パーティションとクラスタの推奨事項を管理する
このドキュメントでは、パーティションとクラスタの Recommender の仕組みと、推奨事項と分析情報の表示方法、パーティションとクラスタの推奨事項を適用する方法について説明します。
Recommender の仕組み
BigQuery のパーティショニングとクラスタリングの Recommender は、BigQuery テーブルを最適化するためのパーティションまたはクラスタの推奨事項を生成します。Recommender は、BigQuery テーブルのワークフローを分析し、テーブル パーティショニングまたはテーブル クラスタリングのいずれかを使用してワークフローとクエリの費用を最適化するための推奨事項を提供します。
Recommender サービスの詳細については、Recommender の概要をご覧ください。
パーティショニングとクラスタリングの Recommender は過去 30 日間のプロジェクトのワークロード実行データを使用して、最適ではないパーティショニングとクラスタリングの構成について BigQuery テーブルを分析します。また、Recommender は ML を使用して、異なるパーティショニングまたはクラスタリングの構成でワークロードの実行がどの程度最適化されるかを予測します。Recommender は、テーブルのパーティショニングまたはクラスタリングによって大幅な費用削減が見込めると判断した場合、推奨事項を生成します。パーティショニングとクラスタリングの Recommender では、次のタイプの推奨事項が生成されます。
| 既存のテーブルタイプ | 推奨事項サブタイプ | 推奨事項の例 |
|---|---|---|
| パーティション分割なし、クラスタ化なし | パーティション | 「column_C を DAY でパーティショニングすることで、毎月約 64 スロット時間を削減する」 |
| パーティション分割なし、クラスタ化なし | クラスタ | 「column_C でクラスタリングすることで、毎月約 64 スロット時間を削減する」 |
| パーティション分割、クラスタ化なし | クラスタ | 「column_C でクラスタリングすることで、毎月約 64 スロット時間を削減する」 |
それぞれの推奨事項は、次の 3 つの部分で構成されています。
- 特定のテーブルをパーティショニングまたはクラスタリングを行うためのガイダンス
- パーティショニングまたはクラスタリングを行うテーブル内の特定の列
- 推奨事項の適用による毎月の推定削減額
Recommender は、潜在的なワークロード削減額を計算するために、過去 30 日間の実行ワークロード データが将来のワークロードを表すことを前提としています。
また、Recommender API は、テーブル ワークロード情報を分析情報の形式で返します。分析情報は、プロジェクトのワークロードの理解に役立つ検出結果であり、パーティションまたはクラスタの推奨事項によってワークロードの費用がどのように改善されるかに関するより多くのコンテキストを提供します。
制限事項
パーティショニングとクラスタリングの Recommender は、レガシー SQL を使用した BigQuery テーブルをサポートしていません。Recommender は、推奨事項を生成するときに、分析でレガシー SQL クエリを除外します。また、レガシー SQL を使用して BigQuery テーブルにパーティションの推奨事項を適用すると、そのテーブル内のレガシー SQL ワークフローがすべて機能しなくなります。
パーティションの推奨事項を適用する前に、レガシー SQL ワークフローを GoogleSQL に移行してください。
BigQuery では、テーブルのパーティショニング スキームの変更はサポートされていません。テーブルのパーティショニングを変更できるのは、テーブルのコピーに対してのみです。詳細については、パーティションの推奨事項を適用するをご覧ください。
ロケーション
パーティショニングとクラスタリングの Recommender は、次の処理ロケーションで使用できます。
| リージョンの説明 | リージョン名 | 詳細 | |
|---|---|---|---|
| アジア太平洋 | |||
| デリー | asia-south2 |
||
| 香港 | asia-east2 |
||
| ジャカルタ | asia-southeast2 |
||
| ムンバイ | asia-south1 |
||
| 大阪 | asia-northeast2 |
||
| ソウル | asia-northeast3 |
||
| シンガポール | asia-southeast1 |
||
| シドニー | australia-southeast1 |
||
| 台湾 | asia-east1 |
||
| 東京 | asia-northeast1 |
||
| ヨーロッパ | |||
| ベルギー | europe-west1 |
|
|
| ベルリン | europe-west10 |
|
|
| EU(マルチリージョン) | eu |
||
| フランクフルト | europe-west3 |
||
| ロンドン | europe-west2 |
|
|
| オランダ | europe-west4 |
|
|
| チューリッヒ | europe-west6 |
|
|
| 南北アメリカ | |||
| アイオワ | us-central1 |
|
|
| ラスベガス | us-west4 |
||
| ロサンゼルス | us-west2 |
||
| モントリオール | northamerica-northeast1 |
|
|
| バージニア州北部 | us-east4 |
||
| オレゴン | us-west1 |
|
|
| ソルトレイクシティ | us-west3 |
||
| サンパウロ | southamerica-east1 |
|
|
| トロント | northamerica-northeast2 |
|
|
| 米国(マルチリージョン) | us |
||
始める前に
必要な権限
パーティションとクラスタの推奨事項にアクセスするために必要な権限を取得するには、BigQuery パーティショニング クラスタリング Recommender 閲覧者(roles/recommender.bigqueryPartitionClusterViewer)の IAM ロールを付与するよう管理者に依頼してください。ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
この事前定義ロールには、パーティションとクラスタの推奨事項にアクセスするために必要な権限が含まれています。必要とされる正確な権限については、「必要な権限」セクションを開いてご確認ください。
必要な権限
パーティションとクラスタの推奨事項にアクセスするには、次の権限が必要です。
-
recommender.bigqueryPartitionClusterRecommendations.get -
recommender.bigqueryPartitionClusterRecommendations.list
カスタムロールや他の事前定義ロールを使用して、これらの権限を取得することもできます。
BigQuery における IAM ロールと権限の詳細については、IAM の概要をご覧ください。
推奨事項を表示する
このセクションでは、 Google Cloud コンソール、Google Cloud CLI、Recommender API を使用して、パーティションとクラスタの推奨事項と分析情報を表示する方法について説明します。
次のオプションのいずれかを選択します。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
ナビゲーション メニューで [推奨事項] をクリックします。
[推奨事項] タブには、プロジェクトで利用できるすべての推奨事項が一覧表示されます。
[BigQuery ワークロード費用の最適化] パネルで、[すべて表示] をクリックします。
費用の推奨事項の表には、現在のプロジェクトに対して生成されたすべての推奨事項が一覧表示されます。たとえば、次のスクリーンショットでは、Recommender が
example_tableテーブルを分析し、example_column列をクラスタリングすれば、表示された程度のバイト数とスロット数を節約できると推奨しています。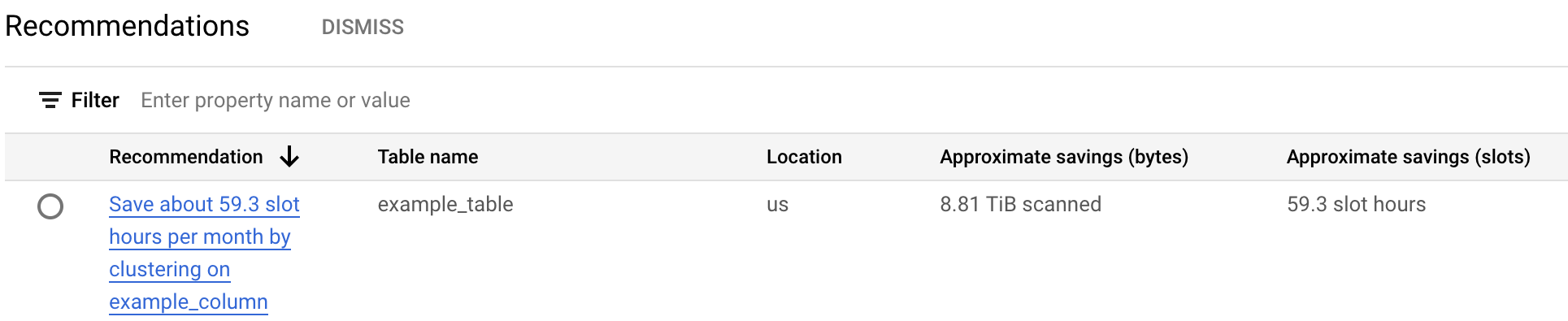
テーブルの分析情報と推奨事項の詳細を表示するには、[推奨事項] をクリックします。
gcloud
特定のプロジェクトのパーティションまたはクラスタの推奨事項を表示するには、gcloud recommender recommendations list コマンドを使用します。
gcloud recommender recommendations list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--recommender=google.bigquery.table.PartitionClusterRecommender \
--format=FORMAT_TYPE \
次のように置き換えます。
PROJECT_NAME: BigQuery テーブルを含むプロジェクトの名前REGION_NAME: プロジェクトが存在するリージョンFORMAT_TYPE: サポートされている gcloud CLI 出力形式(例えば、JSON)
| プロパティ | サブタイプに関連 | 説明 |
|---|---|---|
recommenderSubtype |
パーティションまたはクラスタ | 推奨の種類を示します。 |
content.overview.partitionColumn |
パーティション | パーティショニングを推奨する列の名前。 |
content.overview.partitionTimeUnit |
パーティション | 推奨されるパーティショニングの時間単位。たとえば、DAY は、該当の列を日単位でパーティショニングすることが推奨されていることを意味します。 |
content.overview.clusterColumns |
クラスタ | クラスタリングを推奨する列の名前。 |
- Recommender のレスポンス内の他のフィールドの詳細については、REST Resource:
projects.locations.recommendersrecommendationをご覧ください。 - Recommender API の使用の詳細については、API の使用 - 推奨事項をご覧ください。
gcloud CLI を使用してテーブルの分析情報を表示するには、gcloud recommender insights list コマンドを使用します。
gcloud recommender insights list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--insight-type=google.bigquery.table.StatsInsight \
--format=FORMAT_TYPE \
次のように置き換えます。
PROJECT_NAME: BigQuery テーブルを含むプロジェクトの名前REGION_NAME: プロジェクトが存在するリージョンFORMAT_TYPE: サポートされている gcloud CLI 出力形式(例えば、JSON)
| プロパティ | サブタイプに関連 | 説明 |
|---|---|---|
content.existingPartitionColumn |
クラスタ | 既存のパーティショニング列(存在する場合) |
content.tableSizeTb |
すべて | テーブルのサイズ(テラバイト単位) |
content.bytesReadMonthly |
すべて | テーブルから読み取られた月間のバイト数 |
content.slotMsConsumedMonthly |
すべて | テーブルで実行されているワークロードが消費した月間のスロット時間(ミリ秒単位) |
content.queryJobsCountMonthly |
すべて | テーブルで実行されている月間のジョブ数 |
- 分析情報のレスポンス内の他のフィールドの詳細については、REST Resource:
projects.locations.insightTypes.insightsをご覧ください。 - 分析情報の使用について詳しくは、API の使用 - 分析情報をご覧ください。
REST API
特定のプロジェクトに関するパーティションまたはクラスタの推奨事項を表示するには、REST API を使用します。各コマンドに認証トークンを指定する必要があります。これは gcloud CLI を使用して取得できます。認証トークンの取得方法については、ID トークンの取得方法をご覧ください。
curl list リクエストを使用して、特定のプロジェクトのすべての推奨事項を表示できます。
curl
-H "Authorization: Bearer $GCLOUD_AUTH_TOKEN"
-H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/recommenders/google.bigquery.table.PartitionClusterRecommender/recommendations
次のように置き換えます。
GCLOUD_AUTH_TOKEN: 有効な gcloud CLI アクセス トークンの名前PROJECT_NAME: BigQuery テーブルを含むプロジェクトの名前
| プロパティ | サブタイプに関連 | 説明 |
|---|---|---|
recommenderSubtype |
パーティションまたはクラスタ | 推奨の種類を示します。 |
content.overview.partitionColumn |
パーティション | パーティショニングを推奨する列の名前。 |
content.overview.partitionTimeUnit |
パーティション | 推奨されるパーティショニングの時間単位。たとえば、DAY は、該当の列を日単位でパーティショニングすることが推奨されていることを意味します。 |
content.overview.clusterColumns |
クラスタ | クラスタリングを推奨する列の名前。 |
- Recommender のレスポンス内の他のフィールドの詳細については、REST Resource:
projects.locations.recommendersrecommendationをご覧ください。 - Recommender API の使用の詳細については、API の使用 - 推奨事項をご覧ください。
REST API を使用してテーブルの分析情報を表示するには、次のコマンドを実行します。
curl -H "Authorization: Bearer $GCLOUD_AUTH_TOKEN" -H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/insightTypes/google.bigquery.table.StatsInsight/insights
次のように置き換えます。
GCLOUD_AUTH_TOKEN: 有効な gcloud CLI アクセス トークンの名前PROJECT_NAME: BigQuery テーブルを含むプロジェクトの名前
| プロパティ | サブタイプに関連 | 説明 |
|---|---|---|
content.existingPartitionColumn |
クラスタ | 既存のパーティショニング列(存在する場合) |
content.tableSizeTb |
すべて | テーブルのサイズ(テラバイト単位) |
content.bytesReadMonthly |
すべて | テーブルから読み取られた月間のバイト数 |
content.slotMsConsumedMonthly |
すべて | テーブルで実行されているワークロードが消費した月間のスロット時間(ミリ秒単位) |
content.queryJobsCountMonthly |
すべて | テーブルで実行されている月間のジョブ数 |
- 分析情報のレスポンス内の他のフィールドの詳細については、REST Resource:
projects.locations.insightTypes.insightsをご覧ください。 - 分析情報の使用について詳しくは、API の使用 - 分析情報をご覧ください。
クラスタの推奨事項を適用する
クラスタの推奨事項を適用するには、次のいずれかを行います。
クラスタを元のテーブルに直接適用する
クラスタの推奨事項は、既存の BigQuery テーブルに直接適用できます。この方法は、コピーしたテーブルに推奨事項を適用するよりも迅速ですが、バックアップ テーブルは保持されません。
パーティション分割されていないテーブルまたはパーティション分割テーブルに新しいクラスタリング仕様を適用する手順は次のとおりです。
bq ツールで、新しいクラスタリングと一致するようにテーブルのクラスタリング仕様を更新します。
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
次のように置き換えます。
CLUSTER_COLUMN: クラスタリングする列(例:mycolumn)DATASET: テーブルを含むデータセットの名前(例:mydataset)ORIGINAL_TABLE: 元のテーブルの名前(例:mytable)
tables.updateまたはtables.patchの API メソッドを呼び出して、クラスタリング仕様を変更することもできます。新しいクラスタリング仕様に従ってすべての行をクラスタ化するには、次の
UPDATEステートメントを実行します。UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
コピーしたテーブルにクラスタを適用する
BigQuery テーブルにクラスタの推奨事項を適用するときに、まず元のテーブルをコピーしてから、コピーしたテーブルに推奨事項を適用します。この方法では、変更をクラスタリング構成にロールバックする必要がある場合に、元のデータが確実に保持されます。
この方法を使用すると、パーティション分割されていないテーブルとパーティション分割されたテーブルの両方にクラスタの推奨事項を適用できます。
Google Cloud コンソールで、[BigQuery] ページに移動します。
Query Editor で、
LIKE演算子を使用して、元のテーブルと同じメタデータ(クラスタリング仕様を含む)を含む空のテーブルを作成します。CREATE TABLE DATASET.COPIED_TABLE LIKE DATASET.ORIGINAL_TABLE
次のように置き換えます。
DATASET: テーブルを含むデータセットの名前(例:mydataset)COPIED_TABLE: コピーしたテーブルの名前(例:copy_mytable)ORIGINAL_TABLE: 元のテーブルの名前(例:mytable)
Google Cloud コンソールで、Cloud Shell エディタを開きます。
Cloud Shell エディタで、
bq updateコマンドを使用して、コピーしたテーブルのクラスタリング仕様を推奨されたクラスタリングと一致するように更新します。bq update --clustering_fields=CLUSTER_COLUMN DATASET.COPIED_TABLE
CLUSTER_COLUMNは、クラスタリングする列(例えば、mycolumn)に置き換えます。tables.updateまたはtables.patchの API メソッドを呼び出して、クラスタリング仕様を変更することもできます。パーティショニングまたはクラスタリングが存在する場合は、クエリエディタで、元のテーブルのパーティショニングとクラスタリングの構成を使用してテーブル スキーマを取得します。スキーマを取得するには、元のテーブルの
INFORMATION_SCHEMA.TABLESビューを表示します。SELECT ddl FROM DATASET.INFORMATION_SCHEMA.TABLES WHERE table_name = 'DATASET.ORIGINAL_TABLE;'
出力は、
PARTITION BY句を含む ORIGINAL_TABLE の完全なデータ定義言語(DDL)ステートメントです。DDL 出力の引数の詳細については、CREATE TABLEステートメントをご覧ください。DDL 出力には、元のテーブルのパーティショニング タイプが表示されます。
パーティショニング タイプ 出力の例 パーティション分割なし PARTITION BY句が存在しない。テーブル列によるパーティション分割 PARTITION BY c0PARTITION BY DATE(c0)PARTITION BY DATETIME_TRUNC(c0, MONTH)取り込み時間によるパーティション分割 PARTITION BY _PARTITIONDATEPARTITION BY DATETIME_TRUNC(_PARTITIONTIME, MONTH)コピーしたテーブルにデータを取り込みます。使用するプロセスは、パーティション タイプに従って決まります。
- 元のテーブルがパーティション分割されていないか、テーブル列によってパーティション分割されている場合は、元のテーブルからコピーしたテーブルにデータを取り込みます。
INSERT INTO DATASET.COPIED_TABLE SELECT * FROM DATASET.ORIGINAL_TABLE
元のテーブルが取り込み時間によってパーティション分割されている場合は、次の手順に沿って操作します。
INFORMATION_SCHEMA.COLUMNSビューを使用して、データ取り込み式を形成する列のリストを取得します。SELECT ARRAY_TO_STRING(( SELECT ARRAY( SELECT column_name FROM DATASET.INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'ORIGINAL_TABLE')), ", ")
出力は、列名のカンマ区切りのリストです。
元のテーブルからコピーされたテーブルにデータを取り込みます。
INSERT DATASET.COPIED_TABLE (COLUMN_NAMES, _PARTITIONTIME) SELECT *, _PARTITIONTIME FROM DATASET.ORIGINAL_TABLE
COLUMN_NAMESは、前のステップの出力である列のカンマ区切りのリスト(たとえば、col1, col2, col3)に置き換えます。
これで、元のテーブルと同じデータを含むクラスタ化されたテーブルが作成されました。次のステップでは、元のテーブルを新しいクラスタ化テーブルに置き換えます。
- 元のテーブルがパーティション分割されていないか、テーブル列によってパーティション分割されている場合は、元のテーブルからコピーしたテーブルにデータを取り込みます。
元のテーブルの名前をバックアップ テーブルに変更します。
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
BACKUP_TABLEは、バックアップ テーブルの名前(たとえば、backup_mytable)に置き換えます。コピーされたテーブルの名前を元のテーブルに変更します。
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
これで、元のテーブルがクラスタの推奨事項に従ってクラスタ化されました。
- IAM 権限、行レベルのアクセス、列レベルのアクセスなどのアクセスと権限。
- テーブル クローン、テーブル スナップショット、検索インデックスなどのテーブル アーティファクト。
- マテリアライズド ビューやテーブルをコピーした際に実行されたジョブなど、進行中のテーブル プロセスのステータス。
- タイムトラベルを使用して過去のテーブルデータにアクセスする能力。
- 元のテーブルに関連付けられているメタデータ(例:
table_option_list、column_option_list)。詳細については、データ定義言語ステートメントをご覧ください。
問題が発生した場合は、影響を受けるアーティファクトを新しいテーブルに手動で移行する必要があります。
クラスタ化テーブルを確認したら、必要に応じて、次のコマンドでバックアップ テーブルを削除できます。DROP TABLE DATASET.BACKUP_TABLE
マテリアライズド ビューでクラスタを適用する
テーブルのマテリアライズド ビューを作成して、推奨事項が適用された元のテーブルのデータを保存できます。マテリアライズド ビューを使用して推奨事項を適用することで、クラスタ化されたデータを自動更新によって常に最新の状態に保つことができます。マテリアライズド ビューをクエリ、管理、保存する場合は、料金に関する考慮事項があります。クラスタ化されたマテリアライズド ビューの作成方法については、クラスタ化されたマテリアライズド ビューをご覧ください。パーティションの推奨事項を適用する
パーティションの推奨事項を適用するには、元のテーブルのコピーに適用する必要があります。BigQuery では、テーブルのパーティショニング スキーマの変更はサポートされていません。たとえば、パーティション分割されていないテーブルをパーティション分割テーブルに変更すること、テーブルのパーティショニング スキーマを変更すること、ベーステーブルとは異なるパーティショニング スキーマを使用してマテリアライズド ビューを作成することはできません。テーブルのパーティショニングを変更できるのは、テーブルのコピーに対してのみです。
コピーしたテーブルにパーティションの推奨事項を適用する
BigQuery テーブルにパーティションの推奨事項を適用するときは、まず元のテーブルをコピーしてから、コピーしたテーブルに推奨事項を適用します。このアプローチにより、パーティションをロールバックする必要がある場合に、元のデータが保持されます。
次の手順では、推奨事項の例を使用して、パーティション時間単位 DAY でテーブルをパーティション分割します。
パーティションの推奨事項を使用して、テーブルのコピーを作成します。
CREATE TABLE DATASET.COPIED_TABLE PARTITION BY DATE_TRUNC(PARTITION_COLUMN, DAY) AS SELECT * FROM DATASET.ORIGINAL_TABLE
次のように置き換えます。
DATASET: テーブルを含むデータセットの名前(例:mydataset)COPIED_TABLE: コピーしたテーブルの名前(例:copy_mytable)PARTITION_COLUMN: パーティショニングする列(例:mycolumn)
パーティション分割テーブルの作成の詳細については、パーティション分割テーブルの作成をご覧ください。
元のテーブルの名前をバックアップ テーブルに変更します。
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
BACKUP_TABLEは、バックアップ テーブルの名前(たとえば、backup_mytable)に置き換えます。コピーされたテーブルの名前を元のテーブルに変更します。
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
これで、元のテーブルがパーティションの推奨事項に従ってパーティション分割されました。
- IAM 権限、行レベルのアクセス、列レベルのアクセスなどのアクセスと権限。
- テーブル クローン、テーブル スナップショット、検索インデックスなどのテーブル アーティファクト。
- マテリアライズド ビューやテーブルをコピーした際に実行されたジョブなど、進行中のテーブル プロセスのステータス。
- タイムトラベルを使用して過去のテーブルデータにアクセスする能力。
- 元のテーブルに関連付けられているメタデータ(例:
table_option_list、column_option_list)。詳細については、データ定義言語ステートメントをご覧ください。 - レガシー SQL を使用して、クエリ結果をパーティション分割テーブルに書き込む能力。レガシー SQL はパーティション分割テーブルでは完全にはサポートされていません。この解決策の一つは、パーティションの推奨事項の適用前に、レガシー SQL ワークフローを GoogleSQL に移行することです。
問題が発生した場合は、影響を受けるアーティファクトを新しいテーブルに手動で移行する必要があります。
パーティション分割テーブルを確認したら、必要に応じて、次のコマンドでバックアップ テーブルを削除できます。DROP TABLE DATASET.BACKUP_TABLE
料金
テーブルに推奨事項を適用すると、次の費用が発生する可能性があります。
- 処理費用。推奨事項を適用する際は、BigQuery プロジェクトにデータ定義言語(DDL)クエリまたはデータ操作言語(DML)クエリを実行します。
- ストレージの費用。テーブルをコピーする場合は、コピーした(またはバックアップの)テーブル用に追加のストレージを使用します。
標準の処理料金とストレージ料金が、プロジェクトに関連付けられた請求先アカウントに応じて適用されます。詳細については、BigQuery の料金をご覧ください。
トラブルシューティング
問題: 特定のテーブルに対する推奨事項が表示されない。
次の条件を満たすテーブルには、パーティションの推奨事項が表示されないことがあります。
- テーブルが 100 GB 未満。
- テーブルがすでにパーティション分割またはクラスタ化されている。
次の条件を満たすテーブルには、クラスタの推奨事項が表示されないことがあります。
- テーブルが 10 GB 未満。
- テーブルがすでにクラスタ化されている。
次のような場合は、パーティションとクラスタの推奨事項の両方が抑制されることがあります。
- データ操作言語(DML)オペレーションによるテーブルの書き込みコストが高い。
- テーブルが過去 30 日間読み取られていない。
- 1 か月あたりの推定削減額が少なすぎる(1 スロット時間未満の削減)。