このドキュメントは、Oracle® 11g/12c データベースから Cloud SQL for PostgreSQL バージョン 12 への移行を計画し、実施する際に必要な情報とガイダンスを提供するシリーズの一つです。このシリーズには、最初の設定のパートに加えて、次のパートが含まれています。
- Oracle ユーザーの Cloud SQL for PostgreSQL への移行: 用語と機能(このドキュメント)
- Oracle から Cloud SQL for PostgreSQL への移行: データ型、ユーザー、テーブル
- Oracle から Cloud SQL for PostgreSQL への移行: クエリ、ストアド プロシージャ、関数、トリガー
- Oracle から Cloud SQL for PostgreSQL への移行: セキュリティ、オペレーション、モニタリング、ロギング
- Oracle Database のユーザーとスキーマを Cloud SQL for PostgreSQL に移行する
用語
このセクションでは、Oracle と Cloud SQL for PostgreSQL のデータベース用語の類似点と相違点の詳細について説明します。また、それぞれのデータベース プラットフォームの主な要素を確認して比較します。この比較では、アーキテクチャ上の違いから Oracle バージョン 11g と 12c を区別しています(たとえば、Oracle 12c ではマルチテナント機能を導入しています)。ここで言及している Cloud SQL for PostgreSQL のバージョンは 12 です。
このセクションでは、Oracle と Cloud SQL for PostgreSQL の主な用語の相違点に重点を置いて説明します。具体的な詳細については、このドキュメントで後述します。
| Oracle 11g | 説明 | Cloud SQL for PostgreSQL | 主な違い |
|---|---|---|---|
| インスタンス | 1 つの Oracle 11g インスタンスで保持できるデータベースは 1 つのみです。 | インスタンス | 1 つの Cloud SQL for PostgreSQL インスタンスは、厳密に 1 つのデータベース クラスタを保持します。データベース クラスタは、共通のデータ領域に格納されるデータベースの集まりです。 |
| データベース | 1 つのデータベースが 1 つのインスタンスとみなされます(データベースの名前はインスタンス名と同じです)。 | データベース | 複数または 1 つのデータベースが複数のアプリケーションに対応します。 |
| スキーマ | スキーマとユーザーはどちらもデータベース オブジェクトのオーナーとみなされるため、この 2 つは同義です(ユーザーの作成では、スキーマの指定やユーザーへの割り当ては必要ありません)。 | スキーマ | データベースにはスキーマが 1 つ以上含まれています。テーブルなどのオブジェクトはスキーマに含まれます。同じデータベース内の異なるスキーマで、同じオブジェクト名を競合することなく使用できます。 |
| ユーザー | 両方ともデータベース オブジェクトのオーナーであるため、スキーマと同義です(例: インスタンス → データベース → スキーマ/ユーザー → データベース オブジェクト)。 | ロール | ロールには、設定方法に応じて、データベース ユーザーまたはデータベース ユーザーのグループのいずれかを設定できます。テーブルなどのデータベース オブジェクトを所有できます。 ロールのスコープはデータベース クラスタ全体に設定されています。ロールのメンバーシップを別のロールに付与することもできます。 |
| ロール | グループとして連結できる定義済みのデータベース権限一式。データベース ユーザーに割り当てることができます。 | ||
| 管理者 / SYSTEM ユーザー |
以下の最高レベルのアクセス権が割り当てられた Oracle 管理者ユーザー:SYS |
cloudsqlsuperuser | Cloud SQL for PostgreSQL にはデフォルトの postgres ユーザーがあります。このユーザーは cloudsqlsuperuser ロールの構成要素であり、CREATEROLE、CREATEDB、LOGIN の各属性(特権)を付与されています。Cloud SQL for PostgreSQL はマネージド サービスであるため、高度な権限が必要な特定のシステム プロシージャやテーブルへのアクセスを制限します。したがって、 postgres ユーザーには SUPERUSER と REPLICATION の属性はありません。superuser 属性を持つユーザーを作成することや、アクセス権を取得することはできません。 |
| ディクショナリ / メタデータ |
Oracle では以下のメタデータ テーブルを使用します。USER_TableName |
ディクショナリ / メタデータ |
Cloud SQL for PostgreSQL は ANSI 標準 INFORMATION_SCHEMA を使用してディクショナリとメタデータ情報を提供します。 |
| システムの動的ビュー | Oracle の動的ビュー: V$ViewName |
システムの 動的ビュー |
Cloud SQL for PostgreSQL には、次のような動的統計情報ビューがあります。pg_stat_ViewNamepg_statio_ViewName |
| テーブルスペース | Oracle データベースのプライマリ論理ストレージ。テーブルスペースごとに 1 つ以上のデータファイルを格納できます。 | テーブルスペース | Cloud SQL for PostgreSQL では、データファイルは事前定義のディレクトリ構造を使用して、データベース クラスタのデータ ディレクトリ PGDATA に格納されます。Cloud SQL for PostgreSQL のテーブルスペースは、データファイルを保存できるファイル システム内のカスタム ロケーションを定義するメカニズムを備えています。Cloud SQL for PostgreSQL はマネージド サービスであるため、 Google Cloudがホストマシンの基盤となるファイル システムを管理します。Cloud SQL for PostgreSQL に新しいテーブルスペースを作成することはできません。 |
| データファイル | データを保持し、 特定のテーブルスペースで定義されている Oracle データベースの物理要素です。 データファイルは初期サイズと最大サイズによって定義され、1 つのデータファイルで複数のテーブルのデータを保持できます。 Oracle のデータファイルは .dbf サフィックスを使用します(必須ではありません)。 |
データファイル | Cloud SQL for PostgreSQL は、各データベースを独自のサブディレクトリ内のデータベース クラスタに保存します。データベース内の各テーブルとインデックスは、そのサブディレクトリ内の個別のファイルに保存されます。 |
| システム テーブルスペース | Oracle データベース全体のデータ ディクショナリ テーブルとビュー オブジェクトを格納します。 | 存在しません | データ ディクショナリのテーブルとビュー オブジェクトは、事前定義されたディレクトリ構造を使用して、データベース クラスタのデータ ディレクトリ PGDATA の INFORMATION_SCHEMA に格納されます。 |
| 一時テーブルスペース | セッション中に有効なスキーマ オブジェクトが含まれます。 また、サーバーメモリに収まりきらない実行中のオペレーションもサポートします。 |
一時ファイル | 一時ファイルは、サーバーメモリに格納できない実行中のオペレーションを保存するために使用されます。これらのファイルは pgsql_tmp というディレクトリに保存され、SQL ステートメントの実行中にのみ作成されます。 |
| Undo テーブルスペース | 特殊なタイプのシステム永続テーブルスペース。 自動 UNDO 管理モード(デフォルト)でデータベースを実行中にロールバック オペレーションを管理するために Oracle によって使用されます。 |
存在しません | ロールバック オペレーションを可能にするために、Cloud SQL for PostgreSQL は、テーブルのデータファイル内で更新または削除された行を保持します。バキュームは、更新または削除された行が占有するディスク容量の復元または再利用のプロセスです。 |
| ASM | Oracle ASM(Automatic Storage Management)は、高パフォーマンスの統合データベース ファイル システムおよびディスク マネージャーです。ASM が構成された Oracle データベースでは、すべてのストレージ管理が自動的に行われます。 | サポート対象外 | Cloud SQL for PostgreSQL は、OS ファイル システムに依存してデータファイルを保存しますが、Oracle ASM に相当するものはありません。ただし、Cloud SQL for PostgreSQL は、ストレージの自動増量、パフォーマンス、スケーラビリティなどのストレージ管理の自動化を実現する多くの機能をサポートしています。 |
| テーブル / ビュー | ユーザーが作成する基本的なデータベース オブジェクト。 | テーブル / ビュー | Oracle と同じ。 |
| マテリアライズド ビュー | 特定の SQL ステートメントを使用して定義します。 手動で、または特定の構成に基づいて自動更新できます。 |
マテリアライズド ビュー | マテリアライズド ビューは Oracle と同様に機能します。手動で更新する場合は REFRESH
MATERIALIZED VIEW ステートメントを使用します。 |
| シーケンス | Oracle 固有の値生成ツール。 | シーケンス | Oracle と類似しています。 |
| シノニム | 他のデータベース オブジェクトの代替識別子の役割を果たす、Oracle データベース オブジェクト。 | サポート対象外 | Cloud SQL for PostgreSQL にはシノニムが存在しません。回避策として、適切な権限が設定されている間はビューを使用できます。 |
| パーティショニング | Oracle では、大規模なテーブルを小さい複数のパーティションに分割して管理するためのパーティショニング ソリューションが多数用意されています。 | パーティショニング | Cloud SQL for PostgreSQL は、Oracle スタイルの宣言パーティショニングと継承を使用したパーティショニングの両方をサポートしています。これにより、パーティショニングに関する柔軟性が向上します。 |
| フラッシュバック データベース | Oracle データベースを以前に定義した時間まで初期化するために使用できる Oracle 独自の機能。誤って変更または破損したデータをクエリまたは復元できます。 | サポート対象外 | 別の解決策として、Cloud SQL バックアップとポイントインタイム リカバリを使用して、データベースを以前の状態に復元できます(たとえば、テーブルをドロップする前に復元)。 |
| sqlplus | Oracle のコマンドライン インターフェース。データベース インスタンスをクエリして管理できます。 | psql | Cloud SQL for PostgreSQL: クエリと管理を目的とする同等のコマンドライン インターフェース。Cloud SQL に対して適切な権限を持つクライアントであれば、どのクライアントからでも接続できます。 |
| PL/SQL | ANSI SQL を拡張した Oracle のプロシージャ言語。 | PL/pgSQL | Cloud SQL for PostgreSQL には、PL/pgSQL と呼ばれる独自のプロシージャ言語があります。これは Oracle の PL/SQL と類似しています。2 つの言語の主な相違点の概要については、Oracle PL/SQL からの移植をご覧ください。 |
| パッケージとパッケージの本文 | Oracle 固有の機能。ストアド プロシージャと関数を同じ論理参照にグループ化します。 | サポート対象外 | Cloud SQL for PostgreSQL は、スキーマを使用して関数を整理します。 |
| ストアド プロシージャと関数 | PL/SQL を使用してコードの機能を実装します。 | ストアド プロシージャと関数 | Cloud SQL for PostgreSQL は、PL/pgSQL や C などのさまざまなプログラミング言語を使用したストアド プロシージャと関数の実装をサポートします。 |
| トリガー | テーブルに対する DML 実装を制御する Oracle オブジェクト。 | トリガー | Oracle と類似しています。 |
| PFILE / SPFILE | Oracle のインスタンス レベルとデータベース レベルのパラメータは、SPFILE というバイナリ ファイルに格納されます(以前のバージョンでは PFILE と呼ばれていました)。パラメータの手動設定用テキスト ファイルとしてこれを使用できます。 |
Cloud SQL for PostgreSQL データベース フラグ | データベース フラグ ユーティリティを使用して、Cloud SQL for PostgreSQL のパラメータを設定または変更できます。 |
| SGA / PGA / AMM |
データベース インスタンスへのメモリ割り当てを制御する、Oracle のメモリ パラメータ。 | メモリ関連のパラメータ | Cloud SQL for PostgreSQL には独自のメモリ パラメータがあります。類似したパラメータとしては、shared_buffers、temp_buffers、work_mem などがあります。Cloud SQL for PostgreSQL では、これらのパラメータは選択したインスタンス タイプによって事前定義され、それに応じて値が変わります。データベース フラグ ユーティリティを使用すると、これらのパラメータの一部を調整できます。 |
| バッファ キャッシュ | バッファ キャッシュからキャッシュ データを取得することにより、SQL I/O オペレーションを削減します。メモリ パラメータは、データベース レベルで、またはクエリヒントを使用してセッション レベルで管理できます。 | 類似の機能 | Cloud SQL for PostgreSQL のバッファ キャッシュ サイズは、shared_buffer パラメータで制御されます。これは、Cloud SQL では公開されません。Cloud SQL は、インスタンスのサイズの適正化に使用するメモリ使用量の指標を備えています。 |
| データベース ヒント | オプティマイザーの動作に影響を与える SQL ステートメントに対する影響を制御することにより、パフォーマンスの改善をもたらす Oracle の機能。Oracle には 50 種類を超えるデータベース ヒントがあります。 | サポート対象外 | Cloud SQL for PostgreSQL はデータベース ヒントをサポートしていません。明示的な JOIN 構文を使用して、Cloud SQL for PostgreSQL のクエリ プランナーをある程度制御できます。 |
| RMAN | Oracle Recovery Manager ユーティリティ。複数の障害復旧シナリオやクローン作成などをサポートする拡張機能を使用して、データベース バックアップを作成できます。 | Cloud SQL for PostgreSQL のバックアップ | Cloud SQL for PostgreSQL では、オンデマンド バックアップと自動バックアップの 2 つの方法で完全バックアップを適用できます。 |
| データバンプ (EXPDP / IMPDP) |
エクスポート / インポート、データベースのバックアップ(スキーマまたはオブジェクト レベル)、スキーマ メタデータ、スキーマ SQL ファイルの生成など、さまざまな機能に使用できる Oracle ダンプ生成ユーティリティ。 | Cloud SQL for PostgreSQL のエクスポート / インポート | Cloud SQL for PostgreSQL には、Cloud Storage バケットとの間でエクスポート / インポートを行う際の 2 つの形式(SQL と CSV)が用意されています。 または、pg_dump などのエクスポート / インポート ユーティリティを使用して、データベース インスタンスに接続することもできます。 |
| SQL*Loader | テキスト ファイル、CSV ファイルなどの外部ファイルからデータをアップロードできるツール。 | psql \copy |
PSQL クライアントの \copy コマンドを使用すると、テキスト、CSV、バイナリ ファイル(Oracle ではその他のファイル形式をサポート)を、対応する構造のデータベース テーブルに読み込むことができます。 |
| Data Guard | スタンバイ インスタンスを使用した、Oracle の障害復旧ソリューション。ユーザーはスタンバイ インスタンスから READ オペレーションを実行できます。 |
Cloud SQL for PostgreSQL の高可用性とレプリケーション | 障害復旧または高可用性を実現するために、Cloud SQL for PostgreSQL はフェイルオーバー レプリカ アーキテクチャを備えています。また、(READ と WRITE を分離した)読み取り専用オペレーションにはリードレプリカを使用できます。 |
| Active Data Guard / GoldenGate |
Oracle の主要なレプリケーション ソリューション。スタンバイ(DR)、読み取り専用インスタンス、双方向レプリケーション(マルチマスター)、データ ウェアハウジングなど、さまざまな目的で使用できます。 | Cloud SQL for PostgreSQL リードレプリカ | Cloud SQL for PostgreSQL のリードレプリカは、読み取りと書き込みを分離したクラスタリングを実装します。現時点では、Golden Gate 双方向レプリケーションのようなマルチマスター構成や、異種混合レプリケーションはサポートされていません。 |
| RAC | Oracle Real Application Cluster。Oracle 独自のクラスタリング ソリューションであり、1 つのストレージ ユニットで複数のデータベース インスタンスをデプロイして高可用性を確保できます。 | サポート対象外 | Cloud SQL for PostgreSQL はマルチマスター アーキテクチャをサポートしていません。Cloud SQL for PostgreSQL は、スタンバイ インスタンスを通じて高可用性を実現し、リードレプリカにより読み取りスケーラビリティを改善します。 |
| Grid / Cloud Control(OEM) | データベースおよびその他の関連するサービスをウェブ アプリケーションの形式で管理、モニタリングするための Oracle ソフトウェア。高負荷のワークロードを把握するためにリアルタイムでデータベースを分析する際に非常に便利です。 | Google Cloud コンソール、 Cloud Monitoring |
モニタリングには Cloud SQL for PostgreSQL を使用します。このコンソールでは、時間とリソースに基づく詳細なグラフも確認できます。また、Cloud Monitoring を使用して、特定の Cloud SQL for PostgreSQL モニタリング指標とログ分析を保持し、高度なモニタリング機能を利用することもできます。 |
| REDO ログ | 事前に割り当てられた 2 つ(またはそれ以上)の定義済みファイルで構成される Oracle のトランザクション ログ。データが変更されると変更内容が記録されます。REDO ログの目的は、インスタンスに障害が発生した場合にデータベースを保護することです。 | WAL ログ | Cloud SQL for PostgreSQL は、Write-Ahead Logging(WAL)を使用して、データファイルに対する変更を永続ストレージにフラッシュして、クラッシュ リカバリを可能にします。 |
| アーカイブログ | アーカイブログでは、バックアップやレプリケーションのオペレーションなどがサポートされています。各 REDO ログ切り替えオペレーションが完了するたびに、Oracle によってアーカイブログ(有効になっている場合)への書き込みが行われます。 | WAL のアーカイブ | WAL ログ保持に関する Cloud SQL for PostgreSQL 実装。WAL アーカイブが使用され、ポイントインタイム リカバリで有効になります。 |
| 制御ファイル | Oracle の制御ファイルは、データベースに関する情報を保持します。具体的には、データファイルと REDO ログの名前と場所、現在のログシーケンス番号、インスタンス チェックポイントに関する情報などです。 | PGDATA and pg_control
|
Cloud SQL for PostgreSQL アーキテクチャには、Oracle 制御ファイルに相当するコンセプトがありません。データベース関連のファイルは、一般に PGDATA として参照されるディレクトリに配置されます。レコードとチェックポイントに関連する WAL 情報は pg_control に格納されます。 |
| システム変更番号(SCN) | SCN は、Oracle データベース内の特定の時点をマークします。 | ログシーケンス番号(LSN) | Cloud SQL for PostgreSQL の同等の機能は LSN です。SCN と同様に、LSN は時間の経過とともに単調に増加します。 |
| AWR | Oracle AWR(自動ワークロード リポジトリ)は、Oracle データベース インスタンスのパフォーマンスに関する詳細レポートです。これは、パフォーマンスを診断するための DBA ツールとみなされています。 | Statistics Collector | Cloud SQL for PostgreSQL には Oracle AWR に相当するレポートはありませんが、Statistics Collector によって収集されたパフォーマンス データが収集されます。収集された統計情報は、pg_stat_* ビューと pg_statio_* ビューを通じて公開されます。 |
DBMS_SCHEDULER
|
事前定義されたオペレーションを設定して実行時間を決定するための Oracle ユーティリティ。 | サポート対象外 | Cloud SQL for PostgreSQL には、組み込みのスケジューリング ユーティリティは用意されていません。 Google Cloud は Cloud Scheduler を備えており、エクスポートなどのデータベース タスクのスケジュールを設定できます。 |
| 透過的データ暗号化 | 保存データを保護するために、ディスクに保存されているデータを暗号化します。 | Cloud SQL Advanced Encryption Standard | Cloud SQL for PostgreSQL は 256 ビットの Advanced Encryption Standard(AES-256)を使用して、保存中と転送中のデータを保護します。 |
| Advanced Compression | データベースのストレージ フットプリントを改善して、ストレージ コストを削減し、データベースのパフォーマンスを向上させるために、Oracle はデータ(テーブル / インデックス)の高度な圧縮機能として Advanced Compression を提供しています。 | TOAST | Cloud SQL for PostgreSQL は、Oracle の高度な圧縮に直接対応するのではなく、TOAST と呼ばれるインフラストラクチャを使用して、サイズが過大な可変長データを 1 つのデータページに格納できるよう、自動的に透過的な圧縮を行います。 |
| SQL Developer | 無料で使用できる Oracle の SQL GUI。SQL ステートメントと PL / SQL ステートメントを管理、実行できます。 | pgAdmin | 無料で使用できる Cloud SQL for PostgreSQL の SQL GUI。SQL コードと PostgreSQL コードのステートメントを管理、実行できます。 |
| アラートログ | 一般的なデータベース オペレーションとエラーが記録される Oracle のメインログ。 | PostgreSQL のエラー報告とロギング | Cloud Logging のログビューアを使用して PostgreSQL エラーログを検査します。 |
| DUAL テーブル | SYSDATE や USER などの疑似列の値を取得するための Oracle の特殊なテーブル。 |
存在しません | Cloud SQL for PostgreSQL では、SQL ステートメントから FROM 句を省略できます。例:SELECT NOW();は、PostgreSQL の有効なステートメントです。 |
| 外部テーブル | Oracle では、データベースの外部に存在するファイルのデータをソースとする外部テーブルを作成できます。 | サポート対象外 | Cloud SQL for PostgreSQL は、マネージド サービスとして、データベース インスタンスを実行するホストの基盤となるファイル システムを公開しません。 回避策として、ソースデータを PostgreSQL テーブルにインポートしてデータをクエリできます。 |
| リスナー | 受信データベース接続をリッスンする役割を果たす Oracle ネットワーク プロセス。 | Cloud SQL 承認済みネットワーク | Cloud SQL for PostgreSQL は、Cloud SQL 承認済みネットワークの構成ページで許可されると、リモートソースからの接続を受け入れます。 |
| TNSNAMES | Oracle のネットワーク構成ファイル。接続エイリアスを使用して接続を確立するためのデータベース アドレスを定義します。 | 存在しません | Cloud SQL for PostgreSQL は、Cloud SQL インスタンス接続名またはプライベート / パブリック IP アドレスを使用して外部接続を受け入れます。Cloud SQL Proxy は、特定の IP アドレスを許可する、または SSL の構成を行うことを必要とせずに、Cloud SQL for PostgreSQL に接続するための、その他の安全なアクセス方法です。 |
| インスタンスのデフォルト ポート | 1521 | インスタンスのデフォルト ポート | 5432 |
| データベース リンク | ローカルやリモートのデータベース オブジェクトを操作するために使用できる、Oracle のスキーマ オブジェクト。 | 外部データラッパー(FDW) | Cloud SQL for PostgreSQL の postgres_fdw 拡張機能を使用すると、他の(「外部」)PostgreSQL データベースのテーブルを現在のデータベースの「外部」テーブルとして公開できます。このテーブルは、ローカルのテーブルとほぼ同じように使用できます。 |
Oracle 12c と Cloud SQL for PostgreSQL の用語の相違点
| Oracle 12c | 説明 | Cloud SQL for PostgreSQL | 主な違い |
|---|---|---|---|
| インスタンス | Oracle 12c で導入されたマルチテナント機能では、Oracle インスタンスが単一のデータベースをホストできる Oracle 11g とは異なり、インスタンスは複数のデータベースをプラガブル データベース(PDB)として保持できます。 | インスタンス | 1 つの Cloud SQL for PostgreSQL インスタンスは、厳密に 1 つのデータベース クラスタを保持します。データベース クラスタは、共通のデータ領域に格納されるデータベースの集まりです。 |
| CDB | マルチテナント コンテナ データベース(CDB)では 1 つ以上の PDB をサポートでき、(すべての PDB に適用される)ロールなどの CDB グローバル オブジェクトを作成できます。 | PostgreSQL インスタンス | Cloud SQL for PostgreSQL インスタンスは Oracle CDB に相当します。どちらのシステムも、ホストされるデータベースのシステムレイヤを提供します。 |
| PDB | PDB(プラガブル データベース)を使用すると、サービスやアプリケーションを互いに分離できます。PDB は移植可能なスキーマ コレクションとして使用できます。 | PostgreSQL データベース / スキーマ |
Cloud SQL for PostgreSQL データベースは、複数のサービスとアプリケーションだけでなく、多数のデータベース ユーザーに対応できます。 |
| セッション シーケンス | Oracle 12c 以降では、シーケンスの作成をセッション レベル(セッション内でのみ固有の値を返します)またはグローバル レベル(一時テーブルを作成する場合など)で行うことができます。 | 一時シーケンス | 一時シーケンスは現在のデータベース セッション用に作成され、セッションの終了時に自動的に破棄されます。 |
| Identity 列 | Oracle 12c の IDENTITY 型を使用すると、シーケンスが生成されてテーブル列に関連付けられます。手動で別個の Sequence オブジェクトを作成する必要はありません。 |
SERIAL 列 | 列のデータ型を SERIAL として定義すると、Cloud SQL for PostgreSQL は自動的にシーケンスを作成し、テーブルに新しい行が挿入されたときにそのシーケンスを使用して列の値を入力します。 |
| シャーディング | Oracle Sharding は、1 つの Oracle データベースを複数の小さいデータベース(シャード)に分割するソリューションです。OLTP 環境のスケーラビリティ、可用性、地理的分散を実現できます。 | (機能としては)サポート対象外 | Cloud SQL for PostgreSQL には、シャーディング機能に相当する機能はありません。シャーディングを実装するには、(データ プラットフォームとしての)Cloud SQL for PostgreSQL と、サポート アプリケーション層を使用します。 |
| インメモリ データベース | Oracle には、OLTP と混合ワークロードに対するデータベース パフォーマンスを改善できる一連の機能が用意されています。 | サポート対象外 | Cloud SQL for PostgreSQL には、同等の組み込み機能はありません。ただし、代わりにマネージド Redis サービスである Memorystore を使用できます。 |
| リダクション | Oracle の高度なセキュリティ機能の 1 つ。リダクションでは、ユーザーやアプリケーションによって機密データが表示されないように列をマスクできます。 | サポート対象外 | Cloud SQL for PostgreSQL には、同等の組み込み機能はありません。ただし、Sensitive Data Protection を利用して機密データを匿名化できます。 |
機能
Oracle 11g/12c データベースと Cloud SQL for PostgreSQL データベースはそれぞれ異なるアーキテクチャ(インフラストラクチャと拡張プロシージャ言語)にビルドされていますが、どちらもリレーショナル データベースの同じ基本要素を共有しています。データベース オブジェクト、マルチユーザー同時実行ワークロード、ACID のプロパティを使用したトランザクションをサポートします。アプリケーションのさまざまなニーズに応じて、複数の分離レベルを持つロック競合の管理も行います。また、オンライン トランザクション処理(OLTP)オペレーションとオンライン分析処理(OLAP)オペレーションの両方で、継続的なアプリケーション要件に対処します。
次のセクションでは、Oracle と Cloud SQL for PostgreSQL 間のいくつかの主な機能の相違点について説明します。相違点をハイライト表示する必要があると考えられる場合は、セクションに詳細な技術的な内容の比較を掲載しています。
既存のデータベースの作成と表示
| Oracle 11g / 12c | Cloud SQL for PostgreSQL 12 |
|---|---|
通常、Oracle Database Creation Assistant(DBCA)ユーティリティを使用して、データベースを作成し、既存のものを表示します。手動で作成されたデータベースまたはインスタンスの場合は、追加のパラメータを指定する必要があります。SQL> CREATE DATABASE ORADB |
次の例のように、CREATE DATABASE Name; という形式のステートメントを使用します。postgres=> CREATE DATABASE PGSQLDB; |
| Oracle 12c | Cloud SQL for PostgreSQL 12 |
Oracle 12c では、コンテナ データベース(CDB)テンプレートから、または既存の PDB から PDB のクローンを作成して、PDB をシードから作成できます。いくつかのパラメータを使用します。SQL> CREATE PLUGGABLE DATABASE PDB |
次の例のように、CREATE DATABASE Name; という形式のステートメントを使用します。postgres=> CREATE DATABASE PGSQLDB; |
すべての PDB を一覧表示します。SQL> SHOW is PDBS; |
すべての既存データベースを一覧表示します。postgres=> \list |
別の PDB に接続します。SQL> ALTER SESSION SET CONTAINER=pdb; |
別のデータベースに接続します。postgres=> \connect databaseName;または postgres=> \c databaseName |
特定の PDB を開くか、閉じます(オープン / 読み取り専用)。SQL> ALTER PLUGGABLE DATABASE pdb CLOSE; |
単一のデータベースではサポートされていません。 すべてのデータベースが同じ Cloud SQL for PostgreSQL インスタンスに属しており、すべてのデータベースが起動するかダウンしています。 |
Google Cloud コンソールを使用したデータベースの管理
Google Cloud コンソールで、[データベース] > [SQL] > [インスタンス] >(PostgreSQL インスタンスを選択)> [データベース]に移動します。
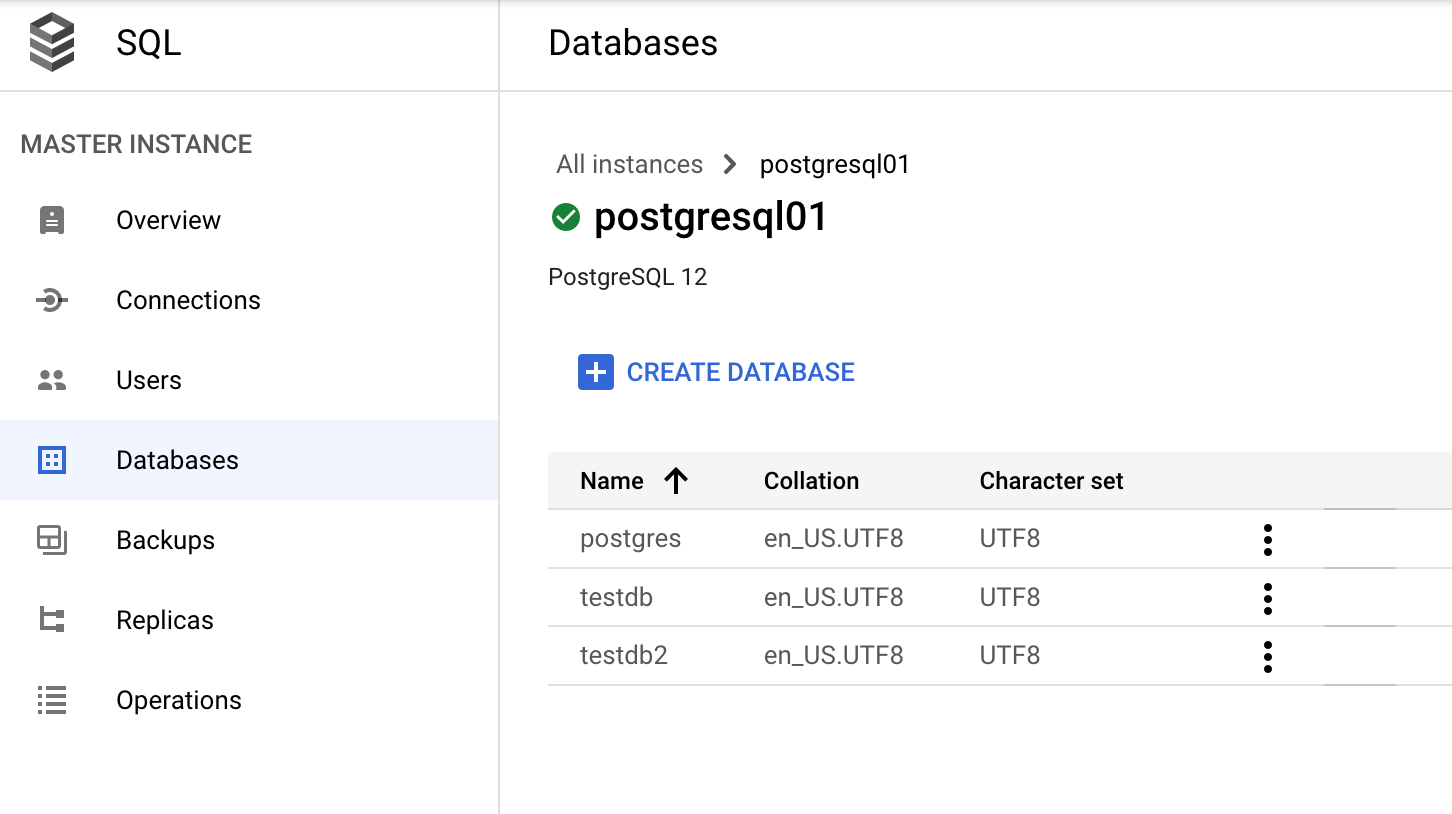
データ ディクショナリと動的ビュー
Oracle データベースは、さまざまなデータベース メンテナンスとモニタリング タスクを容易にする動的パフォーマンス ビュー(V$ ビュー)と、データ ディクショナリを備えています。データ ディクショナリにはデータベースのオブジェクトを管理するために使用されるすべての情報が格納されますが、動的パフォーマンスのビューには、データベースのパフォーマンスに関連する多くの情報が含まれます。こうしたビューは、データベースの実行中に継続的に更新されます。
これとは対照的に、PostgreSQL にはいくつかのメタデータ カタログが用意されており、Oracle のデータ ディクショナリと動的パフォーマンス ビューに類似した役割を果たします。
- システム カタログ: すべてのデータベース オブジェクトに関するメタデータ。
- 統計情報の収集ビュー: PostgreSQL のアクティビティに関するレポート。
- 情報スキーマのビュー: ANSI SQL 標準に従って報告されるすべてのデータベース オブジェクトに関するメタデータ。
メタデータとシステムの動的ビューの表示
このセクションでは、Cloud SQL for PostgreSQL バージョン 12 の Oracle と対応するデータベース オブジェクトで使用される、最も一般的なメタデータ テーブルとシステムの動的ビューの一部について概要を説明します。
Oracle には、(SYS、SYSTEM などの特定のシステム スキーマで)数百のシステム メタデータ テーブルとビューが用意されていますが、PostgreSQL が備えているのは数十個のみです。いずれの場合も、特定の目的を果たすデータベース オブジェクトが複数存在する可能性があります。
Oracle のメタデータ オブジェクトには以下の複数のレベルがあり、レベルによって必要な権限が異なります。
USER_TableName: ユーザーが表示できます。ALL_TableName: すべてのユーザーが表示できます。DBA_TableName:SYSやSYSTEMなど、DBA 権限を持つユーザーのみが表示できます。
動的パフォーマンス ビューの場合、Oracle では V$/GV$ の接頭辞が使用されます。一方、Cloud SQL for PostgreSQL のメタデータとビューは、information_schema スキーマと pg_catalog スキーマにあります。
| メタデータの種類 | Oracle テーブル / ビュー | Cloud SQL for PostgreSQL のテーブル / ビュー / クエリ |
|---|---|---|
| オープン セッション | V$SESSION |
pg_catalog.pg_stat_activity |
| 実行中のトランザクション | V$TRANSACTION |
サポートされていません。回避策として、1 つ以上のロックを保持するオープン トランザクションのリストが pg_locks から提供されます。 |
| データベース オブジェクト | DBA_OBJECTS |
pg_catalog.pg_class |
| テーブル | DBA_TABLES |
pg_catalog.pg_tables |
| テーブル列 | DBA_TAB_COLUMNS |
pg_catalog.pg_attribute |
| テーブルと列の権限 | TABLE_PRIVILEGES |
information_schema.table_privileges
information_schema.column_privileges |
| パーティション | DBA_TAB_PARTITIONS
DBA_TAB_SUBPARTITIONS |
pg_catalog.pg_partitioned_table |
| ビュー | DBA_VIEWS |
pg_catalog.pg_views |
| 制約 | DBA_CONSTRAINTS |
pg_catalog.pg_constraint |
| インデックス | DBA_INDEXES |
pg_catalog.pg_index |
| マテリアライズド ビュー | DBA_MVIEWS |
pg_catalog.pg_matviews |
| ストアド プロシージャ | DBA_PROCEDURES |
pg_catalog.pg_proc |
| ストアド ファンクション | DBA_PROCEDURES |
pg_catalog.pg_proc |
| トリガー | DBA_TRIGGERS |
pg_catalog.pg_trigger |
| ユーザー | DBA_USERS |
pg_catalog.pg_user |
| ユーザーの権限 | DBA_SYS_PRIVS |
pg_catalog.pg_roles |
| ジョブ / スケジューラ |
DBA_JOBS |
サポートされていません。 |
| テーブルスペース | DBA_TABLESPACES |
pg_catalog.pg_tablespace |
| データファイル | DBA_DATA_FILES |
サポートされていません。 |
| シノニム | DBA_SYNONYMS |
サポートされていません。 |
| シーケンス | DBA_SEQUENCES |
pg_catalog.pg_sequence |
| データベース リンク | DBA_DB_LINKS |
pg_catalog.pg_foreign_server |
| 統計情報 | DBA_TAB_STATISTICS
DBA_TAB_COL_STATISTICS
DBA_SQLTUNE_STATISTICS
DBA_CPU_USAGE_STATISTICS |
pg_catalog.pg_stats |
| ロック | DBA_LOCK |
pg_catalog.pg_locks |
| データベース パラメータ | V$PARAMETER |
pg_catalog.pg_settings
show |
| セグメント | DBA_SEGMENTS |
サポートされていません。 |
| ロール | DBA_ROLES |
pg_catalog.pg_roles |
| セッション履歴 | V$ACTIVE_SESSION_HISTORY |
サポートされていません。 |
| バージョン | V$VERSION |
select version(); |
| 待機イベント | V$WAITCLASSMETRIC |
サポートされていません。 |
| SQL の調整と 分析 |
V$SQL |
サポートされていません。 |
| インスタンスの メモリ調整 |
V$SGA
V$SGASTAT
V$SGAINFO
V$SGA_CURRENT_RESIZE_OPS
V$SGA_RESIZE_OPS
V$SGA_DYNAMIC_COMPONENTS
V$SGA_DYNAMIC_FREE_MEMORY
V$PGASTAT |
Cloud SQL for PostgreSQL には組み込まれていません。pg_buffercache 拡張機能を使用して、共有バッファ キャッシュをリアルタイムで調べます。 |
システム パラメータ
Oracle データベースと Cloud SQL for PostgreSQL データベースはどちらも、デフォルトでの構成だけでなく、特定の機能を果たすように明示的に構成できます。Oracle で構成パラメータを変更するには、特定の管理権限が必要です(主に SYS/SYSTEM ユーザー権限)。
以下に、ALTER SYSTEM ステートメントを使用して Oracle の構成を変更する例を示します。この例では、ユーザーは spfile 構成レベルでのみ「ログイン失敗時の最大試行回数」パラメータを変更しています(変更を適用するには、再起動が必要です)。
SQL> ALTER SYSTEM SET SEC_MAX_FAILED_LOGIN_ATTEMPTS=2 SCOPE=spfile;
次の例では、ユーザーは Oracle パラメータ値の表示のみをリクエストしています。
SQL> SHOW PARAMETER SEC_MAX_FAILED_LOGIN_ATTEMPTS;
出力は次のようになります。
NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ sec_max_failed_login_attempts integer 2
Oracle パラメータの変更は、次の 3 つのスコープで適用されます。
- SPFILE: パラメータの変更は Oracle
spfileにのみ書き込まれ、パラメータを有効にするにはインスタンスの再起動が必要です。 - MEMORY: パラメータの変更はメモリ層にのみ適用されます。ただし、静的パラメータの変更は許可されません。
- BOTH: パラメータの変更はサーバー パラメータ ファイルとインスタンス メモリの両方に適用されます。ただし、静的パラメータの変更は許可されません。
Cloud SQL for PostgreSQL 構成フラグ
Cloud SQL for PostgreSQL のシステム パラメータを変更するには、 Google Cloud コンソールの構成フラグ、gcloud CLI、または CURL を使用します。Cloud SQL for PostgreSQL でサポートされている変更可能なすべてのパラメータのリストをご覧ください。
PostgreSQL のパラメータは次のスコープに分類できます。
- 動的パラメータ: 実行時に変更できます。
- データベース パラメータ: PostgreSQL インスタンス内の特定のデータベースのみに適用されます。
- ロール パラメータ: 特定のデータベースのロールにのみ適用されます。
- 静的パラメータ: 適用するにはインスタンスの再起動が必要です。
- セッション パラメータ: 現在のセッションの存続期間中に限り、他のセッションとは独立してセッション レベルで変更できます。
- グローバル パラメータ: 現在と将来のすべてのセッションに適用されます。
Cloud SQL for PostgreSQL パラメータを変更する例
コンソール
Google Cloud コンソールを使用して、log_connections パラメータを有効にします。
Cloud Storage の [インスタンスの編集] ページに移動します。
次のスクリーンショットのように、[フラグ] で [項目を追加] をクリックし、
log_connectionsを検索します。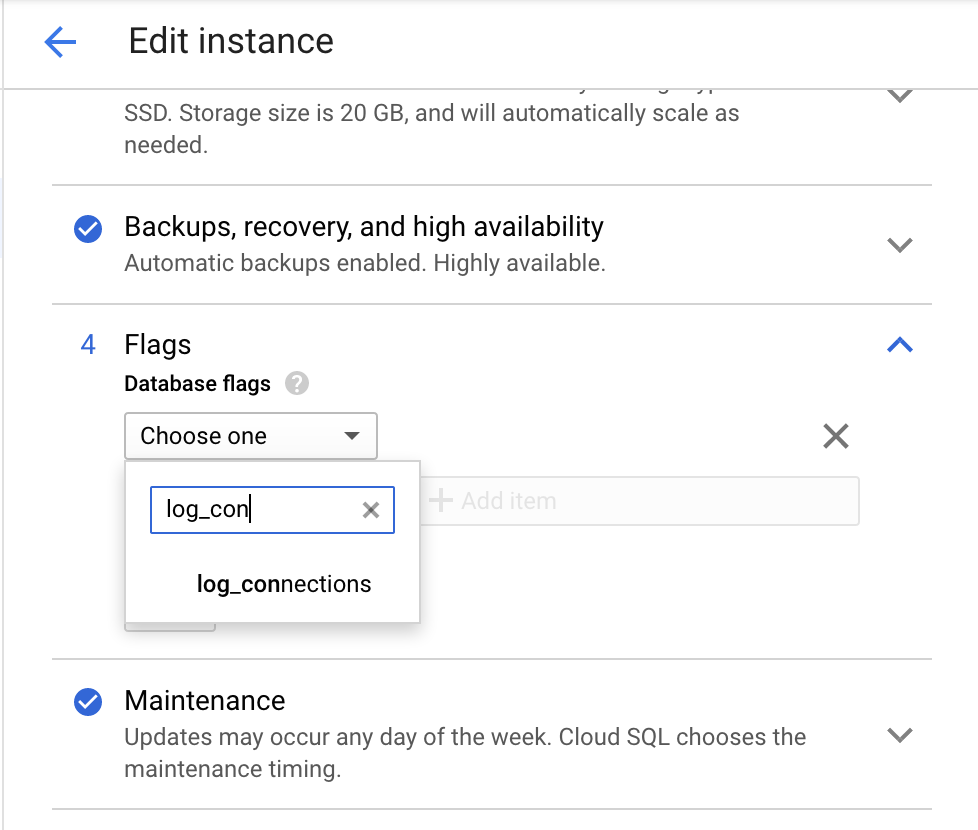
gcloud
- gcloud CLI を使用して、
log_connectionsパラメータを有効にします。
gcloud sql instances patch INSTANCE_NAME \
--database-flags log_connections=on
次のような出力が表示されます。
WARNING: This patch modifies database flag values, which may require your instance to be restarted. Check the list of supported flags - /sql/docs/postgres/flags - to see if your instance will be restarted when this patch is submitted. Do you want to continue (Y/n)?
Cloud SQL for PostgreSQL
セッション レベルで timezone を設定します。この変更は現在のセッションにのみ適用され、セッションの存続期間中にのみ有効になります。
timezone構成パラメータを表示します。postgres=> SHOW timezone;次の出力が表示されます。
timezoneはset to UTCです。TimeZone ---------- UTC (1 row)
timezoneを UTC-9 に設定します。postgres=> SET timezone='UTC-9';timezone構成パラメータを表示します。postgres> SHOW timezone;次の出力が表示されます。
timezoneがUTC-9に設定されています。TimeZone ---------- UTC-9 (1 row)
トランザクションと分離レベル
このセクションでは、Oracle と Cloud SQL for PostgreSQL のトランザクション実行と分離レベルの主な相違点について説明します。
Commit モード
Oracle はデフォルトで非自動 commit モードで動作します。各 DML トランザクションは COMMIT / ROLLBACK ステートメントで確定される必要があります。Oracle と PostgreSQL の基本的な相違点の 1 つは、PostgreSQL は、START TRANSACTION(または BEGIN)に準拠していないコマンドの後に暗黙的に COMMIT を発行することです。これは、他のデータベース エンジンでも「自動 commit」として知られています。自動 commit はデフォルトで有効になっていますが、SET AUTOCOMMIT OFF を使用してセッション レベルで無効にできます。
分離レベル
ANSI / ISO SQL 標準(SQL:92)では、4 つの分離レベルを定義しています。レベルによって、データベース トランザクションの同時実行を処理する方法が異なります。
- Read Uncommitted: 現在処理されているトランザクションで、他のトランザクションで確定されていないデータを参照できます。ロールバックが実行されると、すべてのデータが以前の状態に復元されます。
- Read Committed: トランザクションの実行中に参照できるのは、確定されたデータの変更のみです。確定されていないデータの変更は(「ダーティリード」)は参照できません。
- Repeatable Read: あるトランザクションの実行中に、他のトランザクションで行われた変更を参照できるのは、両方のトランザクションが
COMMITを発行した後、あるいは両方のトランザクションがロールバックされた後に限られます。 - Serializable: 最も厳格かつ強力な分離レベルです。このレベルでは、アクセスされたすべてのレコードがロックされ、レコードがテーブルに追加されないようにリソースがロックされます。
トランザクション分離レベルにより、実行中の他のトランザクションに対する変更データの可視性が管理されます。また、複数の同時実行トランザクションで同じデータにアクセスする際にそれぞれのトランザクションがどのように相互作用するかも、選択した分離レベルによって異なります。
Oracle でサポートされている分離レベル
- Read Committed(デフォルト)
- Serializable
- Read-Only(ANSI/ISO SQL 標準(SQL:92)には含まれていません)
Oracle MVCC(マルチバージョン同時実行制御)
- Oracle では MVCC メカニズムを使用して、データベース全体とすべてのセッションで自動読み取りの整合性を確保しています。
- Oracle は現在のトランザクションのシステム変更番号(SCN)を使用してデータベース ビューの整合性を確保します。したがって、すべてのデータベース クエリは、クエリが実行された時点で SCN に関して commit されているデータのみを返します。
- 分離レベルは、トランザクション レベルとセッション レベルで変更できます。
分離レベルの設定例を次に示します。
-- Transaction Level
SQL> SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SQL> SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SQL> SET TRANSACTION READ ONLY;
-- Session Level
SQL> ALTER SESSION SET ISOLATION_LEVEL = SERIALIZABLE;
SQL> ALTER SESSION SET ISOLATION_LEVEL = READ COMMITTED;
Cloud SQL for PostgreSQL は、ANSI SQL:92 標準で指定されている次の 4 つのトランザクション分離レベルをサポートしています。
- Read Uncommitted(Read Committed と同等の機能)
- Read Committed(デフォルト)
- Repeatable Read
- Serializable
Cloud SQL for PostgreSQL のデフォルトの分離レベルは READ COMMITTED です。これらの分離レベルは、SESSION レベル、TRANSACTION レベル、INSTANCE レベルで変更できます。
現在の分離レベルを TRANSACTION レベルと SESSION レベルの両方で検証するには、次のステートメントを使用します。
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
次のような出力が表示されます。
current_setting ----------------- read committed (1 row)
分離レベルの構文は次のように変更できます。
SET [SESSION CHARACTERISTICS AS] TRANSACTION ISOLATION LEVEL [ REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED | SERIALIZABLE]
分離レベルは SESSION レベルで変更できます。
postgres=> SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- Verify
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
次のような出力が表示されます。
current_setting ----------------- repeatable read (1 row)
INSTANCE レベルの分離レベルは、データベース フラグ default_transaction_isolation で制御します。これを確認するには、次のステートメントを使用します。
postgres=> SHOW DEFAULT_TRANSACTION_ISOLATION;
次のような出力が表示されます。
default_transaction_isolation ------------------------------- repeatable read (1 row)
次のステップ
- Cloud SQL for PostgreSQL ユーザー アカウントの詳細について確認する。
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。