Queste istruzioni mostrano come configurare una soluzione per replicare i dati dalle applicazioni SAP, come SAP S/4HANA o SAP Business Suite, a BigQuery utilizzando SAP Landscape Transformation (LT) Replication Server e SAP Data Services (DS).
Puoi utilizzare la replica dei dati per eseguire il backup dei dati SAP quasi in tempo reale o per consolidare i dati dei tuoi sistemi SAP con i dati dei consumatori di altri sistemi in BigQuery per ricavare informazioni dal machine learning e per l'analisi dei dati su scala petabyte.
Le istruzioni sono destinate agli amministratori di sistema SAP che hanno esperienza di base con la configurazione di SAP Basis, SAP LT Replication Server, SAP DS e Google Cloud.
Architettura

SAP LT Replication Server può fungere da fornitore di dati per il framework Operational Data Provisioning (ODP) di SAP NetWeaver. SAP LT Replication Server riceve i dati dai sistemi SAP collegati e li memorizza nel framework ODP in una coda delta operativa (ODQ) del sistema SAP LT Replication Server. Pertanto, SAP LT Replication Server stesso funge anche da destinazione delle configurazioni di SAP LT Replication Server. Il framework ODP rende disponibili i dati come oggetti ODP corrispondenti alle tabelle di sistema di origine.
Il framework ODP supporta scenari di estrazione e replica per varie applicazioni SAP di destinazione, note come abbonati. Gli iscritti recuperano i dati dalla coda delta per ulteriori elaborazioni.
I dati vengono replicati non appena un sottoscrittore li richiede da un'origine dati tramite un contesto ODP. Più sottoscrittori possono utilizzare la stessa ODQ come origine.
SAP LT Replication Server sfrutta il supporto di Change Data Capture (CDC) di SAP Data Services 4.2 SP1 o versioni successive, che include il provisioning dei dati in tempo reale e funzionalità delta per tutte le tabelle di origine.
Il seguente diagramma illustra il flusso di dati attraverso i sistemi:
- Le applicazioni SAP aggiornano i dati nel sistema di origine.
- SAP LT Replication Server replica le modifiche ai dati e li memorizza nella coda delta operativa.
- SAP DS è un abbonato alla coda delta operativa e la sottopone periodicamente a polling per rilevare le modifiche ai dati.
- SAP DS recupera i dati dalla coda delta, li trasforma in modo che siano compatibili con il formato BigQuery e avvia il job di caricamento che sposta i dati in BigQuery.
- I dati sono disponibili in BigQuery per l'analisi.
In questo scenario, il sistema di origine SAP, SAP LT Replication Server e SAP Data Services possono essere in esecuzione su o al di fuori di Google Cloud. Per ulteriori informazioni di SAP, consulta Provisioning dei dati operativi in tempo reale con SAP Landscape Transformation Replication Server.

Componenti principali della soluzione
Per replicare i dati dalle applicazioni SAP su BigQuery utilizzando SAP Landscape Transformation Replication Server e SAP Data Services, sono necessari i seguenti componenti:
| Componente | Versioni richieste | Note |
|---|---|---|
| Stack del server di applicazioni SAP | Qualsiasi sistema SAP basato su ABAP a partire da R/3 4.6C SAP_Basis (Requisito minimo):
|
In questa guida, il server di applicazioni e il server di database vengono
collettivamente
indicati come sistema di origine, anche se sono in esecuzione su
macchine diverse. Definisci l'utente RFC con l'autorizzazione appropriata (Facoltativo) Definisci uno spazio tabella separato per le tabelle di log |
| Sistema di database (DB) | Qualsiasi versione del database indicata come supportata nella matrice di disponibilità dei prodotti SAP (PAM), soggetta alle eventuali limitazioni dello stack SAP NetWeaver elencate nella PAM. Visita la pagina service.sap.com/pam. | |
| Sistema operativo (OS) | Qualsiasi versione del sistema operativo elencata come supportata nel PAM di SAP, soggetta alle limitazioni dello stack SAP NetWeaver elencate nel PAM. Visita la pagina service.sap.com/pam. | |
| SAP Data Migration Server (DMIS) | DMIS:
|
|
| SAP Landscape Transformation Replication Server | SAP LT Replication Server 2.0 o versioni successive | Richiede una connessione RFC al sistema di origine. La definizione delle dimensioni del sistema SAP LT Replication Server dipende molto dalla quantità di dati archiviati in ODQ e dai periodi di conservazione pianificati. |
| SAP Data Services | SAP Data Services 4.2 SP1 o versioni successive | |
| BigQuery | N/D |
Costi
BigQuery è un componente Google Cloud fatturabile.
Utilizza il Calcolatore prezzi per generare una stima dei costi in base all'utilizzo previsto.
Prerequisiti
Queste istruzioni presuppongono che il server di applicazioni SAP, il server di database, SAP LT Replication Server e SAP Data Services siano già installati e configurati per il normale funzionamento.
Prima di poter utilizzare BigQuery, devi avere un Google Cloud progetto.
Configura un Google Cloud progetto in Google Cloud
Devi abilitare l'API BigQuery e, se non hai ancora creato un Google Cloud progetto, devi farlo anche.
Crea Google Cloud project
Vai alla Google Cloud console e registrati, seguendo la procedura guidata di configurazione.
Accanto al Google Cloud logo nell'angolo in alto a sinistra, fai clic sul menu a discesa e seleziona Crea progetto.
Assegna un nome al progetto e fai clic su Crea.
Una volta creato il progetto (viene visualizzata una notifica in alto a destra), aggiorna la pagina.
Abilita API
Abilita l'API BigQuery:
Attivare l'accesso privato alle Google Cloud API
Per i carichi di lavoro SAP in esecuzione al di fuori di Google Cloud, dopo aver stabilito una connessione di rete a Google Cloud, devi attivare l'accesso privato alle API Google Cloud .
Per ulteriori informazioni, consulta Opzioni di accesso privato Google per i servizi.
Crea un account di servizio
L'account di servizio (in particolare il relativo file di chiavi) viene utilizzato per autenticare SAP DS in BigQuery. Utilizzerai il file della chiave in un secondo momento quando crei il data store di destinazione.
Nella Google Cloud console, vai alla pagina Service account.
Selezionare il tuo progetto Google Cloud .
Fai clic su Crea account di servizio.
Inserisci un nome account di servizio.
Fai clic su Crea e continua.
Nell'elenco Seleziona un ruolo, scegli BigQuery > Editor dati BigQuery.
Fai clic su Aggiungi un altro ruolo.
Nell'elenco Seleziona un ruolo, scegli BigQuery > Utente job BigQuery.
Fai clic su Continua.
Se opportuno, concedi ad altri utenti l'accesso all'account di servizio.
Fai clic su Fine.
Nella pagina Account di servizio della Google Cloud console, fai clic sull'indirizzo email dell'account di servizio appena creato.
Sotto il nome dell'account di servizio, fai clic sulla scheda Chiavi.
Fai clic sul menu a discesa Aggiungi chiave, quindi seleziona Crea nuova chiave.
Assicurati che sia specificato il tipo di chiave JSON.
Fai clic su Crea.
Salva il file della chiave scaricato automaticamente in un luogo sicuro.
Configurazione della replica tra le applicazioni SAP e BigQuery
La configurazione di questa soluzione include i seguenti passaggi di alto livello:
- Configurazione di SAP LT Replication Server
- Configurazione di SAP Data Services
- Creazione del flusso di dati tra SAP Data Services e BigQuery
Configurazione di SAP Landscape Transformation Replication Server
I passaggi che seguono configurano SAP LT Replication Server in modo che agisca come fornitore all'interno del framework di provisioning dei dati operativi e creano una coda delta operativa. In questa configurazione, SAP LT Replication Server utilizza la replica basata su trigger per copiare i dati dal sistema SAP di origine nelle tabelle della coda delta. SAP Data Services, che agisce come sottoscrittore nel framework ODP, recupera i dati dalla coda delta, li trasforma e li carica in BigQuery.
Configura la coda delta operativa (ODQ)
- In SAP LT Replication Server, utilizza la transazione
SM59per creare una destinazione RFC per il sistema di applicazioni SAP che è l'origine dati. - In SAP LT Replication Server, utilizza la transazione
LTRCper creare una configurazione. Nella configurazione, definisci l'origine e la destinazione di SAP LT Replication Server. La destinazione per il trasferimento dei dati utilizzando ODP è lo stesso SAP LT Replication Server.- Per specificare l'origine, inserisci la destinazione RFC per il sistema di applicazioni SAP da utilizzare come origine dati.
- Per specificare il target:
- Inserisci NESSUNO come connessione RFC.
- Scegli Scenario di replica ODQ per la comunicazione con la RFC. In questo scenario, specifica che i dati vengono trasferiti utilizzando l'infrastruttura di provisioning dei dati operativi con code delta operative.
- Assegna un alias coda.
L'alias coda viene utilizzato in SAP Data Services per l'impostazione del contesto ODP della sorgente dati.
Configurazione di SAP Data Services
Creare un progetto di servizi dati
- Apri l'applicazione SAP Data Services Designer.
- Vai a File > Nuovo > Progetto.
- Specifica un nome nel campo Nome progetto.
- In Repository dei servizi dati, seleziona il repository dei servizi dati.
- Fai clic su Fine. Il progetto viene visualizzato in Esplora progetti a sinistra.
SAP Data Services si connette ai sistemi di origine per raccogliere i metadati e poi all'agente SAP Replication Server per recuperare la configurazione e modificare i dati.
Crea un datastore di origine
I passaggi che seguono creano una connessione a SAP LT Replication Server e aggiungono le tabelle di dati al nodo del datastore applicabile nella libreria di oggetti di Designer.
Per utilizzare SAP LT Replication Server con SAP Data Services, devi collegare SAP Data Services alla coda delta operativa corretta in ODP collegando un datastore all'infrastruttura ODP.
- Apri l'applicazione SAP Data Services Designer.
- Fai clic con il tasto destro del mouse sul nome del progetto SAP Data Services in Esplora progetti.
- Seleziona Nuovo > DataStore.
- Inserisci Nome datastore. Ad esempio, DS_SLT.
- Nel campo Tipo di data store, seleziona Applicazioni SAP.
- Nel campo Nome server applicazioni, fornisci il nome dell'istanza di SAP LT Replication Server.
- Specifica le credenziali di accesso a SAP LT Replication Server.
- Apri la scheda Advanced (Avanzate).
- In ODP Context (Contesto ODP), inserisci SLT~ALIAS, dove ALIAS è l'alias della coda specificato in Configurare la coda delta operativa (ODQ).
- Fai clic su OK.
Il nuovo data store viene visualizzato nella scheda Datastore della libreria di oggetti locale in Designer.
Crea il datastore di destinazione
Questi passaggi creano un archivio dati BigQuery che utilizza l'account di servizio che hai creato in precedenza nella sezione Creare un account di servizio. L'account di servizio consente a SAP Data Services di accedere in modo sicuro a BigQuery.
Per ulteriori informazioni, consulta Ottenere l'indirizzo email del tuo account di servizio Google e Ottenere un file della chiave privata dell'account di servizio Google nella documentazione di SAP Data Services.
- Apri l'applicazione SAP Data Services Designer.
- Fai clic con il tasto destro del mouse sul nome del progetto SAP Data Services in Esplora progetti.
- Seleziona Nuovo > DataStore.
- Compila il campo Nome. Ad esempio, BQ_DS.
- Fai clic su Avanti.
- Nel campo Tipo di data store, seleziona Google BigQuery.
- Viene visualizzata l'opzione URL servizio web. Il software completa automaticamente l'opzione con l'URL del servizio web BigQuery predefinito.
- Seleziona Avanzate.
- Completa le opzioni avanzate in base alle descrizioni delle opzioni del data store per BigQuery nella documentazione di SAP Data Services.
- Fai clic su OK.
Il nuovo data store viene visualizzato nella scheda Datastore della libreria di oggetti locali di Designer.
Importa gli oggetti ODP di origine per la replica
Questi passaggi importano gli oggetti ODP dal datastore di origine per i caricamenti iniziali e delta e li rendono disponibili in SAP Data Services.
- Apri l'applicazione SAP Data Services Designer.
- Espandi il data store di origine per il caricamento della replica in Esplora progetti.
- Seleziona l'opzione Metadati esterni nella parte superiore del riquadro a destra. Viene visualizzato l'elenco dei nodi con le tabelle e gli oggetti ODP disponibili.
- Fai clic sul nodo degli oggetti ODP per recuperare l'elenco degli oggetti ODP disponibili. La visualizzazione dell'elenco potrebbe richiedere molto tempo.
- Fai clic sul pulsante Cerca.
- Nella finestra di dialogo, seleziona Dati esterni nel menu Cerca in e Oggetto ODP nel menu Tipo di oggetto.
- Nella finestra di dialogo Ricerca, seleziona i criteri di ricerca per filtrare l'elenco degli oggetti ODP di origine.
- Seleziona dall'elenco l'oggetto ODP da importare.
- Fai clic con il tasto destro del mouse e seleziona l'opzione Importa.
- Inserisci il nome del consumatore.
- Inserisci il nome del progetto.
- Seleziona l'opzione Change Data Capture (CDC) in Modalità di estrazione.
- Fai clic su Importa. Viene avviata l'importazione dell'oggetto ODP in Data Services. L'oggetto ODP è ora disponibile nella raccolta di oggetti nel nodo DS_SLT.
Per saperne di più, consulta Importazione dei metadati dell'origine ODP nella documentazione di SAP Data Services.
Crea un file di schema
Questi passaggi creano un flusso di dati in SAP Data Services per generare un file dello schema che rifletta la struttura delle tabelle di origine. In un secondo momento, utilizzerai il file dello schema per creare una tabella BigQuery.
Lo schema garantisce che il flusso di dati del caricatore BigQuery completi correttamente la nuova tabella BigQuery.
Creare un flusso di dati
- Apri l'applicazione SAP Data Services Designer.
- Fai clic con il tasto destro del mouse sul nome del progetto SAP Data Services in Esplora progetti.
- Seleziona Progetto > Nuovo > Flusso di dati.
- Compila il campo Nome. Ad esempio, DF_BQ.
- Fai clic su Fine.
Aggiorna la raccolta di oggetti
- Fai clic con il tasto destro del mouse sul datastore di origine per il caricamento iniziale in Project Explorer e seleziona l'opzione Aggiorna libreria di oggetti. In questo modo viene aggiornato l'elenco delle tabelle di database delle origini dati che puoi utilizzare nel flusso di dati.
Crea il tuo flusso di dati
- Crea il flusso di dati trascinando le tabelle di origine nello spazio di lavoro del flusso di dati e scegliendo Importa come origine quando richiesto.
- Nella scheda Trasformazioni della libreria di oggetti, trascina una trasformazione XML_Map dal nodo Piattaforma i nel flusso di dati e scegli l'opzione Carico collettivo quando richiesto.
- Collega tutte le tabelle di origine nello spazio di lavoro alla trasformazione della mappa XML.
- Apri la trasformazione mappa XML e completa le sezioni dello schema di input e output in base ai dati che includi nella tabella BigQuery.
- Fai clic con il tasto destro del mouse sul nodo XML_Map nella colonna Schema Out e seleziona Genera schema Google BigQuery dal menu a discesa.
- Inserisci un nome e una posizione per lo schema.
- Fai clic su Salva.
- Fai clic con il tasto destro del mouse sul flusso di dati in Esplora progetti e seleziona Rimuovi.
SAP Data Services genera un file schema con estensione .json.
Crea le tabelle BigQuery
Devi creare tabelle nel set di dati BigQuery su Google Cloud sia per il caricamento iniziale sia per i caricamenti delta. Utilizza gli schemi che hai creato in SAP Data Services per creare le tabelle.
La tabella per il caricamento iniziale viene utilizzata per la replica iniziale dell'intero set di dati di origine. La tabella per i caricamenti delta viene utilizzata per la replica delle modifiche nel set di dati di origine che si verificano dopo il caricamento iniziale. Le tabelle si basano sullo schema generato nel passaggio precedente. La tabella per i caricamenti delta include un campo timestamp aggiuntivo che identifica l'ora di ciascun caricamento delta.
Crea una tabella BigQuery per il caricamento iniziale
Questi passaggi creano una tabella per il caricamento iniziale nel set di dati BigQuery.
- Accedi al tuo Google Cloud progetto nella Google Cloud console.
- Seleziona BigQuery.
- Fai clic sul set di dati applicabile.
- Fai clic su Crea tabella.
- Inserisci un nome per la tabella. Ad esempio, BQ_INIT_LOAD.
- In Schema, attiva/disattiva l'impostazione per attivare la modalità Modifica come testo.
- Imposta lo schema della nuova tabella in BigQuery copiando e incollando i contenuti del file dello schema che hai creato in Creare un file dello schema.
- Fai clic su Crea tabella.
Crea una tabella BigQuery per i caricamenti delta
Questi passaggi creano una tabella per i caricamenti delta del set di dati BigQuery.
- Accedi al tuo Google Cloud progetto nella Google Cloud console.
- Seleziona BigQuery.
- Fai clic sul set di dati applicabile.
- Fai clic su Crea tabella.
- Inserisci il nome della tabella. Ad esempio, BQ_DELTA_LOAD.
- In Schema,attiva/disattiva l'impostazione per attivare la modalità Modifica come testo.
- Imposta lo schema della nuova tabella in BigQuery copiando e incollando i contenuti del file dello schema che hai creato in Creare un file dello schema.
Nell'elenco JSON nel file dello schema, appena prima della definizione del campo DI_SEQUENCE_NUMBER, aggiungi la seguente definizione del campo DL_TIMESTAMP. Questo campo memorizza il timestamp di ogni esecuzione del caricamento delta:
{ "name": "DL_TIMESTAMP", "type": "TIMESTAMP", "mode": "REQUIRED", "description": "Delta load timestamp" },Fai clic su Crea tabella.
Configurare il flusso di dati tra SAP Data Services e BigQuery
Per configurare il flusso di dati, devi importare le tabelle BigQuery in SAP Data Services come metadati esterni e creare il job di replica e il flusso di dati del caricatore BigQuery.
Importa le tabelle BigQuery
Questi passaggi importano le tabelle BigQuery create nel passaggio precedente e le rendono disponibili in SAP Data Services.
- Nella libreria di oggetti di SAP Data Services Designer, apri il datastore BigQuery creato in precedenza.
- Nella parte superiore del riquadro a destra, seleziona Metadati esterni. Vengono visualizzate le tabelle BigQuery che hai creato.
- Fai clic con il tasto destro del mouse sul nome della tabella BigQuery applicabile e seleziona Importa.
- Viene avviata l'importazione della tabella selezionata in SAP Data Services. La tabella è ora disponibile nella raccolta di oggetti nel nodo del datastore di destinazione.
Crea un job di replica e il flusso di dati del caricatore BigQuery
Questi passaggi creano un job di replica e il flusso di dati in SAP Data Services che viene utilizzato per caricare i dati da SAP LT Replication Server nella tabella BigQuery.
Il flusso di dati è costituito da due parti. Il primo esegue il caricamento iniziale dei dati degli oggetti ODP di origine nella tabella BigQuery, mentre il secondo abilita i caricamenti delta successivi.
Creare una variabile globale
Affinché il job di replica possa determinare se eseguire un caricamento iniziale o un caricamento delta, devi creare una variabile globale per monitorare il tipo di caricamento nella logica del flusso di dati.
- Nel menu dell'applicazione SAP Data Services Designer, vai a Strumenti > Voci.
- Fai clic con il tasto destro del mouse su Voci globali e seleziona Inserisci.
- Fai clic con il tasto destro del mouse sulla variabile Nome e seleziona Proprietà.
- Inserisci $INITLOAD nella variabile Nome.
- In Tipo di dati, seleziona Int.
- Inserisci 0 nel campo Valore.
- Fai clic su OK.
Crea il job di replica
- Fai clic con il tasto destro del mouse sul nome del progetto in Esplora progetti.
- Seleziona Nuovo > Job batch
- Compila il campo Nome. Ad esempio, JOB_SRS_DS_BQ_REPLICATION.
- Fai clic su Fine.
Crea la logica del flusso di dati per il caricamento iniziale
Creare una condizione
- Fai clic con il tasto destro del mouse su Nome job e seleziona l'opzione Aggiungi nuovo > Condizionale.
- Fai clic con il tasto destro del mouse sull'icona della condizione e seleziona Rinomina.
Modifica il nome in InitialOrDelta.

Apri l'editor delle condizioni facendo doppio clic sull'icona delle condizioni.
Nel campo If statement (Istruttura If), inserisci $INITLOAD = 1, che imposta la condizione per eseguire il caricamento iniziale.
Fai clic con il tasto destro del mouse nel riquadro Poi e seleziona Aggiungi nuovo > Script.
Fai clic con il tasto destro del mouse sull'icona Script e seleziona Rinomina.
Modifica il nome. Ad esempio, queste istruzioni utilizzano InitialLoadCDCMarker.
Fai doppio clic sull'icona Script per aprire l'editor di funzioni.
Inserisci
print('Beginning Initial Load');Inserisci
begin_initial_load();
Fai clic sull'icona Indietro nella barra degli strumenti dell'applicazione per uscire dall'editor di funzioni.
Crea un flusso di dati per il caricamento iniziale
- Fai clic con il tasto destro del mouse nel riquadro Poi e seleziona Aggiungi nuovo > Flusso di dati.
- Rinomina il flusso di dati. Ad esempio, DF_SRS_DS_InitialLoad.
- Collega InitialLoadCDCMarker a DF_SRS_DS_InitialLoad facendo clic sull'icona di output della connessione di InitialLoadCDCMarker e trascinando la linea di connessione all'icona di input di DF_SRS_DS_InitialLoad.
- Fai doppio clic sul flusso di dati DF_SRS_DS_InitialLoad.
Importa e collega il flusso di dati agli oggetti del datastore di origine
- Dal datastore, trascina gli oggetti ODP di origine nell'area di lavoro del flusso di dati. In queste istruzioni, il datastore si chiama DS_SLT. Il nome del tuo datastore potrebbe essere diverso.
- Trascina Trasformazione query dal nodo Piattaforma nella scheda Trasformazioni della raccolta di oggetti sul flusso di dati.
Fai doppio clic sugli oggetti ODP e nella scheda Origine imposta l'opzione Caricamento iniziale su Sì.
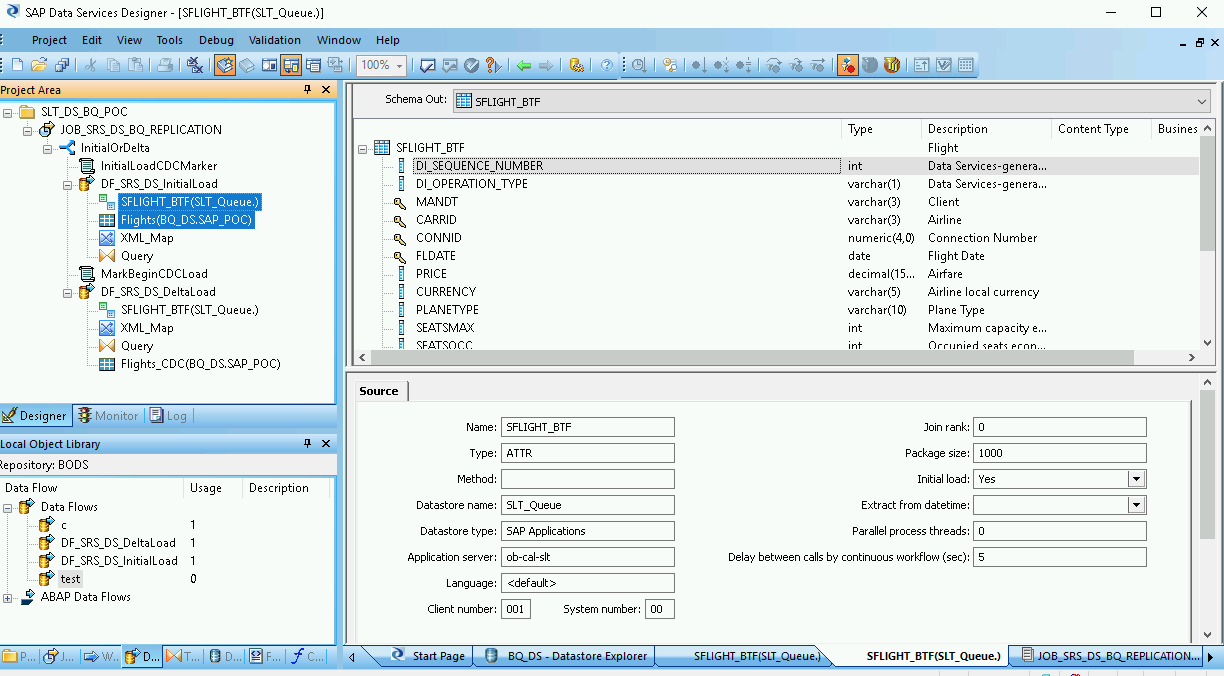
Collega tutti gli oggetti ODP di origine nello spazio di lavoro alla trasformazione Query.
Fai doppio clic su Trasforma query.
Seleziona tutti i campi della tabella in Schema In a sinistra e trascinali in Schema Out a destra.
Per aggiungere una funzione di conversione per un campo data e ora:
- Seleziona il campo data/ora nell'elenco Schema Out (Schema Out) a destra.
- Seleziona la scheda Mappatura sotto gli elenchi di schemi.
Sostituisci il nome del campo con la seguente funzione:
to_date(to_char(FIELDNAME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')dove NOMECAMPO è il nome del campo selezionato.
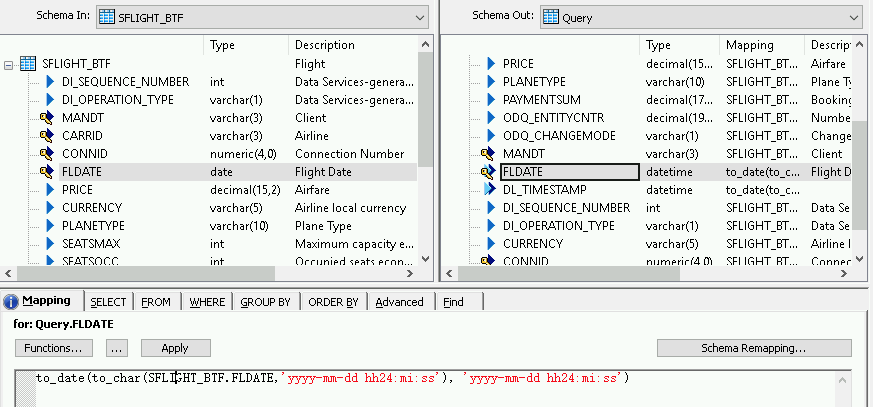
Fai clic sull'icona Indietro nella barra degli strumenti dell'applicazione per tornare al flusso di dati.
Importa e collega il flusso di dati agli oggetti del datastore di destinazione
- Dal datastore nella libreria di oggetti, trascina la tabella BigQuery importata per il caricamento iniziale nel flusso di dati. Il nome del datastore in queste istruzioni è BQ_DS. Il nome del datastore potrebbe essere diverso.
- Dal nodo Piattaforma nella scheda Trasformazioni della libreria di oggetti, trascina una trasformazione XML_Map nel flusso di dati.
- Seleziona Modalità batch nella finestra di dialogo.
- Collega la trasformazione Query alla trasformazione XML_Map.
Collega la trasformazione XML_Map alla tabella BigQuery importata.
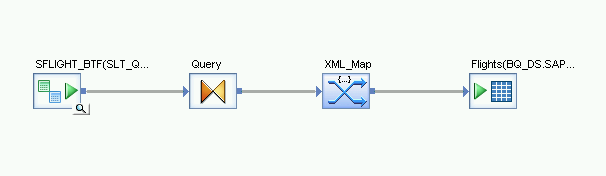
Apri la trasformazione XML_Map e completa le sezioni dello schema di input e output in base ai dati che includi nella tabella BigQuery.
Fai doppio clic sulla tabella BigQuery nello spazio di lavoro per aprirla e completa le opzioni nella scheda Destinazione come indicato nella tabella seguente:
| Opzione | Descrizione |
|---|---|
| Crea porta | Specifica No, che è il valore predefinito. Se specifichi Sì, un file di origine o di destinazione diventa una porta del flusso di dati incorporata. |
| Modalità | Specifica Tronca per il caricamento iniziale, che sostituisce tutti i record esistenti nella tabella BigQuery con i dati caricati da SAP Data Services. Tronca è il valore predefinito. |
| Numero di caricatori | Specifica un numero intero positivo per impostare il numero di caricatori (thread) da utilizzare per l'elaborazione. Il valore predefinito è 4.
Ogni caricatore avvia un job di caricamento riavviabile in BigQuery. Puoi specificare un numero qualsiasi di caricatori. Per determinare il numero appropriato di caricatori, consulta la documentazione di SAP, tra cui: |
| Record con errori massimi per caricatore | Specifica 0 o un numero intero positivo per impostare il numero massimo di record che possono non riuscire per job di caricamento prima che BigQuery interrompa il caricamento dei record. Il valore predefinito è zero (0). |
- Fai clic sull'icona Convalida nella barra degli strumenti in alto.
- Fai clic sull'icona Indietro nella barra degli strumenti dell'applicazione per tornare all'Editor Condizionale.
Crea un flusso di dati per il caricamento delta
Devi creare un flusso di dati per replicare i record di rilevamento dei dati modificati che si accumulano dopo il caricamento iniziale.
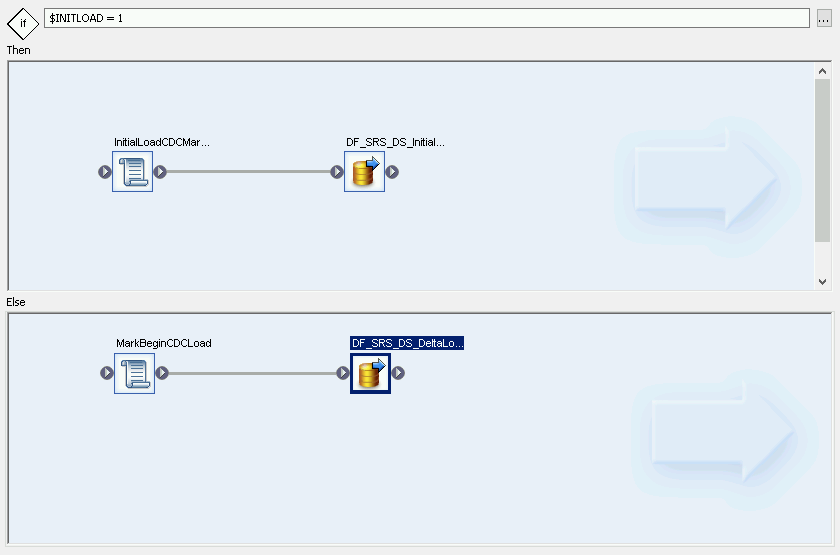
Crea un flusso delta condizionale:
- Fai doppio clic sulla condizione InitialOrDelta.
- Fai clic con il tasto destro del mouse nella sezione Else e seleziona Aggiungi nuovo > Script.
- Rinomina lo script. Ad esempio, MarkBeginCDCLoad.
- Fai doppio clic sull'icona dello script per aprire l'editor di funzioni.
Inserisci print('Inizio caricamento delta');

Fai clic sull'icona Indietro nella barra degli strumenti dell'applicazione per tornare all'Editor delle condizioni.
Crea il flusso di dati per il caricamento delta
- Nell'editor delle condizioni, fai clic con il tasto destro del mouse e seleziona Aggiungi nuovo > Data Flow.
- Rinomina il flusso di dati. Ad esempio, DF_SRS_DS_DeltaLoad.
- Collega MarkBeginCDCLoad a DF_SRS_DS_DeltaLoad, come mostrato nel diagramma seguente.
Fai doppio clic sullo stream di dati DF_SRS_DS_DeltaLoad.
Importa e collega il flusso di dati agli oggetti del datastore di origine
- Trascina gli oggetti ODP di origine dal datastore nello spazio di lavoro del flusso di dati. Il data store in queste istruzioni utilizza il nome DS_SLT. Il nome del tuo datastore potrebbe essere diverso.
- Dal nodo Piattaforma nella scheda Trasformazioni della libreria di oggetti, trascina la trasformazione Query nel flusso di dati.
- Fai doppio clic sugli oggetti ODP e nella scheda Origine, imposta l'opzione Caricamento iniziale su No.
- Collega tutti gli oggetti ODP di origine nell'area di lavoro alla trasformazione Query.
- Fai doppio clic sulla trasformazione Query.
- Seleziona tutti i campi della tabella nell'elenco Schema In a sinistra e trascinali nell'elenco Schema Out a destra.
Attiva il timestamp per i caricamenti delta
I passaggi che seguono consentono a SAP Data Services di registrare automaticamente il timestamp di ogni esecuzione del caricamento delta in un campo della tabella del caricamento delta.
- Fai clic con il tasto destro del mouse sul nodo Query nel riquadro Schema Out a destra.
- Seleziona Nuova colonna di output.
- Inserisci DL_TIMESTAMP in Nome.
- Seleziona Data e ora in Tipo di dati.
- Fai clic su OK.
- Fai clic sul campo DL_TIMESTAMP appena creato.
- Vai alla scheda Mappatura di seguito
Inserisci la seguente funzione:
- to_date(to_char(sysdate(),'aaaa-mm-gg hh24:mi:ss'), 'aaaa-mm-gg hh24:mi:ss')
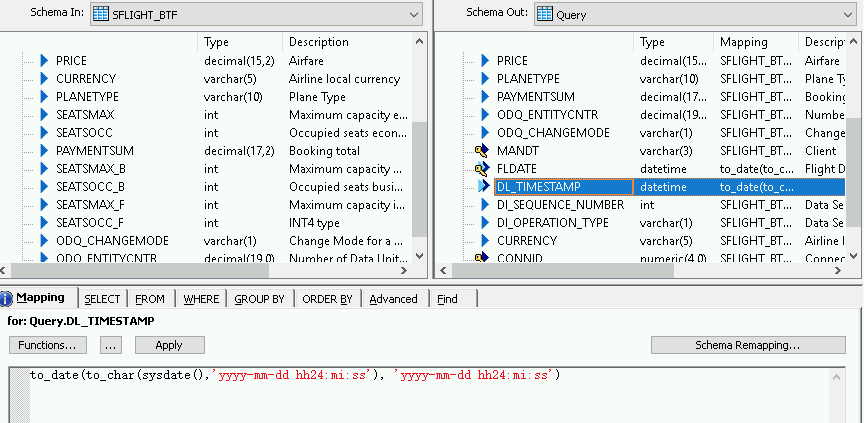
Importa e collega il flusso di dati agli oggetti del datastore di destinazione
- Dal data store nella libreria di oggetti, trascina la tabella BigQuery importata per il caricamento delta nello spazio di lavoro del flusso di dati dopo la trasformazione XML_Map. Queste istruzioni utilizzano il nome del datastore di esempio BQ_DS. Il nome del tuo datastore potrebbe essere diverso.
- Dal nodo Piattaforma nella scheda Trasformazioni della libreria di oggetti, trascina una trasformazione XML_Map nel flusso di dati.
- Collega la trasformazione Query alla trasformazione XML_Map.
Collega la trasformazione XML_Map alla tabella BigQuery importata.
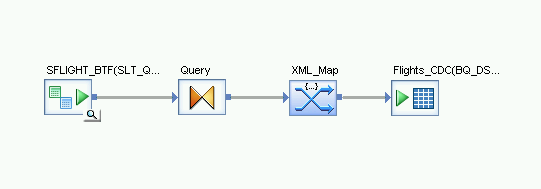
Apri la trasformazione XML_Map e completa le sezioni dello schema di input e output in base ai dati che includi nella tabella BigQuery.
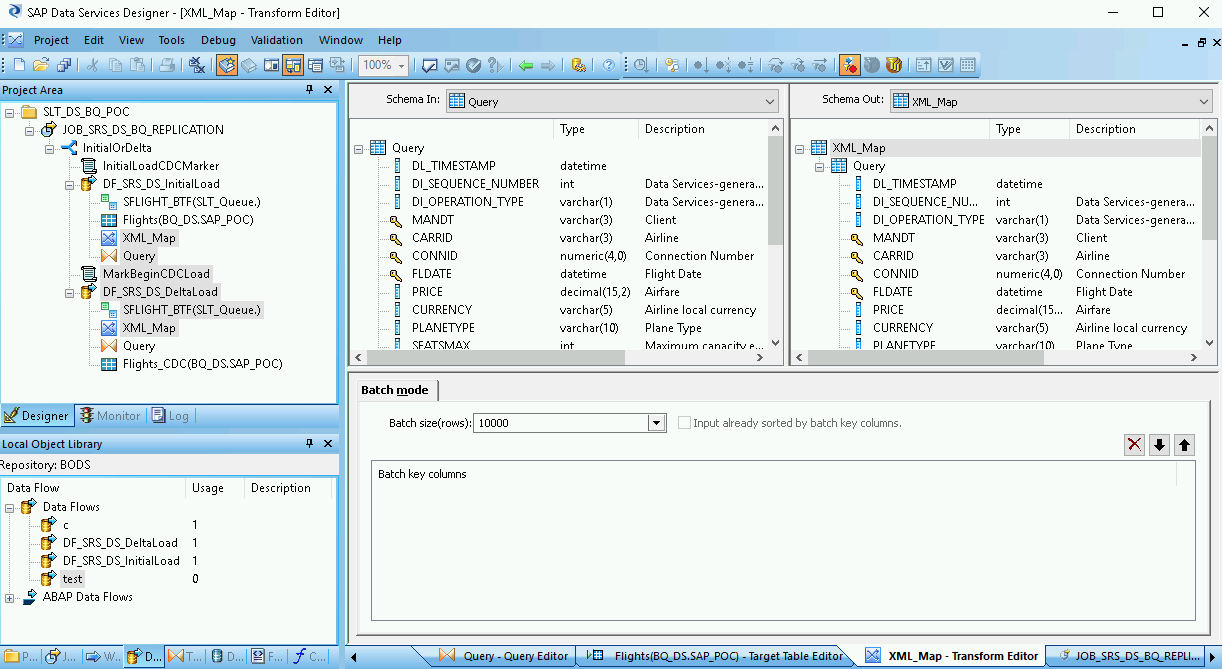
Fai doppio clic sulla tabella BigQuery nell'area di lavoro per aprirla e completa le opzioni nella scheda Destinazione in base alle seguenti descrizioni:
| Opzione | Descrizione |
|---|---|
| Crea porta | Specifica No, che è il valore predefinito. Se specifichi Sì, un file di origine o di destinazione diventa una porta di flusso di dati incorporata. |
| Modalità | Specifica Append per i caricamenti delta, che conserva i record esistenti nella tabella BigQuery quando vengono caricati nuovi record da SAP Data Services. |
| Numero di caricatori | Specifica un numero intero positivo per impostare il numero di caricatori (thread) da utilizzare per l'elaborazione.
Ogni caricatore avvia un job di caricamento riavviabile in BigQuery. Puoi specificare un numero qualsiasi di caricatori. In genere, i caricamenti delta richiedono meno caricatori rispetto al caricamento iniziale. Per determinare il numero appropriato di caricatori, consulta la documentazione SAP, tra cui: |
| Numero massimo di record con errori per caricatore | Specifica 0 o un numero intero positivo per impostare il numero massimo di record che possono non riuscire per job di caricamento prima che BigQuery interrompa il caricamento dei record. Il valore predefinito è zero (0). |
- Fai clic sull'icona Convalida nella barra degli strumenti in alto.
- Fai clic sull'icona Indietro nella barra degli strumenti dell'applicazione per tornare all'editor Condizionale.
Caricamento dei dati in BigQuery
I passaggi per un caricamento iniziale e un caricamento delta sono simili. Per ogni job, avvia il job di replica ed esegui il flusso di dati in SAP Data Services per caricare i dati da SAP LT Replication Server in BigQuery. Una differenza importante tra le due procedure di caricamento è il valore della variabile globale $INITLOAD. Per un caricamento iniziale, $INITLOAD deve essere impostato su 1. Per un caricamento delta, $INITLOAD deve essere 0.
Esegui un caricamento iniziale
Quando esegui un caricamento iniziale, tutti i dati del set di dati di origine vengono replicati nella tabella BigQuery di destinazione collegata al flusso di dati del caricamento iniziale. Tutti i dati nella tabella di destinazione vengono sovrascritti.
- In SAP Data Services Designer, apri Project Explorer.
- Fai clic con il tasto destro del mouse sul nome del job di replica e seleziona Esegui. Viene visualizzata una finestra di dialogo.
- Nella finestra di dialogo, vai alla scheda Variabile globale e modifica il valore di
$INITLOADin 1, in modo che venga eseguito prima il caricamento iniziale. - Fai clic su OK. Viene avviato il processo di caricamento e nel log di SAP Data Services iniziano a comparire i messaggi di debug. I dati vengono caricati nella tabella che hai creato in BigQuery per i caricamenti iniziali. Il nome della tabella di caricamento iniziale in queste istruzioni è BQ_INIT_LOAD. Il nome della tabella potrebbe essere diverso.
- Per verificare se il caricamento è stato completato, vai alla Google Cloud console e apri il set di dati BigQuery contenente la tabella. Se i dati sono ancora in fase di caricamento, accanto al nome della tabella viene visualizzato il messaggio "Caricamento".
Dopo il caricamento, i dati sono pronti per l'elaborazione in BigQuery.
Da questo momento in poi, tutte le modifiche alla tabella di origine vengono registrate nella coda delta di SAP LT Replication Server. Per caricare i dati dalla coda delta in BigQuery, esegui un job di caricamento delta.
Esegui un caricamento delta
Quando esegui un caricamento delta, solo le modifiche apportate al set di dati di origine dall'ultimo caricamento vengono replicate nella tabella BigQuery di destinazione collegata al flusso di dati del caricamento delta.
- Fai clic con il tasto destro del mouse sul nome del job e seleziona Esegui.
- Fai clic su OK. Viene avviato il processo di caricamento e i messaggi di debug iniziano a comparire nel log di SAP Data Services. I dati vengono caricati nella tabella che hai creato in BigQuery per i caricamenti delta. In queste istruzioni, il nome della tabella di caricamento delta è BQ_DELTA_LOAD. Il nome della tabella potrebbe essere diverso.
- Per verificare se il caricamento è stato completato, vai alla Google Cloud console e apri il set di dati BigQuery contenente la tabella. Se i dati sono ancora in fase di caricamento, accanto al nome della tabella viene visualizzato il messaggio "Caricamento".
- Dopo il caricamento, i dati sono pronti per l'elaborazione in BigQuery.
Per tenere traccia delle modifiche ai dati di origine, SAP LT Replication Server registra l'ordine delle operazioni sui dati modificati nella colonna DI_SEQUENCE_NUMBER e il tipo di operazione sui dati modificati nella colonna DI_OPERATION_TYPE (D=elimina, U=aggiorna, I=inserisci). SAP LT Replication Server memorizza i dati nelle colonne delle tabelle della coda delta, da cui vengono replicati in BigQuery.
Pianificazione dei caricamenti delta
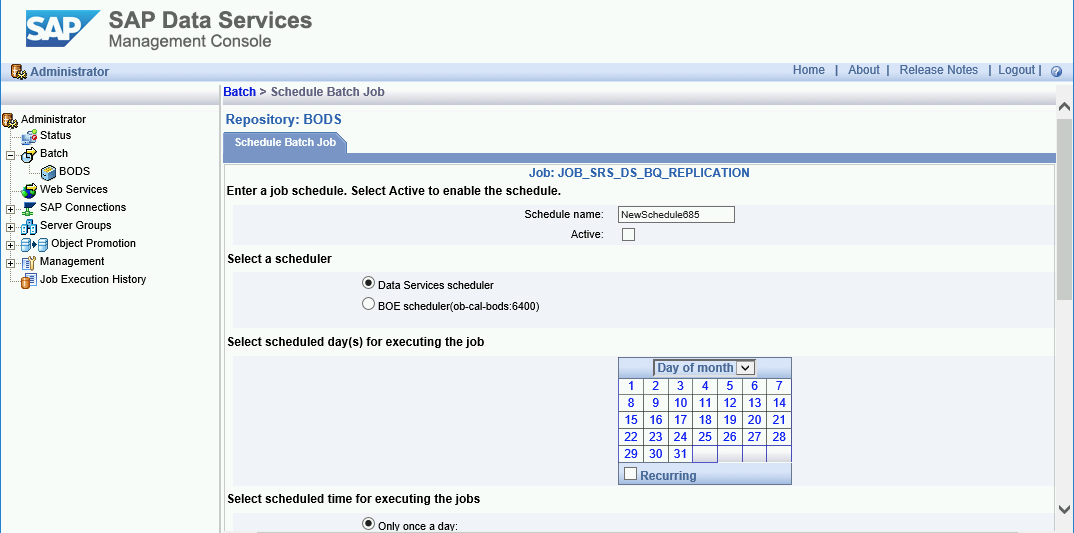
Puoi pianificare l'esecuzione di un job di caricamento delta a intervalli regolari utilizzando la Console di gestione SAP Data Services.
- Apri l'applicazione SAP Data Services Management Console.
- Fai clic su Amministratore.
- Espandi il nodo Batch nella struttura ad albero del menu a sinistra.
- Fai clic sul nome del repository SAP Data Services.
- Fai clic sulla scheda Configurazione job batch.
- Fai clic su Aggiungi pianificazione.
- Inserisci Nome pianificazione.
- Seleziona Attivo.
- Nella sezione Seleziona l'ora pianificata per l'esecuzione dei job, specifica la frequenza per l'esecuzione del caricamento delta.
- Importante: Google Cloud limita il numero di job di caricamento BigQuery che puoi eseguire in un giorno. Assicurati che la pianificazione non superi il limite, che non può essere aumentato. Per ulteriori informazioni sul limite per i job di caricamento di BigQuery, consulta Quote e limiti nella documentazione di BigQuery.
- Espandi Variabili globali e controlla se $INITLOAD è impostato su 0.
- Fai clic su Applica.
Passaggi successivi
Esegui query e analizza i dati replicati in BigQuery.
Per ulteriori informazioni sulle query, vedi:
- Panoramica sull'esecuzione di query sui dati di BigQuery nella documentazione di BigQuery.
Per alcune idee su come consolidare i dati di caricamento iniziale e delta in BigQuery su larga scala, consulta:
- Eseguire mutazioni su larga scala in BigQuery soluzione disponibile nel Google Cloud blog.
- Data Manipulation Language nella documentazione di BigQuery.
Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.