Ce document est le premier d'une série consacrée à la reprise après sinistre (DR, Disaster recovery) dans Google Cloud. Il décrit le processus de planification de reprise après sinistre et vous explique comment établir et mettre en œuvre un plan de reprise. Les parties suivantes présentent des cas d'utilisation spécifiques de reprise après sinistre, avec des exemples de mise en œuvre sur Google Cloud.
Cette série comprend les parties suivantes :
- Guide de planification de reprise après sinistre (ce document)
- Structure de la reprise après sinistre
- Scénarios de reprise après sinistre pour les données
- Scénarios de reprise après sinistre pour les applications
- Concevoir une solution de reprise après sinistre pour des charges de travail limitées à la localité
- Cas d'utilisation de reprise après sinistre : applications d'analyse de données limitées à la localité
- Concevoir une solution de reprise après sinistre pour les pannes d'infrastructure cloud
Introduction
Des événements d'interruption de service peuvent survenir à tout moment. Vous pouvez subir une panne de réseau, votre dernier déploiement d'application peut entraîner un bug critique ou vous pouvez être victime d'une catastrophe naturelle. En cas de problème, il est important de disposer d'un plan de reprise après sinistre solide, ciblé et bien testé.
Un plan bien conçu vous permet en effet de minimiser l'impact financier qu'une éventuelle catastrophe peut causer à votre entreprise. Quels que soient vos besoins en termes de reprise après sinistre, Google Cloud propose une sélection de fonctionnalités et produits puissants, flexibles et économiques qui vous permettent de créer ou d'améliorer la solution qui vous correspond.
Principes de base de la planification de reprise après sinistre
La reprise après sinistre est un sous-ensemble du plan de continuité des activités. Elle commence par une analyse de l'impact commercial qui définit deux métriques clés :
- Un objectif de délai de reprise (RTO), qui correspond à la durée maximale acceptable pendant laquelle votre application peut être indisponible. Cette valeur est généralement définie dans le cadre d'un contrat de niveau de service plus vaste.
- Un objectif de perte de données maximale admissible (RPO), qui correspond à la durée maximale acceptable pendant laquelle votre application peut perdre des données en raison d'un incident majeur. Cette métrique varie en fonction de la manière dont les données sont utilisées. Par exemple, des données utilisateur régulièrement modifiées peuvent avoir un RPO de quelques minutes seulement. En revanche, des données moins critiques et rarement modifiées peuvent avoir un RPO de plusieurs heures. (Cette métrique ne décrit que la durée, elle ne traite pas de la quantité ni de la qualité des données perdues.)
En règle générale, plus les valeurs RTO et RPO sont faibles (c'est-à-dire, plus votre application doit récupérer rapidement d'une interruption), plus les coûts d'exécution de votre application sont élevés. Le graphique suivant décrit le ratio entre les coûts et les valeurs RTO/RPO.
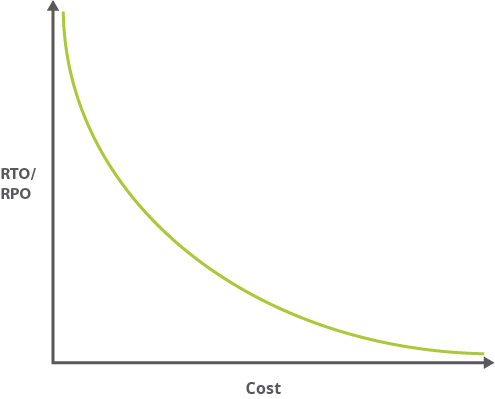
Comme des valeurs RTO et RPO plus faibles impliquent souvent davantage de complexité, les frais administratifs associés s'en voient également accrus. Une application haute disponibilité peut nécessiter la gestion de la distribution entre deux centres de données séparés physiquement, la gestion de la réplication, etc.
Les valeurs RTO et RPO sont généralement regroupées dans une autre métrique : l'objectif de niveau de service (SLO), qui constitue un élément clé mesurable d'un contrat de niveau de service. Les contrats de niveau de service et les SLO sont souvent confondus. Un contrat de niveau de service est un contrat intégral qui spécifie le service à fournir, la manière dont il est géré, ses heures, ses emplacements, ses coûts, ses performances, ses pénalités ainsi que les responsabilités des parties concernées. Les SLO sont quant à eux des caractéristiques spécifiques et mesurables du SLA, telles que la disponibilité, le débit, la fréquence, le temps de réponse ou la qualité. Un SLA peut contenir de nombreux SLO. Les RTO et les RPO sont mesurables et doivent être considérés comme des SLO.
Pour en savoir plus sur les SLO et SLA, consultez le manuel de Google sur l'ingénierie en fiabilité des sites.
Vous planifiez peut-être également une architecture pour la haute disponibilité. Celle-ci n'empiète pas totalement sur la reprise après sinistre, mais il est souvent nécessaire d'en tenir compte lorsque vous réfléchissez aux valeurs RTO et RPO. La haute disponibilité aide à fournir le niveau de performances opérationnelles qui a été convenu (généralement, un temps d'activité) pendant une période supérieure à la normale. Lorsque vous exécutez des charges de travail de production sur Google Cloud, vous pouvez utiliser un système distribué à l'échelle mondiale. Ainsi, en cas de problème dans une région, l'application continue de fournir le service, même s'il est moins disponible. Fondamentalement, cette application exploite son plan de reprise après sinistre.
Pourquoi choisir Google Cloud ?
Comparé à une utilisation sur site conforme aux exigences en matière de RTO et RPO, Google Cloud peut réduire considérablement les coûts associés à ces métriques. Par exemple, la planification de reprise après sinistre classique nécessite de prendre en compte un certain nombre d'exigences, dont les suivantes :
- Capacité : mobiliser suffisamment de ressources pour pouvoir s'adapter en fonction des besoins.
- Sécurité : assurer la sécurité physique pour protéger les ressources.
- Infrastructure réseau : intégrer des composants logiciels tels que des pare-feu et des équilibreurs de charge.
- Assistance : mettre à disposition des techniciens qualifiés pour la maintenance et la résolution des problèmes.
- Bande passante : prévoir une bande passante adaptée aux pics de charge.
- Installations : garantir une infrastructure physique, dont les équipements et l'énergie.
En fournissant une solution hautement gérée sur une plate-forme de production de pointe, Google Cloud vous aide à contourner la plupart ou la totalité de ces facteurs de complication, supprimant ainsi de nombreux coûts d'entreprise. En outre, l'accent mis par Google Cloud sur la simplicité administrative implique également une réduction des coûts de gestion liés aux applications complexes.
Google Cloud offre plusieurs caractéristiques pertinentes pour la planification de la reprise après sinistre :
- Un réseau mondial. Nous possédons l'un des réseaux informatiques les plus étendus et les plus sophistiqués au monde. Le réseau backbone de Google fait appel à une technologie de mise en réseau avancée définie par logiciel et propose des services de mise en cache périphérique pour offrir des performances élevées, constantes et évolutives.
- Redondance. La multiplicité de nos points de présence à travers le monde permet d'assurer une excellente redondance. Vos données sont automatiquement répliquées sur les appareils de stockage de plusieurs sites.
- Évolutivité. Google Cloud est conçu pour évoluer comme d'autres produits Google, tels que la recherche et Gmail, même en cas de pic de trafic important. Les services gérés tels qu'App Engine, les autoscalers Compute Engine et Datastore vous offrent un scaling automatique qui permet à votre application d'augmenter ou de réduire sa capacité selon les besoins.
- Sécurité. Notre modèle de sécurité est le fruit de plus de quinze ans d'expérience consacrés à protéger nos clients et nos applications telles que Gmail et Google Workspace. De plus, nos équipes d'ingénieurs chargés de la fiabilité des sites aident à garantir un niveau de disponibilité élevé et à éviter toute utilisation abusive des ressources de la plate-forme.
- Conformité. Google se soumet régulièrement à des audits tiers indépendants afin de vérifier que Google Cloud est conforme aux règles et bonnes pratiques liées à la sécurité, la confidentialité et la conformité. Google Cloud est conforme aux normes telles que ISO 27001, SOC 2/3 et PCI DSS 3.0.
Modèles de reprise après sinistre
Les modèles de reprise après sinistre peuvent être à froid, à tiède ou à chaud, ce qui indique la facilité avec laquelle un système peut récupérer à la suite d'un problème. Nous pourrions comparer ces modèles à la crevaison d'un pneu de voiture.

Votre réaction lors d'une crevaison dépend de votre niveau de préparation :
- À froid : vous n'avez pas de roue de secours. Vous devez donc appeler quelqu'un pour remplacer le pneu crevé. Votre voyage est interrompu jusqu'à ce qu'on vous apporte la roue de secours et qu'on effectue les réparations.
- À tiède : vous disposez d'une roue de secours et d'un kit de remplacement. Vous pouvez donc reprendre la route grâce au matériel présent dans votre voiture, mais devez toutefois suspendre votre voyage le temps d'effectuer les réparations.
- À chaud : vous possédez des pneus de roulage à plat. Vous devrez peut-être ralentir légèrement, mais cela n'aura aucun impact immédiat sur votre voyage. Vos pneus sont suffisamment en bon état pour que vous puissiez continuer votre route (mais vous devrez tout de même régler le problème à un moment ou un autre).
Établir un plan détaillé de reprise après sinistre
Cette section fournit des recommandations sur l'élaboration d'un plan de reprise après sinistre.
Établir un plan en fonction de vos objectifs de reprise
Lorsque vous établissez votre plan de reprise après sinistre, vous devez combiner vos techniques de récupération relatives à l'application et aux données et examiner la situation dans son ensemble. La manière classique de procéder consiste à déterminer vos valeurs RTO et RPO et à étudier le modèle de reprise après sinistre que vous pouvez adopter pour les atteindre. Par exemple, dans le cas de données historiques axées sur la conformité, vous n'avez probablement pas besoin d'un accès rapide. Il convient alors mieux d'utiliser une valeur RTO élevée et un modèle de reprise après sinistre à froid. Toutefois, si votre service en ligne subit une interruption, vous voudrez pouvoir retrouver le plus rapidement possible les données et la partie de l'application destinée aux clients. Dans ce cas, un modèle à chaud serait plus approprié. Quant à votre système de notification par e-mail, qui n'est généralement pas critique pour votre entreprise, il est sans doute plus adapté à un modèle à tiède.
Pour découvrir comment traiter des cas de figure courants de reprise après sinistre à l'aide de Google Cloud, consultez les scénarios de reprise d'application. Ces scénarios fournissent des stratégies de reprise après sinistre ciblées pour divers cas d'utilisation et proposent des exemples de mises en œuvre sur Google Cloud pour chacun d'entre eux.
Établir un plan pour une reprise de bout en bout
Il ne suffit pas de créer un plan de sauvegarde ou d'archivage des données. Vous devez également vous assurer que votre plan de reprise après sinistre englobe l'ensemble du processus de récupération, de la sauvegarde à la restauration en passant par le nettoyage. Nous abordons ce point dans les documents connexes sur la reprise après sinistre pour les données.
Créer des tâches spécifiques
Au moment d'exécuter votre plan de reprise après sinistre, vous ne voulez pas avoir à deviner à quoi correspond chaque étape. Assurez-vous donc que chaque tâche de votre plan consiste en une ou plusieurs commandes ou actions claires et concrètes. Par exemple, l'action "Exécuter le script de restauration" est trop générale. En revanche, l'action "Ouvrir Bash et exécuter /home/example/restore.sh" est précise et concrète.
Mettre en place des mesures de contrôle
Ajoutez des contrôles pour éviter toute catastrophe et détecter les problèmes avant qu'ils ne surviennent. Vous pouvez par exemple mettre en place un contrôle de surveillance qui envoie une alerte lorsqu'un flux destructeur de données (tel qu'un pipeline de suppression) présente des pics inattendus ou une autre activité inhabituelle. Ce contrôle de surveillance peut également mettre fin aux processus du pipeline si un certain seuil de suppression est atteint, ce qui permet d'éviter des situations catastrophiques.
Préparer le logiciel
Une étape de la planification de reprise après sinistre consiste à s'assurer que le logiciel utilisé est prêt à traiter un événement de récupération.
Vérifier que vous pouvez installer le logiciel
Vérifiez que votre logiciel d'application peut être installé à partir de la source ou d'une image préconfigurée. Assurez-vous de disposer de la licence appropriée pour tout logiciel que vous allez déployer sur Google Cloud. Consultez le fournisseur du logiciel pour en savoir plus.
Assurez-vous que les ressources Compute Engine nécessaires sont disponibles dans l'environnement de reprise. Vous devrez peut-être pré-allouer des instances ou les réserver.
Concevoir un déploiement continu pour la reprise
Votre ensemble d'outils de déploiement continu fait partie intégrante du déploiement de vos applications. Dans le cadre de votre plan, vous devez déterminer à quel emplacement vous allez déployer des artefacts au sein de votre environnement de reprise. Planifiez la zone d'hébergement de votre environnement et de vos artefacts de déploiement continu. Ils doivent être disponibles et opérationnels en cas de sinistre.
Mettre en place des contrôles de sécurité et de conformité
Lors de l'établissement d'un plan de reprise après sinistre, la sécurité joue un rôle majeur. Les contrôles de votre environnement de production doivent pouvoir s'appliquer à votre environnement de reprise. Les règles relatives à la conformité s'appliqueront également à celui-ci.
Configurer la sécurité de la même manière pour les environnements de production et de reprise après sinistre
Assurez-vous que vos contrôles réseau fournissent la même séparation et les mêmes blocages que l'environnement de production source. Apprenez à configurer le VPC partagé et les pare-feu pour établir un réseau centralisé et un contrôle de sécurité de votre déploiement, configurer des sous-réseaux, contrôler le trafic entrant et sortant, etc. Découvrez comment utiliser les comptes de service pour mettre en œuvre le principe du moindre privilège pour les applications qui accèdent aux API Google Cloud. Assurez-vous d'utiliser des comptes de service dans les règles de pare-feu.
Assurez-vous d'accorder aux utilisateurs le même accès à l'environnement de reprise après sinistre que celui dont ils disposent dans l'environnement de production source. La liste suivante présente les différentes méthodes de synchronisation des autorisations entre plusieurs environnements :
Si vous utilisez l'environnement de production Google Cloud, la réplication des stratégies IAM dans l'environnement de reprise après sinistre est simple. Vous pouvez utiliser des outils IaC (Infrastructure as Code) tels que Terraform pour déployer vos stratégies IAM en production. Ces mêmes outils vous permettent ensuite de lier les stratégies aux ressources correspondantes de l'environnement de reprise après sinistre lorsque vous le mettez en place.
Si vous utilisez un environnement de production sur site, vous pouvez mapper les rôles fonctionnels (tels que les rôles d'administrateur réseau et d'auditeur) aux stratégies IAM qui disposent des rôles IAM appropriés. La documentation IAM contient des exemples de configuration de rôles fonctionnels. Vous pouvez par exemple la consulter pour découvrir comment créer des rôles fonctionnels associés à la mise en réseau et aux journaux d'audit.
Vous devez configurer les stratégies IAM de façon à accorder les autorisations appropriées aux produits. Par exemple, vous pouvez vouloir limiter l'accès à certains buckets Cloud Storage.
Si vous utilisez l'environnement de production d'un autre fournisseur cloud, mappez les autorisations des stratégies IAM de l'autre fournisseur aux stratégies IAM Google Cloud.
Vérifier la sécurité de l'environnement de reprise après sinistre
Une fois les autorisations de l'environnement de reprise après sinistre configurées, assurez-vous de toutes les tester. Créez un environnement de test. Utilisez les outils IaC tels que Terraform pour déployer vos stratégies Google Cloud dans l'environnement de test. Vérifiez que les autorisations que vous accordez aux utilisateurs correspondent à celles qu'ils reçoivent sur site.
S'assurer que les utilisateurs peuvent accéder à l'environnement de reprise après sinistre
N'attendez pas qu'une catastrophe se produise pour vérifier que vos utilisateurs peuvent accéder à l'environnement de reprise après sinistre. Assurez-vous que vous avez accordé les droits d'accès appropriés aux utilisateurs, aux développeurs, aux opérateurs, aux data scientists, aux administrateurs de sécurité, aux administrateurs réseau et à tout autre rôle de votre organisation. Si vous utilisez un autre système de gestion de l'authentification, vérifiez que les comptes ont bien été synchronisés avec votre compte Cloud Identity. Comme l'environnement de reprise après sinistre sera votre environnement de production pendant un certain temps, demandez aux utilisateurs devant y accéder de se connecter, puis résolvez les problèmes d'authentification. Tenez compte des utilisateurs qui se connectent à l'environnement de reprise après sinistre lors des tests de reprise réguliers que vous mettez en œuvre.
Pour gérer de manière centralisée les accès SSH aux machines virtuelles lancées, activez la fonctionnalité OS Login sur les projets Google Cloud qui constituent votre environnement de reprise après sinistre.
Former les utilisateurs
Les utilisateurs doivent pouvoir comprendre comment exécuter sur Google Cloud les actions qu'ils ont l'habitude d'effectuer dans l'environnement de production, telles que la connexion, l'accès aux VM, etc. À l'aide de l'environnement de test, expliquez-leur comment réaliser ces tâches d'une manière qui protège votre système.
S'assurer que l'environnement de reprise après sinistre répond aux exigences de conformité
Vérifiez que votre environnement de reprise après sinistre n'est accessible qu'aux utilisateurs autorisés. Assurez-vous également que les informations personnelles sont masquées et chiffrées. Si vous effectuez des tests d'intrusion réguliers dans votre environnement de production, il est conseillé d'inclure l'environnement de reprise après sinistre à ce champ d'application et de procéder à des tests fréquents en mettant en place un environnement de reprise après sinistre.
Lorsque l'environnement de reprise après sinistre est en service, assurez-vous que tous les journaux recueillis figurent dans l'archive de journaux de votre environnement de production. De même, assurez-vous que vous pouvez exporter les journaux d'audit collectés via Cloud Logging vers l'archive de votre récepteur de journaux principal dans le cadre de l'environnement de reprise après sinistre. Utilisez les fonctions du récepteur d'exportations. Pour les journaux d'applications, créez une réplique de votre environnement de journalisation et de surveillance sur site. Si vous utilisez l'environnement de production d'un autre fournisseur cloud, mappez la journalisation et la surveillance de ce fournisseur aux services Google Cloud équivalents. Créez un processus afin de mettre en forme les entrées dans votre environnement de production.
Utiliser Cloud Storage pour les opérations de sauvegarde quotidiennes
Stockez les sauvegardes dans Cloud Storage. Assurez-vous que les buckets contenant les sauvegardes disposent des autorisations appropriées.
Gérer les secrets de manière adaptée
Gérez les clés et les secrets au niveau de l'application en utilisant Google Cloud pour héberger le service de gestion des clés et des secrets (KMS, Key/secret management service). Vous pouvez utiliser Cloud KMS ou une solution tierce comme HashiCorp Vault avec un backend Google Cloud tel que Spanner ou Cloud Storage.
Traiter les données récupérées comme des données de production
Assurez-vous que les contrôles de sécurité relatifs à vos données de production s'appliquent également à vos données récupérées. Les mêmes exigences en matière d'autorisations, de chiffrement et d'audit doivent également s'appliquer.
Sachez où sont stockées vos sauvegardes et qui est autorisé à restaurer les données. Assurez-vous que votre processus de récupération est auditable. À la suite d'une reprise après sinistre, il doit être possible de vérifier qui a accédé aux données de sauvegarde et qui a effectué la récupération.
Vérifier le fonctionnement du plan de reprise après sinistre
Assurez-vous que votre plan de reprise après sinistre fonctionne comme prévu en cas de sinistre.
Disposer d'alternatives pour récupérer les données
En cas de sinistre, votre méthode de connexion à Google Cloud risque de ne plus être disponible. Mettez en œuvre un autre moyen d'accès à Google Cloud pour vous assurer de pouvoir y transférer des données. Vérifiez régulièrement que le chemin de sauvegarde est opérationnel.
Tester régulièrement le plan
Après avoir créé un plan de reprise après sinistre, testez-le régulièrement et notez les éventuels problèmes, puis ajustez le plan en conséquence. Google Cloud vous permet de tester des scénarios de reprise à moindre coût. Nous vous recommandons d'implémenter les éléments suivants afin de faciliter vos tests :
- Automatiser le provisionnement de l'infrastructure. Vous pouvez utiliser des outils IaC tels que Terraform pour automatiser le provisionnement des instances de VM et d'autres infrastructures Google Cloud. Si vous exécutez votre environnement de production sur site, assurez-vous de disposer d'un processus de surveillance capable de lancer le processus de reprise après sinistre lorsqu'il détecte une défaillance, puis de déclencher les actions de reprise appropriées.
- Surveillez et déboguez vos tests avec Cloud Logging et Cloud Monitoring. Google Cloud propose d'excellents outils de journalisation et de surveillance accessibles via des appels d'API. Ils vous permettent d'automatiser le déploiement de scénarios de reprise en réaction à des métriques. Lorsque vous créez des tests, assurez-vous de disposer d'une solution de surveillance et d'alertes adaptées pouvant déclencher les actions de reprise appropriées.
Effectuez les tests abordés précédemment :
- Vérifiez que les autorisations et les accès utilisateurs présentent le même comportement dans l'environnement de reprise après sinistre que dans l'environnement de production.
- Effectuez des tests d'intrusion dans votre environnement de reprise après sinistre.
- Effectuez un test dans lequel votre chemin d'accès habituel à Google Cloud ne fonctionne pas.
Étape suivante
- Apprenez-en plus sur les zones géographiques et régions Google Cloud.
- Consultez d'autres documents de cette série sur la reprise après sinistre :
- Structure de la reprise après sinistre
- Scénarios de reprise après sinistre pour les données
- Scénarios de reprise après sinistre pour les applications
- Concevoir une solution de reprise après sinistre pour des charges de travail limitées à la localité
- Cas d'utilisation de reprise après sinistre : applications d'analyse de données limitées à la localité
- Concevoir une solution de reprise après sinistre pour les pannes d'infrastructure cloud
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Centre d'architecture cloud.