I cluster Anthos su VMware (GKE on-prem) possono essere eseguiti in una delle tre modalità di bilanciamento del carico: integrata, manuale o in bundle. Questo argomento mostra come configurare i cluster Anthos su VMware in modo che vengano eseguiti in modalità di bilanciamento del carico.
Le istruzioni riportate qui sono complete. Per un'introduzione più breve all'utilizzo del bilanciatore del carico di Seesaw, consulta l'articolo sulla guida rapida del bilanciatore del carico di Seesaw.
In modalità di bilanciamento del carico in bundle, i cluster Anthos su VMware forniscono e gestiscono il bilanciatore del carico. Non è necessario ottenere una licenza per un bilanciatore del carico e la quantità di configurazione che devi fare è minima.
Il bilanciatore del carico in bundle fornito da Cluster Anthos su VMware è il bilanciatore del carico di Seesaw.
Vantaggi della modalità di bilanciamento del carico
La modalità di bilanciamento del carico in bundle offre questi vantaggi rispetto alla modalità di bilanciamento del carico manuale:
Un singolo team può essere responsabile sia della creazione del cluster che della configurazione del bilanciatore del carico. Ad esempio, un team di amministrazione del cluster non dovrebbe fare affidamento su un team di networking separato per acquisire, eseguire e configurare il bilanciatore del carico in anticipo.
I cluster Anthos su VMware configurano automaticamente gli indirizzi IP virtuali (VIP) sul bilanciatore del carico. Al momento della creazione del cluster, Cluster Anthos su VMware configura il bilanciatore del carico con VIP per il server API di Kubernetes, il servizio in entrata e i componenti aggiuntivi del cluster. Quando i clienti creano servizi di tipo LoadBalancer, i cluster Anthos su VMware configurano automaticamente i VIP di servizio sul bilanciatore del carico.
Le dipendenze tra organizzazioni, gruppi e amministratori sono ridotte. In particolare, il gruppo che gestisce un cluster dipende meno da quello che gestisce la rete,
Versioni consigliate
Ti consigliamo vivamente di utilizzare vSphere 6.7 o versioni successive e lo Virtual Distributed Switch (VDS) 6.6 o versioni successive per la modalità di bilanciamento del carico in bundle.
Se preferisci, puoi utilizzare le versioni precedenti, ma l'installazione sarà meno sicura. Le sezioni rimanenti di questo argomento forniscono ulteriori dettagli sui vantaggi in termini di sicurezza dell'utilizzo di vSphere 6.7 e VDS 6.6 e versioni successive.
Pianificazione delle VLAN
Un'installazione di cluster Anthos su VMware ha un cluster di amministrazione e uno o più cluster utente. Con la modalità di bilanciamento del carico in bundle, consigliamo vivamente di configurare i cluster su VLAN separate, in particolare perché il cluster di amministrazione è su una propria VLAN.
Se il cluster di amministrazione utilizza la propria VLAN, il traffico del piano di controllo è separato da quello del piano dati. Questa separazione protegge il cluster di amministrazione e i piani di controllo del cluster utente da errori di configurazione involontaria. Tali errori possono, ad esempio, generare problemi come una tempesta di trasmissione dovuta al loop di 2 livelli nella stessa VLAN o un indirizzo IP in conflitto che elimina la separazione desiderata tra il piano dati e il piano di controllo.
Provisioning delle risorse VM per il bilanciamento del carico in bundle (Seesaw)
Con il bilanciamento del carico in bundle, esegui il provisioning di CPU e memoria VM, in base al traffico di rete che prevedi di riscontrare.
Il bilanciatore del carico in bundle non richiede un utilizzo intensivo della memoria e può essere eseguito in VM con 1 GB di memoria. Tuttavia, l'aumento della percentuale di pacchetti di rete richiede più CPU.
La tabella seguente mostra le linee guida su archiviazione, CPU e memoria per il provisioning delle VM. Poiché la frequenza dei pacchetti non è una misurazione tipica delle prestazioni di rete, la tabella mostra anche le linee guida per il numero massimo di connessioni di rete attive. Le linee guida presuppongono inoltre un ambiente in cui le VM abbiano un link da 10 Gbps e le CPU vengano eseguite con una capacità inferiore al 70%.
Quando il bilanciatore del carico in bundle viene eseguito in modalità ad alta disponibilità, esegue una coppia attiva e di backup, quindi tutto il traffico passa attraverso una singola VM.
Poiché i casi d'uso effettivi variano, queste linee guida devono essere modificate in base al traffico effettivo. Monitora le metriche della CPU e della frequenza di pacchetto per apportare le modifiche necessarie.
Se devi modificare CPU e memoria per le VM di Seesaw, devi seguire le istruzioni per eseguire l'upgrade dei bilanciatori del carico. Tieni presente che puoi mantenere la stessa versione del bilanciatore del carico in bundle e modificare solo il numero di CPU e l'allocazione della memoria.
Per i cluster di amministrazione di piccole dimensioni, consigliamo 2 CPU e per i cluster di amministrazione di grandi dimensioni.
| Archiviazione | CPU | Memoria | Velocità pacchetti (pps) | Numero massimo di connessioni attive |
|---|---|---|---|---|
| 20 GB | 1 (non di produzione) | 1 GB | 250.000 | 100 |
| 20 GB | 2 | 3 GB | 450.000 | 300 |
| 20 GB | 4 | 3 GB | 850.000 | 6000 |
| 20 GB | 6 | 3 GB | 1000.000 | 10.000 |
Tieni presente che devi eseguire il provisioning di una singola CPU in un ambiente non di produzione.
Mettere da parte gli indirizzi IP virtuali
Indipendentemente dalla scelta della modalità di bilanciamento del carico, devi mettere da parte diversi indirizzi IP virtuali (VIP) che intendi utilizzare per il bilanciamento del carico. Questi VIP consentono ai client esterni di raggiungere i server API, i servizi in entrata e i servizi aggiuntivi di Kubernetes.
Devi mettere da parte un insieme di VIP per il cluster di amministrazione e un insieme di VIP per ogni cluster utente che intendi creare. Per un determinato cluster, questi VIP devono trovarsi sulla stessa VLAN dei nodi del cluster e delle VM di Seesaw per quel cluster.
Per istruzioni su come mettere da parte i VIP, vedi Creazione di un cluster di amministrazione.
Mettere da parte gli indirizzi IP dei nodi
Con la modalità di bilanciamento del carico in bundle, puoi specificare indirizzi IP statici per i nodi del cluster, oppure i nodi del cluster possono recuperare i propri indirizzi IP da un server DHCP.
Se vuoi che i nodi del tuo cluster abbiano indirizzi IP statici, metti da parte gli indirizzi sufficienti per i nodi nel cluster di amministrazione e i nodi in tutti i cluster utente che intendi creare. Per maggiori dettagli sul numero di indirizzi IP dei nodi da descrivere, consulta la sezione Creazione di un cluster di amministrazione.
Mettere da parte gli indirizzi IP per le VM di Seesaw
Quindi, metti da parte gli indirizzi IP per le VM che eseguiranno i bilanciatori del carico di Seesaw.
Il numero di indirizzi messi da parte varia a seconda che tu voglia creare bilanciatori del carico Seesaw ad alta disponibilità o bilanciatori del carico Seesaw ad alta disponibilità.
Caso 1: bilanciatori del carico ad alta disponibilità
Per il tuo cluster di amministrazione, metti da parte due indirizzi IP per una coppia di VM di Seesaw. Anche per il cluster di amministrazione, riserva un singolo indirizzo IP master per la coppia di VM di Seesaw. Tutti e tre questi indirizzi devono trovarsi sulla stessa VLAN dei tuoi nodi del cluster di amministrazione.
Per ogni cluster utente che intendi creare, metti a disposizione due indirizzi IP per una coppia di VM di Seesaw. Inoltre, per ogni cluster utente, metti da parte un singolo indirizzo IP master per la coppia di VM di Seesaw. Per un determinato cluster utente, tutti e tre questi indirizzi devono trovarsi sulla stessa VLAN dei nodi del cluster utente.
Caso 2: bilanciatori del carico Seesaw non ad alta disponibilità
Per il tuo cluster di amministrazione, riserva un indirizzo IP per una VM di Seesaw. Anche per il cluster di amministrazione, metti da parte un indirizzo IP master per il bilanciatore del carico di Seesaw. Entrambi gli indirizzi devono trovarsi sulla stessa VLAN dei tuoi nodi cluster di amministrazione.
Per ogni cluster utente che intendi creare, metti da parte un solo indirizzo IP per una VM di Seesaw. Inoltre, per ogni cluster utente, metti da parte un indirizzo IP master per il bilanciatore del carico di Seesaw. Entrambi gli indirizzi devono trovarsi sulla stessa VLAN dei nodi del cluster utente.
Pianificare i gruppi di porte
Ogni tua VM di Seesaw ha due interfacce di rete. Una di queste interfacce di rete è configurata con i VIP. L'altra interfaccia di rete è configurata con un indirizzo IP derivato da un file IP che devi fornire.
Per una singola VM di Seesaw, le due interfacce di rete possono essere collegate allo stesso gruppo di porte vSphere oppure possono essere collegate a gruppi di porte separati. Se i gruppi di porte sono separati, devono trovarsi sulla stessa VLAN.
Questo argomento si riferisce a due gruppi di porte:
gruppo di porte con bilanciamento del carico: per una VM di Seesaw, l'interfaccia di rete configurata con i VIP è connessa al gruppo di porte.
Gruppo di porte nodo di cluster: per una VM di Seesaw, l'interfaccia di rete configurata con un indirizzo IP ricavato dal file del blocco IP è collegata a questo gruppo di porte. Anche i nodi del cluster sono connessi a questo gruppo di porte.
Il gruppo di porte del bilanciatore del carico e quello dei nodi del cluster possono essere uguali. Tuttavia, consigliamo vivamente di separarle.
Il seguente diagramma illustra la configurazione di rete consigliata per il bilanciamento del carico di Seesaw:
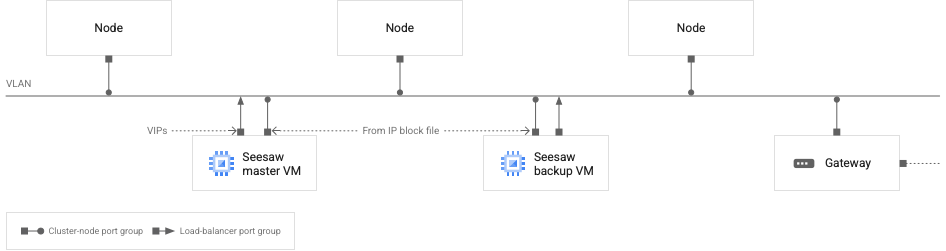 Vedi le VM e i nodi del cluster su una VLAN
Vedi le VM e i nodi del cluster su una VLAN
Il diagramma precedente rappresenta un singolo cluster, ovvero un cluster di amministrazione o un cluster utente. Ti ricordiamo che consigliamo di fare in modo che ogni cluster sia collegato alla propria VLAN.
Nel diagramma, puoi vedere le seguenti caratteristiche della rete:
Sono inoltre presenti due VM di Seesaw, una principale e una di backup.
Le VM di Seesaw si trovano sulla stessa VLAN dei nodi del cluster.
La VM di backup di Seesaw ha due interfacce di rete. Un'interfaccia è configurata con un indirizzo IP recuperato dal file di blocco IP di Seesaw. L'altra interfaccia non è configurata con alcun indirizzo IP.
La VM master di Seesaw ha due interfacce di rete. Un'interfaccia è configurata con un indirizzo IP recuperato dal file di blocco IP di Seesaw. L'altra interfaccia è configurata con i VIP.
Ogni VM di Seesaw ha un'interfaccia di rete connessa al gruppo di porte del bilanciatore del carico. Tutte le altre interfacce di rete nel diagramma sono collegate al gruppo di porte del nodo del cluster.
Tutti gli indirizzi IP, inclusi i VIP, configurati sulle interfacce di rete mostrati nel diagramma devono essere instradabili alla VLAN.
Per un cluster di amministrazione, l'interfaccia VIP sulla VM master di Seesaw è configurata con i seguenti indirizzi IP:
- Il VIP per la VM Seesaw master del cluster di amministrazione
- Il componente aggiuntivo del cluster di amministrazione VIP
- Il VIP del piano di controllo per il cluster di amministrazione
- I VIP del piano di controllo per tutti i cluster utente associati
- VIP per i servizi di tipo LoadBalancer in esecuzione nel cluster di amministrazione
Per un cluster utente, l'interfaccia VIP nella VM master di Seesaw è configurata con i seguenti indirizzi IP:
- Il VIP per la VM Seesaw master del cluster utente
- Il VIP Ingress in cluster utente
- VIP per i servizi di tipo LoadBalancer in esecuzione nel cluster utente
Creazione di file di blocco IP
Per ogni cluster che intendi creare, specifica gli indirizzi che hai scelto per le VM di Seesaw in un file di blocco IP. Questo file di blocco IP è destinato alle VM del bilanciatore del carico, non ai nodi del cluster. Se intendi utilizzare indirizzi IP statici per i nodi del cluster, devi creare un file di blocco IP separato per tali indirizzi. Di seguito è riportato un esempio di file di blocco IP che specifica due indirizzi IP per le VM di Seesaw:
blocks:
- netmask: "255.255.255.0"
gateway: "172.16.20.1"
ips:
- ip: "172.16.20.18"
hostname: "seesaw-vm-1"
- ip: "172.16.20.19"
hostname: "seesaw-vm-2"
Compilazione dei file di configurazione
Prepara un file di configurazione per ciascuno dei tuoi cluster: un cluster amministratore e uno o più cluster utente.
Nel file di configurazione di un determinato cluster, imposta loadBalancer.kind su
"Seesaw".
In loadBalancer, compila la sezione seesaw:
loadBalancer:
kind: Seesaw
seesaw:
ipBlockFilePath::
vrid:
masterIP:
cpus:
memoryMB:
vCenter:
networkName:
enableha:
antiAffinityGroups:
enabled:
seesaw.ipBlockFilePath
Stringa. Imposta questo percorso sul file del blocco IP per le VM di Seesaw. Ad esempio:
loadBalancer:
seesaw:
ipBlockFilePath: "admin-seesaw-ipblock.yaml"
seesaw.vrid
Numero intero. L'identificatore del router virtuale della tua VM Seesaw. Questo identificatore deve essere univoco in una VLAN. L'intervallo valido è 1-255. Ad esempio:
loadBalancer:
seesaw:
vrid: 125
seesaw.masterIP
Stringa. L'indirizzo IP master del bilanciatore del carico di Seesaw. Ad esempio:
loadBalancer:
seesaw:
masterIP: 172.16.20.21
seesaw.cpus
Numero intero. Il numero di CPU per ogni VM Seesaw. Ad esempio:
loadBalancer:
seesaw:
cpus: 4
seesaw.memoryMB
Numero intero. Il numero di megabyte di memoria per ogni VM di Seesaw. Ad esempio:
loadBalancer:
seesaw:
memoryMB: 3072
seesaw.vCenter.networkName
Stringa. Il nome della rete che contiene le VM di Seesaw. Se non impostato, utilizza la stessa rete del cluster. Ad esempio:
loadBalancer:
seesaw:
vCenter:
networkName: "my-seesaw-network"
seesaw.enableHA
Valore booleano. Se vuoi creare un bilanciatore del carico Seesaw ad alta disponibilità, impostalo su true. Altrimenti, imposta questa opzione su false. Ad esempio:
loadBalancer:
seesaw:
enableHA: true
Se imposti enableha su true, devi attivare il MAC Learning.
seesaw.antiAffinityGroups.enabled
Se vuoi applicare una regola di anti-affinità
alle tue VM di Seesaw, imposta il valore di
seesaw.antiAffinityGroups.enabled su true. In caso contrario, imposta il valore
su false. Il valore predefinito è true. Il valore consigliato è
true, in modo che le VM di Seesaw vengano posizionate su host fisici diversi ogni volta che è
possibile. Ad esempio:
loadBalancer:
seesaw
antiAffinityGroups:
enabled: true
Abilitazione dell'apprendimento MAC o della modalità promiscua (solo HA)
Se stai configurando un bilanciatore del carico di Seesaw non ad alta disponibilità, puoi saltare questa sezione.
Se hai impostato loadBalancer.seesaw.disableVRRPMAC su true, non è richiesta la configurazione del machine learning, anche se la rete deve supportare il failover IP tramite l'ARP Gratuitous.
Vedi File di configurazione del cluster utente.
Se configuri un bilanciatore del carico di Seesaw ad alta disponibilità e hai impostato loadBalancer.seesaw.disableVRRPMAC su false, devi abilitare una combinazione di apprendimento MAC, trasmissioni contraffatte e modalità profonda per il gruppo di porte del bilanciatore del carico.
Il modo in cui attivi queste funzionalità varia in base al tipo di sensore che possiedi:
| Tipo di switch | Attivazione delle funzionalità in corso... | Impatto sulla sicurezza |
|---|---|---|
| vSphere 7.0 VDS |
Per vSphere 7.0 con alta disponibilità, devi impostare loadBalancer.seesaw.disableVRRPMAC su true. Il machine learning non è supportato.
|
|
| vSphere 6.7 con VDS 6.6 |
Abilita l'apprendimento MAC e le trasmissioni contraffatte per il bilanciatore del carico eseguendo questo comando: |
Minima. Se il gruppo di porte del bilanciatore del carico è collegato solo alle VM di Seesaw, puoi limitare l'apprendimento MAC alle VM di Seesaw attendibili. |
vSphere 6.5 o vSphere 6.7 con una versione di VDS precedente a 6.6 |
Abilita la modalità promiscua e le trasmissioni contraffatte per il tuo gruppo di porte del bilanciatore del carico. Utilizza l'interfaccia utente vSphere nella pagina del gruppo di porte nella scheda Networking: Edit Settings -> Security. | Tutte le VM sul gruppo di porte del bilanciatore del carico sono in modalità promiscua. Quindi qualsiasi VM sul tuo gruppo di porte del bilanciatore del carico può visualizzare tutto il traffico. Se il gruppo di porte del bilanciatore del carico è collegato solo alle VM di Seesaw, solo quelle possono visualizzare tutto il traffico. |
| Interruttore logico NSX-T | Attiva l'apprendimento MAC sul sensore logico. | vSphere non supporta la creazione di due sensori logici nello stesso dominio di livello 2. Pertanto, le VM di Seesaw e i nodi del cluster devono essere sullo stesso switch logico. Ciò significa che il machine learning è abilitato per tutti i nodi del cluster. Un utente malintenzionato potrebbe ottenere uno spoofing MAC eseguendo pod con privilegi nel cluster. |
| Switch standard vSphere | Abilita la modalità promiscua e le trasmissioni contraffatte per il tuo gruppo di porte del bilanciatore del carico. Utilizza l'interfaccia utente vSphere su ogni host ESXI: Configure -> Virtual switch -> Standard Switch -> Edit Settings on the port group -> Security. | Tutte le VM sul gruppo di porte del bilanciatore del carico sono in modalità promiscua. Quindi qualsiasi VM sul tuo gruppo di porte del bilanciatore del carico può visualizzare tutto il traffico. Se il gruppo di porte del bilanciatore del carico è collegato solo alle VM di Seesaw, solo quelle possono visualizzare tutto il traffico. |
Esecuzione di un controllo preliminare sul file di configurazione
Dopo aver creato i file dei blocchi IP e il file di configurazione del cluster di amministrazione, esegui un controllo preliminare sul tuo file di configurazione:
gkectl check-config --config [ADMIN_CONFIG_FILE]
dove [ADMIN_CONFIG_FILE] è il percorso del file di configurazione del cluster di amministrazione.
Per il file di configurazione del cluster utente, devi includere il file kubeconfig del cluster amministratore nel comando:
gkectl --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] check-config --config [USER_CONFIG_FILE]
dove [ADMIN_CLUSTER_KUBECONFIG] è il percorso del file kubeconfig del cluster di amministrazione.
Se il controllo preliminare non riesce, apporta modifiche al file di configurazione del cluster e ai file dei blocchi IP in base alle esigenze. Quindi esegui di nuovo il controllo preliminare.
Caricamento delle immagini del sistema operativo in corso...
Esegui questo comando per caricare le immagini del sistema operativo nel tuo ambiente vSphere:
gkectl prepare --config [ADMIN_CONFIG_FILE]
dove [ADMIN_CONFIG_FILE] è il percorso del file di configurazione del cluster di amministrazione.
Creazione di un cluster di amministrazione che utilizza la modalità di bilanciamento del carico in bundle
Crea e configura le VM per il bilanciatore del carico del cluster di amministrazione:
gkectl create loadbalancer --config [CONFIG_FILE]
dove [CONFIG_FILE] è il percorso del file di configurazione del cluster di amministrazione.
Crea il cluster di amministrazione:
gkectl create admin --config [CONFIG_FILE]
dove [CONFIG_FILE] è il percorso del file di configurazione del cluster di amministrazione.
Creazione di un cluster utente che utilizza la modalità bilanciamento del carico in bundle
Crea e configura le VM per il bilanciatore del carico del cluster utente:
gkectl --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] create loadbalancer --config [CONFIG_FILE]
Crea il cluster utente:
gkectl --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] create cluster --config [CONFIG_FILE]
dove [ADMIN_CLUSTER_KUBECONFIG] è il percorso del file kubeconfig per il cluster di amministrazione e [CONFIG_FILE] è il percorso del file della configurazione del cluster utente
Test delle prestazioni e del carico
La velocità effettiva di download della tua applicazione scala in modo lineare con il numero di backend. Questo perché i backend inviano risposte direttamente ai client, bypassando il bilanciatore del carico, tramite il ritorno diretto del server.
La velocità effettiva di caricamento dell'applicazione, invece, è limitata dalla capacità della VM di Seesaw che esegue il bilanciamento del carico.
Le applicazioni variano in base alla quantità di CPU e memoria richieste, quindi è fondamentale eseguire un test di carico prima di iniziare a gestire un numero elevato di client.
I test indicano che una singola VM di Seesaw con 6 CPU e 3 GB di memoria può gestire 10 GB/s (tariffa di rete) durante il caricamento del traffico con 10.000 connessioni TCP simultanee. Tuttavia, è importante eseguire un test di carico personalizzato se si prevede di supportare un numero elevato di connessioni TCP simultanee.
Limiti di scalabilità
Grazie al bilanciamento del carico in bundle, i limiti alla scalabilità del cluster possono essere limitati. Esiste un limite al numero di nodi nel cluster e al numero di servizi che possono essere configurati sul bilanciatore del carico. Esiste anche un limite ai controlli di integrità. Il numero di controlli di integrità dipende dal numero di nodi e dal numero di servizi.
A partire dalla versione 1.3.1, il numero di controlli di integrità dipende dal numero di nodi e dal traffico dei servizi locali. Un servizio locale sul traffico è un servizio con l'opzione externalTrafficPolicy impostata su "Local".
| Versione 1.3.0 | Versione 1.3.1 e successive | |
|---|---|---|
| Servizi max (S) | 100 | 500 |
| Numero massimo di nodi (N) | 100 | 100 |
| Numero massimo controlli di integrità | S * N <= 10.000 | N + L * N <= 10.000, dove L è il numero di servizi locali di traffico |
Esempio: nella versione 1.3.1, supponiamo che tu abbia 100 nodi e 99 traffico di Servizi locali. Il numero dei controlli di integrità è quindi 100 + 99 * 100 = 10.000, che rientra nel limite di 10.000.
Upgrade del bilanciatore del carico per cluster di amministrazione
A partire dalla versione 1.4, viene eseguito l'upgrade dei bilanciatori del carico quando esegui l'upgrade del cluster. Non è necessario eseguire altro comando per eseguire l'upgrade dei bilanciatori del carico separatamente. Tuttavia, puoi comunque utilizzare gkectl upgrade loadbalancer di seguito per aggiornare alcuni parametri.
Puoi aggiornare CPU e memoria per le tue VM di Seesaw. Crea un nuovo file di configurazione come nell'esempio che segue, imposta le CPU e la memoria per le VM di Seesaw. Lasciarli vuoti per mantenerli invariati. Se bundlePath è impostato, eseguirà l'upgrade del bilanciatore del carico a quello specificato nel bundle.
Ad esempio:
apiVersion: v1
kind: AdminCluster
bundlePath:
loadBalancer:
kind: Seesaw
seesaw:
cpus: 3
memoryMB: 3072
Quindi esegui questo comando per eseguire l'upgrade del bilanciatore del carico:
gkectl upgrade loadbalancer --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] --config [ADMIN_CLUSTER_CONFIG] --admin-cluster
dove:
[ADMIN_CLUSTER_KUBECONFIG] è il file kubeconfig per il cluster di amministrazione.
[ADMIN_CLUSTER_CONFIG] è il file di configurazione del cluster di amministrazione creato.
Durante un upgrade di un bilanciatore del carico, si verificherà un tempo di inattività. Se l'alta disponibilità è abilitata per il bilanciatore del carico, il tempo di inattività massimo è di due secondi.
Upgrade del bilanciatore del carico per cluster utente
A partire dalla versione 1.4, viene eseguito l'upgrade dei bilanciatori del carico quando esegui l'upgrade del cluster. Non è necessario eseguire altro comando per eseguire l'upgrade dei bilanciatori del carico separatamente. Tuttavia, puoi comunque utilizzare gkectl upgrade loadbalancer di seguito per aggiornare alcuni parametri.
Puoi aggiornare CPU e memoria per le tue VM di Seesaw. Crea un nuovo file di configurazione come nell'esempio che segue, imposta le CPU e la memoria per le VM di Seesaw. Lasciali vuoti
per non modificarli. Se è impostato il valore gkeOnPremVersion, verrà eseguito l'upgrade del bilanciatore del carico a quello specificato da questa versione.
Ad esempio:
apiVersion: v1
kind: UserCluster
name: cluster-1
gkeOnPremVersion:
loadBalancer:
kind: Seesaw
seesaw:
cpus: 4
memoryMB: 3072
Quindi esegui questo comando per eseguire l'upgrade del bilanciatore del carico:
gkectl upgrade loadbalancer --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] --config [USER_CLUSTER_CONFIG]
dove:
[ADMIN_CLUSTER_KUBECONFIG] è il file kubeconfig per il cluster di amministrazione.
[USER_CLUSTER_CONFIG] è il file di configurazione utente che hai creato.
[CLUSTER_NAME] è il nome del cluster di cui è in corso l'upgrade.
Visualizzazione dei log di Seesaw
Il bilanciatore del carico associato a Seesaw archivia i file di log nelle VM di Seesaw in /var/log/seesaw/. Il file di log più importante è seesaw_engine.INFO.
A partire dalla versione 1.6, se Stackdriver è abilitato, i log vengono caricati anche su Cloud. Puoi visualizzarle nella risorsa "anthos_l4lb"". Per disabilitare il caricamento dei log, puoi connetterti a SSH per connetterti alla VM ed eseguire:
sudo systemctl disable --now docker.fluent-bit.service
Visualizzazione delle informazioni sulle VM di Seesaw
Puoi trovare informazioni sulle VM di Seesaw per un cluster nella risorsa personalizzata SeesawGroup.
Visualizza la risorsa personalizzata SeesawGroup per un cluster:
kubectl --kubeconfig [CLUSTER_KUBECONFIG] get seesawgroups -n kube-system -o yaml
dove [CLUSTER_KUBECONFIG] è il percorso del file kubeconfig per il cluster.
L'output ha un campo isReady che mostra se le VM sono pronte a gestire il traffico. L'output mostra anche i nomi e gli indirizzi IP delle VM di Seesaw e quale VM è la VM principale:
apiVersion: seesaw.gke.io/v1alpha1
kind: SeesawGroup
metadata:
...
name: seesaw-for-cluster-1
namespace: kube-system
...
spec: {}
status:
machines:
- hostname: cluster-1-seesaw-1
ip: 172.16.20.18
isReady: true
lastCheckTime: "2020-02-25T00:47:37Z"
role: Master
- hostname: cluster-1-seesaw-2
ip: 172.16.20.19
isReady: true
lastCheckTime: "2020-02-25T00:47:37Z"
role: Backup
Visualizzazione delle metriche di Seesaw
Il bilanciatore del carico associato a Seesaw fornisce le seguenti metriche:
- Velocità effettiva per servizio o nodo
- Velocità pacchetti per servizio o nodo
- Connessioni attive per servizio o nodo
- Utilizzo CPU e memoria
- Numero di pod di backend integri per servizio
- Quale VM è la principale e qual è il backup
- Tempo di attività
A partire dalla versione 1.6, queste metriche vengono caricate in Cloud con Stackdriver. Puoi visualizzarli nella risorsa di monitoraggio di "anthos_l4lb".
Puoi anche utilizzare soluzioni di monitoraggio e dashboard a tua scelta, purché supporti il formato Prometheus.
Eliminazione di un bilanciatore del carico
Se elimini un cluster che utilizza il bilanciamento del carico in bundle, devi eliminare le VM di Seesaw per tale cluster. Puoi farlo eliminando le VM di Seesaw nell'interfaccia utente di vSphere.
In alternativa, a partire dalla versione 1.4.2, puoi eseguire gkectl e passare file di configurazione per eliminare il bilanciatore del carico in bundle e il relativo file di gruppo.
Per i cluster di amministrazione, esegui il comando seguente:
gkectl delete loadbalancer --config [ADMIN_CONFIG_FILE] --seesaw-group-file [GROUP_FILE]
Per i cluster utente, esegui il comando seguente:
gkectl delete loadbalancer --config [CLUSTER_CONFIG_FILE] --seesaw-group-file [GROUP_FILE] --kubeconfig [ADMIN_CLUSTER_KUBECONFIG]
dove
[ADMIN_CONFIG_FILE] è il file di configurazione del cluster di amministrazione
[CLUSTER_CONFIG_FILE] è il file di configurazione del cluster utente
[ADMIN_CLUSTER_KUBECONFIG] è il file
kubeconfigdel cluster di amministrazione[GROUP_FILE] è il file del gruppo di Seesaw. Il nome del file del gruppo ha il formato
seesaw-for-[CLUSTER_NAME]-[IDENTIFIER].yaml.
Versioni precedenti alla 1.4.2
Nelle versioni precedenti alla 1.4.2, in alternativa, puoi eseguire questo comando, che elimina le VM di Seesaw e il file dei gruppi di Seesaw:
gkectl delete loadbalancer --config vsphere.yaml --seesaw-group-file [GROUP_FILE]
dove
[GROUP_FILE] è il file del gruppo di Seesaw. Il file del gruppo si trova nella workstation di amministrazione accanto a
config.yaml. Il nome del file del gruppo ha il formatoseesaw-for-[CLUSTER_NAME]-[IDENTIFIER].yaml.vsphere.yamlè un file che contiene le seguenti informazioni sul tuo server vCenter:
vcenter:
credentials:
address:
username:
password:
datacenter:
cacertpath:
Risolvere i problemi
Ottenere una connessione SSH a una VM di Seesaw
Occasionalmente potresti voler connetterti a una VM di Seesaw tramite SSH per risolvere i problemi o eseguire il debug.
Recupero della chiave SSH in corso...
Se hai già creato il cluster, segui questi passaggi per ottenere la chiave SSH:
Recupera il secret di
seesaw-sshdal cluster. Recupera la chiave SSH dal Secret e dalla codifica base64. Salva la chiave decodificata in un file temporaneo:kubectl --kubeconfig [CLUSTER_KUBECONFIG] get -n kube-system secret seesaw-ssh -o \ jsonpath='{@.data.seesaw_ssh}' | base64 -d | base64 -d > /tmp/seesaw-ssh-keydove [CLUSTER_KUBECONFIG] è il file kubeconfig per il cluster.
Imposta le autorizzazioni appropriate per il file della chiave:
chmod 0600 /tmp/seesaw-ssh-key
Se non hai ancora creato il cluster, segui questi passaggi per ottenere la chiave SSH:
Individua il file denominato
seesaw-for-[CLUSTER_NAME]-[IDENTIFIER].yaml.Il file è denominato file di gruppo e si trova accanto a
config.yaml.gkectl create loadbalancerstampa anche la posizione del file del gruppo.Nel file, recupera il valore
credentials.ssh.privateKeye decodificalo in base64. Salva la chiave decodificata in un file temporaneo:cat seesaw-for-[CLUSTER_NAME]-[IDENTIFIER].yaml | grep privatekey | sed 's/ privatekey: //g' \ | base64 -d > /tmp/seesaw-ssh-key
Imposta le autorizzazioni appropriate per il file della chiave:
chmod 0600 /tmp/seesaw-ssh-key
Ora puoi connetterti tramite SSH alla VM Seesaw:
ssh -i /tmp/seesaw-ssh-key ubuntu@[SEESAW_IP]
dove [SEESAW_IP] è l'indirizzo IP della VM di Seesaw.
Recupero snapshot
Puoi acquisire snapshot per le VM di Seesaw utilizzando il comando gkectl diagnose snapshot insieme al flag --scenario.
Se imposti --scenario su all o all-with-logs, l'output include le istantanee di Seesaw insieme ad altri snapshot.
Se imposti --scenario su seesaw, l'output include solo gli snapshot Seesaw.
Esempi:
gkectl diagnose snapshot --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] --scenario seesaw
dove [ADMIN_CLUSTER_KUBECONFIG] è il file kubeconfig per il cluster di amministrazione.
gkectl diagnose snapshot --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] --cluster-name [CLUSTER_NAME] --scenario seesaw
gkectl diagnose snapshot --seesaw-group-file [GROUP_FILE] --scenario seesaw
dove [GROUP_FILE] è il percorso del file del gruppo del cluster:
ad esempio:seesaw-for-gke-admin-xxxxxx.yaml.
Problemi noti
Cisco ACI non funziona con il server DSR
Seesaw viene eseguito in modalità DSR e per impostazione predefinita non funziona in Cisco ACI a causa dell'apprendimento IP del piano dati. Puoi trovare una possibile soluzione alternativa utilizzando il gruppo di endpoint dell'applicazione qui.