Run Apache Spark and Apache Hadoop workloads with the flexibility and predictability of Cloud Dataproc
James Malone
Product Manager, Google Cloud
One major advantage of open source software is its dynamic nature—an active development community can provide frequent updates, useful fixes, and innovative features. As the recently announced merger of Apache Hadoop vendors shows, the businesses that support open source software development are also subject to market changes over time. Recently, customers have asked: what does this news mean for running Apache Spark and Hadoop in the cloud? Instead of creating uncertainty, the recent market changes underscore the benefits of running cloud-native managed Spark and services, such as Cloud Dataproc, which helps to reduce uncertainty and to provide flexibility in the following three ways:
It provides software and hardware flexibility
It offers predictable and transparent pricing with ephemeral use
It offers the latest innovations while providing stability and support
Software and hardware flexibility
When you create a Cloud Dataproc cluster, you start by selecting from one of many Cloud Dataproc versions. Additionally, you can configure optional components and initialization actions to expand the number of components running on your clusters. To save any customizations for re-use, you can deploy a custom image in order to share a customized Cloud Dataproc image across an entire project. All of these features make it easy to create clusters suited for specific tasks and enable customers to easily use several clusters, all running different software, without management headaches.
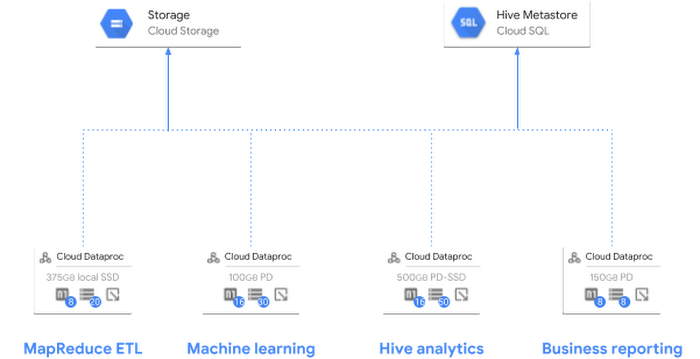
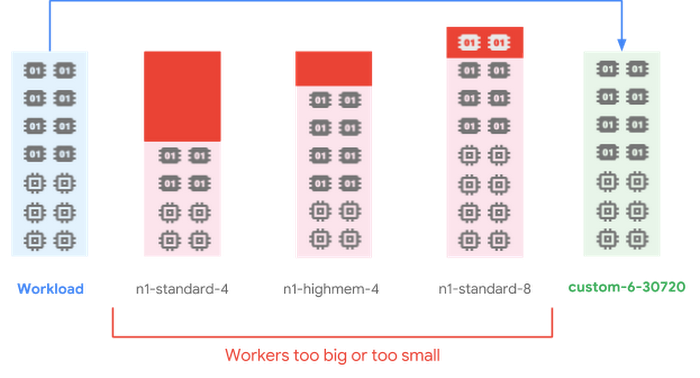
Each cluster’s hardware configuration is also important, which is why Cloud Dataproc offers several options to customize the cluster’s hardware properties. In addition to standard machine types Cloud Dataproc clusters also support custom machine types. Custom machines allow you to specify the number of cores and amount of memory in each worker, so you can be sure the cluster has exactly the resources it needs.
Predictable, transparent pricing with ephemeral use
Customers who are migrating to the cloud from on-premises datacenters often share a common complaint: their uncertainty around the costs invested in and benefits derived from their existing investments in Spark and Hadoop. Cloud economics can mitigate some of these concerns—Cloud Dataproc is specifically designed to stabilize pricing, even when you use your cluster ephemerally.
Since Cloud Dataproc pricing is based on resources consumed, it’s relatively easy to predict costs. You can project future costs with the Google Cloud Platform Pricing Calculator, or if you want to lower and secure future costs, you can also sign up for committed use discounts, and Cloud Dataproc will automatically apply them to your billing statement. Determining your Cloud Dataproc costs to date is also easy by filtering billing data using the automatically-applied Cloud Dataproc labels. For example, you can use the label goog-dataproc-location to filter Cloud Dataproc billing data by region.
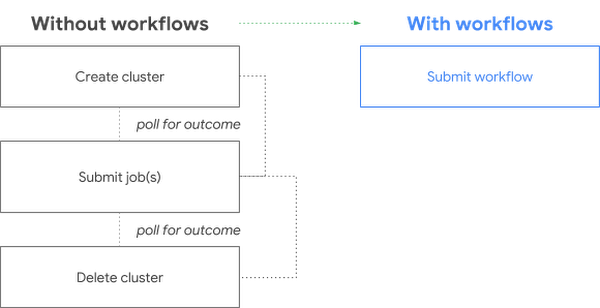
In addition to modeling and understanding costs, we designed Cloud Dataproc to let you easily control costs for new and existing clusters. For non-critical workloads, you can use preemptible virtual machines allow you to lower compute costs. Customers also often expressed concern that someone will forget to delete an unused cluster, so we developed scheduled deletion. Finally, we recently made workflow templates generally available that allow you to create a cluster, run a set of work, and delete a cluster all in one operation, so that you pay only for your exact usage.
Innovation combined with stability and support
Google played a role in the creation of the Apache Hadoop ecosystem with the release of the MapReduce paper. With Cloud Dataproc, we continue to contribute to the Spark and Hadoop open source communities today. One common concern from customers moving into cloud is: what happens when I discover a bug in the open source stack? In these cases, we often create patches (you can find an example here), apply them to Cloud Dataproc, and also release them upstream. We aren’t just focused solely on fixes: we also contribute new features to the open source codebase for Cloud Dataproc and release them back to the community (example, this).
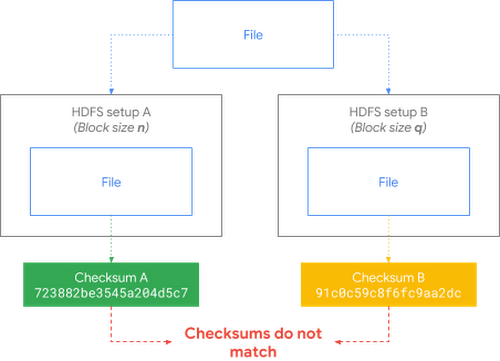
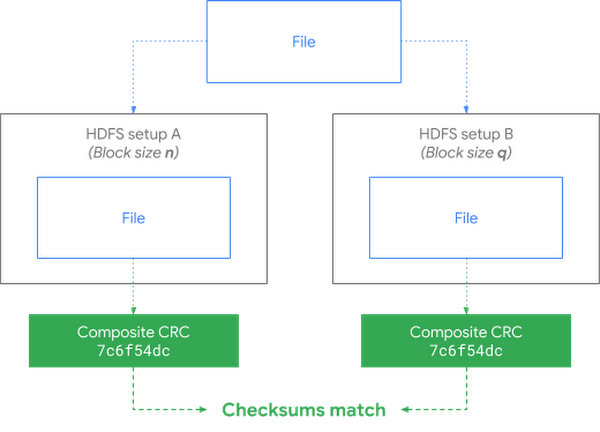
Importantly, we also design new features and open-source them to solve common customer pains. You can take a look at one example, the HDFS-13056 patch. This change allows HDFS to compare files even if it is configured differently cluster to cluster.This is an important capability for customers moving files from on-premises HDFS to cloud targets like Cloud Storage.
With Cloud Dataproc and other managed cloud services, you have access to support for both the infrastructure and the software all in one place. Instead of worrying about who you should call or whether your issue will be passed around, we provide you with a single point of contact. GCP tools like Google Stackdriver also make management of your cloud resources, including Cloud Dataproc clusters, very easy.
Get started with Cloud Dataproc
While recent market news around Spark and Hadoop may have caused some uncertainty, Cloud Dataproc is ready for use today, to bring flexibility, predictability, and certainty to your data processing workloads. You can test out Cloud Dataproc right now with one of our quickstarts or how-to guides.

