このドキュメントでは、Spanner でマルチテナンシーを実装するさまざまな方法について説明しています。また、データ マネジメント パターンとテナント ライフサイクル管理についても説明します。このドキュメントは、マルチテナント アプリケーションをリレーショナル データベースとして Spanner に実装するデータベース アーキテクト、データ アーキテクト、エンジニアを対象としています。このコンテキストを使用して、マルチテナント データを保存するさまざまな方法を説明します。マルチテナント アプリケーションにアクセスするエンティティを示すため、記事を通して「テナント」、「顧客」、「組織」という用語を一貫して使用します。このページの例は、人事(HR)SaaS プロバイダが Google Cloudにマルチテナント アプリケーションを実装したものです。1 つの要件は、HR SaaS プロバイダの複数の顧客がマルチテナント アプリケーションにアクセスする必要があることです。このような顧客はテナントと呼ばれます。
マルチテナンシー
マルチテナンシーは、ソフトウェア アプリケーションの単一のインスタンス(またはいくつかのインスタンス)で複数のテナントまたはお客様にサービスを提供する場合に使用します。このソフトウェア パターンは、単一のテナントまたは顧客から、数百または数千にまでスケーリングできます。このアプローチはクラウド コンピューティング プラットフォームにとって重要で、基盤となるインフラストラクチャは複数の組織で共有されます。
マルチテナンシーは、データベースなどの共有コンピューティング リソースによるパーティショニングの 1 つの手法であると考えられます。アパートの住人に例えると、住人は水道管や電線などのインフラストラクチャを共有しますが、各住人はアパート内の専用のテナント スペースを持ちます。マルチテナンシーは、Software-as-a-Service(SaaS)アプリケーションの一部です。
Spanner は、リレーショナル データベース モデルのメリットと非リレーショナルの水平方向のスケーラビリティを備えた、 Google Cloudの整合性のあるエンタープライズ クラスの分散型フルマネージド データベースです。Spanner では、スキーマとのリレーショナル セマンティクス、データ型の強制適用、強整合性、複数ステートメントの ACID トランザクション、ANSI 2011 SQL を実装する SQL クエリ言語を使用できます。 99.999% の可用性 SLA により、計画的なメンテナンスやリージョンの障害が発生した場合にゼロ ダウンタイムを実現します。 また、高可用性とスケーラビリティにより、最新のマルチテナント アプリケーションもサポートします。
テナントデータ マッピング基準
マルチテナント アプリケーションでは、各テナントのデータが基盤となる Spanner データベースの複数のアーキテクチャ アプローチで分離されます。テナントのデータを Spanner にマッピングするために使用されるさまざまなアーキテクチャ アプローチの概要を次に示します。
- インスタンス: テナントは 1 つの Spanner インスタンスにのみ存在します。そのテナント用のデータベースは 1 つのみです。
- データベース: テナントは、複数のデータベースを含む 1 つの Spanner インスタンスのデータベースに存在します。
- テーブル: テナントはデータベース内の排他的なテーブルに存在し、複数のテナントを同じデータベースに配置できます。
- 行: テナントデータは、データベース テーブルの行です。これらのテーブルは他のテナントと共有されます。
上記の基準はデータ マネジメント パターンと呼ばれています。詳細はマルチテナンシーのデータ マネジメント パターンセクションをご覧ください。上記の説明は次の基準に基づいています。
- データの分離: 複数のテナント間でのデータ分離の度合いは、マルチテナンシーの重要な考慮事項です。たとえば、データを物理的に分離する必要があるかどうか、テナントのデータごとに設定できる独立した ACL(アクセス制御リスト)があるかどうかなどです。分離は、他のカテゴリの条件に対する選択項目によって決まります。たとえば、特定の規制やコンプライアンスの要件が分離の度合いに影響する場合があります。
- アジリティ: インスタンス、データベース、テーブル、または行の作成に関する、テナントのオンボーディングとオフボーディング作業の容易性を示します。
- 運用: 一般的なテナント固有のデータベース オペレーションと管理作業(定期的なメンテナンス、ロギング、バックアップ、障害復旧など)の実装の可用性または複雑性を示します。
- スケーリング: 将来の成長に対応できるシームレスな拡張性を示します。各パターンの説明には、そのパターンでサポートできるテナント数が示されています。
- パフォーマンス:
- リソース分離: 各テナントへの排他的なリソースの割り当て、ノイジー ネイバー現象への対処、各テナントに対する予測可能な読み取りおよび書き込みパフォーマンスを行う機能。
- テナントあたりの最小リソース: テナントあたりの平均最小リソース量。これは、個々のテナントごとにこの金額以上を支払う必要があるという意味ではありません。すべてのテナント(N 個)に対して、少なくとも N 倍の金額を支払う必要があります。
- リソースの効率性: 他のテナントのアイドル状態のリソースを使用して、全体的な費用を節約できます。
- レイテンシの最適化のためのロケーションの選択: 各テナントに対して特定のレプリケーション トポロジを選択できるため、各テナントのデータは、テナントにとって最適なレイテンシを提供するロケーションに配置できます。
- 規制とコンプライアンス: リソースやメンテナンス オペレーションの完全な分離が必要となる、規制の厳しい業界や国の要件に対応する機能。たとえば、フランスの場合、データ保持要件として、個人識別情報はフランス国内にのみ物理的に保存される必要があります。金融業界では通常、顧客管理の暗号鍵(CMEK)が必要です。各テナントは独自の暗号鍵を使用する場合があります。
これらの基準に関連する各データ マネジメント パターンについては、次のセクションで詳しく説明します。特定の一連のテナントに対してデータ マネジメント パターンを選択する場合は、同じ基準を使用します。
マルチテナンシーのデータ マネジメント パターン
以降のセクションでは、インスタンス、データベース、テーブル、行の 4 つの主要なデータ マネジメント パターンについて説明します。
インスタンス
完全な分離を実現するため、インスタンスのデータ マネジメント パターンでは、各テナントのデータを固有の Spanner インスタンスとデータベースに保存します。Spanner インスタンスには、1 つ以上のデータベースを含めることができます。このパターンでは、作成されるデータベースは 1 つのみです。前述の HR アプリケーションでは、顧客の組織ごとに異なる 1 つのデータベースを含む個別の Spanner インスタンスが作成されます。
次の図でわかるように、データ マネジメント パターンではインスタンスごとに 1 つのテナントが対応しています。
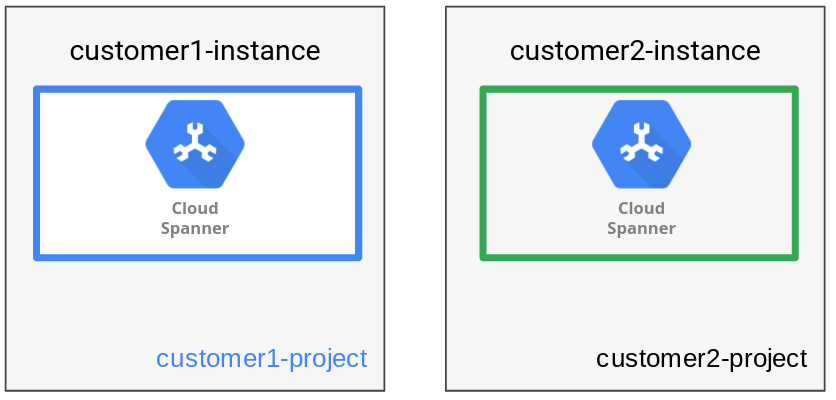
テナントごとに個別のインスタンスを用意するため、別々のGoogle Cloud プロジェクトを使用してテナントごとに異なる信頼境界を確立できます。また、各テナントのロケーション(リージョンまたはマルチリージョン)、ロケーションの柔軟性の最適化、パフォーマンスに基づいてインスタンス構成が選択できるというメリットがあります。
このアーキテクチャは、任意の数のテナントにスケーリングできます。SaaS プロバイダは、所定のリージョン内に任意の数のインスタンスを作成し、ハードリミットを設定できます。
次の表に、インスタンスのデータ マネジメント パターンがさまざまな基準にどのように影響するかを示します。
| 条件 | インスタンス - インスタンスのデータ マネジメント パターンごとに 1 つのテナント |
|---|---|
| データの分離 |
|
| アジリティ |
|
| オペレーション |
|
| 規模 |
|
| パフォーマンス |
|
| 規制要件とコンプライアンス要件 |
|
要約すると、重要なポイントは次のとおりです。
- アドバンテージ: 最高レベルの分離ができる
- デメリット: 運用上のオーバーヘッドが最も大きく、テナントあたり 100 PU の最小要件によりコストが高くなる可能性があります。テナント間でのリソースの共有はサポートされていません。
インスタンスのデータ マネジメント パターンは、次のシナリオに最適です。
- 異なるテナントが幅広いリージョンに分散しており、ローカライズされたソリューションが必要です。
- 一部のテナントでは、規制やコンプライアンス要件により、非常に高度なセキュリティ プロトコルと監査プロトコルが求められます。
- テナントのサイズは大きく異なります。大容量でトラフィックの多いテナント間でリソースを共有すると、競合や相互の機能低下が発生する可能性があります。
データベース
データベースのデータ マネジメント パターンでは、各テナントは 1 つの Spanner インスタンスのデータベースの中に存在します。1 つのインスタンスに対して複数のデータベースを作成できます。テナント数に対してインスタンスが 1 つでは不十分な場合、複数のインスタンスを作成します。このパターンは、1 つの Spanner インスタンスが複数のテナントにより共有されることを意味します。
Spanner には、インスタンスあたり 100 データベースというハードリミットがあります。この上限により、SaaS プロバイダが 100 人を超えるユーザーにスケーリングする場合、プロバイダは複数の Spanner インスタンスを作成して使用する必要があります。
HR アプリケーションの場合、SaaS プロバイダは各テナントの作成および管理を、Spanner インスタンスの個別のデータベースで行います。
次の図に示すように、データ マネジメント パターンではデータベースごとに 1 つのテナントがあります。
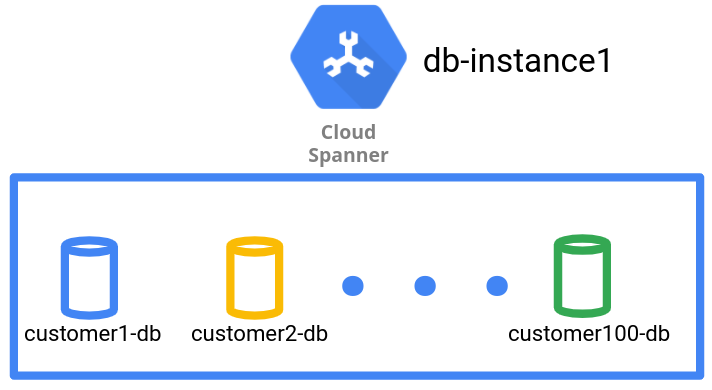
データベースのデータ マネジメント パターンでは、異なるテナントデータでデータベース レベルでの論理分離を実現します。ただし、これは単一の Spanner インスタンスであるため、地域別パーティション分割機能が使用されていない限り、すべてのテナント データベースが同じレプリケーション トポロジと、同一の基盤となるコンピューティングとストレージの設定を共有します。Spanner の地域別パーティション分割機能を使用すると、異なるロケーションにインスタンス パーティションを作成し、同じインスタンス内の異なるデータベースに異なるインスタンス パーティションを使用できます。
次の表で、データベースのデータ マネジメント パターンがさまざまな基準にどのように影響するかを示します。
| 条件 | データベース - データベースのデータ マネジメント パターンごとに 1 つのテナント |
|---|---|
| データの分離 |
|
| アジリティ |
|
| オペレーション |
|
| 規模 |
|
| パフォーマンス |
|
| 規制要件とコンプライアンス要件 |
|
要約すると、重要なポイントは次のとおりです。
- 利点: 中程度のデータ分離とリソース分離、中程度のリソース効率性。各テナントは独自のバックアップと CMEK を設定できます。
- デメリット: インスタンスあたりのテナント数に限りがある、地域別パーティション分割機能を使用しない限り、ロケーションの柔軟性に欠ける。
データベースのデータ マネジメント パターンは、次のシナリオに最適です。
- 複数のお客様が同一のデータ所在地内に所在しているか、同じ規制機関に属している場合。
- テナントは、システムベースのデータ分離とデータのバックアップと復元の機能を必要としますが、インフラストラクチャのリソース共有に適しています。
- テナントには独自の CMEK が必要です。
- 費用は重要な考慮事項です。テナントごとに必要な最小リソースは、インスタンスの費用よりも少なくなります。テナントは、他のテナントのアイドル状態のリソースを使用することをおすすめします。
テーブル
テーブルのデータ マネジメント パターンでは、単一のスキーマを実装する単一のデータベースが複数のテナントに使用され、各テナントのデータに別々のテーブルが使用されます。これらのテーブルを区別するには、テーブル名に tenant ID を接頭辞、接尾辞、または名前付きスキーマとして含めます。
テナントごとに個別のテーブルを使用するデータ マネジメント パターンは、前述のオプション(インスタンスとデータベース管理パターン)と比較してはるかに低い分離レベルになります。オンボーディングでは、新しいテーブルおよび関連する参照完全性とインデックスの作成が関係してきます。
データベースあたりのテーブル数には 5,000 という上限があります。一部のお客様は、この制限によってアプリケーションの利用が制限される可能性があります。
さらに、顧客ごとに個別のテーブルを使用すると、スキーマ更新オペレーションのバックログが大きくなる可能性があります。このようなバックログは解決に時間がかかります。
HR アプリケーションの場合、SaaS プロバイダは顧客ごとに一連のテーブルを作成します。その際、テーブル名の接頭辞として tenant ID を使用します。たとえば customer1_employee、customer1_payroll、customer1_department のように指定します。または、テナント ID を名前付きスキーマとして使用し、テーブルに customer1.employee、customer1.payroll、customer1.department という名前を付けることもできます。
次の図に示すように、テーブルのデータ マネジメント パターンには、テナントごとに一連のテーブルが 1 つあります。
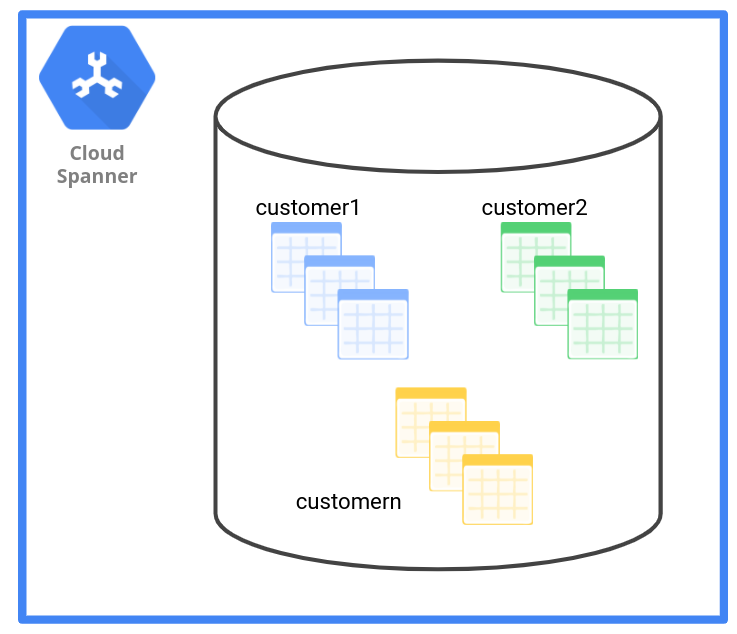
次の表で、テーブルのデータ マネジメント パターンがさまざまな基準にどのように影響するかを示します。
| 条件 | テーブル - テナントのデータ マネジメント パターンごとに一連のテーブルが 1 つ |
|---|---|
| データの分離 |
|
| アジリティ |
|
| オペレーション |
|
| 規模 |
|
| パフォーマンス |
|
| 規制要件とコンプライアンス要件 |
|
要約すると、重要なポイントは次のとおりです。
- 利点: 中程度の拡張性とリソース効率。
- デメリット:
- 中程度のデータ分離とリソース分離。
- 新しい地域別パーティション分割機能を使用しない限り、ロケーションの柔軟性に欠ける。
- テナントを個別にモニタリングできない。テーブルレベルで利用可能なリソース使用量情報は、テーブルサイズの統計情報のみです。
- テナントは独自の CMEK とバックアップを設定できません。
テーブルのデータ マネジメント パターンは、次のシナリオに最適です。
- データの分離が法的には義務付けられていないものの、論理的な分離とセキュリティ制御が必要なマルチテナント アプリケーション。
- 費用は重要な考慮事項です。テナントあたりの最小費用は、データベースあたりの費用よりも低くなります。
行
最終的なデータ マネジメント パターンでは、共通のテナントセットを持つ複数のテナントにサービスを提供します。各行は特定のテナントに属します。データ マネジメント パターンはマルチテナントの究極の姿であり、インフラストラクチャからスキーマ、データモデルまで、すべてが複数のテナント間で共有されます。テーブル内では、主キーに基づいて行が分割され、tenant ID がキーの最初の要素となります。スケーリングの観点から Spanner はこのパターンを最大限にサポートしています。これは、テーブルを無限にスケーリングできるためです。
HR アプリケーションの場合、給与支払テーブルの主キーは customerID と payrollID の組み合わせになります。
次の図に示すように、行のデータ マネジメント パターンには複数のテナント用にテーブルが 1 つあります。

他のすべてのパターンとは異なり、行パターンのデータアクセスをテナントごとに個別に制御することはできません。各テナントが固有のデータベース テーブルを持っている場合、テーブル数を減らすことでスキーマ更新オペレーションを高速化できます。この方法により、オンボーディング、オフボーディング、オペレーションが簡素化されます。
次の表で、行のデータ マネジメント パターンがさまざまな基準にどのように影響するかを示します。
| 条件 | 行 - テナントのデータ マネジメント パターンごとに一連の行が 1 つ |
|---|---|
| データの分離 |
|
| アジリティ |
|
| オペレーション |
|
| 規模 |
|
| パフォーマンス |
|
| 規制要件とコンプライアンス要件 |
|
要約すると、重要なポイントは次のとおりです。
- メリット: 優れた拡張性、運用上のオーバーヘッドが少ない、スキーマ管理が簡素化されます。
- デメリット: リソースの競合が多い、各テナントのセキュリティ制御とモニタリングの欠如。
このパターンは、次のようなシナリオに最適です。
- メンテナンスの容易さに比べて、厳格なデータ セキュリティ分離が問題にならないさまざまな部門に対応する内部アプリケーション。
- リソースのプロビジョニングの最小化を同時に行う場合の、無料枠のアプリケーションを使用するテナント向けの最大リソース共有。
データ マネジメント パターンとテナント ライフサイクル管理
次の表は、すべての高いレベルの基準を満たすさまざまなデータ マネジメント パターンの概要を示しています。
| インスタンス | データベース | テーブル | 行 | |
|---|---|---|---|---|
| データの分離 | 完了 | 高 | 中 | 低 |
| アジリティ | 低 | 中 | 中 | 最高 |
| 運用のしやすさ | 高 | 高 | 低 | 低 |
| 規模 | 高 | 制限あり(上限に達した場合に追加のインスタンスが使用されない限り) | 制限あり(上限に達した場合に追加のデータベースを使用しない限り) | 最高 |
| パフォーマンス1 - リソースの分離 | 高 | 低 | 低 | 低 |
| パフォーマンス1 - テナントあたりの最小リソース | 高 | 中程度に高い | 中 | テナントあたりの最小数なし |
| パフォーマンス1 - リソースの効率性 | 低 | 高 | 高 | 高 |
| パフォーマンス1 - レイテンシの最適化のためのロケーションの選択 | 高 | 中 | 中 | 中 |
| 規制とコンプライアンス | 最高 | 高 | 中 | 低 |
1 パフォーマンスはスキーマ設計とクエリのベスト プラクティスに大きく依存します。この値は、あくまでも平均的な期待値です。
特定のマルチテナント アプリケーションに対する最適なデータ マネジメント パターンは、基準に基づいてほとんどの要件を満たしているものです。不要な特定の基準がある場合はその行を無視できます。
統合されたデータ マネジメント パターン
多くの場合、マルチテナント アプリケーションの要件を満たすには単一のデータ マネジメント パターンで十分です。それが当てはまる場合、設計で単一のデータ マネジメント パターンを想定できます。
無料枠、通常の階層、エンタープライズ層をサポートするマルチテナント アプリケーションなど、一部のマルチテナント アプリケーションでは同時に複数のデータ マネジメント パターンが必要になります。
無料枠:
- 費用対効果を高める必要がある
- データ量の上限がある
- 通常は機能が限定される
- 無料枠での選択肢としては行のデータ マネジメント パターンが適切
- テナント管理は簡単
- 特定のテナント リソースまたは排他的なテナント リソースを作成する必要がない
通常の階層:
- 費用を支払っている顧客で、スケーリングや分離に対する強い要件が特にない場合に適している。
- 通常の階層での選択肢としては、テーブルまたはデータベースのデータ マネジメント パターンが適切。
- テーブルとインデックスはテナント専用。
- データベースのデータ マネジメント パターンでのバックアップが容易
- テーブルのデータ マネジメント パターンではバックアップに対するサポートはなし
- テナント バックアップは、Spanner の外部のユーティリティとして実装する必要がある。
エンタープライズ階層:
- 通常、すべての面で完全な自律性を持つ高級階層。
- テナントは、専用のスケーリングや完全分離などの専用リソースを保有。
- インスタンスのデータ マネジメント パターンは、エンタープライズ層に適している。
ベスト プラクティスは、データベースごとに異なるデータ マネジメント パターンを維持することです。Spanner データベース内で異なるデータ マネジメント パターンを組み合わせることは可能ですが、その場合、アプリケーションのアクセス ロジックとライフサイクル オペレーションの実装が困難になります。
アプリケーション設計のセクションで、1 つのデータ マネジメント パターンまたは複数のデータ マネジメント パターンを使用する場合の、マルチテナント アプリケーション設計上の考慮事項について概説します。
テナント ライフサイクルを管理する
テナントにはライフサイクルがあります。したがって、マルチテナント アプリケーションに対応する管理オペレーションを実装する必要があります。テナントの作成、更新、削除の基本的なオペレーションに加えて、次のようなデータ関連のオペレーションも検討してください。
テナントデータのエクスポート:
- テナントを削除する場合は、先にデータをエクスポートし、場合によりテナントがデータセットを使用できるようにすることをおすすめします。
- 行またはテーブルのデータ マネジメント パターンを使用する場合、マルチテナント アプリケーション システムはエクスポートを実装するか、データベース機能(データベースのエクスポート)にマッピングする必要があります。また、テナントに対応するデータの一部を取り出すカスタム ロジックを実装する必要があります。
テナントデータのバックアップ:
- インスタンスまたはデータベースのデータ マネジメント パターンを使用し、個々のテナントのデータのバックアップを行う場合は、データベースのエクスポート関数またはバックアップ関数を使用します。
- テーブルまたは行のデータ マネジメント パターンを使用して個々のテナントデータをバックアップする場合、マルチテナント アプリケーションはこのオペレーションを実装する必要があります。Spanner データベースは、どのデータがどのテナントに属するものか特定できません。
テナントデータの移動:
あるデータ マネジメント パターンからテナントを移行する(またはインスタンスまたはデータベース間で同じデータ マネジメント パターン内でテナントを移動する)には、1 つのデータ マネジメント パターンからデータを抽出し、そのデータを新しいデータ マネジメント パターンに挿入する必要があります。
- アプリケーションのダウンタイムが発生する場合は、エクスポートまたはインポートを行います。
- ダウンタイムを確保できない場合は、ダウンタイム ゼロのデータベース移行を行います。
ノイジーネイバーの状況の軽減が、テナントを移動するもう 1 つの理由です。
アプリケーション設計
マルチテナント アプリケーションを設計する際は、テナント認識型のビジネス ロジックを実装します。つまり、アプリケーションがビジネス ロジックを実行するのは、常に既知のテナントのコンテキスト内に限られることになります。
データベースの観点からみると、アプリケーションの設計とはテナントが存在するデータ マネジメント パターンに対して各クエリを実行する必要があることを意味しています。以下のセクションでは、マルチテナント アプリケーション設計の中心となるいくつかのコンセプトについて説明します。
テナントの動的接続とクエリ構成
テナントデータからテナント アプリケーションのリクエストへの動的マッピングには、マッピング構成が使用されます。
- データベースまたはインスタンスのデータ マネジメント パターンでは、接続文字列でテナントデータにアクセスできます。
- テーブルのデータ マネジメント パターンでは、正しいテーブル名を決定する必要があります。
- 行のデータ マネジメント パターンでは、適切な述語を使用して特定のテナントのデータを取得します。
テナントは、4 つのデータ マネジメント パターンのどれにでも配置できます。次のマッピング実装は、すべてのデータ マネジメント パターンを同時に使用するマルチテナント アプリケーションの一般的な接続構成に対応するものです。あるテナントが 1 つのパターン内に存在する場合、一部のマルチテナント アプリケーションは、すべてのテナントに対して 1 つのデータ マネジメント パターンを使用します。このケースは、次のマッピングで暗黙的にカバーされています。
テナントがビジネス ロジック(従業員がテナント ID を使用してログインする場合など)を実行する場合、アプリケーション ロジックでテナントのデータ管理パターン、特定のテナント ID のデータの場所、およびオプションでテーブルの命名規則(テーブル パターン用)を決定する必要があります。
このアプリケーション ロジックでは、テナントからデータ管理パターンのマッピングを行う必要があります。次のコードサンプルでは、connection string はテナントデータが存在するデータベースを示しています。このサンプルでは、Spanner インスタンスとデータベースを識別します。データ マネジメント パターンがインスタンスとデータベースの場合、次のコードを使用するだけで、アプリケーションは接続してクエリを実行します。
tenant id -> (data management pattern,
database connection string)
テーブルと行のデータ マネジメント パターンには追加の設計が必要です。
テーブルのデータ マネジメント パターン
テーブルのデータ マネジメント パターンの場合、同じデータベース内に複数のテナントがあります。各テナントには固有のテーブルがあります。テーブルは名前で区別されます。どのテーブルがどのテナントのものかを明確にします。
1 つの方法は、各テナントのテーブルをテナントの名前にちなんだ名前空間に配置し、テーブル名を namespace.name で完全修飾することです。たとえば、ID が 356 のテナントの T356 名前空間内に EMPLOYEE テーブルを配置すると、アプリケーションは T356.EMPLOYEE を使用してテーブルへのリクエストに対応できます。
もう 1 つの方法は、テーブル名にテナント ID を付加することです。たとえば、EMPLOYEE テーブルは、ID が 356 のテナントに対して T356_EMPLOYEE といいます。アプリケーションは、マッピングが返されたデータベースにクエリを送信するときに、各テーブルの先頭に tenant
ID という接頭辞を付ける必要があります。
テナント ID の代わりに他のテキストを使用する場合は、テナント ID から名前付きスキーマ名前空間またはテーブル接頭辞へのマッピングを維持できます。
アプリケーション ロジックを簡素化するために、1 レベルの間接化を導入できます。たとえば、アプリケーションで共通ライブラリを使用して、テナントからの呼び出しの名前空間またはテーブル接頭辞を自動的に接続できます。
行データ マネジメント パターン
行のデータ マネジメント パターンにも同様の設計が必要です。このパターンでは、スキーマが 1 つあります。テナントデータは行として保存されます。データへのアクセス権を適切に取得するには、各クエリに述語を追加して、適切なテナントを選択してください。
適切なテナントを見つける方法の 1 つは、各テーブルに TENANT という列を用意することです。データの分離を強化するには、この列の値を主キーの一部にする必要があります。列の値は tenant ID です。各クエリは、既存の WHERE 句に述語 AND TENANT = tenant ID を追加するか、述語 AND TENANT = tenant
ID を含む WHERE 句を追加する必要があります。
データベースに接続して適切なクエリを作成するには、アプリケーション ロジックでテナント ID を使用できる必要があります。パラメータとして渡すことも、スレッド コンテキストとして保存することもできます。
一部のライフサイクル オペレーションでは、テナントからデータ マネジメント パターンへのマッピング構成を変更する必要があります。たとえば、データ マネジメント パターン間でテナントを移動する場合は、データ マネジメント パターンとデータベース接続文字列を更新する必要があります。テーブル接頭辞の更新が必要になることもあります。
クエリの生成とアトリビューション
マルチテナント アプリケーションの基本的な原則は、複数のテナントが単一のクラウド リソースを共有できることです。前述のデータ マネジメント パターンは、単一のテナントが単一の Spanner インスタンスに割り当てられる場合を除き、このカテゴリに分類されます。
リソースの共有は、データの共有に限りません。モニタリングとロギングも共有されます。たとえば、テーブルのデータ マネジメント パターンと行のデータ マネジメント パターンでは、すべてのテナントに対するすべてのクエリが同じ監査ログに記録されます。
クエリがログに記録されると、クエリテキストを調べて、クエリの対象テナントを判別する必要があります。行のデータ マネジメント パターンでは、述語を解析する必要があります。テーブルのデータ マネジメント パターンでは、テーブル名の 1 つを解析する必要があります。
データベースまたはインスタンスのデータ マネジメント パターンでは、クエリテキストにはテナント情報はありません。これらのパターンのテナント情報を取得するには、テナントからデータ管理パターンのマッピング テーブルにクエリを実行する必要があります。
クエリテキストを解析せずに特定のクエリのテナントを決定すると、ログとクエリを簡単に分析できるようになります。すべてのデータ マネジメント パターンにわたってクエリのテナントを均一に識別する方法の一つとして、クエリテキストに tenant ID と(必要に応じて)label を含むコメントを追加する方法があります。
次のクエリは、TENANT 356 で識別されたテナントのすべての従業員データを選択するものです。SQL 構文の解析とプレディケートからのテナント ID の抽出を回避するため、コメントとしてテナント ID が追加されています。コメントにより、SQL 構文を解析することなく抽出が可能になります。
SELECT * FROM EMPLOYEE
-- TENANT 356
WHERE TENANT = 'T356';
または
SELECT * FROM T356_EMPLOYEE;
-- TENANT 356
この設計では、テナントに関して実行するすべてのクエリは、データ マネジメント パターンに関係なくそのテナントに関連付けられます。テナントが 1 つのデータ管理パターンから別のデータ管理パターンに移動された場合、クエリテキストが変更されることがありますが、クエリテキスト内のアトリビューションは同じままです。
上記のコードサンプルはメソッドの 1 つにすぎません。もう 1 つの方法は、ラベルと値の代わりに JSON オブジェクトをコメントとして挿入することです。
SELECT * FROM T356_EMPLOYEE;
-- {"TENANT": 356}
タグを使用してクエリをテナントに関連付け、組み込みの spanner_sys テーブルの統計情報を表示することもできます。
テナント アクセス ライフサイクルのオペレーション
設計の考え方に応じて、マルチテナント アプリケーションは、前述のデータ ライフサイクル オペレーションを直接実装することも、別のテナント管理ツールを作成することもできます。
実装戦略に関係なく、ライフサイクル オペレーションはアプリケーション ロジックを実行していないときに実行する必要があります。たとえば、テナントのデータ マネジメント パターンを別のデータ マネジメント パターンに移行している間は、データが単一のデータベースに存在しないため、アプリケーション ロジックは実行できません。データが単一のデータベース内にない場合、アプリケーションの観点から、次の 2 つの操作が必要になります。
- テナントの停止: アプリケーション ロジックによるすべてのアクセスが無効になります。データ ライフサイクルのオペレーションは可能です。
- テナントの開始:アプリケーション ロジックによるテナントデータへのアクセスが可能です。アプリケーション ロジックに干渉するライフサイクル オペレーションは無効になります。
頻繁には使用されないものの、テナントの緊急シャットダウンが重要なライフサイクル オペレーションとなることがあります。違反が疑われる場合で、アプリケーション ロジックだけでなくライフサイクル オペレーションも含めたテナントのデータに対するすべてのアクセスの禁止が必要な場合は、このシャットダウンを使用します。違反はデータベースの内部または外部で発生する可能性があります。
緊急状態を削除するライフサイクル オペレーションも必要です。このようなオペレーションでは、相互制御を実装するために、複数の管理者による同時ログインを必須とするように設定することも可能です。
アプリケーションの分離
さまざまなデータ マネジメント パターンによって、テナントデータの分離の度合いが異なります。分離レベル(インスタンス)から最小分離レベル(行)まで、さまざまな分離が可能です。
マルチテナント アプリケーションのコンテキストでは、類似したデプロイメント決定を行う必要があります。つまり、すべてのテナントが同じアプリケーション デプロイメントを使用して、(同じデータ管理パターンで)データにアクセスできるかどうか、が大事です。たとえば、1 つの Kubernetes クラスタがすべてのテナントをサポートしている場合、1 つのテナントがデータにアクセスすると同クラスタがビジネス ロジックを実行します。
または、データ マネジメント パターンの場合であれば、アプリケーションのデプロイごとに異なるテナントが転送される場合があります。大規模なテナントはそれ専用のアプリケーション デプロイメントにアクセスできますが、小規模または無料枠のテナントはアプリケーション デプロイメントを共有します。
このドキュメントで説明するデータ マネジメント パターンを同等のアプリケーションのデータ マネジメント パターンと完全に一致させるのではなく、すべてのテナントが単一のアプリケーション デプロイメントを共有できるよう、データベースのデータ マネジメント パターンを使用できます。これらのすべてのテナントは、データベースのデータ マネジメント パターンを持ち、1 つのアプリケーション デプロイメントを共有することが可能です。
マルチテナンシーは、特にリソースの効率性が重要な役割を果たす場合に、重要なアプリケーション設計データ マネジメント パターンです。Spanner は、複数のデータ マネジメント パターンをサポートしています。マルチテナント アプリケーションの実装にご利用ください。 99.999% の可用性 SLA により、計画的なメンテナンスやリージョンの障害が発生した場合にゼロ ダウンタイムを実現します。 また、高可用性とスケーラビリティにより、最新のマルチテナント アプリケーションもサポートします。