本文是由 4 篇文章组成的系列文章中的第 3 篇。该系列文章讨论如何在 Google Cloud 上使用 AI Platform 来预测客户生命周期价值 (CLV)。
本系列文章包含以下内容:
- 第 1 篇:简介。 介绍了 CLV 以及用于预测 CLV 的两种建模方法。
- 第 2 篇:训练模型。 介绍了如何准备数据和训练模型。
- 第 3 篇:部署到生产系统(本文)。介绍了如何将第 2 篇所述的模型部署到生产系统。
- 第 4 篇:使用 AutoML Tables。 介绍了如何使用 AutoML Tables 构建和部署模型。
安装代码
如要按本文所述的流程进行操作,您需要安装 GitHub 中的示例代码。
如果您已安装 gcloud CLI,请在计算机上打开一个终端窗口来运行这些命令。如果未安装 gcloud CLI,请打开 Cloud Shell 实例。
克隆示例代码库:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
按照 README 文件中的安装和自动化部分的安装说明,设置环境并部署解决方案组件,包括示例数据集和 Cloud Composer 环境。
以下部分中的命令示例假定您已完成上述两个步骤。
根据安装说明,您可以按照 README 文件的设置部分所述为您的环境设置变量。
更改 REGION 变量,使其与距离您的地理位置最近的 Google Cloud 区域相对应。如需查看区域列表,请参阅区域和地区。
架构和实现
下图显示了本文所讨论的架构。

该架构包括以下功能:
- 数据提取:将数据导入 BigQuery。
- 数据准备:将原始数据转换为可供模型使用的数据。
- 模型训练:构建、训练和调节模型,使其能够执行预测。
- 提供预测:存储离线预测并提供预测结果,并且延迟低。
- 自动化:通过 Cloud Composer 执行和管理所有这些任务。
提取数据
本系列文章并未讨论某种具体的数据提取方式。BigQuery 支持多种数据提取方式,包括从 Pub/Sub、Cloud Storage 和 BigQuery Data Transfer Service 提取数据。如需了解详情,请参阅面向数据仓库专业人员的 BigQuery 介绍。在本系列文章所介绍的方法中,我们使用的是公共数据集。请按照 README 文件中的示例代码所述,将此数据集导入 BigQuery。
准备数据
要准备数据,请按照本系列文章第 2 篇中的说明,在 BigQuery 上执行查询。在生产架构中,您需要执行相关查询,并将其作为 Apache Airflow 有向无环图 (DAG) 的一部分。下文中的自动化部分详细介绍了如何执行查询来进行数据准备。
在 AI Platform 上训练模型
本部分内容概述了架构的训练部分。
无论您选择何种类型的模型,此解决方案中显示的代码都已经过打包以便在 AI Platform 上运行,用于培训和预测。AI Platform 提供以下优势:
- 您可以在本地或者在云端分布式环境下运行 Cloud ML Engine。
- AI Platform 内置了与其他 Google 产品(例如 Cloud Storage)的连接。
- 您只需使用少数几个命令即可运行 AI Platform。
- AI Platform 可帮助进行超参数调节。
- AI Platform 可随着基础架构的细微变化(如果有)而进行扩缩。
为了使 AI Platform 能够训练和评估模型,您需要提供训练、评估和测试数据集。您可以按照本系列文章第 2 篇中的说明,通过运行 SQL 查询来创建数据集。然后,您可以将这些数据集从 BigQuery 表格导出至 Cloud Storage。在本文所述的生产架构中,查询由 Airflow DAG 来执行,下文“自动化”部分对此进行了详细说明。您可以按照 README 文件的“Run DAGs”(运行 DAG)部分中的说明手动执行 DAG。
进行预测
您可以在线创建预测,也可以离线创建预测。但创建预测与传送预测不同。在此 CLV 环境中,有些事件(例如,客户登录网站或访问零售店)不会显著影响客户的生命周期价值。因此,即使可能必须实时呈现预测结果,也仍然可以离线执行预测。离线预测具有以下操作特点:
- 您可以为训练任务和预测任务执行相同的预处理步骤。如果针对训练和预测执行不同的预处理,可能会降低预测结果的准确性。这种现象称为“训练-应用偏差”。
- 您可以使用相同的工具为训练和预测准备数据。在本系列文章所讨论的方法中,主要采用 BigQuery 来准备数据。
您可以使用 AI Platform 部署模型并使用批处理作业进行离线预测。对于预测,AI Platform 可协助进行如下任务:
- 管理版本。
- 随着基础架构的细微变化而进行扩缩。
- 大规模部署。
- 与其他 Google Cloud 产品进行交互。
- 提供服务等级协议 (SLA)。
批量预测任务会使用 Cloud Storage 上存储的文件进行输入和输出。对于 DNN 模型,task.py 中定义的以下传送函数定义了输入格式:
此代码中的 Estimator 模型函数(位于 model.py 中)所返回的 EstimatorSpec 中定义了预测输出格式:
进行预测
在创建并部署模型后,您可以使用模型来执行 CLV 预测。下面是常见的 CLV 使用场景:
- 数据专家可以在构建用户细分群组时利用离线预测。
- 当客户在线或在商店中与您的品牌互动时,您的组织可以实时提供具体服务。
使用 BigQuery 进行分析
了解 CLV 是启动预测任务的关键。本文主要侧重于根据以前的销售数据计算生命周期价值。销售数据通常来自客户关系管理 (CRM) 工具,但关于用户行为的信息也可能有其他来源(例如 Google Analytics 360)。
如果您想执行以下任何任务,请使用 BigQuery:
- 存储来自众多来源的结构化数据。
- 从常用的 SaaS 工具(例如 Google Analytics 360、YouTube 或 Google Ads)中自动传输数据。
- 运行临时查询,包括联接 TB 级的客户数据。
- 使用领先的商业智能工具直观地呈现您的数据。
除了用作托管式存储空间和查询引擎外,BigQuery 还可以通过 BigQuery ML 直接运行机器学习算法。通过将每位客户的 CLV 值加载到 BigQuery,数据分析师、科学家和工程师在执行任务时可利用更多的指标。下一部分中讨论的 Airflow DAG 包括一项任务,即将 CLV 预测加载到 BigQuery。
使用 Datastore 提供低延迟的服务
通常可以重复使用离线预测来实时提供预测。对于这种情况,预测新鲜度不是非常重要,重要的是可以在适当的时间方便地访问数据。
存储离线预测并实时传送预测意味着,客户的行为不会立即改变其 CLV。但重要的是,您能够快速访问 CLV。例如,在客户使用网站、向帮助台咨询问题或通过销售终端结帐时,您的公司可能希望能够快速做出反应。在这类情况下,快速响应有助于改善客户关系。因此,可以将预测输出存储在敏捷的数据库中,并为前端提供安全的查询功能,这是成功的关键。
假设您拥有数十万唯一身份客户。那么,Datastore 不失为明智之选,原因如下:
- Cloud Datastore 支持 NoSQL 文档数据库。
- Cloud Datastore 允许使用键(客户 ID)快速访问数据,另外还支持 SQL 查询。
- 用户可以通过 REST API 访问 Cloud Datastore。
- Cloud Datastore 是一种即用型服务,也就是说,它不存在设置方面的开销。
- Cloud Datastore 会自动扩缩。
由于无法直接将 CSV 数据集加载到 Datastore,因此在该解决方案中,我们会使用 Dialogflow 的 Apache Beam(带有一个 JavaScript 模板)将 CLV 预测结果加载到 Datastore 中。该 JavaScript 模板中的以下代码段展示了如何进行加载:
如果您的数据位于 Datastore 中,那么您可以选择与数据进行交互的方式,其中包括:
- 从应用中使用 Datastore 客户端库。
- 使用 Cloud Endpoints 或 Apigee API Platform 构建一个 API 端点。
- 将 Cloud Functions 用于无服务器任务。
解决方案自动化
如果您要开始使用数据,以便执行初步的预处理、训练和预测步骤,则可以参考本文到目前为止所介绍的步骤。但是,您的平台还没有为生产环境做好准备,因为您还需要自动化和故障管理功能。
某些脚本可以帮助将这些步骤粘合在一起。但最佳做法是,通过工作流管理工具自动执行这些步骤。Apache Airflow 是一种常用的工作流管理工具。您可以使用 Cloud Composer 在 Google Cloud 上运行托管式 Airflow 流水线。
您可以利用 Airflow 配合有向无环图 (DAG),指定各项任务以及该任务与其他任务的关系。根据本系列文章所介绍的方法,您需要执行以下步骤:
- 创建 BigQuery 数据集。
- 将公共数据集从 Cloud Storage 加载到 BigQuery。
- 清理 BigQuery 表中的数据,并将其写入新的 BigQuery 表。
- 根据一个 BigQuery 表中的数据创建特征,并将其写入另一个 BigQuery 表。
- 如果是深度神经网络 (DNN) 模型,请在 BigQuery 中将数据拆分为训练集和评估集。
- 将数据集导出至 Cloud Storage,并将其提供给 AI Platform。
- 让 AI Platform 定期训练模型。
- 将更新后的模型部署到 AI Platform。
- 定期对新数据执行批量预测。
- 将已保存在 Cloud Storage 中的预测保存到 Datastore 和 BigQuery。
设置 Cloud Composer
如需了解如何设置 Cloud Composer,请参阅 GitHub 代码库 README 文件中的说明。
适用于该解决方案的有向无环图
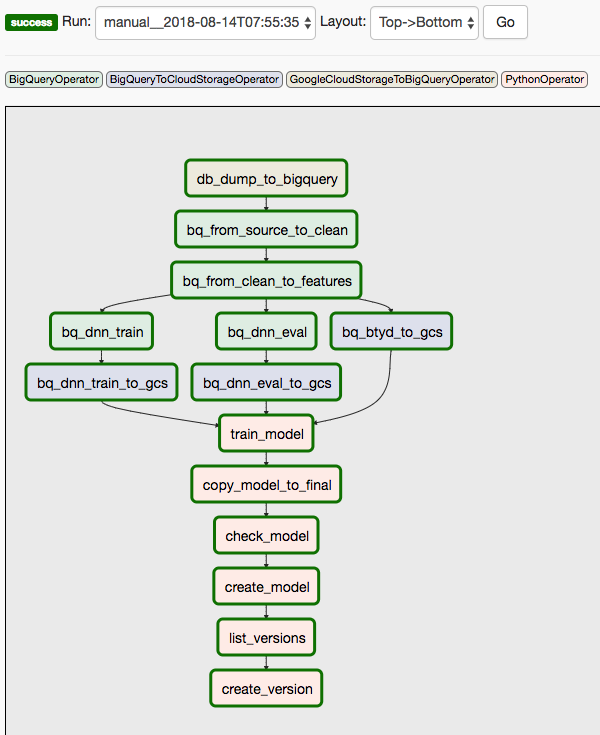
该解决方案使用了两个 DAG。第一个 DAG 涵盖前面列出的第 1 步到第 8 步:
下图显示的是 Cloud Composer/Airflow 界面,该界面对 Airflow DAG 步骤的第 1 步到第 8 步进行了总结。
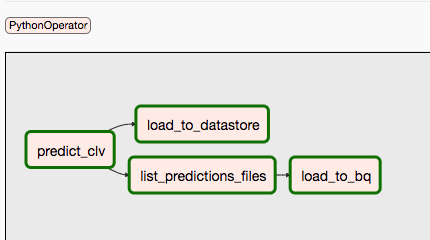
第二个 DAG 涵盖第 9 步和第 10 步。
下图对 Airflow DAG 流程的第 9 步和第 10 步进行了总结。
由于预测任务和训练任务可能会按不同的时间表单独执行,因此两个 DAG 是相互分开的。例如,您可能会执行以下操作:
- 每天针对新客户或现有客户预测数据。
- 每周重新训练一次模型,以整合新数据;或者在收到特定数量的新交易后触发重新训练。
如需手动触发第一个 DAG,您可以在 Cloud Shell 中或使用 gcloud CLI 运行自述文件的 Run Dags(运行 DAG)部分中的命令。
conf 参数会将变量传递给自动化流程各个不同的部分。例如,在以下 SQL 查询(用于从已清理的数据中提取功能)中,变量用来对 FROM 子句进行参数化:
您可以使用类似的命令触发第二个 DAG。如需了解详情,请参阅 GitHub 代码库中的 README 文件。
后续步骤
- 运行 GitHub 代码库中的完整示例。
- 利用以下某些数据,将新功能整合到 CLV 模型中:
- 点击流数据(这些数据可帮助您预测尚无历史数据的客户的 CLV)。
- 产品部门和类别,可以增加额外的上下文信息,并且可能对神经网络有所帮助。
- 通过使用该解决方案所用的输入创建的新特征,例如阈值日期之前最后几周或几个月的销售趋势。
- 阅读第 4 篇:为模型使用 AutoML Tables。
- 了解其他预测解决方案。
- 探索有关 Google Cloud 的参考架构、图表、教程和最佳做法。查看我们的 Cloud Architecture Center。