
Managed Service for Apache Spark(以前称为 Dataproc)
以全新方式运行 Spark 工作负载:更轻松、更智能、更快速
以零运维无服务器 Spark 或托管式集群运行 Apache Spark 工作负载。利用智能体 AI 工作流加快开发速度,并利用 Lightning Engine 提升性能。
新客户可获得 300 美元赠金,用于试用 Managed Service for Apache Spark 和其他 Google Cloud 产品。
Apache Spark 是 Apache Software Foundation 的商标。

功能
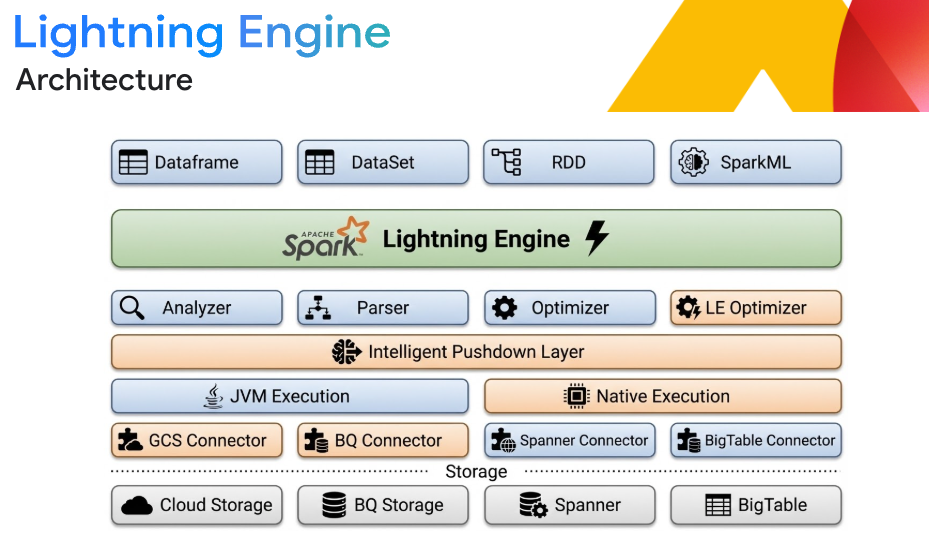
借助 Lightning Engine 实现业界领先的性能
灵活的湖仓一体互操作性
构建开放式湖仓一体架构,保证引擎独立性。直接从 Google Cloud Storage 处理 Apache Iceberg 等开放格式的数据。与 BigQuery 和 Knowledge Catalog(以前称为 Dataplex)无缝集成,实现统一的分析和治理,确保真正的多引擎互操作性,而无需翻译层。
依托 AI 技术的统一开发者体验
利用数据智能体来处理积压工作,这些智能体不仅能回答问题,还能执行操作。使用 VSCode 智能体扩展程序中内置的 Gemini 加快工作流速度,从而提高 Spark 工作负载从开发到生产的效率,或者使用您选择的 IDE。使用开箱即用的 Data Cloud 智能体自动整理数据和编写 PySpark 代码,或使用 Data Agent Kit 直接从 IDE 管理数据集并运行查询。使用 Gemini Cloud Assist 自动排查中断的 Spark 作业的问题。在单个统一的 AI 优先笔记本中结合使用 SQL 和 Spark。
支持企业级 AI/机器学习
构建整个机器学习生命周期,并将其付诸使用。借助 NVIDIA RAPIDS 支持的 GPU 和预配置的 PyTorch 和 XGBoost 机器学习运行时,加速模型训练和推理。与 Google Cloud AI 生态系统集成,编排端到端 MLOps,并通过 Gemini Enterprise Agent Platform Model Registry 集成管理资产。
安全、可伸缩且无缝的迁移
使用 IAM、VPC Service Controls 和 Kerberos 与您的安全状况无缝集成。使用 Managed Service for Apache Spark 模板和工具,轻松迁移云端和旧版 Spark 工作负载。支持 Spark 2.x 到 Spark 4.0,无需立即重构代码即可直接原样迁移工作负载。
多租户效率与 FinOps 控制
最大限度地提高资源利用率,减少空闲费用。部署多租户 Spark 集群,最多可让 800 名用户共享计算资源,同时保持严格的数据和环境隔离。利用缩减至零功能、按秒计费和 Spot 虚拟机支持灵活工作负载,控制账单费用。
开放灵活的生态系统
不会受制于特定供应商。我们的托管式集群针对 Apache Spark 进行了优化,同时还支持 Apache Hadoop、Flink 和 Trino 等 30 多种开源工具。与 Managed Service for Apache Airflow 等编排器无缝集成,并使用 Kubernetes 和 Docker 进行扩展,以实现最大的灵活性。
部署选项
| 部署选项 | 您可以根据自己工作负载的需求选择最合适的方案:具有精细控制的托管集群,或者采用零运维的无服务器体验。 | ||
|---|---|---|---|
| 部署模式: | 内容: | 适用场景: | 付费项 |
无服务器 | Spark 作业即服务。 Managed Spark,托管式基础设施。 | 新的流水线、互动式分析和突发性工作负载,在这些场景中,零运维、按作业付费的模型是首选。 | 作业运行时间 |
集群 | Spark 集群即服务。 Managed Spark,您的基础设施 | 迁移旧版 Spark 或 OSS 工作负载、运行永久性集群,或需要深度开源自定义。 | 集群正常运行时间 |
部署选项
您可以根据自己工作负载的需求选择最合适的方案:具有精细控制的托管集群,或者采用零运维的无服务器体验。
无服务器
Spark 作业即服务。
Managed Spark,托管式基础设施。
新的流水线、互动式分析和突发性工作负载,在这些场景中,零运维、按作业付费的模型是首选。
作业运行时间
集群
Spark 集群即服务。
Managed Spark,您的基础设施
迁移旧版 Spark 或 OSS 工作负载、运行永久性集群,或需要深度开源自定义。
集群正常运行时间
大规模数据工程
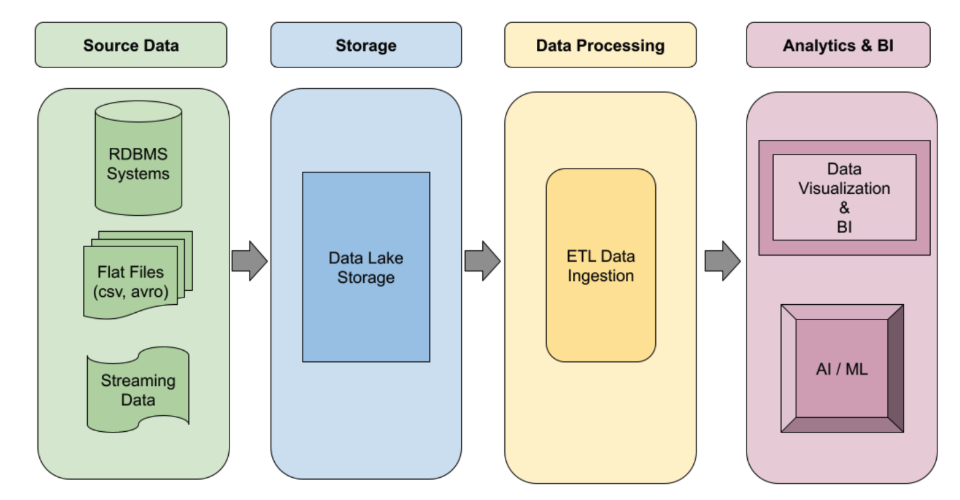
自动化 ETL 流水线
自动化 ETL 流水线
构建稳健的事件驱动型 Spark ETL 流水线,可根据需求自动扩缩。利用无服务器执行来处理高峰工作负载,或利用托管式集群来处理持久性作业。使用工作流模板端到端地自动执行最重要的生产级数据处理作业。


教程、快速入门和实验
自动化 ETL 流水线
自动化 ETL 流水线
构建稳健的事件驱动型 Spark ETL 流水线,可根据需求自动扩缩。利用无服务器执行来处理高峰工作负载,或利用托管式集群来处理持久性作业。使用工作流模板端到端地自动执行最重要的生产级数据处理作业。
数据科学和机器学习
互动式数据科学
互动式数据科学
让数据科学家能够探索数据并迭代 Spark ML 模型。使用 Gemini 通过 VSCode 智能体扩展程序或您选择的 IDE 统一 SQL 和 Spark,无缝地从数据探索过渡到使用 PySpark 通过无服务器执行构建模型。只需一条命令,即可挂接 GPU。


教程、快速入门和实验
互动式数据科学
互动式数据科学
让数据科学家能够探索数据并迭代 Spark ML 模型。使用 Gemini 通过 VSCode 智能体扩展程序或您选择的 IDE 统一 SQL 和 Spark,无缝地从数据探索过渡到使用 PySpark 通过无服务器执行构建模型。只需一条命令,即可挂接 GPU。
湖仓一体现代化改造
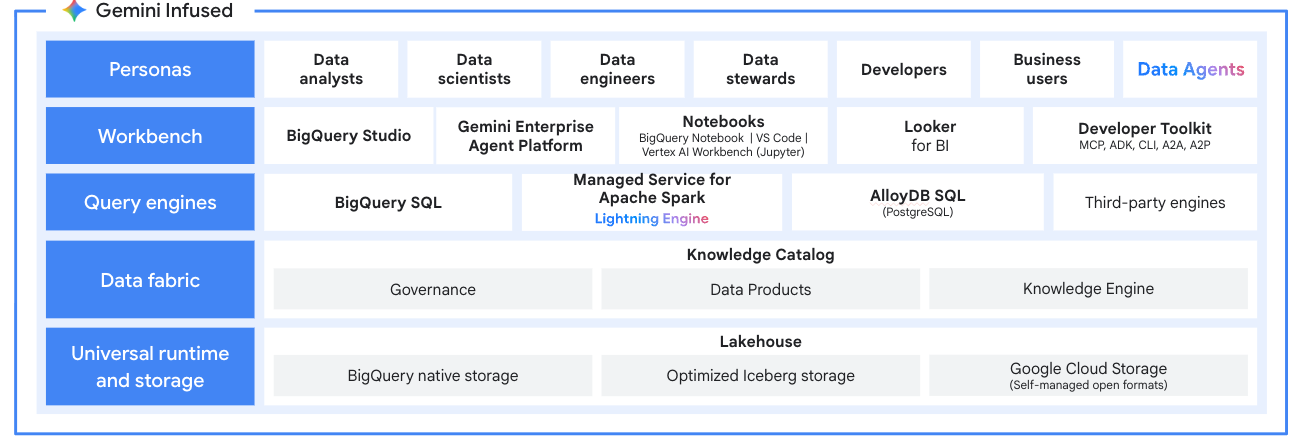
开放式数据湖仓一体
开放式数据湖仓一体
将 Managed Service for Apache Spark 用作现代数据湖仓的处理引擎。直接从数据湖处理 Apache Iceberg 等开放格式的数据,消除数据孤岛。与 BigQuery 和 Lakehouse for Apache Iceberg 集成,打造统一的多引擎分析平台。

教程、快速入门和实验
开放式数据湖仓一体
开放式数据湖仓一体
将 Managed Service for Apache Spark 用作现代数据湖仓的处理引擎。直接从数据湖处理 Apache Iceberg 等开放格式的数据,消除数据孤岛。与 BigQuery 和 Lakehouse for Apache Iceberg 集成,打造统一的多引擎分析平台。
价格
| Managed Service for Apache Spark 的定价方式 | 价格取决于您选择的部署模式。无服务器按作业执行次数计费,集群按底层计算和正常运行时间计费。 | |
|---|---|---|
| 部署模式: | 收费项: | 价格: |
无服务器 | 用多少、付多少。计算、GPU 和 shuffle 存储空间按秒计费。缩减至零可确保您绝不会为空闲容量付费。 | 起价 0.06 美元/DCU 小时 |
高级层级和加速器: 使用 Lightning Engine,性能最高可提升 4.9 倍,或挂接 NVIDIA GPU 来处理 AI/机器学习工作负载。 | 起价 0.089 美元/DCU 小时 无服务器高级层级 | |
集群 | 按集群正常运行时间付费。按底层 Compute Engine 资源计费,另加固定管理费。利用 Spot 虚拟机和零扩缩来优化成本。 | 起价 0.01 美元/vCPU 小时 管理费 |
Lightning Engine 加购项: 为您的集群带来突破性的性能。执行速度最高可比开源 Spark 快 4.9 倍。 | 起价 0.0025 美元/vCPU 小时 | |
详细了解 Managed Service for Apache Kafka 定价。查看所有价格详情。
Managed Service for Apache Spark 的定价方式
价格取决于您选择的部署模式。无服务器按作业执行次数计费,集群按底层计算和正常运行时间计费。
无服务器
用多少、付多少。计算、GPU 和 shuffle 存储空间按秒计费。缩减至零可确保您绝不会为空闲容量付费。
Starting at
0.06 美元/DCU 小时
高级层级和加速器:
使用 Lightning Engine,性能最高可提升 4.9 倍,或挂接 NVIDIA GPU 来处理 AI/机器学习工作负载。
Starting at
0.089 美元/DCU 小时
无服务器高级层级
集群
按集群正常运行时间付费。按底层 Compute Engine 资源计费,另加固定管理费。利用 Spot 虚拟机和零扩缩来优化成本。
Starting at
0.01 美元/vCPU 小时
管理费
Lightning Engine 加购项:
为您的集群带来突破性的性能。执行速度最高可比开源 Spark 快 4.9 倍。
Starting at
0.0025 美元/vCPU 小时
详细了解 Managed Service for Apache Kafka 定价。查看所有价格详情。
业务用例
客户成功案例

“我们看到,一些质量检查从 11 小时缩短到几分钟。”
Michael Manos,Dun & Bradstreet 首席技术官
迁移到 Google Cloud 后,Dun & Bradstreet 显著提高了数据流的速度,将质量检查流程从数小时缩短到几分钟,并将发布新数据所需的时间缩短了一半。这一强大的数据基础还使 Dun & Bradstreet 能够充分利用 Google Cloud 生态系统的强大功能,包括先进的数据和 AI 技术。



Managed Service for Apache Spark 的独特优势
借助灵活的部署选项,释放零运维生产力。您可以选择无服务器执行或全托管式集群,旨在消除基础设施开销与繁琐的手动调优负担。
智能体 AI 开发。借助内置于 VSCode 智能体扩展程序或您自选 IDE 中的 Gemini,以及能够自动执行 PySpark 编码、数据整理和作业问题排查的数据智能体,在统一的笔记本中加速您的工作流。
业界领先的卓越性能,由 Lightning Engine 强力驱动。将要求最严苛的 ETL 和数据科学工作负载的处理速度提升高达 4.9 倍,从而显著降低总拥有成本 (TCO)










其他资源:
常见问题解答
Dataproc 和 Serverless Spark 有哪些变化?
为了优化您的驾驭体验,我们将 Dataproc 与 Google Cloud Serverless for Apache Spark 集于一体,打造出统一的产品:Managed Service for Apache Spark。您将获得同样强大的性能支持,且现在可以从统一界面中灵活选择您偏好的部署模型——无论是零运维的无服务器模式,还是全托管式集群。深入探索两种部署模式的详尽差异。
我应该在何种情况下选择无服务器集群,而不是托管式集群?
若您希望专注于代码开发而无需投入精力管理基础设施,无服务器模式是构建新流水线和执行临时分析的理想之选。若您需要精细化控制,或正在迁移传统/云端 Spark 及其他 OSS 工作负载,亦或是需要配备丰富开源工具的持久性集群,托管式集群将是您的最佳选择。
什么是 Lightning Engine?
Lightning Engine 是 Google Cloud 原生的、经过高度优化的执行引擎。该引擎采用 C++ 库构建,实现了从高吞吐量存储连接器到智能缓存的每一层架构优化。其性能相较于标准 Spark 提升高达 4.9 倍,性价比是领先的高速 Spark 竞品的 2 倍,且无需更改代码即可无缝集成到您的无服务器或集群部署中。
我是否需要安装自己的机器学习库,例如 PyTorch?
无需如此。如果您运行的是 AI/机器学习工作负载,可以利用我们预配置的机器学习运行时。这些环境内置了 PyTorch、XGBoost 和 scikit-learn 等常用库,并配备经过优化的 NVIDIA GPU 驱动程序,旨在免除复杂的设置流程。
Managed Service for Apache Spark 是否与开源完全兼容?
是。我们提供与开源 Apache Spark 完全兼容的环境。您可以直接运行现有的 Spark 代码而无需修改,从而实现工作负载的灵活迁移,并协助您避免受制于供应商。
Gemini AI 如何帮助进行 Spark 开发?
您可以将 Gemini AI 直接引入自选的 IDE 中,使其成为您的 AI 副驾驶。它能协助您更高效地编写和调试 PySpark 代码,同时 Gemini Cloud Assist 可针对失败的作业提供自动化的根本原因分析与排查建议。
我可以使用这项服务来构建开放式数据湖仓一体吗?
当然可以。Managed Service for Apache Spark 是 Google Cloud 开放式湖仓一体架构的核心处理引擎。它支持直接从 Cloud Storage 处理 Apache Iceberg 等开放格式的数据,并能与 BigQuery 及 Knowledge Catalog for Apache Iceberg 无缝集成。
标准和高级价格层级如何运作?
标准层级和高级层级目前仅适用于无服务器部署。标准版是实现经济高效的通用批处理和 ETL 的理想之选。高级层级专为要求最严苛的工作负载而设计,通过 Lightning Engine 释放比开源 Apache Spark 高出 4.9 倍的性能潜能,并支持接入 GPU 加速的 AI/ML 功能。


















