AI in Depth: Cloud Dataproc meets TensorFlow on YARN: Let TonY help you train right in your cluster
Gonzalo Gasca Meza
Developer Programs Engineer, Google
Keqiu Hu
Staff Software Engineer, LinkedIn
Apache Hadoop has become an established and long-running framework for distributed storage and data processing. Google’s Cloud Dataproc is a fast, easy-to-use, fully managed cloud service for running Apache Spark and Apache Hadoop clusters in a simple, cost-efficient way. With Cloud Dataproc, you can set up a distributed storage platform without worrying about the underlying infrastructure. But what if you want to train TensorFlow workloads directly on your distributed data store?
This post will explain how to install a Hadoop cluster for LinkedIn open-source project TonY (TensorFlow on YARN). You will deploy a Hadoop cluster using Cloud Dataproc and TonY to launch a distributed machine learning job. We’ll explore how you can use two of the most popular machine learning frameworks: TensorFlow and PyTorch.
TensorFlow supports distributed training, allowing portions of the model’s graph to be computed on different nodes. This distributed property can be used to split up computation to run on multiple servers in parallel. Orchestrating distributed TensorFlow is not a trivial task and not something that all data scientists and machine learning engineers have the expertise, or desire, to do—particularly since it must be done manually. TonY provides a flexible and sustainable way to bridge the gap between the analytics powers of distributed TensorFlow and the scaling powers of Hadoop. With TonY, you no longer need to configure your cluster specification manually, a task that can be tedious, especially for large clusters.
The components of our system:
First, Apache Hadoop
Apache Hadoop is an open source software platform for distributed storage and distributed processing of very large data sets on computer clusters built from commodity hardware. Hadoop services provides for data storage, data processing, data access, data governance, security, and operations.
Next, Cloud Dataproc
Cloud Dataproc is a managed Spark and Hadoop service that lets you take advantage of open source data tools for batch processing, querying, streaming, and machine learning. Cloud Dataproc’s automation capability helps you create clusters quickly, manage them easily, and save money by turning clusters off when you don't need them. With less time and money spent on administration, you can focus on your jobs and your data.
And now TonY
TonY is a framework that enables you to natively run deep learning jobs on Apache Hadoop. It currently supports TensorFlow and PyTorch. TonY enables running either single node or distributed training as a Hadoop application. This native connector, together with other TonY features, runs machine learning jobs reliably and flexibly.
Installation
Setup a Google Cloud Platform project
Get started on Google Cloud Platform (GCP) by creating a new project, using the instructions found here.
Create a Cloud Storage bucket
Then create a Cloud Storage bucket. Reference here.
Create a Hadoop cluster via Cloud Dataproc using initialization actions
You can create your Hadoop cluster directly from Cloud Console or via an appropriate `gcloud` command. The following command initializes a cluster that consists of 1 master and 2 workers:
When creating a Cloud Dataproc cluster, you can specify in your TonY initialization actions script that Cloud Dataproc should run on all nodes in your Cloud Dataproc cluster immediately after the cluster is set up.
Note: Use Cloud Dataproc version 1.3-deb9, which is supported for this deployment. Cloud Dataproc version 1.3-deb9 provides Hadoop version 2.9.0. Check this version list for details.
Once your cluster is created. You can verify that under Cloud Console > Big Data > Cloud Dataproc > Clusters, that cluster installation is completed and your cluster’s status is Running.
Go to Cloud Console > Big Data > Cloud Dataproc > Clusters and select your new cluster:
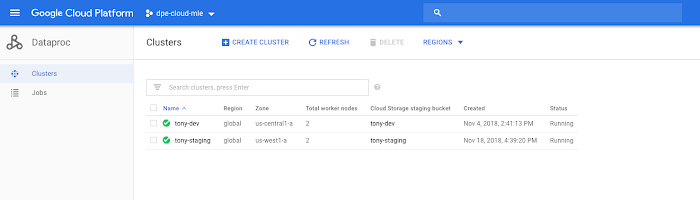
You will see the Master and Worker nodes.
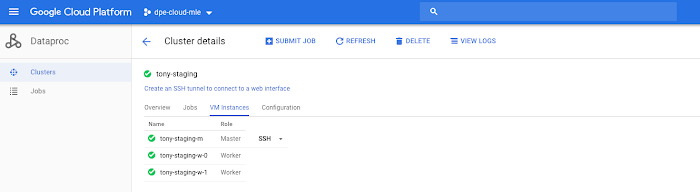
Connect to your Cloud Dataproc master server via SSH
Click on SSH and connect remotely to Master server.
Verify that your YARN nodes are active
Example
Installing TonY
TonY’s Cloud Dataproc initialization action will do the following:
Install and build TonY from GitHub repository.
Create a sample folder containing TonY examples, for the following frameworks:
TensorFlow
PyTorch
The following folders are created:
TonY install folder (TONY_INSTALL_FOLDER) is located by default in:
- TonY samples folder (TONY_SAMPLES_FOLDER) is located by default in:
The Tony samples folder will provide 2 examples to run distributed machine learning jobs using:
- TensorFlow MNIST example
- PyTorch MNIST example
Running a TensorFlow distributed job
Launch a TensorFlow training job
You will be launching the Dataproc job using a `gcloud` command.
The following folder structure was created during installation in `TONY_SAMPLES_FOLDER`, where you will find a sample Python script to run the distributed TensorFlow job.
This is a basic MNIST model, but it serves as a good example of using TonY with distributed TensorFlow. This MNIST example uses “data parallelism,” by which you use the same model in every device, using different training samples to train the model in each device. There are many ways to specify this structure in TensorFlow, but in this case, we use “between-graph replication” using tf.train.replica_device_setter.
Dependencies
TensorFlow version 1.9
Note: If you require a more recent TensorFlow and TensorBoard version, take a look at the progress of this issue to be able to upgrade to latest TensorFlow version.
Connect to Cloud Shell
Open Cloud Shell via the console UI:
Use the following gcloud command to create a new job. Once launched, you can monitor the job. (See the section below on where to find the job monitoring dashboard in Cloud Console.)
Running a PyTorch distributed job
Launch your PyTorch training job
For PyTorch as well, you can launch your Cloud Dataproc job using gcloud command.
The following folder structure was created during installation in the TONY_SAMPLES_FOLDER, where you will find an available sample script to run the TensorFlow distributed job:
Dependencies
- PyTorch version 0.4
- Torch Vision 0.2.1
Launch a PyTorch training job
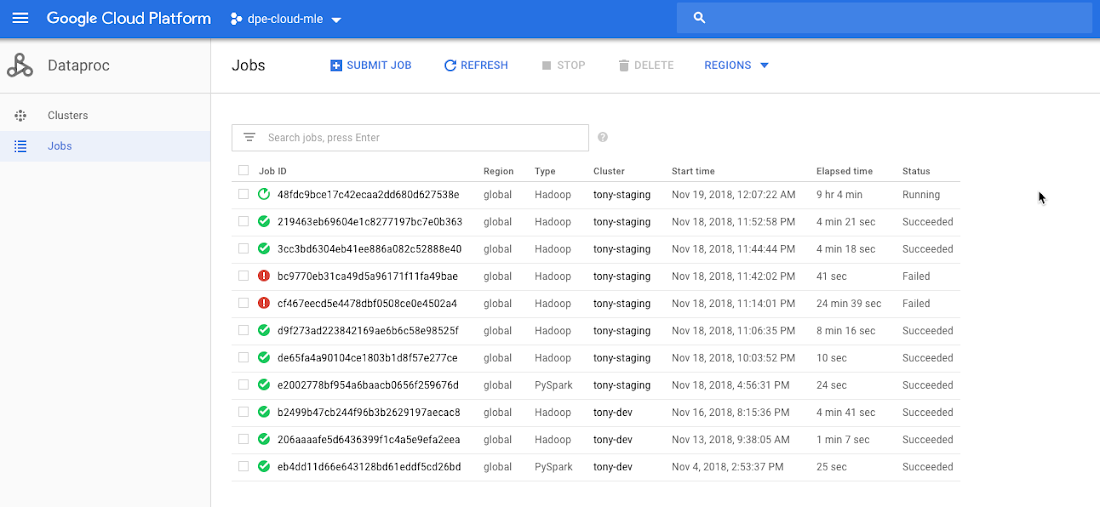
Verify your job is running successfully
You can track Job status from the Dataproc Jobs tab: navigate to Cloud Console > Big Data > Dataproc > Jobs.
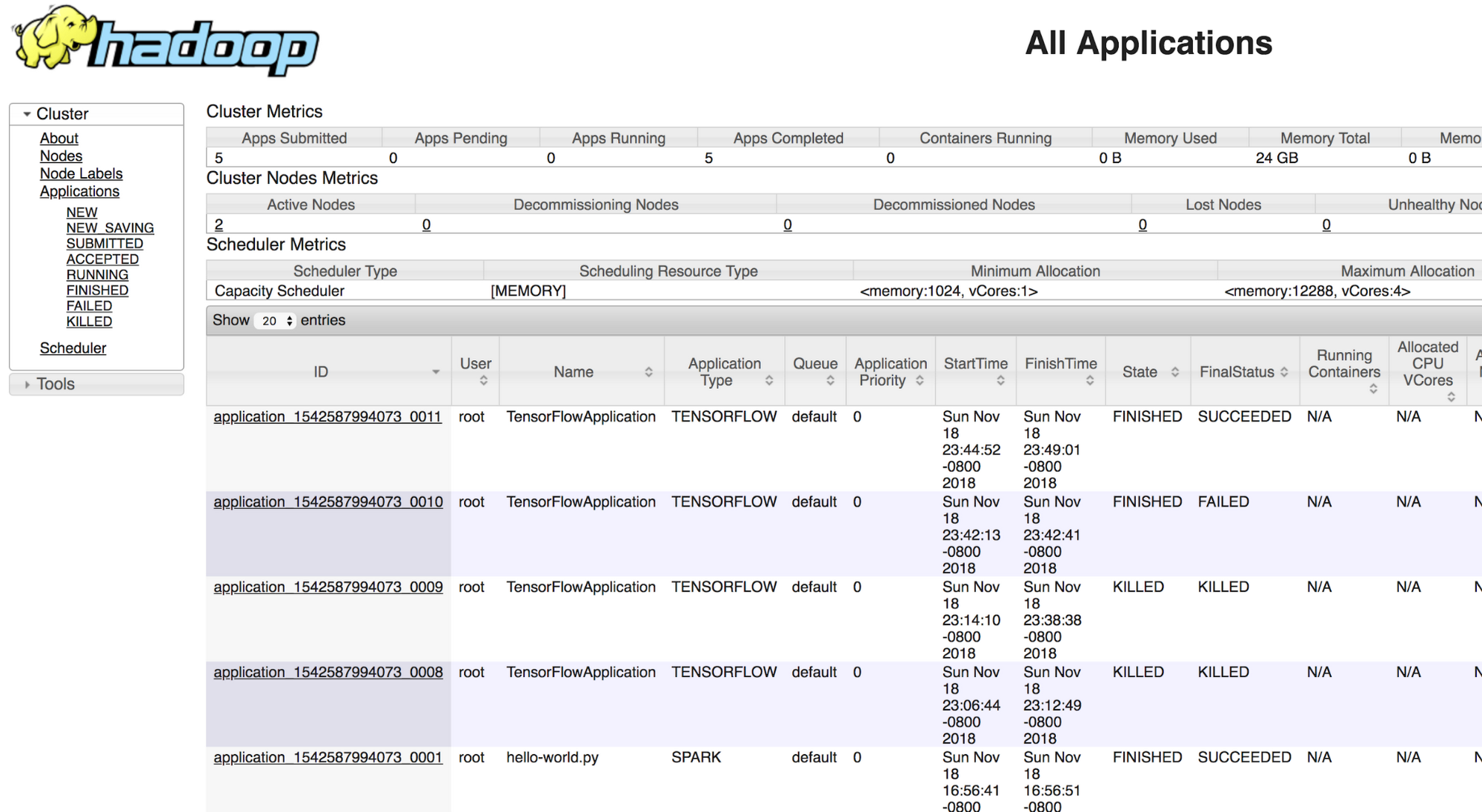
Access your Hadoop UI
Logging via web to Cloud Dataproc’s master node via web: http://<Node_IP>:8088 and track Job status. Please take a look at this section to see how to access the Cloud Dataproc UI.
Cleanup resources
Delete your Cloud Dataproc cluster
Conclusion
Deploying TensorFlow on YARN enables you to train models straight from your data infrastructure that lives in HDFS and Cloud Storage. If you’d like to learn more about some of the related topics mentioned in this post, feel free to check out the following documentation links:
Acknowledgements: Anthony Hsu, LinkedIn Software Engineer; and Zhe Zhang, LinkedIn Core Big Data Infra team manager.



