BigQuery への Teradata の移行チュートリアル
このドキュメントでは、サンプルデータを使用して Teradata から BigQuery に移行する方法について説明します。Teradata データ ウェアハウスから BigQuery にスキーマとデータの両方を転送するプロセスに沿って概念実証を行います。
目標
- 合成データを生成して、Teradata にアップロードする。
- BigQuery Data Transfer Service(BQDT)を使用して、スキーマとデータを BigQuery に移行する。
- クエリが Teradata と BigQuery で同じ結果を返すことを確認する。
費用
このクイックスタートでは、 Google Cloudの以下の課金対象コンポーネントを使用します。
- BigQuery: このチュートリアルでは、1 GB 近くのデータを BigQuery に保存し、クエリの 1 回の実行あたり 2 GB 未満のデータを処理します。Google Cloud の無料枠の一部として、BigQuery では特定の上限まで無料でリソースを使用できるようになっています。これらの無料使用枠上限は、無料トライアル期間中だけでなく、期間終了後も適用されます。無料使用量上限を超えた場合と無料トライアル期間が満了した場合は、BigQuery の料金ページに記載されている料金体系に沿って課金されます。
料金計算ツールを使用すると、予想使用量に基づいて費用の見積もりを作成できます。
前提条件
- インターネットにアクセスできるマシンに書き込み権限と実行権限があることを確認し、データ生成ツールをダウンロードして実行できるようにします。
- Teradata データベースに接続できることを確認します。
マシンに Teradata BTEQ と FastLoad クライアント ツールがインストールされていることを確認します。Teradata クライアント ツールは Teradata ウェブサイトから入手できます。ツールをインストールする際にサポートを必要とされる場合は、ツールのインストール、構成、実行の詳細についてシステム管理者にお問い合わせください。BTEQ に代わる方法として、次の方法があります。
- DBeaver などのグラフィカル インターフェースを備えたツールをインストールします。
- Python 用 Teradata SQL Driver をインストールして、Teradata データベースとのやり取りをスクリプト化するために使用します。
BigQuery Data Transfer Service エージェントが BigQuery に接続してスキーマとデータを転送できるように、マシンがGoogle Cloud と接続していることを確認します。
はじめに
このクイックスタートでは、移行の概念実証について説明します。クイックスタートでは、合成データを生成して Teradata に読み込みます。次に、BigQuery Data Transfer Service を使用して、スキーマとデータを BigQuery に移行します。最後に、両方のクエリを実行して結果を比較します。Teradata のスキーマとデータが BigQuery に 1 対 1 でマッピングされていることが最終状態になります。
このクイックスタートは、BigQuery Data Transfer Service を使用してスキーマとデータを移行するために、実践的な経験を積みたいと思っているデータ ウェアハウス管理者、デベロッパー、データ使用者を対象としています。
データの生成
Transaction Processing Performance Council(TPC)は、ベンチマークの仕様を公開する非営利団体です。これらの仕様は、データ関連のベンチマークを実施するための事実上の業界標準になっています。
TPC-H 仕様は、意思決定支援に重点を置いたベンチマークです。このクイックスタートでは、この仕様の一部を使用してテーブルを作成し、実際のデータ ウェアハウスのモデルとして合成データを生成します。この仕様はベンチマーク用に作成されていますが、ベンチマーク タスクではなく、移行の概念実証の一部としてこのモデルを使用します。
- Teradata に接続している PC でウェブブラウザを開き、TPC ウェブサイトから最新の TPC-H ツールをダウンロードします。
- コマンド ターミナルを開き、ツールをダウンロードしたディレクトリに移動します。
ダウンロードした ZIP ファイルを展開します。file-name は、ダウンロードしたファイルの名前に置き換えます。
unzip file-name.zip
名前にツールのバージョン番号が含まれるディレクトリが抽出されます。このディレクトリには、DBGEN データ生成ツールの TPC ソースコードと TPC-H 仕様が含まれています。
dbgenサブディレクトリに移動します。次の例のように、使用しているバージョンに対応する親ディレクトリ名を使用します。cd 2.18.0_rc2/dbgen次のテンプレートを使用して makefile を作成します。
cp makefile.suite makefileテキスト エディタで makefile を編集します。たとえば vi を使用する場合は、次のようにファイルを編集します。
vi makefilemakefile で、次の変数の値を変更します。
CC = gcc # TDAT -> TERADATA DATABASE = TDAT MACHINE = LINUX WORKLOAD = TPCH環境によっては、C コンパイラ(
CC)またはMACHINE値が異なる場合があります。必要であれば、システム管理者に確認してください。変更を保存し、ファイルを閉じます。
makefile を実行します。
makedbgenツールを使用して TPC-H データを生成します。dbgen -vデータの生成には数分かかります。
-v(詳細)フラグを指定すると、コマンドによって進行状況がレポートされます。データの生成が完了すると、現在のフォルダに.tblという拡張子の ASCII ファイルが 8 個生成されます。これらのファイルには、各 TPC-H テーブルに読み込む合成データがパイプ区切りで記述されています。
Teradata へのサンプルデータのアップロード
このセクションでは、生成されたデータを Teradata データベースにアップロードします。
TPC-H データベースを作成する
Basic Teradata Query(BTEQ)という Teradata クライアントを使用して、1 つ以上の Teradata データベース サーバーと通信し、各システムで SQL クエリを実行します。このセクションでは、BTEQ を使用して TPC-H テーブル用に新しいデータベースを作成します。
Teradata BTEQ クライアントを開きます。
bteqTeradata にログインします。teradata-ip と teradata-user は、実際の環境での対応する値に置き換えます。
.LOGON teradata-ip/teradata-user
tpchという名前のデータベースを作成し、2 GB の領域を割り当てます。CREATE DATABASE tpch AS PERM=2e+09;BTEQ を終了します。
.QUIT
生成されたデータを読み込む
このセクションでは、FastLoad スクリプトを作成し、サンプル テーブルの作成と読み込みを行います。テーブル定義については、TPC-H 仕様のセクション 1.4 をご覧ください。セクション 1.2 には、データベース スキーマ全体のエンティティの関係図が掲載されています。
次の手順は、TPC-H テーブルの中で最も大きく複雑な lineitem テーブルを作成する方法を示しています。lineitem テーブルが完成したら、残りのテーブルにも同じ手順を繰り返します。
テキスト エディタで、
fastload_lineitem.flという名前の新しいファイルを作成します。vi fastload_lineitem.fl次のスクリプトをファイルにコピーします。このスクリプトは、Teradata データベースに接続して
lineitemという名前のテーブルを作成します。logonコマンドで、teradata-ip、teradata-user、teradata-pwd を接続の詳細情報に置き換えます。logon teradata-ip/teradata-user,teradata-pwd; drop table tpch.lineitem; drop table tpch.error_1; drop table tpch.error_2; CREATE multiset TABLE tpch.lineitem, NO FALLBACK, NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO ( L_ORDERKEY INTEGER NOT NULL, L_PARTKEY INTEGER NOT NULL, L_SUPPKEY INTEGER NOT NULL, L_LINENUMBER INTEGER NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_LINESTATUS CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_COMMITDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_RECEIPTDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_SHIPINSTRUCT CHAR(25) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPMODE CHAR(10) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_COMMENT VARCHAR(44) CHARACTER SET LATIN CASESPECIFIC NOT NULL) PRIMARY INDEX ( L_ORDERKEY ) PARTITION BY RANGE_N(L_COMMITDATE BETWEEN DATE '1992-01-01' AND DATE '1998-12-31' EACH INTERVAL '1' DAY);スクリプトではまず、
lineitemテーブルと一時エラーテーブルが存在しないことを確認し、lineitemテーブルの作成に進みます。同じファイルに次のコードを追加し、新しく作成したテーブルにデータを読み込みます。3 つのブロック(
define、insert、values)のテーブル フィールドにすべて入力し、読み込みのデータ型としてvarcharを使用します。begin loading tpch.lineitem errorfiles tpch.error_1, tpch.error_2; set record vartext; define in_ORDERKEY(varchar(50)), in_PARTKEY(varchar(50)), in_SUPPKEY(varchar(50)), in_LINENUMBER(varchar(50)), in_QUANTITY(varchar(50)), in_EXTENDEDPRICE(varchar(50)), in_DISCOUNT(varchar(50)), in_TAX(varchar(50)), in_RETURNFLAG(varchar(50)), in_LINESTATUS(varchar(50)), in_SHIPDATE(varchar(50)), in_COMMITDATE(varchar(50)), in_RECEIPTDATE(varchar(50)), in_SHIPINSTRUCT(varchar(50)), in_SHIPMODE(varchar(50)), in_COMMENT(varchar(50)) file = lineitem.tbl; insert into tpch.lineitem ( L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER, L_QUANTITY, L_EXTENDEDPRICE, L_DISCOUNT, L_TAX, L_RETURNFLAG, L_LINESTATUS, L_SHIPDATE, L_COMMITDATE, L_RECEIPTDATE, L_SHIPINSTRUCT, L_SHIPMODE, L_COMMENT ) values ( :in_ORDERKEY, :in_PARTKEY, :in_SUPPKEY, :in_LINENUMBER, :in_QUANTITY, :in_EXTENDEDPRICE, :in_DISCOUNT, :in_TAX, :in_RETURNFLAG, :in_LINESTATUS, :in_SHIPDATE, :in_COMMITDATE, :in_RECEIPTDATE, :in_SHIPINSTRUCT, :in_SHIPMODE, :in_COMMENT ); end loading; logoff;
FastLoad スクリプトでは、前のセクションで生成した
lineitem.tblという名前のディレクトリ内のファイルからデータを読み込みます。変更を保存し、ファイルを閉じます。
FastLoad スクリプトを実行します。
fastload < fastload_lineitem.flTPC-H 仕様のセクション 1.4 に記載されている残りの TPC-H テーブルについて、この手順を繰り返します。テーブルごとに手順を調整してください。
BigQuery へのスキーマとデータの移行
スキーマとデータを BigQuery に移行する方法については、別のチュートリアル(Teradata からのデータの移行)をご覧ください。ここでは、このチュートリアルで行うステップについて詳しく説明しています。他のチュートリアルの手順が完了したら、このドキュメントに戻り、次のクエリ結果の確認セクションに進んでください。
BigQuery データセットを作成する
最初の Google Cloud 構成手順では、移行後のテーブルを保持するためのデータセットを BigQuery で作成するように求められます。データセットの名前を tpch に設定します。このクイックスタートの最後のクエリは、この名前を前提としています。変更の必要はありません。
# Use the bq utility to create the dataset
bq mk --location=US tpch
サービス アカウントを作成する
また、 Google Cloud 構成手順の一部として、Identity and Access Management(IAM)サービス アカウントを作成する必要があります。このサービス アカウントは、BigQuery にデータを書き込み、一時的なデータを Cloud Storage に保存するために使用されます。
# Set the PROJECT variable
export PROJECT=$(gcloud config get-value project)
# Create a service account
gcloud iam service-accounts create tpch-transfer
BigQuery データセットと Cloud Storage のステージング領域を管理できるように、サービス アカウントに権限を付与します。
# Set TPCH_SVC_ACCOUNT = service account email
export TPCH_SVC_ACCOUNT=tpch-transfer@${PROJECT}.iam.gserviceaccount.com
# Bind the service account to the BigQuery Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/bigquery.admin
# Bind the service account to the Storage Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/storage.admin
Cloud Storage ステージング バケットを作成する
Google Cloud 構成のもう 1 つのタスクは、Cloud Storage バケットを作成することです。このバケットは、BigQuery に取り込まれるデータファイルのステージング領域として BigQuery Data Transfer Service によって使用されます。
# Use gcloud storage to create the bucket
gcloud storage buckets create gs://${PROJECT}-tpch --location=us-central1
テーブル名のパターンを指定する
BigQuery Data Transfer Service の新しい転送を構成するときに、転送対象にするテーブルを記述する式を指定する必要があります。このクイックスタートでは、tpch データベースのすべてのテーブルを転送します。
式の形式は database.table です。テーブル名はワイルドカードにすることもできます。Java のワイルドカードは 2 つのドットで始まるため、tpch データベースからすべてのテーブルを転送する式は次のようになります。
tpch..*
ドットは 2 つあります。
クエリ結果の確認
サンプルデータを作成してデータを Teradata にアップロードし、別のチュートリアルで説明した BigQuery Data Transfer Service を使用してデータを BigQuery に移行しました。次に、2 つの TPC-H 標準クエリを実行して、Teradata と BigQuery で同じ結果になっていることを確認します。
料金概要レポートのクエリを実行する
最初のクエリは、料金概要レポートクエリです(TPC-H 仕様セクション 2.4.1)。このクエリは、指定した日付に請求、発送、返品された商品の数を返します。
完全なクエリは次のようになります。
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice*(1-l_discount)) AS sum_disc_price,
SUM(l_extendedprice*(1-l_discount)*(1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM tpch.lineitem
WHERE l_shipdate BETWEEN '1996-01-01' AND '1996-01-10'
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;
Teradata でクエリを実行します。
- BTEQ を実行し、Teradata に接続します。詳しくは、このドキュメントの TPC-H データベースを作成するをご覧ください。
出力の表示幅を 500 文字に変更します。
.set width 500クエリをコピーし、BTEQ プロンプトに貼り付けます。
出力は次のようになります。
L_RETURNFLAG L_LINESTATUS sum_qty sum_base_price sum_disc_price sum_charge avg_qty avg_price avg_disc count_order ------------ ------------ ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------- N O 629900.00 943154565.63 896323924.4600 932337245.114003 25.45 38113.41 .05 24746
同じクエリを BigQuery で実行します。
BigQuery コンソールに移動します。
クエリをクエリエディタにコピーします。
FROM行のデータセット名が正しいことを確認します。[実行] をクリックします。
結果は Teradata での結果と同じです。
必要であれば、クエリの間隔を広げて、テーブル内のすべての行をスキャンすることもできます。
ローカル サプライヤー ボリューム クエリを実行する
2 番目の例は、ローカル サプライヤー ボリューム クエリのレポートです(TPC-H 仕様の 2.4.5 項を参照)。このクエリは、その国の顧客とサプライヤーによって得られた収益を品目別に返します。この結果は、流通センターの設置場所を計画する際に役立ちます。
完全なクエリは次のようになります。
SELECT
n_name AS nation,
SUM(l_extendedprice * (1 - l_discount) / 1000) AS revenue
FROM
tpch.customer,
tpch.orders,
tpch.lineitem,
tpch.supplier,
tpch.nation,
tpch.region
WHERE c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
AND o_orderdate >= '1996-01-01'
AND o_orderdate < '1997-01-01'
GROUP BY
n_name
ORDER BY
revenue DESC;
前のセクションで説明したように、クエリを Teradata BTEQ と BigQuery コンソールで実行します。
Teradata の結果は次のとおりです。
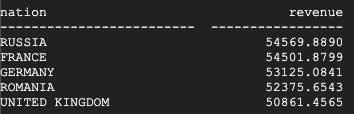
BigQuery の結果は次のとおりです。
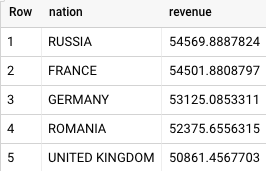
Teradata と BigQuery の両方が同じ結果を返します。
商品タイプの収益測定クエリを実行する
移行を検証する最後のテストでは、商品タイプの収益測定クエリにある最後のサンプルクエリを使用します(TPC-H 仕様セクション 2.4.9 を参照)。このクエリは、その年に注文されたすべてのパーツの収益を国別および年別に返します。結果は、パーツ名と特定のサプライヤーの部分文字列でフィルタリングされます。
完全なクエリは次のようになります。
SELECT
nation,
o_year,
SUM(amount) AS sum_profit
FROM (
SELECT
n_name AS nation,
EXTRACT(YEAR FROM o_orderdate) AS o_year,
(l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity)/1e+3 AS amount
FROM
tpch.part,
tpch.supplier,
tpch.lineitem,
tpch.partsupp,
tpch.orders,
tpch.nation
WHERE s_suppkey = l_suppkey
AND ps_suppkey = l_suppkey
AND ps_partkey = l_partkey
AND p_partkey = l_partkey
AND o_orderkey = l_orderkey
AND s_nationkey = n_nationkey
AND p_name like '%blue%' ) AS profit
GROUP BY
nation,
o_year
ORDER BY
nation,
o_year DESC;
前のセクションで説明したように、クエリを Teradata BTEQ と BigQuery コンソールで実行します。
Teradata の結果は次のとおりです。
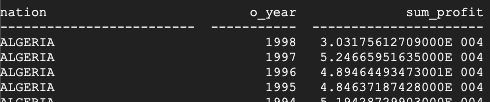
BigQuery の結果は次のとおりです。
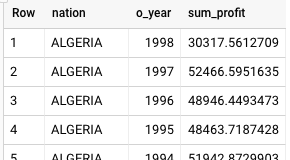
Teradata と BigQuery の両方で同じ結果が返されますが、Teradata の合計は科学的記数法で返されます。
その他のクエリ
必要に応じて、TPC-H 仕様セクション 2.4 項で定義されている残りの TPC-H クエリを実行します。
DBGEN ツールと同じディレクトリにある QGEN ツールを使用すると、TPC-H 規格に準拠したクエリを生成できます。QGEN は DBGEN と同じ makefile を使用してビルドされます。make を実行して dbgen をコンパイルすると、qgen 実行可能ファイルも生成されます。
ツールとコマンドライン オプションの詳細については、各ツールの README ファイルをご覧ください。
クリーンアップ
このチュートリアルで使用したリソースについて Google Cloud アカウントに課金されないようにするには、リソースを削除します。
プロジェクトの削除
課金を発生させないようにする最も簡単な方法は、このチュートリアルで作成したプロジェクトを削除することです。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- Teradata から BigQuery への移行の手順を確認する。