Ce document explique comment déplacer des tâches Apache Spark vers Dataproc. Il est destiné aux ingénieurs et architectes big data. Il couvre des sujets tels que les facteurs à prendre en compte pour la migration, la préparation, la migration des tâches et la gestion.
Présentation
Lorsque vous souhaitez déplacer des charges de travail Apache Spark d'un environnement sur site vers Google Cloud, nous vous recommandons d'exécuter des clusters Apache Spark/Apache Hadoop à l'aide de Dataproc. Ce service, qui est offert par Google Cloud, est entièrement géré et bénéficie d'une assistance complète. Il vous permet de séparer le stockage et le calcul, ce qui vous aide à gérer vos coûts et à faire preuve de plus de flexibilité dans le scaling des charges de travail.
Si un environnement Hadoop géré ne répond pas à vos besoins, vous pouvez également employer une configuration différente. Par exemple, vous pouvez exécuter Spark sur Google Kubernetes Engine (GKE), ou louer des machines virtuelles sur Compute Engine et configurer vous-même un cluster Hadoop ou Spark. Cependant, tenez compte du fait que les options autres que l'utilisation de Dataproc sont autogérées et ne bénéficient que de l'assistance de la communauté.
Planifier votre migration
Il existe de nombreuses différences entre l'exécution de tâches Spark sur site et l'exécution de tâches Spark sur des clusters Hadoop ou Dataproc sur Compute Engine. Il est important d'examiner de près votre charge de travail et de vous préparer à la migration. Dans cette section, nous décrivons les facteurs à considérer et les dispositions à prendre avant de migrer des tâches Spark.
Identifier les types de tâches et planifier les clusters
Comme décrit dans cette section, il existe trois types de charges de travail Spark.
Tâches par lot régulièrement planifiées
Les tâches par lot régulièrement planifiées incluent des cas d'utilisation tels que des processus ETL quotidiens ou horaires, ou des pipelines pour l'entraînement de modèles de machine learning avec Spark ML. Pour les cas précités, nous vous recommandons de créer un cluster pour chaque charge de travail par lot, puis de le supprimer une fois la tâche terminée. Vous avez la possibilité de configurer le cluster, car vous pouvez ajuster la configuration pour chaque charge de travail séparément. Les clusters Dataproc sont facturés par incréments de blocs d'une seconde après la première minute. Cette approche est donc également rentable, car vous pouvez appliquer des libellés aux clusters. Pour en savoir plus, consultez la page Tarifs de Dataproc.
Vous pouvez mettre en œuvre des tâches par lot avec des modèles de workflow ou en procédant comme suit :
Créez un cluster et attendez la fin de l'opération. Vous pouvez vérifier si le cluster a été créé à l'aide d'un appel d'API ou d'une commande gcloud. Si vous exécutez la tâche sur un cluster Dataproc dédié, il peut s'avérer utile de désactiver l'allocation dynamique et le service de brassage externe. La commande
gcloudsuivante affiche les propriétés de configuration Spark fournies lors de la création du cluster Dataproc :dataproc clusters create ... \ --properties 'spark:spark.dynamicAllocation.enabled=false,spark:spark.shuffle.service.enabled=false,spark.executor.instances=10000'Envoyez la tâche au cluster (vous pouvez surveiller l'état de la tâche à l'aide d'un appel d'API ou d'une commande gcloud). Exemple :
jobId=$(gcloud --quiet dataproc jobs submit pyspark \ --async \ --format='value(reference.jobId)' \ --cluster $clusterName \ --region global \ gs://dataproc-examples-2f10d78d114f6aaec76462e3c310f31f/src/pyspark/hello-world/hello-world.py) gcloud dataproc jobs describe $jobId \ --region=global \ --format='value(status.state)'Une fois la tâche exécutée, supprimez le cluster à l'aide d'un appel d'API ou d'une commande gcloud.
Tâches traitées par flux
Pour les tâches traitées par flux, vous devez créer un cluster Dataproc à exécution longue, puis le configurer pour qu'il s'exécute en mode haute disponibilité. Dans ce cas de figure, nous vous déconseillons d'employer des VM préemptives.
Charges de travail ad hoc ou interactives envoyées par les utilisateurs
Les exemples de charges de travail ad hoc peuvent inclure des utilisateurs qui écrivent des requêtes ou exécutent des tâches analytiques au cours de la journée.
Dans ce cas, vous devez décider si le cluster doit s'exécuter en mode haute disponibilité, si vous souhaitez faire appel à des VM préemptives et comment vous allez gérer l'accès au cluster. Vous pouvez planifier la création et l'arrêt d'un cluster (par exemple, si vous n'en avez jamais besoin la nuit ou le week-end), et vous pouvez mettre en œuvre un scaling à la hausse et à la baisse conformément au planning.
Identifier les sources de données et les dépendances
Chaque tâche possède ses propres dépendances (par exemple, les sources de données dont elle a besoin), et les autres équipes au sein de votre entreprise peuvent dépendre du résultat des tâches. Par conséquent, vous devez identifier toutes les dépendances, puis créer un plan de migration qui inclut des procédures pour les points suivants :
Migration étape par étape de toutes les sources de données vers Google Cloud. Au début, il est utile de mettre en miroir la source de données dans Google Cloud afin d'en disposer dans deux endroits.
Migration tâche par tâche des charges de travail Spark vers Google Cloud dès que les sources de données correspondantes ont été migrées. Comme pour les données, il est possible qu'à un certain moment, deux charges de travail s'exécutent en parallèle dans votre ancien environnement et dans Google Cloud.
Migration d'autres charges de travail qui dépendent du résultat des charges de travail Spark. Sinon, vous pouvez simplement répliquer le résultat dans l'environnement initial.
Arrêt des tâches Spark dans l'ancien environnement une fois que toutes les équipes dépendantes ont confirmé qu'elles n'en ont plus besoin.
Choisir les options de stockage
Vous disposez de deux options de stockage avec les clusters Dataproc : vous pouvez stocker toutes les données dans Cloud Storage, ou vous pouvez utiliser des disques locaux ou des disques persistants avec les nœuds de calcul des clusters. L'option adaptée dépend de la nature des tâches.
Comparer Cloud Storage et HDFS
Un connecteur Cloud Storage est installé sur chaque nœud d'un cluster Dataproc. Par défaut, il est installé sous /usr/lib/hadoop/lib. Le connecteur met en œuvre l'interface Hadoop FileSystem et rend Cloud Storage compatible avec HDFS.
Étant donné que Cloud Storage est un système de stockage BLOB (Binary Large Object), le connecteur émule les répertoires en fonction du nom de l'objet. Vous pouvez accéder à vos données en utilisant le préfixe gs:// au lieu de hdfs://.
En règle générale, le connecteur Cloud Storage ne nécessite aucune personnalisation. Toutefois, si vous devez lui apporter des modifications, vous pouvez suivre les instructions relatives à la configuration du connecteur. Une liste complète des clés de configuration est également disponible.
Cloud Storage constitue un excellent choix dans les cas suivants :
- Les données au format ORC, Parquet, Avro ou autre seront utilisées par différents clusters ou différentes tâches, et vous aurez besoin de la persistance des données en cas d'arrêt du cluster.
- Vous avez besoin d'un débit élevé, et les données sont stockées dans des fichiers de plus de 128 Mo.
- Vous avez besoin d'une durabilité interzone pour les données.
- Vous avez besoin que les données aient une disponibilité élevée. Par exemple, vous souhaitez éliminer le composant NameNode HDFS en tant que point unique de défaillance.
Le stockage HDFS local constitue un excellent choix dans les cas suivants :
- Les tâches nécessitent de nombreuses opérations de métadonnées. Par exemple, vous disposez de milliers de partitions et de répertoires, et chaque fichier est d'une taille relativement petite.
- Vous modifiez fréquemment les données HDFS ou vous renommez des répertoires. (Les objets Cloud Storage étant immuables, renommer un répertoire est une opération coûteuse, car elle consiste à copier tous les objets sur une nouvelle clé, puis à les supprimer).
- Vous exécutez fréquemment l'opération append sur les fichiers HDFS.
Les charges de travail impliquent des E/S lourdes. Par exemple, vous avez beaucoup d'écritures partitionnées, comme ci-dessous :
spark.read().write.partitionBy(...).parquet("gs://")Vous avez des charges de travail d'E/S qui sont particulièrement sensibles à la latence. Par exemple, vous avez besoin d'une latence de 0 à 9 millisecondes par opération de stockage.
En général, nous recommandons d'utiliser Cloud Storage comme source de données initiale et finale dans un pipeline de big data. Par exemple, si un workflow contient cinq tâches Spark en série, la première d'entre elles extrait les données initiales de Cloud Storage, puis écrit les données de brassage et le résultat de la tâche intermédiaire dans HDFS. La tâche Spark finale écrit ses résultats dans Cloud Storage.
Ajuster la taille de l'espace de stockage
L'utilisation de Dataproc avec Cloud Storage vous permet de réduire les besoins en termes de disque et les coûts, car vous placez les données à cet emplacement plutôt que dans le HDFS. Lorsque vous conservez les données sur Cloud Storage et ne les stockez pas sur le HDFS local, vous pouvez utiliser des disques plus petits pour le cluster. En rendant le cluster véritablement à la demande, vous pouvez également séparer stockage et calcul, comme indiqué précédemment, ce qui vous permet de réduire considérablement les coûts.
Même si vous stockez toutes les données dans Cloud Storage, le cluster Dataproc a besoin de HDFS pour certaines opérations, telles que le stockage de fichiers de contrôle et de récupération, ou l'agrégation de journaux. Il a également besoin d'espace disque local non-HDFS pour le brassage. Vous pouvez réduire la taille de disque par nœud de calcul si vous n'utilisez pas beaucoup le HDFS local.
Voici quelques options pour ajuster la taille du HDFS local :
- Réduisez la taille totale du HDFS local en diminuant la taille des disques persistants principaux pour le maître et les nœuds de calcul. Le disque persistant principal contient également le volume de démarrage et les bibliothèques système. Par conséquent, allouez au moins 100 Go.
- Augmentez la taille totale du HDFS local en augmentant la taille du disque persistant principal pour les nœuds de calcul. Envisagez cette option avec prudence. Il est rare que l'emploi de HDFS avec des disques persistants standards génère de meilleures performances pour les charges de travail que l'utilisation de Cloud Storage ou du HDFS local avec un disque SSD.
- Associez jusqu'à huit disques SSD (de 375 Go chacun) à chaque nœud de calcul, puis utilisez-les pour HDFS. Il s'agit d'une bonne option si vous devez utiliser HDFS pour des charges de travail à forte demande d'E/S et que vous avez besoin d'une latence inférieure à 10 millisecondes. Assurez-vous que vous employez un type de machine disposant de suffisamment de processeurs et de mémoire sur le nœud de calcul pour accepter ces disques.
- Utilisez des disques persistants SSD (PD-SSD) pour le maître ou les nœuds de calcul en tant que disque principal.
Accéder à Dataproc
L'accès à Dataproc ou à Hadoop sur Compute Engine diffère de l'accès à un cluster sur site. Vous devez déterminer les paramètres de sécurité et les options d'accès au réseau.
Mise en réseau
Toutes les instances de VM d'un cluster Dataproc nécessitent une mise en réseau interne, ainsi que des ports UDP, TCP et ICMP ouverts. Vous pouvez autoriser l'accès au cluster Dataproc à partir d'adresses IP externes à l'aide de la configuration réseau par défaut ou d'un réseau VPC. Le cluster Dataproc disposera d'un accès réseau à tous les services Google Cloud (buckets Cloud Storage, API, etc.), quelle que soit l'option de réseau que vous choisissez. Pour autoriser l'accès réseau depuis ou vers des ressources sur site, choisissez une configuration de réseau VPC et configurez les règles de pare-feu appropriées. Pour en savoir plus, consultez le guide Configuration du réseau de cluster Dataproc et la section Accéder à YARN ci-dessous.
Gestion de l'authentification et des accès
En plus de l'accès réseau, le cluster Dataproc a besoin d'autorisations pour accéder aux ressources. Par exemple, pour écrire des données dans un bucket Cloud Storage, il doit disposer d'un accès en écriture à celui-ci. Vous établissez l'accès à l'aide de rôles. Parcourez votre code Spark et recherchez toutes les ressources non-Dataproc dont le code a besoin, puis attribuez les rôles appropriés au compte de service du cluster. Assurez-vous également que les utilisateurs qui créeront des clusters, des tâches, des opérations et des modèles de workflow disposent des autorisations appropriées.
Pour obtenir plus de détails et connaître les bonnes pratiques, consultez la documentation IAM.
Valider Spark et les autres dépendances de bibliothèque
Comparez votre version de Spark et les versions des autres bibliothèques à la liste des versions Dataproc officielle, et recherchez toutes les bibliothèques qui ne sont pas encore disponibles. Nous vous recommandons d'utiliser les versions de Spark officiellement compatibles avec Dataproc.
Si vous devez ajouter des bibliothèques, vous pouvez procéder comme suit :
- Créez une image personnalisée d'un cluster Dataproc.
- Créez des scripts d'initialisation dans Cloud Storage pour votre cluster. Vous pouvez exécuter des scripts d'initialisation pour installer des dépendances supplémentaires, copier des fichiers binaires, etc.
- Recompilez le code Java ou Scala, puis empaquetez toutes les dépendances supplémentaires qui ne font pas partie de la distribution de base en tant que "fichier Fat JAR" à l'aide de Gradle, Maven, Sbt ou d'un autre outil.
Ajuster la taille du cluster Dataproc
Quelle que soit la configuration du cluster, qu'elle soit sur site ou dans le cloud, la taille du cluster est cruciale pour les performances des tâches Spark. Une tâche Spark dotée de ressources insuffisantes soit sera lente, soit échouera, en particulier si elle ne dispose pas de suffisamment de mémoire d'exécuteur. Pour obtenir des conseils sur les points à prendre en compte lors du dimensionnement d'un cluster Hadoop, consultez la section Dimensionner votre cluster du guide de migration Hadoop.
Les sections suivantes décrivent certaines options pour le dimensionnement du cluster.
Obtenir la configuration des tâches Spark en cours
Examinez la configuration des tâches Spark en cours et assurez-vous que le cluster Dataproc est assez volumineux. Si vous passez d'un cluster partagé à plusieurs clusters Dataproc (un pour chaque charge de travail par lot), examinez la configuration YARN de chaque application pour déterminer le nombre d'exécuteurs dont vous avez besoin, le nombre de processeurs par exécuteur et le volume total de la mémoire d'exécuteur. Si des files d'attente YARN sont configurées sur votre cluster sur site, identifiez les tâches qui partagent les ressources de chaque file d'attente et détectez les goulots d'étranglement. Cette migration représente une opportunité de supprimer toutes les restrictions en matière de ressources auxquelles vous auriez pu être soumis dans le cluster sur site.
Choisir des types de machines et des options de disque
Choisissez le nombre et le type de VM correspondant aux besoins de la charge de travail. Si vous avez décidé d'utiliser le HDFS local pour le stockage, assurez-vous que les VM disposent du type et de la taille de disque appropriés. N'oubliez pas de prendre en compte les besoins en ressources des programmes de pilote dans votre calcul.
Chaque VM est soumise à un plafond de sortie réseau de 2 Gbit/s par processeur virtuel. L'écriture sur des disques persistants ou sur des disques persistants SSD est comptabilisée dans ce plafond, de sorte qu'une VM ayant un très petit nombre de processeurs virtuels peut être limitée par ce plafond lorsqu'elle écrit sur ces disques. Cela est susceptible de se produire lors de la phase de brassage, lorsque Spark écrit les données de brassage sur le disque et les déplace sur le réseau entre les exécuteurs. Les disques persistants nécessitent au moins deux processeurs virtuels pour atteindre des performances d'écriture maximales, tandis que les disques persistants SSD en exigent quatre. Notez que ces valeurs minimales ne prennent pas en compte le trafic tel que les communications entre les VM. De plus, la taille de chaque disque affecte ses performances optimales.
La configuration que vous choisissez aura un impact sur le coût du cluster Dataproc. Les tarifs de Dataproc s'ajoutent au prix par instance de Compute Engine pour chaque VM et pour les autres ressources Google Cloud. Si vous souhaitez en savoir plus et utiliser le simulateur de coût Google Cloud afin d'obtenir une estimation des coûts, consultez la page Tarifs de Dataproc.
Effectuer une analyse comparative des performances et procéder à des optimisations
Une fois que vous avez terminé la phase de migration des tâches, mais avant d'arrêter d'exécuter les charges de travail Spark dans le cluster sur site, effectuez une analyse comparative des tâches Spark et envisagez de procéder à des optimisations. N'oubliez pas que vous pouvez redimensionner le cluster si votre configuration n'est pas optimale.
Dataproc sans serveur pour l'autoscaling Spark
Utilisez Dataproc Serverless pour l'exécution des charges de travail Spark sans provisionner ni gérer votre propre cluster. Spécifiez les paramètres de charge de travail, puis envoyez la charge de travail au service Dataproc sans serveur. Le service exécutera la charge de travail sur une infrastructure de calcul gérée en effectuant un autoscaling des ressources selon les besoins. Les frais de Dataproc sans serveur ne s'appliquent qu'au moment où la charge de travail est exécutée.
Procéder à la migration
Cette section traite de la migration des données, de la modification du code des tâches et de la façon dont les tâches sont exécutées.
Migrer les données
Avant d'exécuter des tâches Spark dans votre cluster Dataproc, vous devez migrer vos données vers Google Cloud. Pour en savoir plus, consultez le guide de migration des données.
Migrer le code Spark
Une fois que vous avez planifié la migration vers Dataproc et déplacé les sources de données requises, vous pouvez migrer le code des tâches. S'il n'y a aucune différence dans les versions de Spark entre les deux clusters et si vous souhaitez stocker des données sur Cloud Storage au lieu du HDFS local, il vous suffit de remplacer le préfixe hdfs:// de tous les chemins de fichiers HDFS par gs://.
Si vous utilisez différentes versions de Spark, consultez les notes de version de Spark, comparez les deux versions et adaptez le code Spark en conséquence.
Vous pouvez copier les fichiers JAR des applications Spark dans le bucket Cloud Storage lié au cluster Dataproc ou dans un dossier HDFS. La section suivante explique les options disponibles pour l'exécution de tâches Spark.
Si vous décidez d'utiliser des modèles de workflow, nous vous recommandons de tester séparément chaque tâche Spark que vous prévoyez d'ajouter. Vous pouvez ensuite exécuter une dernière série de tests sur le modèle pour vous assurer que son workflow est correct (aucune tâche en amont manquante, résultats stockés aux bons emplacements, etc.).
Exécuter des tâches
Vous pouvez exécuter des tâches Spark de différentes manières :
À l'aide de la commande
gcloudsuivante :gcloud dataproc jobs submit [COMMAND]
où :
[COMMAND]estspark,pysparkouspark-sqlVous pouvez définir les propriétés Spark à l'aide de l'option
--properties. Pour en savoir plus, consultez la documentation sur cette commande.À l'aide du même processus que celui que vous avez utilisé avant de migrer la tâche vers Dataproc. Le cluster Dataproc doit être accessible sur site, et vous devez employer la même configuration.
À l'aide de Cloud Composer. Vous pouvez créer un environnement (un serveur Apache Airflow géré), définir plusieurs tâches Spark en tant que workflow DAG, puis exécuter l'intégralité du workflow.
Pour en savoir plus, consultez le guide Envoyer une tâche.
Gérer les tâches après la migration
Une fois que vous avez déplacé les tâches Spark vers Google Cloud, il est important de les gérer à l'aide des outils et des mécanismes fournis par Google Cloud. Cette section traite de la journalisation, de la surveillance, de l'accès aux clusters, du scaling de ces clusters et de l'optimisation des tâches.
Utiliser la journalisation et la surveillance des performances
Dans Google Cloud, vous pouvez vous servir de Cloud Logging et de Cloud Monitoring pour afficher et personnaliser les journaux, ainsi que pour surveiller les tâches et les ressources.
Le meilleur moyen d'identifier l'erreur ayant entraîné l'échec d'une tâche Spark est d'examiner le résultat du pilote et les journaux générés par les exécuteurs Spark.
Vous pouvez récupérer le résultat du programme de pilote à l'aide de Google Cloud Console ou d'une commande gcloud. Le résultat est également stocké dans le bucket Cloud Storage du cluster Dataproc. Pour en savoir plus, consultez la section sur les résultats du pilote de tâches dans la documentation Dataproc.
Tous les autres journaux se trouvent dans des fichiers différents à l'intérieur des machines du cluster. Il est possible de voir les journaux de chaque conteneur à partir de l'interface utilisateur Web de l'application Spark (ou du serveur d'historique à la fin du programme) dans l'onglet des exécuteurs. Vous devez parcourir chaque conteneur Spark pour afficher chaque journal. Si vous écrivez des journaux ou imprimez sur stdout ou stderr dans le code de votre application, les journaux sont enregistrés dans la redirection de stdout ou stderr.
Dans un cluster Dataproc, YARN est configuré pour collecter tous ces journaux par défaut. Ceux-ci sont disponibles dans Cloud Logging. Cloud Logging fournit une vue consolidée et concise de tous les journaux afin que vous ne perdiez pas de temps à parcourir les journaux de conteneurs à la recherche d'erreurs.
La figure suivante représente la page Cloud Logging dans la console Google Cloud. Vous pouvez afficher tous les journaux de votre cluster Dataproc en sélectionnant son nom dans le menu de sélection. N'oubliez pas d'allonger la durée dans le sélecteur de période.
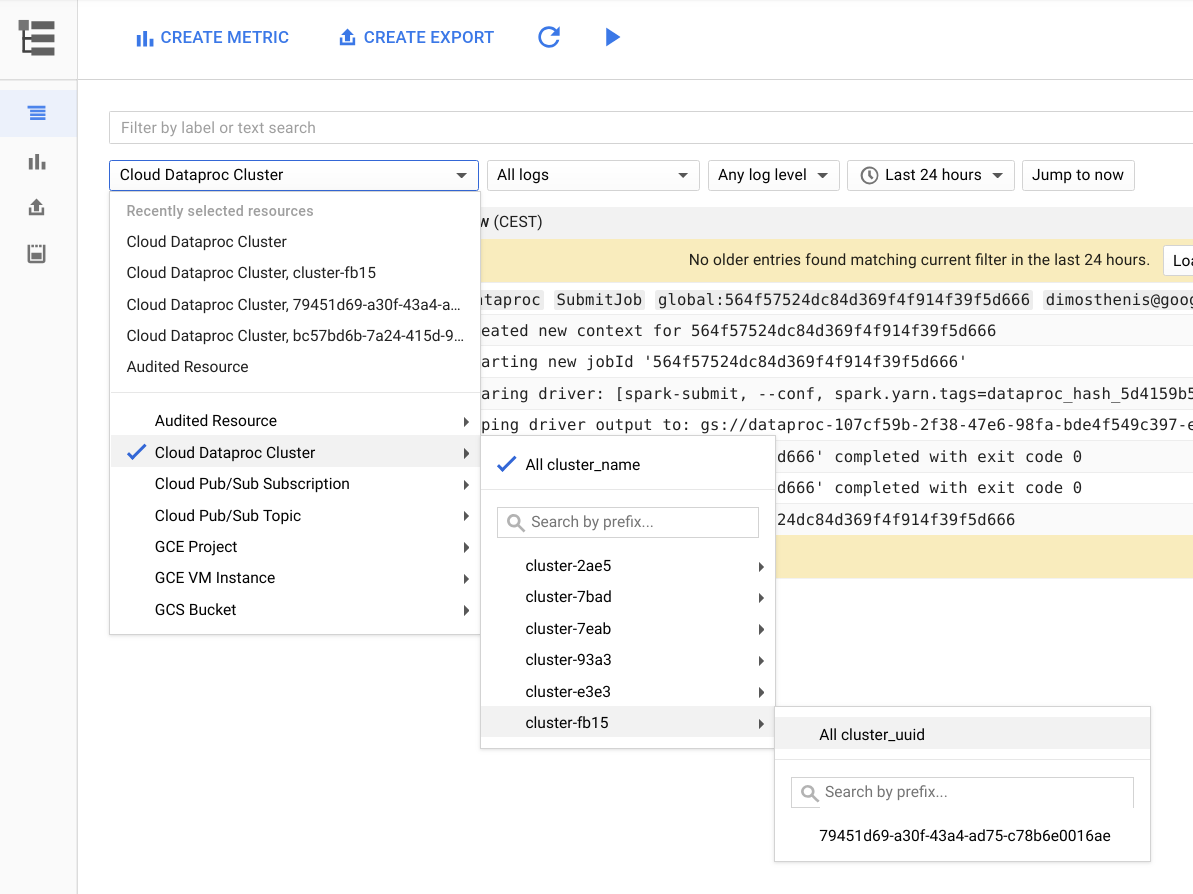
Vous pouvez obtenir les journaux d'une application Spark en filtrant sur son ID. Vous pouvez obtenir l'ID de l'application à partir du résultat du pilote.
Créer et utiliser des libellés
Pour trouver les journaux plus rapidement, vous pouvez créer et utiliser vos propres libellés pour chaque cluster ou pour chaque tâche Dataproc. Par exemple, vous pouvez créer un libellé avec la clé env et la valeur exploration, puis l'utiliser pour votre tâche d'exploration de données. Vous pouvez ensuite obtenir des journaux pour toutes les créations de tâches d'exploration en filtrant avec label:env:exploration dans Cloud Logging.
Notez que ce filtre ne renverra pas tous les journaux de cette tâche, mais uniquement les journaux de création de ressources.
Définir le niveau de journalisation
Vous pouvez définir le niveau de journalisation du pilote à l'aide de la commande gcloud suivante :
gcloud dataproc jobs submit hadoop --driver-log-levels
Vous définissez le niveau de journalisation pour le reste de l'application à partir du contexte Spark. Exemple :
spark.sparkContext.setLogLevel("DEBUG")Surveiller les tâches
Cloud Monitoring peut surveiller l'utilisation du processeur, du disque et du réseau du cluster, ainsi que les ressources YARN. Vous pouvez créer un tableau de bord personnalisé afin d'obtenir des graphiques à jour pour ces métriques et pour d'autres. Dataproc s'exécute sur Compute Engine. Si vous souhaitez visualiser l'utilisation du processeur, les E/S du disque ou les métriques réseau dans un graphique, vous devez sélectionner une instance de VM Compute Engine comme type de ressource, puis filtrer par nom de cluster. Le schéma suivant présente un exemple de résultat.
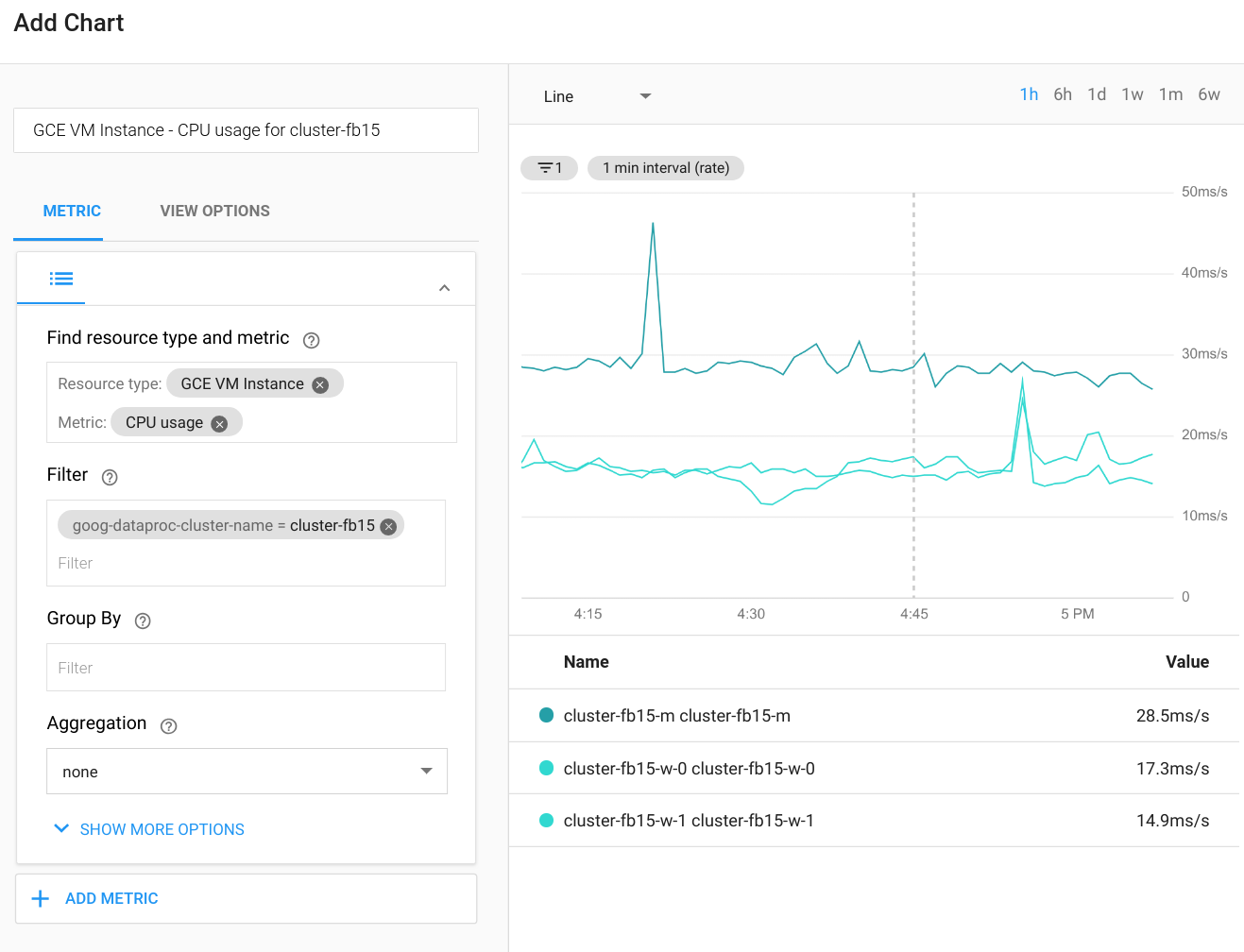
Pour afficher les métriques des requêtes, des étapes ou des tâches Spark, connectez-vous à l'interface utilisateur Web de l'application Spark. La section suivante explique comment procéder. Pour plus d'informations sur la création de métriques personnalisées, consultez le guide Métriques personnalisées de l'agent.
Accéder à YARN
Vous pouvez accéder à l'interface Web du gestionnaire de ressources YARN depuis l'extérieur du cluster Dataproc en configurant un tunnel SSH. Il est préférable d'utiliser le proxy SOCKS léger au lieu du transfert de port local, car la navigation dans l'interface Web est plus facile de cette façon.
Les URL suivantes sont utiles pour accéder à YARN :
Gestionnaire de ressources YARN :
http://[MASTER_HOST_NAME]:8088Serveur d'historique Spark :
http://[MASTER_HOST_NAME]:18080
Si le cluster Dataproc ne comporte que des adresses IP internes, vous pouvez vous connecter via une connexion VPN ou via un hôte bastion. Pour en savoir plus, consultez la page Choisir une option de connexion pour les VM internes uniquement.
Procéder au scaling et au redimensionnement des clusters Dataproc
Vous pouvez effectuer un scaling du cluster Dataproc en augmentant ou en diminuant le nombre de nœuds de calcul principaux ou secondaires (préemptifs). Dataproc est également compatible avec la mise hors service concertée.
Un certain nombre de facteurs influencent le scaling à la baisse dans Spark. Tenez compte des points suivants :
Nous vous déconseillons d'utiliser
ExternalShuffleService, en particulier si vous effectuez régulièrement un scaling à la baisse du cluster. La lecture aléatoire se sert des résultats écrits sur le disque local du nœud de calcul une fois la phase de calcul exécutée. Le nœud ne peut donc pas être supprimé, même si les ressources de calcul ne sont plus utilisées.Spark met en cache les données en mémoire (RDD et ensembles de données), et les exécuteurs employés pour la mise en cache ne se ferment jamais. Par conséquent, si un nœud de calcul sert à la mise en cache, il ne fera jamais l'objet d'une mise hors service concertée. La suppression forcée des nœuds de calcul aurait une incidence sur les performances globales, car les données mises en cache seraient perdues.
L'allocation dynamique est désactivée dans Spark Streaming par défaut, et la clé de configuration qui définit ce comportement n'est pas documentée. (vous pouvez suivre une discussion sur le comportement de l'allocation dynamique dans ce fil de discussion sur les problèmes liés à Spark). Si vous utilisez Spark Streaming ou Spark Structured Streaming, vous devez également désactiver explicitement l'allocation dynamique comme indiqué précédemment dans la section Identifier les types de tâches et planifier les clusters.
En général, nous vous recommandons d'éviter d'effectuer un scaling à la baisse d'un cluster Dataproc si vous exécutez des charges de travail par lot ou par flux.
Optimiser les performances
Cette section explique comment améliorer les performances et réduire les coûts lors de l'exécution de tâches Spark.
Gérer les tailles de fichiers Cloud Storage
Pour obtenir des performances optimales, divisez vos données Cloud Storage en fichiers d'une taille allant de 128 Mo à 1 Go. L'utilisation de nombreux petits fichiers peut créer un goulot d'étranglement. Si vous disposez d'un grand nombre de petits fichiers, envisagez de les copier pour les traiter dans le HDFS local, puis de recopier les résultats.
Passer à des disques SSD
Si vous effectuez de nombreuses opérations de lecture aléatoire ou écritures partitionnées, passez à des disques SSD pour améliorer les performances.
Placer les VM dans la même zone
Pour réduire les coûts de mise en réseau et améliorer les performances, utilisez le même emplacement régional pour les buckets Cloud Storage que pour les clusters Dataproc.
Par défaut, lorsque vous employez des points de terminaison Dataproc mondiaux ou régionaux, les VM du cluster sont placées dans la même zone (ou dans une autre zone de la même région ayant une capacité suffisante) lors de la création de celui-ci. Vous pouvez également spécifier la zone lors de la création du cluster.
Utiliser des VM préemptives
Le cluster Dataproc peut utiliser des instances de VM préemptives en tant que nœuds de calcul. Cela se traduit par des coûts de calcul par heure inférieurs pour les charges de travail non critiques par rapport à l'utilisation d'instances normales. Toutefois, vous devez prendre en compte certains facteurs lorsque vous utilisez des VM préemptives :
- Les VM préemptives ne peuvent pas être utilisées pour le stockage HDFS.
- Par défaut, les VM préemptives sont créées avec un disque de démarrage d'une plus petite taille. Vous pouvez remplacer cette configuration si vous exécutez des charges de travail très aléatoires. Pour en savoir plus, consultez la page VM préemptives dans la documentation Dataproc.
- Nous déconseillons de préempter plus de la moitié du nombre total de nœuds de calcul.
Lorsque vous utilisez des VM préemptives, nous vous recommandons d'ajuster votre configuration de cluster pour qu'elle soit plus tolérante aux échecs de tâches, car les VM risquent d'être moins disponibles. Par exemple, définissez des paramètres de ce type dans la configuration de YARN :
yarn.resourcemanager.am.max-attempts mapreduce.map.maxattempts mapreduce.reduce.maxattempts spark.task.maxFailures spark.stage.maxConsecutiveAttempts
Vous pouvez facilement ajouter ou supprimer des VM préemptives dans le cluster. Pour en savoir plus, consultez la page VM préemptives.
Étape suivante
- Consultez le guide sur la migration de l'infrastructure Hadoop sur site vers Google Cloud.
- Consultez notre description du cycle de vie d'une tâche Dataproc.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Centre d'architecture cloud.