Cet article constitue la quatrième partie d'une série en quatre parties qui explique comment prédire la valeur du client (CLV) à l'aide d'AI Platform sur Google Cloud. Cet article vous explique comment utiliser AutoML Tables pour effectuer les prédictions.
Cette série est constituée des articles suivants :
- Partie 1 : Introduction. Présente la CLV et deux techniques de modélisation permettant sa prédiction.
- Partie 2: Entraîner le modèle. Explique comment préparer les données et entraîner les modèles.
- Partie 3 : Déployer en production. Décrit comment déployer les modèles présentés dans la partie 2 sur un système de production.
- Partie 4 : Utiliser AutoML Tables (cet article). Explique comment créer et déployer un modèle en utilisant AutoML Tables.
Le processus détaillé sur cette page s'appuie sur les étapes de traitement des données via BigQuery décrites dans la partie 2 de la série. Cet article explique comment importer l'ensemble de données BigQuery dans AutoML Tables et comment créer un modèle. Il vous apprend également à intégrer le modèle AutoML au système de production décrit dans la partie 3.
Le code employé pour la mise en œuvre de ce système se trouve dans le dépôt GitHub utilisé pour les parties précédentes de la série. Cet article vous explique comment exploiter le code de ce dépôt avec AutoML Tables.
Avantages d'AutoML Tables
Dans les parties précédentes de cette série, nous vous avons montré comment prédire la valeur du client à l'aide d'un modèle statistique et d'un modèle de réseau de neurones profond (DNN, Deep Neural Network) mis en œuvre dans TensorFlow. AutoML Tables présente plusieurs avantages par rapport aux deux autres méthodes:
- La création du modèle ne nécessite aucun codage. Une UI de console vous permet de créer, d'entraîner, de gérer et de déployer vos ensembles de données et vos modèles.
- Vous pouvez facilement ajouter ou modifier des caractéristiques directement depuis l'interface de la console.
- Le processus d'entraînement est automatisé, y compris le réglage d'hyperparamètres.
- AutoML Tables recherche la meilleure architecture pour votre ensemble de données, ce qui vous évite d'avoir à choisir parmi les nombreuses options disponibles.
- AutoML Tables fournit une analyse détaillée des performances d'un modèle entraîné, y compris de l'importance des caractéristiques.
Par conséquent, il peut s'avérer plus rapide et plus économique de développer un modèle entièrement optimisé à l'aide d'AutoML Tables.
Un déploiement en production d'une solution AutoML Tables nécessite l'utilisation de l'API cliente Python pour créer et déployer des modèles, ainsi que pour exécuter des prédictions. Cet article explique comment créer et entraîner des modèles AutoML Tables à l'aide de l'API cliente. Pour savoir comment effectuer ces étapes à l'aide de la console AutoML Tables, consultez la documentation AutoML Tables.
Installer le code
Suivez la procédure détaillée dans la partie 2 de cette série pour installer le code si vous ne l'avez pas déjà fait. Le fichier README du dépôt GitHub décrit toutes les étapes nécessaires pour préparer votre environnement, installer le code et configurer AutoML Tables dans votre projet.
Si vous avez déjà installé le code, suivez ces étapes supplémentaires pour terminer l'installation requise ici :
- Activez l'API AutoML Tables dans votre projet.
- Activez l'environnement miniconda que vous avez précédemment installé.
- Installez la bibliothèque cliente Python, comme décrit dans la documentation d'AutoML Tables.
- Créez et téléchargez un fichier de clé API, puis enregistrez-le dans un emplacement connu pour une utilisation ultérieure avec la bibliothèque cliente.
Exécuter le code
Vous allez exécuter des commandes Python pour la plupart des étapes décrites dans cet article. Après avoir préparé votre environnement et installé le code, vous disposez des options suivantes pour exécuter le code :
Exécutez le code dans un notebook Jupyter. Dans la fenêtre de terminal de votre environnement miniconda activé, exécutez la commande suivante :
$ (clv) jupyter notebook
Le code de chacune des étapes décrites dans cet article est stocké dans un notebook situé dans le dépôt de code
notebooks/clv_automl.ipynb. Ouvrez ce notebook dans l'interface Jupyter. Vous pouvez ensuite effectuer toutes les étapes du tutoriel.Exécutez le code en tant que script Python. Les étapes de ce tutoriel concernant le code se trouvent dans le dépôt de code du fichier
clv_automl/clv_automl.py. Le script utilise des arguments sur la ligne de commande pour les paramètres configurables tels que l'ID du projet, l'emplacement du fichier de clé API, la région Google Cloud et le nom de l'ensemble de données BigQuery. Vous exécutez le script depuis la fenêtre de terminal de votre environnement miniconda activé, en remplaçant[YOUR_PROJECT]par le nom de votre projet Google Cloud :$ (clv) cd clv_automl $ (clv) python clv_automl.py --project_id [YOUR_PROJECT]
Pour obtenir la liste complète des paramètres et valeurs par défaut, reportez-vous à la méthode
create_parserdu script, ou exécutez le script sans argument pour afficher la documentation sur son utilisation.Une fois l'environnement Cloud Composer installé comme décrit dans le fichier README, exécutez le code en lançant les graphes orientés acycliques (DAG, Directed Acyclic Graph) comme indiqué dans la section Exécuter les DAG dans la suite de ce document.
Préparer les données
Cet article utilise le même ensemble de données et les mêmes étapes de préparation des données via BigQuery que celles décrites dans la partie 2 de la série. Une fois l'agrégation des données terminée comme indiqué dans la partie 2, vous pouvez créer un ensemble de données à utiliser avec AutoML Tables.
Créer l'ensemble de données AutoML Tables
Pour commencer, importez les données que vous avez préparées via BigQuery dans AutoML Tables.
Pour initialiser le client, définissez le nom du fichier de clé sur le nom du fichier que vous avez téléchargé à l'étape d'installation :
keyfile_name = "mykey.json" client = automl_v1beta1.AutoMlClient.from_service_account_file(keyfile_name)Créez l'ensemble de données :
create_dataset_response = client.create_dataset( location_path, {'display_name': dataset_display_name, 'tables_dataset_metadata': {}}) dataset_name = create_dataset_response.name
Importer les données depuis BigQuery
Une fois l'ensemble de données créé, vous pouvez importer les données depuis BigQuery.
Importez les données de BigQuery dans l'ensemble de données AutoML Tables :
dataset_bq_input_uri = 'bq://{}.{}.{}'.format(args.project_id, args.bq_dataset, args.bq_table) input_config = { 'bigquery_source': { 'input_uri': dataset_bq_input_uri}} import_data_response = client.import_data(dataset_name, input_config)
Entraîner le modèle
Une fois que vous avez créé l'ensemble de données AutoML pour les données CLV, vous pouvez créer le modèle AutoML Tables.
Obtenez les spécifications de colonne AutoML Tables pour chaque colonne de l'ensemble de données :
list_table_specs_response = client.list_table_specs(dataset_name) table_specs = [s for s in list_table_specs_response] table_spec_name = table_specs[0].name list_column_specs_response = client.list_column_specs(table_spec_name) column_specs = {s.display_name: s for s in list_column_specs_response}Les spécifications de colonne sont nécessaires pour les prochaines étapes.
Définissez l'une des colonnes en tant qu'étiquette du modèle AutoML Tables :
TARGET_LABEL = 'target_monetary' ... label_column_name = TARGET_LABEL label_column_spec = column_specs[label_column_name] label_column_id = label_column_spec.name.rsplit('/', 1)[-1] update_dataset_dict = { 'name': dataset_name, 'tables_dataset_metadata': { 'target_column_spec_id': label_column_id } } update_dataset_response = client.update_dataset(update_dataset_dict)Ce code utilise la même colonne d'étiquette (
target_monetary) que le modèle DNN TensorFlow de la partie 2.Définissez les caractéristiques à utiliser pour l'entraînement du modèle :
feat_list = list(column_specs.keys()) feat_list.remove('target_monetary') feat_list.remove('customer_id') feat_list.remove('monetary_btyd') feat_list.remove('frequency_btyd') feat_list.remove('frequency_btyd_clipped') feat_list.remove('monetary_btyd_clipped') feat_list.remove('target_monetary_clipped')Les caractéristiques utilisées pour entraîner le modèle AutoML Tables sont les mêmes que celles ayant permis d'entraîner le modèle de DNN TensorFlow dans la partie 2 de cette série. Toutefois, il est bien plus simple d'ajouter des caractéristiques au modèle ou d'en retirer avec AutoML Tables. Une fois une caractéristique créée dans BigQuery, elle est automatiquement incluse dans le modèle, sauf si vous la supprimez explicitement, comme indiqué dans l'extrait de code ci-dessus.
Définissez les options de création du modèle. Pour cet ensemble de données, nous vous recommandons de choisir un objectif d'optimisation visant à réduire l'erreur absolue moyenne, représenté par le paramètre
MINIMIZE_MAE.model_display_name = args.automl_model model_training_budget = args.training_budget * 1000 model_dict = { 'display_name': model_display_name, 'dataset_id': dataset_name.rsplit('/', 1)[-1], 'tables_model_metadata': { 'target_column_spec': column_specs['target_monetary'], 'input_feature_column_specs': [ column_specs[x] for x in feat_list], 'train_budget_milli_node_hours': model_training_budget, 'optimization_objective': 'MINIMIZE_MAE' } }Pour en savoir plus, consultez la documentation d'AutoML Tables concernant les objectifs d'optimisation.
Créez le modèle et commencez l'entraînement :
create_model_response = client.create_model(location_path, model_dict) create_model_result = create_model_response.result() model_name = create_model_result.nameLa valeur de renvoi de l'appel client (
create_model_response) est immédiatement renvoyée. La valeurcreate_model_response.result()est une promesse qui bloque votre code jusqu'à la fin de l'entraînement. La valeurmodel_nameest un chemin de ressource nécessaire pour les autres appels client qui opèrent sur le modèle.
Évaluer le modèle
Une fois l'entraînement terminé, vous pouvez récupérer les statistiques d'évaluation du modèle. Vous pouvez utiliser la console Google Cloud ou l'API cliente.
Si vous utilisez la console, accédez à l'onglet Evaluate (Évaluer) de la console AutoML Tables :

Si vous utilisez l'API cliente, récupérez les statistiques d'évaluation du modèle :
model_evaluations = [e for e in client.list_model_evaluations(model_name)] model_evaluation = model_evaluations[0]Un résultat semblable à celui-ci s'affiche :
name: "projects/595920091534/locations/us-central1/models/TBL3912308662231629824/modelEvaluations/9140437057533851929" create_time { seconds: 1553108019 nanos: 804478000 } evaluated_example_count: 125 regression_evaluation_metrics: { mean_absolute_error: 591.091 root_mean_squared_error: 853.481 mean_absolute_percentage_error: 21.47 r_squared: 0.907 }
La racine carrée de l'erreur quadratique moyenne est de 853,481. Il s'agit d'un meilleur résultat que celui obtenu pour les modèles probabilistes et TensorFlow utilisés dans cette série. Toutefois, comme indiqué dans la partie 2, nous vous recommandons d'essayer toutes les techniques fournies sur vos données afin d'identifier les plus performantes.
Déployer le modèle AutoML
Les DAG Cloud Composer des articles précédents de cette série ont été mis à jour de façon à inclure le modèle AutoML Tables pour l'entraînement et la prédiction. Pour en savoir plus sur le fonctionnement des DAG Cloud Composer, consultez la section Automatiser la solution de la partie 3.
Vous pouvez installer le système d'orchestration Cloud Composer pour cette solution en suivant les instructions du fichier README.
Les DAG mis à jour appellent des méthodes dans le script clv_automl/clv_automl.py, lesquelles répliquent les appels de code client indiqués précédemment afin de créer le modèle et d'exécuter des prédictions.
DAG d'entraînement
Le nouveau DAG pour l'entraînement inclut des tâches permettant de créer un modèle AutoML Tables. Le schéma suivant illustre ce DAG.

DAG de prédiction
Le nouveau DAG pour la prédiction inclut des tâches permettant d'effectuer des prédictions par lots à l'aide du modèle AutoML Tables. Le schéma suivant illustre ce DAG.
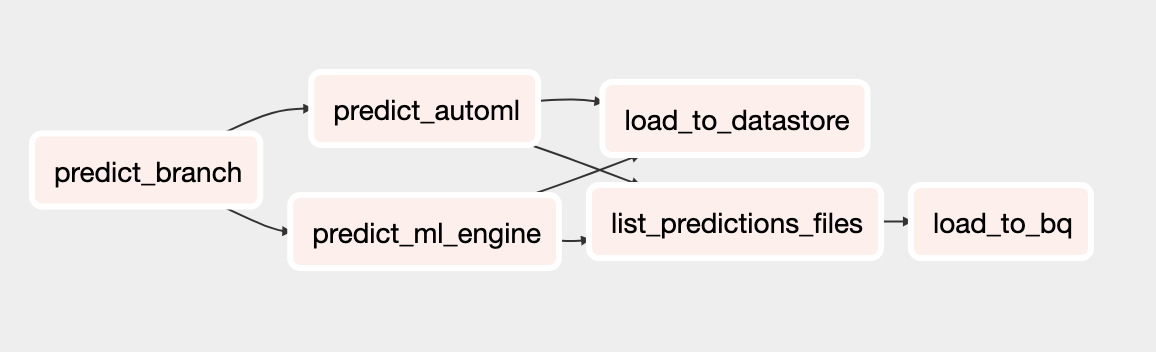
Exécuter les DAG
Pour déclencher les DAG manuellement, vous pouvez exécuter les commandes décrites dans la section Run Dags (Exécuter les DAG) du fichier README dans Cloud Shell ou en utilisant Google Cloud CLI.
Pour exécuter le DAG
build_train_deploy, utilisez le code suivant :gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ build_train_deploy \ --conf '{"model_type":"automl", "project":"'${PROJECT}'", "dataset":"'${DATASET_NAME}'", "threshold_date":"2011-08-08", "predict_end":"2011-12-12", "model_name":"automl_airflow", "model_version":"v1", "max_monetary":"15000"}'Exécutez le DAG
predict_serve:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ predict_serve \ --conf '{"model_name":"automl_airflow", "model_version":"v1", "dataset":"'${DATASET_NAME}'"}'
Étape suivante
- Consultez la série complète de tutoriels sur la valeur du client.
- Exécutez l'exemple complet dans le dépôt GitHub.
- Découvrez d'autres solutions de prévisions de prédiction.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.