Ce document décrit un exemple de pipeline mis en œuvre dans Google Cloud et réalisant une modélisation des tendances. Il est destiné aux ingénieurs de données, aux ingénieurs en machine learning ou aux équipes de science du marketing qui créent et déploient des modèles de machine learning. Dans ce document, nous partons du principe que vous maîtrisez les concepts de machine learning et que vous connaissez bien les Google Cloud, BigQuery, Kubeflow Pipelines, Python et les notebooks Jupyter. Il suppose également que vous comprenez Google Analytics 360 et la fonctionnalité d'exportation brute dans BigQuery.
Le pipeline avec lequel vous travaillez utilise des exemples de données Google Analytics. Le pipeline crée plusieurs modèles en utilisant BigQuery ML et XGBoost, après quoi vous exécutez le pipeline en utilisant Kubeflow Pipelines sur Vertex AI Pipelines. Ce document décrit les processus d'entraînement, d'évaluation et de déploiement des modèles. Elle explique également comment automatiser l'ensemble du processus.
Le code complet du pipeline se trouve dans un notebook Jupyter hébergé dans un dépôt GitHub.
Qu'est-ce que la modélisation des tendances ?
La modélisation des tendances prédit les actions qu'un consommateur peut effectuer. Par exemple, prédire les consommateurs les plus susceptibles d'acheter un produit, de s'inscrire à un service ou même de se désengager et ne plus être un client actif d'une marque.
La sortie d'un modèle de tendances est un score compris entre 0 et 1 pour chaque consommateur, ce score représentant la probabilité que le consommateur effectue l'action en question. L'un des principaux facteurs qui incitent les entreprises à modéliser les tendances est la nécessité de mieux exploiter les données propriétaires. Pour les cas d'utilisation marketing, les meilleurs modèles de tendances incluent des signaux provenant de sources en ligne et hors connexion, tels que des données d'analyse de site et des données CRM.
Cette démonstration utilise des exemples de données GA360 hébergés dans BigQuery. Pour votre cas d'utilisation, vous pouvez envisager d'autres signaux hors connexion.
Comment le MLOps simplifie vos pipelines de ML
La plupart des modèles de ML ne sont pas utilisés en production. Les résultats du modèle génèrent des insights. Souvent, une fois que les équipes de data science ont terminé un modèle, une équipe d'ingénieurs en ML ou d'ingénierie logicielle doit l'encapsuler dans le code en production en utilisant un framework tel que Flask ou FastAPI. Ce processus nécessite souvent de créer le modèle dans un nouveau framework, ce qui signifie que les données doivent être retransformées. Ce travail peut prendre plusieurs semaines, voire plusieurs mois, ce qui explique que la plupart des modèles ne soient jamais utilisés en production.
Les opérations de machine learning (MLOps) sont devenues importantes pour tirer profit des projets de ML, et le MLOps est désormais un ensemble de compétences en évolution pour les entreprises de data science. Pour aider les entreprises à comprendre cette valeur, Google Cloud a publié un Guide de formation au MLOps qui fournit une présentation de MLOps.
En appliquant les principes du MLOps et les directives Google Cloud, vous pouvez transférer des modèles vers un point de terminaison à l'aide d'un processus automatique qui supprime une grande partie de la complexité du processus manuel. Les outils et processus présentés dans ce document décrivent une approche permettant de contrôler votre pipeline de bout en bout, ce qui vous aide à mettre vos modèles en production. Le document du guide des professionnels mentionné précédemment fournit une solution horizontale et un aperçu des possibilités offertes par les opérations MLOps et Google Cloud.
Qu'est-ce que Kubeflow Pipelines et qu'est-ce que Vertex AI ?
Kubeflow Pipelines est un framework Open Source que vous utilisez pour créer votre pipeline.
Chaque étape du processus Kubeflow Pipelines consiste en un conteneur indépendant qui peut prendre des entrées ou produire des résultats sous la forme d'artefacts. Par exemple, si une étape du processus crée votre ensemble de données, le résultat est l'artefact d'ensemble de données. Cet artefact d'ensemble de données peut être utilisé en tant qu'entrée pour l'étape suivante. Chaque composant étant un conteneur distinct, vous devez fournir des informations pour chaque composant du pipeline, par exemple le nom de l'image de base et la liste des dépendances.
Vertex AI Pipelines vous permet d'exécuter des pipelines créés à l'aide de Kubeflow Pipelines ou de TensorFlow Extended (TFX). Sans Vertex AI, l'exécution de l'un de ces frameworks Open Source à grande échelle nécessite la configuration et la maintenance de vos propres clusters Kubernetes. Vertex AI Pipelines résout ce problème. Comme il s'agit d'un service géré, il évolue à la hausse ou à la baisse en fonction des besoins, et ne nécessite aucune maintenance continue.
Processus de compilation du pipeline
L'exemple décrit dans ce document se sert d'un notebook Juptyer pour créer les composants du pipeline et les compiler, les exécuter et les automatiser. Comme indiqué précédemment, le notebook est hébergé dans un dépôt GitHub.
Vous pouvez exécuter le code du notebook à l'aide d'une instance de notebooks gérés par l'utilisateur Vertex AI Workbench, qui gère l'authentification à votre place. Vertex AI Workbench vous permet de travailler avec des notebooks pour créer des machines, créer des notebooks et vous connecter à Git. (Vertex AI Workbench inclut de nombreuses autres fonctionnalités, mais celles-ci ne sont pas abordées dans le présent document.)
Une fois l'exécution du pipeline terminée, un diagramme semblable au suivant est généré dans Vertex AI Pipelines :
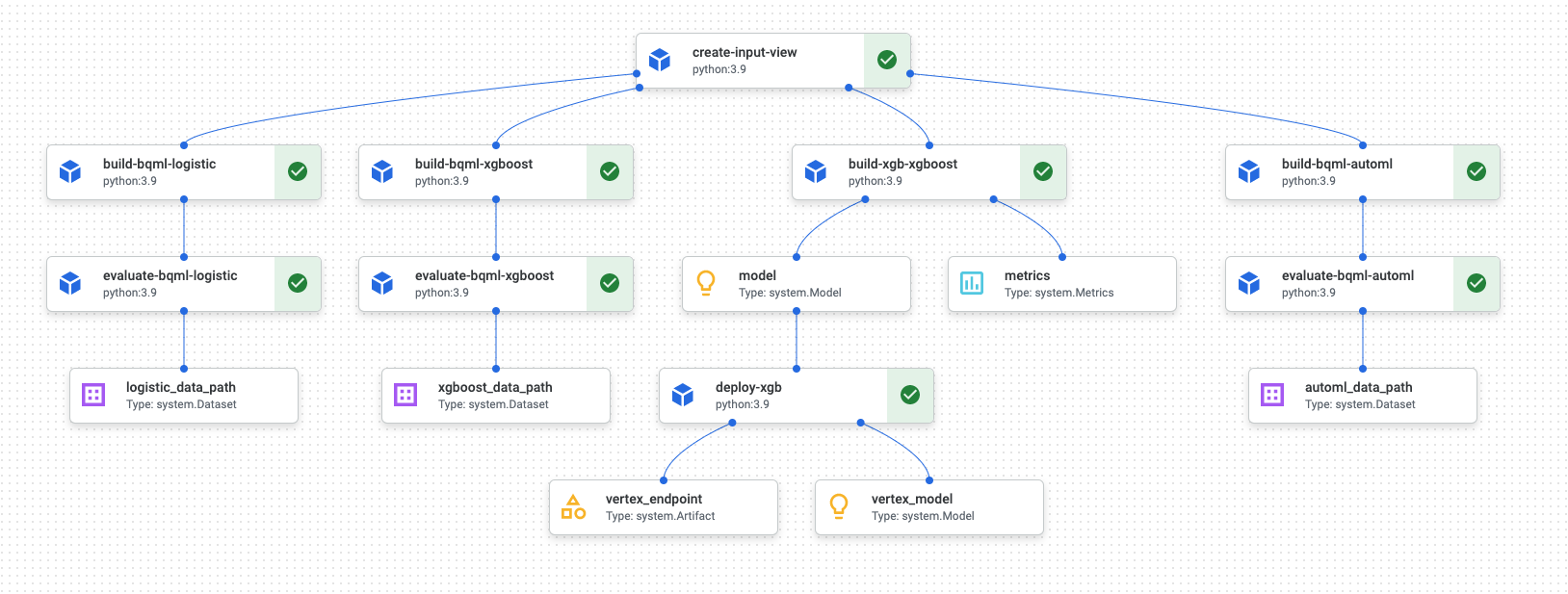
Le schéma précédent est un graphe orienté acyclique (DAG). La compilation et la vérification du DAG sont une étape centrale pour comprendre vos données ou votre pipeline de ML. Les principaux attributs des DAG sont le fait que les composants circulent dans une seule direction (dans ce cas, de haut en bas) et qu'aucun cycle ne se produit, c'est-à-dire qu'aucun composant parent ne repose pas sur son composant enfant. Certains composants peuvent s'exécuter en parallèle, tandis que d'autres ont des dépendances et s'exécutent donc en série.
La case à cocher verte de chaque composant indique que le code a été exécuté correctement. Si des erreurs se sont produites, un point d'exclamation rouge s'affiche. Vous pouvez cliquer sur chaque composant du schéma pour afficher plus de détails sur la tâche.
Le schéma du DAG est inclus dans cette section du document. Il sert de plan pour chaque composant créé par le pipeline. La liste suivante fournit une description de chaque composant :
Le pipeline complet effectue les étapes suivantes, comme illustré dans le schéma du DAG :
create-input-view: ce composant crée une vue BigQuery. Le composant copie le code SQL à partir d'un bucket Cloud Storage et renseigne les valeurs de paramètre que vous fournissez. Cette vue BigQuery est l'ensemble de données d'entrée utilisé par la suite pour tous les modèles du pipeline.build-bqml-logistic: le pipeline utilise BigQuery ML pour créer un modèle de régression logistique. Une fois ce composant terminé, un nouveau modèle est visible dans la console BigQuery. Cet objet de modèle vous permet de consulter les performances du modèle et, par la suite, de créer des prédictions.evaluate-bqml-logistic: le pipeline utilise ce composant pour créer une courbe de précision/rappel (logistic_data_pathdans le diagramme DAG) pour la régression logistique. Cet artefact est stocké dans un bucket Cloud Storage.build-bqml-xgboost: ce composant crée un modèle XGBoost en utilisant BigQuery ML. Une fois ce composant terminé, vous pouvez afficher un nouvel objet de modèle (system.Model) dans la console BigQuery. Cet objet vous permettra de consulter les performances du modèle et, par la suite, de créer des prédictions.evaluate-bqml-xgboost: ce composant crée une courbe de précision/rappel nomméexgboost_data_pathpour le modèle XGBoost. Cet artefact est stocké dans un bucket Cloud Storage.build-xgb-xgboost: le pipeline crée un modèle XGBoost. Ce composant utilise Python au lieu de BigQuery ML afin de vous permettre de découvrir différentes approches pour la création du modèle. Une fois ce composant terminé, il stocke un objet de modèle et des métriques de performances dans un bucket Cloud Storage.deploy-xgb: ce composant déploie le modèle XGBoost. Il crée un point de terminaison autorisant les prédictions par lot ou en ligne. Vous pouvez explorer le point de terminaison dans l'onglet Modèles de la page de la console Vertex AI. Le point de terminaison effectue un autoscaling en fonction du trafic.build-bqml-automl: le pipeline crée un modèle AutoML en utilisant BigQuery ML. Une fois ce composant terminé, un nouvel objet de modèle est visible dans la console BigQuery. Cet objet vous permettra de consulter les performances du modèle et, par la suite, de créer des prédictions.evaluate-bqml-automl: le pipeline crée une courbe de précision/rappel pour le modèle AutoML. L'artefact est stocké dans un bucket Cloud Storage.
Notez que le processus ne transfère pas les modèles BigQuery ML à un point de terminaison. En effet, vous pouvez générer des prédictions directement à partir de l'objet de modèle qui se trouve dans BigQuery. Lorsque vous décidez d'utiliser BigQuery ML et d'autres bibliothèques pour votre solution, réfléchissez à la façon dont les prédictions doivent être générées. Si une prédiction quotidienne par lot répond à vos besoins, rester dans l'environnement BigQuery peut simplifier votre workflow. Toutefois, si vous avez besoin de prédictions en temps réel ou si votre scénario nécessite une fonctionnalité figurant dans une autre bibliothèque, suivez les étapes décrites dans le présent document pour transférer votre modèle enregistré vers un point de terminaison.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
Notebook Jupyter associé à ce scénario
Les tâches de création et de construction du pipeline sont intégrées à un notebook Jupyter situé dans un dépôt GitHub.
Pour effectuer les tâches, vous obtenez le notebook, puis vous exécutez les cellules de code dans le notebook, dans l'ordre indiqué. Le flux décrit dans ce document suppose que vous exécutez les notebooks dans Vertex AI Workbench.
Ouvrir l'environnement Vertex AI Workbench
Commencez par cloner le dépôt GitHub dans un environnement Vertex AI Workbench.
- Dans la console Google Cloud, sélectionnez le projet dans lequel vous souhaitez créer le notebook.
Accédez à la page Vertex AI Workbench.
Dans l'onglet Notebooks gérés par l'utilisateur, cliquez sur Nouveau notebook.
Dans la liste des types de notebooks, choisissez un notebook Python 3.
Dans la boîte de dialogue Nouveau notebook, cliquez sur Options avancées, puis, sous Type de machine, sélectionnez le type de machine que vous souhaitez utiliser. En cas de doute, choisissez n1-standard-1 (1 vCPU, 3,75 Go de RAM).
Cliquez sur Create (Créer).
La création de l'environnement de notebook prend quelques instants.
Une fois le notebook créé, sélectionnez-le, puis cliquez sur Ouvrir JupyterLab.
L'environnement JupyterLab s'ouvre dans votre navigateur.
Pour ouvrir un onglet de terminal, sélectionnez Fichier > Nouveau > Lanceur d'applications.
Cliquez sur l'icône Terminal dans l'onglet Lanceur d'applications.
Dans le terminal, clonez le dépôt GitHub
mlops-on-gcp:git clone https://github.com/GoogleCloudPlatform/cloud-for-marketing/
Une fois la commande terminée, le dossier
cloud-for-marketings'affiche dans le navigateur de fichiers.
Configurer les paramètres des notebooks
Avant d'exécuter le notebook, vous devez le configurer. Le notebook nécessite un bucket Cloud Storage pour stocker les artefacts de pipeline. Vous devez donc commencer par créer ce bucket.
- Créez un bucket Cloud Storage dans lequel le notebook peut stocker des artefacts de pipeline. Le nom du bucket doit être globalement unique.
- Dans le dossier
cloud-for-marketing/marketing-analytics/predicting/kfp_pipeline/, ouvrez le notebookPropensity_Pipeline.ipynb. - Dans le notebook, définissez la valeur de la variable
PROJECT_IDsur l'ID du projet Google Cloud dans lequel vous souhaitez exécuter le pipeline. - Définissez la valeur de la variable
BUCKET_NAMEsur le nom du bucket que vous venez de créer.
La suite du présent document présente les extraits de code importants pour comprendre le fonctionnement du pipeline. Pour obtenir la mise en œuvre complète, consultez le dépôt GitHub.
Créer la vue BigQuery
La première étape du pipeline génère les données d'entrée, qui seront utilisées pour créer chaque modèle. Ce composant Kubeflow Pipelines génère une vue BigQuery. Pour simplifier le processus de création de la vue, du code SQL a déjà été généré et enregistré dans un fichier texte dans GitHub.
Le code de chaque composant commence par la décoration (modification d'une classe parente ou d'une fonction via des attributs) de la classe de composant Kubeflow Pipelines. Le code définit ensuite la fonction create_input_view, qui est une étape dans le pipeline.
La fonction nécessite plusieurs entrées. Certaines de ces valeurs sont actuellement codées en dur dans le code, comme la date de début et la date de fin. Lorsque vous automatisez votre pipeline, vous pouvez modifier le code pour utiliser des valeurs appropriées (par exemple, en utilisant la fonction CURRENT_DATE pour obtenir une date), Vous pouvez également mettre à jour le composant pour utiliser ces valeurs en tant que paramètres plutôt que de les conserver en dur. Vous devez également remplacer la valeur de ga_data_ref par le nom de votre table GA360 et définir la valeur de la variable conversion sur votre conversion. (Cet exemple utilise les exemples de données GA360 publiques.)
La liste suivante affiche le code du composant create-input-view.
@component(
# this component builds a BigQuery view, which will be the underlying source for model
packages_to_install=["google-cloud-bigquery", "google-cloud-storage"],
base_image="python:3.9",
output_component_file="output_component/create_input_view.yaml",
)
def create_input_view(view_name: str,
data_set_id: str,
project_id: str,
bucket_name: str,
blob_path: str
):
from google.cloud import bigquery
from google.cloud import storage
client = bigquery.Client(project=project_id)
dataset = client.dataset(data_set_id)
table_ref = dataset.table(view_name)
ga_data_ref = 'bigquery-public-data.google_analytics_sample.ga_sessions_*'
conversion = "hits.page.pageTitle like '%Shopping Cart%'"
start_date = '20170101'
end_date = '20170131'
def get_sql(bucket_name, blob_path):
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blob = bucket.get_blob(blob_path)
content = blob.download_as_string()
return content
def if_tbl_exists(client, table_ref):
...
else:
content = get_sql()
content = str(content, 'utf-8')
create_base_feature_set_query = content.
format(start_date = start_date,
end_date = end_date,
ga_data_ref = ga_data_ref,
conversion = conversion)
shared_dataset_ref = client.dataset(data_set_id)
base_feature_set_view_ref = shared_dataset_ref.table(view_name)
base_feature_set_view = bigquery.Table(base_feature_set_view_ref)
base_feature_set_view.view_query = create_base_feature_set_query.format(project_id)
base_feature_set_view = client.create_table(base_feature_set_view)
Créer le modèle BigQuery ML
Une fois la vue créée, vous exécutez le composant nommé build_bqml_logistic pour créer un modèle BigQuery ML. Ce bloc du notebook est un composant essentiel. La vue d'entraînement que vous avez créée dans le premier bloc vous permet de créer un modèle BigQuery ML. Dans cet exemple, le notebook utilise la régression logistique.
Pour plus d'informations sur les types de modèle et les hyperparamètres disponibles, consultez la documentation de référence de BigQuery ML.
La liste suivante indique le code pour ce composant.
@component(
# this component builds a logistic regression with BigQuery ML
packages_to_install=["google-cloud-bigquery"],
base_image="python:3.9",
output_component_file="output_component/create_bqml_model_logistic.yaml"
)
def build_bqml_logistic(project_id: str,
data_set_id: str,
model_name: str,
training_view: str
):
from google.cloud import bigquery
client = bigquery.Client(project=project_id)
model_name = f"{project_id}.{data_set_id}.{model_name}"
training_set = f"{project_id}.{data_set_id}.{training_view}"
build_model_query_bqml_logistic = '''
CREATE OR REPLACE MODEL `{model_name}`
OPTIONS(model_type='logistic_reg'
, INPUT_LABEL_COLS = ['label']
, L1_REG = 1
, DATA_SPLIT_METHOD = 'RANDOM'
, DATA_SPLIT_EVAL_FRACTION = 0.20
) AS
SELECT * EXCEPT (fullVisitorId, label),
CASE WHEN label is null then 0 ELSE label end as label
FROM `{training_set}`
'''.format(model_name = model_name, training_set = training_set)
job_config = bigquery.QueryJobConfig()
client.query(build_model_query_bqml_logistic, job_config=job_config)
Utiliser XGBoost au lieu de BigQuery ML
Le composant illustré dans la section précédente utilise BigQuery ML. La section suivante des notebooks vous explique comment utiliser XGBoost directement dans Python au lieu d'utiliser BigQuery ML.
Vous exécutez le composant nommé build_bqml_xgboost pour le créer afin d'exécuter un modèle de classification XGBoost standard avec une recherche de grille. Le code enregistre ensuite le modèle en tant qu'artefact dans le bucket Cloud Storage que vous avez créé.
La fonction accepte des paramètres supplémentaires (metrics et model) pour les artefacts de sortie. Ces paramètres sont requis par Kubeflow Pipelines.
@component(
# this component builds an xgboost classifier with xgboost
packages_to_install=["google-cloud-bigquery", "xgboost", "pandas", "sklearn", "joblib", "pyarrow"],
base_image="python:3.9",
output_component_file="output_component/create_xgb_model_xgboost.yaml"
)
def build_xgb_xgboost(project_id: str,
data_set_id: str,
training_view: str,
metrics: Output[Metrics],
model: Output[Model]
):
...
data_set = f"{project_id}.{data_set_id}.{training_view}"
build_df_for_xgboost = '''
SELECT * FROM `{data_set}`
'''.format(data_set = data_set)
...
xgb_model = XGBClassifier(n_estimators=50,
objective='binary:hinge',
silent=True,
nthread=1,
eval_metric="auc")
random_search = RandomizedSearchCV(xgb_model,
param_distributions=params,
n_iter=param_comb,
scoring='precision',
n_jobs=4,
cv=skf.split(X_train,y_train),
verbose=3,
random_state=1001 )
random_search.fit(X_train, y_train)
xgb_model_best = random_search.best_estimator_
predictions = xgb_model_best.predict(X_test)
score = accuracy_score(y_test, predictions)
auc = roc_auc_score(y_test, predictions)
precision_recall = precision_recall_curve(y_test, predictions)
metrics.log_metric("accuracy",(score * 100.0))
metrics.log_metric("framework", "xgboost")
metrics.log_metric("dataset_size", len(df))
metrics.log_metric("AUC", auc)
dump(xgb_model_best, model.path + ".joblib")
Créer un point de terminaison
Vous exécutez le composant nommé deploy_xgb pour créer un point de terminaison en utilisant le modèle XGBoost de la section précédente. Le composant prend l'artefact de modèle XGBoost précédent, crée un conteneur, puis déploie le point de terminaison, tout en fournissant l'URL du point de terminaison en tant qu'artefact afin que vous puissiez l'afficher. Une fois cette étape terminée, un point de terminaison Vertex AI a été créé et vous pouvez l'afficher sur la page de console de Vertex AI.
@component(
# Deploys xgboost model
packages_to_install=["google-cloud-aiplatform", "joblib", "sklearn", "xgboost"],
base_image="python:3.9",
output_component_file="output_component/xgboost_deploy_component.yaml",
)
def deploy_xgb(
model: Input[Model],
project_id: str,
vertex_endpoint: Output[Artifact],
vertex_model: Output[Model]
):
from google.cloud import aiplatform
aiplatform.init(project=project_id)
deployed_model = aiplatform.Model.upload(
display_name="tai-propensity-test-pipeline",
artifact_uri = model.uri.replace("model", ""),
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-4:latest"
)
endpoint = deployed_model.deploy(machine_type="n1-standard-4")
# Save data to the output params
vertex_endpoint.uri = endpoint.resource_name
vertex_model.uri = deployed_model.resource_name
Définir le pipeline
Pour définir le pipeline, vous devez définir chaque opération en fonction des composants que vous avez créés précédemment. Vous pouvez ensuite spécifier l'ordre des éléments du pipeline s'ils ne sont pas explicitement appelés dans le composant.
Par exemple, le code suivant dans le notebook définit un pipeline. Dans ce cas, le code nécessite l'exécution du composant build_bqml_logistic_op après le composant create_input_view_op.
@dsl.pipeline(
# Default pipeline root. You can override it when submitting the pipeline.
pipeline_root=PIPELINE_ROOT,
# A name for the pipeline.
name="pipeline-test",
description='Propensity BigQuery ML Test'
)
def pipeline():
create_input_view_op = create_input_view(
view_name = VIEW_NAME,
data_set_id = DATA_SET_ID,
project_id = PROJECT_ID,
bucket_name = BUCKET_NAME,
blob_path = BLOB_PATH
)
build_bqml_logistic_op = build_bqml_logistic(
project_id = PROJECT_ID,
data_set_id = DATA_SET_ID,
model_name = 'bqml_logistic_model',
training_view = VIEW_NAME
)
# several components have been deleted for brevity
build_bqml_logistic_op.after(create_input_view_op)
build_bqml_xgboost_op.after(create_input_view_op)
build_bqml_automl_op.after(create_input_view_op)
build_xgb_xgboost_op.after(create_input_view_op)
evaluate_bqml_logistic_op.after(build_bqml_logistic_op)
evaluate_bqml_xgboost_op.after(build_bqml_xgboost_op)
evaluate_bqml_automl_op.after(build_bqml_automl_op)
Compiler et exécuter le pipeline
Vous pouvez maintenant compiler et exécuter le pipeline.
Le code suivant du notebook définit la valeur enable_caching sur "true" afin d'activer la mise en cache. Lorsque la mise en cache est activée, aucune exécution précédente de composant n'est exécutée à nouveau si elle a abouti. Cette option est utile, notamment lorsque vous testez le pipeline, car l'exécution est plus rapide et utilise moins de ressources lorsque la mise en cache est activée.
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="pipeline.json"
)
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
run = pipeline_jobs.PipelineJob(
display_name="test-pipeine",
template_path="pipeline.json",
job_id="test-{0}".format(TIMESTAMP),
enable_caching=True
)
run.run()
Automatiser le pipeline
À ce stade, vous avez lancé le premier pipeline. Vous pouvez consulter la page Vertex AI Pipelines de la console pour afficher l'état de cette tâche. Vous pouvez surveiller la création et l'exécution de chaque conteneur. Vous pouvez également cliquer sur les erreurs correspondantes pour suivre les erreurs de composants spécifiques de cette section.
Pour planifier le pipeline, vous devez créer une fonction Cloud et utiliser un programmeur semblable à une tâche Cron.
Le code de la dernière section du notebook planifie l'exécution du pipeline une fois par jour, comme indiqué dans l'extrait de code suivant :
from kfp.v2.google.client import AIPlatformClient
api_client = AIPlatformClient(project_id=PROJECT_ID,
region='us-central1'
)
api_client.create_schedule_from_job_spec(
job_spec_path='pipeline.json',
schedule='0 * * * *',
enable_caching=False
)
Utiliser le pipeline terminé en production
Le pipeline terminé a effectué les tâches suivantes :
- Vous avez créé un ensemble de données d'entrée.
- Vous avez entraîné plusieurs modèles à l'aide de BigQuery ML et de XGBoost pour Python.
- Vous avez analysé les résultats du modèle.
- Vous avez déployé le modèle XGBoost.
Vous avez également automatisé le pipeline à l'aide de Cloud Functions et de Cloud Scheduler pour une exécution quotidienne.
Le pipeline défini dans le notebook a été créé pour illustrer la création de différents modèles. Vous n'exécuteriez pas le pipeline tel qu'il est actuellement construit dans un scénario de production. Toutefois, vous pouvez utiliser ce pipeline comme guide et modifier les composants en fonction de vos besoins. Par exemple, vous pouvez modifier le processus de création de caractéristiques pour tirer parti de vos données, modifier les plages de dates et éventuellement créer d'autres modèles. Vous devriez également choisir, parmi ceux illustrés, le modèle qui répond le mieux à vos exigences de production.
Lorsque le pipeline est prêt pour la production, vous pouvez mettre en œuvre des tâches supplémentaires. Par exemple, vous pouvez mettre en œuvre un modèle champion/challenger dans lequel un nouveau modèle est créé chaque jour, le nouveau modèle (le challenger) et le modèle existant (le champion) étant évalués en utilisant de nouvelles données. Vous ne passez le nouveau modèle en production que si ses performances sont supérieures à celles du modèle actuel. Pour surveiller la progression de votre système, vous pouvez également conserver un enregistrement des performances quotidiennes du modèle et visualiser les tendances de performances.
Étape suivante
- Pour savoir comment utiliser le MLOps pour créer des systèmes de ML prêts pour la production, consultez le Guide du MLOps.
- Pour en savoir plus sur Vertex AI, consultez la documentation sur Vertex AI.
- Pour en savoir plus sur Kubeflow Pipelines, consultez la documentation KFP.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.