概要: データ ウェアハウスを BigQuery に移行する
このドキュメントでは、データ ウェアハウジング技術に適用される一般的なコンセプトと、BigQuery への移行の体系化と構造化に使用できるフレームワークについて説明します。
用語
データ ウェアハウスの移行について言及する際に、次の用語を使用します。
- ユースケース
-
ユースケースには、長期にわたるプロダクトの販売量の追跡など、ビジネス価値の実現に必要な、すべてのデータセット、データ処理、およびシステムとユーザーとの間のやり取りが含まれます。データ ウェアハウジングでは、ユースケースは次の要素で構成されます。
- 顧客管理(CRM)データベースなど、さまざまなデータソースから元データを取り込むデータ パイプライン。
- データ ウェアハウスに格納されるデータ。
- データの操作、処理、分析を行うスクリプトとプロシージャ。
- データの読み取りや操作を行うビジネス アプリケーション。
- ワークロード
-
依存関係を共有している一連のユースケース。たとえば、ユースケースには次のような依存関係があります。
- 購入レポートは単独で使用でき、支出の把握や割引のリクエストに役立ちます。
- 販売レポートは単独で使用でき、マーケティング キャンペーンの計画に役立ちます。
- 損益レポートは購入と販売の両方のレポートに依存し、業績の判断に役立ちます。
- ビジネス アプリケーション
- エンドユーザーが対話するシステム(ビジュアル レポートやダッシュボードなど)。ビジネス アプリケーションは、運用データ パイプラインまたはフィードバック ループの形式をとる場合もあります。たとえば、商品価格の変更が計算または予測された後、運用データ パイプラインがトランザクショナル データベースで新しい商品価格を更新します。
- 上流プロセス
- データ ウェアハウスにデータを読み込むソースシステムとデータ パイプライン。
- 下流プロセス
- データ ウェアハウス内のデータの処理、クエリ、可視化に使用されるスクリプト、プロシージャ、ビジネス アプリケーション。
- オフロード移行
-
新しい環境でエンドユーザーのユースケースをできるだけ早く稼働させるための移行方法です。新しい環境で使用できる追加の容量を利用する場合にも、このアプローチを採用できます。ユースケースは次のようにしてオフロードされます。
- 従来のデータ ウェアハウスからスキーマとデータをコピーして同期します。
- 下流のスクリプト、プロシージャ、ビジネス アプリケーションを移行します。
オフロードで移行すると、データ パイプラインの移行が複雑になり、作業が増えることがあります。
- 完全な移行
- オフロード移行と類似した移行アプローチですが、スキーマとデータをコピーして同期するのではなく、上流のソースシステムからデータを直接取り込み、新しいクラウド データ ウェアハウスに移行するように構成します。つまり、ユースケースに必要なデータ パイプラインも移行します。
- エンタープライズ データ ウェアハウス(EDW)
- 分析データベースだけでなく、複数の重要な分析コンポーネントやプロシージャから構成されるデータ ウェアハウス。組織のワークロードを処理するために必要なデータ パイプライン、クエリ、ビジネス アプリケーションなどが含まれます。
- クラウド データ ウェアハウス(CDW)
- EDW と同じ特性を持ち、クラウドのフルマネージド サービス(この場合は BigQuery)で実行されるデータ ウェアハウス。
- データ パイプライン
- さまざまなタイプのデータ変換を実行する一連の機能とタスクにより、データシステムを接続するプロセス。詳細については、このシリーズのデータ パイプラインとはをご覧ください 。
BigQuery に移行する理由
過去数十年にわたり、企業はデータ ウェアハウス技術を発展させてきました。大量の保存データに対して記述的分析を適用し、中核となるビジネス オペレーションに対する知見を得るケースが増えています。クエリ、レポート、オンライン分析処理を中心とする従来のビジネス インテリジェンス(BI)機能は、かつては企業の明暗を分ける差別化要因でしたが、現在ではありふれていてアピール ポイントではなくなっています。
今求められているのは、記述的分析を使用した過去のイベントの把握にとどまらない、予測分析の機能です。予測分析では、データパターンの抽出と将来についての確率論的主張に、機械学習(ML)が用いられることがよくあります。最終的な目標は、過去から得られた情報と、将来に関する予測を組み合わせて、リアルタイムのアクションを自動的に導き出す処方的分析を開発することです。
従来のデータ ウェアハウスでは、オンライン トランザクション処理(OLTP)システムなどのソースから元データを取得します。次に、データのサブセットが抽出され、定義されているスキーマに基づいて変換され、データ ウェアハウスに読み込まれます。従来のデータ ウェアハウスはバッチでデータのサブセットを取得し、柔軟性の低いスキーマに基づいてデータを格納するため、リアルタイム分析の処理や、突発的なクエリには対応できません。このような制約に対処するために、Google は BigQuery を設計しました。
従来のデータ ウェアハウスを実装、維持している IT 組織の規模と複雑さが原因で、革新的なアイデアの実現に時間がかかることがよくあります。スケーラブルで可用性に優れた、安全なデータ ウェアハウス アーキテクチャの構築は何年にも及ぶ場合があり、多額の費用もかかります。BigQuery は、サーバーレスのデータ ウェアハウスの運用に利用できる高度な Software as a Service(SaaS)テクノロジーを提供します。これにより、インフラストラクチャの保守やプラットフォームの開発を Google Cloudに任せて、中核となる業務の促進に専念できます。
BigQuery は、スケーラブルで柔軟性があり、コスト効率に優れた方法で構造化データの格納、処理、分析を行います。データ量が急増した場合は、必要に応じてストレージやリソースを追加できます。また、データに高度な分析を行うこともできます。さらに、ビッグデータ分析や機械学習を始めたばかりの組織や、オンプレミスのビッグデータ システムが複雑になるのを回避したい組織は、BigQuery を従量課金制で利用して、マネージド サービスを試すことができます。
BigQuery を使用すると、以前には解決が困難だった問題も解決できます。機械学習を利用して新たなデータパターンを検出し、新しい仮説をテストすることもできます。その結果、ビジネス パフォーマンスの現状を適時に把握し、成果向上のためにプロセスを変更できるようになります。さらに、このシリーズの後半で説明するように、ビッグデータ分析から収集された関連性の高い分析情報をエンドユーザーに提供できます。
移行の対象と方法: 移行フレームワーク
移行は複雑で時間のかかる作業です。したがって、フレームワークに準拠して移行作業を段階的に行うことをおすすめします。具体的には、次のフェーズで移行作業を行います。
- 準備と発見: ワークロードとユースケースを調査し、移行準備を行います。
- 計画: ユースケースに優先順位を付け、成功指標を定義して移行を計画します。
- 実行: 評価から検証までの移行ステップを繰り返します。
準備と発見
初期段階では、準備と発見が中心になります。これにより、既存のユースケースを発見し、初期段階の懸念事項を早期に見つけることができます。また、期待されるメリットを事前に分析することも重要です。たとえば、パフォーマンスがどのくらい向上するのか(同時実行性の向上など)、総所有コスト(TCO)がどのくらい低減するのかを検討します。このフェーズは、移行のメリットを認識するうえで重要なフェーズとなります。
データ ウェアハウスは通常、幅広いユースケースをサポートします。また、データ アナリストやビジネス意思決定者など多数の関係者が存在します。ユースケースの状況、ユースケースの成果、新しいユースケースの計画の有無を把握する際に、これらのグループの担当者と一緒に検討することをおすすめします。
発見フェーズのプロセスは、次のタスクで構成されます。
- BigQuery の価値提案を検証し、従来のデータ ウェアハウスと比較します。
- 最初の TCO 分析を行います。
- 移行の影響を受けるユースケースを特定します。
- 依存関係を特定するために、移行の基になるデータセットとデータ パイプラインの特徴をモデル化します。
ユースケースを分析するため、アンケートを作成して、SME、エンドユーザー、関係者から情報を収集します。アンケートには次の項目が含まれている必要があります。
- ユースケースの目的、ビジネス上の価値は何か。
- 機能以外の要件はあるか。たとえば、データの最新性、同時使用の有無を考慮する。
- このユースケースは大きなワークロードの一部か。他のユースケースに依存しているか。
- ユースケースの基盤となるデータセット、テーブル、スキーマは何か。
- データ パイプラインがこれらのデータセットに与える影響を認識しているか。
- 現在使用されている BI ツール、レポート、ダッシュボードは何か。
- 運用ニーズ、パフォーマンス、認証、ネットワーク帯域幅に関する現在の技術要件は何か。
次の図は、移行前のアーキテクチャの概要です。使用可能なデータソース、データ パイプライン、運用パイプライン、フィードバック ループ、エンドユーザーがアクセスできる BI レポート、ダッシュボードを示しています。

計画
計画フェーズでは、準備と発見フェーズで得られた結果を評価し、それを使用して移行を計画します。このフェーズは、次のタスクで構成されます。
ユースケースをカタログ化して優先順位を付ける
移行作業をイテレーションに分割することをおすすめします。既存のユースケースと新しいユースケースの両方をカタログ化し、優先順位を割り当てます。詳細については、このドキュメントのイテレーション アプローチを使用した移行とユースケースの優先順序付けのセクションをご覧ください。
成功の指標を定義する
移行を始める前に、重要業績評価指標(KPI)など、明確な成功指標を定義することが重要です。これにより、各イテレーションで移行が成功しているかどうか評価できます。また、後のイテレーションで移行プロセスを改善することもできます。
「完了」の意味を定義する
複雑な移行の場合、特定のユースケースの移行の完了がわかりにくいことがあるため、目的の終了状態を明確に定義しておく必要があります。この定義は、移行するすべてのユースケースに適用できるように一般化しておく必要があります。この定義は、ユースケースを完全に移行するための最小条件のセットとして機能します。この定義には通常、ユースケースの統合、テスト、文書化が行われていることを確認するチェック ポイントを設定する必要があります。
概念実証(POC)、短期間の状態、理想的な終了状態を設計し、提案する
ユースケースの優先順位を決めた後、移行全体について検討します。最初のユースケースの移行を概念実証(POC)として考え、最初の移行アプローチを検証します。最初の数週間から数か月で実現可能なものを短期的な状態として考えます。移行計画がユーザーに与える影響を考慮し、ハイブリッド ソリューションにするのか、それとも一部のユーザーを対象にワークロードを一挙に移行するのかを検討します。
時間と費用の見積もりを作成する
移行プロジェクトを成功させるには、現実的な時間を見積もることが重要です。これを実現するには、すべての関係者と話し合って、プロジェクトに関与できるかどうか、また関与できる場合はその度合いについても確認する必要があります。これにより、人件費をより正確に見積もることができます。予想されるクラウド リソースの消費コストを計算するには、BigQuery ドキュメントのストレージとクエリの費用の見積もりと BigQuery 費用の管理の概要をご覧ください。
移行パートナーを特定して交流する
BigQuery のドキュメントには、移行を実施するために使用できる多くのツールとリソースが記載されています。ただし、事前の経験がない場合や、組織内で必要とされる専門知識が不足している場合は、大規模で複雑な移行を行うことは困難です。そのため、最初に移行パートナーを決めておくことをおすすめします。詳細については、グローバル パートナーとコンサルティング サービス プログラムをご覧ください。
イテレーション アプローチを使用した移行
大規模なデータ ウェアハウジングのオペレーションをクラウドに移行する場合は、イテレーション アプローチを採用することをおすすめします。したがって、BigQuery への移行は、このアプローチで行うことになります。イテレーションで移行の労力を分割することで、プロセス全体が容易になり、リスクが軽減されます。また、イテレーションごとに学習と改善の機会が生まれます。
イテレーションとは、1 つ以上の関連するユースケースをオフロードまたは完全移行するために必要な作業を、一定期間内に繰り返し行うことを指します。イテレーションは、アジャイル手法のスプリント サイクルと考えることができます。イテレーションは 1 つ以上のユーザー ストーリーから構成されます。
トラッキングを容易にするため、個々のユースケースを 1 つ以上のユーザー ストーリーに関連付けてみましょう。たとえば、「価格アナリストが過去 1 年間の商品価格の変動を分析し、将来の価格を計算する」というユーザー ストーリーについて考えてみます。
対応するユースケースは次のようになります。
- 商品や価格を格納するトランザクション データベースからデータを取り込む。
- 取り込んだデータを、商品ごとに 1 つの時系列データに変換し、欠損値があれば入力する。
- データ ウェアハウスの 1 つ以上のテーブルに結果を格納する。
- 結果を Python ノートブック(ビジネス アプリケーション)で利用できるようにする。
このユースケースのビジネス価値は価格分析をサポートすることです。
他のユースケースと同様に、このユースケースは複数のユーザー ストーリーに対応しています。
ユースケースの移行を完成するため、ユースケースをオフロードした後にイテレーションを行います。それ以外の方法では、既存のデータ ウェアハウスへの依存関係が残る可能性があります。データの取得先が既存のデータ ウェアハウスになってしまうからです。その後に続く完全移行は、オフロードと完全移行(オフロードなし)の差分処理になります。具体的には、データ パイプラインを移行してデータ ウェアハウスのデータの抽出、変換、読み込みを行います。
ユースケースの優先順序付け
移行を開始する時点と終了する時点はビジネスニーズによって異なります。クラウドの導入パスで移行を成功させるには、早期の段階で移行に成功することが不可欠なため、ユースケースの移行順序を決めることが重要になります。初期段階で障害が発生すると、全体的な移行プロセスに大幅な遅れが生じる可能性があります。Google Cloud や BigQuery のメリットを活用することもできますが、以前のデータ ウェアハウスで作成または管理されていたさまざまなユースケースのデータセットやデータ パイプラインをすべて処理する作業は複雑で、時間がかかる可能性があります。
すべてのケースに当てはまる対処策はありませんが、オンプレミスのユースケースやビジネス アプリケーションを評価する場合は、ベストプラクティスの使用をおすすめします。このような事前計画により、移行プロセスが容易になり、BigQuery への移行がスムーズになります。
以下では、ユースケースの優先順位を判断する方法について説明します。
アプローチ: 移行の機会を探る
特定のユースケースに対する投資収益率を最大にするため、現在の環境を見直します。クラウドへの移行がビジネスに必要な理由を探している場合、このアプローチが役立ちます。また、移行の総費用を評価するために、データポイントを追加することもできます。
優先順位を付けるユースケースを特定するため、次のような質問に答えてみましょう。
- ユースケースに、従来のエンタープライズ データ ウェアハウスによって制限されているデータセットやデータ パイプラインが存在するか。
- 既存のエンタープライズ データ ウェアハウスで、ハードウェアの更新や拡張が必要かどうか。必要な場合は、すぐにでもユースケースを BigQuery にオフロードできます。
移行の機会を特定することで、ユーザーとビジネスに具体的かつ即時的なメリットが生まれます。
アプローチ: 分析ワークロードを先に移行する
オンライン トランザクション処理(OLTP)ワークロードの前にオンライン分析処理(OLAP)ワークロードを移行します。多くの場合、データ ウェアハウスには組織内で唯一、グローバルな組織ビューの作成に必要なあらゆるデータが格納されています。そのため、一般的に組織は、トランザクション システムへフィードバックするデータ パイプラインを導入し、ステータスの更新やプロセスの起動を行います。たとえば、商品の在庫が少ないときに、在庫を買い入れることができます。OLTP ワークロードは多くの場合、OLAP ワークロードよりも複雑で、より厳密な運用要件とサービスレベル契約(SLA)が適用されるため、OLAP ワークロードを先に移行するほうが容易になる傾向があります。
アプローチ: ユーザー エクスペリエンスを重視する
特定のデータセットを移行し、新しいタイプの高度な分析を行うことで、ユーザー エクスペリエンスを向上させることができます。たとえば、ユーザー エクスペリエンスを向上させる方法としてリアルタイム分析があります。過去のデータとリアルタイムのデータ ストリームを統合することで、洗練されたユーザー エクスペリエンスを構築できます。次に例を示します。
- バックオフィスの従業員に、モバイルアプリで在庫が少なくなっていることを知らせるアラートを送る。
- オンラインのお客様に、あと 1 ドル使えばリワード層がレベルアップすることを知らせる。
- 看護師のスマートウォッチに患者のバイタルサインに関するアラートを送る。これにより、看護師がタブレットで患者の治療歴を取得して最善の処置を施せるようになる。
また、予測分析や処方的分析でユーザー エクスペリエンスを強化することもできます。そのような場合は、BigQuery ML、Vertex AI AutoML 表形式、または Google の画像分析、動画分析、音声認識、自然言語、翻訳向けに Google が事前にトレーニングしたモデルを使用できます。また、ビジネスニーズに合わせたユースケースに対しては、Vertex AI を使用してカスタム トレーニング モデルの構築も可能です。次のようなものがあります。
- 市場動向とユーザーの購入行動に基づいて商品を推薦する。
- フライトの遅延を予測する。
- 不正行為を検出する。
- 不適切なコンテンツを報告する。
- 競合アプリにはない革新的なアイデア。
アプローチ: 最低リスクに基づいてユースケースの優先順位を決める
移行のリスクが最も低いユースケースを評価し、初期段階での移行の最有力候補にすることができます。たとえば、次のような質問に答えてみてください。
- このユースケースのビジネス上の重要性は何か。
- 多くの従業員や顧客がユースケースに依存しているか。
- ユースケースのターゲット環境は何か(開発環境、本番環境など)。
- IT チームはこのユースケースをどの程度理解しているか。
- ユースケースの依存関係と統合の数はどのくらいか。
- Google の IT チームが、ユースケースに関して適切かつ最新の完全なドキュメントを持っているか。
- ユースケースの運用要件(SLA)は何か。
- ユースケースの法的要件や政府のコンプライアンス要件は何か。
- 基礎となるデータセットにアクセスするためのダウンタイムとレイテンシの影響はどの程度か。
- ビジネス オーナーがユースケースの移行を早期に行うことを熱望しているか。
この質問リストを精査することで、データセットとデータ パイプラインのリスクのランク付けを行えます。リスクの低いアセットを先に移行し、リスクの高いアセットは後から移行します。
実行
以前のシステムに関する情報を収集し、ユースケースの優先順位を作成したら、ユースケースをワークロードにグループ化して移行を繰り返します。
イテレーションは、1 つのユースケース、1 つのワークロードに関する複数のユースケース、複数のユースケースで構成されます。イテレーションでどのオプションを使用するかは、ユースケースの相互接続性、共有された依存性、作業に使用できるリソースによって決まります。
通常、移行には次の手順が含まれます。
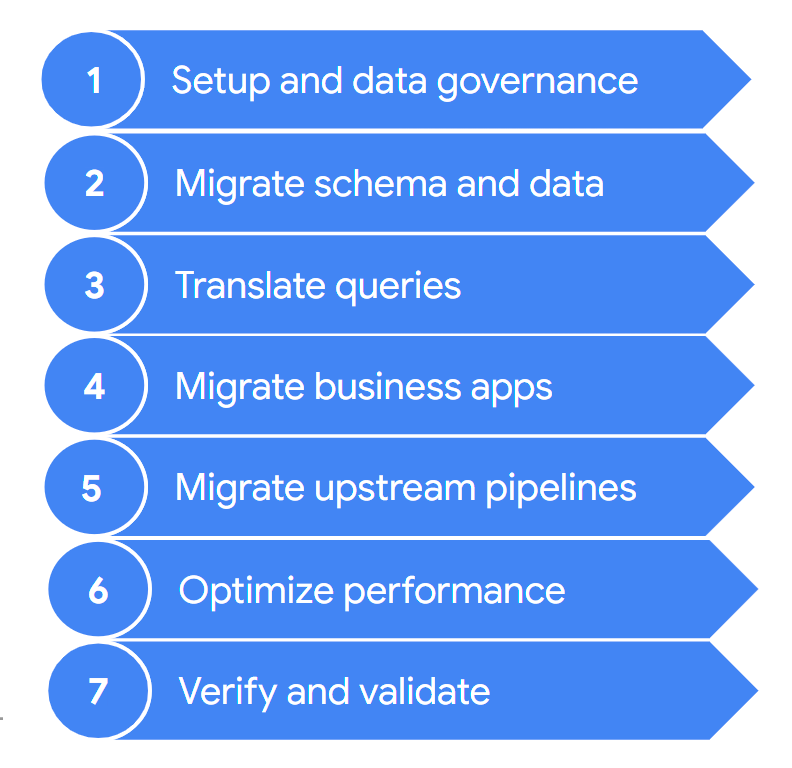
手順については、以降のセクションで詳しく説明します。各イテレーションでこれらのステップをすべて実行しなくてもよい場合もあります。たとえば、あるイテレーションで、以前のデータ ウェアハウスから BigQuery に一部のデータをコピーするとします。一方、このイテレーションでは、取り込みパイプラインを元のデータソースから BigQuery 用に変更することに重点が置かれます。
1. 設定とデータ ガバナンス
セットアップは、 Google Cloudでユースケースを実行するために必要な基本的な作業です。設定には、Google Cloud プロジェクト、ネットワーク、Virtual Private Cloud(VPC)、データ ガバナンスの構成などがあります。現在の状況を把握し、何が効果的かを判断することも含まれます。これは、移行作業の要件を理解するのに役立ちます。BigQuery 移行評価機能を使用することで、このステップをスムーズに行うことができます。
データ ガバナンスは、取得から使用および廃棄に至るまでのライフサイクルにわたって、データを管理するための原則に則ったアプローチです。データ ガバナンス プログラムによって、データ アクティビティに関わるポリシー、手順、責任、制御の概要が明確に示されます。このプログラムによって、情報の収集、維持、使用、配布に際して、組織のデータに関する整合性とセキュリティ ニーズの両方を確実に満たすことができます。また、従業員がデータを探索し、最大限に活用できるようにします。
データ ガバナンスのドキュメントは、オンプレミスのデータ ウェアハウスを BigQuery に移行する際に必要となるデータ ガバナンスと制御について理解するために役立ちます。
2. スキーマとデータの移行
データ ウェアハウスのスキーマは、データの構造化方法とデータ エンティティ間の関係を定義します。スキーマはデータ設計の中核であり、上流と下流の両方で多くのプロセスに影響を及ぼします。
スキーマとデータ移行のドキュメントでは、データを BigQuery に移行する方法が解説されています。また、BigQuery の機能を最大限に活用するにはスキーマの更新が推奨されることについても詳細な情報があります。
3. クエリの変換
バッチ SQL 変換を使用して SQL コードを一括で移行することも、インタラクティブ SQL 変換を使用してアドホック クエリを変換することもできます。
従来のデータ ウェアハウスの中には、SQL 標準の拡張機能が含まれているものがあります。BigQuery は、こうした独自の拡張機能をサポートしていません。代わりに、ANSI / ISO SQL:2011 規格に準拠しています。つまり、SQL トランスレータが解釈できない場合、一部のクエリでは手動のリファクタリングが必要になることがあります。
4. ビジネス アプリケーションの移行
ビジネス アプリケーションには、ダッシュボードからカスタム アプリケーション、トランザクション システムにフィードバック ループを提供する運用データ パイプラインまで、さまざまなものがあります。
BigQuery の操作に関する分析オプションの詳細については、BigQuery 分析の概要をご覧ください。このトピックでは、データから説得力のある分析情報を取得するために使用できるレポート作成ツールと分析ツールの概要について説明します。
データ パイプラインのドキュメントのフィードバック ループ セクションでは、上流のシステムへのフィードバック ループを、データ パイプラインを使用して作成する方法が説明されています。
5. データ パイプラインの移行
データ パイプラインのドキュメントには、以前のデータ パイプラインを Google Cloudに移行するための手順、パターン、技術が記載されています。このドキュメントは、データ パイプラインの概要、データ パイプラインで採用できる手順とパターン、大規模なデータ ウェアハウスの場合に利用できる移行のオプションとテクノロジーを理解するうえで役立ちます。
6. パフォーマンスの最適化
BigQuery は、小規模とペタバイト規模のデータセットのデータを効率的に処理します。BigQuery を使用すると、新しく移行したデータ ウェアハウスでもデータ分析ジョブをそのまま実行できます。特定の状況でクエリのパフォーマンスが期待どおりでない場合は、クエリ パフォーマンスの最適化の概要を参照しガイダンスに従ってください。
7. 確認と検証
それぞれのイテレーションの最後に、次の点を検証して、ユースケースの移行に成功したことを確認します。
- データとスキーマが完全に移行されている。
- データ ガバナンスに関する要件が完全に満たされ、テストされている。
- メンテナンスとモニタリングの手順が確立され、自動化されている。
- クエリが正しく変換されている。
- 移行されたデータ パイプラインが期待どおりに機能している。
- ビジネス アプリケーションが、移行後のデータとクエリにアクセスするように正しく構成されている。
Data Validation Tool を使用できます。このツールは、オープンソースの Python CLI ツールで、移行元と移行先の環境のデータを比較して、一致することを確認します。複数の接続タイプとマルチレベルの検証機能をサポートします。
また、パフォーマンスの改善、コストの削減、新しい技術やビジネス チャンスの獲得など、ユースケースの移行による影響を測定することも重要です。その後、投資収益率をより正確に定量化し、イテレーションの成功基準と比較します。
イテレーションの検証が完了したら、移行したユースケースを本番環境にリリースし、移行したデータセットやビジネス アプリケーションへのアクセス権をユーザーに付与します。
最後に、次のイテレーションの効率と品質が向上するように、今回の教訓を記録して学習します。
移行作業の概要
このドキュメントで説明したように、移行作業は従来のデータ ウェアハウスと BigQuery の両方で行います。次の図は、両方のデータ ウェアハウスが同様の機能とパスを提供することを示しています。どちらもソースシステムからデータを取り込み、ビジネス アプリケーションと連携し、必要なユーザー アクセスを可能にしています。この図では、データ ウェアハウスから BigQuery にデータが同期されている点に注意してください。これにより、移行作業中のユースケースのオフロードが可能になります。

データ ウェアハウスから BigQuery に完全に移行する場合、移行の終了状態は次のようになります。

次のステップ
次のツールを使用して BigQuery の移行を行います。
- 移行評価を実行して、データ ウェアハウスの BigQuery への移行の実現可能性と潜在的なメリットを評価します。
- インタラクティブ SQL トランスレータ、Translation API、バッチ SQL トランスレータなどの SQL 変換ツールを使用して、SQL クエリから GoogleSQL(Gemini 拡張 SQL カスタマイズを含む)への変換を自動化します。
- データ ウェアハウスを BigQuery に移行したら、データ検証ツールを実行して、新しく移行したデータを検証します。
データ ウェアハウスの移行の詳細については、次のリソースをご覧ください。
- Cloud アーキテクチャ センターには、 Google Cloudへの移行を計画して実行するための移行リソースが用意されています。
- データ ウェアハウスからスキーマとデータを移行する方法を学習する
- データ ウェアハウスからデータ パイプラインを移行する方法を学習する
- BigQuery のデータ ガバナンスについて学習する
プロフェッショナル サービス チームと協力して、 Google Cloud 移行の計画とデプロイを支援します。詳細については、Google Cloud プロフェッショナル サービスをご覧ください。
特定のデータ ウェアハウスから BigQuery への移行について学習する: