本文是由 4 篇文章组成的系列文章中的第 2 篇。该系列文章讨论如何在 Google Cloud 上使用 AI Platform 来预测客户生命周期价值 (CLV)。
本系列文章包含以下内容:
- 第 1 篇:简介。 介绍了 CLV 以及用于预测 CLV 的两种建模方法。
- 第 2 篇:训练模型(本文)。介绍了如何准备数据和训练模型。
- 第 3 篇:部署到生产系统。介绍了如何将第 2 篇所述的模型部署到生产系统。
- 第 4 篇:使用 AutoML Tables。 介绍如何使用 AutoML Tables 构建和部署模型。
用于实现此系统的代码位于 GitHub 代码库中。 本系列文章讨论了此代码的用途和使用方法。
简介
本文紧接第 1 篇,在第 1 篇中,您已了解用于预测客户生命周期价值 (CLV) 的两种不同模型:
- 概率模型
- 深度神经网络 (DNN) 模型(一种机器学习模型)
如第 1 篇所述,本系列文章的目标之一是比较这些用于预测 CLV 的模型。本文介绍了如何准备数据并构建和训练两种模型来预测 CLV,还提供了一些比较信息。
安装代码
如要按本文所述的流程进行操作,您需要安装 GitHub 中的示例代码。
如果您已安装 gcloud CLI,请在计算机上打开一个终端窗口来运行这些命令。如果未安装 gcloud CLI,请打开 Cloud Shell 实例。
克隆示例代码库:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
按照 README 文件的安装部分中的安装说明来设置环境。
数据准备
本部分介绍了如何获取和清理数据。
获取和清理源数据集
在计算 CLV 之前,您必须确保源数据至少包含以下内容:
- 用于区分各个客户的客户 ID。
- 每位客户的购买金额,即客户在特定时间消费的金额。
- 每项购买交易的日期。
在本文中,我们将讨论如何使用 UCI 机器学习代码库中公开提供的在线零售数据集中的历史销售数据来训练模型。[1]
第一步是将数据集以 CSV 文件格式复制到 Cloud Storage。
然后,使用其中一种适用于 BigQuery 的加载工具来创建一个名为 data_source 的表格。(此名称可任意设置,但 GitHub 代码库中的代码使用的是这一名称。)数据集可在与本系列文章关联的公共存储分区中找到,并且已经转换为 CSV 格式。
- 在计算机上或 Cloud Shell 中,运行在 GitHub 代码库中 README 文件的“设置”部分中介绍的命令。
示例数据集包含下表中列出的字段。对于本文中介绍的方法,您只需使用“会用到”列设置为是的字段。某些字段不能直接使用,但是有助于新建字段,例如 UnitPrice 和 Quantity 可创建 order_value。
| 会用到 | 字段 | 类型 | 说明 |
|---|---|---|---|
| 否 | InvoiceNo |
STRING |
标称。唯一分配给每笔交易的 6 位整数。
如果此代码以字母 c 开头,则表示交易取消。 |
| 否 | StockCode |
STRING |
商品(内容)代码。标称,唯一分配给每项不同商品的 5 位整数。 |
| 否 | Description |
STRING |
商品名称。标称。 |
| 是 | Quantity |
INTEGER |
每笔交易的每项商品的数量。数值。 |
| 是 | InvoiceDate |
STRING |
采用 mm/dd/yy hh:mm 格式的帐单日期和时间。生成每笔交易的日期和时间。 |
| 是 | UnitPrice |
FLOAT |
单价。数值。以英镑表示的每单位商品价格。 |
| 是 | CustomerID |
STRING |
客户编号。标称。唯一分配给每位客户的 5 位整数。 |
| 否 | Country |
STRING |
国家/地区名称。标称。每位客户所在国家/地区的名称。 |
清理数据
无论您使用哪种模型,都必须执行一组所有模型都通用的准备和清理步骤。为了获取一组可用的字段和记录,您需要执行以下操作:
- 按日期而不是使用
InvoiceNo对订单进行分组,因为此解决方案中概率模型所用的最小时间单位是天。 - 仅保留对概率模型有用的字段。
- 仅保留订单数量和消费金额为正数的记录(例如购买交易)。
- 仅保留订单数量为负数的记录(例如退货)。
- 仅保留包含客户 ID 的记录。
- 仅保留在过去 90 天内购买了商品的客户。
- 仅保留在用于创建特征的时间段内至少购买了两次商品的客户。
您可以使用以下 BigQuery 查询来执行所有这些操作。(与先前的命令一样,请在克隆了 GitHub 代码库的环境中运行此代码。)由于数据较旧,因此本文将日期“2011 年 12 月 12 日”视作当前日期。
此查询会执行两项任务。首先,如果有效数据集较大,此查询会缩减此数据集。(此解决方案的有效数据集非常小,但是此查询可以在几秒钟内将超大的数据集缩小两个数量级。)
其次,此查询会创建一个要使用的基础数据集,如下所示:
customer_id
|
order_date
|
order_value
|
order_qty_articles
|
|---|---|---|---|
| 16915 | 2011-08-04 | 173.7 | 6 |
| 15349 | 2011-07-04 | 107.7 | 77 |
| 14794 | 2011-03-30 | -33.9 | -2 |
已清理的数据集还包含 order_qty_articles 字段。此字段仅供下一部分讲述的深度神经网络 (DNN) 使用。
定义训练期和目标期
您必须选择阈值日期,这是训练模型前的一项准备工作。该日期会将订单分成两个部分:
- 阈值日期之前的订单用于训练模型。
- 阈值日期之后的订单用于计算目标值。

Lifetimes 库包括数据预处理方法。但是,用于 CLV 的数据集可能非常庞大,因此在单个机器上执行数据预处理并不现实。在本文介绍的方法中,我们通过直接在 BigQuery 中执行查询来将订单分成两组。机器学习模型和概率模型应使用相同的查询,以确保两个模型对同样的数据进行操作。
机器学习模型和概率模型的最佳阈值日期可能并不相同。您可以直接在 SQL 语句中更新此日期值。请将最佳阈值日期视为一个超参数。 通过探索数据并运行一些测试训练,您可以找到最合适的值。
您可以在 SQL 查询的 WHERE 子句中使用阈值日期,以便从已清理的数据表中选择训练数据,如以下示例所示:
聚合数据
将数据按训练期和目标期进行拆分后,您可以聚合数据,以便为每个客户创建实际的特征和目标。对于概率模型,聚合操作仅限于最近一次消费、消费频率和消费金额(即 RFM)字段。DNN 模型同样使用 RFM 特征,但也可以使用其他特征来提高预测效果。
以下查询展示了如何同时为 DNN 模型和概率模型创建特征:
下表列出了该查询创建的特征。
| 特征名称 | 说明 | 概率 | DNN |
|---|---|---|---|
monetary_dnn
|
每个客户在特征期内的所有订单的总消费金额。 | x | |
monetary_btyd
|
每个客户在特征期内的所有订单的平均消费金额。概率模型假设第一个订单的值为 0。这是由查询强制执行的。 | x | |
recency
|
客户在特征期内所下的第一个订单与最后一个订单之间的时间。 | x | |
frequency_dnn
|
客户在特征期内所下的订单数量。 | x | |
frequency_btyd
|
客户在特征期内所下的订单数量减去第一个订单。 | x | |
T
|
从客户下第一个订单到特征期结束这段时间。 | x | x |
time_between
|
客户在特征期内所下订单的平均间隔时间。 | x | |
avg_basket_value
|
特征期内客户购物篮中的平均消费金额。 | x | |
avg_basket_size
|
特征期内客户购物篮中的平均商品数量。 | x | |
cnt_returns
|
特征期内发生客户退货的订单数量。 | x | |
has_returned
|
在特征期内是否至少有一个订单发生了客户退货。 | x | |
frequency_btyd_clipped
|
与 frequency_btyd 相同,但受上限异常值限制。 |
x | |
monetary_btyd_clipped
|
与 monetary_btyd 相同,但受上限异常值限制。 |
x | |
target_monetary_clipped
|
与 target_monetary 相同,但受上限异常值限制。 |
x | |
target_monetary
|
客户花费的总金额(包括训练期和目标期)。 | x |
您需要在代码中选择这些列。对于概率模型,可以使用 Pandas DataFrame 进行选择:
对于 DNN 模型,您可以在 context.py 文件中定义 TensorFlow 特征。这些模型将忽略以下特征:
customer_id。这是一个唯一的值,不能用作特征。target_monetary。这是模型必须预测的目标,因此不能用作输入。
为 DNN 创建训练集、评估集和测试集
本部分仅适用于 DNN 模型。要训练机器学习模型,您应该使用三个不重叠的数据集:
使用训练 (70–80%) 数据集了解权重,以降低损失函数的值。训练会持续进行,直到损失函数的值不再降低为止。
在训练阶段使用评估 (10–15%) 数据集,以防出现过拟合现象(即模型在使用训练数据时表现良好,但通用性不佳)。
在完成所有训练和评估后,应使用一次测试 (10–15%) 数据集,以最终衡量模型的性能。模型在训练过程中从未见过该数据集,因此该数据集能够从统计意义上有效地衡量模型的准确性。
以下查询会创建一个大约包含 70% 数据的训练集。该查询通过以下方法来隔离数据:
- 计算客户 ID 的哈希值,这会生成一个整数。
- 使用模运算来选择低于特定阈值的哈希值。
评估集和测试集使用相同的概念,其中高于阈值的数据将会被保留。
训练
您在上一部分已经看到,可以使用不同的模型来尝试预测 CLV。本文所使用的代码可让您决定使用哪个模型。您可以使用传递给以下训练 Shell 脚本的 model_type 参数来选择模型。其余的工作可以交给代码来完成。
训练的首要目标是使两个模型的性能能够高于原生基准,我们会在下面定义此基准。如果两种模型的性能都高于基准(应该高于基准),那么您可以比较这两种模型的性能。
对模型进行基准测试
在本系列文章中,我们使用以下参数定义了一项原生基准:
- 平均购物篮价值。此值是根据阈值日期之前所下的所有订单计算的。
- 订单数量。此值是针对训练时间间隔根据阈值日期之前所下的所有订单计算的。
- 数量系数。此值是根据阈值日期之前的天数与阈值日期到现在的日期之间的天数之比计算的。
基准简单假设客户在训练时间间隔内确定的购买率在目标时间间隔内保持不变。因此,如果客户在 40 天内购买了 6 次,则假设他们将在 60 天内购买 9 次 (60/40 * 6 = 9)。将每个客户的数量系数、订单数量和平均购物篮价值相乘,即可得出该客户的原生预测目标值。
基准误差是指均方根误差 (RMSE):平均每个客户的预测目标值与实际目标值之间的绝对差。可以在 BigQuery 中使用以下查询来计算 RMSE:
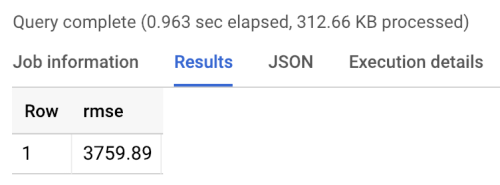
基准返回的 RMSE 等于 3760,如运行基准生成的以下结果所示。模型的值应该高于该值。
概率模型
如本系列文章的第 1 篇所述,本系列文章使用了名为 Lifetimes 的 Python 库,该库支持各种模型,包括帕累托/负二项分布 (NBD) 和贝塔-几何分布 (BG/NBD) 模型。以下示例代码展示了如何使用概率模型并借助 Lifetimes 库来预测生命周期价值。
要在本地环境中使用概率模型来生成 CLV 结果,您可以运行以下 mltrain.sh 脚本。您需要提供相关参数值来指定训练期的开始和结束日期以及预测期的结束日期。
./mltrain.sh local data --model_type paretonbd_model --threshold_date [YOUR_THRESHOLD_DATE] --predict_end [YOUR_END_DATE]
DNN 模型
示例代码涉及在 TensorFlow 中实现使用预制 Estimator DNNRegressor 类的 DNN 模型以及自定义 Estimator 模型。DNNRegressor 和自定义 Estimator 使用相同数量的层,并在每个层中使用相同数量的神经元。这些值是需要调节的超参数。在以下 task.py 文件中,您可以找到包含某些超参数的列表,这些超参数已设置为经测试可以产生良好结果的值。
如果您在使用 AI Platform,则可以利用超参数调节特征,对您在 yaml 文件中定义的一系列参数进行测试。AI Platform 会使用贝叶斯优化对超参数空间执行搜索。
模型比较结果
下表显示了根据示例数据集训练的各个模型的 RMSE 值。所有模型都是使用 RFM 数据训练的。由于系统会随机初始化参数,因此每次运行所生成的 RMSE 值会略有不同。DNN 模型使用了一些其他特征,例如平均购物篮价值和退货数量。
| 模型 | RMSE |
|---|---|
| DNN | 947.9 |
| BG/NBD | 1557 |
| 帕累托/NBD | 1558 |
结果表明,在该数据集中,DNN 模型在预测消费金额时的性能优于概率模型。但是,相对较小的 UCI 数据集限制了这些结果的统计有效性。您应该尝试针对您的数据集使用每种方法,以了解哪种方法可以提供最佳结果。所有模型都是根据从该数据提取的 RFM 值使用相同的原始数据(包括客户 ID、订单日期及订单价值)训练得出的。DNN 训练数据包含了一些其他特征,例如平均购物篮大小及退货数量。
DNN 模型仅输出客户的总消费金额。如果您想预测客户消费频率或客户流失情况,则必须执行一些额外的任务:
- 以不同的方式准备数据,以更改目标,还可能需要更改阈值日期。
- 重新训练回归器模型,以预测您感兴趣的目标。
- 调节超参数。
这样做的目的是对两种模型的相同输入特征进行比较。使用 DNN 的一项好处是,您可以在本示例中所使用特征的基础上添加更多特征,以改善结果。通过 DNN,您可以利用来自点击流事件、用户个人资料或商品特征等来源的数据。
致谢
Dua, D. and Karra Taniskidou, E. (2017). UCI Machine Learning Repository http://archive.ics.uci.edu/ml. 加利福尼亚州欧文市:加州大学信息与计算机科学学院。
后续步骤
- 阅读本系列文章的第 3 篇:部署到生产环境,以了解如何部署这些模型。
- 了解其他预测解决方案。
- 探索有关 Google Cloud 的参考架构、图表、教程和最佳做法。查看我们的 Cloud Architecture Center。