您可以使用 Google Cloud 构建可扩缩、高效且有效的服务,以便向网店中的用户提供相关商品推荐。
电商网站的竞争从未像现在这样激烈。客户的整体消费在上升,但平均花费却在下降。单个购物车的平均规模减小了,部分原因是因为客户只需点点鼠标即可选择其他提供商。而向潜在客户提供相关商品推荐可以在将顾客转化为买家和增加平均订单规模方面发挥核心作用。
阅读此解决方案后,您应该能够根据特定工作负载的需求设置一个支持基本商品推荐引擎的环境,以便您可以发展和改进商品推荐引擎。在 Google Cloud 上运行商品推荐引擎可为您想要的解决方案提供所需的灵活性和可扩缩性。
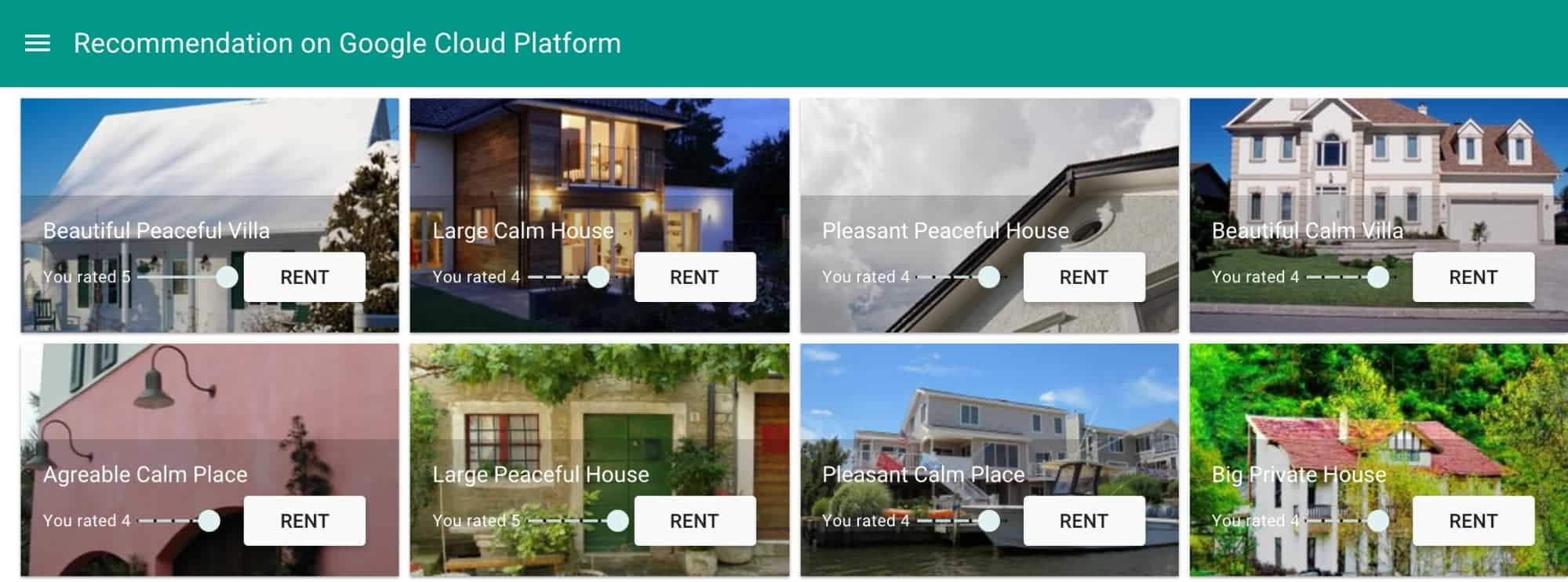
在此解决方案中,您将了解房地产租赁公司如何计算相关商品推荐并将其呈现给正在浏览网站的客户。
使用场景
Samantha 正在寻找一所出租屋以在度假期间暂住。她在度假出租屋网站上已保存过个人资料,之前曾租用并给几个度假出租屋套餐打过分。现在,Samantha 正在根据她的偏好和品味寻找商品推荐,而该系统应该已经知道 Sam 的品味了。显然,根据她的评分页面,她似乎喜欢 house 类型的住宿。因此,系统应该推荐类似的商品。
解决方案概览
为了提供商品推荐,无论是在客户浏览时进行实时响应,还是稍后发送电子邮件,都需要处理若干事项。首先,虽然您对用户的品味和偏好知之甚少,但您可以仅根据商品属性提出推荐。但是,您的系统需要能够向您的用户学习,收集有关他们的品味和偏好的数据。随着时间的推移和收集了足够的数据,您可以使用机器学习算法执行有用的分析并提供有意义的商品推荐。其他用户的输入也可以改善机器学习的结果,使系统能够定期重新训练。该解决方案适合已经具有足够数据、能够从机器学习算法中受益的商品推荐系统。
商品推荐引擎通常通过以下四个阶段处理数据:

下图展示了这种系统的架构:
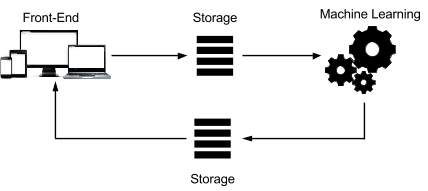
每个步骤都可以自定义以满足要求。该系统包括以下项:
可扩缩的前端,用于记录用户交互以收集数据。
永久性存储区,可由机器学习平台访问。将数据加载到此存储区中涉及到几个步骤,例如导入和导出,以及数据转换。
一个机器学习平台,可以分析现有内容以创建相关商品推荐。
可根据商品推荐的及时性要求,实时或稍后由前端使用的存储。
选择组件
为了在速度、简单性、成本控制和准确性之间取得良好平衡,该解决方案使用了 App Engine、Cloud SQL 和使用 Dataproc 在 App Engine 上运行的 Apache Spark。
App Engine 每秒可处理数万个查询,且几乎不需要管理。无论是创建网站还是将数据保存到后端存储,App Engine 都可以让您编写代码并在几秒钟内将其部署到生产环境中。
此外,Cloud SQL 还提供了简单的部署。例如,Cloud SQL 可以纵向扩容到具有高达 208 GB RAM 的 32 核虚拟机,并且可以按需将存储系统增长到 10 TB、每 GB 30 IOPS 和数千个并发连接。这些规格足以满足此解决方案中的示例,并适用于大量实际的商品推荐引擎。Cloud SQL 还具有可以直接从 Spark 进行访问的优势。
Spark 提供比典型 Hadoop 设置更好的性能,可以比 Hadoop 快 10 到 100 倍。使用 Spark MLlib,您可以在几分钟内分析数亿个评分,从而提高商品推荐的敏捷性,使管理员能够更频繁地运行算法。Spark 尽可能利用内存进行计算,以减少到磁盘的往返。此外,它还试图最小化 I/O。此解决方案使用 Compute Engine 来托管分析基础架构。Compute Engine 可通过每秒按需定价将分析的价格保持在尽可能低的水平。
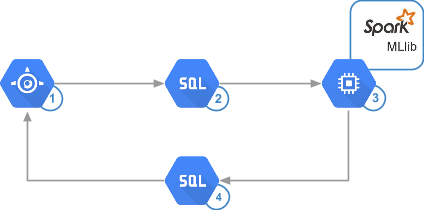
下图映射到先前的架构图,显示了每个步骤使用的技术:
收集数据
商品推荐引擎可以基于用户的隐式行为或其显式输入来收集有关用户的数据。
行为数据易于收集,因为您可以保留用户活动的日志。收集这些数据也很简单,因为它不需要用户做任何额外的操作,他们已经在使用该应用。这种方法的缺点是分析起来比较困难。例如,从不太有用的日志中过滤有用的日志可能很麻烦。
输入数据可能更难收集,因为用户会采取其他操作,例如撰写评论,而且由于各种原因,用户可能不想提供此数据。但是,当涉及到理解用户偏好时,收集的此类结果具有极高的精确度。
存储数据
您为算法提供的数据越多,商品推荐就越好。这意味着任何商品推荐项目都可能在短时间内变成大数据项目。
用于创建商品推荐的数据类型可帮助您确定要使用的存储类型。您可以选择使用 NoSQL 数据库、标准 SQL 数据库、甚至某种对象存储。前述存储方案都是可行的,具体取决于您是捕获用户输入还是行为,以及诸如易于实现、存储系统可以管理的数据量、与环境的其余部分的集成以及可移植性等因素。
在保存用户评分或事件时,可扩缩和托管数据库可最大限度地减少所需的操作任务量,并有助于集中精力在商品推荐上。Cloud SQL 可以满足这两种需求,并且可以直接从 Spark 加载数据。
以下示例代码显示了 Cloud SQL 表的架构。Accommodation 表表示出租物业,而 Rating 表表示用户对特定物业的评分。
CREATE TABLE Accommodation
(
id varchar(255),
title varchar(255),
location varchar(255),
price int,
rooms int,
rating float,
type varchar(255),
PRIMARY KEY (ID)
);
CREATE TABLE Rating
(
userId varchar(255),
accoId varchar(255),
rating int,
PRIMARY KEY(accoId, userId),
FOREIGN KEY (accoId)
REFERENCES Accommodation(id)
);
Spark 可以从各种来源接收数据,例如 Hadoop HDFS 或 Cloud Storage。此解决方案使用 Spark Java 数据库连接 (JDBC) 连接器直接从 Cloud SQL 接收数据。由于 Spark 作业并行运行,因此连接器必须在所有集群实例上可用。
分析数据
设计分析阶段要求您了解应用的要求,这些要求包括:
商品推荐的及时性。例如应用可以提供商品推荐的速度有多快?
数据的过滤方法。例如应用是否仅根据用户的品味进行商品推荐,还是根据其他用户的想法调整数据,或者根据逻辑上适合的商品进行调整?
了解及时性
分析数据时要考虑的第一个因素是您需要多快地向用户提供商品推荐。如果您想立即提供商品推荐,比如当用户正在查看商品时,您将需要更灵活的分析类型,而不是在以后向客户发送包含商品推荐的电子邮件。
实时系统可以在创建数据时对其进行处理。这种类型的系统通常涉及可以处理和分析事件数据流的工具。要提供即时商品推荐,就需要一个实时系统。
批量分析要求您定期处理数据。这种方法意味着需要创建足够的数据以使分析相关,例如每日销售量。另外,批处理系统也适于稍后发送电子邮件的模式。
通过近实时分析,您可以快速收集数据,以便每隔几分钟或几秒钟刷新一次分析。近实时系统适合在同一浏览会话期间提供商品推荐。
商品推荐属于这三个及时性类别之一,要获得一个针对商品推荐的在线销售工具,您可以考虑介于近实时和批处理之间的工具,具体取决于应用获得的流量和用户输入量。运行分析的平台可以直接从保存数据的数据库或定期保存在永久性存储中的转储中运行。
过滤数据
构建商品推荐引擎的核心组件是过滤。最常见的方法包括:
基于内容:一种受欢迎的推荐商品具有与用户看法或喜好类似的属性。
集群:无论用户做了什么,推荐的商品都能很好地协作工作。
协作:其他喜欢这些相同商品并具有相同看法和喜好的用户,也会喜欢推荐的商品。
虽然 Google Cloud 可以支持前述全部方法,但该解决方案侧重于通过使用 Apache Spark 实现的协同过滤。如需了解基于内容的过滤或集群过滤的详细信息,请参阅附录。
通过协作过滤,您可以抽象化商品属性,并根据用户的品味进行预测。此过滤的输出基于这样的假设,即过去喜欢相同商品的两个不同用户现在也可能会喜欢相同的商品。
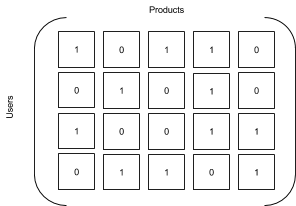
您可以将有关评分或互动的数据表示为一组矩阵,将商品和用户作为维度。协作过滤会尝试预测特定用户 - 商品对的矩阵中的缺失单元格。例如,以下两个矩阵是相似的,但第二个是从第一个矩阵推断出来的,用数字一替换现有的评分,用数字零替换缺失的评分。得出的矩阵是真值表,其中的数字一表示用户与商品的交互。
| 评分矩阵 | 交互矩阵 |
|---|---|
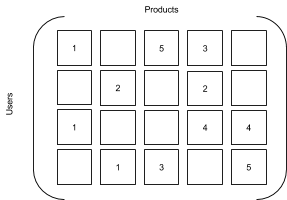 |
 |
可通过以下两种不同的方法部署协同过滤:
基于内存的过滤,用以计算商品或用户之间的相似性。
基于模型的过滤,用以学习能够指示用户如何对商品进行评分和与其交互的基本模式。
此解决方案使用基于模型的方法,在这种方法中,用户对商品进行了评分。
这个解决方案所需的所有分析功能都可以通过 PySpark 获得,它为 Spark 编程语言提供了一个 Python 接口。其他选项则可以使用 Scala 或 Java 获得。如需了解详情,请参阅 Spark 文档。
训练模型
Spark MLlib 实现了交替最小二乘 (ALS) 算法来训练模型。您将使用以下参数的各种组合来获得方差和偏差之间的最佳折衷:
秩:导致用户给出评分的未知因素的数量,可能包括年龄、性别或位置等因素。秩越高,商品推荐在某种程度上就越好。在内存和 CPU 配置允许的情况下,一个良好的做法是从 5 开始并以 5 为增量,直到商品推荐的改进速度减慢。
Lambda:一个正则化参数,用于防止过拟合,由高方差和低偏差表示。方差表示与给定点的理论上正确的值相比,预测在多次运行时在给定点处波动的程度。偏差表示生成的预测与您尝试预测的真实值差距有多大。当模型在使用已知噪声训练数据时运行良好,但在实际测试数据时表现不佳,就会发生过拟合。Lambda 越高,过拟合越低,但偏差越大。值 0.01、1 和 10 都是适合用来测试的值。
下图显示了方差和偏差之间的关系。靶心代表算法用于预测的值。
方差与偏差(最佳值位于左上角) 
迭代:训练运行的次数。在此示例中,您将针对秩和 lambda 的各种组合执行 5 次、10 次和 20 次迭代。
以下示例代码显示如何启动在 Spark 中运行的 ALS 模型训练。
from pyspark.mllib.recommendation import ALS
model = ALS.train(training, rank = 10, iterations = 5, lambda_=0.01)
找到合适的模型
使用 ALS 算法进行的协作过滤基于三个不同的数据集:
训练集:包含已知输出的数据。这套数据看起来是完美的结果。在此解决方案中,它包含用户评分。
验证集:包含有助于调整训练以选择正确的参数组合并选择最佳模型的数据。
测试集:包含将用于评估最佳训练模型的性能的数据。这相当于在实际示例中运行分析。
要找到最佳模型,您需要根据计算的模型、验证集及其大小计算均方根误差 (RMSE)。RMSE 越低,模型越好。
分发商品推荐
要快速轻松地向用户提供结果,您需要将它们加载到可以按需查询的数据库中。同样,Cloud SQL 在这方面也是一个很好的选择。从 Spark 1.4 起,您可以将预测结果直接写入 PySpark 数据库。
Recommendation 表的架构如下所示:
CREATE TABLE Recommendation
(
userId varchar(255),
accoId varchar(255),
prediction float,
PRIMARY KEY(userId, accoId),
FOREIGN KEY (accoId)
REFERENCES Accommodation(id)
);
代码演示
本节将演示用于训练模型的代码。
从 Cloud SQL 获取数据
Spark SQL 上下文使您可以通过 JDBC 连接器轻松连接到 Cloud SQL 实例。加载的数据采用 DataFrame 格式。
将 DataFrame 转换为 RDD 并创建各种数据集
Spark 使用一种称为弹性分布式数据集 (RDD) 的概念,它有助于并行处理各种元素。RDD 是从永久性存储区创建的只读集合。它们可以在内存中进行处理,因此非常适合迭代处理。
回想一下,要获得最佳模型进行预测,您需要将数据集拆分为三个不同的集合。以下代码使用辅助函数,该函数以 60/20/20 百分比为基础随机拆分非重叠值:
基于各种参数训练模型
回想一下,当使用 ALS 方法时,系统需要使用秩、正则化和迭代参数来找到最佳模型。因为存在评分,所以必须将 train 函数的结果与验证集进行比较。您需要确保用户的品味也包含在训练集中。
计算用户的最高预测
现在您有一个可以给出合理预测的模型,您可以根据其他用户的品味和具有相似品味的其他用户的评分,来使用此预测模型查看用户最感兴趣的内容。在此步骤中,您可以看到之前描述的矩阵映射。
保存最高预测
现在您已拥有了包含所有预测的列表,您可以将前 10 个预测保存在 Cloud SQL 中,以便系统可以向用户提供一些商品推荐。例如,在用户登录网站时就可以使用这些预测。
运行解决方案
要运行此解决方案,请按照 GitHub 页面上的分步说明进行操作。按照说明操作,您应该能够计算商品推荐并显示给用户。
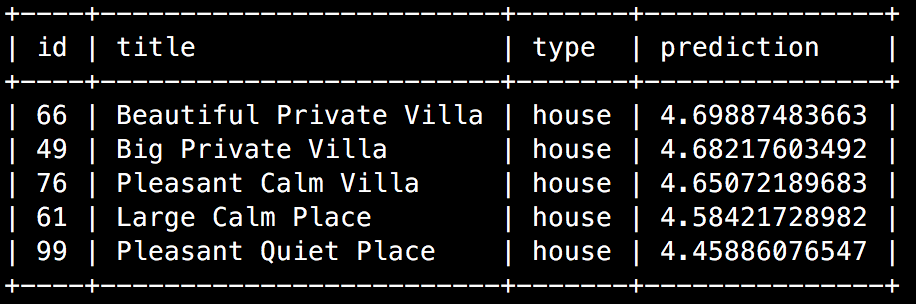
最终的 SQL 代码从数据库中提取最高的商品推荐并将其显示在 Samantha 的欢迎页面上。
在 Google Cloud 控制台或 MySQL 客户端中运行时,查询返回类似于以下示例的结果:
在网站中,相同的查询可以增强欢迎页面并增加将访问者转换为客户的可能性:
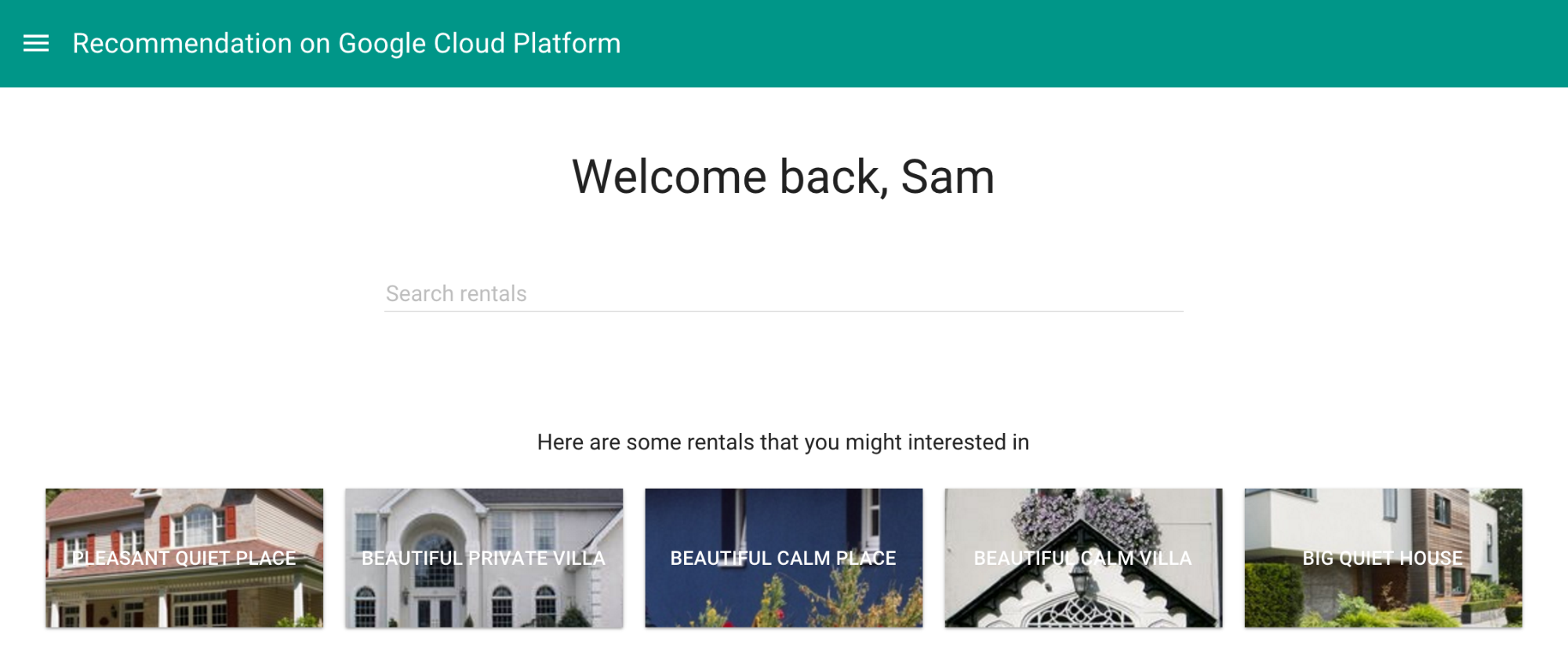
正如场景描述中所讨论的那样,此页面根据系统已经掌握的 Samantha 偏好,显示出 Samantha 所喜欢的内容。
教程
您可以从 GitHub 获取本教程的完整内容,包括设置说明和源代码。
费用
本教程使用 Google Cloud 的以下收费组件:
如需根据您的预计使用量来估算费用,请使用价格计算器。
后续步骤
- 探索有关 Google Cloud 的参考架构、图表、教程和最佳做法。查看我们的 Cloud Architecture Center。
- 了解如何使用 Google Cloud 产品构建端到端解决方案。
- 如需详细了解监控,请参阅输出或网页界面上的 Dataproc 文档。
附录
交叉过滤
虽然您已经了解了如何构建有效且可扩缩的协作过滤解决方案,但将结果与其他类型的过滤相结合可以改进商品推荐。不妨考虑其他两种主要的过滤类型,包括基于内容和集群。组合使用这些方法可以为用户提供更好的商品推荐。
基于内容的过滤
基于内容的过滤直接与商品属性协同工作,并了解它们的相似之处,这有助于为具有属性但用户评分很少的商品创建推荐。随着用户群的增长,即使有大量用户,这种类型的过滤也仍然会处于可管理的范围。
要添加基于内容的过滤,您可以将其他用户以前的评分用于目录中的商品。根据这些评分,您可以找到与当前商品最相似的商品。
计算两个商品之间相似性的一种常用方法是使用余弦相似度并找到最相近的商品:
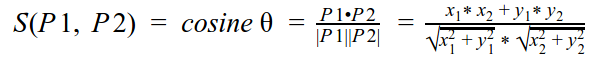

相似性结果将在 0 和 1 之间。越接近 1,商品越相似。

请参考以下矩阵:
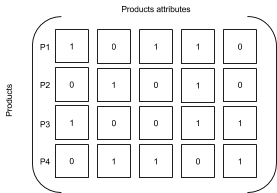
在该矩阵中,P1 和 P2 之间的相似性可以按以下公式进行计算:
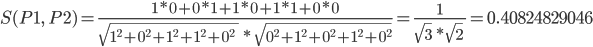
您可以通过各种工具实现基于内容的过滤。如需了解更多信息,请参阅:
Twitter 所有对的相似性。添加到 MLlib 的
CosineSimilaritiesScala 函数可以在 Spark 环境中运行。Mahout。如果要访问更多库以补充或替换某些 MLlib 算法,可以使用
ssh连接到实例或使用初始化操作在 Dataproc 控制器节点(主节点)上安装 Mahout:sudo apt-get update sudo apt-get install mahout -y
聚簇
了解浏览页面的上下文以及用户当前正在查看的内容也很重要。例如,在不同时间浏览页面的同一个人可能对两种完全不同的商品感兴趣,或甚至可能在为他人购买礼物。因此,就必须能够了解哪些商品与当前显示的商品相似。使用 K-mean 集群可以使系统根据其核心属性将类似的商品放入存储分区中。
对于这个解决方案,举个例子,一个想要在伦敦租房子的人可能对目前在奥克兰租房不感兴趣,因此系统应该在做商品推荐时过滤掉这些信息。
from pyspark.mllib.clustering import KMeans, KMeansModel
clusters = KMeans.train(parsedData, 2,
maxIterations=10,
runs=10,
initializationMode="random")
360 度视图
您可以通过纳入其他客户数据来进一步改进商品推荐,例如以往的订单、支持以及年龄、位置或性别等个人属性。这些属性通常可在客户关系管理 (CRM) 或企业资源规划 (ERP) 系统中找到,有助于缩小选择范围。
再深入思考,您会发现不仅内部系统数据会对用户的行为和选择产生影响,外部因素也是一样。在这个解决方案的度假房屋租赁用例中,年轻家庭可能还希望了解当地的空气质量。因此,将基于 Google Cloud 构建的商品推荐引擎与其他 API(如 Breezometer)集成会进一步提升竞争优势。