本教程演示了如何使用 Dataflow 从联机事务处理 (OLTP) 关系型数据库中提取、转换和加载 (ETL) 数据到 BigQuery 以进行分析。
本教程适用于对 BigQuery 的分析查询功能和 Dataflow 的批处理功能感兴趣的数据库管理员、运维专业人员和云架构师。
OLTP 数据库通常是关系型数据库,用于为电子商务网站、软件即服务 (SaaS) 应用或游戏等存储信息和流程事务。OLTP 数据库通常针对需要 ACID 属性的事务进行了优化:原子性、一致性、隔离性及耐用性,并且通常具有高度规范化的架构。相比之下,数据仓库往往经过优化以用于数据检索和分析,而不是事务,且通常具有反规范化的架构。通常,对 OLTP 数据库中的数据进行反规范化会使其更适用于 BigQuery 中的分析。
目标
本教程展示了两种执行 ETL 以将规范化 RDBMS 数据转换为反规范化 BigQuery 数据的方法:
- 使用 BigQuery 来加载和转换数据。使用此方法可将少量数据一次性加载到 BigQuery 中进行分析。在对大型或多个数据集使用自动化之前,您也可以使用此方法对数据集进行原型设计。
- 使用 Dataflow 来加载、转换和清理数据。使用此方法可以加载大量数据、从多个数据源加载数据,或者以增量方式或自动加载数据。
费用
在本文档中,您将使用 Google Cloud 的以下收费组件:
您可使用价格计算器根据您的预计使用情况来估算费用。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备工作
- 登录您的 Google Cloud 账号。如果您是 Google Cloud 新手,请创建一个账号来评估我们的产品在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
-
启用 Compute Engine 和 Dataflow API。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
-
启用 Compute Engine 和 Dataflow API。
使用 MusicBrainz 数据集
本教程依赖于 MusicBrainz 数据库中表的 JSON 快照,该数据库基于 PostgreSQL 构建,包含有关所有 MusicBrainz 音乐的信息。MusicBrainz 架构包含的一些元素如下:
- 音乐人
- 发行组
- 发行版本
- 录制内容
- 作品
- 标签
- 这些实体之间的许多关系。
MusicBrainz 架构包括三个相关的表:artist、recording 和 artist_credit_name。artist_credit 表示参与某个录制内容表演的音乐人,而 artist_credit_name 表中的行通过 artist_credit 值将录制内容与其对应的音乐人关联。
本教程提供的 PostgreSQL 表已经提取为以换行符分隔的 JSON 格式并存储在公共 Cloud Storage 存储桶中:gs://solutions-public-assets/bqetl。
如果想要自行执行此步骤,您需要拥有一个包含 MusicBrainz 数据集的 PostgreSQL 数据库,并使用以下命令导出每个表:
host=POSTGRES_HOST
user=POSTGRES_USER
database=POSTGRES_DATABASE
for table in artist recording artist_credit_name
do
pg_cmd="\\copy (select row_to_json(r) from (select * from ${table}) r ) to exported_${table}.json"
psql -w -h ${host} -U ${user} -d ${db} -c $pg_cmd
# clean up extra '\' characters
sed -i -e 's/\\\\/\\/g' exported_${table}.json
done
方法 1:使用 BigQuery 执行 ETL
使用此方法可将少量数据一次性加载到 BigQuery 中进行分析。在对大型或多个数据集使用自动化之前,您也可以使用此方法对数据集进行原型设计。
创建 BigQuery 数据集
如需创建 BigQuery 数据集,请分别将各个 MusicBrainz 表加载到 BigQuery 中,然后联接加载的表,使每一行都包含您想要的数据关联。您将联接结果存储在新的 BigQuery 表格中。然后,您可以删除加载的原始表。
在 Google Cloud 控制台中,打开 BigQuery。
在探索器面板中,点击项目名称旁边的菜单 more_vert,然后点击创建数据集。
在创建数据集对话框中,完成以下步骤:
- 在数据集 ID 字段中,输入
musicbrainz。 - 将数据位置设置为 us。
- 点击创建数据集。
- 在数据集 ID 字段中,输入
导入 MusicBrainz 表
对于每个 MusicBrainz 表,请执行以下步骤将表添加到您创建的数据集中:
- 在 Google Cloud 控制台的 BigQuery 探索器面板中,展开您的项目名称所在的行以显示新创建的
musicbrainz数据集。 - 点击
musicbrainz数据集旁边的菜单 more_vert,然后点击创建表。 在创建数据集对话框中,完成以下步骤:
- 在基于以下数据创建表下拉列表中,选择 Google Cloud Storage。
在从 GCS 存储桶中选择文件字段中,输入数据文件的路径:
solutions-public-assets/bqetl/artist.json在文件格式部分中,选择 JSONL(以换行符分隔的 JSON)。
确保项目包含您的项目名称。
确保数据集为
musicbrainz。对于表,输入表名称
artist。在表类型中,使原生表处于选中状态。
在架构部分下方,点击以开启以文本形式修改。
下载
artist架构文件并在文本编辑器或查看器中打开它。将架构部分的内容替换为您下载的架构文件的内容。
点击创建表:
等待加载作业完成。
加载完成后,新表将显示在数据集下。
重复第 1 步到第 5 步,以创建包含以下更改的
artist_credit_name表:为源数据文件使用以下路径:
solutions-public-assets/bqetl/artist_credit_name.json使用
artist_credit_name作为表名称。下载
artist_credit_name架构文件并使用该架构的内容。
重复第 1 步到第 5 步,以创建包含以下更改的
recording表:为源数据文件使用以下路径:
solutions-public-assets/bqetl/recording.json使用
recording作为表名称。下载
recording架构文件,并使用该架构的内容。
手动对数据进行反规范化
为了对数据进行反规范化,请将数据联接到一个新的 BigQuery 表格中,该表中每位音乐人的每一条录制内容各占一行,并且包括您希望保留用于分析的选定元数据。
- 如果 BigQuery 查询编辑器未在 Google Cloud 控制台中打开,请点击 add_box 编写新查询。
复制以下查询并将其粘贴到查询编辑器中:
SELECT artist.id, artist.gid AS artist_gid, artist.name AS artist_name, artist.area, recording.name AS recording_name, recording.length, recording.gid AS recording_gid, recording.video FROM `musicbrainz.artist` AS artist INNER JOIN `musicbrainz.artist_credit_name` AS artist_credit_name ON artist.id = artist_credit_name.artist INNER JOIN `musicbrainz.recording` AS recording ON artist_credit_name.artist_credit = recording.artist_credit点击 settings 更多下拉列表,然后选择查询设置。
在查询设置对话框中,完成以下步骤:
- 选择为查询结果设置目标表。
- 在数据集中,输入
musicbrainz并选择项目中的数据集。 - 在表 ID 中,输入
recordings_by_artists_manual。 - 对于目标表的写入设置,点击覆盖表。
- 选中允许大型结果(无大小限制)复选框。
- 点击保存。
点击 play_circle_filled 运行。
查询完成后,查询结果数据在新创建的 BigQuery 表格中按照每位音乐人的歌曲进行组织,并在查询结果中显示结果示例,例如:
行 id artist_gid artist_name area recording_name length recording_gid video 1 97546 125ec42a... unknown 240 Horo Gun Toireamaid Hùgan Fhathast Air 174106 c8bbe048... FALSE 2 266317 2e7119b5... Capella Istropolitana 189 Concerto Grosso in D minor, op. 2 no. 3: II. Adagio 134000 af0f294d... FALSE 3 628060 34cd3689... Conspirare 5196 Liturgy, op. 42: 9. Praise the Lord from the Heavens 126933 8bab920d... FALSE 4 423877 54401795... Boys Air Choir 1178 Nunc Dimittis 190000 111611eb... FALSE 5 394456 9914f9f9... L’Orchestre de la Suisse Romande 23036 Concert Waltz no. 2, op. 51 509960 b16742d1... FALSE
方法 2:使用 Dataflow 执行 ETL 以转到 BigQuery
在本教程的这一部分中,您将使用示例程序通过 Dataflow 流水线将数据加载到 BigQuery 中,而不是使用 BigQuery 界面。然后使用 Beam 编程模型对数据进行反规范化和清理,以便加载到 BigQuery 中。
开始之前,请查看相关概念和示例代码。
查看概念
虽然本例中的数据规模很小并且可以使用 BigQuery 界面快速上传,但在本教程中,您也可以使用 Dataflow 执行 ETL。当您执行大规模联接时,使用 Dataflow 而非 BigQuery 界面来执行 ETL 以转到 BigQuery,大规模联接是指处理约有 500-5000 列、超过 10 TB 的数据以完成以下目标:
- 您希望在数据加载到 BigQuery 之后便进行清理或转换,而不是存储数据并在存储之后进行联接。因此,使用此方法还具有较低的存储要求,因为数据只会以联接和转换状态存储在 BigQuery 中。
- 您计划进行自定义数据清理(不能只通过 SQL 来实现)。
- 您计划在加载过程中将该数据与 OLTP 外部的数据(例如日志或远程访问的数据)组合在一起。
- 您计划使用持续集成或持续部署 (CI/CD) 来实现数据加载逻辑的测试和部署自动化。
- 您期望随着时间的推移逐步迭代和增强/改进 ETL 流程。
- 您计划以增量方式添加数据,而不是执行一次性 ETL。
以下是示例程序创建的数据流水线图表:

在示例代码中,许多流水线步骤被分组或封装到简便方法中,给定描述性名称,并重复使用。在以上图表中,重复使用的步骤由虚线框起。
查看流水线代码
此代码创建一个执行以下步骤的流水线:
将您要在联接中使用的每个表从公共 Cloud Storage 存储桶加载到字符串的
PCollection集合中。每个元素包含表中以 JSON 表示的一行。将这些 JSON 字符串转换为
MusicBrainzDataObject对象的表示形式,然后通过其中一个列值(如主键或外键)组织对象表示形式。根据共同音乐人联接列表。
artist_credit_name将音乐人团队与其录制内容进行关联,并包含音乐人外键。artist_credit_name表作为键值KV对象列表进行加载。K成员为音乐人。使用
MusicBrainzTransforms.innerJoin()方法联接列表。- 按要联接的键成员对
KV对象的集合进行分组。这会生成带有长键(artist.id列值)的KV对象的PCollection,并生成CoGbkResult(代表根据键结果合并分组)。CoGbkResult对象是对象列表的元组,其具有第一和第二个PCollections集合的共同键值。在运行group方法中的CoGroupByKey操作之前,该元组通过为每个PCollection配制的 Tuple 标记可以进行寻址。 将每个对象匹配合并到表示联接结果的
MusicBrainzDataObject对象中。将集合重新组织为
KV对象列表以开始下一次联接。此时,K值为artist_credit列,用于联接录制内容表。将结果与按
MusicBrainzDataObject组织的已加载的录制内容集合进行联接,获得artist_credit.id对象的最终生成集合。将生成的
MusicBrainzDataObjects对象映射到TableRows。将生成的
TableRows写入 BigQuery。
- 按要联接的键成员对
如需详细了解 Beam 流水线编程机制,请参阅以下有关编程模型的主题:
在查看完代码执行的步骤后,您可以运行流水线。
创建 Cloud Storage 存储桶
运行流水线代码
在 Google Cloud Console 中,打开 Cloud Shell。
设置项目和流水线脚本的环境变量
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow export DATASET=musicbrainz将 PROJECT_ID 替换为 Google Cloud 项目的项目 ID。
确保
gcloud正在使用您在本教程开头部分创建或选择的项目:gcloud config set project $PROJECT_ID遵循最小权限安全原则,为 Dataflow 流水线创建服务账号,并仅授予其所需的权限:
musicbrainz数据集上的roles/dataflow.worker、roles/bigquery.jobUser和dataEditor角色:gcloud iam service-accounts create musicbrainz-dataflow export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.com gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member=serviceAccount:${SERVICE_ACCOUNT} \ --role=roles/dataflow.worker gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member=serviceAccount:${SERVICE_ACCOUNT} \ --role=roles/bigquery.jobUser bq query --use_legacy_sql=false \ "GRANT \`roles/bigquery.dataEditor\` ON SCHEMA musicbrainz TO 'serviceAccount:${SERVICE_ACCOUNT}'"为 Dataflow 流水线创建一个存储桶以用于临时文件,并向其授予
musicbrainz-dataflow服务账号的Owner权限:export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} gsutil mb -l us ${DATAFLOW_TEMP_BUCKET} gsutil acl ch -u ${SERVICE_ACCOUNT}:O ${DATAFLOW_TEMP_BUCKET}克隆包含 Dataflow 代码的代码库:
git clone https://github.com/GoogleCloudPlatform/bigquery-etl-dataflow-sample.git切换到示例目录:
cd bigquery-etl-dataflow-sample编译并运行 Dataflow 作业:
./run.sh simple运行该作业大约需要 10 分钟时间。
如需查看流水线的进度,请在 Google Cloud 控制台中进入 Dataflow 页面。
作业的状态显示在状态列中。状态为成功表示作业已完成。
(可选)如需查看作业图表并详细了解步骤,请点击作业名称(例如
etl-into-bigquery-bqetlsimple)。作业完成后,进入 BigQuery 页面。
如需在新表上运行查询,请在查询编辑器窗格中输入以下内容:
SELECT artist_name, artist_gender, artist_area, recording_name, recording_length FROM musicbrainz.recordings_by_artists_dataflow WHERE artist_area is NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;结果窗格将显示一组结果,如下所示:
行 artist_name artist_gender artist_area recording_name recording_length 1 mirin 2 107 Sylphia 264000 2 mirin 2 107 Dependence 208000 3 Gaudiburschen 1 81 Die Hände zum Himmel 210000 4 Sa4 1 331 Ein Tag aus meiner Sicht 221000 5 Dpat 1 7326 Cutthroat 249000 6 Dpat 1 7326 Deloused 178000 实际输出可能会有所不同,因为结果未排序。
清理数据
接下来,请对 Dataflow 流水线稍做更改,以便您可以加载对照表并将其作为辅助输入进行处理,如下图所示。

当您查询生成的 BigQuery 表时,如果不手动查找 MusicBrainz 数据库的 area 表中的区域数字 ID,则很难确定音乐人来自哪里。这会使得分析查询结果变得复杂。
同样,音乐人性别也显示为 ID,但整个 MusicBrainz 性别表仅包含三行。为了解决此问题,您可以在 Dataflow 流水线中添加一个步骤,以使用 MusicBrainz area 和 gender 表将 ID 映射到其正确的标签。
artist_area 和 artist_gender 表包含的行数明显少于音乐人或录制内容数据表。后续表中的元素数量分别受到地理区域数量或性别数量的限制。
因此,查找步骤会使用称为辅助输入的 Dataflow 功能。
辅助输入作为按行分隔的 JSON 文件(在包含 Musicbrainz 数据集的公开 Cloud Storage 存储桶中)的表导出,并且可通过一个步骤用来对表数据进行反规范化。
查看用于向流水线添加辅助输入的代码
在运行流水线之前,请查看代码以便深入了解新步骤。
此代码演示了如何使用辅助输入进行数据清理。MusicBrainzTransforms 类为使用辅助输入将外键值映射到标签提供了更多便利。MusicBrainzTransforms 库提供了一种创建内部查找类的方法。该查找类的作用是描述每个对照表以及用标签和可变长度参数替换的字段。keyKey 是包含查找键的列名,valueKey 是包含对应标签的列名。
每个辅助输入都作为单个映射对象进行加载,用于查找 ID 的对应标签。
首先,对照表的 JSON 最初加载到具有空命名空间的 MusicBrainzDataObjects,然后转换为从 Key 列值到 Value 列值的映射。
所有这些 Map 对象都通过其 destinationKey(该键将替换为查找值)的值加入一个 Map。
然后,在从 JSON 转换音乐人对象时,destinationKey 的值(以数字开头)将替换为其标签。
如需添加 artist_area 和 artist_gender 字段的解码,请完成以下步骤:
在 Cloud Shell 中,确保为流水线脚本设置了环境:
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow_sideinputs export DATASET=musicbrainz export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.com将 PROJECT_ID 替换为 Google Cloud 项目的项目 ID。
运行流水线以创建具有解码区域和音乐人性别的表:
./run.sh simple-with-lookups和之前一样,要查看流水线的进度,请进入 Dataflow 页面。
流水线将需要约 10 分钟才能完成。
作业完成后,进入 BigQuery 页面。
执行包含
artist_area和artist_gender的相同查询:SELECT artist_name, artist_gender, artist_area, recording_name, recording_length FROM musicbrainz.recordings_by_artists_dataflow_sideinputs WHERE artist_area is NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;在输出中,
artist_area和artist_gender现在已解码:行 artist_name artist_gender artist_area recording_name recording_length 1 mirin Female Japan Sylphia 264000 2 mirin Female Japan Dependence 208000 3 Gaudiburschen Male Germany Die Hände zum Himmel 210000 4 Sa4 Male Hamburg Ein Tag aus meiner Sicht 221000 5 Dpat Male Houston Cutthroat 249000 6 Dpat Male Houston Deloused 178000 实际输出可能会有所不同,因为结果未排序。
优化 BigQuery 架构
在本教程的最后一部分,您将运行一个流水线,该流水线会使用嵌套字段生成更优化的表架构。
请花点时间查看用于生成该表这一优化版本的代码。
下图展示了一个稍有不同的 Dataflow 流水线,它将音乐人的录制内容嵌套在每个音乐人行中,而不是创建重复的音乐人行。

数据的当前表示形式呈展平状态。也就是说,每个记录的录制内容对应一行,其中包括来自 BigQuery 架构的所有音乐人的元数据,以及所有录制内容和 artist_credit_name 元数据。这种展平化表示形式至少有两个缺点:
- 它会为每个记入音乐人的录制内容重复
artist元数据,这会增加所需的存储空间。 - 当您将数据导出为 JSON 时,它会导出重复该数据的数组,而不是具有嵌套录制内容数据的音乐人,但后者可能才是您想要的结果。
在没有任何性能损失且不使用额外存储空间的情况下,您可以通过对 Dataflow 流水线进行一些更改,将录制内容存储为每个音乐人记录中的重复字段,而不是每行存储一个录制内容。
流水线不是通过 artist_credit_name.artist 将录制内容与音乐人信息进行联接,而是在音乐人对象中创建嵌套的录制内容列表。
执行批量插入操作时,BigQuery API 的行大小上限为 100 MB,流式插入上限为 10 MB,因此代码会将给定记录的嵌套录制内容数量限制为 1,000 个元素,以确保不会达到此限制。如果给定的音乐人拥有超过 1,000 个录制内容,则代码将复制该行(包括 artist 元数据),并继续将录制内容数据嵌套在复制行中。
下图显示了流水线的来源、转换和接收器。
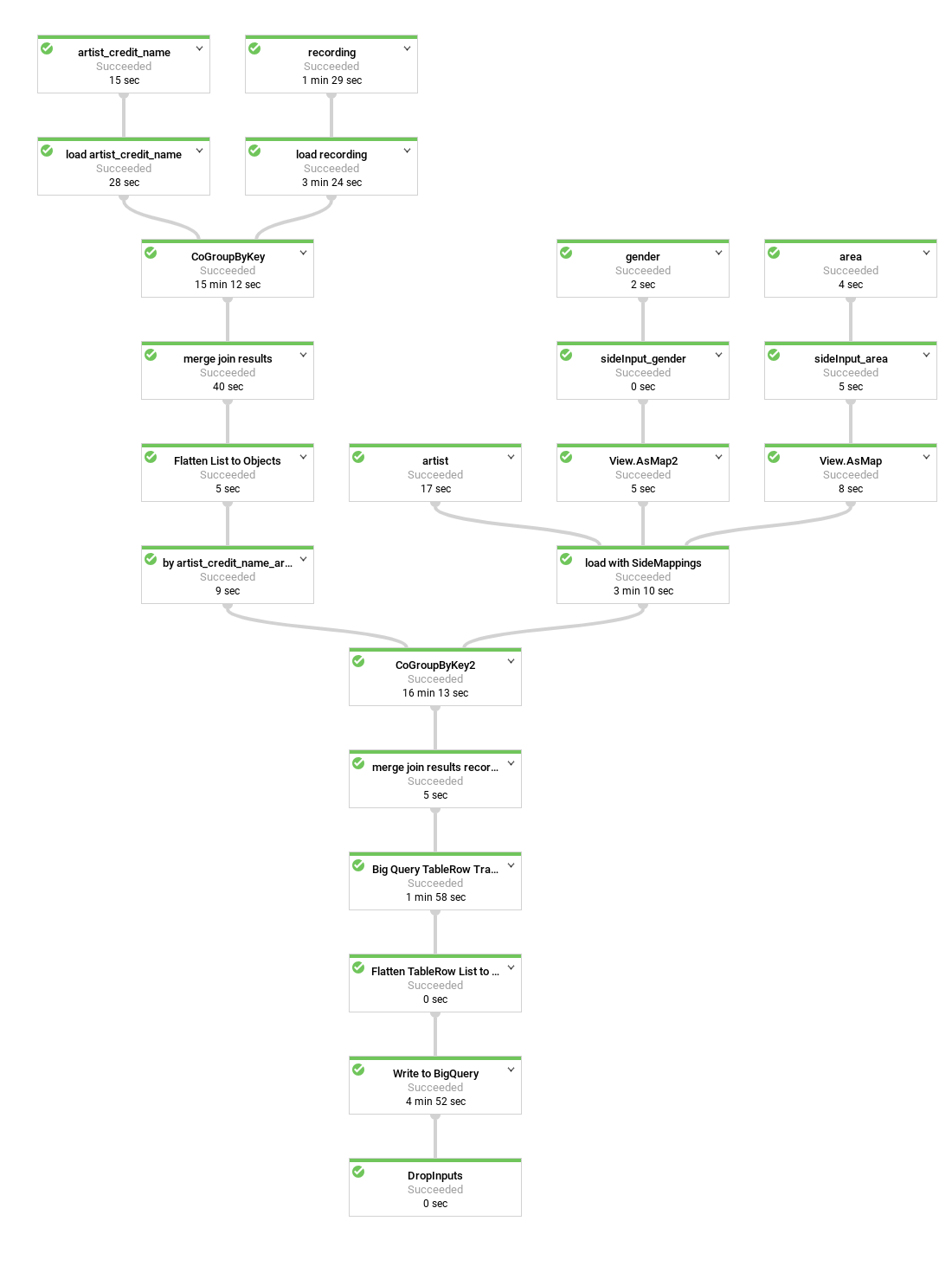
大多数情况下,步骤名称在代码中作为 apply 方法调用的一部分提供。
若要创建此优化流水线,请完成以下步骤:
在 Cloud Shell 中,确保为流水线脚本设置了环境:
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow_nested export DATASET=musicbrainz export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.com运行流水线以嵌套音乐人行中的录制内容行:
./run.sh nested和之前一样,要查看流水线的进度,请进入 Dataflow 页面。
流水线将需要约 10 分钟才能完成。
作业完成后,进入 BigQuery 页面。
从嵌套在 BigQuery 的表中查询字段:
SELECT artist_name, artist_gender, artist_area, artist_recordings FROM musicbrainz.recordings_by_artists_dataflow_nested WHERE artist_area IS NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;在输出中,
artist_recordings显示为可展开的嵌套行:行 artist_name artist_gender artist_area artist_recordings 1 mirin Female Japan (5 rows) 3 Gaudiburschen Male Germany (1 row) 4 Sa4 Male Hamburg (10 rows) 6 Dpat Male Houston (9 rows) 实际输出可能会有所不同,因为结果未排序。
运行查询以从
STRUCT提取值并使用这些值来过滤结果,例如对于拥有包含“Justin”一词的录制内容的音乐人:SELECT artist_name, artist_gender, artist_area, ARRAY(SELECT artist_credit_name_name FROM UNNEST(recordings_by_artists_dataflow_nested.artist_recordings)) AS artist_credit_name_name, ARRAY(SELECT recording_name FROM UNNEST(recordings_by_artists_dataflow_nested.artist_recordings)) AS recording_name FROM musicbrainz.recordings_by_artists_dataflow_nested, UNNEST(recordings_by_artists_dataflow_nested.artist_recordings) AS artist_recordings_struct WHERE artist_recordings_struct.recording_name LIKE "%Justin%" LIMIT 1000;在输出中,
artist_credit_name_name和recording_name显示为可展开的嵌套行,例如:行 artist_name artist_gender artist_area artist_credit_name_name recording_name 1 Damonkenutz null null (1 row) 1 Yellowpants (Justin Martin remix) 3 Fabian Male Germany (10+ rows) 1 Heatwave . 2 Starlight Love . 3 Dreams To Wishes . 4 Last Flight (Justin Faust remix) . ... 4 Digital Punk Boys null null (6 rows) 1 Come True . 2 We Are... (Punkgirlz remix by Justin Famous) . 3 Chaos (short cut) . ... 实际输出可能会有所不同,因为结果未排序。
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
删除项目
- 在 Google Cloud 控制台中,进入管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关闭以删除项目。
逐个删除资源
请按照相应步骤逐个删除资源,而非删除整个项目。
删除 Cloud Storage 存储分区
- 在 Google Cloud 控制台中,进入 Cloud Storage 存储桶页面。
- 点击要删除的存储分区对应的复选框。
- 如需删除存储分区,请点击删除,然后按照说明操作。
删除 BigQuery 数据集
打开 BigQuery 网页界面。
选择您在本教程中创建的 BigQuery 数据集。
点击删除delete。
后续步骤
- 详细了解如何为 BigQuery 编写查询。 查询数据介绍了如何运行同步和异步查询以及如何创建用户定义函数 (UDF) 等。
- 了解 BigQuery 语法。BigQuery 使用类似 SQL 的语法,如需了解此语法,请参阅查询参考(旧版 SQL)。
- 探索有关 Google Cloud 的参考架构、图表和最佳做法。查看我们的 Cloud Architecture Center。