Data loading best practices for AI/ML inference on GKE
Brian Kaufman
Senior Product Manager, Google
Akshay Ram
Group Product Manager, GKE
As AI models increase in sophistication, there’s increasingly large model data needed to serve them. Loading the models and weights along with necessary frameworks to serve them for inference can add seconds or even minutes of scaling delay, impacting both costs and the end-user’s experience.
For example, inference servers such as Triton, Text Generation Inference (TGI), or vLLM are packaged as containers that are often over 10GB in size; this can make them slow to download, and extend pod startup times in Kubernetes. Then, once the inference pod starts, it needs to load model weights, which can be hundreds of GBs in size, further adding to the data loading problem.
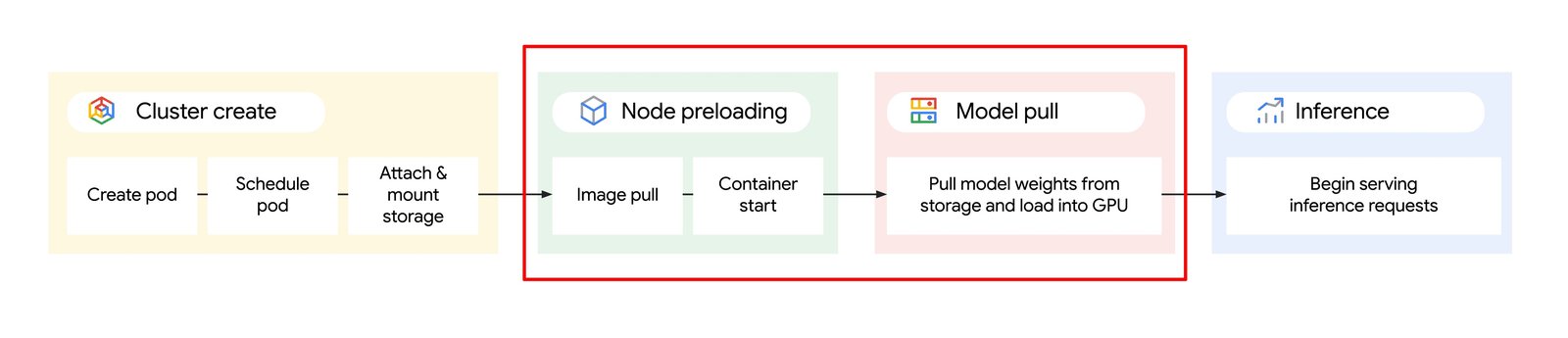
This blog explores techniques to accelerate data loading for both inference serving containers and downloading models + weights, so you can accelerate the overall time to load your AI/ML inference workload on Google Kubernetes Engine (GKE).
1. Accelerating container load times using secondary boot disks to cache container images with your inference engine and applicable libraries directly on the GKE node.
2. Accelerating model + weight load times from Google Cloud Storage with Cloud Storage Fuse or Hyperdisk ML.
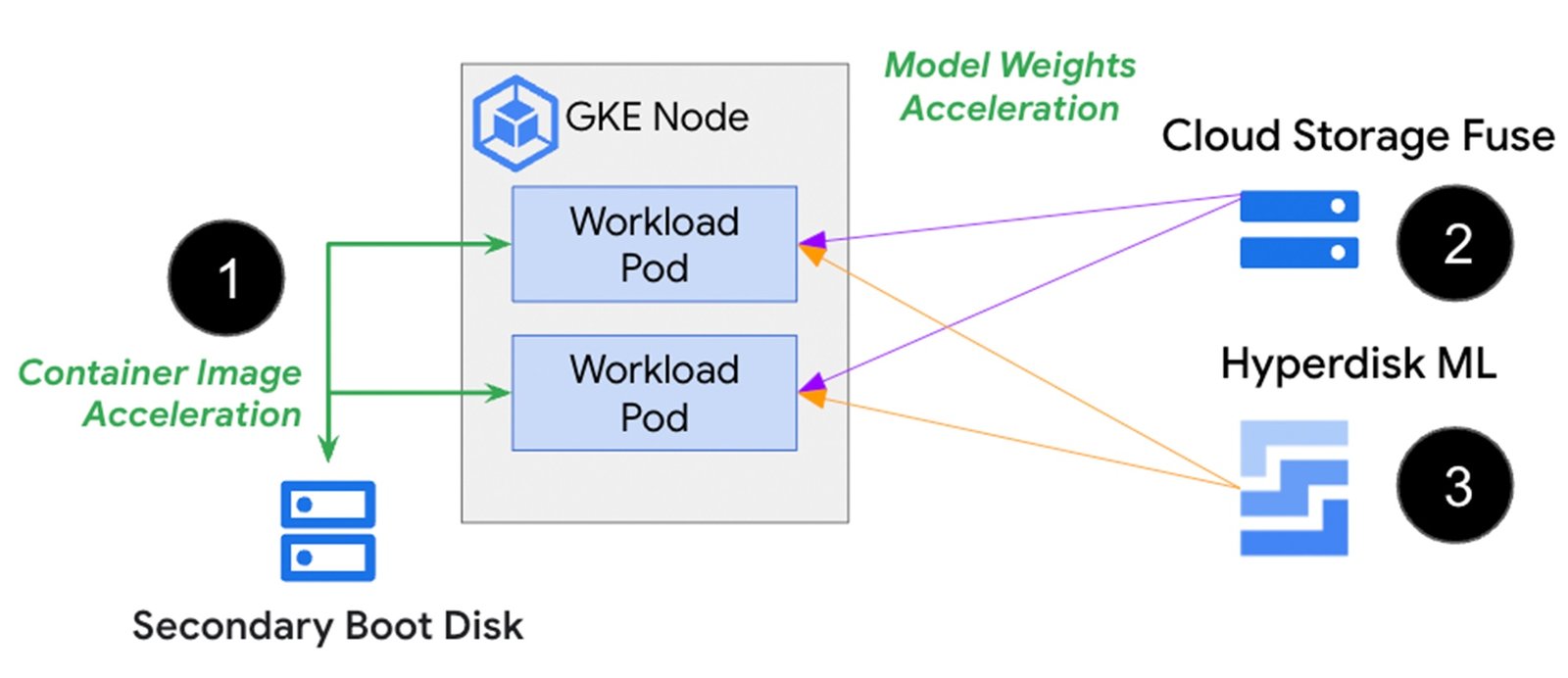
The image above shows a secondary boot disk (1) that stores the container image ahead of time, avoiding the image download process during pod/container startup. And for AI/ML inference workloads with demanding speed and scale requirements, Cloud Storage Fuse (2) and Hyperdisk ML (3) are options to connect the pod to model + weight data stored in Cloud Storage or a network attached disk. Let’s look at each of these approach in more detail below.
Accelerating container load times with secondary boot disks
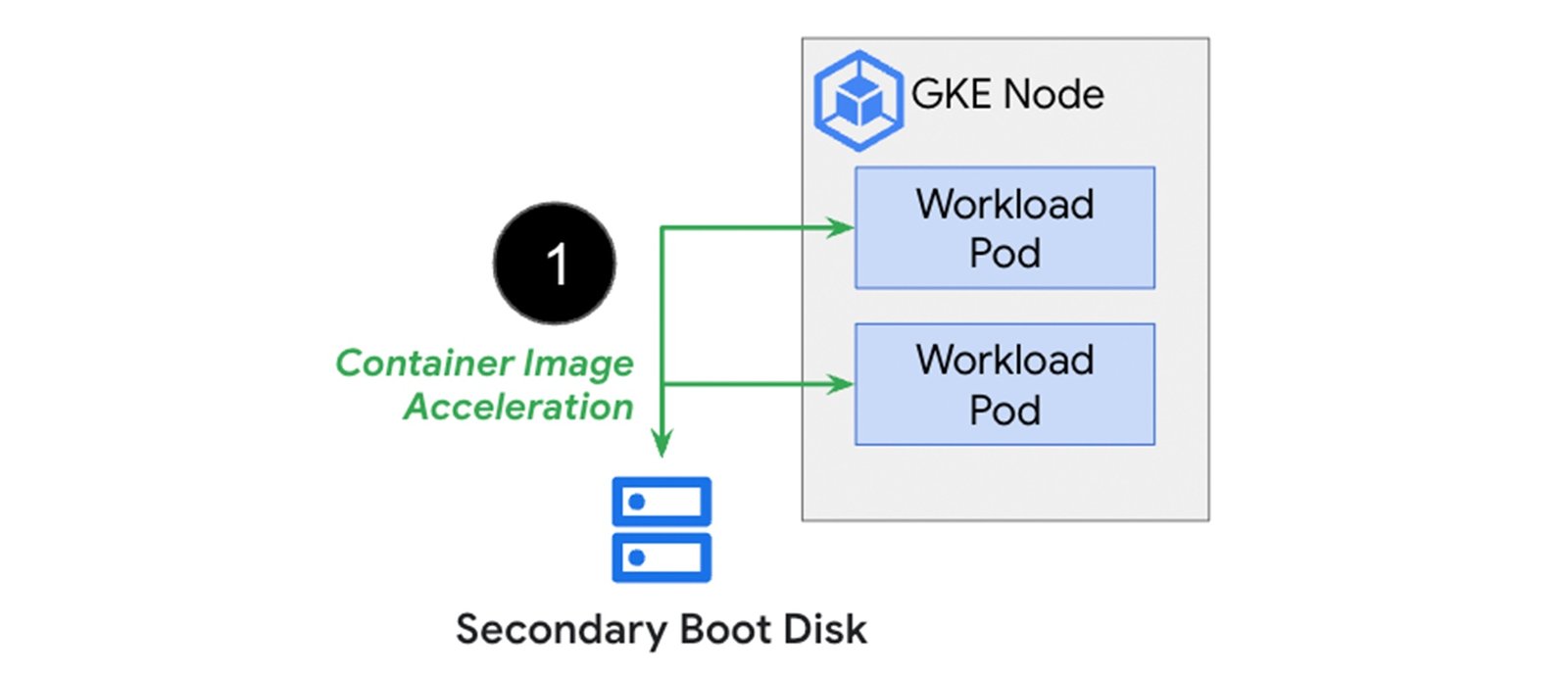
GKE lets you pre-cache your container image into a secondary boot disk that is attached to your node at creation time. The benefit of loading your containers this way is that you skip the image download step and can begin launching your containers immediately, which drastically improves startup time. The diagram below shows container image download times grow linearly with container image size. Those times are then compared with using a cached version of the container image that is pre-loaded on the node.
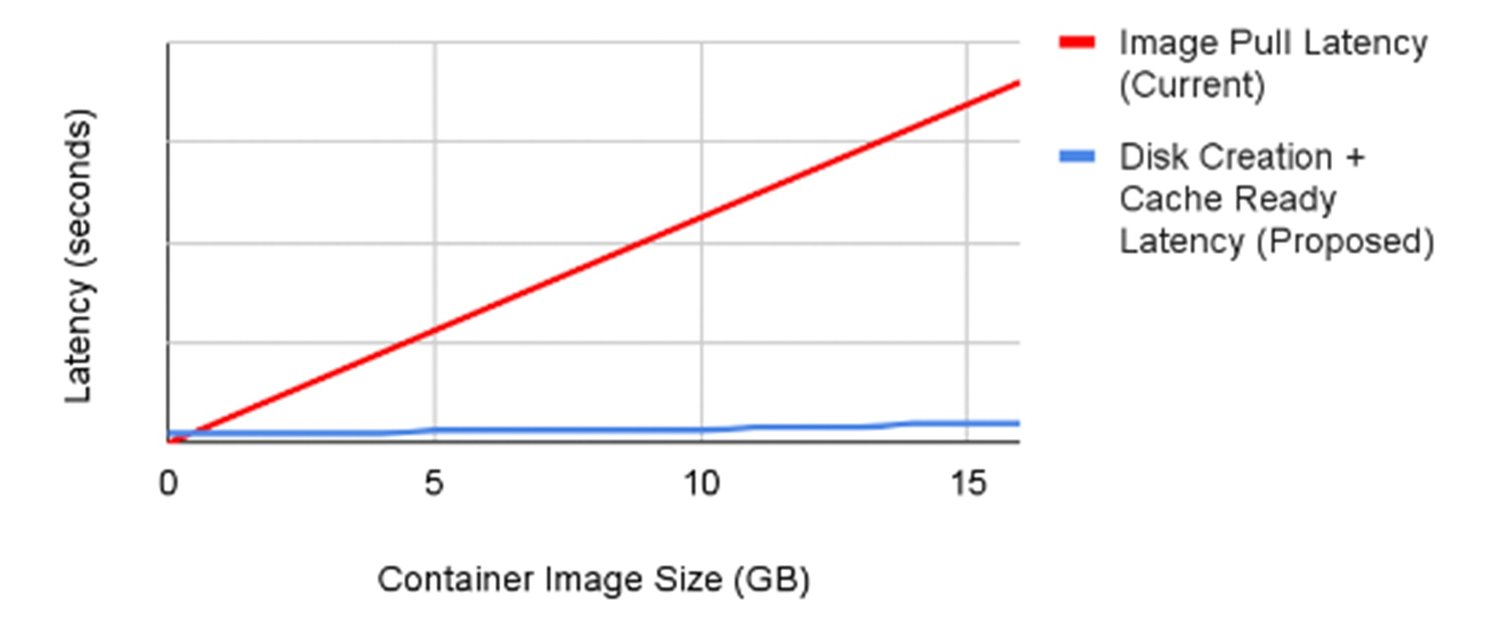
Caching a 16GB container image ahead of time on a secondary boot disk has shown reductions in load time of up to 29x when compared with downloading the container image from a container registry. Additionally, this approach lets you benefit from the acceleration independent of container size, allowing for large container images to be loaded predictably fast!
To use secondary boot disks, first create the disk with all your images, create an image out of the disk, and specify the disk image while creating your GKE node pools as a secondary boot disk. For more, see the documentation.
Accelerating model weights load times
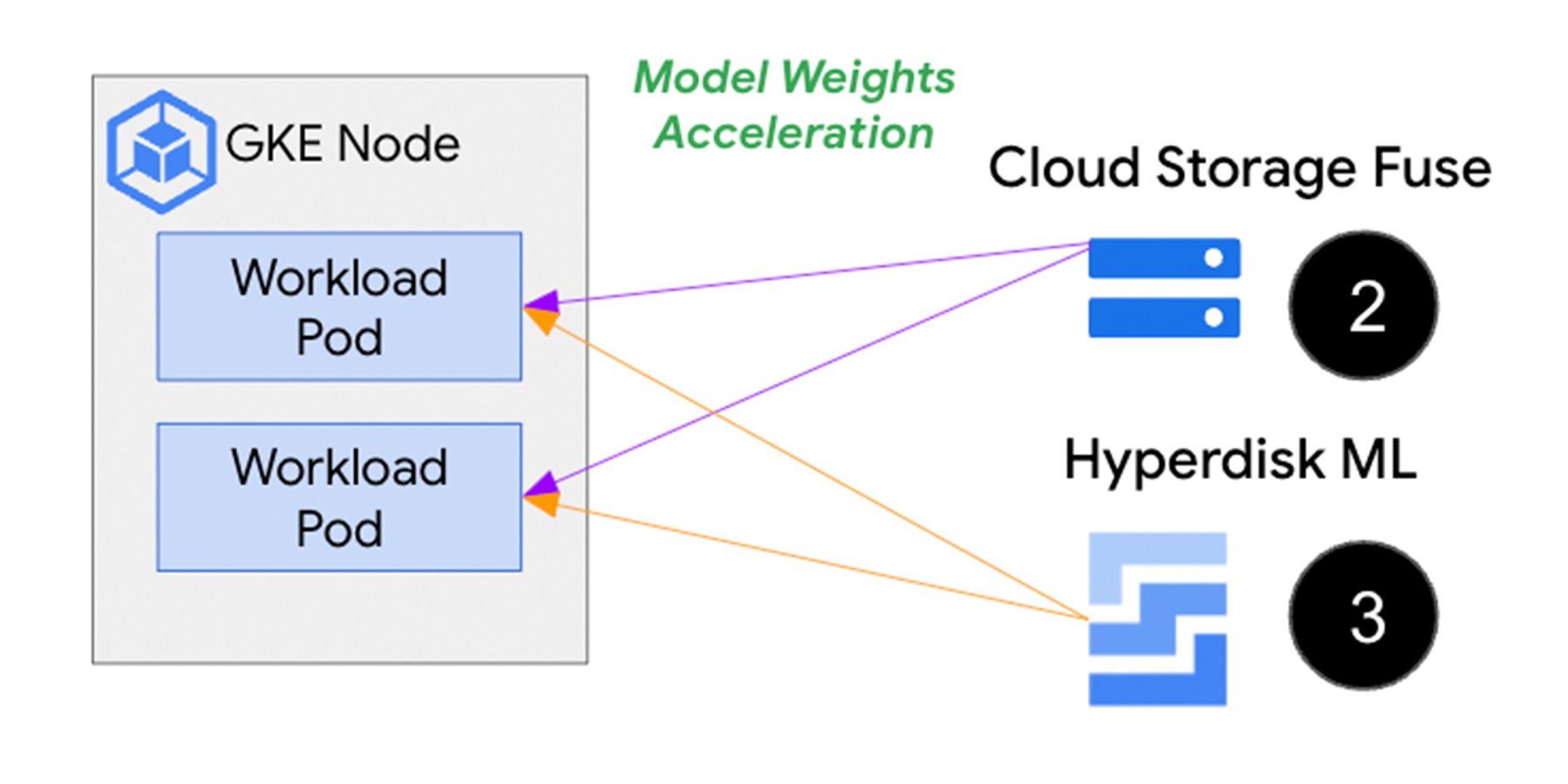
Many ML frameworks output their checkpoints (snapshots of model weights) to object storage such as Google Cloud Storage, a common choice for long-term storage. Using Cloud Storage as the source of truth, there are two main products to retrieve your data at the GKE-pod level: Cloud Storage Fuse and Hyperdisk ML (HdML).
When selecting one product or the other there are two main considerations:
-
Performance - how quickly can the data be loaded by the GKE node
-
Operational simplicity - how easy is it to update this data
Cloud Storage Fuse provides a direct link to Cloud Storage for model weights that reside in object storage buckets. Additionally there is a caching mechanism for files that need to be read multiple times to prevent additional downloads from the source bucket (which adds latency). Cloud Storage Fuse is appealing because there are no pre-hydration operational activities for a pod to do to download new files in a given bucket. It’s important to note that if you switch buckets that the pod is connected to, you will need to restart the pod with an updated Cloud Storage Fuse configuration. To further improve performance, you can enable parallel downloads, which spawns multiple workers to download a model, significantly improving model pull performance.
Hyperdisk ML gives you better performance and scalability than downloading files directly to the pod from Cloud Storage or other online location. Additionally, you can attach up to 2500 nodes to a single Hyperdisk ML instance, with aggregate bandwidth up 1.2 TiB/sec. This makes it a strong choice for inference workloads that span many nodes and where the same data is downloaded repeatedly in a read-only fashion. To use Hyperdisk ML, load your data on the Hyperdisk ML disk prior to using it, and again upon each update. Note that this adds operational overhead if your data changes frequently.
Which model+weight loading product you use depends on your use case. The table below provides a more detailed comparison of each:
As you can see there are other considerations besides throughput to take into account when architecting a performant model loading strategy.
Conclusion
Loading large AI models, weights, and container images into GKE-based AI models can delay workload startup times. By using a combination of the three methods described above — secondary boot disk for container images, Hyperdisk ML OR Cloud Storage Fuse for models + weights — get ready to accelerate data load times for your AI/ML inference applications.
Next steps:
