Announcing the beta release of SparkR job types in Cloud Dataproc

Christopher Crosbie
Product Manager, Data Analytics
Mikhail Chrestkha
Applied AI Solutions Manager
The R programming language is often used for building data analysis tools and statistical apps, and cloud computing has opened up new opportunities for those of you developing with R. Google Cloud Platform (GCP) lets you store a massive amount of data cost-effectively, then take advantage of managed compute resources only when you’re ready to scale your analysis.
We’re pleased to announce the beta release of SparkR jobs on Cloud Dataproc, which is the latest chapter in building R support on GCP. SparkR is a package that provides a lightweight front end to use Apache Spark from R. This integration lets R developers use dplyr-like operations on datasets of nearly any size stored in Cloud Storage. SparkR also supports distributed machine learning using MLlib. You can use this integration to process against large Cloud Storage datasets or perform computationally intensive work.
Cloud Dataproc is GCP’s fully managed cloud service for running Apache Spark and Apache Hadoop clusters in a simple and cost-efficient way. The Cloud Dataproc Jobs API makes it easy to submit SparkR jobs to a cluster without having to open firewalls to access web-based IDEs or SSH directly onto the master node. With the Jobs API, you can automate the repeatable R statistics you want to run on your datasets.
Using GCP for R lets you avoid the infrastructure barriers that used to impose limits on understanding your data, such as choosing which datasets to sample because of compute or data size limits. With GCP, you can build large-scale models to analyze datasets of sizes that previously would have required huge upfront investments in high-performance computing infrastructures.
What happens when you move R to the cloud?
When you move R to the cloud, you’ll see the familiar RStudio interface that has served you well in prior R endeavors. While the SparkR Jobs API offers an easy way to execute SparkR code and automate tasks, most R developers will still perform the exploratory analysis using RStudio. Here’s an overview of this setup:
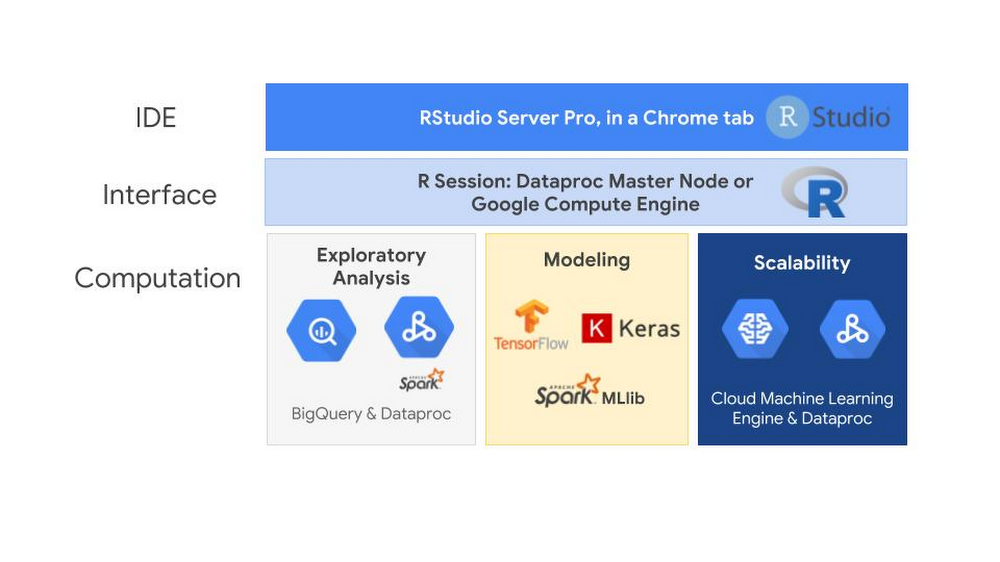
The interface running the RStudio server could be running on either a Cloud Dataproc master node, a Google Compute Engine virtual machine or even somewhere outside of GCP entirely. One of the advantages of using GCP is that you only need to pay for the RStudio server while it is in use. You can create an RStudio server and shut it off when you’re not using it. This pay-as-you go system also applies to RStudio Pro, the commercial distribution of RStudio.
The computation engines available in GCP is where using R in the cloud can really expand your statistical capabilities.The bigrquery package makes it easy to work with data stored in BigQuery by allowing you to query BigQuery tables and retrieve metadata about your projects, datasets, tables, and jobs. The SparkR package, when run on Cloud Dataproc, makes it possible to use R to analyze and structure the data stored in Cloud Storage.
Once you have explored and prepared your data for modeling, you can use TensorFlow, Keras and Spark MLlib libraries. You can use the R interface to Tensorflow to work with the high-level Keras and Estimator APIs, and when you need more control, it provides full access to the core TensorFlow API. SparkR jobs on Dataproc allow you to train and score Spark MLlib models at scale. To train and host TensorFlow and Keras models at scale, you can use the R interface to Cloud Machine Learning (ML) Engine and let GCP manage the resources for you.
GCP offers an end-to-end managed environment for building, training and scoring models in R. Here’s how to connect all these services in your R environment.
Using RStudio: A familiar friend

The first step for most R developers is finding a way to use RStudio. While connecting to the cloud from your desktop is an option, many users prefer to have a cloud-based server version of RStudio. This helps you pick up your desktop settings from wherever you’re working, keep a backup of your work outside your personal computer, and put RStudio on the same network as your data sources. Taking advantage of Google’s high-performance network is something that can greatly improve your R performance when you move data into R’s memory space from other parts of the cloud.
If you plan to use Cloud Dataproc, you can follow this tutorial to install the open source version of RStudio server on Cloud Dataproc’s master node and access the web UI security over an SSH SOCKS tunnel. An advantage to running RStudio on Cloud Dataproc is that you can take advantage of Cloud Dataproc Autoscaling (currently in alpha). With autoscaling, you can have a minimum cluster size as you are developing your SparkR logic. Once you submit your job for large-scale processing, you don’t need to do anything different or worry about modifying your server. You simply submit your SparkR job to RStudio, and the Dataproc cluster scales to meet the needs of your job within the intervals that you set.
RStudio Pro, the commercial distribution of RStudio, has a few advantages over the open source version. RStudio Server Pro provides features such as team productivity, security, centralized management, metrics, and commercial support directly from RStudio.
You can even launch a production-ready deployment of RStudio Pro directly from the Google Cloud Marketplace in a matter of minutes. The instructions in the next section provide guidance on how to deploy RStudio Pro.
Launch an instance of RStudio Server Pro from Cloud Launcher (optional)
Cloud Marketplace contains hundreds of development stacks, solutions, and services optimized to run on GCP via one-click deployment.
To launch RStudio Pro, you use the search bar at the top of the screen:
- Type RStudio in the Cloud Launcher search bar.
- Click RStudio Server Pro.
- Click Launch on Compute Engine.
Follow the instructions. When successful, you should see a screen similar to the one below.
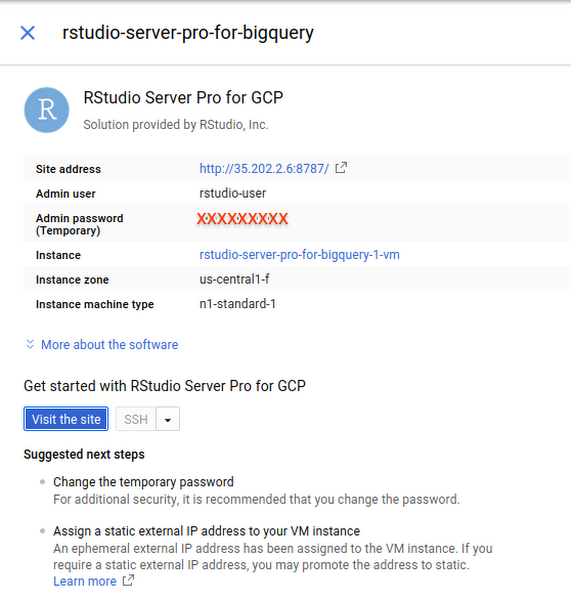
A quick note on pricing: The page for launching an instance of RStudio Server Pro includes an estimated costs table. To the left, it also says: “Estimated costs are based on 30-day, 24 hours per day usage in Central US region. Sustained use discount is included.” However, note that most individual users use their instances intermittently and shouldn’t expect the estimated costs provided in that table. GCP has a pay-as-you-go pricing model calculated on a per-second usage basis.
Submitting SparkR jobs from Cloud Dataproc
Once you’ve connected R to Google Cloud, you can submit SparkR jobs using the new beta release in Cloud Dataproc. Here’s how to do that:
1. Click Jobs on the left-hand side of the Dataproc user interface.2. Choose a job type of “SparkR” from the Job Type drop-down menu.
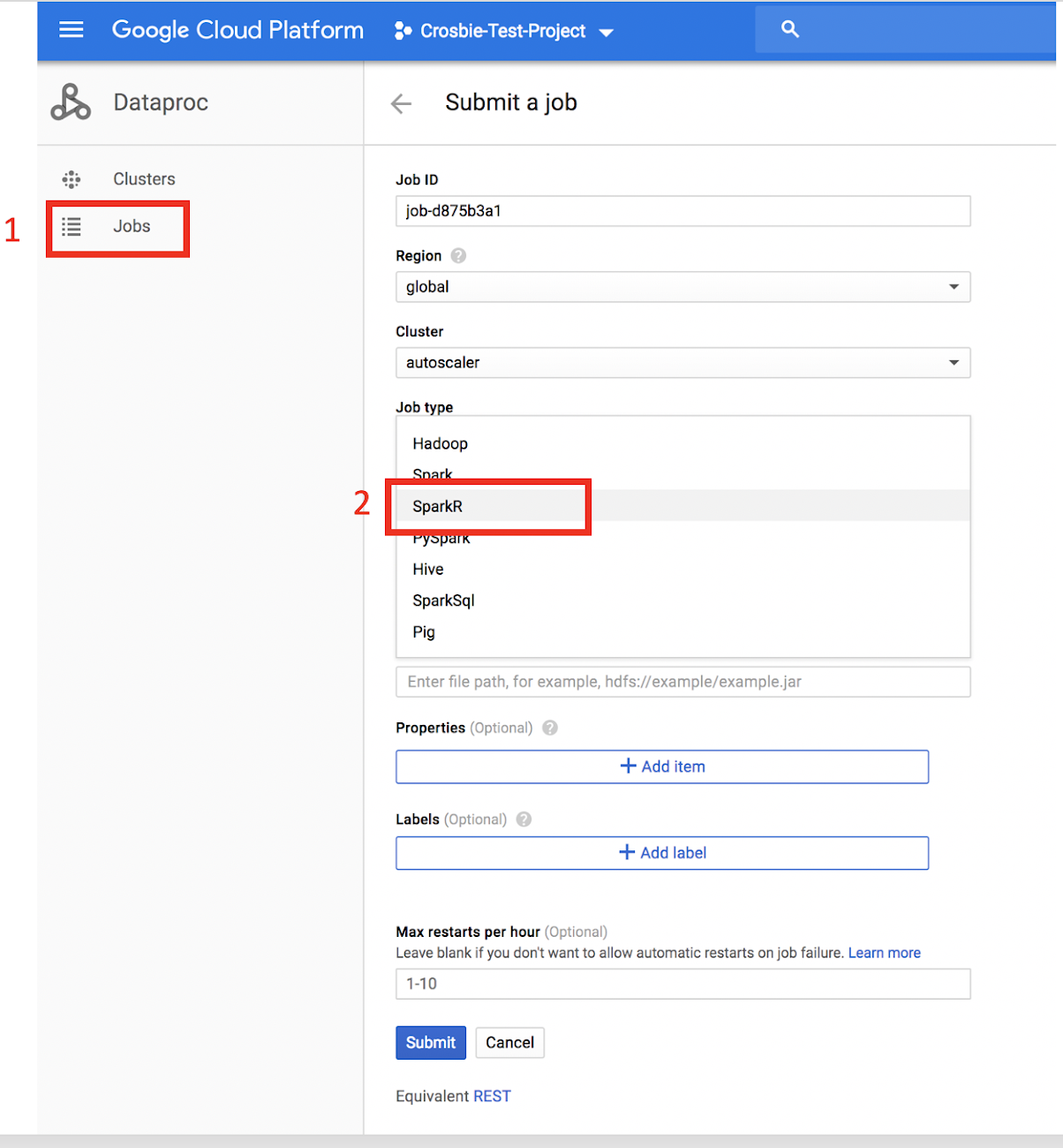
3. Populate the name of an R file you want to run that is stored either on the cluster or in Cloud Storage (capital R filename required).
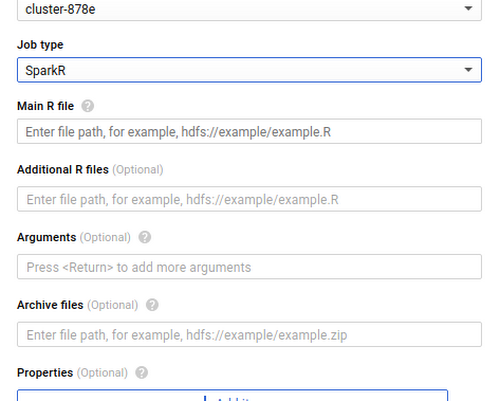
SparkR jobs can also be used in either the gcloud beta or API. This makes it easy to automate SparkR processing steps so you can retrain models on complete datasets, pre-process data that you send to Cloud ML Engine, or generate tables for BigQuery from unstructured datasets in Cloud Storage.
When submitting a SparkR job, be sure to require the SparkR package and start the SparkR session at the top of your script.
An example job output is displayed here:
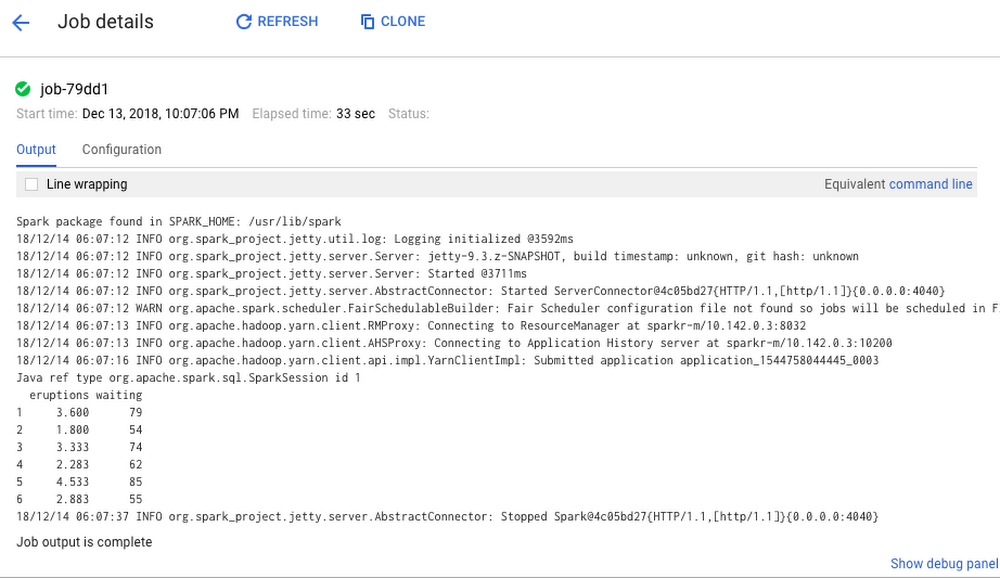
Connecting R to the rest of GCP
As mentioned earlier, the R community has created many packages for interacting with GCP. The following instructions can serve as a cheat sheet for quickly getting up and running with the most common packages and tools used by R developers on GCP, including SparkR.
Prerequisite Python dependencies for TensorFlow stack for RStudio
TensorFlow for R has two low-level Python dependencies that are difficult to install from within RStudio. If you are using RStudio Server Pro, you can SSH into the machine and run:
At the time of this writing, Tensorflow is not supported directly on Cloud Dataproc due to incompatibility of operating system support.
Install additional R packages
To generate an R session with the GCP integrations described above, run the following command in the R console:
This step takes a few minutes. TensorFlow and Keras also restart your R session during installation.
After installation is complete, execute the following command to confirm that the installation was successful:
You can also (optionally) try out a quick check on your BigQuery by querying a public dataset:
Define the connection to BigQuery from R:
Then upload and collect jobs:
And look at query results:
Install the cloudml package
The cloudml package is a high-level interface between R and Cloud ML Engine, Google’s platform for building massive machine learning models and bringing them to production. Cloud ML Engine provides a seamless interface for accessing cloud resources, letting you focus on model development, data processing, and inference. To get started with the cloudml package:
1. Install the rstudio/cloudml package from GitHub with devtools:
2. After cloudml is installed, install the Google Cloud SDK (gcloud) to interact with your Google Cloud account from within R.
When you run gcloud_install, a few questions appear.
3. Press ENTER to use the default values of the questions:
- Do you want to help improve the Google Cloud SDK (Y/N)?
- Do you want to continue (Y/N)?
- Enter a path to an rc file to update, or leave blank to use [/home/rstudio-user/.bashrc]:
4. When asked which account you want to use to perform operations for this configuration, select the first account in the project (the default service account).
5. Enter the Google Cloud project ID.
Using R in the cloud
This is just the start of the ways we have seen customers delving into GCP and the R ecosystem. The architecture diagram below shows an example of a full deployment of R on Google Cloud Platform for building deep learning models.
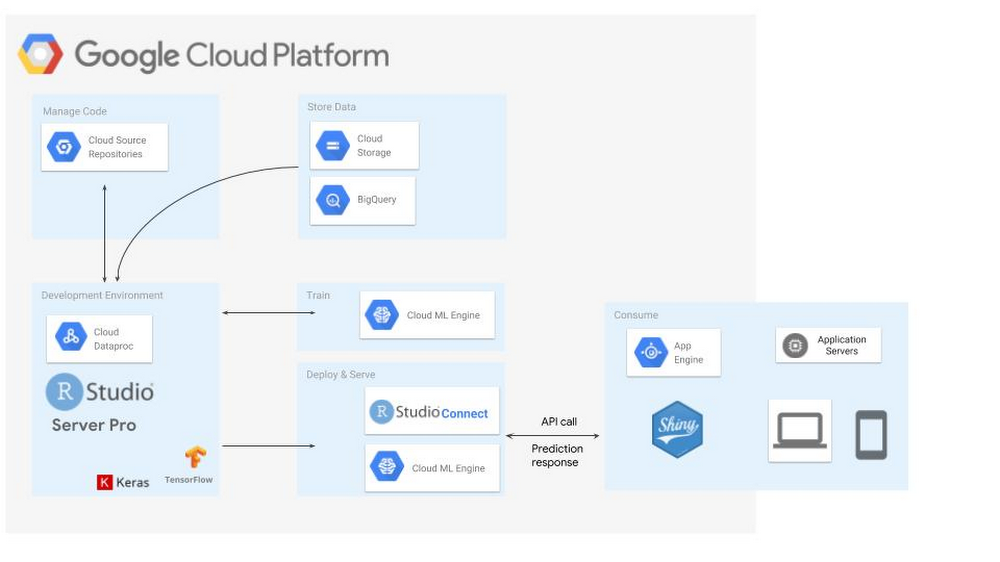
To learn more about this architecture and how to get started with R on Google Cloud, check out this Next ’18 session on Getting Started with Deep Learning Models in R using Google Cloud and RStudio.
For more on getting started with SparkR, check out this post or the Apache SparkR documentation.
Thanks to additional contributor Michael Quinn, quantitative analyst at Google.



