Les jeux sur mobiles génèrent une grande quantité de données de télémétrie des joueurs et d'événements de jeu. Ces données peuvent fournir des renseignements sur le comportement des joueurs et leur implication dans le jeu. Du fait de la nature des jeux sur mobiles (caractérisés par un grand nombre d'appareils clients, des connexions Internet irrégulières et des problèmes de gestion de la batterie et de l'alimentation), la télémétrie des joueurs et l'analyse des événements de jeu se voient confrontées à des défis uniques.
Cette architecture de référence permet de bénéficier de fonctionnalités avancées de collecte, de stockage et d'analyse de grands volumes de données télémétriques relatives aux joueurs dans Google Cloud.
Plus précisément, vous allez découvrir deux principaux schémas d'architecture permettant d'analyser les événements des jeux sur mobiles :
- Traitement en temps réel d'événements individuels à l'aide d'un schéma de traitement par flux
- Traitement groupé d'événements agrégés à l'aide d'un schéma de traitement par lot
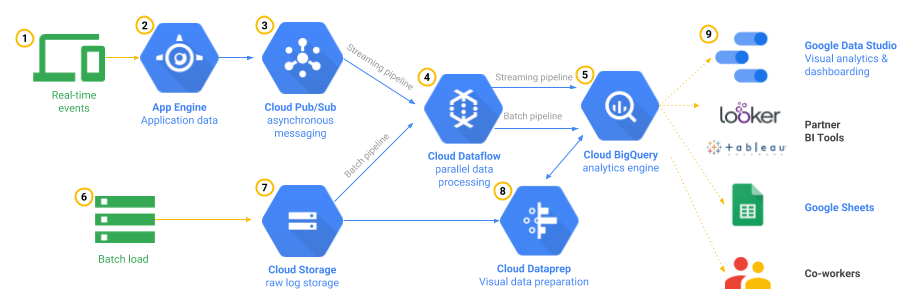
Figure 1 : Architecture de référence pour la télémétrie de jeu
La figure 1 illustre les pipelines de traitement des deux schémas mentionnés ci-dessus, ainsi que certains composants facultatifs vous permettant d'explorer, de visualiser et de partager les résultats. L'architecture de référence est hautement disponible et évolutive à mesure que le volume de vos données augmente. Notez également qu'elle n'est composée que de services gérés pour vos pipelines d'analyse de données, éliminant alors le besoin d'exécuter des machines virtuelles ou de gérer des systèmes d'exploitation. Cette particularité se vérifie notamment lorsque votre serveur de jeu se charge de l'authentification des utilisateurs via App Engine. Le reste de cet article vous explique pas à pas le fonctionnement de cette architecture.
Traitement d'événements en temps réel à l'aide d'un schéma par flux
Cette section décrit un exemple de schéma d'architecture qui ingère, traite et analyse un grand nombre d'événements de manière simultanée, à partir de plusieurs sources différentes. Le traitement s'effectue parallèlement à la production des événements de jeu, ce qui vous permet de réagir et de prendre des décisions en temps réel.
De nombreux jeux sur mobiles génèrent un grand nombre de messages d'événement. Certains de ces messages sont déclenchés par le joueur, d'autres par une heure spécifique, etc. Par conséquent, les ensembles de données ne disposent d'aucune limite, et vous ne pouvez pas prévoir combien d'événements devront être traités. Ainsi, la bonne approche consiste à traiter les données à l'aide d'un moteur d'exécution en flux continu.
Imaginez que votre application mobile soit un jeu de rôle dans lequel les joueurs combattent les forces du mal, en prenant part à des quêtes afin de vaincre de puissants monstres. Pour suivre la progression du joueur, un message d'événement traditionnel comprend un identifiant spécifique au joueur, un horodatage d'événement, des métriques indiquant la quête, la santé actuelle du joueur, etc. Le message pourrait ressembler à l'exemple suivant, qui décrit un message d'événement de fin de combat à l'aide d'un identifiant d'événement playerkillednpc.
{
"eventTime":"2015-10-27T20:34:12.675362426+08:00",
"userId":"gamer@example.com",
"sessionId":"b6ff8881-0c30-9add-374c-c32052cee256",
"eventId":"playerkillednpc",
…
"attackRoll":17,
"damageRoll":13
}
Cet exemple présente un événement lié à un combat, mais les messages d'événement peuvent inclure tous types d'informations pertinentes pour votre entreprise, tels que des événements d'achat dans le jeu.
Puisque vous ne pouvez pas prédire de quelle façon vous pourriez avoir à interroger vos données à l'avenir, il est judicieux de consigner un maximum de points de données. Cela permet de fournir le contexte supplémentaire nécessaire pour vos futures requêtes de données. Par exemple, quelle information s'avère-t-elle la plus utile : le fait qu'un joueur ait effectué un achat dans le jeu à hauteur de 50 centimes, ou bien le fait qu'il ait acheté un sortilège efficace contre le boss de la quête 15, et qu'il se soit fait tuer cinq fois de suite par ce boss au cours des 30 minutes précédant l'achat ? L'enregistrement de données d'événement complètes vous offre un aperçu détaillé de ce qui se passe exactement dans votre jeu.
Source du message : mobile ou serveur de jeu ?
Indépendamment des champs de contenu de vos messages d'événement, vous devez décider si vous souhaitez que l'appareil de l'utilisateur final exécutant l'application mobile envoie directement ces messages à la couche d'ingestion Cloud Pub/Sub, ou si vous préférez passer par le serveur de jeu. Cette deuxième option présente un avantage : l'authentification et la validation sont gérées par votre application. L'inconvénient, toutefois, est que vous avez besoin d'une capacité de traitement de serveur supplémentaire pour gérer la charge des messages d'événement provenant des appareils mobiles.
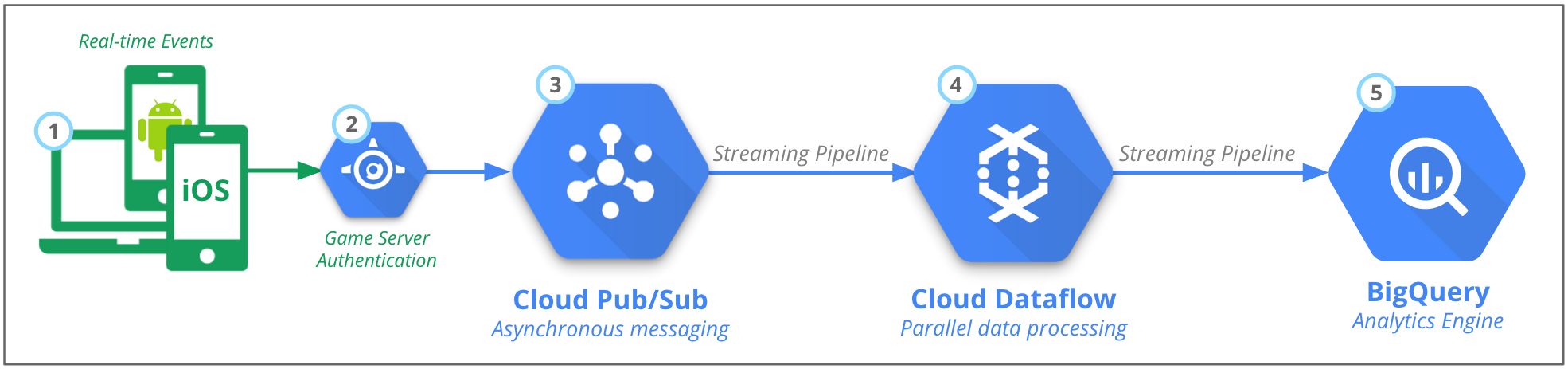
Figure 2 : Traitement en temps réel des événements des serveurs et des clients de jeu
Quelle que soit la source des données, l'architecture du backend reste principalement la même. Comme le montre la figure 2, elle se décompose en cinq grandes parties :
- Les messages d'événements en temps réel sont envoyés par un nombre important de sources, par exemple des millions d'applications mobiles.
- L'authentification est gérée par le serveur de jeu.
- Pub/Sub intègre et stocke temporairement ces messages.
- Dataflow transforme l'événement JSON en données structurées basées sur des schémas.
- Ces données sont chargées dans le moteur d'analyse BigQuery.
Pub/Sub : ingérer des événements à grande échelle
Pour gérer cette charge, vous avez besoin d'un service évolutif capable de recevoir et de stocker temporairement ces messages d'événement. Comme chaque événement individuel prend peu d'espace, le nombre total de messages est plus préoccupant que le besoin global de stockage.
Le service d'ingestion doit également permettre plusieurs méthodes de sortie. Les événements doivent donc être utilisables par plusieurs destinations. Enfin, vous devriez pouvoir choisir d'utiliser le service en tant que file d'attente (où chaque destination interroge l'outil pour récupérer de nouveaux messages) ou d'employer une méthode push (envoyant des événements de manière proactive au moment de leur réception).
Heureusement, le service Pub/Sub propose toutes ces fonctionnalités. La figure 3 décrit la couche d'ingestion recommandée. Celle-ci permet de traiter des millions de messages chaque seconde, et de les stocker pendant un maximum de sept jours sur un espace de stockage persistant. Pub/Sub emploie un modèle de publication/abonnement dans lequel un ou plusieurs éditeurs peuvent envoyer des messages à un sujet ou plus. Un même sujet peut également comporter plusieurs abonnés.
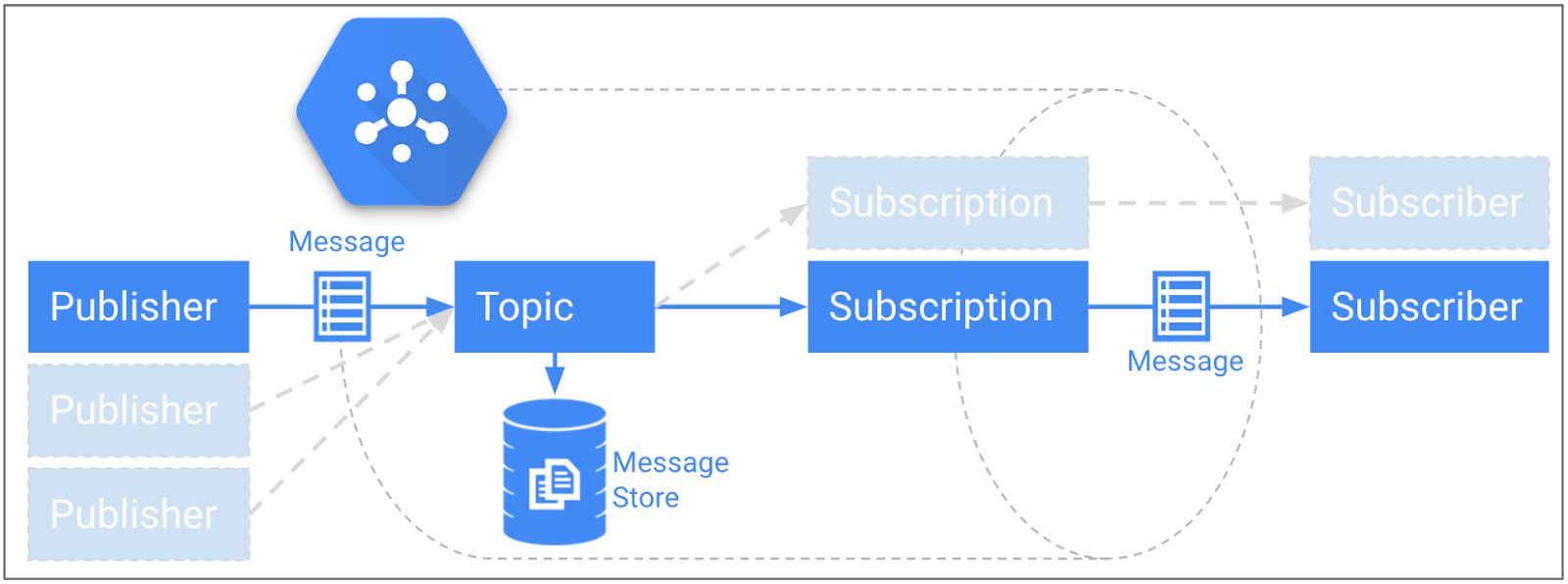
Figure 3 : Modèle de publication/abonnement Pub/Sub avec espace de stockage persistant
Vous pouvez choisir le nombre de sujets ainsi que leur regroupement. Comme ce nombre est directement lié à la quantité de pipelines Dataflow que vous créez, il est préférable de regrouper les événements connectés de manière logique. Un éditeur Pub/Sub peut par exemple être un appareil mobile individuel ou un serveur de jeu, et plusieurs éditeurs peuvent être présents sur un même sujet. Vous devez seulement pouvoir vous authentifier et envoyer un message correctement formaté via HTTPS.
Une fois qu'un message (dans le cas présent, un événement de télémétrie de joueur) est reçu par le service Pub/Sub, il est stocké de façon durable dans la banque de messages jusqu'à ce que chaque abonnement au sujet l'ait récupéré.
Pipeline de flux de données Dataflow
Dataflow propose un langage de haut niveau permettant de décrire les pipelines de traitement de données de manière simple. Vous pouvez les exécuter à l'aide du service géré Dataflow. Le pipeline Dataflow s'exécute en mode de livraison continue et reçoit les messages du sujet Pub/Sub dès leur arrivée via un abonnement. Dataflow se charge ensuite du traitement requis avant d'ajouter ces messages à une table BigQuery.
Ce traitement peut prendre la forme de simples opérations au niveau des éléments, telles que la mise en minuscules de tous les noms d'utilisateurs ou l'association d'éléments avec d'autres sources de données (comme l'association d'une table de noms d'utilisateurs aux statistiques des joueurs).
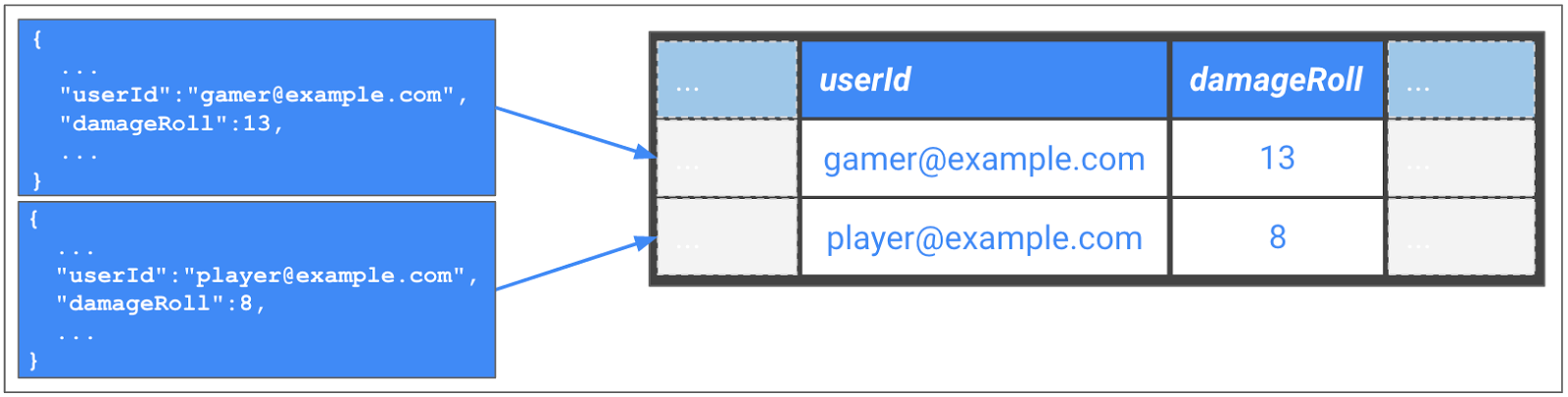
Figure 4 : Transformation des messages JSON au format de table BigQuery
Dataflow peut effectuer tous types de tâches de traitement de données, telles que la validation en temps réel des données d'entrée. La détection des fraudes est l'un des cas d'utilisation possibles. Vous pouvez par exemple identifier un joueur dont les points de vie maximum sortent de la plage valide. Un autre cas d'utilisation est le nettoyage des données, qui vous permet entre autres de vous assurer qu'un message d'événement est bien formé et correspond au schéma BigQuery.
L'exemple de la figure 4 extrait le message JSON d'origine du serveur de jeu et le convertit en un schéma BigQuery. L'intérêt est que vous n'avez pas à gérer de serveurs ni de machines virtuelles pour réaliser cette action. Dataflow effectue les tâches de démarrage, d'exécution et d'arrêt des ressources de calcul pour traiter votre pipeline en parallèle. Vous pouvez également réutiliser le même code pour le traitement par flux et par lot.
Le SDK Dataflow Open Source offre une exécution des pipelines distincte de l'exécution de votre programme Dataflow. Votre programme Dataflow construit le pipeline, et le code que vous avez écrit génère une série d'étapes qui devront être exécutées par un exécuteur de pipeline. Cet exécuteur peut correspondre au service géré Dataflow sur Google Cloud, à un service d'exécution tiers tel que Spark et Flink, ou à un exécuteur de pipeline local qui exécute les étapes directement dans votre environnement local, ce qui s'avère particulièrement utile pour les activités de test et de développement.
Dataflow s'assure que chaque élément est traité exactement une fois, et vous pouvez aussi bénéficier des fonctionnalités de fenêtrage temporel et des déclencheurs pour regrouper les événements en fonction de l'heure réelle à laquelle ils se sont produits (heure de l'événement), et non de celle à laquelle ils ont été envoyés à Dataflow (heure de traitement). Certains messages peuvent être retardés depuis leur source en raison de problèmes de connexion mobile à Internet ou de batterie, mais vous voudrez tout de même regrouper les événements par session utilisateur à un moment ou un autre. La fonctionnalité de fenêtrage de session intégrée à Dataflow permet d'effectuer ce regroupement. Consultez l'article en anglais The world beyond batch: Streaming 101 (Le monde au-delà du regroupement de données : les bases des flux) pour obtenir une excellente introduction aux stratégies de fenêtrage des données.
Si vos événements contiennent un champ de session unique, tel qu'un identifiant unique universel (UUID), vous pouvez également regrouper des événements connexes à l'aide de cette clé. Le choix le plus approprié dépendra de votre scénario spécifique.
BigQuery : un entrepôt de données entièrement géré destiné à l'analyse de données à grande échelle
BigQuery comprend deux composants principaux : tout d'abord un système de stockage qui assure la persistance de vos données avec une redondance géographique et une haute disponibilité, puis un moteur d'analyse qui vous permet d'exécuter des requêtes de type SQL sur des ensembles de données très volumineux. BigQuery organise ses données dans des ensembles de données pouvant contenir plusieurs tables. Le service requiert la définition d'un schéma pour chaque table, et Dataflow nous a principalement servi, dans la section précédente, à organiser les données d'événement brutes au format JSON dans une structure de schéma BigQuery à l'aide du connecteur BigQuery intégré.
Une fois les données chargées dans une table BigQuery, vous pouvez exécuter des requêtes SQL interactives pour extraire des informations précieuses. BigQuery est conçu pour des opérations à très grande échelle, et il vous permet d'exécuter des requêtes d'agrégation sur des pétaoctets de données tout en conservant des temps de réponse rapides. C'est la solution idéale pour l'analyse interactive.
Outils de visualisation des données
Google Data Studio vous permet de créer et de partager des tableaux de bord interactifs qui accèdent à une grande variété de sources de données telles que BigQuery.
BigQuery s'intègre également aux outils courants de veille stratégique et de visualisation, tels que Looker. Enfin, vous pouvez exécuter des requêtes BigQuery directement dans Google Sheets et Microsoft Excel.
Traitement groupé à l'aide d'un schéma par lot
Le deuxième schéma principal consiste à traiter normalement des ensembles de données vastes et limités qui n'ont pas besoin d'être gérés en temps réel. Les pipelines de traitement par lot servent souvent à créer des rapports, ou sont combinés avec des sources en temps réel pour tirer le meilleur parti des deux méthodes. Vous pouvez alors obtenir des données historiques fiables comprenant les dernières informations fournies par les pipelines de flux en temps réel.
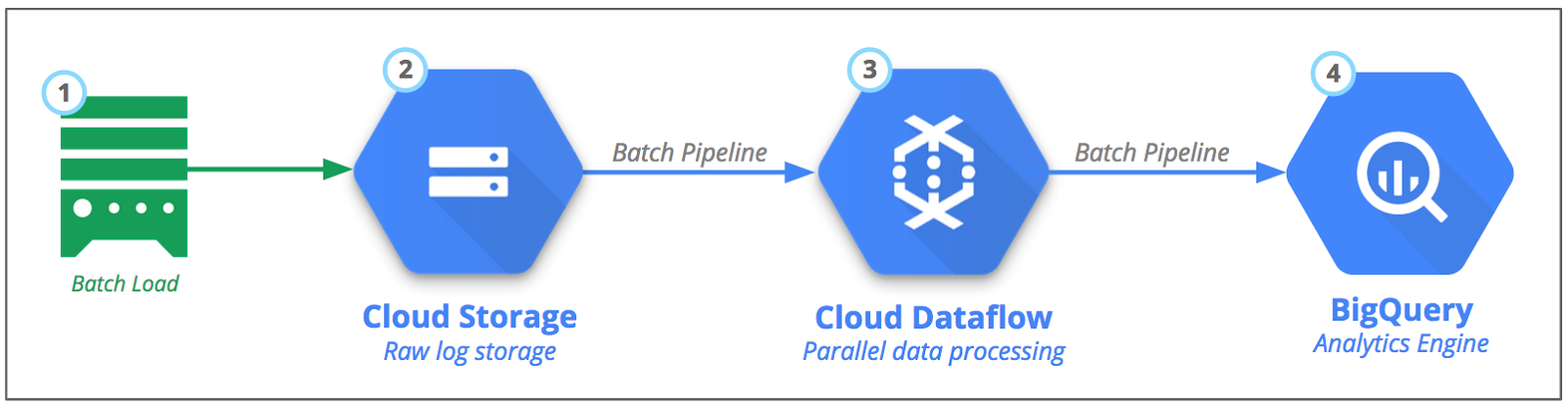
Figure 5 : Traitement par lot des événements et journaux des serveurs de jeu
Cloud Storage est l'endroit idéal pour stocker des fichiers volumineux. Il s'agit d'un service de stockage d'objets durable, économique et hautement disponible. Mais vous vous demandez peut-être comment importer des données dans Cloud Storage ? La réponse dépend de vos sources de données, et nous allons aborder le sujet dans les sections suivantes. Vous allez découvrir trois différents scénarios de sources de données : les données présentes sur site, les données provenant d'autres fournisseurs cloud et les données disponibles dans Google Cloud.
Scénario 1 : Transférer des fichiers à partir de serveurs sur site
Un certain nombre de méthodes vous permettent de transférer en toute sécurité des fichiers journaux depuis votre centre de données sur site. La plus courante consiste à utiliser l'utilitaire de ligne de commande Open Source gsutil pour configurer les transferts de fichiers récurrents. La commande gsutil offre plusieurs fonctionnalités utiles, telles que les importations parallèles multithread lorsque vous disposez de nombreux fichiers et la synchronisation automatique d'un répertoire local ou les importations avec reprise pour les fichiers volumineux. L'utilitaire permet en outre de diviser en fragments de petite taille les fichiers très volumineux et de les importer en parallèle. Ces fonctionnalités réduisent la durée d'importation et exploitent au maximum votre connexion réseau.
Si votre bande passante Internet est insuffisante pour effectuer des importations en temps opportun, vous pouvez vous connecter directement à Google Cloud à l'aide de l'appairage direct ou de l'appairage opérateur. Si vous préférez toutefois envoyer des médias physiques, vous pouvez également utiliser le service Transfer Appliance hors connexion.
Scénario 1 : Transférer des fichiers provenant d'autres fournisseurs cloud
Certains fichiers journaux peuvent être stockés auprès d'autres fournisseurs cloud. Vous exécutez peut-être un serveur de jeu chez l'un de ces fournisseurs et transmettez les journaux à son service de stockage. Ou vous utilisez peut-être un service disposant d'une cible de stockage par défaut. Amazon Cloudfront (un service réseau de diffusion de contenu), par exemple, stocke ses journaux dans un bucket Amazon S3. Heureusement, le déplacement des données depuis Amazon S3 vers Cloud Storage s'effectue facilement.
Si vous transférez quotidiennement de grandes quantités de fichiers d'Amazon S3 vers Cloud Storage, vous pouvez exploiter le service de transfert de stockage pour déplacer des fichiers à partir de sources telles qu'Amazon S3 ou les services HTTP/HTTPS. Vous pouvez configurer des transferts récurrents de manière régulière. En outre, le service de transfert de stockage est compatible avec plusieurs options avancées. Le service tire parti de la large bande passante réseau entre les principaux fournisseurs cloud et utilise des techniques avancées d'optimisation de la bande passante pour atteindre des vitesses de transfert très élevées.
Ce service est recommandé pour les transferts d'au moins 1 à 10 To afin d'éviter les coûts opérationnels associés à l'exécution sur plusieurs serveurs de l'outil gsutil mentionné dans le scénario 1. Pour les transferts de petite taille, ou lorsque vous devez déplacer des données plusieurs fois par jour, l'outil gsutil mentionné dans le scénario 1 peut être un bon choix.
Scénario 3 : Les données sont déjà présentes dans Google Cloud
Dans certains cas, les données dont vous avez besoin sont automatiquement stockées par défaut dans Cloud Storage. Par exemple, les données de Google Play Store telles que les avis, rapports financiers, installations, plantages et absences de réponse de l'application (ANR) sont disponibles dans un bucket Cloud Storage sous votre compte développeur Google Play. Dans ce cas, vous pouvez conserver les données dans le bucket d'origine vers lequel elles ont été exportées, sauf si vous souhaitez les déplacer vers un autre bucket.
Schéma de service de transfert asynchrone
Pour bénéficier d'une approche évolutive et à long terme, vous pouvez mettre en œuvre un schéma de service de transfert asynchrone dans lequel vous lancez des transferts basés sur des événements ou déclencheurs à l'aide d'une ou plusieurs files d'attente et messageries. Par exemple, lorsqu'un nouveau fichier journal est écrit sur le disque ou dans le magasin de fichiers source, un message est envoyé à la file d'attente et les nœuds de calcul se chargent de transférer cet objet vers Cloud Storage, en ne supprimant le message de la file qu'une fois l'opération terminée.
Autre schéma de lot : chargement direct depuis Cloud Storage vers BigQuery
Vous vous demandez peut-être s'il est réellement nécessaire d'utiliser Dataflow entre Cloud Storage et BigQuery. Vous pouvez directement charger les fichiers à partir de fichiers JSON dans Cloud Storage en fournissant un schéma, et en lançant une tâche de chargement. Vous pouvez également interroger directement des fichiers de sauvegarde CSV, JSON ou Datastore dans un bucket Cloud Storage. Cette solution peut être acceptable au début, mais gardez à l'esprit les avantages de l'utilisation de Dataflow :
Transformez les données avant de les stocker. Vous pouvez par exemple rassembler les données avant de les importer dans BigQuery en regroupant différents types de données dans des tables distinctes. Cette démarche peut vous aider à réduire les coûts BigQuery en diminuant le nombre de lignes que vous interrogez. Dans un scénario en temps réel, vous pouvez utiliser Dataflow pour calculer les classements dans des sessions individuelles ou des cohortes telles que des guildes et des équipes.
Utilisez de manière interchangeable les pipelines de données par streaming et par lot écrits dans Dataflow. Modifiez la source et le récepteur de données, par exemple depuis Pub/Sub vers Cloud Storage, et le même code fonctionnera dans les deux scénarios.
Optez pour des schémas de base de données plus flexibles. Si vous avez par exemple ajouté des champs supplémentaires à vos événements au fil du temps, vous voudrez peut-être ajouter les données JSON brutes additionnelles à un champ collecteur dans le schéma puis utiliser la fonctionnalité de requête JSON de BigQuery pour interroger ce champ particulier. Vous pouvez ensuite interroger plusieurs tables BigQuery, même si l'événement de la source requiert absolument des schémas différents. C'est ce que décrit la figure 6.
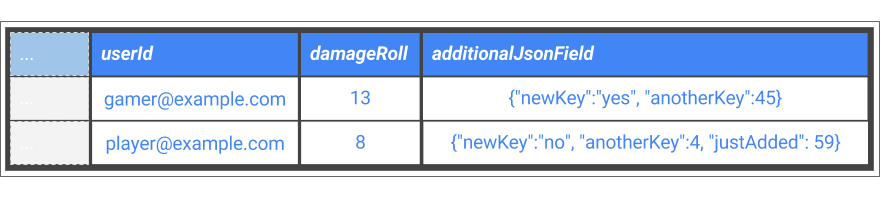
Figure 6 : Colonne supplémentaire permettant de récupérer de nouveaux champs d'événement dans un fichier JSON brut
Considérations opérationnelles pour les architectures de référence
Une fois que vous avez établi et créé vos pipelines, il est important de surveiller les performances et les exceptions potentielles. L'interface utilisateur de surveillance de Dataflow offre une représentation graphique de vos tâches de pipeline de données, ainsi que des métriques clés. La figure 7 vous montre une capture d'écran de cette interface.

Figure 7 : Console de surveillance Dataflow intégrée
La console Dataflow fournit des informations sur le graphique d'exécution du pipeline, ainsi que des métriques sur les performances actuelles, telles que le nombre de messages traités à chaque étape, le retard système estimé et la marque de données. Dataflow est intégré au service Cloud Logging. Pour obtenir des informations détaillées à ce sujet, reportez-vous à la capture d'écran de la figure 8.

Figure 8 : Cloud Logging est intégré à Dataflow