Cet article constitue la troisième partie d'une série en quatre parties qui explique comment prédire la valeur du client (CLV) à l'aide d'AI Platform sur Google Cloud.
Cette série est constituée des articles suivants :
- Partie 1 : Introduction. Présente la CLV et deux techniques de modélisation permettant sa prédiction.
- Partie 2 : Entraîner le modèle. Explique comment préparer les données et entraîner les modèles.
- Partie 3 : Déployer en production (cet article). Décrit comment déployer les modèles présentés dans la partie 2 sur un système de production.
- Partie 4 : Utiliser AutoML Tables. Explique comment créer et déployer un modèle en utilisant AutoML Tables.
Installer le code
Si vous souhaitez suivre le processus décrit dans cet article, vous devez installer l'exemple de code depuis GitHub.
Si gcloud CLI est installé, ouvrez une fenêtre de terminal sur votre ordinateur pour exécuter ces commandes. Si gcloud CLI n'est pas installé, ouvrez une instance de Cloud Shell.
Clonez l'exemple de dépôt de code :
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Suivez les instructions d'installation figurant dans les sections relatives à l'installation et à l'automatisation du fichier README pour configurer votre environnement et déployer les composants de la solution. Cela inclut l'exemple d'ensemble de données et l'environnement Cloud Composer.
Les exemples de commandes indiqués dans les sections ci-après supposent que vous avez exécuté ces étapes.
Dans le cadre des instructions d'installation, vous configurez des variables pour votre environnement, comme indiqué dans la section sur la configuration du fichier README.
Modifiez la variable REGION pour qu'elle corresponde à la région Google Cloud la plus proche de vous géographiquement. Pour obtenir la liste des régions, consultez la page Régions et zones.
Architecture et mise en œuvre
Le schéma suivant représente l'architecture employée dans cet article.

L'architecture est divisée entre les fonctions suivantes :
- Ingestion des données : les données sont importées dans BigQuery.
- Préparation des données : les données brutes sont transformées de façon à être exploitables par les modèles.
- Entraînement des modèles : les modèles sont créés, entraînés et réglés de façon qu'ils puissent servir à exécuter des prédictions.
- Diffusion des prédictions : les prédictions hors connexion sont stockées et mises à disposition à une faible latence.
- Automatisation : toutes ces tâches sont exécutées et gérées via Cloud Composer.
Ingérer des données
Cette série d'articles ne traite pas d'une méthode spécifique d'ingestion de données. BigQuery peut ingérer des données de plusieurs manières, par exemple depuis Pub/Sub, Cloud Storage et le service de transfert de données BigQuery. Pour en savoir plus, consultez la page BigQuery pour les experts en entrepôts de données. Dans l'approche décrite dans cette série, nous utilisons un ensemble de données public. Vous importez cet ensemble de données dans BigQuery, comme décrit dans l'exemple de code du fichier README.
Préparer des données
Pour préparer des données, vous exécutez sur BigQuery des requêtes semblables à celles présentées dans la partie 2 de cette série. Dans une architecture de production, vous exécutez les requêtes dans le cadre d'un graphe orienté acyclique (DAG, Directed Acyclic Graph) Apache Airflow. La section sur l'automatisation plus loin dans ce document fournit davantage de détails sur l'exécution de requêtes pour la préparation des données.
Entraîner le modèle sur AI Platform
Cette section offre un aperçu de la partie entraînement de l'architecture.
Quel que soit le type de modèle que vous choisissez, vous pouvez exécuter le code présenté dans cette solution sur AI Platform à la fois pour l'entraînement et la prédiction. AI Platform offre les avantages suivants :
- Vous pouvez l'exécuter localement ou dans le cloud dans un environnement distribué.
- Il offre une connectivité intégrée à d'autres produits Google tels que Cloud Storage.
- Vous pouvez l'exécuter à l'aide de seulement quelques commandes.
- Il facilite le réglage des hyperparamètres.
- Son scaling nécessite des changements d'infrastructure minimes, le cas échéant.
Pour que AI Platform puisse entraîner et évaluer un modèle, vous devez fournir des ensembles de données d'entraînement, d'évaluation et de test. Pour créer les ensembles de données, exécutez des requêtes SQL telles que celles présentées dans la partie 2 de cette série. Ensuite, exportez-les à partir de tables BigQuery vers Cloud Storage. Dans l'architecture de production présentée dans cet article, les requêtes sont exécutées par un DAG Airflow, qui est décrit plus en détail dans la section sur l'automatisation ci-dessous. Vous pouvez exécuter le DAG manuellement, comme décrit dans la section Run DAGs (Exécuter les DAG) du fichier README.
Diffuser les prédictions
Les prédictions peuvent être créées en ligne ou hors connexion. Toutefois, créer des prédictions et les diffuser sont deux opérations différentes. Dans ce contexte de la CLV, des événements tels qu'un client qui se connecte à un site Web ou qui se rend dans un magasin de détail n'ont pas une très forte incidence sur la valeur du client. Par conséquent, les prédictions peuvent être effectuées hors connexion, même si les résultats doivent être présentés en temps réel. La prédiction hors connexion présente les caractéristiques opérationnelles suivantes :
- Vous pouvez exécuter les mêmes étapes de prétraitement pour l'entraînement et la prédiction. En cas de prétraitement différent, vos prédictions peuvent être moins précises. Ce phénomène est appelé décalage entraînement-diffusion.
- Vous pouvez préparer les données pour l'entraînement et pour la prédiction à l'aide des mêmes outils. L'approche présentée dans cette série emploie principalement BigQuery pour préparer les données.
Vous pouvez utiliser AI Platform pour déployer le modèle et effectuer des prédictions hors ligne à l'aide d'une tâche par lot. Pour la prédiction, AI Platform facilite l'exécution des tâches suivantes :
- Gestion des versions
- Scaling avec des changements d'infrastructure minimes
- Déploiement à grande échelle
- Interagir avec d'autres Google Cloud produits
- Utilisation d'un contrat de niveau de service
La tâche de prédiction par lot utilise des fichiers stockés sur Cloud Storage en entrée et en sortie. Pour le modèle de réseau de neurones profond (DNN, Deep Neural Network), la fonction de diffusion suivante, définie dans task.py, définit le format des entrées :
Le format de sortie des prédictions est défini dans un élément EstimatorSpec renvoyé par la fonction du modèle Estimator dans ce code extrait de model.py :
Utiliser les prédictions
Dès que les modèles ont été créés et déployés, vous pouvez vous en servir pour prédire la CLV. Voici des cas d'utilisation courants de la CLV :
- Un spécialiste des données peut exploiter les prédictions hors connexion lors de la création de segments d'utilisateurs.
- Votre organisation peut faire des offres spécifiques en temps réel, lorsqu'un client interagit avec votre marque en ligne ou dans un magasin.
Effectuer des analyses avec BigQuery
La compréhension de la CLV est essentielle pour les activations. Cet article porte principalement sur le calcul de la valeur vie client en fonction des ventes précédentes. Les données de vente proviennent généralement d'outils de gestion de la relation client (CRM, Customer Relationship Management), mais les informations sur le comportement des utilisateurs peuvent avoir d'autres sources telles que Google Analytics 360.
Vous devez utiliser BigQuery si vous souhaitez effectuer l'une des tâches suivantes :
- Stocker des données structurées provenant de nombreuses sources
- Transférer automatiquement des données à partir d'outils SaaS courants comme Google Analytics 360, YouTube ou AdWords
- Exécuter des requêtes ad hoc, y compris des jointures sur des téraoctets de données client
- Visualiser les données à l'aide des principaux outils de veille stratégique
Outre son rôle de moteur de stockage et de requête géré, BigQuery peut exécuter directement des algorithmes de machine learning à l'aide de BigQuery ML. En chargeant la valeur CLV de chaque client dans BigQuery, vous permettez aux analystes de données, aux data scientists et aux ingénieurs d'exploiter des métriques supplémentaires dans leurs tâches. Le DAG Airflow décrit dans la section suivante inclut une tâche permettant de charger les prédictions de CLV dans BigQuery.
Diffuser à une faible latence avec Datastore
Les prédictions effectuées hors connexion peuvent souvent être réutilisées pour fournir des prédictions en temps réel. Pour ce scénario, la fraîcheur des prédictions n'est pas essentielle. Il est par contre indispensable de pouvoir accéder rapidement aux données, au moment voulu.
Le stockage des prédictions hors connexion à des fins de diffusion en temps réel implique que les actions entreprises par un client ne modifieront pas immédiatement sa CLV. Cependant, il est important d'avoir rapidement accès à cette CLV. Par exemple, votre entreprise peut souhaiter réagir rapidement lorsqu'un client utilise votre site Web, pose une question à votre service d'assistance ou passe commande auprès de votre point de vente. Dans de tels cas de figure, une réponse rapide peut améliorer la relation client. Par conséquent, le stockage des résultats des prédictions dans une base de données rapide et la mise à disposition de requêtes sécurisées sur votre interface sont les clés du succès.
Supposons que vous ayez des centaines de milliers de clients uniques. Datastore est idéal pour les raisons suivantes:
- Il est compatible avec les bases de données orientées documents NoSQL.
- Il fournit un accès rapide aux données à l'aide d'une clé (numéro client), et active également les requêtes SQL.
- Il est accessible via une API REST.
- Il est prêt à l'emploi, ce qui signifie qu'il n'entraîne aucune surcharge de configuration.
- Son scaling est automatique.
Il n'existe aucun moyen de charger directement un ensemble de données CSV dans Datastore. Ainsi, dans cette solution, nous employons Apache Beam sur Dialogflow avec un modèle JavaScript pour charger les prédictions CLV dans Datastore. L'extrait de code suivant du modèle JavaScript montre comment procéder :
Lorsque les données se trouvent dans Datastore, vous pouvez choisir le mode d'interaction souhaité, par exemple :
- Utilisation des bibliothèques clientes Datastore à partir de votre application
- Créer un point de terminaison d'API à l'aide de Cloud Endpoints ou de la plate-forme d'API Apigee
- Utilisation de fonctions Cloud Run pour les tâches sans serveur
Automatiser la solution
Vous exécutez les étapes décrites jusqu'à présent lorsque vous commencez à utiliser les données afin d'exécuter les premières étapes de prétraitement, d'entraînement et de prédiction. Mais votre plate-forme n'est pas complètement prête pour la production, car vous devez encore procéder à l'automatisation et à la gestion des échecs.
Certains scripts peuvent aider faire le lien entre ces étapes. Cependant, il est recommandé d'automatiser les étapes à l'aide d'un gestionnaire de workflow. Apache Airflow est un outil de gestion de workflow couramment utilisé. Vous pouvez aussi exécuter un pipeline Airflow géré sur Google Cloudà l'aide de Cloud Composer.
Airflow fonctionne avec les DAG, qui vous permettent de spécifier chaque tâche ainsi que sa relation avec les autres tâches. Dans l'approche décrite dans cette série, vous exécutez les étapes suivantes :
- Créer des ensembles de données BigQuery
- Charger l'ensemble de données public de Cloud Storage vers BigQuery
- Nettoyer les données d'une table BigQuery, puis les écrire dans une nouvelle table BigQuery
- Créer des caractéristiques basées sur des données dans une table BigQuery, puis les écrire dans une autre table BigQuery
- Si le modèle est un réseau de neurones profond (DNN, Deep Neural Network), diviser les données en un ensemble d'entraînement et un ensemble d'évaluation dans BigQuery
- Exporter les ensembles de données vers Cloud Storage et les mettre à la disposition de AI Platform
- Configurer AI Platform de sorte qu'il entraîne régulièrement le modèle
- Déployer le modèle mis à jour sur AI Platform
- Exécuter régulièrement une prédiction par lot sur de nouvelles données
- Enregistrer les prédictions déjà enregistrées dans Cloud Storage dans Datastore et BigQuery
Configurer Cloud Composer
Pour en savoir plus sur la configuration de Cloud Composer, consultez les instructions figurant dans le fichier README du dépôt GitHub.
Graphes orientés acycliques pour cette solution
Cette solution fait appel à deux DAG. Le premier DAG couvre les étapes 1 à 8 de la séquence répertoriée précédemment :
Le schéma suivant illustre l'interface utilisateur de Cloud Composer/Airflow, qui résume les étapes 1 à 8 du DAG Airflow.
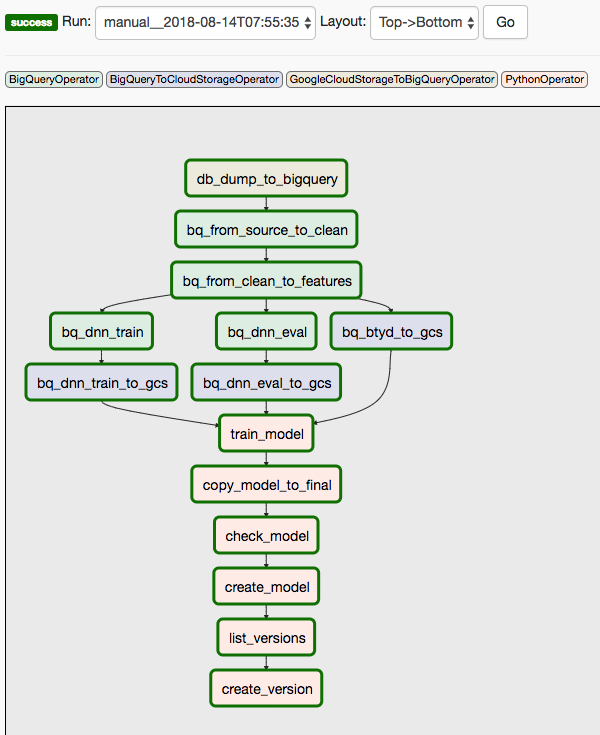
Le second DAG couvre les étapes 9 et 10.
Le schéma suivant résume les étapes 9 et 10 du processus DAG Airflow.
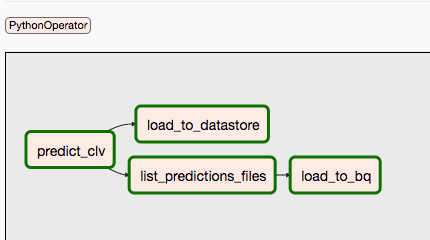
Les DAG sont séparés, car les prédictions et l'entraînement peuvent se dérouler indépendamment et selon un calendrier différent. Vous pouvez, par exemple, effectuer les opérations suivantes :
- Prédire quotidiennement les données pour les clients nouveaux ou existants
- Ré-entraîner le modèle chaque semaine pour incorporer de nouvelles données, ou le déclencher après la réception d'un nombre spécifique de nouvelles transactions
Pour déclencher manuellement le premier DAG, vous pouvez exécuter la commande décrite dans la section Run Dags (Exécuter les DAG) du fichier README dans Cloud Shell ou à l'aide de la CLI gcloud.
Le paramètre conf transmet des variables à différentes parties de l'automatisation. Par exemple, dans la requête SQL suivante, qui est employée pour extraire des caractéristiques des données nettoyées, les variables servent à paramétrer la clause FROM :
Vous pouvez déclencher le second DAG à l'aide d'une commande similaire. Pour plus de détails, consultez le fichier README du dépôt GitHub.
Étapes suivantes
- Exécutez l'exemple complet dans le dépôt GitHub.
- Intégrez de nouvelles caractéristiques dans le modèle de CLV à l'aide des éléments suivants :
- Des données sur les flux de clics, qui peuvent vous aider à prédire la CLV des clients pour lesquels vous ne possédez aucune donnée historique.
- Des départements et des catégories de produits, qui peuvent ajouter du contexte et aider le réseau de neurones.
- Des caractéristiques que vous créez avec les mêmes entrées que celles employées dans cette solution. Il peut s'agir par exemple des tendances des ventes pour les dernières semaines ou les derniers mois précédant la date seuil.
- Consultez la section Partie 4 : Utiliser AutoML Tables pour le modèle.
- Découvrez d'autres solutions de prévisions de prédiction.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.