Cet article constitue la deuxième partie d'une série en quatre parties qui explique comment prédire la valeur du client à l'aide d'AI Platform (AI Platform) sur Google Cloud.
Cette série est constituée des articles suivants :
- Partie 1 : Introduction. Présente la CLV et deux techniques de modélisation permettant sa prédiction.
- Partie 2 : Entraîner le modèle (cet article). Explique comment préparer les données et entraîner les modèles.
- Partie 3 : Déployer en production. Décrit comment déployer les modèles présentés dans la partie 2 sur un système de production.
- Partie 4 : Utiliser AutoML Tables. Explique comment créer et déployer un modèle en utilisant AutoML Tables.
Le code employé pour la mise en œuvre de ce système se trouve dans un dépôt GitHub. Cette série explique à quoi sert le code et comment il est utilisé.
Introduction
Cet article fait suite à la partie 1, dans laquelle vous avez découvert deux types de modèles différents permettant de prédire la CLV :
- Des modèles probabilistes
- Des modèles de réseau de neurones profond (DNN, Deep Neural Network), qui constituent un type de modèle de ML
Comme indiqué dans la partie 1, l'un des objectifs de cette série est de comparer ces modèles concernant la prédiction de la CLV. La présente partie de la série décrit comment vous pouvez préparer les données, et créer et entraîner les deux types de modèles afin de prédire la CLV. Elle fournit également des éléments de comparaison.
Installer le code
Si vous souhaitez suivre le processus décrit dans cet article, vous devez installer l'exemple de code depuis GitHub.
Si gcloud CLI est installé, ouvrez une fenêtre de terminal sur votre ordinateur pour exécuter ces commandes. Si gcloud CLI n'est pas installé, ouvrez une instance de Cloud Shell.
Clonez l'exemple de dépôt de code :
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Suivez les instructions d'installation figurant dans la section relative à l'installation du fichier README pour configurer votre environnement.
Préparer les données
Cette section décrit comment vous pouvez obtenir les données et les nettoyer.
Obtenir et nettoyer l'ensemble de données source
Pour être en mesure de calculer la CLV, vous devez vous assurer que les données source contiennent au moins les éléments suivants :
- Un numéro client, qui permet de différencier les clients individuels
- Un montant d'achat par client, qui indique la somme dépensée par un client à un moment donné
- La date de chaque achat
Cet article explique comment entraîner des modèles en utilisant l'historique des données de vente de Online Retail Data Set (ensemble de données concernant l'e-commerce) de l'UCI Machine Learning Repository (dépôt de machine learning de l'Université de Californie à Irvine).[1]
La première étape consiste à copier l'ensemble de données sous forme d'un fichier CSV dans Cloud Storage.
À l'aide de l'un des outils de chargement de BigQuery, vous créez ensuite une table nommée data_source. (Il s'agit d'un nom arbitraire, mais qui est employé par le code du dépôt GitHub.) L'ensemble de données est disponible dans un bucket public associé à cette série. Il a déjà été converti au format CSV.
- Sur votre ordinateur ou dans Cloud Shell, exécutez les commandes décrites dans la section relative à la configuration du fichier README du dépôt GitHub.
L'exemple d'ensemble de données contient les champs répertoriés dans le tableau suivant. Dans le cas de l'approche décrite dans cet article, vous n'utiliserez que les champs dont la colonne Utilisé est définie sur Oui. Certains champs ne sont pas utilisés directement, mais permettent de créer d'autres champs. Par exemple, UnitPrice et Quantity permettent de créer order_value.
| Utilisé | Champ | Type | Description |
|---|---|---|---|
| Non | InvoiceNo |
STRING |
Nominal. Nombre entier à six chiffres attribué de manière unique à chaque transaction.
Lorsque ce code commence par la lettre c, cela indique une annulation. |
| No | StockCode |
STRING |
Code produit (article). Nominal, nombre entier à cinq chiffres attribué de manière unique à chaque produit distinct. |
| Non | Description |
STRING |
Nom du produit (article). Nominal. |
| Oui | Quantity |
INTEGER |
Quantité de chaque produit (article) par transaction. Numérique. |
| Oui | InvoiceDate |
STRING |
Date et heure de facture au format mm/jj/aa hh:mm. Correspond au jour et à l'heure de génération de chaque transaction. |
| Oui | UnitPrice |
FLOAT |
Prix unitaire. Numérique. Correspond au prix du produit par unité en livres sterling. |
| Oui | CustomerID |
STRING |
Numéro client. Nominal. Correspond à un nombre entier à cinq chiffres attribué de manière unique à chaque client. |
| Non | Country |
STRING |
Nom du pays. Nominal. Correspond au nom du pays où réside le client. |
Nettoyer les données
Quel que soit le modèle employé, vous devez exécuter un ensemble d'étapes de préparation et de nettoyage communes à tous les modèles. Les opérations suivantes sont requises pour obtenir un ensemble de champs et d'enregistrements exploitables :
- Regroupez les commandes par jour plutôt que d'utiliser
InvoiceNo, car l'unité de temps minimale utilisée par les modèles probabilistes dans cette solution correspond à un jour. - Ne conservez que les champs utiles pour les modèles probabilistes.
- Ne conservez que les enregistrements contenant des valeurs monétaires et des volumes de commande positifs, tels que les achats.
- Ne conservez que les enregistrements comportant des volumes de commande négatifs, tels que les retours.
- Ne conservez que les enregistrements comportant un numéro client.
- Ne conservez que les clients ayant effectué un achat au cours des 90 derniers jours.
- Ne conservez que les clients ayant effectué au moins deux achats au cours de la période employée pour créer des caractéristiques.
Vous pouvez effectuer toutes ces opérations à l'aide de la requête BigQuery ci-après. (Comme pour les commandes précédentes, vous exécutez ce code là où vous avez cloné le dépôt GitHub.) Étant donné que les données sont anciennes, la date du 12 décembre 2011 est considérée comme la date du jour aux fins du présent article.
Cette requête effectue deux tâches. Tout d'abord, si l'ensemble de données de travail est volumineux, la requête le réduit (l'ensemble de données de travail pour cette solution est assez petit, mais cette requête peut réduire un ensemble de données extrêmement volumineux de deux ordres de grandeur en quelques secondes).
Deuxièmement, la requête crée un ensemble de données de base semblable à ce qui suit :
customer_id
|
order_date
|
order_value
|
order_qty_articles
|
|---|---|---|---|
| 16915 | 2011-08-04 | 173.7 | 6 |
| 15349 | 2011-07-04 | 107.7 | 77 |
| 14794 | 2011-03-30 | -33.9 | -2 |
L'ensemble de données nettoyé contient également le champ order_qty_articles. Ce champ n'est inclus qu'à des fins d'utilisation par le DNN décrit dans la section suivante.
Définir les intervalles d'entraînement et cibles
Pour préparer l'entraînement des modèles, vous devez choisir une date seuil. Cette date sépare les commandes en deux partitions :
- Les commandes antérieures à la date seuil servent à l'entraînement du modèle.
- Les commandes ultérieures à la date seuil servent au calcul de la valeur cible.

La bibliothèque Lifetimes comprend des méthodes de prétraitement des données. Toutefois, les ensembles de données que vous utilisez pour la CLV peuvent être assez volumineux, ce qui rend difficile le prétraitement des données sur une seule machine. Dans le cadre de l'approche décrite dans cet article, les commandes sont scindées en deux ensembles à l'aide de requêtes exécutées directement dans BigQuery. Les modèles probabilistes et de ML emploient les mêmes requêtes, garantissant ainsi que les deux types de modèles fonctionnent sur les mêmes données.
La date seuil optimale des modèles de ML peut être différente de celle des modèles probabilistes. Vous pouvez mettre à jour cette valeur de date directement dans l'instruction SQL. Considérez la date seuil optimale comme un hyperparamètre. Pour trouver la valeur la plus appropriée, explorez les données et exécutez des entraînements test.
La date seuil est utilisée dans la clause WHERE de la requête SQL qui sélectionne les données d'entraînement dans la table de données nettoyée, comme illustré dans l'exemple suivant :
Agréger des données
Une fois que vous avez scindé les données en intervalles d'entraînement et cibles, vous les agrégez afin de créer des caractéristiques et des cibles réelles pour chaque client. Pour les modèles probabilistes, l'agrégation est limitée aux champs de récence, de fréquence et de montant (RFM). Concernant les modèles de DNN, ils emploient également des caractéristiques RFM, mais ils peuvent utiliser des caractéristiques supplémentaires pour améliorer les prédictions.
La requête suivante montre comment créer des caractéristiques pour les modèles de DNN et les modèles probabilistes en même temps :
Le tableau suivant répertorie les caractéristiques créées par la requête.
| Nom de la fonctionnalité | Description | Probabiliste | DNN |
|---|---|---|---|
monetary_dnn
|
Somme des valeurs monétaires de toutes les commandes par client au cours de la période de création des caractéristiques. | X | |
monetary_btyd
|
Moyenne des valeurs monétaires de toutes les commandes pour chaque client au cours de la période de création des caractéristiques. Les modèles probabilistes supposent que la valeur de la première commande est 0. Cela est imposé par la requête. | X | |
recency
|
Délai entre la première et la dernière des commandes passées par un client au cours de la période de création des caractéristiques. | X | |
frequency_dnn
|
Nombre de commandes passées par un client au cours de la période de création des caractéristiques. | X | |
frequency_btyd
|
Nombre de commandes passées par un client au cours de la période de création des caractéristiques, moins la première commande. | X | |
T
|
Délai entre la première commande passée par un client et la fin de la période de création des caractéristiques. | X | X |
time_between
|
Délai moyen entre les commandes d'un client au cours de la période de création des caractéristiques. | X | |
avg_basket_value
|
Valeur monétaire moyenne du panier du client au cours de la période de création des caractéristiques. | X | |
avg_basket_size
|
Nombre d'articles figurant en moyenne dans le panier du client au cours de la période de création des caractéristiques. | X | |
cnt_returns
|
Nombre de commandes que le client a retournées au cours de la période de création des caractéristiques. | X | |
has_returned
|
Indique si le client a retourné au moins une commande au cours de la période de création des caractéristiques. | X | |
frequency_btyd_clipped
|
Caractéristique identique à frequency_btyd, mais dont les valeurs aberrantes sont tronquées. |
X | |
monetary_btyd_clipped
|
Caractéristique identique à monetary_btyd, mais dont les valeurs aberrantes sont tronquées. |
X | |
target_monetary_clipped
|
Caractéristique identique à target_monetary, mais dont les valeurs aberrantes sont tronquées. |
X | |
target_monetary
|
Montant total dépensé par un client, y compris pendant les périodes d'entraînement et cibles. | X |
La sélection de ces colonnes se déroule dans le code. Pour les modèles probabilistes, la sélection est effectuée à l'aide d'un DataFrame Pandas :
Pour les modèles DNN, les fonctionnalités TensorFlow sont définies dans le fichier context.py. Pour ces modèles, les éléments suivants sont ignorés en tant que caractéristiques :
customer_id. Il s'agit d'une valeur unique qui ne présente pas d'utilité en tant que fonctionnalité.target_monetary. Il s'agit de la cible que le modèle doit prédire. Elle n'est donc pas utilisée comme entrée.
Créer les ensembles d'entraînement, d'évaluation et de test du DNN
Cette section ne s'applique qu'aux modèles de DNN. Pour entraîner un modèle de ML, vous devez employer trois ensembles de données qui ne se chevauchent pas :
L'ensemble de données d'entraînement (70–80 %) permet l'apprentissage des pondérations afin de réduire une fonction de perte. L'entraînement continue jusqu'à ce que la fonction de perte cesse de décliner.
L'ensemble de données d'évaluation (10–15 %) est employé pendant la phase d'entraînement pour éviter le surapprentissage, c'est-à-dire une situation où un modèle donne de bons résultats avec les données d'entraînement mais est difficile à généraliser.
L'ensemble de données de test (10–15 %) ne doit servir qu'une seule fois, une fois l'entraînement et l'évaluation terminés, pour effectuer une mesure finale des performances du modèle. Il s'agit d'un ensemble de données que le modèle n'a jamais vu pendant le processus d'entraînement. Il fournit donc une mesure statistiquement valide de la précision du modèle.
La requête suivante crée un ensemble d'entraînement comportant environ 70 % des données. Elle sépare les données à l'aide de la technique suivante :
- Un hachage du numéro client est calculé, ce qui produit un entier.
- Une opération modulo permet de sélectionner les valeurs de hachage inférieures à un certain seuil.
Le même concept est appliqué pour l'ensemble d'évaluation et l'ensemble de test, où les données dépassant le seuil sont conservées.
Formation
Comme vous l'avez vu dans la section précédente, vous pouvez utiliser différents modèles pour prédire la CLV. Le code utilisé dans cet article a été conçu pour vous permettre de choisir le modèle à utiliser. Vous choisissez le modèle à l'aide du paramètre model_type que vous transmettez au script shell d'entraînement suivant. Le code s'occupe du reste.
L'objectif premier de l'entraînement est de permettre aux deux modèles de dépasser un benchmark naïf, défini ci-dessous. Si les deux types de modèles peuvent le dépasser (ce qui doit être le cas), vous pouvez alors comparer les performances de chaque type l'un par rapport à l'autre.
Procéder au benchmarking des modèles
Pour les besoins de cette série d'articles, un benchmark naïf est défini à l'aide des paramètres suivants :
- Valeur moyenne du panier. Ce paramètre est calculé sur toutes les commandes passées avant la date seuil.
- Nombre de commandes. Ce paramètre est calculé pour l'intervalle d'entraînement sur toutes les commandes passées avant la date seuil.
- Multiplicateur de comptage. Ce paramètre est calculé sur la base du ratio entre le nombre de jours avant la date seuil et le nombre de jours entre la date seuil et la date actuelle.
Le benchmark suppose naïvement que la fréquence d'achat d'un client au cours de l'intervalle d'entraînement reste constante tout au long de l'intervalle cible. Ainsi, si un client effectue six achats sur une période de 40 jours, l'hypothèse est qu'il en effectuera neuf sur une période de 60 jours (60/40 * 6 = 9). La multiplication de la valeur moyenne du panier, du nombre de commandes et du multiplicateur de comptage de chaque client permet d'obtenir pour celui-ci une valeur cible prédite naïve.
L'erreur de benchmark est la racine carrée de l'erreur quadratique moyenne (RMSE, Root Mean Square Error), soit la moyenne pour tous les clients de la différence absolue entre la valeur cible prédite et la valeur cible réelle. La RMSE est calculée à l'aide de la requête suivante dans BigQuery :
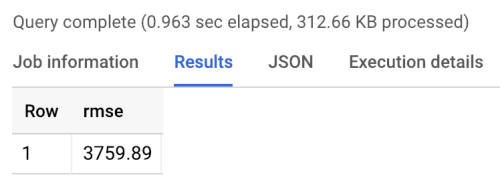
Le benchmark renvoie une RMSE d'environ 3760, comme indiqué dans les résultats d'exécution du benchmark ci-après. Les modèles devraient dépasser cette valeur.
Modèles probabilistes
Comme indiqué dans la partie 1, cette série d'articles utilise une bibliothèque Python appelée "Lifetimes" qui est compatible avec divers modèles, dont les modèles Pareto/Loi binomiale négative (NBD, Negative Binomial Distribution) et bêta-géométrique (BG/NBD). L'exemple de code suivant montre comment employer la bibliothèque Lifetimes pour effectuer des prédictions de la valeur vie client avec des modèles probabilistes.
Pour générer des résultats de CLV à l'aide du modèle probabilité dans votre environnement local, vous pouvez exécuter le script mltrain.sh suivant. Vous fournissez des paramètres pour les dates de début et de fin de l'intervalle d'entraînement et pour la fin de la période de prédiction.
./mltrain.sh local data --model_type paretonbd_model --threshold_date [YOUR_THRESHOLD_DATE] --predict_end [YOUR_END_DATE]
Modèles de DNN
L'exemple de code inclut des mises en œuvre dans TensorFlow de DNN à l'aide de la classe Estimator DNNRegressor prédéfinie, ainsi qu'un modèle Estimator personnalisé. Le DNNRegressor et l'estimateur personnalisé utilisent le même nombre de couches et le même nombre de neurones dans chaque couche. Ces valeurs sont des hyperparamètres qui doivent être ajustés. Dans le fichier task.py suivant, vous trouverez une liste de certains hyperparamètres définis sur des valeurs testées manuellement et ayant donné de bons résultats.
Si vous utilisez AI Platform, vous pouvez employer la fonctionnalité de réglage des hyperparamètres, qui permet de tester une plage de paramètres que vous définissez dans un fichier yaml. AI Platform utilise l'optimisation bayésienne pour exécuter des recherches sur l'espace d'hyperparamètres.
Résultats de la comparaison des modèles
Le tableau suivant montre les valeurs RMSE de chaque modèle, tel qu'il a été entraîné sur l'exemple d'ensemble de données. Tous les modèles sont entraînés sur des données RFM. Les valeurs RMSE varient légèrement entre les exécutions, en raison de l'initialisation aléatoire des paramètres. Le modèle de DNN utilise des caractéristiques supplémentaires telles que la valeur moyenne du panier et le nombre de retours.
| Modèle | RMSE |
|---|---|
| DNN | 947.9 |
| BG/NBD | 1557 |
| Pareto/NBD | 1558 |
Les résultats montrent que pour cet ensemble de données, le modèle de DNN surpasse les modèles probabilistes lors de la prédiction de la valeur monétaire. Cependant, la taille relativement petite de l'ensemble de données de l'UCI limite la validité statistique de ces résultats. Vous devriez appliquer chacune des techniques à votre ensemble de données pour voir laquelle vous permet d'obtenir les meilleurs résultats. Tous les modèles ont été entraînés en utilisant les mêmes données d'origine (y compris le numéro client, la date et la valeur de la commande) sur les valeurs RFM extraites de ces données. Les données d'entraînement du modèle de DNN incluent certaines caractéristiques supplémentaires telles que la taille moyenne du panier et le nombre de retours.
Le modèle de DNN n'affiche que la valeur monétaire globale du client. Si vous souhaitez prédire la fréquence ou la perte d'utilisateurs, vous devez effectuer quelques tâches supplémentaires :
- Préparez les données différemment pour changer la cible et éventuellement la date seuil.
- Ré-entraînez un modèle de régression pour prédire la cible qui vous intéresse.
- Réglez les hyperparamètres.
L'objectif ici était d'effectuer une comparaison avec les mêmes caractéristiques d'entrée pour les deux types de modèles. L'emploi des DNN présente un avantage : vous pouvez améliorer vos résultats en ajoutant des caractéristiques en plus de celles utilisées dans cet exemple. Avec les DNN, vous pouvez tirer parti des données de sources telles que des événements de flux de clics, des profils utilisateur ou des caractéristiques de produit.
Remerciements
Dua, D. and Karra Taniskidou, E. (2017). UCI Machine Learning Repository : http://archive.ics.uci.edu/ml. Irvine, Californie : Université de Californie, School of Information and Computer Science.
Étape suivante
- Consultez la partie 3 : Déployer en production de cette série d'articles pour comprendre comment déployer ces modèles.
- Découvrez d'autres solutions de prévisions de prédiction.
- Explorez des architectures de référence, des schémas, des tutoriels et des bonnes pratiques concernant Google Cloud. Consultez notre Centre d'architecture cloud.