Introducing BigQuery metastore, a unified metadata service with Apache Iceberg support
Yuri Volobuev
Principal Engineer
Vinod Ramachandran
Senior Product Manager, Google
Does your organization use multiple data processing engines like BigQuery, Apache Spark, Apache Flink and Apache Hive? Wouldn’t it be great if you could provide a single source of truth for all of your analytics workloads? Now you can, with the public preview of BigQuery metastore, a fully managed, unified metadata service that provides processing engine interoperability while enabling consistent data governance.
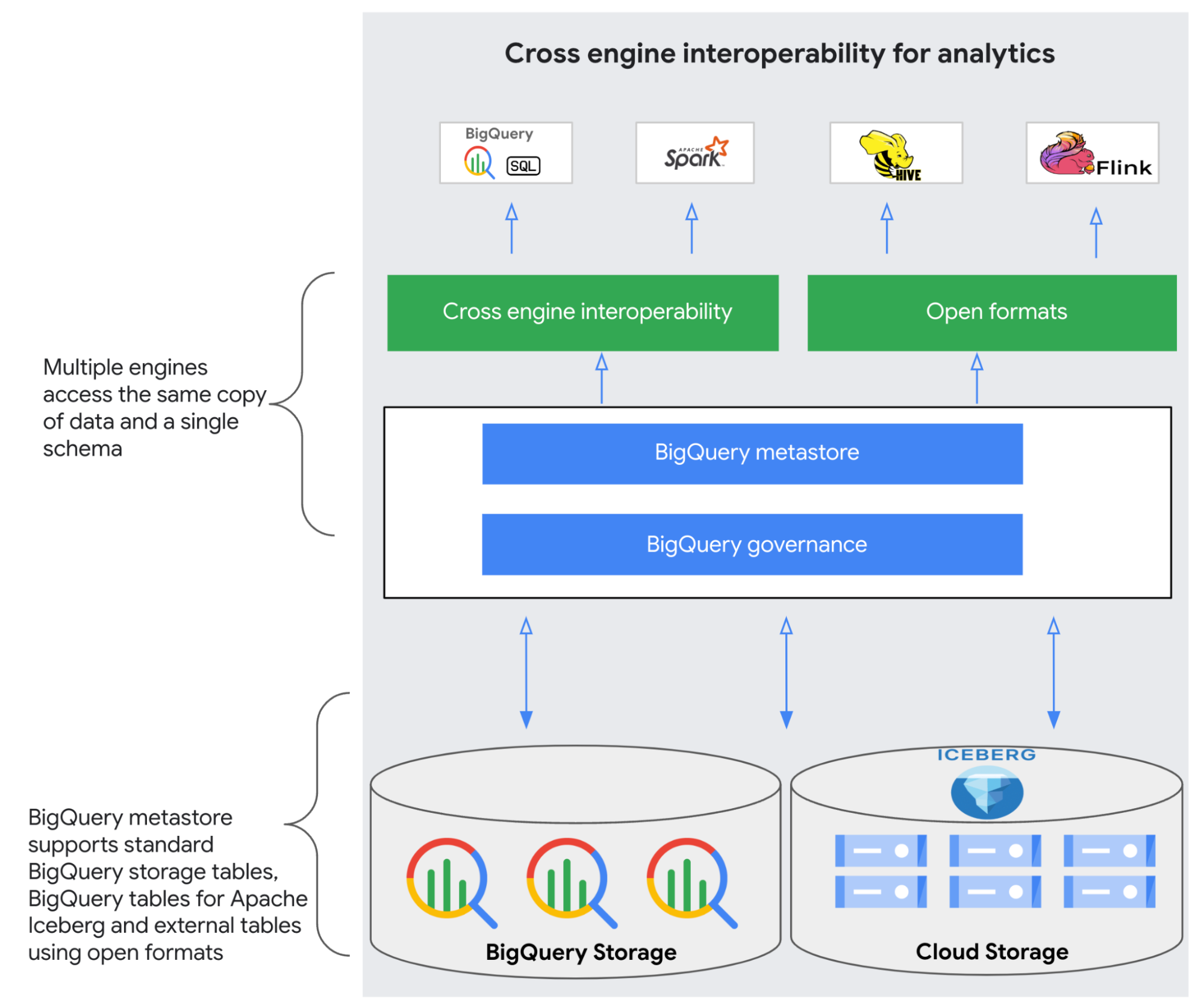
BigQuery metastore is a highly scalable runtime metadata service that works with multiple engines, for example, BigQuery, Apache Spark, Apache Hive and Apache Flink, and supports the open Apache Iceberg table format. This allows analytics engines to query one copy of the data with a single schema, whether the data is stored in BigQuery storage tables, BigQuery tables for Apache Iceberg, or BigLake external tables. BigQuery metastore serves as a critical component for customers looking to migrate and modernize from legacy data lakes to a modern lakehouse architecture. Integrated deeply with BigQuery’s enterprise capabilities, this solution provides built-in security and governance for user interactions with data.
The challenges of metadata management
Traditionally, metastores and other metadata management systems are tightly coupled with data processing engines. If you are using multiple processing engines, that means maintaining multiple copies of the data and metadata persisted in different metastores. For example, when you create a table definition in Hive Metastore for querying from an open-source engine like Spark, you have to recreate the table definition to query the same data in BigQuery. You also have to build pipelines to keep table definitions synchronized across different metastores. This fragmentation can result in stale metadata, lack of visibility into data lineage, security and access challenges, and a subpar user experience.
A metastore for the lakehouse era
BigQuery metastore is designed for the lakehouse architecture, which combines the benefits of data lakes and data warehouses without having to manage both a data lake and a data warehouse — any data, any user, any workload, on a unified platform. It supports open data formats such as Apache Iceberg that are accessible by a variety of processing engines, including BigQuery, Spark, Flink and Hive. The unification of metadata across engines makes it easier to discover and use data, supporting self-service BI and ML tools to drive innovation, while maintaining data governance.
Furthermore, BigQuery metastore is serverless with no setup or configuration required and automatically scales with your workloads. This no-ops environment reduces TCO and democratizes your data for data analysts, data engineers and data scientists.
Key benefits of BigQuery metastore include:
-
Cross-engine interoperability: BigQuery metastore provides a single shared metastore for the lakehouse architecture, with a unified view of all metadata for all data sources in the lakehouse, making it easy for your users to find and understand the data they need. This enables query processing and DML for data stored in open and proprietary formats across object stores, BigQuery storage, and across analytics runtimes.
-
Support for open formats and catalogs: BigQuery metastore provides support for BigQuery storage tables, BigQuery tables for Apache Iceberg and external tables.
-
Built-in governance: BigQuery metastore is integrated with key governance capabilities provided in BigQuery, such as automated cataloging and universal search, business metadata, data profiling, data quality, fine-grained access controls, data masking, sharing, data lineage and audit logging.
-
Fully managed at BigQuery scale: Being a serverless, fully managed service, BigQuery metastore is very easy to use and has integrations with key engines (BigQuery, Spark, Hive and Flink). The infrastructure foundation used for BigQuery metastore ensures that it scales to the growing query processing volume of your application and can handle traffic at BigQuery scale.
BigQuery metastore in action
Now, let’s take a look at how to use BigQuery metastore. The PySpark script below sets up a Spark environment to interact with a BigQuery storage table, a BigQuery table for Apache Iceberg, and a BigQuery external table. Detailed documentation is provided here.
To customize this script for your environment, simply replace the following variables:
-
WAREHOUSE_DIRECTORY: the URI of the Cloud Storage folder that contains your data warehouse -
CATALOG_NAME: the name of the catalog that you're using -
MATERIALIZATION_NAMESPACE: the namespace for storing temporary results
Learn more
With the BigQuery metastore, you now have a modern, serverless solution to meet your metadata management needs, enabling cross-engine interoperability with built-in governance. To try out BigQuery metastore today, see the documentation. If you would like to migrate from Dataproc Metastore to BigQuery metastore, see the documentation on migration tooling.


