このページでは、メジャーの一部である
typeパラメータについて説明します。
typeは、ディメンションまたはフィルタの一部としても使用できます。詳しくは、ディメンション、フィルタ、パラメータの種類に関するドキュメントをご覧ください。
typeは、dimension_groupパラメータのドキュメント ページに記載されているとおり、ディメンション グループの一部として使用することもできます。
使用状況
measure: field_name {
type: measure_field_type
}
}
|
階層
type |
使用可能なフィールドタイプ
測定許可
メジャータイプ |
このページでは、メジャーに割り当てることができるさまざまなタイプについて詳しく説明します。メジャーに含めることができるタイプは 1 つのみです。タイプが指定されていない場合、デフォルトは string です。
一部のメジャータイプには補助パラメーターがあります。補助パラメーターについては、該当するセクションで説明しています。
メジャータイプのカテゴリ
各メジャータイプは、次のいずれかのカテゴリに分類されます。各カテゴリによって、メジャータイプが集計を実行するかどうか、メジャー タイプが参照できるフィールドのタイプ、filters パラメータを使用してメジャー タイプをフィルタできるかどうかが決まります。
- 集計メジャー: 集計メジャータイプは、
sumやaverageなどの集計を実行します。集計メジャーではディメンションのみを参照できます。他のメジャーを参照することはできません。これは、filtersパラメータで使用できる唯一のメジャータイプです。 - 非集計メジャー: 非集計メジャーは、その名前が示すように、集計を実行しないメジャータイプ(
number、yesnoなど)です。メジャータイプでは単純な変換が行われますが、集計を実行しないため、集計メジャーまたは以前に集計されたディメンションのみを参照できます。これらのメジャータイプではfiltersパラメータを使用できません。 - SQL 後のメジャー: SQL 後のメジャーは、Looker がクエリ SQL を生成した後に特定の計算を行う特別なメジャー タイプです。参照できるのは数値メジャーまたは数値ディメンションのみです。これらのメジャータイプでは
filtersパラメータを使用できません。
タイプ定義のリスト
| Type | Category | 説明 |
|---|---|---|
average |
集計 | 列内の値の平均を生成します。 |
average_distinct |
集計 | 非正規化データを使用する場合に、値の平均(平均)を適切に生成する。詳しい説明については、以下の定義を参照してください。 |
count |
集計 | 行のカウントを生成します。 |
count_distinct |
集計 | 列内の一意の値のカウントを生成します。 |
date |
非集計 | 日付を含むメジャーに使用します。 |
list |
集計 | 列内の一意の値のリストを生成します。 |
max |
集計 | 列内の最大値を生成します。 |
median |
集計 | 列内の値の中央値(中間値)を生成します。 |
median_distinct |
集計 | 結合によってファンアウトが発生した場合に、値の中央値(中点値)が適切に生成されることを確認します。詳しい説明については、以下の定義を参照してください。 |
min |
集計 | 列内の最小値を生成します。 |
number |
非集計 | 数値を含むメジャーに使用します。 |
percent_of_previous |
Post-SQL | 表示された行間の差分割合(%)を生成します。 |
percent_of_total |
Post-SQL | 表示された各行の合計に対する割合(%)を生成します。 |
percentile |
集計 | 列内の指定パーセンタイルの値を生成します。 |
percentile_distinct |
集計 | 結合でファンアウトが発生すると、指定されたパーセンタイルで適切に値が生成されます。詳しい説明については、以下の定義を参照してください。 |
running_total |
Post-SQL | 表示された各行の現在までの合計を生成します。 |
string |
非集計 | 文字や特殊文字を含むメジャーの場合(MySQL の GROUP_CONCAT 関数の場合と同様) |
sum |
集計 | 列内の値の合計を生成します。 |
sum_distinct |
集計 | 非正規化されたデータを使用すると、値の合計を正しく生成できます。 詳しくは、以下の定義をご覧ください。 |
yesno |
非集計 | 何かが真であるか偽であるかを示すフィールドに使用します。 |
int |
非集計 |
5.4 で削除
type: number に置き換え |
average
type: average は、指定されたフィールドの値を平均します。SQL の AVG 関数に似ています。ただし、未加工の SQL を記述するのとは異なり、Looker はクエリの結合にファンアウトがあっても平均を適切に計算します。
type: average メジャーの sql パラメータは、数値テーブルの列、LookML ディメンション、または LookML ディメンションの組み合わせになる任意の有効な SQL 式を取ることができます。
type: average フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
たとえば、次の LookML では、sales_price ディメンションを平均して avg_order というフィールドを作成し、金額形式($1,234.56)で表示します。
measure: avg_order {
type: average
sql: ${sales_price} ;;
value_format_name: usd
}
average_distinct
type: average_distinct は非正規化データセットで使用します。sql_distinct_key パラメータで定義された一意の値に基づいて、該当のフィールドで重複しない値が平均化されます。
これは高度な概念であり、例を使ってより明確に説明できます。次のような非正規化テーブルについて考えます。
| Order Item ID | Order ID | 注文出荷 |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20.00 |
| 4 | 2 | 20.00 |
| 5 | 2 | 20.00 |
この場合、注文ごとに複数の行があることがわかります。そのため、order_shipping 列にシンプルな type: average メジャーを追加した場合、実際の平均は 15.00 ですが、値は 16.00 になります。
# Will NOT calculate the correct average
measure: avg_shipping {
type: average
sql: ${order_shipping} ;;
}
正確な結果を得るためには、sql_distinct_key パラメータを使用して、一意の各エンティティ(この場合は一意の順序)を Looker が識別する方法を説明できます。これにより、正しい 15.00 金額が計算されます。
# Will calculate the correct average
measure: avg_shipping {
type: average_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key の一意の値ごとに、sql に対応する値が 1 つだけ必要です。上の例は、order_id が 1 のすべての行の order_shipping が 10.00 で、order_id が 2 のすべての行の order_shipping が 20.00 というように、同じように動作します。
type: average_distinct フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
count
type: count は、SQL の COUNT 関数と同様に、テーブル カウントを行います。ただし、未加工の SQL を記述するのとは異なり、クエリの結合にファンアウトが含まれている場合でも、Looker はカウントを適切に計算します。
type: count メジャーは sql パラメータをサポートしていません。type: count メジャーはテーブルの主キーに基づいてテーブル カウントを行うためです。テーブルの主キー以外のフィールドでテーブル数を指定する場合は、type: count_distinct メジャーを使用します。
たとえば、次の LookML は、フィールド number_of_products を作成します。
view: products {
measure: number_of_products {
type: count
drill_fields: [product_details*] # optional
}
}
type: count メジャーを定義するときに drill_fields(フィールド用)パラメータを指定するのが一般的であり、ユーザーがそれをクリックすると、カウントを構成する個々のレコードが表示されます。
Explore で
type: countのメジャーを使用すると、ビジュアリゼーションに「Count」という単語ではなく、ビュー名で結果のラベルが付けられます。混乱を避けるため、ビジュアリゼーション設定の [Series] で [Show Full Field Name] を選択するか、複数形のビュー名を持つview_labelを使用することをおすすめします。
主キーではないフィールドで(COUNT_DISTINCT ではなく)COUNT を実行する場合は、type: number のメジャーを使用して行います。詳しくは、count メジャーと count_distinct メジャータイプの違いのヘルプセンター記事をご覧ください。
filters パラメータを使用して、type: count のメジャーにフィルタを追加できます。
count_distinct
type: count_distinct は、特定のフィールドの一意の値の数を計算します。SQL の COUNT DISTINCT 関数を利用します。
type: count_distinct メジャーの sql パラメータは、テーブルの列、LookML ディメンション、または LookML ディメンションの組み合わせを生成する有効な SQL 式を取ることができます。
たとえば、次の LookML は、一意の顧客 ID の数をカウントするフィールド number_of_unique_customers を作成します。
measure: number_of_unique_customers {
type: count_distinct
sql: ${customer_id} ;;
}
filters パラメータを使用して、type: count_distinct のメジャーにフィルタを追加できます。
date
type: date は、日付を含むフィールドで使用されます。
type: date メジャーの sql パラメータは、日付となる有効な SQL 式をとることができます。実際には、ほとんどの SQL 集計関数は日付を返しないため、この型はほとんど使用されません。一般的な例外としては、日付ディメンションの MIN または MAX があります。
type: date を使用して最大または最小の日付メジャーを作成する
最大日付または最小日付のメジャーを作成する場合は、最初は type: max または type: min のメジャーを使用すると効果的だと思われるかもしれません。ただし、これらのメジャータイプは数値フィールドとのみ互換性があります。代わりに、type: date のメジャーを定義し、sql パラメータで参照されている日付フィールドを MIN() 関数または MAX() 関数でラップすることで、最大または最小の日付をキャプチャできます。
たとえば、updated という type: time のディメンション グループがあるとします。
dimension_group: updated {
type: time
timeframes: [time, date, week, month, raw]
sql: ${TABLE}.updated_at ;;
}
次のように、このディメンション グループの最大日付を取得する type: date のメジャーを作成します。
measure: last_updated_date {
type: date
sql: MAX(${updated_raw}) ;;
convert_tz: no
}
この例では、type: max のメジャーを使用して last_updated_date メジャーを作成する代わりに、MAX() 関数を sql パラメータに適用します。また、ディメンション グループ updated の定義ではタイムゾーンの変換が行われているため、last_updated_date メジャーでは convert_tz パラメータが no に設定されているため、メジャーで二重タイムゾーン変換が行われません。詳細については、convert_tz パラメータに関するドキュメントをご覧ください。
last_updated_date メジャーの LookML の例では、type: date を省略できます。この値は type のデフォルト値 string であるため、文字列として処理されます。ただし、type: date を使用すると、ユーザーをより適切にフィルタできるようになります。
last_updated_date メジャーの定義では、${updated_date} の期間ではなく ${updated_raw} の期間が参照されています。${updated_date} から返される値は文字列であるため、${updated_raw} を使用して実際の日付値を参照する必要があります。
datatype パラメータを type: date とともに使用して、データベース テーブルで使用する日付データのタイプを指定してクエリのパフォーマンスを高めることもできます。
datetime 列の最大値または最小値のメジャーを作成する
type: datetime 列の最大値の計算は若干異なります。この場合は、次のようにタイプを宣言せずにメジャーを作成します。
measure: last_updated_datetime {
sql: MAX(${TABLE}.datetime_string_field) ;;
}
list
type: list は、指定したフィールドに個別の値のリストを作成します。これは、MySQL の GROUP_CONCAT 関数に似ています。
type: list メジャーに sql パラメータを含める必要はありません。代わりに、list_field パラメータを使用して、リストの作成元となるディメンションを指定します。
使用方法は次のとおりです。
measure: field_name {
type: list
list_field: my_field_name
}
}
たとえば、次の LookML は、name ディメンションに基づいてメジャー name_list を作成します。
measure: name_list {
type: list
list_field: name
}
list については、次の点に注意してください。
listメジャータイプはフィルタリングをサポートしていません。type: listメジャーではfiltersパラメータを使用できません。listメジャータイプは、置換演算子($)を使用して参照できません。${}構文を使用してtype: listメジャーを参照することはできません。
list でサポートされているデータベース言語
Looker プロジェクトで type: list をサポートするには、データベース言語もサポートしている必要があります。次の表に、Looker の最新リリースで type: list をサポートしている言語を示します。
max
type: max は、指定されたフィールドで最大の値を検出します。SQL の MAX 関数を利用します。
type: max メジャーの sql パラメータは、有効な SQL 式を取り、数値テーブルの列、LookML ディメンション、または LookML ディメンションの組み合わせにすることができます。
type: max のメジャーは数値フィールドにのみ対応しているため、type: max のメジャーを使用して最大の日付を求めることはできません。代わりに、date セクションの例で示したように、type: date のメジャーの sql パラメータで MAX() 関数を使用して最大日付を取得できます。
type: max フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
たとえば、次の LookML は、sales_price ディメンションを参照して largest_order というフィールドを作成し、金額形式($1,234.56)で表示します。
measure: largest_order {
type: max
sql: ${sales_price} ;;
value_format_name: usd
}
現時点では、文字列や日付に type: max メジャーを使用することはできませんが、MAX 関数を手動で追加して、そのようなフィールドを作成できます。次に例を示します。
measure: latest_name_in_alphabet {
type: string
sql: MAX(${name}) ;;
}
median
type: median は、指定されたフィールドの値の中点値を返します。これは、データに大きすぎる外れ値または小さすぎる外れ値がいくつか含まれており、それに起因してデータの単純平均が歪む場合に特に役立ちます。
次のようなテーブルについて考えます。
注文商品 ID | 費用 | 中間点-------------:|--------------: 2 | 10.00 | 4 | 10.00 | 3 | 20.00 | 中点値 1 | 80.00 | 5 | 90.00 |
見やすいように、表は費用で並べ替えられていますが、結果には影響しません。average 型は 42 を返します(すべての値を加算して 5 で除算)。median 型は中点値 20.00 を返します。
値が偶数の場合は、中点に最も近い 2 つの値の平均値を使用して中央値を算出します。偶数行からなる次のようなテーブルについて考えます。
注文商品 ID | 費用 | 中間点-------------:|--------------: 2 | 10 | 3 | 20 | 中点付近に最も近い 1 | 80 | 中点付近に最も近い 4 | 90
中央値の中央値は (20 + 80)/2 = 50 です。
type: median メジャーの sql パラメータは、数値テーブルの列、LookML ディメンション、または LookML ディメンションの組み合わせになる任意の有効な SQL 式を取ることができます。
type: median フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
例
たとえば、次の LookML では、sales_price ディメンションを平均して median_order というフィールドを作成し、金額形式($1,234.56)で表示します。
measure: median_order {
type: median
sql: ${sales_price} ;;
value_format_name: usd
}
median について考慮すべきこと
ファンアウトに関連するフィールドに median を使用している場合、Looker は代わりに median_distinct の使用を試みます。ただし、medium_distinct は特定の言語でのみサポートされています。対象の言語について median_distinct を使用できない場合、Looker はエラーを返します。median は 50 パーセンタイルと見なせるため、方言が個別のパーセンタイルをサポートしていないことがエラーで示されます。
median でサポートされているデータベース言語
Looker プロジェクトで median タイプをサポートするには、データベース言語もサポートしている必要があります。次の表に、Looker の最新リリースで median タイプをサポートしている言語を示します。
クエリにファンアウトが発生すると、Looker は median を median_distinct に変換しようとします。これは、median_distinct をサポートする言語でのみ成功します。
median_distinct
結合にファンアウトが含まれる場合は、type: median_distinct を使用します。sql_distinct_key パラメータで定義された一意の値に基づいて、該当のフィールドで重複しない値が平均化されます。メジャーに sql_distinct_key パラメータがない場合、Looker は primary_key フィールドの使用を試みます。
注文品目テーブルと注文テーブルを結合した次のようなクエリ結果について考えます。
| Order Item ID | Order ID | 注文出荷 |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
この場合、注文ごとに複数の行があることがわかります。各注文が複数の注文アイテムにマッピングされているため、このクエリにはファンアウトが含まれています。median_distinct はこれを考慮したうえで、10、20、50 の個別値間の中央値を求め、値 20 を取得します。
正確な結果を得るためには、sql_distinct_key パラメータを使用して、一意の各エンティティ(この場合は一意の順序)を Looker が識別する方法を説明できます。これにより、正しい額が計算されるようになります。
measure: median_shipping {
type: median_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key の一意の値ごとに、メジャーの sql パラメータ内の対応する値が 1 つだけ含まれている必要があります。言い換えれば、order_id が 1 のすべての行の order_shipping が 10 で、order_id が 2 のすべての行の order_shipping が 20 というように動作するからです。
type: median_distinct フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
median_distinct について考慮すべきこと
medium_distinct メジャータイプは、特定の言語でのみサポートされています。median_distinct がこの方言で使用できない場合、Looker はエラーを返します。median は 50 パーセンタイルと見なせるため、方言が個別のパーセンタイルをサポートしていないことがエラーで示されます。
median_distinct でサポートされているデータベース言語
Looker プロジェクトで median_distinct タイプをサポートするには、データベース言語もサポートしている必要があります。次の表に、Looker の最新リリースで median_distinct タイプをサポートしている言語を示します。
min
type: min は、指定されたフィールドの最小値を検索します。SQL の MIN 関数を利用します。
type: min メジャーの sql パラメータは、有効な SQL 式を取り、数値テーブルの列、LookML ディメンション、または LookML ディメンションの組み合わせにすることができます。
type: min のメジャーは数値フィールドにのみ対応しているため、type: min のメジャーを使用して最小の日付を見つけることはできません。代わりに、type: date のメジャーの sql パラメータで MIN() 関数を使用して最小値をキャプチャします。これは、MAX() 関数を使用して type: date のメジャーを使用して最大値をキャプチャするのと同じです。これは、このページの date セクションで以前示しています。ここには、sql パラメータで MAX() 関数を使用して最大日付を求める例が含まれています。
type: min フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
たとえば、次の LookML は、sales_price ディメンションを参照して smallest_order というフィールドを作成し、金額形式($1,234.56)で表示します。
measure: smallest_order {
type: min
sql: ${sales_price} ;;
value_format_name: usd
}
現時点では、文字列や日付に type: min メジャーを使用することはできませんが、MIN 関数を手動で追加して、そのようなフィールドを作成できます。次に例を示します。
measure: earliest_name_in_alphabet {
type: string
sql: MIN(${name}) ;;
}
number
type: number は数値または整数とともに使用されます。type: number のメジャーは集約を実行せず、他のメジャーで簡単な変換を行います。別のメジャーに基づいてメジャーを定義する場合は、ネストされた集計エラーを回避するために、新しいメジャーは type: number にする必要があります。
type: number メジャーの sql パラメータは、数値または整数となる有効な SQL 式を取ることができます。
type: number フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
たとえば、次の LookML は、total_sale_price と total_gross_margin の集約メジャーに基づいて total_gross_margin_percentage というメジャーを作成し、小数点以下 2 桁をパーセンテージ形式で表示します(12.34%)。
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
}
measure: total_gross_margin {
type: sum
value_format_name: usd
sql: ${gross_margin} ;;
}
measure: total_gross_margin_percentage {
type: number
value_format_name: percent_2
sql: ${total_gross_margin}/ NULLIF(${total_sale_price},0) ;;
}
上の例では、NULLIF() SQL 関数を使用してゼロ除算エラーの可能性も削除しています。
type: number について考慮すべきこと
type: number メジャーを使用する際は、次の点に注意してください。
type: numberのメジャーは、他のディメンションではなく、他のメジャーでのみ算術演算を実行します。- Looker の対称集計は、結合全体で計算すると、
type: numberメジャーの SQL の集計関数を保護しません。 filtersパラメータはtype: numberメジャーでは使用できませんが、回避策についてはfiltersのドキュメントをご確認ください。type: numberメジャーはユーザーに候補を提供しません。
percent_of_previous
type: percent_of_previous は、セルとその列内にある前のセルとの差(%)を計算します。
type: percent_of_previous メジャーの sql パラメータは、別の数値メジャーを参照する必要があります。
type: percent_of_previous フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。ただし、value_format_name パラメータのパーセンテージ形式は、type: percent_of_previous メジャーでは機能しません。これらのパーセンテージ書式は値に100を乗算するものであり、前の計算のパーセント結果を歪める原因となります。
次の例では、LookML が count メジャーに基づいてメジャー count_growth を作成します。
measure: count_growth {
type: percent_of_previous
sql: ${count} ;;
}
Looker UIでは、次のように表示されます。
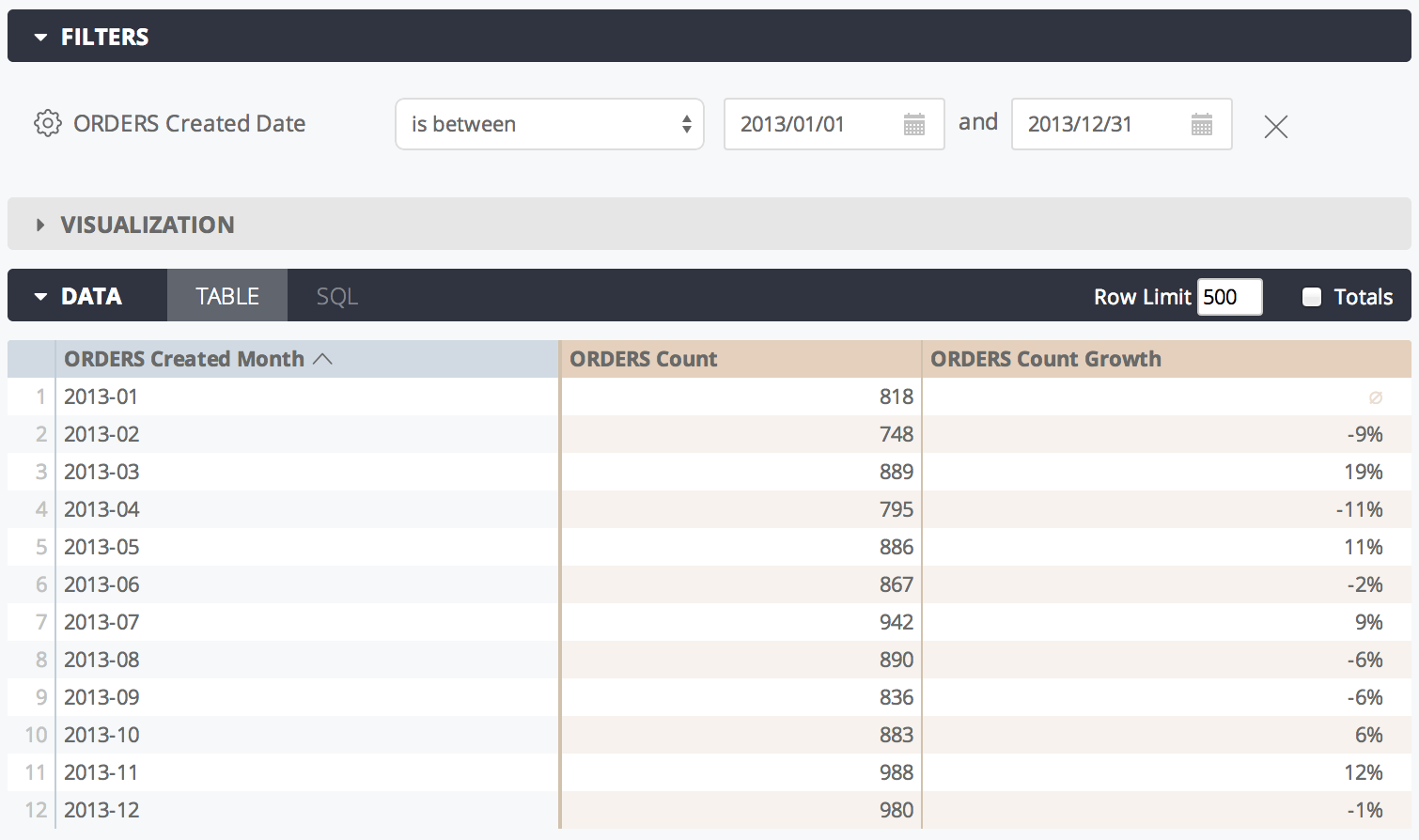
percent_of_previous の値は並べ替え順序によって異なります。並べ替えを変更した場合は、percent_of_previous 値を再計算するためにクエリを再実行する必要があります。クエリがピボットされる場合、percent_of_previous 列の下ではなく行に対して実行されます。現時点でこの動作は変更できません。
また、percent_of_previous メジャーは、データベースからデータが返された後に計算されます。つまり、percent_of_previous メジャーは別のメジャー内で参照しないでください。異なるタイミングで計算されるため、正確な結果が得られない可能性があります。これは、percent_of_previous メジャーをフィルタできないことも意味します。
percent_of_total
type: percent_of_total は、列の合計のセルの部分を計算します。この割合は、クエリによって返されたすべての行に対して計算されます。すべての可能な行の合計ではありません。ただし、クエリによって返されるデータが行数の上限を超えると、フィールドの値が null として表示されます。これは、合計の割合を計算するには、完全な結果が必要になるためです。
type: percent_of_total メジャーの sql パラメータは、別の数値メジャーを参照する必要があります。
type: percent_of_total フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。ただし、value_format_name パラメータのパーセンテージ形式は、type: percent_of_total メジャーでは機能しません。これらの割合形式には、値に 100 が掛けられるため、percent_of_total の計算結果に歪みが生じます。
次の例では、LookML が total_gross_margin メジャーに基づいてメジャー percent_of_total_gross_margin を作成します。
measure: percent_of_total_gross_margin {
type: percent_of_total
sql: ${total_gross_margin} ;;
}
Looker UIでは、次のように表示されます。

クエリがピボットされる場合、percent_of_total 列の下ではなく行に対して実行されます。これが不要な場合は、メジャー定義に direction: "column" を追加します。
また、percent_of_total メジャーは、データベースからデータが返された後に計算されます。つまり、percent_of_total メジャーは別のメジャー内で参照しないでください。異なるタイミングで計算されるため、正確な結果が得られない可能性があります。これは、percent_of_total メジャーをフィルタできないことも意味します。
percentile
type: percentile は、特定のフィールドの値で指定した値を返します。例えば、75番目のパーセンタイルを指定した場合、データセット内の他の75%の値より大きい値が返されます。
Looker は、返す値を特定するために、データ値の合計数を計算し、指定されたパーセンタイルにデータ値の合計数を掛けます。データの実際の並べ替え方法に関係なく、Looker はデータ値の相対的な順序を値で識別します。返されるデータ値は、次に説明するように、計算結果が整数になるかそうでないかに応じて変わります。
計算値が整数でない場合
Looker は計算値を切り上げ、それを使用して返すデータ値を識別します。この例の 19 個のテストスコアのセットでは、75 パーセンタイルは 19 × 0.75 = 14.25 と識別されます。つまり、値の 75% が最初の 14 個のデータ値(15 位以下)にあることを意味します。したがって、75%のデータ値より大きい15番目のデータ値(87)が返されます。

計算値が整数である場合
このやや複雑なケースでは、Looker はその位置のデータ値の平均と次のデータ値を返します。これを理解するために、20 個のテストスコアのセットについて考えてみます。75 パーセンタイルは 20 * .75 = 15 で識別されます。つまり、15 番目の位置のデータ値は 75 パーセンタイルの一部であり、データ値の 75% を超える値を返す必要があります。Looker は 15 番目の位置(82)と 16 番目の位置(87)の平均値を返すことで、75% を保証します。実際の平均(84.5)はデータ値のセットには存在しませんが、75%のデータ値より大きくなります。

必須パラメーターとオプションパラメーター
percentile: キーワードを使用して、小数値(戻り値を下回るデータの割合)を指定します。たとえば、データ順で 75 パーセンタイルの値を指定するには percentile: 75 を使用し、10 パーセンタイルの値を返すには percentile: 10 を使用します。50 パーセンタイルで値を求める場合は、percentile: 50 を指定するか、単純に中央値タイプを使用します。
type: percentile メジャーの sql パラメータは、数値テーブルの列、LookML ディメンション、または LookML ディメンションの組み合わせになる任意の有効な SQL 式を取ることができます。
type: percentile フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
例
たとえば、次の LookML は、test_scores_75th_percentile というフィールドを作成します。このフィールドは、test_scores ディメンションの 75 パーセンタイルの値を返します。
measure: test_scores_75th_percentile {
type: percentile
percentile: 75
sql: ${TABLE}.test_scores ;;
}
percentile について考慮すべきこと
ファンアウトに関連するフィールドに対して percentile を使用している場合、Looker は代わりに percentile_distinct の使用を試みます。percentile_distinct がこの方言で使用できない場合、Looker はエラーを返します。詳細については、percentile_distinct でサポートされている言語をご覧ください。
percentile でサポートされているデータベース言語
Looker プロジェクトで percentile タイプをサポートするには、データベース言語もサポートしている必要があります。次の表に、Looker の最新リリースで percentile タイプをサポートしている言語を示します。
percentile_distinct
type: percentile_distinct は特殊なパーセンタイル形式です。結合にファンアウトが含まれる場合に使用してください。sql_distinct_key パラメータで定義された一意の値に基づいて、該当のフィールドで重複しない値を使用します。メジャーに sql_distinct_key パラメータがない場合、Looker は primary_key フィールドの使用を試みます。
注文品目テーブルと注文テーブルを結合した次のようなクエリ結果について考えます。
| Order Item ID | Order ID | 注文出荷 |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
| 7 | 4 | 70 |
| 8 | 4 | 70 |
| 9 | 5 | 110 |
| 10 | 5 | 110 |
この場合、注文ごとに複数の行があることがわかります。各注文が複数の注文アイテムにマッピングされているため、このクエリにはファンアウトが含まれています。percentile_distinct はこれを考慮したうえで、10、20、50、70、110 の個別値を使用してパーセンタイル値を見つけます。25番目のパーセンタイルを指定した場合は2番目の個別値(20)が返され、80番目のパーセンタイルを指定した場合は4番目と5番目の個別値の平均(90)が返されます。
必須パラメーターとオプションパラメーター
小数値を指定するには、percentile: キーワードを使用します。たとえば、データ順で 75 パーセンタイルの値を指定するには percentile: 75 を使用し、10 パーセンタイルの値を返すには percentile: 10 を使用します。50 パーセンタイルで値を見つけたい場合は、代わりに median_distinct タイプを使用できます。
正確な結果を得るには、sql_distinct_key パラメータを使用して Looker が一意のエンティティ(この場合は一意の順序)を識別する方法を指定します。
以下に、percentile_distinct を使用して 90 パーセンタイルの値を返す例を示します。
measure: order_shipping_90th_percentile {
type: percentile_distinct
percentile: 90
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key の一意の値ごとに、メジャーの sql パラメータ内の対応する値が 1 つだけ含まれている必要があります。上の例は、order_id が 1 のすべての行の order_shipping が 10、order_id が 2 のすべての行の order_shipping が 20 というように、同じように動作します。
type: percentile_distinct フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
percentile_distinct について考慮すべきこと
percentile_distinct がこの方言で使用できない場合、Looker はエラーを返します。詳細については、percentile_distinct でサポートされている言語をご覧ください。
percentile_distinct でサポートされているデータベース言語
Looker プロジェクトで percentile_distinct タイプをサポートするには、データベース言語もサポートしている必要があります。次の表に、Looker の最新リリースで percentile_distinct タイプをサポートしている言語を示します。
running_total
type: running_total は、列に沿ったセルの累積合計を計算します。ピボットの結果として行が処理される場合を除き、行方向で合計を計算することはできません。
type: running_total メジャーの sql パラメータは、別の数値メジャーを参照する必要があります。
type: running_total フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
たとえば、次の LookML は、total_sale_price メジャーに基づいてメジャー cumulative_total_revenue を作成します。
measure: cumulative_total_revenue {
type: running_total
sql: ${total_sale_price} ;;
value_format_name: usd
}
Looker UIでは、次のように表示されます。

running_total の値は並べ替え順序によって異なります。並べ替えを変更した場合は、running_total 値を再計算するためにクエリを再実行する必要があります。クエリがピボットされる場合、running_total 列の下ではなく行に対して実行されます。これが不要な場合は、メジャー定義に direction: "column" を追加します。
また、running_total メジャーは、データベースからデータが返された後に計算されます。つまり、running_total メジャーは別のメジャー内で参照しないでください。異なるタイミングで計算されるため、正確な結果が得られない可能性があります。これは、running_total メジャーをフィルタできないことも意味します。
string
type: string は文字または特殊文字を含むフィールドで使用されます。
type: string メジャーの sql パラメータは、文字列になる有効な SQL 式を取ることができます。実際には、ほとんどの SQL 集計関数は文字列を返さないため、この型はほとんど使用されません。一般的な例外の一つは MySQL の GROUP_CONCAT 関数ですが、Looker はそのようなユースケース向けの type: list を提供しています。
たとえば、次の LookML は、category というフィールドの一意の値を組み合わせて、フィールド category_list を作成します。
measure: category_list {
type: string
sql: GROUP_CONCAT(${category}) ;;
}
この例では、string が type のデフォルト値であるため、type: string は省略できます。
sum
type: sum は、指定されたフィールドの値を加算します。SQL の SUM 関数に似ています。ただし、未加工の SQL を記述するのとは異なり、クエリの結合にファンアウトが含まれている場合でも Looker は合計を計算します。
type: sum メジャーの sql パラメータは、数値テーブルの列、LookML ディメンション、または LookML ディメンションの組み合わせになる任意の有効な SQL 式を取ることができます。
type: sum フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
たとえば、次の LookML では、sales_price ディメンションを加算して total_revenue というフィールドを作成し、金額形式($1,234.56)で表示しています。
measure: total_revenue {
type: sum
sql: ${sales_price} ;;
value_format_name: usd
}
sum_distinct
type: sum_distinct は非正規化データセットで使用します。sql_distinct_key パラメータで定義された一意の値に基づいて、特定のフィールドに重複しない値を加算します。
これは高度な概念であり、例を使ってより明確に説明できます。次のような非正規化テーブルについて考えます。
| Order Item ID | Order ID | 注文出荷 |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20.00 |
| 4 | 2 | 20.00 |
| 5 | 2 | 20.00 |
この場合、注文ごとに複数の行があることがわかります。そのため、order_shipping 列にシンプルな type: sum メジャーを追加した場合、送料の合計は実際には 30.00 になりますが、合計は 80.00 になります。
# Will NOT calculate the correct shipping amount
measure: total_shipping {
type: sum
sql: ${order_shipping} ;;
}
正確な結果を得るためには、sql_distinct_key パラメータを使用して、一意の各エンティティ(この場合は一意の順序)を Looker が識別する方法を説明できます。これにより、正しい 30.00 金額が計算されます。
# Will calculate the correct shipping amount
measure: total_shipping {
type: sum_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key の一意の値ごとに、sql に対応する値が 1 つだけ必要です。上の例は、order_id が 1 のすべての行の order_shipping が 10.00 で、order_id が 2 のすべての行の order_shipping が 20.00 というように、同じように動作します。
type: sum_distinct フィールドは、value_format パラメータまたは value_format_name パラメータを使用してフォーマットできます。
yesno
type: yesno は、正誤問題を示すフィールドを作成します。値は、Explore UI に [Yes] と [No] と表示されます。
type: yesno メジャーの sql パラメータは、TRUE または FALSE と評価される有効な SQL 式を受け取ります。条件が TRUE と評価されると、ユーザーに [はい] と表示されます。それ以外の場合、[いいえ] が表示されます。
type: yesno メジャーの SQL 式には、集計のみを含める必要があります。つまり、SQL 集計または LookML メジャーへの参照を指定します。LookML ディメンションへの参照または集計ではない SQL 式への参照を含む yesno フィールドを作成する場合は、メジャーではなく type: yesno を含むディメンションを使用します。
type: number のメジャーと同様に、type: yesno のメジャーは集計を行わず、他の集計を参照するだけです。
たとえば、以下の total_sale_price メジャーは注文内の注文商品の合計金額です。is_large_total という 2 つ目のメジャーは type: yesno です。is_large_total メジャーには、total_sale_price 値が $1,000 より大きいかどうかを評価する sql パラメータがあります。
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]
}
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
別のフィールドの type: yesno フィールドを参照する場合は、type: yesno フィールドをブール値(つまり、すでに true または false の値が含まれているもの)として扱う必要があります。例:
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
}
# This is correct
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} THEN 200 ELSE 100 END ;;
}
# This is NOT correct
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} = 'Yes' THEN 200 ELSE 100 END ;;
}