New GA Dataproc features extend data science and ML capabilities
Chris Crosbie
Product Manager, Data Analytics
The life of a data scientist can be challenging. If you’re in this role, your job may involve anything from understanding the day-to-day business behind the data to keeping up with the latest machine learning academic research. With all that a data scientist must do to be effective, you shouldn’t have to worry about migrating data environments or dealing with processing limitations associated with working with raw data.
Google Cloud’s Dataproc lets you run cloud-native Apache Spark and Hadoop clusters easily. This is especially helpful as data growth relocates data scientists and machine learning researchers from personal servers and laptops into distributed cluster environments like Apache Spark, which offers Python and R interfaces for data of any size. You can run open source data processing on Google Cloud, making Dataproc one of the fastest ways to extend your existing data analysis to cloud-sized datasets.
We’re announcing the general availability of several new Dataproc features that will let you apply the open source tools, algorithms, and programming languages that you use today to large datasets. This can be done without having to manage clusters and computers. These new GA features make it possible for data scientists and analysts to build production systems based on personalized development environments.
You can keep data as the focal point of your work, instead of getting bogged down with peripheral IT infrastructure challenges.
Here’s more detail on each of these features.
Streamlined environments with autoscaling and notebooks
With Dataproc autoscaling and notebooks, data scientists can work in familiar notebook environments that remove the need to change underlying resources or contend with other analysts for cluster processing. You can do this by combining Dataproc’s component gateway for notebooks with autoscaling GA,
With Dataproc autoscaling, a data scientist can work on their own isolated and personalized small cluster while running descriptive statistics, building features, developing custom packages, and testing various models. Once you’re ready to run your analysis on the full dataset, you can do the full analysis within the same cluster and notebook environment, as long as autoscaling is enabled. The cluster will simply grow to the size needed to process the full dataset and then scale itself back down when the processing is completed. You don’t need to waste time trying to move over to a larger server environment or figure out how to migrate your work.
Remember that when working with large datasets in a Jupyter notebook for Spark, you may often want to stop the Spark context that is created by default and instead use a configuration with larger memory limits, as shown in the example below.
#In Jupyter you have to stop the current context first
sc.stop()
#in this example, the driver program that runs is given access to all memory on the master
conf = (SparkConf().set(\"spark.driver.maxResultSize\", 0))
#restart the Spark context with your new configuration
sc = SparkContext(conf=conf)
Autoscaling and notebooks makes a great development environment for right-sizing cluster resources and working in a collaborative environment. Once you are ready to move from development to an automated process for production jobs, the Dataproc Jobs API makes this an easy transition.
Logging and monitoring for SparkR job types
The Dataproc Jobs API makes it possible to submit a job to an existing Cloud Dataproc cluster with jobs.submit call over HTTP, using the gcloud command-line tool or in the Google Cloud Platform Console itself. With the GA release of SparkR job type, you can have SparkR jobs logged and monitored, which makes it easy to build automated tooling around R code. The Jobs API also allows for separation between permissions of who has access to submit jobs on a cluster and who has permissions to reach the cluster itself. The Jobs API makes it possible for data scientists and analysts to schedule production jobs without setting up gateway nodes or networking configurations.
As shown in the below image, you can combine the Dataproc Jobs API with Cloud Scheduler’s HTTP target for automating tasks such as re-running jobs for operational pipelines or re-training ML models at predetermined intervals. Just be sure that the scope and service account used in the Cloud Scheduler job have the correct access permissions to all the Dataproc resources required.
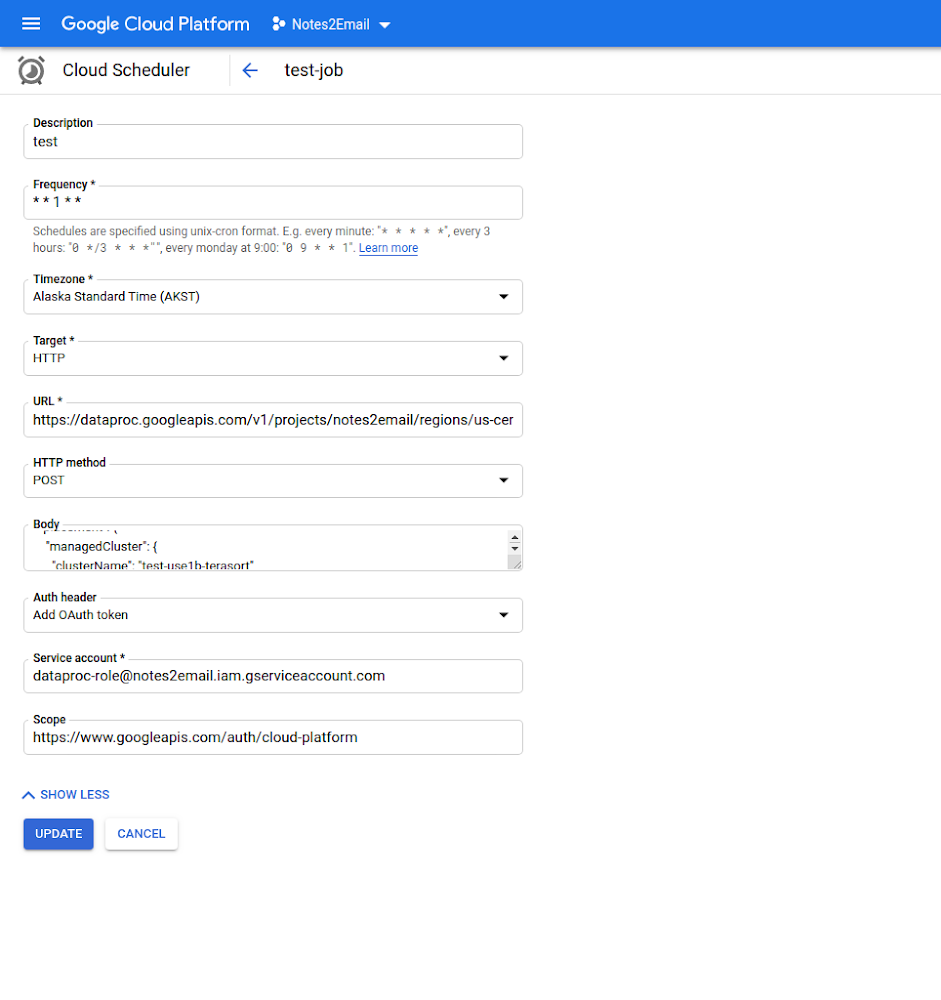
For more sophisticated tasks that involve running jobs with multiple steps or creating a cluster alongside the jobs, workflow templates offer another HTTP target that can be used from schedulers. For both workflow templates and Dataproc jobs, Cloud Scheduler is a good choice as a scheduling tool based on time. Cloud Functions is a good option if you prefer to run Dataproc jobs in response to new files in Cloud Storage or events in Pub/Sub. Cloud Composer is yet another scheduling option if your job needs to orchestrate data pipelines outside of Dataproc.
For more on moving R to the cloud and how customers are using the Dataproc Jobs API for SparkR, check out this blog post on SparkR and this Google Cloud Next ‘19 talk on Data Science at Scale with R on Google Cloud.
Accelerator support for GPUs
Often Spark and other Hadoop frameworks are preprocessing steps for creating datasets that are appropriate for deep learning models that use GPUs. With this in mind, Dataproc now offers support for attaching GPUs to clusters. This is another feature that unifies the processing environment for data scientists and saves analysts the time and hassle of re-configuring underlying cluster resources. In a single workflow template, you can automate a series of jobs that mixes and matches Spark ML and GPU-based deep learning algorithms.
For datasets that need to scale beyond the memory of a single GPU, RAPIDS on Dataproc is a framework that uses both GPUs and Dataproc’s ability to launch and control a cluster of VMs with API calls. To get started with RAPIDS on Dataproc, check out the RAPIDS initialization action and the associated example notebooks based on NYC taxi data.
Scheduled cluster deletion
Often times, you may have spent your day building a model or tweaking that SQL query to pull back the cohort of information you need from a massive dataset. You click “run” to kick off a long-running job and head home for the weekend. When Monday comes, the results are ready for review. While using the autoscaler to utilize more compute resources is one way to help get answers faster, there will inevitably be long-running queries and jobs that go unattended.
To make sure you do not overpay for these unattended jobs, use cluster scheduled deletion to automatically delete a cluster after a specified idle period when submitting a job using the Dataproc Jobs API. That way, you can leave for the weekend and not have to worry about continuing to check in on when you can delete the cluster and stop paying for Dataproc clusters to be running. Cluster scheduled deletion offers two additional options for time-based deletion that will make sure you stop paying for Dataproc clusters if you forget to delete the cluster when you leave for the day or if you inadvertently leave your cluster running.


