Ce document explique comment mesurer les performances du système d'inférence TensorFlow que vous avez créé dans la section Déployer un système d'inférence TensorFlow évolutif. Il explique également comment ajuster les paramètres pour améliorer le débit du système.
Le déploiement est basé sur l'architecture de référence décrite dans la section Système d'inférence TensorFlow évolutif.
Cette série est destinée aux développeurs qui connaissent déjà les frameworks de Google Kubernetes Engine et de machine learning (ML), y compris TensorFlow et TensorRT.
Ce document n'a pas pour vocation de fournir les données de performances d'un système particulier. Au lieu de cela, il offre des conseils généraux sur le processus de mesure des performances. Les métriques de performance que vous voyez, telles que le nombre total de requêtes par seconde (RPS) et les temps de réponse (ms), varient en fonction du modèle entraîné, des versions logicielles et des configurations matérielles que vous utilisez.
Architecture
Pour obtenir une vue d'ensemble de l'architecture du système d'inférence TensorFlow, consultez la section Système d'inférence TensorFlow évolutif.
Objectifs
- Définir les objectifs et les métriques de performances
- Mesurer les performances de référence
- Effectuer une optimisation du graphique
- Mesurer la conversion FP16
- Mesurer la quantification INT8
- Ajuster le nombre d'instances
Coûts
Pour en savoir plus sur les coûts associés au déploiement, consultez la section Coûts.
Une fois que vous avez terminé les tâches décrites dans ce document, vous pouvez éviter de continuer à payer des frais en supprimant les ressources que vous avez créées. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
Assurez-vous d'avoir déjà suivi les procédures décrites dans la section Déployer un système d'inférence TensorFlow évolutif.
Dans ce document, vous allez utiliser les outils suivants :
- Un terminal SSH de l'instance de travail que vous avez préparée dans la section Créer un environnement de travail.
- Le tableau de bord Grafana que vous avez préparé à la section Déployer des serveurs de surveillance avec Prometheus et Grafana.
- La console Locust que vous avez préparée dans la section Déployer un outil de test de charge.
Définir le répertoire
Dans la console Google Cloud, accédez à Compute Engine > Instances de VM.
Accéder à la page "Instances de VM"
L'instance
working-vmque vous avez créée s'affiche.Pour ouvrir la console (terminal) de l'instance, cliquez sur SSH.
Dans le terminal SSH, définissez le répertoire actuel sur le sous-répertoire
client:cd $HOME/gke-tensorflow-inference-system-tutorial/clientDans ce document, vous allez exécuter toutes les commandes à partir de ce répertoire.
Définir l'objectif de performances
Lorsque vous mesurez les performances des systèmes d'inférence, vous devez définir l'objectif de performances et les métriques de performances appropriées en fonction du cas d'utilisation du système. À des fins de démonstration, ce document utilise les objectifs de performances suivants :
- Au moins 95 % des requêtes reçoivent des réponses dans un délai de 100 ms.
- Le débit total, représenté par le nombre de requêtes par seconde (RPS), s'améliore sans contrevenir à l'objectif précédent.
En utilisant ces hypothèses, vous mesurez et améliorez le débit des modèles ResNet-50 suivants avec différentes optimisations. Lorsqu'un client envoie des requêtes d'inférence, il spécifie le modèle en utilisant le nom du modèle figurant dans cette table.
| Nom du modèle | Optimisation |
|---|---|
original |
Modèle d'origine (sans optimisation avec TF-TRT) |
tftrt_fp32 |
Optimisation du graphique (taille du lot : 64, groupes d'instances : 1) |
tftrt_fp16 |
Conversion en FP16 en plus de l'optimisation du graphique (taille du lot : 64, groupes d'instances : 1) |
tftrt_int8 |
Quantification avec INT8 en plus de l'optimisation du graphique (taille du lot : 64, groupes d'instances : 1) |
tftrt_int8_bs16_count4 |
Quantification avec INT8 en plus de l'optimisation du graphique (taille du lot : 16, groupes d'instances : 4) |
Mesurer les performances de référence
Vous allez commencer par utiliser TF-TRT comme base pour mesurer les performances du modèle d'origine non optimisé. Vous comparez les performances des autres modèles avec celles des modèles d'origine afin d'évaluer quantitativement l'amélioration des performances. Lorsque vous avez déployé Locust, il était déjà configuré pour envoyer des requêtes pour le modèle d'origine.
Ouvrez la console Locust que vous avez préparée dans la section Déployer un outil de test de charge.
Vérifiez que le nombre de clients (appelés esclaves) est défini sur 10.
Si le nombre est inférieur à 10, les clients démarrent toujours. Dans ce cas, attendez quelques minutes jusqu'à ce qu'il passe à 10.
Mesurez les performances :
- Dans le champ Nombre d'utilisateurs à simuler, saisissez
3000. - Dans le champ Taux d'apparition, saisissez
5. - Pour augmenter le nombre d'utilisations simulées de 5 par seconde jusqu'à 3 000, cliquez sur Démarrer le travail en essaim.
- Dans le champ Nombre d'utilisateurs à simuler, saisissez
Cliquez sur Graphiques.
Les graphiques montrent les résultats des performances obtenues. Notez que si la valeur Nombre total de requêtes par seconde augmente de manière linéaire, la valeur Temps de réponse (ms) augmente de la même façon.
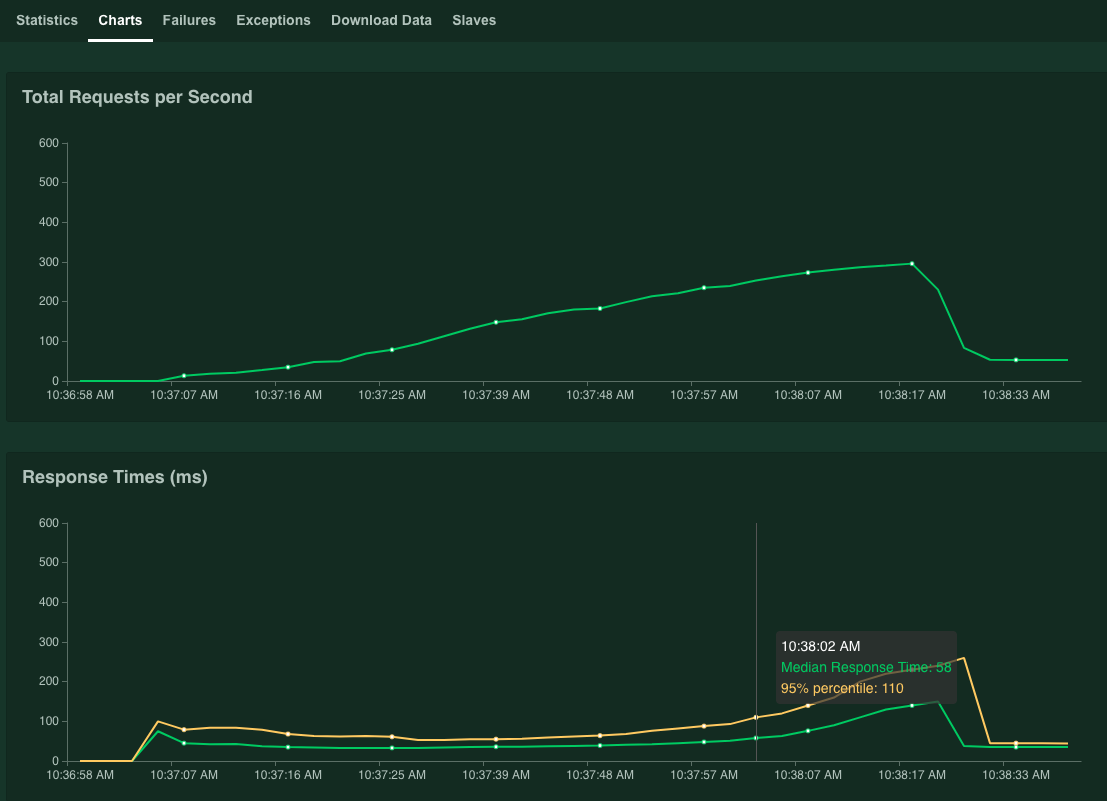
Lorsque la valeur de 95% du temps de réponse dépasse 100 ms, cliquez sur Stop pour arrêter la simulation.
Si vous maintenez le pointeur sur le graphique, vous pouvez vérifier le nombre de requêtes par seconde correspondant aux cas où la valeur de 95 % des centiles des temps de réponse a dépassé 100 ms.
Par exemple, dans la capture d'écran suivante, le nombre de requêtes par seconde est égal à 253,1.

Nous vous recommandons de répéter cette mesure plusieurs fois et de prendre en compte une moyenne pour tenir compte de la fluctuation.
Dans le terminal SSH, redémarrez Locust :
kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustPour répéter la mesure, répétez cette procédure.
Optimiser les graphiques
Dans cette section, vous allez évaluer les performances du modèle tftrt_fp32, qui est optimisé avec TF-TRT pour l'optimisation du graphique. Il s'agit d'une optimisation courante qui est compatible avec la plupart des cartes de GPU NVIDIA.
Dans le terminal SSH, redémarrez l'outil de test de charge :
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp32 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustLa ressource
configmapspécifie le modèle en tant quetftrt_fp32.Redémarrez le serveur Triton :
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Attendez quelques minutes jusqu'à ce que les processus du serveur soient prêts.
Vérifiez l'état du serveur :
kubectl get podsLe résultat ressemble à ce qui suit, où la colonne
READYaffiche l'état du serveur :NAME READY STATUS RESTARTS AGE inference-server-74b85c8c84-r5xhm 1/1 Running 0 46sLa valeur
1/1dans la colonneREADYindique que le serveur est prêt.Mesurez les performances :
- Dans le champ Nombre d'utilisateurs à simuler, saisissez
3000. - Dans le champ Taux d'apparition, saisissez
5. - Pour augmenter le nombre d'utilisations simulées de 5 par seconde jusqu'à 3 000, cliquez sur Démarrer le travail en essaim.
Les graphiques montrent l'amélioration des performances de l'optimisation du graphique TF-TRT.
Par exemple, votre graphique peut indiquer que le nombre de requêtes par seconde est maintenant de 381 avec un temps de réponse médian de 59 ms.
- Dans le champ Nombre d'utilisateurs à simuler, saisissez
Convertir en FP16
Dans cette section, vous allez évaluer les performances du modèle tftrt_fp16, qui est optimisé avec TF-TRT pour l'optimisation du graphique et la conversion FP16. Il s'agit d'une optimisation disponible pour NVIDIA T4.
Dans le terminal SSH, redémarrez l'outil de test de charge :
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp16 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustRedémarrez le serveur Triton :
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Attendez quelques minutes jusqu'à ce que les processus du serveur soient prêts.
Mesurez les performances :
- Dans le champ Nombre d'utilisateurs à simuler, saisissez
3000. - Dans le champ Taux d'apparition, saisissez
5. - Pour augmenter le nombre d'utilisations simulées de 5 par seconde jusqu'à 3 000, cliquez sur Démarrer le travail en essaim.
Les graphiques montrent l'amélioration des performances de la conversion FP16 en plus de l'optimisation du graphique TF-TRT.
Par exemple, votre graphique peut indiquer que le nombre de requêtes par seconde est maintenant de 1072,5 avec un temps de réponse médian de 63 ms.
- Dans le champ Nombre d'utilisateurs à simuler, saisissez
Quantifier avec INT8
Dans cette section, vous allez évaluer les performances du modèle tftrt_int8, qui est optimisé avec TF-TRT pour l'optimisation du graphe et la quantification INT8. Cette optimisation est disponible pour NVIDIA T4.
Dans le terminal SSH, redémarrez l'outil de test de charge :
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustRedémarrez le serveur Triton :
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Attendez quelques minutes jusqu'à ce que les processus du serveur soient prêts.
Mesurez les performances :
- Dans le champ Nombre d'utilisateurs à simuler, saisissez
3000. - Dans le champ Taux d'apparition, saisissez
5. - Pour augmenter le nombre d'utilisations simulées de 5 par seconde jusqu'à 3 000, cliquez sur Démarrer le travail en essaim.
Les graphiques montrent les résultats des performances obtenues.
Par exemple, votre graphique peut indiquer que le nombre de requêtes par seconde est maintenant de 1085,4 avec un temps de réponse médian de 32 ms.
Dans cet exemple, le résultat ne montre pas une augmentation significative des performances par rapport à la conversion FP16. En théorie, le GPU NVIDIA T4 peut gérer les modèles de quantification INT8 plus rapidement que les modèles de conversion FP16. Dans ce cas, le goulot d'étranglement peut être différent des performances des GPU. Vous pouvez le vérifier à partir des données d'utilisation du GPU dans le tableau de bord Grafana. Par exemple, si l'utilisation est inférieure à 40 %, cela signifie que le modèle ne peut pas utiliser pleinement les performances du GPU.
Comme le montre la section suivante, vous pourrez peut-être faciliter ce goulot d'étranglement en augmentant le nombre de groupes d'instances. Par exemple, augmentez le nombre de groupes d'instances de 1 à 4, puis réduisez la taille de lot de 64 à 16. Cette approche conserve le nombre total de requêtes traitées sur un seul GPU à 64.
- Dans le champ Nombre d'utilisateurs à simuler, saisissez
Ajuster le nombre d'instances
Dans cette section, vous allez mesurer les performances du modèle tftrt_int8_bs16_count4. Ce modèle possède la même structure que tftrt_int8, mais vous modifiez la taille de lot et le nombre de groupes d'instances, comme décrit dans la section Quantifier avec INT8.
Dans le terminal SSH, redémarrez Locust :
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8_bs16_count4 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust kubectl scale deployment/locust-slave --replicas=20 -n locustDans cette commande, vous utilisez la ressource
configmappour spécifier le modèle en tant quetftrt_int8_bs16_count4. Vous augmentez également le nombre de pods clients Locust pour générer suffisamment de charges de travail afin de mesurer la limitation des performances du modèle.Redémarrez le serveur Triton :
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Attendez quelques minutes jusqu'à ce que les processus du serveur soient prêts.
Mesurez les performances :
- Dans le champ Nombre d'utilisateurs à simuler, saisissez
3000. - Dans le champ Taux d'apparition, saisissez
15. Pour ce modèle, atteindre la limite de performances peut mettre beaucoup de temps si le taux d'apparition est défini sur5. - Pour augmenter le nombre d'utilisations simulées de 5 par seconde jusqu'à 3 000, cliquez sur Démarrer le travail en essaim.
Les graphiques montrent les résultats des performances obtenues.
Par exemple, votre graphique peut indiquer que le nombre de requêtes par seconde est maintenant de 2236,6 avec un temps de réponse médian de 38 ms.
En ajustant le nombre d'instances, vous pouvez quasiment doubler le nombre de requêtes par seconde. Notez que l'utilisation du GPU a augmenté sur le tableau de bord Grafana (par exemple, l'utilisation peut atteindre 75 %).
- Dans le champ Nombre d'utilisateurs à simuler, saisissez
Performances et nœuds multiples
Lorsque vous effectuez un scaling avec plusieurs nœuds, vous mesurez les performances d'un pod unique. Étant donné que les processus d'inférence sont exécutés indépendamment sur différents pods de manière "sans partage", vous pouvez supposer que le débit total évoluera de manière linéaire avec le nombre de pods. Cette hypothèse s'applique tant qu'il n'existe pas de goulots d'étranglement, tels que la bande passante réseau, entre les clients et les serveurs d'inférence.
Toutefois, il est important de comprendre comment les requêtes d'inférence sont équilibrées entre plusieurs serveurs d'inférence. Triton utilise le protocole gRPC pour établir une connexion TCP entre un client et un serveur. Étant donné que Triton réutilise la connexion établie pour envoyer plusieurs requêtes d'inférence, les requêtes d'un même client sont toujours envoyées au même serveur. Pour distribuer les requêtes sur plusieurs serveurs, vous devez utiliser plusieurs clients.
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cette série soient facturées sur votre compte Google Cloud, vous pouvez supprimer le projet.
Supprimer le projet
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étapes suivantes
- Apprenez-en plus sur la configuration de ressources de calcul pour la prédiction.
- En savoir plus sur Google Kubernetes Engine (GKE).
- En savoir plus sur Cloud Load Balancing.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.