作成と更新に適したアクセスレベルが設定されます。
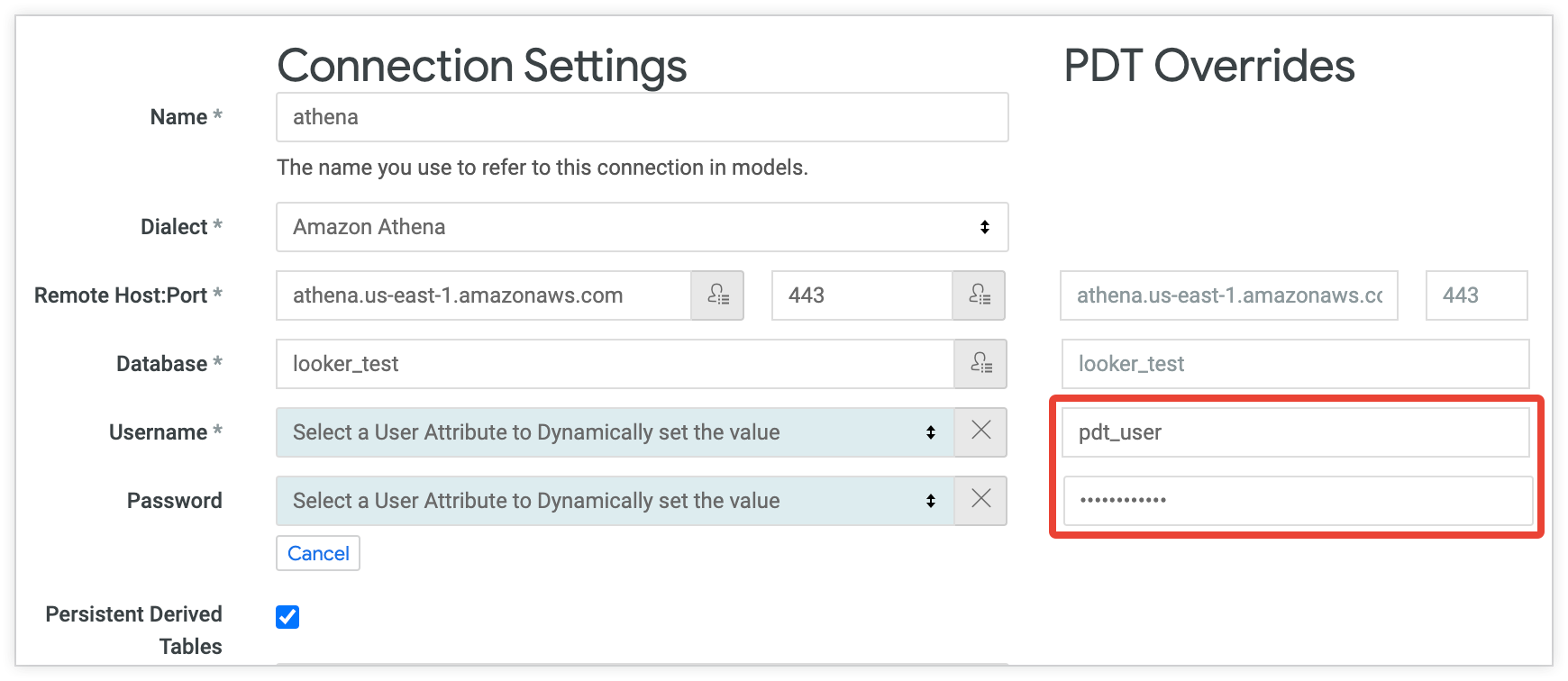
[PDT オーバーライド] 列ではデータベース ユーザーやその他の接続プロパティを変更できますが、PDT オーバーライドではデフォルト接続と同じデータを読み取り、同じ場所にデータを書き込む必要があります。Lookerは、データを読み取った場所と違う場所に書き込むことができません。
接続設定のテスト
認証情報を入力したら、[これらの設定をテスト] をクリックして、情報が正しいことと、データベースが接続可能であることを確認します。
接続が1つ以上のテストに合格しない場合は、次の情報を確認してください。
- データベース接続のテストに関するドキュメント ページで、トラブルシューティングの手順を試す。
- Versa 3 で Mongo バージョン 3.6 以前を実行していて、通信リンクに障害が発生した場合は、Mongo Connector のドキュメントをご覧ください。
- 一時スキーマと PDT に関する正常な接続メッセージを受信するには、Looker データベースの設定時にその機能を許可する必要があります。手順については、データベースの構成手順のドキュメントをご覧ください。
Snowflake や Google BigQuery など、OAuth を使用するデータベース接続にはユーザー ログインが必要です。いずれかの接続をテストする際に OAuth ユーザー アカウントにログインしていない場合は、ログインリンクとともに警告が表示されます。このリンクをクリックして、OAuth資格情報を入力するか、またはLookerによるOAuthアカウント情報へのアクセスを許可します。
それでも障害が続く場合は、Lookerサポートに連絡してください。
ユーザーとしてテスト
ユーザー属性値への接続値を 1 つ以上設定した場合は、[これらの設定をテスト] ボタンの上に [ユーザーとしてテスト] オプションが表示されます。ユーザーを選択して [Test Settings Settings] をクリックし、データベースがこのユーザーとして接続してクエリを実行できることを確認します。
データベース接続の追加
データベース接続の設定とテストが完了したら、[接続の追加] をクリックします。これで、データベース接続が [Connections] ページのリストに追加されます。
次のステップ
データベースを Looker に接続したら、ユーザーのログイン オプションを構成します。