BigQuery データ キャンバスで分析する
このドキュメントでは、データ分析にデータ キャンバスを使用する方法について説明します。Dataplex Universal Catalog を使用してデータ キャンバスのメタデータを管理することもできます。
BigQuery Studio データ キャンバス(Gemini in BigQuery の機能)では、自然言語プロンプトと分析ワークフローのグラフィック インターフェースを使用して、データの検索、変換、クエリ、可視化を行うことができます。
分析ワークフローについて、BigQuery データ キャンバスは有向非巡回グラフ(DAG)を使用して、ワークフローのグラフィカルなビューを提供します。BigQuery データ キャンバスでは、クエリ結果を反復処理して、1 か所で複数の質問分岐を操作できます。
BigQuery データ キャンバスは、分析タスクを高速化し、データ アナリストやデータ エンジニアなどのデータ プロフェッショナルがデータから分析情報を導出するプロセスを支援するように設計されています。特定のツールに関する技術的な知識は必要ありません。SQL の読み取りと書き込みに関する基本的な知識があれば十分です。BigQuery データ キャンバスは、Dataplex Universal Catalog メタデータと連携し、自然言語に基づいて適切なテーブルを識別します。
BigQuery データ キャンバスは、ビジネス ユーザーが直接使用することを目的としたものではありません。
BigQuery データ キャンバスは、Gemini in BigQuery を使用して、データの検索、SQL の作成、グラフの生成、データ概要の作成を行います。
Gemini for Google Cloud がデータを使用する方法とタイミングに関する説明をご覧ください。
機能
BigQuery データ キャンバスでは、次のことができます。
Dataplex Universal Catalog メタデータと自然言語クエリまたはキーワード検索構文を使用して、テーブル、ビュー、マテリアライズド ビューなどのアセットを検索する。
次のような基本的な SQL クエリに自然言語を使用する。
FROM句、数学関数、配列、構造体を含むクエリ。- 2 つのテーブルに対する
JOINオペレーション。
自然言語を使用して目的を説明することで、カスタムの可視化を作成する。
データ分析情報を自動生成する。
制限事項
自然言語コマンドは、以下では適切に機能しない場合があります。
- BigQuery ML
- Apache Spark
- オブジェクト テーブル
- BigLake
INFORMATION_SCHEMAビュー- JSON
- ネストされたフィールドと繰り返しフィールド
- 複雑な関数とデータ型(
DATETIME、TIMEZONEなど)
Geomap グラフではデータの可視化は機能しません。
プロンプトのベスト プラクティス
適切なプロンプト手法を使用すると、複雑な SQL クエリを生成できます。次の推奨事項により、BigQuery データ キャンバスで自然言語プロンプトを改善して、クエリの精度を高めることができます。
わかりやすく書く。リクエストは明確に記述します。あいまいな表現は避けましょう。
直接的な質問をする。最も正確な回答を得るには、質問は一度に 1 つにしてプロンプトを簡潔にします。最初に複数の質問を含むプロンプトを指定した場合は、質問の各部分を個別に列挙して、Gemini が理解できるようにします。
焦点を絞った明示的な指示を与える。プロンプトではキーワードを強調します。
操作の順序を指定する。明確な指示を順序立てて提供します。焦点を絞った小さなステップにタスクを分割します。
改善して繰り返す。さまざまな言い回しやアプローチを試して、どれが最善の結果をもたらすのか確かめます。
詳細については、BigQuery データ キャンバスのプロンプト記述に関するベスト プラクティスをご覧ください。
始める前に
- Google Cloud プロジェクトで Gemini in BigQuery が有効になっていることを確認します。通常、このステップは管理者が行います。
- BigQuery データ キャンバスを使用するには、必要な Identity and Access Management(IAM)権限があることを確認します。
- Dataplex Universal Catalog でデータ キャンバスのメタデータを管理するには、 Google Cloud プロジェクトで Dataplex API が有効になっていることを確認します。
必要なロール
BigQuery データ キャンバスを使用するために必要な権限を取得するには、プロジェクトに対する次の IAM ロールを付与するよう管理者に依頼します。
-
BigQuery Studio ユーザー(
roles/bigquery.studioUser) -
Gemini for Google Cloud ユーザー(
roles/cloudaicompanion.user)
ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
必要な権限は、カスタムロールや他の事前定義ロールから取得することもできます。
BigQuery における IAM ロールと権限の詳細については、IAM の概要をご覧ください。
Dataplex Universal Catalog でデータ キャンバスのメタデータを管理するには、必要な Dataplex Universal Catalog ロールと dataform.repositories.get 権限があることを確認します。
ノードタイプ
キャンバスは、1 つ以上のノードのコレクションです。ノードの接続順序は任意です。BigQuery データ キャンバスには、次のノードタイプがあります。
- テキスト
- 検索
- テーブル
- SQL
- 可視化
- 分析情報
テキストノード
BigQuery データ キャンバスでは、テキストノードを使用してリッチテキスト コンテンツをキャンバスに追加できます。キャンバスに説明、メモ、指示を追加して、分析のコンテキストと目的を自分自身や他のユーザーが簡単に理解できるようにするのに役立ちます。テキストノード エディタには、書式設定用のマークダウンなど、任意のテキスト コンテンツを入力できます。この機能を使用すると、視覚的に魅力的で有益なテキスト ブロックを作成できます。
テキストノードでは、次の操作を行うことができます。
- ノードを削除する。
- ノードをデバッグする。
- ノードを複製する。
検索ノード
BigQuery データ キャンバスでは、検索ノードを使用してデータアセットを見つけ、キャンバスに組み込むことができます。自然言語クエリやキーワード検索と、操作する実際のデータとの間のブリッジとして機能します。
検索クエリを自然言語またはキーワードで指定します。検索ノードはデータアセットを検索します。Dataplex Universal Catalog メタデータを活用して、コンテキスト認識を強化します。BigQuery データ キャンバスには、最近使用したテーブル、クエリ、保存済みクエリも表示されます。
検索ノードは、クエリに一致する関連のデータアセットのリストを返します。列名とテーブルの説明が考慮されます。次に、データ キャンバスにテーブルノードとして追加するアセットを選択します。ここで、データをさらに分析して可視化できます。
検索ノードでは、次の操作を行うことができます。
- ノードを削除する。
- ノードをデバッグする。
- ノードを複製する。
テーブルノード
BigQuery データ キャンバスでは、テーブルノードは分析ワークフローに組み込んだ特定のテーブルを表します。作業中のデータを表し、直接操作できます。
テーブルノードには、テーブルの名前、スキーマ、データのプレビューなどのテーブルに関する情報が表示されます。テーブル スキーマ、テーブルの詳細、テーブルのプレビューなどの詳細を表示して、テーブルを操作できます。
テーブルノードでは、次の操作を行うことができます。
- ノードを削除する。
- ノードをデバッグする。
- ノードを複製する。
- ノードを実行する。
- ノードと次のノードを実行する。
データ キャンバスでは、次の操作を行うことができます。
- 新しい SQL ノードで結果をクエリする。
- 結果を別のテーブルに結合する。
SQL ノード
BigQuery データ キャンバスでは、SQL ノードを使用してキャンバス内で直接カスタム SQL クエリを実行できます。SQL コードは、SQL ノード エディタで直接記述することも、自然言語プロンプトを使用して生成することもできます。
SQL ノードは、指定されたデータソースに対して指定された SQL クエリを実行します。SQL ノードは結果テーブルを生成します。このテーブルは、キャンバス内の他のノードに接続して、詳細な分析や可視化を行うことができます。
クエリの実行後、インタラクティブ クエリの実行と同様に、スケジュールされたクエリとしてエクスポートすることや、クエリ結果のエクスポート、キャンバスの共有ができます。
SQL ノードでは、次の操作を行うことができます。
- SQL ステートメントをスケジュールされたクエリとしてエクスポートする。
- ノードを削除する。
- ノードをデバッグする。
- ノードを複製する。
- ノードを実行する。
- ノードと次のノードを実行する。
データ キャンバスでは、次の操作を行うことができます。
- 新しい SQL ノードで結果をクエリする。
- 結果を可視化ノードで可視化する。
- 分析情報ノードで結果に関する分析情報を生成する。
- 結果を別のテーブルに結合する。
可視化ノード
BigQuery データ キャンバスでは、可視化ノードを使用してデータを視覚的に表示し、傾向、パターン、分析情報を簡単に把握できます。さまざまなグラフタイプから選択できるため、データに最適なグラフを選択してカスタマイズできます。
可視化ノードはテーブルを入力として受け取ります。テーブルは、SQL クエリの結果またはテーブルノードです。選択したグラフの種類と入力テーブルのデータに基づいて、可視化ノードがグラフを生成します。[自動グラフ] を選択すると、BigQuery がデータに最適なグラフタイプを選択します。生成されたグラフが可視化ノードに表示されます。
可視化ノードを使用すると、色、ラベル、データソースの変更など、グラフをカスタマイズできます。グラフを PNG ファイルとしてエクスポートすることもできます。
次のグラフタイプを使用してデータを可視化する。
- 棒グラフ
- ヒートマップ
- 折れ線グラフ
- 円グラフ
- 散布図
可視化ノードでは、次の操作を行うことができます。
- グラフを PNG ファイルとしてエクスポートする。
- ノードをデバッグする。
- ノードを複製する。
- ノードを実行する。
- ノードと次のノードを実行する。
データ キャンバスでは、次の操作を行うことができます。
- 分析情報ノードで結果に関する分析情報を生成する。
- 可視化を編集する。
分析情報ノード
BigQuery データ キャンバスの分析情報ノードを使用すると、データ キャンバス内のデータから分析情報とサマリーを生成できます。これにより、キャンバスでパターンの検出、データ品質の評価、統計分析を行うことができます。データ内のトレンド、パターン、異常、相関関係を特定し、データ分析結果の簡潔で明確な要約を生成します。
データ分析情報の詳細については、BigQuery でデータ分析情報を生成するをご覧ください。
分析情報ノードでは、次の操作を行うことができます。
- ノードを削除する。
- ノードを複製する。
- ノードを実行する。
BigQuery データ キャンバスを使用する
BigQuery データ キャンバスは、 Google Cloud コンソール、クエリ、テーブルで使用できます。
[BigQuery] ページに移動します。
クエリエディタで、[ SQL クエリ] の横にある [新規作成]、[データ キャンバス] の順にクリックします。
[自然言語] プロンプト フィールドに、自然言語プロンプトを入力します。
たとえば、「
Find me tables related to trees」と入力すると、BigQuery データ キャンバスから、bigquery-public-data.usfs_fia.plot_treeやbigquery-public-data.new_york_trees.tree_speciesなどの一般公開データセットを含む、使用可能なテーブルのリストが返されます。テーブルを選択します。
選択したテーブルのテーブルノードが BigQuery データ キャンバスに追加されます。スキーマ情報の表示、テーブルの詳細の表示、データのプレビューを行うには、テーブルノードにあるタブを選択します。
省略可: データ キャンバスを保存したら、次のツールバーを使用して、データ キャンバスの詳細やバージョン履歴を表示できます。また、新しいコメントの追加や既存のコメントへの返信、既存のコメントへのリンクの取得を行うことができます。
[詳細]、[バージョン履歴]、[コメント] のツールバー機能はプレビュー版です。これらの機能に関するフィードバックやサポートをリクエストする場合は、bqui-workspace-pod@google.com までメールをお送りください。
次の例は、分析ワークフローで BigQuery データ キャンバスを使用するさまざまな方法を示しています。
サンプル ワークフロー: データの検索、クエリ、可視化
この例では、BigQuery データ キャンバスで自然言語プロンプトを使用して、データを検索し、クエリを生成して編集します。その後、グラフを作成します。
プロンプト 1: データを検索する
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで、[ SQL クエリ] の横にある [新規作成]、[データ キャンバス] の順にクリックします。
[データを検索する] をクリックします。
filter_list(検索フィルタを編集します)をクリックし、[検索のフィルタ] ペインで [BigQuery の一般公開データセット] 切り替えボタンをオンにします。
[自然言語] プロンプト フィールドに、次の自然言語プロンプトを入力します。
Chicago taxi tripsBigQuery データ キャンバスは、Dataplex Universal Catalog メタデータに基づいて、使用可能なテーブルのリストを生成します。複数のテーブルを選択できます。
bigquery-public-data.chicago_taxi_trips.taxi_tripsテーブルを選択し、[キャンバスに追加] をクリックします。taxi_tripsのテーブルノードが BigQuery データ キャンバスに追加されます。スキーマ情報の表示、テーブルの詳細の表示、データのプレビューを行うには、テーブルノードにある各種タブを選択します。
プロンプト 2: 選択したテーブルで SQL クエリを生成する
bigquery-public-data.chicago_taxi_trips.taxi_trips テーブルに対する SQL クエリを生成するには、次の操作を行います。
データ キャンバスで [クエリ] をクリックします。
[自然言語] プロンプト フィールドに次のように入力します。
Get me the 100 longest tripsBigQuery データ キャンバスで、次のような SQL クエリが生成されます。
SELECT taxi_id, trip_start_timestamp, trip_end_timestamp, trip_miles FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` ORDER BY trip_miles DESC LIMIT 100;
プロンプト 3: クエリを編集する
生成したクエリを編集するには、クエリを手動で編集するか、自然言語プロンプトを変更してクエリを再生成します。この例では、自然言語プロンプトを使用してクエリを編集し、乗客が現金で支払ったルートのみを選択します。
[自然言語] プロンプト フィールドに次のように入力します。
Get me the 100 longest trips where the payment type is cashBigQuery データ キャンバスで、次のような SQL クエリが生成されます。
SELECT taxi_id, trip_start_timestamp, trip_end_timestamp, trip_miles FROM `PROJECT_ID.chicago_taxi_trips_123123.taxi_trips` WHERE payment_type = 'Cash' ORDER BY trip_miles DESC LIMIT 100;
上の例の
PROJECT_IDは、 Google Cloud プロジェクトの ID です。クエリの結果を表示するには、[実行] をクリックします。
グラフを作成する
- データ キャンバスで [可視化] をクリックします。
[棒グラフの作成] をクリックします。
BigQuery データ キャンバスで、ルート ID ごとに最も移動距離の長いルートを表示する棒グラフが作成されます。BigQuery データ キャンバスでは、グラフだけでなく、可視化の基となるデータの主な情報が要約されます。
省略可: 次のいずれかを行います。
- グラフを変更するには、[編集] をクリックし、[可視化を編集] ペインでグラフを編集します。
- データ キャンバスを共有するには、[共有] をクリックし、[リンクを共有] をクリックして、BigQuery データ キャンバスのリンクをコピーします。
- データ キャンバスをクリーンアップするには、[](その他の操作)を選択し、[](キャンバスを消去)を選択します。この手順により、空白のキャンバスが表示されます。
サンプル ワークフロー: テーブルを結合する
この例では、BigQuery データ キャンバスで自然言語プロンプトを使用してデータを検索し、テーブルを結合します。その後、クエリをノートブックとしてエクスポートします。
プロンプト 1: データを検索する
[自然言語] プロンプト フィールドに、次のプロンプトを入力します。
Information about treesBigQuery データ キャンバスに、ツリーに関する情報を含むテーブルが候補としていくつか表示されます。
この例では、
bigquery-public-data.new_york_trees.tree_census_1995テーブルを選択し、[キャンバスに追加] をクリックします。キャンバスにテーブルが表示されます。
プロンプト 2: 住所でテーブルを結合する
データ キャンバスで [結合] をクリックします。
BigQuery データ キャンバスに、結合するテーブルの候補が表示されます。
[自然言語] プロンプト フィールドを新たに開くには、[表を検索してください] をクリックします。
[自然言語] プロンプト フィールドに、次のプロンプトを入力します。
Information about treesbigquery-public-data.new_york_trees.tree_census_2005テーブルを選択し、[キャンバスに追加] をクリックします。キャンバスにテーブルが表示されます。
データ キャンバスで [結合] をクリックします。
[On this canvas] セクションで [Table cell] チェックボックスをオンにして、[OK] をクリックします。
[自然言語] プロンプト フィールドに、次のプロンプトを入力します。
Join on addressBigQuery データ キャンバスに、これら 2 つのテーブルを住所で結合する SQL クエリの候補が表示されます。
SELECT * FROM `bigquery-public-data.new_york_trees.tree_census_2015` AS t2015 JOIN `bigquery-public-data.new_york_trees.tree_census_1995` AS t1995 ON t2015.address = t1995.address;
クエリを実行して結果を表示するには、[実行] をクリックします。
クエリをノートブックとしてエクスポートする
BigQuery データ キャンバスでは、クエリをノートブックとしてエクスポートできます。
- データ キャンバスで [ノートブックとしてエクスポート] をクリックします。
- [ノートブックを保存] ペインで、ノートブックの名前と保存先のリージョンを入力します。
- [保存] をクリックします。ノートブックが正常に作成されます。
- 省略可: 作成したノートブックを確認するには、[開く] をクリックします。
サンプル ワークフロー: プロンプトを使用してグラフを編集する
この例では、BigQuery データ キャンバスの自然言語プロンプトを使用して、データの検索、クエリ、フィルタを行い、可視化の詳細を編集します。
プロンプト 1: データを検索する
米国の名前に関するデータを検索するために、次のプロンプトを入力します。
Find data about USA namesBigQuery データ キャンバスで、テーブルのリストが生成されます。
この例では、
bigquery-public-data.usa_names.usa_1910_currentテーブルを選択し、[キャンバスに追加] をクリックします。
プロンプト 2: データをクエリする
データをクエリするには、データ キャンバスで [クエリ] をクリックし、次のプロンプトを入力します。
Summarize this dataBigQuery データ キャンバスで、次のようなクエリが生成されます。
SELECT state, gender, year, name, number FROM `bigquery-public-data.usa_names.usa_1910_current`
[実行] をクリックします。クエリ結果が表示されます。
プロンプト 3: データをフィルタする
- データ キャンバスで [これらの結果に対してクエリを実行する] をクリックします。
データをフィルタするには、[SQL] プロンプト フィールドに次のプロンプトを入力します。
Get me the top 10 most popular names in 1980BigQuery データ キャンバスで、次のようなクエリが生成されます。
SELECT name, SUM(number) AS total_count FROM `bigquery-public-data`.usa_names.usa_1910_current WHERE year = 1980 GROUP BY name ORDER BY total_count DESC LIMIT 10;
クエリを実行すると、1980 年に生まれた子供に多い名前の上位 10 個を含むテーブルが返されます。
グラフを作成して編集する
データ キャンバスで [可視化] をクリックします。
BigQuery データ キャンバスに、棒グラフ、円グラフ、折れ線グラフ、カスタムの可視化など、使用できる可視化オプションが候補として表示されます。
この例では、[棒グラフの作成] をクリックします。
BigQuery データ キャンバスで、次のような棒グラフが作成されます。
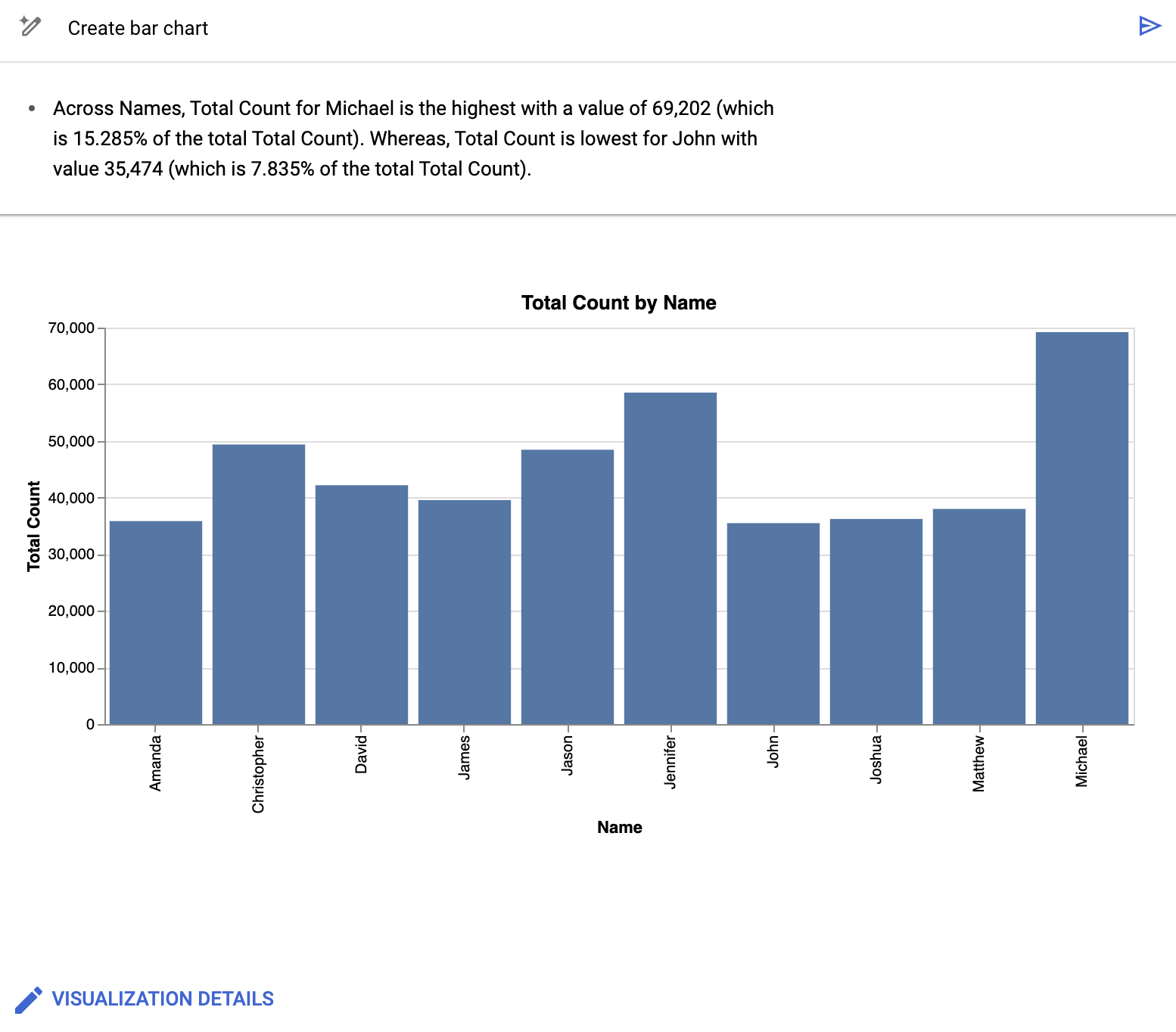
BigQuery データ キャンバスでは、グラフだけでなく、可視化の基となるデータの主な情報が要約されます。グラフを変更するには、[Visualization details] をクリックし、サイドパネルでグラフを編集します。
プロンプト 4: 可視化の詳細を編集する
[可視化] プロンプト フィールドに次のように入力します。
Create a bar chart sorted high to low, with a gradientBigQuery データ キャンバスで、次のような棒グラフが作成されます。
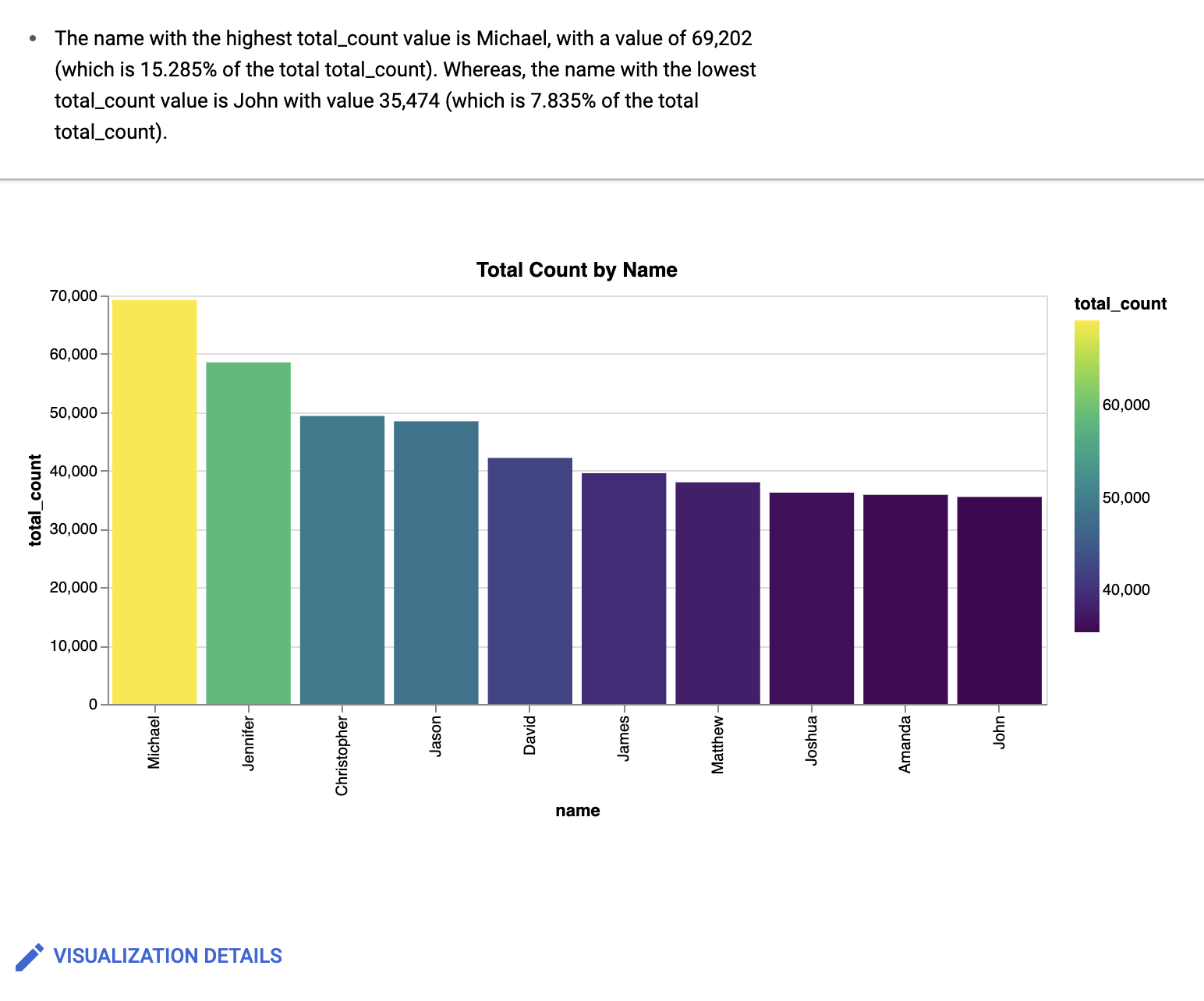
省略可: さらに変更を加えるには、[編集] をクリックします。
[可視化を編集] ペインが表示されます。グラフのタイトル、X 軸の名前、Y 軸の名前などの詳細を編集できます。また、[JSON エディタ] タブをクリックすると、JSON 値に基づいてグラフを直接編集できます。
Gemini アシスタントを使用する
Gemini を活用したチャット機能を利用して、BigQuery データ キャンバスを操作できます。チャット アシスタントは、リクエストに基づいてノードを作成し、クエリを実行して、可視化を作成できます。アシスタントが使用するテーブルを選択したり、アシスタントの動作を指示する手順を追加できます。アシスタントは、新しいデータ キャンバスまたは既存のデータ キャンバスで動作します。
Gemini アシスタントを使用する手順は次のとおりです。
- アシスタントを開くには、データ キャンバスで spark(データ キャンバス アシスタントを開く)をクリックします。
[データに関する質問をする] フィールドに、自然言語プロンプトを入力します。たとえば、次のように入力します。
Show me interesting statistics of my data.Make a chart based on my data, sorted high to low.I want to see sample data from my table.
レスポンスには、リクエストに基づくノードが含まれます。たとえば、アシスタントにデータのグラフを作成するよう依頼すると、データ キャンバスに可視化ノードが作成されます。
[データに関する質問をする] フィールドをクリックすると、次のこともできます。
- データを追加するには、[設定] をクリックします。
- 指示を追加するには、[設定] をクリックします。
アシスタントを続けて操作する場合は、自然言語のプロンプトを追加します。
データ キャンバスを操作しながら、自然言語プロンプトを継続的に作成できます。
データを追加する
Gemini チャット インターフェースを使用する場合は、アシスタントが参照先のデータセットを認識できるようにデータを追加できます。アシスタントは、プロンプトを実行する前にテーブルを選択するように求めます。アシスタントでデータを検索するときに、検索可能なデータの範囲をすべてのプロジェクト、スター付きのプロジェクト、現在のプロジェクトに制限できます。検索に一般公開データセットを含めるかどうかを指定することもできます。
Gemini アシスタントにデータを追加する手順は次のとおりです。
- アシスタントを開くには、データ キャンバスで spark(データ キャンバス アシスタントを開く)をクリックします。
- [設定] をクリックし、[データを追加] をクリックします。
- 省略可: 検索結果に一般公開データセットを含めるには、[一般公開データセット] 切り替えボタンをオンにします。
- 省略可: 検索結果の範囲を別のプロジェクトに変更するには、[範囲] メニューから適切なプロジェクト オプションを選択します。
- アシスタントに追加する各テーブルのチェックボックスをオンにします。
- アシスタントで提案されていないテーブルを検索するには、[表を検索してください] をクリックします。
- [自然言語] プロンプト フィールドに、探しているテーブルの説明を入力して、Enter キーを押します。
- アシスタントに追加する各テーブルのチェックボックスをオンにして、[OK] をクリックします。
- [キャンバス アシスタントの設定] ペインを閉じます。
選択したデータに基づいて、アシスタントが分析を行います。
指示を追加する
Gemini チャット インターフェースを使用する場合は、アシスタントの動作を指示する手順を追加できます。これらの指示は、データ キャンバス内のすべてのプロンプトに適用されます。以下に、指示の例を示します。
Visualize trends over time.Chart colors: Red (negative), Green (positive)Domain: USA
アシスタントに指示を追加する手順は次のとおりです。
- アシスタントを開くには、データ キャンバスで spark(データ キャンバス アシスタントを開く)をクリックします。
- [設定] をクリックします。
- [指示] フィールドに、アシスタントに指示する手順のリストを追加して、[キャンバス アシスタントの設定] ペインを閉じます。
アシスタントは指示を記憶し、以降のプロンプトに適用します。
Gemini アシスタントのベスト プラクティス
BigQuery データ キャンバス アシスタントから最良の結果を得るには、次のベスト プラクティスに従ってください。
あいまいな記述は避けて、具体的に記述する。計算、分析、可視化する内容を明確に記述します。たとえば、「
Analyze trip data」ではなく「Calculate the average trip duration for trips starting in council district eight」とします。データの正確なコンテキストを提供する。アシスタントが操作できるのは、ユーザーが提供したデータだけです。関連するすべてのテーブルと列をキャンバスに追加してください。
シンプルなものから始めて、繰り返し処理する。アシスタントが基本的な構造とデータを理解できるように、シンプルな質問から始めます。たとえば、最初に「
Show total trips by」と入力し、次に「subscriber_typeShow total trips by」と入力します。subscriber_typeand break down the result bycouncil_district複雑な質問は分解する。複数のステップから構成されるプロセスの場合は、プロンプトを明確な部分に分けて記述するか、主要なステップごとに別のプロンプトを作成することを検討してください。たとえば、「
First, find the top five busiest stations by trip count. Second, calculate the average trip duration for trips starting from only those top five stations」とします。計算を明確に記述する。
SUM、MAX、AVERAGEのような明確な計算式を指定します。たとえば、「Find the」とします。MAXtrip duration perbike_id永続的なコンテキストと設定にはシステム指示を使用する。システム指示を使用して、すべてのプロンプトに適用される情報ルールと設定を指定します。
キャンバスを見直す。生成されたノードを常に確認して、ロジックがリクエストと一致し、結果が正確であることを確認します。
テストを実施する。さまざまな言い回しや詳細レベル、プロンプト構造を試して、アシスタントが特定のデータと分析ニーズにどのように対応するかを確認します。
列名を参照する。可能な限り、選択したデータの実際の列名を使用します。たとえば、「
Show trips by subscriber type」ではなく「Show the count of trips grouped by」とします。subscriber_typeandstart_station_name
ワークフローの例: Gemini アシスタントを使用する
この例では、Gemini アシスタントで自然言語プロンプトを使用して、データの検索、クエリ、可視化を行います。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで、[ SQL クエリ] の横にある [新規作成]、[データ キャンバス] の順にクリックします。
[データを検索する] をクリックします。
filter_list(検索フィルタを編集します)をクリックし、[検索のフィルタ] ペインで [BigQuery の一般公開データセット] 切り替えボタンをオンにします。
[自然言語] プロンプト フィールドに、次の自然言語プロンプトを入力します。
bikeshareBigQuery データ キャンバスは、Dataplex Universal Catalog メタデータに基づいて、使用可能なテーブルのリストを生成します。複数のテーブルを選択できます。
bigquery-public-data.austin_bikeshare.bikeshare_stationsテーブルとbigquery-public-data.austin_bikeshare.bikeshare_tripsを選択し、[キャンバスに追加] をクリックします。選択した各テーブルのテーブルノードが BigQuery データ キャンバスに追加されます。スキーマ情報の表示、テーブルの詳細の表示、データのプレビューを行うには、テーブルノードにあるタブを選択します。
アシスタントを開くには、データ キャンバスで spark(データ キャンバス アシスタントを開く)をクリックします。
[設定] をクリックします。
[指示] フィールドに、アシスタントに対する次の手順を追加します。
Tasks: - Visualize findings with charts - Show many charts per question - Make sure to cover each part via a separate line of reasoning[キャンバス アシスタントの設定] ペインを閉じます。
[データに関する質問をする] フィールドに、次の自然言語プロンプトを入力します。
Show the number of trips by council district and subscriber type[データに関する質問] フィールドには、引き続きプロンプトを入力できます。次の自然言語プロンプトを入力します。
What are most popular stations among the top 5 subscriber types最後のプロンプトを入力します。
What station is least used to start and end a trip関連するプロンプトをすべて入力すると、アシスタントに指定したプロンプトと指示に従って、関連するクエリノードと可視化ノードがキャンバスに表示されます。目的の結果が得られるように、プロンプトの入力を続けるか、既存のプロンプトを変更します。
すべてのデータ キャンバスを表示する
プロジェクト内のすべてのデータ キャンバスのリストを表示するには、次の操作を行います。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、[データ キャンバス] の横にある [アクションを表示] をクリックし、次のいずれかを行います。
- 現在のタブでリストを開くには、[すべて表示] をクリックします。
- 新しいタブでリストを開くには、[次の中にすべて表示] > [新しいタブ] をクリックします。
- 分割タブでリストを開くには、[次の中にすべて表示] > [分割タブ] をクリックします。
データ キャンバスのメタデータを表示する
データ キャンバスのメタデータを表示するには、次の操作を行います。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクトと [データ キャンバス] フォルダを開き、必要に応じて [共有データ キャンバス] フォルダを開きます。メタデータを表示するデータ キャンバスの名前をクリックします。
[概要] ペインで、使用されているリージョンや最終更新日など、データ キャンバスに関する情報を確認します。
データ キャンバスのバージョンを操作する
データ キャンバスは、リポジトリの内側または外側に作成できます。データ キャンバスのバージョニングは、データ キャンバスの場所によって処理が異なります。
リポジトリ内のデータ キャンバスのバージョニング
リポジトリは、BigQuery またはサードパーティ プロバイダ内に存在する Git リポジトリです。リポジトリのワークスペースを使用して、データ キャンバスのバージョン管理を行うことができます。詳細については、ファイルでバージョン管理を使用するをご覧ください。
リポジトリ外のデータ キャンバスのバージョニング
データ キャンバスのバージョンを表示、比較、復元できます。
データ キャンバスのバージョンを表示して比較する
データ キャンバスの異なるバージョンを表示して、現在のバージョンと比較するには、次の操作を行います。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクトと [データ キャンバス] フォルダを開き、必要に応じて [共有データ キャンバス] フォルダを開きます。アクティビティを表示するデータ キャンバスの名前をクリックします。
(バージョン履歴)をクリックすると、データ キャンバスのバージョンが日付の降順で表示されます。
データ キャンバスのバージョンの横にある (アクションを表示)をクリックし、[比較] をクリックします。比較ペインが開きます。選択したデータ キャンバスのバージョンと現在のデータ キャンバスのバージョンを比較します。
省略可: 個別のペインではなくインラインでバージョンを比較するには、[比較]、[インライン] の順にクリックします。
データ キャンバスのバージョンを復元する
比較ペインから復元する場合は、復元するかどうかを選択する前に、データ キャンバスの以前のバージョンを現在のバージョンと比較できます。
- [エクスプローラ] ペインで、プロジェクトと [データ キャンバス] フォルダを開きます。また、必要であれば [共有データ キャンバス] フォルダも開きます。以前のバージョンを復元するデータ キャンバスの名前をクリックします。
- (バージョン履歴)をクリックします。
復元するデータ キャンバスのバージョンの横にある (アクションを表示)をクリックし、[比較] をクリックします。
比較ペインが開きます。選択したデータ キャンバスのバージョンと最新のデータ キャンバスのバージョンを比較します。
比較後に以前のデータ キャンバスのバージョンを復元するには、[復元] をクリックします。
[確認] をクリックします。
Dataplex Universal Catalog でメタデータを管理する
Dataplex Universal Catalog を使用すると、データ キャンバスのメタデータを表示して管理できます。データ キャンバスは、追加の構成をせずにデフォルトのまま Dataplex Universal Catalog で使用できます。
Dataplex Universal Catalog を使用すると、すべての BigQuery ロケーションでデータ キャンバスを管理できます。Dataplex Universal Catalog でデータ キャンバスを管理する場合は、Dataplex Universal Catalog の割り当てと上限および Dataplex Universal Catalog の料金が適用されます。
Dataplex Universal Catalog は、データ キャンバスから次のメタデータを自動的に取得します。
- データアセット名
- データアセットの親
- データアセットのロケーション
- データアセットのタイプ
- 対応する Google Cloud プロジェクト
Dataplex Universal Catalog は、データ キャンバスを次の値を持つエントリとしてログに記録します。
- システム エントリ グループ
- データ キャンバスのシステム エントリ グループは
@dataformです。Dataplex Universal Catalog でデータ キャンバス エントリの詳細を表示するには、dataformシステム エントリ グループを表示する必要があります。エントリ グループ内のすべてのエントリのリストを表示する方法については、Dataplex のドキュメントのエントリ グループの詳細を表示するをご覧ください。 - システム エントリのタイプ
- データ キャンバスのシステム エントリ タイプは
dataform-code-assetです。データ キャンバスの詳細を表示するには、dataform-code-assetシステム エントリ タイプを表示して、アスペクトベースのフィルタで結果をフィルタし、dataform-code-assetアスペクト内のtypeフィールドをDATA_CANVASに設定する必要があります。次に、選択したデータ キャンバスのエントリを選択します。選択したエントリタイプの詳細を表示する手順については、Dataplex Universal Catalog ドキュメントのエントリタイプの詳細を表示するをご覧ください。選択したエントリの詳細を表示する手順については、Dataplex Universal Catalog ドキュメントのエントリの詳細を表示するをご覧ください。 - システム アスペクト タイプ
- データ キャンバスのシステム アスペクト タイプは
dataform-code-assetです。データ キャンバス エントリにアスペクトをアノテーションして、Dataplex Universal Catalog のデータ キャンバスにコンテキストを追加するには、dataform-code-assetアスペクト タイプを表示して、アスペクトベースのフィルタで結果をフィルタし、dataform-code-assetアスペクト内のtypeフィールドをDATA_CANVASに設定します。エントリにアスペクトをアノテーションする方法については、Dataplex Universal Catalog ドキュメントのアスペクトを管理してメタデータを拡充するをご覧ください。 - タイプ
- データ キャンバスのタイプは
DATA_CANVASです。このタイプでは、アスペクトベースのフィルタでaspect:dataplex-types.global.dataform-code-asset.type=DATA_CANVASクエリを使用して、dataform-code-assetシステム エントリ タイプとdataform-code-assetアスペクト タイプのデータ キャンバスをフィルタできます。
Dataplex Universal Catalog でアセットを検索する方法については、Dataplex Universal Catalog ドキュメントの Dataplex Universal Catalog でデータアセットを検索するをご覧ください。
料金
この機能の料金の詳細については、Gemini in BigQuery の料金の概要をご覧ください。
割り当てと上限
この機能の割り当てと上限については、Gemini in BigQuery の割り当てをご覧ください。
ロケーション
BigQuery データ キャンバスは、すべての BigQuery ロケーションで使用できます。Gemini in BigQuery はグローバルに運用されるため、データ処理を特定のリージョンに限定することはできません。Gemini in BigQuery がデータを処理するロケーションの詳細については、Gemini のサービス提供ロケーションをご覧ください。
フィードバックを送信する
Google にフィードバックを送信して、BigQuery データ キャンバスで表示される候補の改善にご協力ください。フィードバックを送信するには、次の操作を行います。
Google Cloud コンソールのツールバーで、[フィードバックを送信] をクリックします。
(省略可)DAG JSON 情報をコピーしてフィードバックに追加のコンテキストを提供するには、(コピー)をクリックします。
フォームに記入してフィードバックを送信するには、フォームをクリックします。
データ共有設定はプロジェクト全体に適用されます。これは、serviceusage.services.enable と serviceusage.services.list の IAM 権限を持つプロジェクト管理者のみ設定できます。Trusted Tester プログラムでのデータの使用について詳しくは、 Google Cloud Trusted Tester プログラムの Gemini をご覧ください。
この機能に関するフィードバックを直接送信するには、datacanvas-feedback@google.com 宛てにメールをお送りください。
次のステップ
Gemini アシスタント機能を使用してクエリを作成する方法を学習する。
ノートブックの作成方法を学習する。
データ分析情報を使用してデータに関する自然言語クエリを生成する方法について確認する。