Teradata からスキーマとデータを移行する
BigQuery Data Transfer Service と特別な移行エージェントを組み合わせると、Teradata オンプレミス データ ウェアハウス インスタンスから BigQuery にデータをコピーできます。このドキュメントでは、BigQuery Data Transfer Service を使用して Teradata からデータを移行する手順をステップごとに説明します。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- ログビューア(
roles/logging.viewer) - ストレージ管理者(
roles/storage.admin)、または次の権限を付与するカスタムロール。storage.objects.createstorage.objects.getstorage.objects.list
- BigQuery 管理者(
roles/bigquery.admin)または次の権限を付与するカスタムロール。bigquery.datasets.createbigquery.jobs.createbigquery.jobs.getbigquery.jobs.listAllbigquery.transfers.getbigquery.transfers.update
- 移行エージェントは、Teradata インスタンスと G Google Cloud APIs との JDBC 接続を使用します。ファイアウォールによってネットワーク アクセスがブロックされていないことを確認します。
- Java Runtime Environment 8 以降がインストールされていることを確認します。
- 抽出方法で説明されているように、選択した抽出方法に十分な保存容量があることを確認してください。
- Teradata Parallel Transporter(TPT)抽出を使用することを決定した場合は、
tbuildユーティリティがインストールされていることを確認してください。抽出方法の選択について詳しくは、抽出方法をご覧ください。 システム テーブルと移行されるテーブルへの読み取りアクセス権限を持つ Teradata ユーザーのユーザー名とパスワードがあることを確認します。
Teradata インスタンスに接続するためのホスト名とポート番号がわかるようにしてください。
client_emailprivate_key:-----BEGIN PRIVATE KEY-----と-----END PRIVATE KEY-----の間のすべての文字をコピーします。/n文字もすべて含まれます。二重引用符は含まれません。ACCESS_ID: アクセスキー ID、またはサービス アカウント キーファイルのclient_email値。ACCESS_KEY: シークレット アクセスキー、またはサービス アカウント キーファイルのprivate_key値。Google Cloud コンソールで、[BigQuery] ページに移動します。
[データ転送] をクリックします。
[転送を作成] をクリックします。
[ソースタイプ] セクションで、次の操作を行います。
- [Migration: Teradata] を選択します。
- [転送構成名] に、転送の表示名(例:
My Migration)を入力します。表示名には、後で修正が必要になった場合に簡単に識別できる任意の名前を使用できます。 - 省略可: [スケジュール オプション] は、デフォルト値の [毎日](作成時間に基づく)のままにするか、繰り返しの増分転送にする場合は別の時間を選択します。それ以外の場合は、1 回の転送ごとに [オンデマンド] を選択します。
[転送先の設定] で、該当するデータセットを選択します。
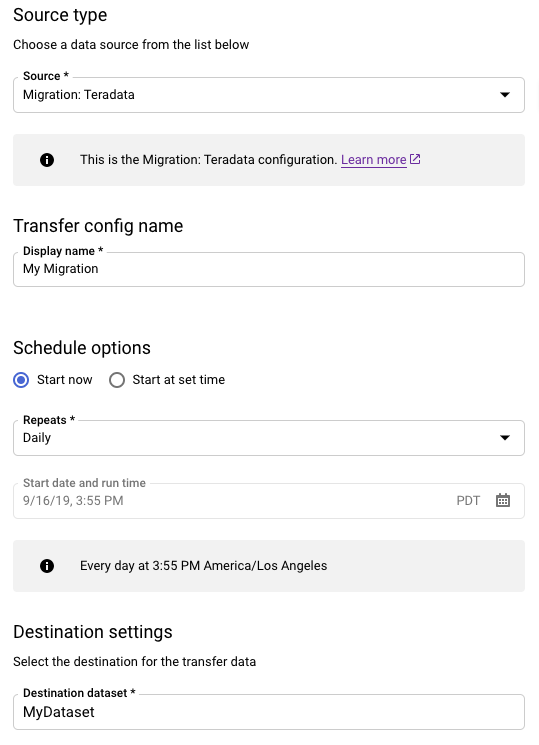
[データソースの詳細] セクションで、Teradata 転送について具体的な詳細情報を入力し続けます。
- [Database type] で、[Teradata] を選択します。
- Cloud Storage バケットについては、移行データをステージングするための Cloud Storage バケットの名前を探索します。接頭辞
gs://は入力しないでください。バケット名のみを入力してください。 - [Database name] に、Teradata のソース データベースの名前を入力します。
[Table name patterns] に、ソース データベース内のテーブル名を照合するためのパターンを入力します。正規表現を使用してパターンを指定できます。次に例を示します。
sales|expensesは、salesとexpensesという名前のテーブルに一致します。.*はすべてのテーブルを照合します。
サービス アカウントのメールアドレスには、移行エージェントで使用されるサービス アカウントの認証情報に関連付けられているメールアドレスを入力します。
省略可: [Schema file path] には、カスタム スキーマ ファイルのパスとファイル名を入力します。カスタム スキーマ ファイルの作成の詳細については、カスタム スキーマ ファイルをご覧ください。このフィールドを空白にすると、BigQuery がソーステーブル スキーマを自動的に検出します。
省略可: [Translation output root directory] に、BigQuery 変換エンジンによって提供されるスキーマ マッピング ファイルのパスとファイル名を入力します。スキーマ マッピング ファイルの生成の詳細については、スキーマに翻訳エンジンの出力を使用する(プレビュー)をご覧ください。このフィールドを空白にすると、BigQuery がソーステーブル スキーマを自動的に検出します。
省略可: [GCS への直接アンロードを有効にする] で、チェックボックスをオンにして Cloud Storage のアクセス モジュールを有効にします。
[サービス アカウント] メニューで、Google Cloud プロジェクトに関連付けられているサービス アカウントからサービス アカウントを選択します。ユーザー認証情報を使用する代わりに、サービス アカウントを転送に関連付けることができます。データ転送でサービス アカウントを使用する方法の詳細については、サービス アカウントの使用をご覧ください。
- フェデレーション ID でログインした場合、転送を作成するにはサービス アカウントが必要です。Google アカウントでログインした場合、転送用のサービス アカウントは省略可能です。
- サービス アカウントには必要な権限が付与されている必要があります。
省略可: [通知オプション] セクションで、次のようにします。
[保存] をクリックします。
[転送の詳細] ページで [構成] タブをクリックします。
移行エージェントを実行するために必要になるため、この転送のリソース名をメモします。
--data_source--display_name--target_dataset--params- project ID はプロジェクト ID です。
--project_idで特定のプロジェクトを指定しない場合は、デフォルトのプロジェクトが使用されます。 - dataset は、転送構成の対象のデータセット(
--target_dataset)です。 - name は、転送構成の表示名(
--display_name)です。転送の表示名には、後で修正が必要になった場合に識別できる任意の名前を使用できます。 - service_account は、転送の認証に使用されるサービス アカウント名です。サービス アカウントは、転送の作成に使用した
project_idが所有している必要があります。また、リストされた必要な権限がすべて付与されている必要があります。 - parameters には、作成される転送構成のパラメータ(
--params)を JSON 形式で指定します。例:--params='{"param":"param_value"}'- Teradata の移行では、次のパラメータを使用します。
bucketは、移行中にステージング領域として機能する Cloud Storage バケットです。database_typeは、Teradata です。agent_service_accountは、作成したサービス アカウントに関連付けられたメールアドレスです。database_nameは、Teradata のソース データベースの名前です。table_name_patternsは、ソース データベース内のテーブル名を照合するためのパターンです。正規表現を使用してパターンを指定できます。このパターンは、Java の正規表現の構文に従っている必要があります。たとえば、次のような情報が得られます。sales|expensesは、salesとexpensesという名前のテーブルに一致します。.*はすべてのテーブルを照合します。
is_direct_gcs_unload_enabledは、Cloud Storage への直接アンロードを有効にするブール値フラグです。
- Teradata の移行では、次のパラメータを使用します。
- data_source は、データソース(
--data_source)です。on_premises 新しいセッションを開きます。コマンドラインで、次の形式に従う初期化コマンドを実行します。
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --initialize
次の例は、JDBC ドライバと移行エージェントの JAR ファイルがローカルの
migrationディレクトリにある場合の初期化コマンドを示しています。Unix、Linux、Mac OS
java -cp \ /usr/local/migration/terajdbc4.jar:/usr/local/migration/mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --initialize
Windows
すべてのファイルを
C:\migrationフォルダにコピーして(またはコマンドのパスを修正して)、次を実行します。java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --initialize
プロンプトが表示されたら、次のオプションを構成します。
- Teradata Parallel Transporter(TPT)テンプレートをディスクに保存するかどうかを選択します。TPT による抽出方法の使用を計画している場合、Teradata インスタンスに適したパラメータを使用して、保存されたテンプレートを変更できます。
- 転送ジョブがファイルの抽出に使用できるローカル ディレクトリへのパスを入力します。抽出方法で説明されている推奨の最小限のストレージ スペースがあることを確認します。
- データベースのホスト名を入力します。
- データベースのポートを入力します。
- 抽出方法として Teradata Parallel Transporter(TPT)を使用するかどうかを選択します。
- 省略可: データベースの認証情報ファイルへのパスを入力します。
BigQuery Data Transfer Service の構成名を指定するかどうかを選択します。
すでに設定した転送用に移行エージェントを初期化する場合は、次のようにします。
- 転送のリソース名を入力します。これは、転送の [転送の詳細] ページの [構成] タブで確認できます。
- プロンプトが表示されたら、作成する移行エージェント構成ファイルのパスとファイル名を入力します。転送を開始するには、移行エージェントを実行するときにこのファイルを参照します。
- 以降の手順はスキップします。
移行エージェントを使用して転送を設定する場合は、Enter キーを押して次のプロンプトにとびます。
Google Cloud プロジェクト ID を入力します。
Teradata にソース データベースの名前を入力します。
ソース データベース内のテーブル名と照合するパターンを入力します。正規表現を使用してパターンを指定できます。次に例を示します。
sales|expensesは、salesとexpensesという名前のテーブルに一致します。.*はすべてのテーブルを照合します。
省略可: ローカルの JSON スキーマ ファイルのパスを入力します。繰り返し転送する場合は、実行することを強くおすすめします。
スキーマ ファイルを使用しない場合、または移行エージェントに作成させる場合は、[Enter] を押して次のプロンプトにとびます。
新しいスキーマ ファイルを作成するかどうかを選択します。
スキーマ ファイルを作成する場合は、次のようにします。
- タイプ
yes。 - システム テーブルと移行するテーブルへの読み取りアクセス権限を持つ teradata ユーザーのユーザー名を入力します。
そのユーザーのパスワードを入力します。
移行エージェントはスキーマ ファイルを作成し、その場所を出力します。
スキーマ ファイルを変更して、パーティショニング、クラスタ化、主キー、変更トラッキング列をマークし、このスキーマを転送構成に使用することを確認します。ヒントについては、カスタム スキーマ ファイルをご覧ください。
Enterを押して、次のプロンプトにとびます。
スキーマ ファイルを作成しない場合は、
noと入力します。- タイプ
BigQuery に読み込む前に、移行データをステージングするためのターゲットの Cloud Storage バケットの名前を入力します。移行エージェントがカスタム スキーマ ファイルを作成していた場合は、このバケットにアップロードされます。
BigQuery に宛先のデータセットの名前を入力します。
転送構成の表示名を入力します。
作成される移行エージェント構成ファイルのパスとファイル名を入力します。
リクエストされたすべてのパラメータを入力すると、移行エージェントは構成ファイルを作成し、指定したローカルパスにそれを出力します。構成ファイルの詳細については、次のセクションをご覧ください。
transfer-configuration: BigQuery のこの転送構成に関する情報。teradata-config: この Teradata の抽出に固有の情報。connection: ホスト名とポートに関する情報local-processing-space: Cloud Storage にアップロードする前に、エージェントがテーブルデータを抽出する先の抽出フォルダ。database-credentials-file-path:(省略可)Teradata データベースに自動的に接続するための認証情報を含むファイルのパス。このファイルには、認証情報用の 2 行が含まれている必要があります。次の例に示すように、ユーザー名/パスワードを使用できます。username=abc password=123
username=abc secret_resource_id=projects/my-project/secrets/my-secret-name/versions/1
max-local-storage: 指定されたステージング ディレクトリでの抽出に使用するローカル ストレージの最大容量。デフォルト値は50GBです。サポートされている形式はnumberKB|MB|GB|TBです。すべての抽出モードで、ファイルは Cloud Storage にアップロードされた後、ローカルのステージング ディレクトリから削除されます。
use-tpt: 抽出方法として Teradata Parallel Transporter(TPT)を使用するように移行エージェントに指示します。テーブルごとに、移行エージェントは TPT スクリプトを生成し、
tbuildプロセスを開始して、完了を待ちます。tbuildプロセスが完了すると、エージェントは抽出されたファイルを一覧表示して Cloud Storage にアップロードしてから、TPT スクリプトを削除します。詳しくは、抽出方法をご覧ください。transfer-views: ビューからのデータも転送するように移行エージェントに指示します。これは、移行中にデータのカスタマイズが必要な場合にのみ使用します。それ以外の場合は、ビューを BigQuery ビューに移行します。このオプションには次の前提条件があります。- このオプションは、Teradata バージョン 16.10 以降でのみ使用できます。
- ビューには整数列「partition」が定義されており、基になるテーブルの特定の行のパーティションの ID を指す必要があります。
max-sessions: 抽出ジョブ(FastExport または TPT)で使用されるセッションの最大数を指定します。0 に設定すると、Teradata データベースは各抽出ジョブのセッションの最大数を決定します。gcs-upload-chunk-size: 大きなファイルがチャンク形式で Cloud Storage にアップロードされます。このパラメータとmax-parallel-uploadは、Cloud Storage に同時にアップロードするデータの量を制御するために使用されます。たとえば、gcs-upload-chunk-sizeが 64 MB でmax-parallel-uploadが 10 MB の場合、移行エージェントは 640 MB(64 MB * 10)のデータを同時にアップロードできます。チャンクのアップロードに失敗した場合は、チャンク全体を再試行する必要があります。チャンクサイズは小さくする必要があります。max-parallel-upload: この値は、移行エージェントがファイルを Cloud Storage にアップロードするために使用する最大スレッド数を決定します。指定しない場合、Java 仮想マシンで使用可能なプロセッサ数がデフォルトで使用されます。一般的な経験則として、エージェントを実行するマシンのコア数に基づいて値を選択します。したがって、コア数がnの場合、最適なスレッド数はnとなります。コアがハイパースレッドの場合、最適な数は(2 * n)になります。max-parallel-uploadを調整する際に考慮する必要があるネットワーク帯域幅などの設定もあります。このパラメータを調整すると、Cloud Storage へのアップロードのパフォーマンスを向上させることができます。spool-mode: ほとんどの場合、NoSpool モードが最適です。NoSpoolは、エージェント構成のデフォルト値です。NoSpool の短所のいずれかがケースに当てはまる場合、このパラメータを変更します。max-unload-file-size: 抽出されるファイルの最大サイズを決定します。このパラメータは TPT 抽出には適用されません。max-parallel-extract-threads: この構成は FastExport モードでのみ使用されます。Teradata からデータを抽出するために使用する並列スレッドの数を決定します。このパラメータを調整すると、抽出のパフォーマンスが向上する可能性があります。tpt-template-path: この構成を使用して、カスタム TPT 抽出スクリプトを入力として使用します。このパラメータを使用して、移行データに変換を適用できます。schema-mapping-rule-path: (省略可)デフォルトのマッピング ルールをオーバーライドするスキーマ マッピングを含む構成ファイルのパス。 一部のマッピング タイプは Teradata Parallel Transporter(TPT)モードでのみ機能します。例: Teradata 型
TIMESTAMPから BigQuery 型DATETIMEへのマッピング。{ "rules": [ { "database": { "name": "database.*", "tables": [ { "name": "table.*" } ] }, "match": { "type": "COLUMN_TYPE", "value": "TIMESTAMP" }, "action": { "type": "MAPPING", "value": "DATETIME" } } ] }
属性:
database: (省略可)nameは、含まれるデータベースの正規表現です。デフォルトではすべてのデータベースが含まれます。tables: (省略可)テーブルの配列が含まれます。nameは、含まれるテーブルの正規表現です。デフォルトではすべてのテーブルが含まれています。match: (必須)type: サポートされる値:COLUMN_TYPE。valueサポートされる値:TIMESTAMP、DATETIME。
action: (必須)type: サポートされる値:MAPPING。valueサポートされる値:TIMESTAMP、DATETIME。
compress-output: (省略可)Cloud Storage に保存する前にデータを圧縮するかどうかを指定します。これは tpt-mode にのみ適用されます。 デフォルト値はfalseです。gcs-module-config-dir: (省略可)Cloud Storage バケットにアクセスするための認証情報ファイルのパス。デフォルトのディレクトリは$HOME/.gcsですが、このパラメータを使用してディレクトリを変更できます。gcs-module-connection-count: (省略可)Cloud Storage サービスへの TCP 接続の数を指定します。デフォルト値は 10 です。gcs-module-buffer-size: (省略可) TCP 接続に使用するバッファのサイズを指定します。デフォルトは 8 MB(8,388,608 バイト)です。使いやすさを考慮して、次の乗数を使用できます。k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-buffer-count: (省略可)gcs-module-connection-countで指定された TCP 接続で使用するバッファの数を指定します。Cloud Storage サービスへの TCP 接続数の 2 倍の値を使用することをおすすめします。デフォルト値は 2 *gcs-module-connection-countです。gcs-module-max-object-size: (省略可) このパラメータは、Cloud Storage オブジェクトのサイズを制御します。このパラメータの値は、整数または整数の後にスペースなしで次のいずれかの乗数が続く値になります。k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-writer-instances: (省略可)このパラメータは、Cloud Storage ライター インスタンスの数を指定します。デフォルトでは、値は 1 です。この値を大きくすると、TPT エクスポートの書き込みフェーズでのスループットを増やすことができます。
JDBC ドライバ、移行エージェント、前の初期化ステップで作成した構成ファイルへのパスを指定して、エージェントを実行します。
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=path to configuration file
Unix、Linux、Mac OS
java -cp \ /usr/local/migration/Teradata/JDBC/terajdbc4.jar:mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=config.json
Windows
すべてのファイルを
C:\migrationフォルダにコピーして(またはコマンドのパスを修正して)、次を実行します。java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --configuration-file=config.json
移行を進める準備ができたら、
Enterを押します。初期化中に指定されたクラスパスが有効であれば、エージェントは続行します。プロンプトが表示されたら、データベース接続のユーザー名とパスワードを入力します。ユーザー名とパスワードが有効であれば、データの移行が開始します。
(省略可)移行を開始するコマンドでは、毎回ユーザー名とパスワードを入力する代わりに、認証情報ファイルをエージェントに渡すフラグを使用することもできます。詳しくは、エージェント構成ファイルの省略可能なパラメータ
database-credentials-file-pathをご覧ください。認証情報は暗号化されないため、ローカル ファイル システム上でファイルを保存するフォルダへのアクセスを制限するために適切な措置を講じてください。移行が完了するまで、このセッションを開いたままにしてください。定期的な移行転送を作成した場合は、このセッションを無期限に開いたままにしてください。このセッションが中断すると、現在と将来の転送は失敗します。
エージェントが動作しているかどうかを定期的にモニタリングします。転送の進行中に、24 時間以内にエージェントの応答がない場合、転送は失敗します。
転送の進行中またはスケジュール中に移行エージェントが停止すると、 Google Cloud コンソールにエラーのステータスが表示され、エージェントを再起動するように求められます。移行エージェントを再起動するには、移行エージェントの実行のコマンドを使用して、このセクション(移行エージェントの実行)の最初からやり直します。初期化コマンドを繰り返す必要はありません。転送は、テーブルが完了しなかった時点から再開されます。
- Teradata から BigQuery へのテスト移行を試みます。
- BigQuery Data Transfer Service の詳細を確認する。
- Batch SQL 変換を使用して SQL コードを移行する。
必要な権限を設定する
転送を作成するプリンシパルに、転送ジョブを含むプロジェクトで次のロールがあることを確認します。
データセットの作成
データを保存する BigQuery データセットを作成します。テーブルを作成する必要はありません。
Cloud Storage バケットを作成する
転送ジョブ中にデータをステージングするための Cloud Storage バケットを作成します。
ローカル環境を準備する
このセクションのタスクを完了して、転送ジョブのためのローカル環境を準備します。
ローカルマシンの要件
Teradata 接続の詳細
JDBC ドライバをダウンロードする
Teradata からデータ ウェアハウスに接続できるマシンに terajdbc4.jar JDBC ドライバ ファイルをダウンロードします。
GOOGLE_APPLICATION_CREDENTIALS 変数を設定します。
始める前にセクションでダウンロードしたサービス アカウント キーを環境変数 GOOGLE_APPLICATION_CREDENTIALS に設定します。
VPC Service Controls の下り(外向き)ルールを更新する
BigQuery Data Transfer Service マネージド Google Cloud プロジェクト(プロジェクト番号: 990232121269)を VPC Service Controls の境界の下り(外向き)ルールに追加します。
オンプレミスで実行されているエージェントと BigQuery Data Transfer Service との間の通信チャネルは、転送トピックごとに Pub/Sub メッセージを公開することで行われます。BigQuery Data Transfer Service では、データを抽出するためにコマンドをエージェントに送信する必要があり、エージェントはステータスを更新してデータ抽出のレスポンスを返すために BigQuery Data Transfer Service にメッセージを公開する必要があります。
カスタム スキーマ ファイルを作成する
自動スキーマ検出の代わりにカスタム スキーマ ファイルを使用するには、手動で作成するか、移行エージェントを初期化する際にエージェントに作成させます。
手動でスキーマ ファイルを作成し、 Google Cloud コンソールを使用して転送を作成する場合は、転送に使用する予定のものと同じプロジェクトの Cloud Storage バケットにスキーマ ファイルをアップロードします。
移行エージェントをダウンロードする
データ ウェアハウスに接続できるマシンに移行エージェントをダウンロードします。移行エージェントの JAR ファイルを Teradata JDBC ドライバの JAR ファイルと同じディレクトリに移動します。
アクセス モジュールの認証情報ファイルを設定
抽出に Teradata Parallel Transporter(TPT)ユーティリティで Cloud Storage 用アクセス モジュールを使用する場合は、認証情報ファイルが必要です。
認証情報ファイルを作成する前に、サービス アカウント キーを作成しておく必要があります。ダウンロードしたサービス アカウント キーファイルから、次の情報を取得します。
必要な情報を取得したら、認証情報ファイルを作成します。デフォルトの場所が $HOME/.gcs/credentials の認証情報ファイルの例を次に示します。
[default] gcs_access_key_id = ACCESS_ID gcs_secret_access_key = ACCESS_KEY
次のように置き換えます。
転送を設定する
BigQuery Data Transfer Service で転送を作成します。
カスタム スキーマ ファイルを自動的に作成する場合は、移行エージェントを使用して転送を設定します。
bq コマンドライン ツールを使用してオンデマンド転送を作成できません。 Google Cloud コンソールまたは BigQuery Data Transfer Service API を使用する必要があります。
定期的な転送を作成する場合は、後続の転送からのデータを BigQuery に読み込むときに適切に分割できるようにスキーマ ファイルを指定することを強くおすすめします。スキーマ ファイルがない場合、BigQuery Data Transfer Service は転送されるソースデータからテーブル スキーマを推定し、パーティショニング、クラスタリング、主キー、変更トラッキングに関するすべての情報が失われます。また、初期転送後、その後の転送では以前移行したテーブルをスキップします。スキーマ ファイルの作成方法については、カスタム スキーマ ファイルをご覧ください。
コンソール
bq
bq ツールで Cloud Storage の転送を作成すると、転送構成は 24 時間ごとに繰り返し設定されます。オンデマンド転送では、 Google Cloud コンソールまたは BigQuery Data Transfer Service API を使用します。
bq ツールを使用して通知を構成できません。
bq mk コマンドを入力して、転送作成フラグ --transfer_config を指定します。次のフラグも必要です。
bq mk \ --transfer_config \ --project_id=project ID \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters' \ --data_source=data source
ここで
たとえば、次のコマンドは、Cloud Storage バケット mybucket とターゲット データセット mydataset を使用して、My Transfer という名前の Teradata 転送を作成します。転送は Teradata データ ウェアハウス mydatabase からすべてのテーブルを移行します。オプションのスキーマ ファイルは myschemafile.json です。
bq mk \ --transfer_config \ --project_id=123456789876 \ --target_dataset=MyDataset \ --display_name='My Migration' \ --params='{"bucket": "mybucket", "database_type": "Teradata", "database_name":"mydatabase", "table_name_patterns": ".*", "agent_service_account":"myemail@mydomain.com", "schema_file_path": "gs://mybucket/myschemafile.json", "is_direct_gcs_unload_enabled": true}' \ --data_source=on_premises
コマンドを実行すると、次のようなメッセージが表示されます。
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
指示に従って、認証コードをコマンドラインに貼り付けます。
API
projects.locations.transferConfigs.create メソッドを使用して、TransferConfig リソースのインスタンスを指定します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
移行エージェント
必要に応じて、移行エージェントから直接転送を設定できます。詳細については、移行エージェントを初期化するをご覧ください。
移行エージェントを初期化する
新しい転送用に移行エージェントを初期化する必要があります。初期化は定期的な転送であるかどうかにかかわらず、1 回だけ必要です。初期化は移行エージェントのみを構成します。転送は開始しません。
移行エージェントを使用してカスタム スキーマ ファイルを作成する場合は、転送に使用するプロジェクトと同じ名前の作業ディレクトリの下に書き込み可能ディレクトリがあることを確認してください。これが、移行エージェントがスキーマ ファイルを作成する場所です。たとえば、/home で作業し、プロジェクト myProject で転送を設定する場合、ディレクトリ /home/myProject を作成し、そこにユーザーが書き込み可能であることを確認します。
移行エージェントの構成ファイル
初期化ステップで作成される構成ファイルは次の例のようになります。
{
"agent-id": "81f452cd-c931-426c-a0de-c62f726f6a6f",
"transfer-configuration": {
"project-id": "123456789876",
"location": "us",
"id": "61d7ab69-0000-2f6c-9b6c-14c14ef21038"
},
"source-type": "teradata",
"console-log": false,
"silent": false,
"teradata-config": {
"connection": {
"host": "localhost"
},
"local-processing-space": "extracted",
"database-credentials-file-path": "",
"max-local-storage": "50GB",
"gcs-upload-chunk-size": "32MB",
"use-tpt": true,
"transfer-views": false,
"max-sessions": 0,
"spool-mode": "NoSpool",
"max-parallel-upload": 4,
"max-parallel-extract-threads": 1,
"session-charset": "UTF8",
"max-unload-file-size": "2GB"
}
}
移行エージェント構成ファイルの転送ジョブ オプション
移行エージェントを実行します。
移行エージェントを初期化して構成ファイルを作成したら、次のステップでエージェントを実行し、移行を開始します。
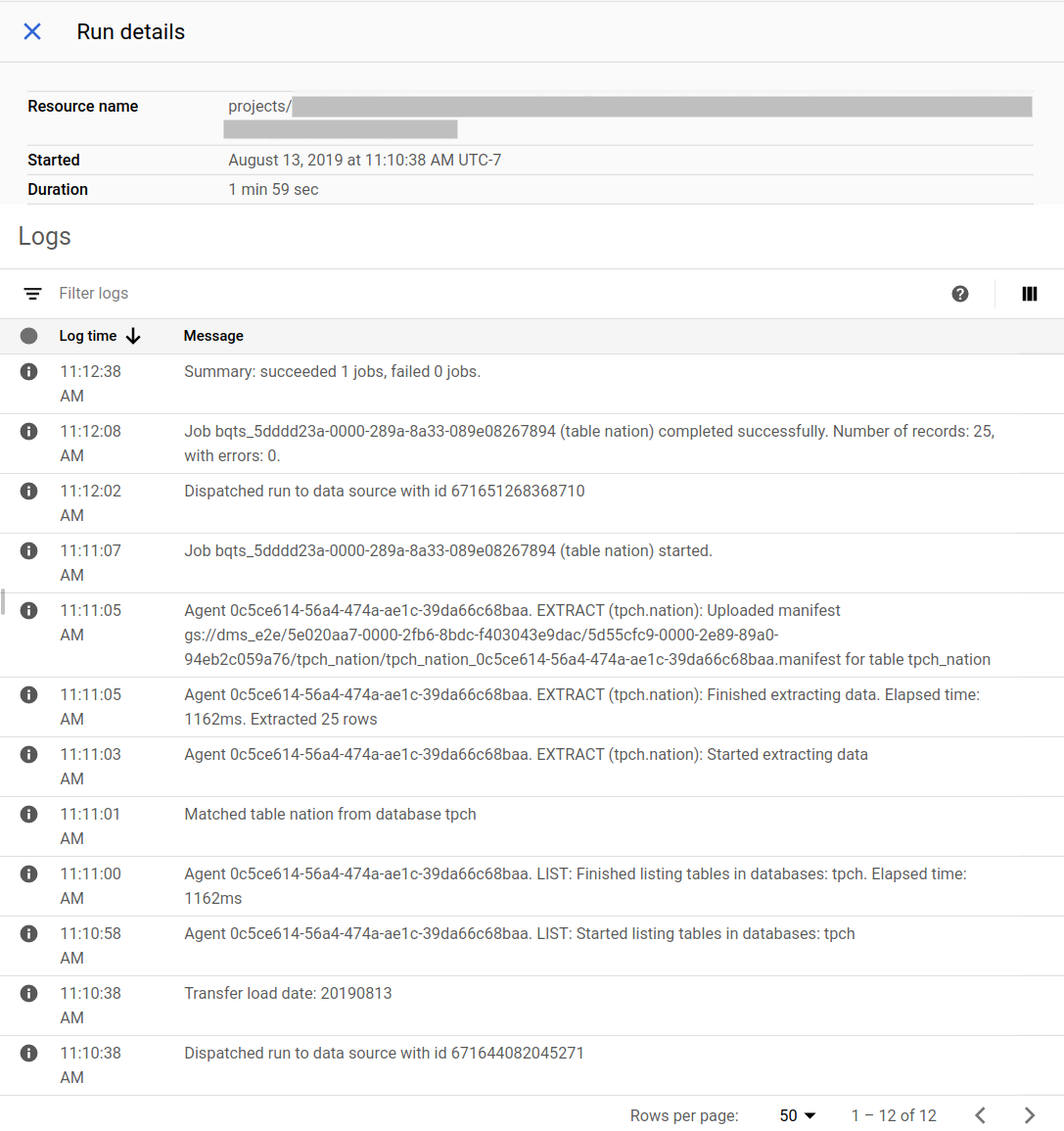
移行の進行状況を追跡する
移行のステータスは Google Cloud コンソールで確認できます。Pub/Sub またはメール通知を設定することもできます。BigQuery Data Transfer Service の通知をご覧ください。
BigQuery Data Transfer Service は、転送構成の作成時に指定されたスケジュールで転送をスケジューリングして開始します。転送がアクティブなときに、移行エージェントが実行されていることが重要です。24 時間以内にエージェント側からの更新がない場合、転送は失敗します。
Google Cloud コンソールの移行ステータスの例:
移行エージェントをアップグレードする
新しいバージョンの移行エージェントが使用可能な場合は、手動で移行エージェントを更新する必要があります。BigQuery Data Transfer Service に関する通知を受け取るには、リリースノートに登録してください。