HDFS vs. Cloud Storage: Pros, cons and migration tips

Dennis Huo
Software Engineer, Cloud Dataproc Lead
Christopher Crosbie
Product Manager, Data Analytics

With the recent merger of Hadoop companies Cloudera and Hortonworks, some are asking: Is the Hadoop file system officially dead? The news around this merger has reiterated the impact of the economics of cloud. Reports are now going as far as saying that using cloud storage can easily “crush Hadoop storage costs.” Object stores such as Google Cloud Storage are overtaking on-premise Hadoop Distributed File System (HDFS) deployments at a rapid pace.

HDFS was once the quintessential component of the Hadoop stack. So the yellow elephant in the room here is: Can HDFS really be a dying technology if Apache Hadoop and Apache Spark continue to be widely used? The data architects and engineers who understand the nuances of replacing a file system with an object store may be wondering if reports of HDFS’ death have been, as Mark Twain might say, “greatly exaggerated.”
An object store has a very different data storage architecture than that of HDFS. Many patterns and paradigms developed specifically around HDFS primitives may not translate into object storage as well as you’d like.
Let’s dive into these and other trade-offs you might encounter when moving your Hadoop and Spark jobs from HDFS to object storage. We’re obviously well-versed in advice on using an object store like Google Cloud Storage, but we’ll provide a clear distinction of when HDFS makes sense. Whether you’re using object storage or HDFS, moving data from a data center to the cloud for storage can greatly reduce costs and operational burden.
The pros and cons of Cloud Storage vs. HDFS
The move from HDFS to Cloud Storage brings some tradeoffs. Here are the pros and cons:
Moving to Cloud Storage: the cons
- Cloud Storage may increase I/O variance. In many situations, Cloud Storage has a higher I/O variance than HDFS. This can be problematic if you have consistent I/O requirements, such as an application backed by HBase or another NoSQL database. While the read I/O variance can often be mitigated with caching and read replicas, you may want to consider Cloud Bigtable or Cloud Datastore.
- Cloud Storage does not support file appends or truncates. Objects are immutable, which means that an uploaded object cannot change throughout its storage lifetime. In practice, this means that you cannot make incremental changes to objects, such as append operations or truncate operations. (You can, however, overwrite objects, so incremental updates can be achieved by rewriting an object with the desired updates.)
- Cloud Storage is not POSIX-compliant. To be fair, HDFS is also not fully POSIX-compliant. However, over the years, HDFS has incorporated many POSIX-like features, and developers have built Hadoop and Spark applications to take advantage of features which may not translate well to Cloud Storage. For example, Cloud Storage directory renames are not atomic, since they are metadata pointers, not true directories.
This also means that directory metadata and permissions will not work as they do in HDFS. Hadoop applications such as Ranger and Sentry (to name just a couple) take dependencies on these HDFS permissions. When moving these apps, pay attention to make sure that proper permissioning still works as expected.
4. Cloud Storage may not expose all file system information. If you were to run a command such as “hadoop fsck -files -blocks” against a directory in HDFS, you would see an output of useful information, ranging from status to racks to corrupted blocks. Cloud Storage abstracts the entire management layer of all storage, so the same command using the connector simply returns “Filesystem is Cloud Storage.” (By the same token, “no storage management overhead” can be a pro; see below.)
5. Cloud storage may have greater request latency.
Cloud storage may have a greater request round-trip latency compared to HDFS. For typical large-scale ETL jobs, this isn't a significant factor, but small jobs, large numbers of small files, or large numbers of sequential file system operations can be sensitive to per-request latency.
Moving to Cloud Storage: the pros
Lower costs. With Cloud Storage, you only pay for what you use instead of over-buying hardware up front and guessing how much data storage you may eventually need. The bytes you purchase on Cloud Storage are also post-replication, so you don’t need to pay for Google Compute Engine instances to be up and running on a persistent drive that is replicated three times. This can translate to substantial savings—Enterprise Strategy Group (ESG) research found that organizations that move from an always-on HDFS deployment on-prem to Cloud Storage (on Cloud Dataproc) typically have a 57% lower total cost of ownership.
2. Separation from compute and storage. When you store data in Cloud Storage instead of HDFS, you can access it directly from multiple clusters. This makes it easier to tear down and set up new clusters without moving the data. It also makes it possible to take advantage of job-scoped clusters.
3. Interoperability. Storing data in Cloud Storage enables seamless interoperability between Spark and Hadoop instances as well as other GCP services. Exported Cloud Storage files can be imported into Google BigQuery, and using Cloud Storage makes it easy to experiment with Cloud Dataflow for managed data processing tasks.
4. HDFS compatibility with equivalent (or better) performance. You can access Cloud Storage data from your existing Hadoop or Spark jobs simply by using the gs:// prefix instead of hfds:://. In most workloads, Cloud Storage actually provides the same or better performance than HDFS on Persistent Disk.
5. High data availability. Data stored in Cloud Storage is highly available and globally replicated (when using multi-regional storage) without a loss of performance. Cloud Storage is not vulnerable to NameNode single point of failure or even cluster failure.
6. No storage management overhead. Unlike HDFS, Cloud Storage requires no routine maintenance such as running checksums on the files, upgrading or rolling back to a previous version of the file system and other administrative tasks. Google’s site reliability engineering (SRE) teams do this work for you.
7. Quick startup. In HDFS, a MapReduce job can’t start until the NameNode is out of safe mode—a process that can take from a few seconds to many minutes, depending on the size and state of your data. With Cloud Storage, you can start your jobs as soon as the task nodes start. Since Google Cloud bills per second, our customers have found that this faster start leads to significant cost savings over time.
8. Google IAM security. Using Cloud Storage instead of HDFS puts you directly into the GCP security models so you can take advantage of IAM controls like Service Accounts and don’t need a separate HDFS permissioning system.
9. Global consistency. Cloud Storage provides strong global consistency for the below operations; this includes both data and metadata.
Read-after-write
Read-after-metadata-update
Read-after-delete
Bucket listing
Object listing
Granting access to resources
Having these operations strongly consistent makes Cloud Storage an appropriate place for job destinations and avoids the overhead of the complicated workarounds needed for eventually consistent object stores.
When to choose HDFS: 5 job types to consider
Cloud Storage is a good choice for many workloads, but there are five specific job types that may be better suited for HDFS.
1. Jobs that require Hadoop 2 but less than Hadoop 2.7
In versions of Hadoop that fall between versions 2.0 and 2.7.x, the FileOutputCommitter is much slower on Cloud Storage than HDFS. A patch does fix this issue starting in Hadoop 2.7. Note that this is not applicable to Cloud Dataproc customers, since the fix has been applied there.
2. Jobs requiring low variance in performance and/or very fast round-trips for metadata or small reads
Jobs that are expected to run at interactive speed may be more sensitive to tail latency of the slowest tasks. Jobs that involve many small random-access reads and/or many sequential metadata requests may be sensitive to tail latency as well as the overall greater latency of request round-trips. Such jobs may be better suited to HDFS.
3. Jobs requiring POSIX-like features
Jobs requiring file system features like strictly atomic directory renames, fine-grained HDFS permissions, or HDFS symlinks can only work on HDFS.
4. Reference tables or lookup values
Jobs that re-query the same pieces of data often and don't require shuffle activity may benefit from a localized HDFS version of the data. That allows jobs to automatically use disk buffer caches. A common best practice is to maintain the reference table sources in Cloud Storage but bring the file into HDFS as a first step in the job.
5. Iterative or recursive analysis on small datasets
Jobs running many iterations on a small dataset, which is much smaller than the total available memory, will likely experience faster HDFS performance due to disk buffer cache. Again, a common best practice is to maintain the table sources in Cloud Storage but bring the file into HDFS as a first step in the job.
Converting from HDFS to Cloud Storage
Once you decide to convert your storage layer from HDFS to Cloud Storage, the first step is to install, configure and start to experiment with the Cloud Storage connector.
If you are using Cloud Dataproc, Google’s fully managed cloud service for running Apache Spark and Apache Hadoop clusters, the Cloud Storage connector comes pre-installed. The same goes for Hortonworks Data Platform (HDP). Starting in HDP 3.0, Cloud Storage has become a fully integrated connector for data access and processing of Hadoop and Spark workloads.
While MapR does not integrate with the connector by default, they do provide a quick start guide that is easy to follow.
You can also install the Cloud Storage Connector on pretty much any Apache Hadoop/Spark cluster by following these installation instructions. Once you have gained basic experience using the Cloud Storage connector, you can explore the Google Cloud documentation on Migrating HDFS Data from On-Premise to Google Cloud Platform.
To modify existing jobs to use Cloud Storage after you’ve installed the Cloud Storage connector, using "gs://foo-bucket/foo-data-directory" works just like any other "hdfs://namenode/foo-data-directory" path.
Just change the input and output paths and Cloud Storage will work for most typical jobs without further modification.
Tips and tricks for using the Cloud Storage connector
Here are some tips and tricks to consider when you’re choosing which jobs to move with the Cloud Storage connector.
Increase fs.gs.block.size for large files.
Because Cloud Storage abstracts the internal block sizes, a default value of 64MB is simply that—a default. If you have files larger than ~512MB and the job is large, you may consider increasing this value to 1GB. Since this is a “fake” value just for Hadoop’s “getSplits” calls, it can be different per job or even on the same underlying datasets.
You’ll want to aim for fewer than 10,000 to 20,000 input splits. In most situations, this translates into 10TB of data being the tipping point for when you want to set fs.bs.block.size to 1GB.
Another way to think about this setting is to try and make each map task take about 60 seconds to run for each input split. That way the task JVM setup and scheduling overhead is minimal compared to the task runtime.
Take advantage of storage classes for Hadoop.
Google Cloud Storage offers four storage classes, all with the same throughput, low latency, and high durability. The classes only differ by their availability, minimum storage durations, and pricing for storage and access.
The Cloud Storage tools and APIs to access the data remain the same regardless of storage class. You can write a Spark or Hadoop job against data designated at a lower-cost tier without needing a separate archiving service.
These are the basics of Cloud Storage classes in the context of Hadoop.
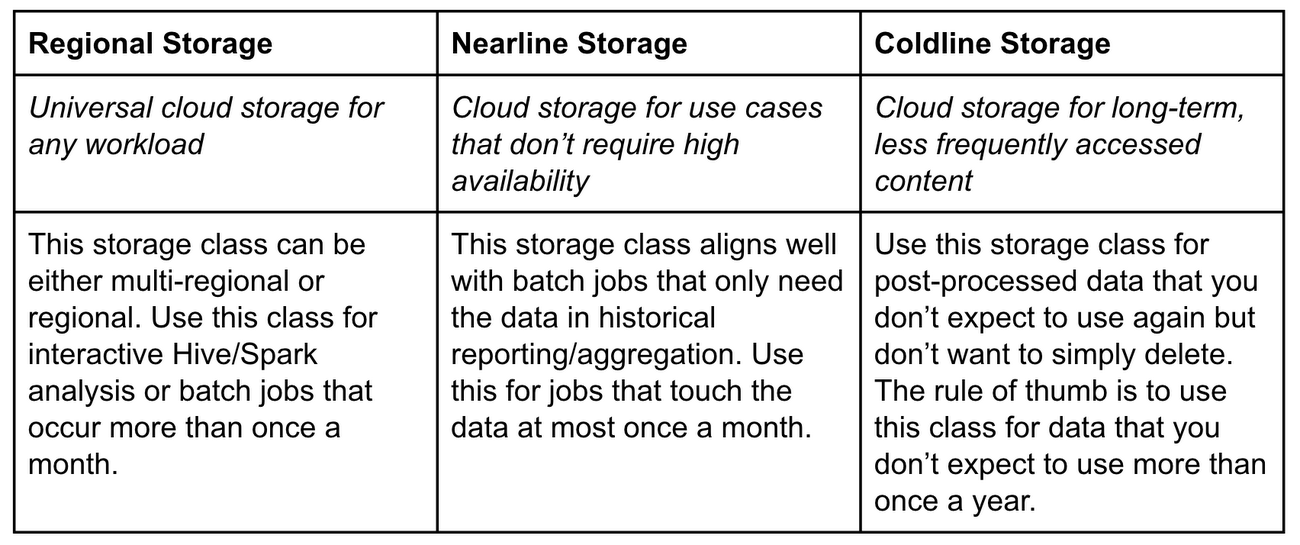
Note on regional storage: most Hadoop workloads will use regional storage over multi-regional storage in order to guarantee processing happens in the same region as the data
Next steps for laying out your data in GCS
Plan carefully when you’re choosing HDFS vs. Cloud Storage with these best practices, and explore more about Cloud Storage here.


