Dataplex Automatic Discovery makes Cloud Storage data available for Analytics and governance
Parth Desai
Product Manager, Google
In today's data- and AI-driven world, organizations are grappling with an ever-growing volume of structured and unstructured data. This growth makes it increasingly challenging to locate the right data at the right time, and a significant portion of enterprise data remains undiscovered or underutilized — what’s often referred to as "dark data." In fact, a staggering 66% of organizations report that at least half of their data falls into this category.
To address this challenge, today we’re announcing automatic discovery and cataloging of Google Cloud Storage data with Dataplex, part of BigQuery’s unified platform for intelligent data to AI governance. This powerful capability empowers organizations to:
-
Automatically discover valuable data assets residing within Cloud Storage, including structured and unstructured data such as documents, files, PDFs, images, and more.
-
Harvest and catalog metadata for your discovered assets by keeping schema definitions up-to-date with built-in compatibility checks and partition detection, as data evolves.
-
Enable analytics for data science and AI use cases at scale with auto-created BigLake, external or object tables, eliminating the need for data duplication or manually creating table definitions.
How it works
The automatic discovery and cataloging process in Dataplex is designed to be integrated and efficient, and performs the following steps:
-
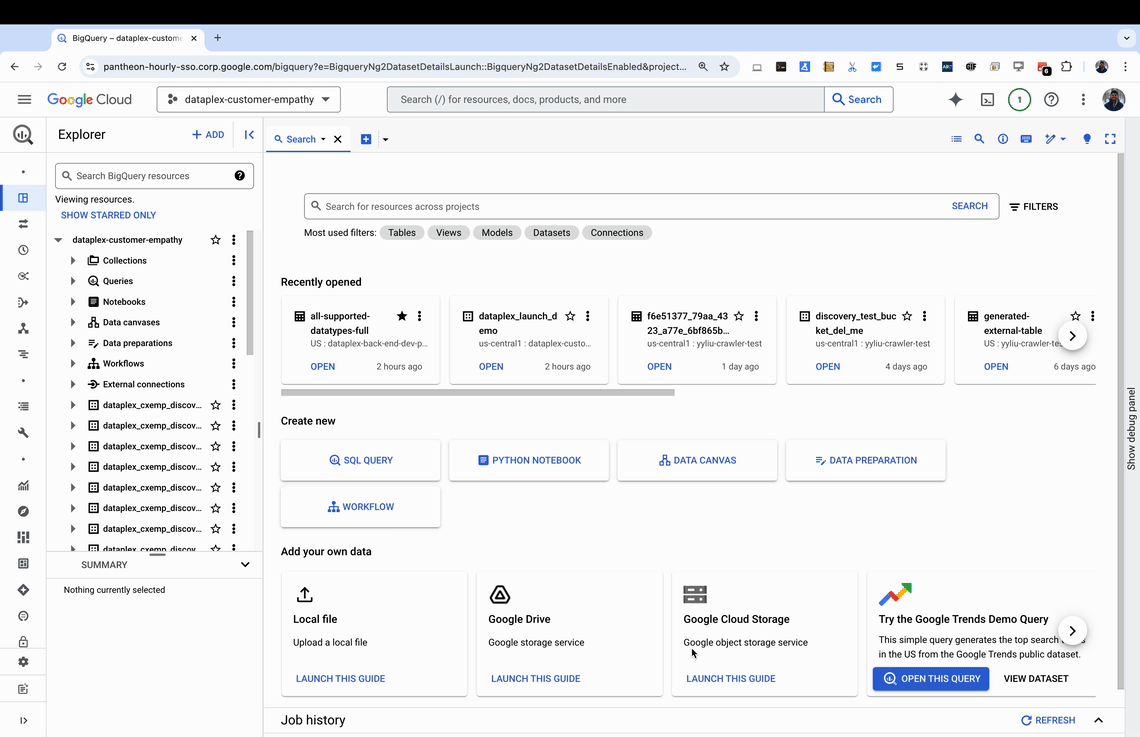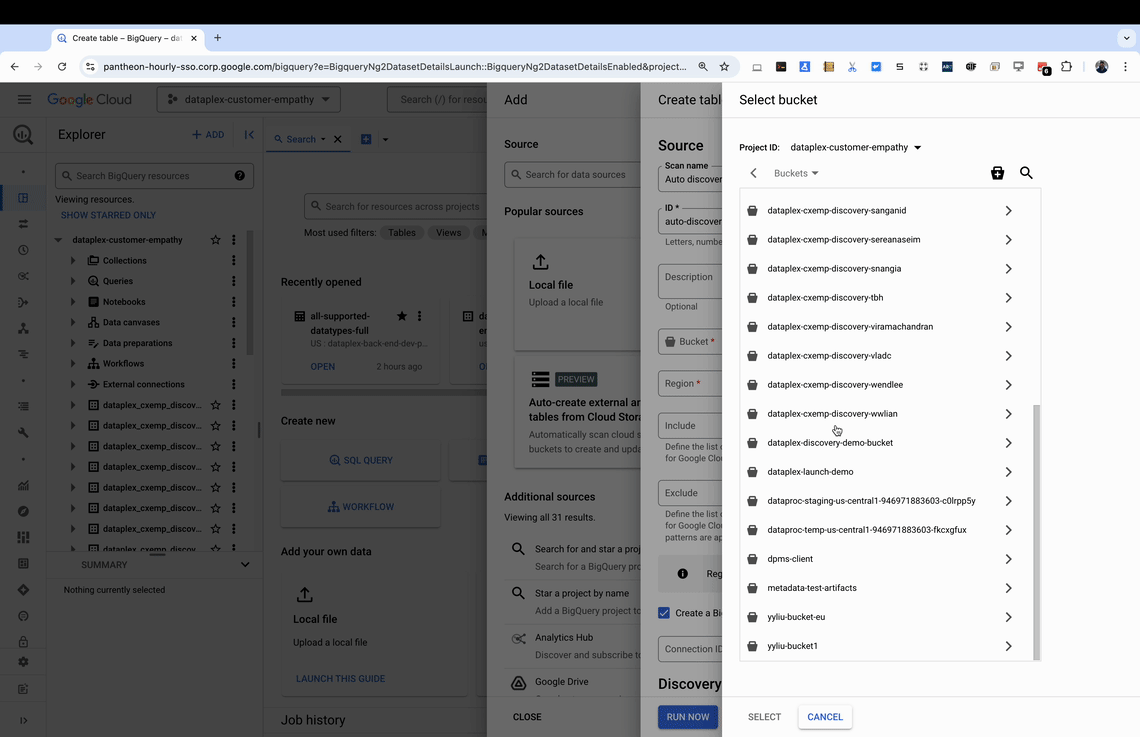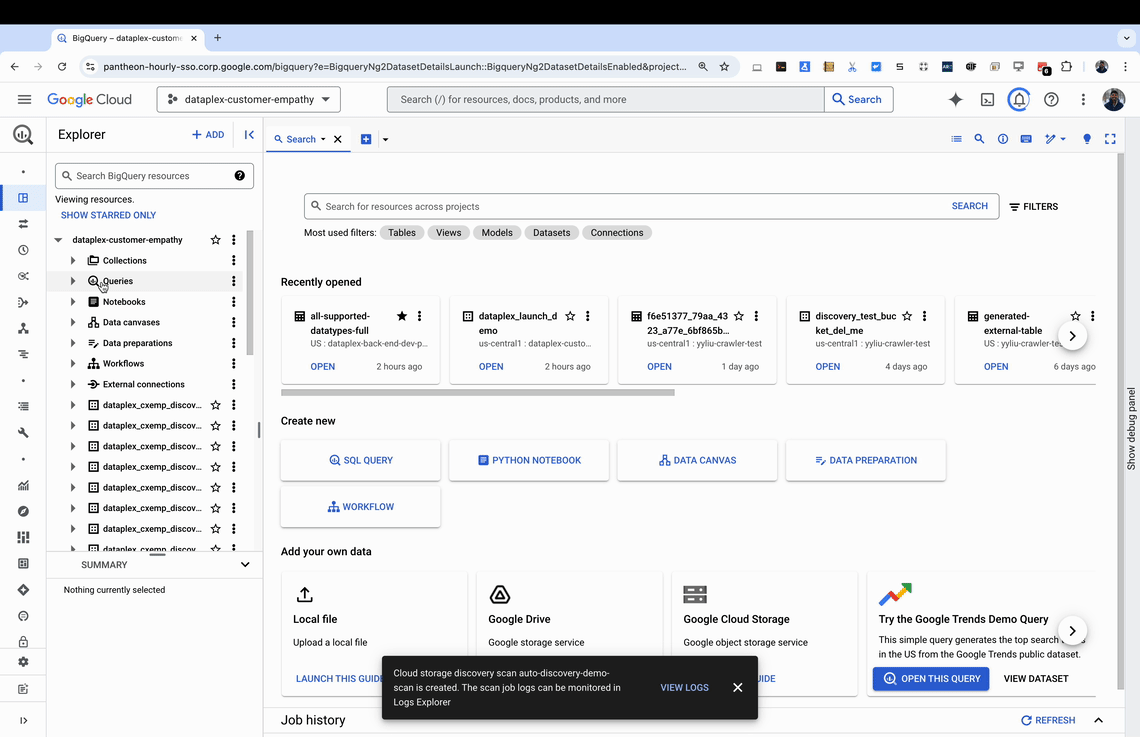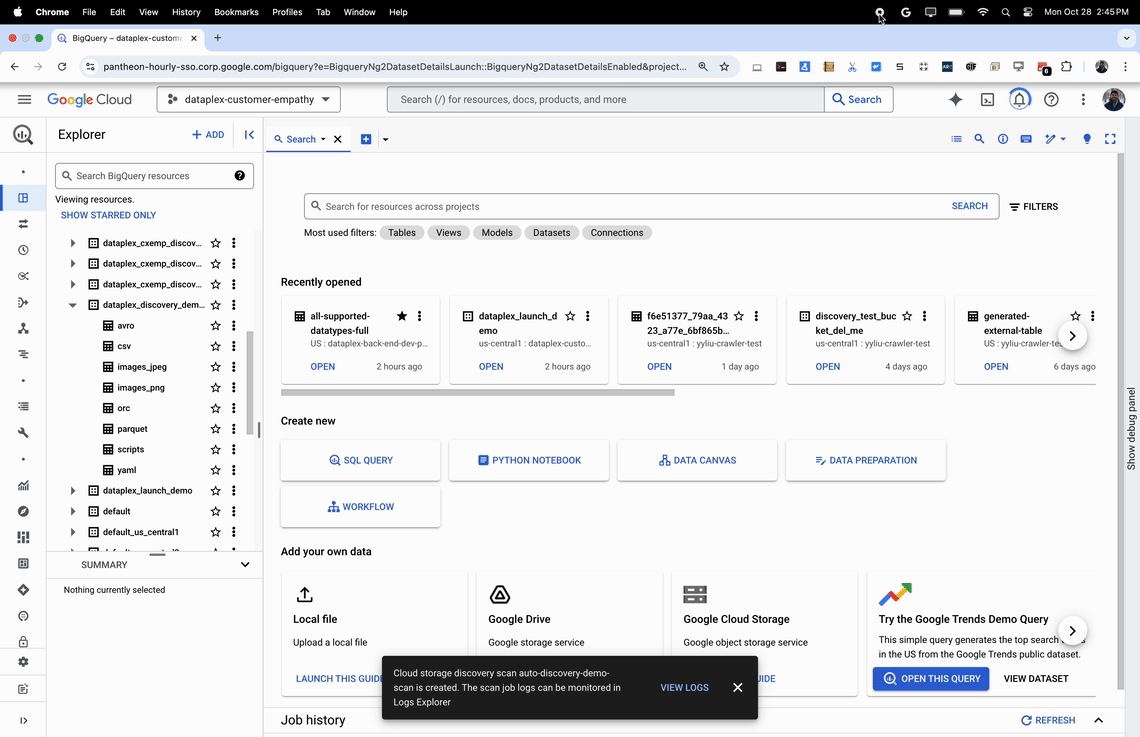
Discovery scan: Discovery scan is configured by the user using the BigQuery Studio UI, CLI or gcloud, which scans your Cloud Storage bucket with up to millions of files, identifying and classifying data assets.
-
Metadata extraction: Relevant metadata, including schema definitions and partition information, is extracted from the discovered assets.
-
Creation of dataset and tables in BigQuery: A new dataset with numerous BigLake, external or object tables (for unstructured data) is automatically created in BigQuery with accurate, up-to-date table definitions. For scheduled scans, these tables will be updated as the data in cloud storage bucket evolves.
-
Analytics and AI preparation: The published dataset and tables are available for analysis, processing, data science, and AI use cases in BigQuery, as well as open-source engines like Spark, Hive, and Pig.
-
Catalog integration: All BigLake tables are integrated into the Dataplex catalog, making them easily searchable and accessible.

Key benefits
Dataplex’s automatic discovery and cataloging feature offers a multitude of benefits for organizations:
-
Enhanced data visibility: Gain a clear understanding of your data and AI assets across Google Cloud, eliminating the guesswork and reducing the time spent searching for relevant information.
-
Reduced manual effort: Cut back on the toil and effort of creating table definitions manually by letting Dataplex scan the bucket and create numerous BigLake tables that correspond to your data in Cloud Storage.
-
Accelerated analytics and AI: Integrate the data that’s discovered into your analytics and AI workflows, unlocking valuable insights and driving informed decision-making.
-
Simplified data access: Provide authorized users with easy access to the data they need, while maintaining appropriate security and control measures.
For Storage admins who are interested in Cloud Storage management and gaining insights into their entire storage estate, please refer to Understand your Cloud Storage footprint with AI-powered queries and insights
Unlock your data’s potential
Automatic discovery and cataloging in Dataplex marks a significant step forward in helping organizations unlock the full potential of their data. By eliminating the challenges associated with dark data and providing a comprehensive, searchable catalog of your Cloud Storage assets, Dataplex empowers you to make data-driven decisions with confidence.
We encourage you to explore this powerful new feature and experience the benefits firsthand. To learn more and get started, please visit the Dataplex documentation or contact our team for assistance.
