Neste documento, descrevemos como implantar um mecanismo de exportação para fazer streaming de registros dos recursos do Google Cloud para o Splunk. É necessário já ter lido a arquitetura de referência correspondente para este caso de uso.
Estas instruções são destinadas a operações e administradores de segurança que querem transmitir registros do Google Cloud para o Splunk. Você precisa conhecer o Splunk e o Splunk HTTP Event Collector (HEC) ao usar estas instruções para operações de TI ou casos de uso de segurança. Embora não seja obrigatório, a familiaridade com pipelines do Dataflow, Pub/Sub, Cloud Logging, Identity and Access Management e Cloud Storage é útil para essa implantação.
Para automatizar as etapas de implantação nessa arquitetura de referência usando
infraestrutura como código (IaC, na sigla em inglês), consulte o
repositório
terraform-splunk-log-export do GitHub.
Arquitetura
O diagrama a seguir mostra a arquitetura de referência e como os dados de registro fluem do Google Cloud para o Splunk.

Conforme mostrado no diagrama, o Cloud Logging coleta os registros em um coletor no nível da organização e os envia para o Pub/Sub. O serviço Pub/Sub cria um único tópico e assinatura para os registros e os encaminha para o pipeline principal do Dataflow. O pipeline principal do Dataflow é um pipeline de streaming do Pub/Sub para o Splunk que extrai registros da assinatura do Pub/Sub e os entrega para o Splunk. Paralelo ao pipeline principal do Dataflow, o pipeline secundário do Dataflow é um pipeline de streaming do Pub/Sub para o pipeline do Pub/Sub para reproduzir mensagens se uma entrega falhar. No final do processo, o Splunk Enterprise ou o Splunk Cloud Platform atua como um endpoint HEC e recebe os registros para análise posterior. Para mais detalhes, consulte a seção Arquitetura da arquitetura de referência.
Para implantar essa arquitetura de referência, execute as seguintes tarefas:
- Executar tarefas de configuração.
- Criar um coletor de registros agregado em um projeto dedicado.
- Crie um tópico de mensagens inativas.
- Configurar um endpoint de HEC do Splunk.
- Configurar a capacidade do pipeline do Dataflow.
- Exportar registros para o Splunk.
- Transformar registros ou eventos em andamento usando funções definidas pelo usuário (UDF) no pipeline do Dataflow do Splunk.
- Tratar falhas de entrega para evitar a perda de dados devido a possíveis problemas de configuração ou de falha temporária da rede.
Antes de começar
Conclua as etapas a seguir para configurar um ambiente da sua arquitetura de referência do Google Cloud para o Splunk:
- Criar um projeto, ativar o faturamento e as APIs.
- Conceda papéis do IAM.
- Configurar o ambiente.
- Configure uma rede segura.
Criar um projeto, ativar o faturamento e as APIs
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Monitoring API, Secret Manager, Compute Engine, Pub/Sub, and Dataflow APIs.
Conceder papéis do IAM
No console do Google Cloud, verifique se você tem as seguintes permissões de Identity and Access Management (IAM) para recursos da organização e do projeto. Saiba mais em Como conceder, alterar e revogar acesso a recursos.
| Permissões | Papéis predefinidos | Recurso |
|---|---|---|
|
|
Organização |
|
|
Projeto |
|
|
Projeto |
Se os papéis predefinidos do IAM não incluírem permissões suficientes para você executar suas tarefas, crie um papel personalizado. O papel personalizado oferece o acesso de que você precisa e ajuda a seguir o princípio do privilégio mínimo.
Configure seu ambiente
In the Google Cloud console, activate Cloud Shell.
Defina o projeto para sua sessão ativa do Cloud Shell:
gcloud config set project PROJECT_ID
Substitua
PROJECT_IDpela ID do seu projeto.
Configurar uma rede segura
Nesta etapa, veja como configurar uma rede segura para poder processar e exportar registros para o Splunk Enterprise.
Crie uma rede e uma sub-rede VPC:
gcloud compute networks create NETWORK_NAME --subnet-mode=custom gcloud compute networks subnets create SUBNET_NAME \ --network=NETWORK_NAME \ --region=REGION \ --range=192.168.1.0/24
Substitua:
NETWORK_NAME: o nome da sua redeSUBNET_NAME: o nome da sub-redeREGION: a região que você quer usar para essa rede.
Crie uma regra de firewall para as máquinas virtuais (VMs) de worker do Dataflow se comunicarem:
gcloud compute firewall-rules create allow-internal-dataflow \ --network=NETWORK_NAME \ --action=allow \ --direction=ingress \ --target-tags=dataflow \ --source-tags=dataflow \ --priority=0 \ --rules=tcp:12345-12346
Essa regra permite o tráfego interno entre as VMs do Dataflow que usam as portas TCP 12345-12346. Além disso, o serviço Dataflow define a tag
dataflow.Crie um gateway do Cloud NAT:
gcloud compute routers create nat-router \ --network=NETWORK_NAME \ --region=REGION gcloud compute routers nats create nat-config \ --router=nat-router \ --nat-custom-subnet-ip-ranges=SUBNET_NAME \ --auto-allocate-nat-external-ips \ --region=REGION
Ative o Acesso privado do Google na sub-rede:
gcloud compute networks subnets update SUBNET_NAME \ --enable-private-ip-google-access \ --region=REGION
Criar um coletor de registros
Nesta seção, veja como criar o coletor de registros em toda a organização e o destino do Pub/Sub com as permissões necessárias.
No Cloud Shell, crie um tópico do Pub/Sub e a assinatura associada como o novo destino do coletor de registros:
gcloud pubsub topics create INPUT_TOPIC_NAME gcloud pubsub subscriptions create \ --topic INPUT_TOPIC_NAME INPUT_SUBSCRIPTION_NAME
Substitua:
INPUT_TOPIC_NAME: o nome do tópico do Pub/Sub a ser usado como destino do coletor de registros.INPUT_SUBSCRIPTION_NAME: o nome da assinatura do Pub/Sub para o destino do coletor de registros
Crie o coletor de registros da organização:
gcloud logging sinks create ORGANIZATION_SINK_NAME \ pubsub.googleapis.com/projects/PROJECT_ID/topics/INPUT_TOPIC_NAME \ --organization=ORGANIZATION_ID \ --include-children \ --log-filter='NOT logName:projects/PROJECT_ID/logs/dataflow.googleapis.com'
Substitua:
ORGANIZATION_SINK_NAME: o nome do coletor na organizaçãoORGANIZATION_ID: o ID da organização
O comando consiste nas seguintes sinalizações:
- A flag
--organizationespecifica que o coletor de registros está no nível da organização. - A sinalização
--include-childrené necessária e garante que o coletor de registros no nível da organização inclua todos os registros em todas as subpastas e projetos. - A sinalização
--log-filterespecifica os registros a serem roteados. Neste exemplo, exclua os registros de operações do Dataflow especificamente do projetoPROJECT_ID, porque o pipeline do Dataflow de exportação de registros gera mais registros enquanto os processa. O filtro impede que o pipeline exporte os próprios registros, evitando um ciclo possivelmente exponencial. A saída inclui uma conta de serviço na forma deo#####-####@gcp-sa-logging.iam.gserviceaccount.com.
Conceda o papel de IAM de Editor do Pub/Sub à conta de serviço do coletor de registros no tópico do Pub/Sub
INPUT_TOPIC_NAME. Esse papel permite que a conta de serviço do coletor de registros publique mensagens no tópico.gcloud pubsub topics add-iam-policy-binding INPUT_TOPIC_NAME \ --member=serviceAccount:LOG_SINK_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/pubsub.publisher
Substitua
LOG_SINK_SERVICE_ACCOUNTpelo nome da conta de serviço do coletor de registros.
Criar um tópico de mensagens inativas
Para evitar possíveis perdas de dados quando uma mensagem não é entregue, crie um tópico de mensagens inativas do Pub/Sub e uma assinatura correspondente. A mensagem com falha é armazenada no tópico de mensagens inativas até que um operador ou engenheiro de confiabilidade do site possa investigar e corrigir a falha. Para ver mais informações, consulte a seção Repetir mensagens com falha da arquitetura de referência.
No Cloud Shell, crie um tópico de mensagens inativas do Pub/Sub e uma assinatura para evitar a perda de dados, armazenando mensagens não entregues:
gcloud pubsub topics create DEAD_LETTER_TOPIC_NAME gcloud pubsub subscriptions create --topic DEAD_LETTER_TOPIC_NAME DEAD_LETTER_SUBSCRIPTION_NAME
Substitua:
DEAD_LETTER_TOPIC_NAME: o nome do tópico do Pub/Sub que será o tópico de mensagens inativas.DEAD_LETTER_SUBSCRIPTION_NAME: o nome da assinatura do Pub/Sub para o tópico de mensagens inativas
Configurar um endpoint de HEC do Splunk
Nos procedimentos a seguir, você configura um endpoint de HEC do Splunk e armazena o token de HEC recém-criado como um secret no Secret Manager. Ao implantar o pipeline do Splunk Dataflow, você precisa fornecer o URL do endpoint e o token.
Configurar o HEC do Splunk
- Se você ainda não tiver um endpoint do HEC do Splunk, consulte a documentação do Splunk para saber como configurar o HEC do Splunk (em inglês). O HEC do Splunk é executado no serviço Splunk Cloud Platform ou na sua própria instância do Splunk Enterprise.
- No Splunk, depois de criar um token de HEC do Splunk, copie o valor do token.
- No Cloud Shell, salve o valor do token de HEC do Splunk em um arquivo temporário
chamado
splunk-hec-token-plaintext.txt.
Armazenar o token do HEC do Splunk no Secret Manager
Nesta etapa, você cria um secret e uma única versão do secret subjacente em que armazenar o valor do token HEC do Splunk.
No Cloud Shell, crie um secret para conter o token HEC do Splunk:
gcloud secrets create hec-token \ --replication-policy="automatic"
Para mais informações sobre as políticas de replicação de secrets, consulte Escolher uma política de replicação.
Adicione o token como uma versão do secret usando o conteúdo do arquivo
splunk-hec-token-plaintext.txt:gcloud secrets versions add hec-token \ --data-file="./splunk-hec-token-plaintext.txt"
Exclua o arquivo
splunk-hec-token-plaintext.txtporque ele não é mais necessário.
Configure a capacidade do pipeline do Dataflow
A tabela a seguir resume as práticas recomendadas gerais para definir as configurações de capacidade do pipeline do Dataflow:
| Configuração | Prática recomendada geral |
|---|---|
Sinalização |
Defina como o tamanho da máquina de base |
Sinalização |
Defina como o número máximo de workers necessários para lidar com o EPS de pico esperado de acordo com seus cálculos |
Parâmetro |
Defina como 2 x vCPUs/worker x o número máximo de workers para maximizar o número de conexões HEC paralelas do Splunk |
|
Definido como 10 a 50 eventos/solicitação de registros, desde que o atraso máximo de armazenamento em buffer de dois segundos seja aceitável |
Lembre-se de usar seus próprios valores e cálculos exclusivos ao implantar essa arquitetura de referência no seu ambiente.
Defina os valores para o tipo e a contagem de máquinas. Para calcular valores adequados ao ambiente de nuvem, consulte as seções Tipo de máquina e Contagem de máquinas da arquitetura de referência.
DATAFLOW_MACHINE_TYPE DATAFLOW_MACHINE_COUNT
Defina os valores de paralelismo e contagem em lote do Dataflow. Para calcular valores apropriados para o ambiente de nuvem, consulte as seções Paralelismo e Contagem de lotes da arquitetura de referência.
JOB_PARALLELISM JOB_BATCH_COUNT
Para mais informações sobre como calcular os parâmetros de capacidade do pipeline do Dataflow, consulte a seção Considerações de design para otimização de desempenho e custos desta arquitetura de referência.
Exportar registros usando o pipeline do Dataflow
Nesta seção, você implantará o pipeline do Dataflow seguindo estas etapas:
- Crie um bucket do Cloud Storage e uma conta de serviço de worker do Dataflow.
- Conceda papéis e acesso à conta de serviço do worker do Dataflow.
- Implante o pipeline do Dataflow.
- Visualizar registros no Splunk.
O pipeline entrega mensagens de registro do Google Cloud ao HEC do Splunk.
Criar um bucket do Cloud Storage e uma conta de serviço de worker do Dataflow
No Cloud Shell, crie um novo bucket do Cloud Storage com uma configuração de acesso uniforme no nível do bucket:
gcloud storage buckets create gs://PROJECT_ID-dataflow/ --uniform-bucket-level-access
O bucket do Cloud Storage que você acabou de criar é onde o job do Dataflow organiza arquivos temporários.
No Cloud Shell, crie uma conta de serviço para os worker do Dataflow:
gcloud iam service-accounts create WORKER_SERVICE_ACCOUNT \ --description="Worker service account to run Splunk Dataflow jobs" \ --display-name="Splunk Dataflow Worker SA"
Substitua
WORKER_SERVICE_ACCOUNTpelo nome que você quer usar para a conta de serviço do worker do Dataflow.
Conceder papéis e acesso à conta de serviço do worker do Dataflow
Nesta seção, conceda os papéis necessários à conta de serviço do worker do Dataflow, conforme mostrado na tabela a seguir.
| Papel | Caminho | Finalidade |
|---|---|---|
| Administrador do Dataflow |
|
Ative a conta de serviço para atuar como administrador do Dataflow. |
| Worker do Dataflow |
|
Permitir que a conta de serviço atue como um worker do Dataflow. |
| Administrador de objetos do Storage |
|
Ative a conta de serviço para acessar o bucket do Cloud Storage usado pelo Dataflow para preparar arquivos. |
| Editor pub/sub |
|
Ative a conta de serviço para publicar mensagens com falha no tópico de mensagens inativas do Pub/Sub. |
| Assinante do Pub/Sub |
|
Ative a conta de serviço para acessar a assinatura de entrada. |
| Leitor do Pub/Sub |
|
Ative a conta de serviço para ver a assinatura. |
| Assessor de secret do Secret Manager |
|
Ative a conta de serviço para acessar o secret que contém o token HEC do Splunk. |
No Cloud Shell, conceda à conta de serviço de worker do Dataflow os papéis de administrador e worker do Dataflow necessários para executar operações de job e tarefas de administração do Dataflow:
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/dataflow.worker"
Conceda à conta de serviço do worker do Dataflow acesso para visualizar e consumir mensagens da assinatura de entrada do Pub/Sub:
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.subscriber"
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.viewer"
Conceda à conta de serviço do worker do Dataflow acesso para publicar qualquer mensagem com falha no tópico não processado do Pub/Sub:
gcloud pubsub topics add-iam-policy-binding DEAD_LETTER_TOPIC_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.publisher"
Conceda à conta de serviço do worker do Dataflow acesso ao secret do token HEC do Splunk no Secret Manager:
gcloud secrets add-iam-policy-binding hec-token \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/secretmanager.secretAccessor"
Conceda à conta de serviço do worker do Dataflow acesso de leitura e gravação ao bucket do Cloud Storage a ser usado pelo job do Dataflow para preparar arquivos:
gcloud storage buckets add-iam-policy-binding gs://PROJECT_ID-dataflow/ \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" --role=”roles/storage.objectAdmin”
Implantar o pipeline do Dataflow
No Cloud Shell, defina a seguinte variável de ambiente para o URL do HEC do Splunk:
export SPLUNK_HEC_URL=SPLUNK_HEC_URL
Substitua a variável
SPLUNK_HEC_URLusando o formulárioprotocol://host[:port], em que:protocoléhttpouhttps.hosté o nome de domínio totalmente qualificado (FQDN, na sigla em inglês) ou endereço IP da instância do HEC do Splunk ou, caso você tenha várias instâncias do HEC, o HTTP(S) associado (ou baseado em DNS).porté o número da porta HEC. É opcional e depende da configuração do endpoint do HEC do Splunk.
Um exemplo de uma entrada de URL de HEC do Splunk válida é
https://splunk-hec.example.com:8088. Se você estiver enviando dados para o HEC no Splunk Cloud Platform, consulte Enviar dados para o HEC no Splunk Cloud para determinar as parteshosteportacima do URL específico do HEC do Splunk.O URL do HEC do Splunk não pode incluir o caminho do endpoint do HEC, por exemplo,
/services/collector. No momento, o modelo do Pub/Sub para o Splunk Dataflow aceita apenas o endpoint/services/collectorpara eventos formatados em JSON e anexa automaticamente esse caminho à entrada de URL do HEC do Splunk. Para saber mais sobre esse endpoint do HEC, consulte a documentação do Splunk para endpoint de serviços/coletor.Implante o pipeline do Dataflow usando o modelo do Pub/Sub para o Splunk Dataflow:
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --staging-location=gs://PROJECT_ID-dataflow/temp/ \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://splk-public/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
Substitua
JOB_NAMEpelo formato de nomepubsub-to-splunk-date+"%Y%m%d-%H%M%S".Os parâmetros opcionais
javascriptTextTransformGcsPathejavascriptTextTransformFunctionNameespecificam uma UDF de amostra disponível publicamente:gs://splk-public/js/dataflow_udf_messages_replay.js. O exemplo de UDF inclui exemplos de código para transformação de eventos e lógica de decodificação que você usa para reproduzir as entregas com falha. Para mais informações sobre UDF, consulte Transformar eventos em andamento com UDF.Após a conclusão do job do pipeline, encontre o novo ID do job na saída, copie o ID do job e salve. Insira esse ID de job em uma etapa posterior.
Visualizar registros no Splunk
Os workers do pipeline do Dataflow levam alguns minutos para serem provisionados e estarem prontos para entregar registros ao HEC do Splunk. Verifique se os registros foram recebidos e indexados corretamente na interface de pesquisa do Splunk Enterprise ou Splunk Cloud Platform. Para ver o número de registros por tipo de recurso monitorado:
Abra o Search & Reporting no Splunk.
Execute a pesquisa
index=[MY_INDEX] | stats count by resource.type, em que o índiceMY_INDEXestá configurado para seu token do HEC do Splunk.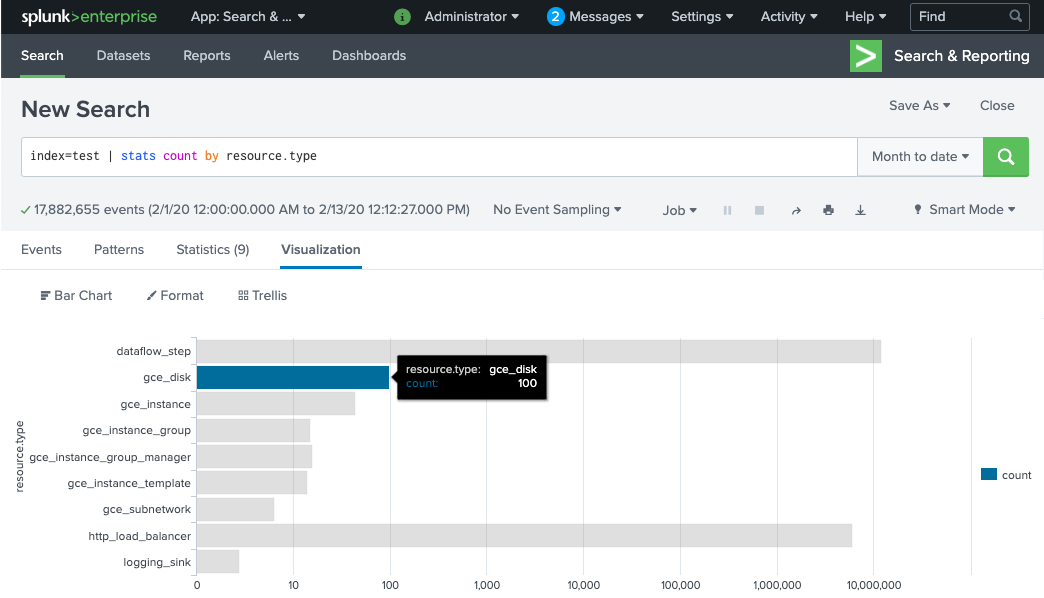
Se você não encontrar eventos, consulte Como tratar falhas de entrega.
Transformar eventos em andamento com a UDF
O modelo do Pub/Sub para o Splunk Dataflow é compatível com uma UDF em JavaScript para transformação de eventos personalizados, como adição de novos campos ou configuração de metadados de HEC do Splunk com base em evento. O pipeline implantado usa esta UDF de amostra.
Nesta seção, saiba como editar a função de UDF de amostra para adicionar um novo campo de evento. Esse novo campo especifica o valor da assinatura do Pub/Sub de origem como informações contextuais adicionais. Em seguida, atualize o pipeline do Dataflow com a UDF modificada.
Modificar a UDF de amostra
No Cloud Shell, faça o download do arquivo JavaScript que contém a função da UDF de amostra (em inglês):
wget https://storage.googleapis.com/splk-public/js/dataflow_udf_messages_replay.js
No editor de texto de sua escolha, abra o arquivo JavaScript, localize o campo
event.inputSubscription, remova a marca de comentário dessa linha e substituasplunk-dataflow-pipelineporINPUT_SUBSCRIPTION_NAME:event.inputSubscription = "INPUT_SUBSCRIPTION_NAME";
Salve o arquivo.
Faça upload do arquivo para o bucket do Cloud Storage:
gcloud storage cp ./dataflow_udf_messages_replay.js gs://PROJECT_ID-dataflow/js/
Atualizar o pipeline do Dataflow com a nova UDF
No Cloud Shell, interrompa o pipeline usando a opção "Drenar" para garantir que os registros já extraídos do Pub/Sub não sejam perdidos:
gcloud dataflow jobs drain JOB_ID --region=REGION
Executar o job do pipeline do Dataflow com a UDF atualizada.
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://PROJECT_ID-dataflow/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
Substitua
JOB_NAMEpelo formato de nomepubsub-to-splunk-date+"%Y%m%d-%H%M%S".
Processar falhas na entrega
Podem ocorrer falhas de entrega devido a erros no processamento de eventos ou na conexão com o HEC do Splunk. Nesta seção, veja como introduzir uma falha na entrega para mostrar o fluxo de trabalho de tratamento de erros. Além disso, aprenda a visualizar e acionar o reenvio das mensagens com falha para o Splunk.
Acionar falhas de entrega
Para introduzir uma falha de entrega manualmente no Splunk, siga um destes procedimentos:
- Se você executar uma única instância, interrompa o servidor do Splunk para causar erros de conexão.
- Desativar o token do HEC relevante da configuração de entrada do Splunk
Resolver problemas de mensagens com falha
Para investigar uma mensagem que falhou, use o console do Google Cloud:
No console do Google Cloud, acesse a página Assinaturas do Pub/Sub.
Clique na assinatura não processada que você criou. Se você tiver usado o exemplo anterior, o nome da assinatura será:
projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME.Para abrir o visualizador de mensagens, clique em Ver mensagens.
Para visualizar mensagens, clique em Pull e deixe a opção Ativar mensagens de confirmação desmarcada.
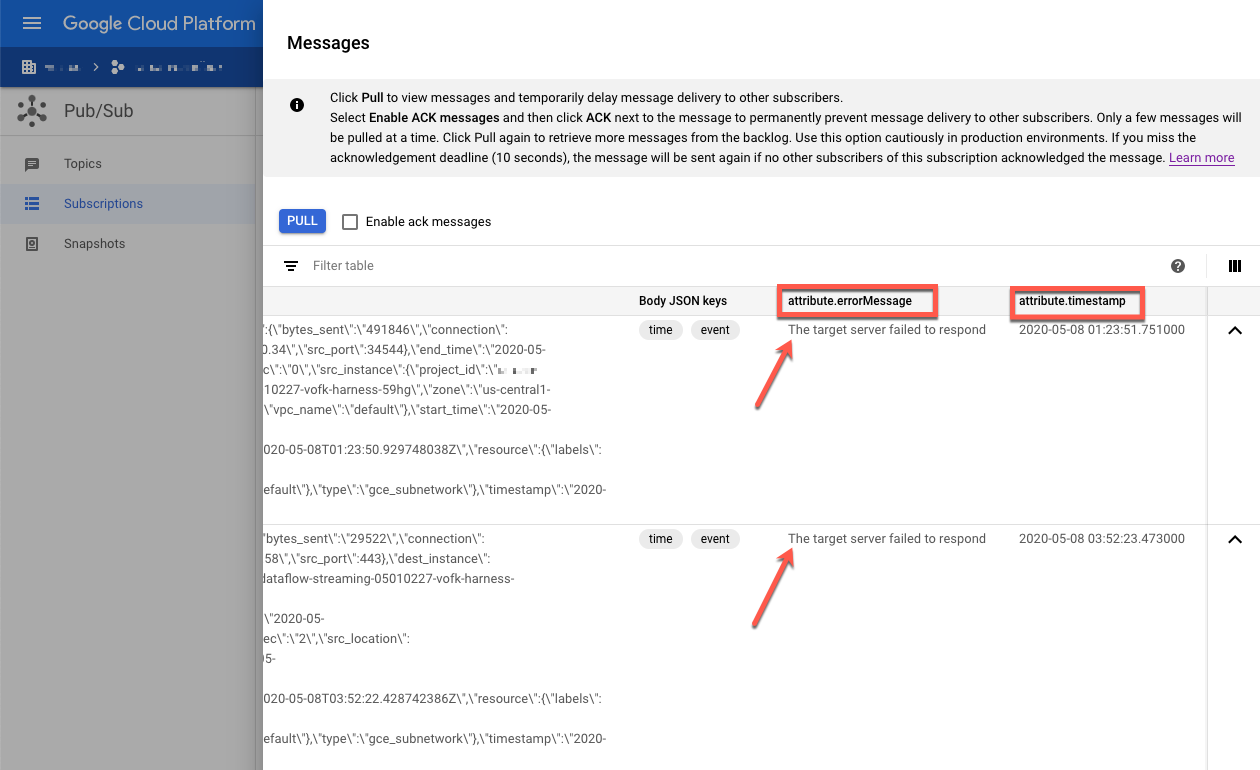
Inspecione as mensagens com falha. Preste atenção no seguinte:
- O payload de eventos do Splunk na coluna
Message body. - A mensagem de erro na coluna
attribute.errorMessage. - O carimbo de data/hora do erro na coluna
attribute.timestamp.
- O payload de eventos do Splunk na coluna
A captura de tela a seguir mostra um exemplo de mensagem de falha que você recebe se o endpoint HEC do Splunk estiver temporariamente inativo ou inacessível. Observe que o
texto do atributo errorMessage é The target server failed to respond.
A mensagem também mostra o carimbo de data/hora associado a cada falha. Use esse carimbo de data/hora para solucionar a causa raiz da falha.
Repetir mensagens com falha
Nesta seção, você precisa reiniciar o servidor do Splunk ou ativar o endpoint do HEC do Splunk para corrigir o erro de entrega. Em seguida, é possível reproduzir as mensagens não processadas.
No Splunk, use um dos seguintes métodos para restaurar a conexão com o Google Cloud:
- Se você interrompeu o servidor do Splunk, reinicie-o.
- Se você tiver desativado o endpoint do HEC do Splunk na seção Acionar falhas de entrega, verifique se ele está funcionando.
No Cloud Shell, tire um snapshot da assinatura não processada antes de reprocessar as mensagens nela. O snapshot evita a perda de mensagens caso haja um erro de configuração inesperado.
gcloud pubsub snapshots create SNAPSHOT_NAME \ --subscription=DEAD_LETTER_SUBSCRIPTION_NAME
Substitua
SNAPSHOT_NAMEpor um nome que ajude a identificar o snapshot, comodead-letter-snapshot-date+"%Y%m%d-%H%M%S.Use o modelo do Pub/Sub para Splunk Dataflow para criar um pipeline do Pub/Sub para o Pub/Sub. O pipeline usa outro job do Dataflow para transferir as mensagens da assinatura não processada de volta para o tópico de entrada.
DATAFLOW_INPUT_TOPIC="INPUT_TOPIC_NAME" DATAFLOW_DEADLETTER_SUB="DEAD_LETTER_SUBSCRIPTION_NAME" JOB_NAME=splunk-dataflow-replay-date +"%Y%m%d-%H%M%S" gcloud dataflow jobs run JOB_NAME \ --gcs-location= gs://dataflow-templates/latest/Cloud_PubSub_to_Cloud_PubSub \ --worker-machine-type=n1-standard-2 \ --max-workers=1 \ --region=REGION \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME,\ outputTopic=projects/PROJECT_ID/topics/INPUT_TOPIC_NAME
Copie o ID do job do Dataflow na resposta ao comando e salve-o para mais tarde. Você inserirá esse ID do job como
REPLAY_JOB_IDao drenar seu job do Dataflow.No console do Google Cloud, acesse a página Assinaturas do Pub/Sub.
Selecione a assinatura não processada. Confirme se o gráfico Contagem de mensagens não confirmadas está abaixo de 0, conforme mostrado na captura de tela a seguir.
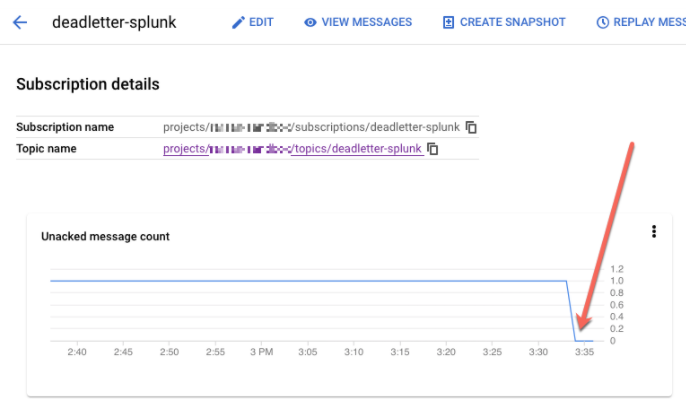
No Cloud Shell, drene o job do Dataflow que você criou:
gcloud dataflow jobs drain REPLAY_JOB_ID --region=REGION
Substitua
REPLAY_JOB_IDpelo ID do job do Dataflow que você salvou anteriormente.
Quando as mensagens são transferidas de volta para o tópico de entrada original, o pipeline principal do Dataflow entrega as mensagens com falha novamente ao Splunk de forma automática.
Confirmar mensagens no Splunk
Para confirmar que as mensagens foram entregues novamente, abra o Search & Reporting no Splunk.
Pesquise
delivery_attempts > 1. Esse é um campo especial que a UDF de amostra adiciona a cada evento para rastrear o número de tentativas de entrega. Expanda o intervalo de tempo de pesquisa para incluir eventos que possam ter ocorrido antes, porque o carimbo de data/hora do evento é a hora original de criação, não o momento da indexação.
Na captura de tela a seguir, as duas mensagens que falharam originalmente agora são entregues e indexadas no Splunk com o carimbo de data/hora correto.
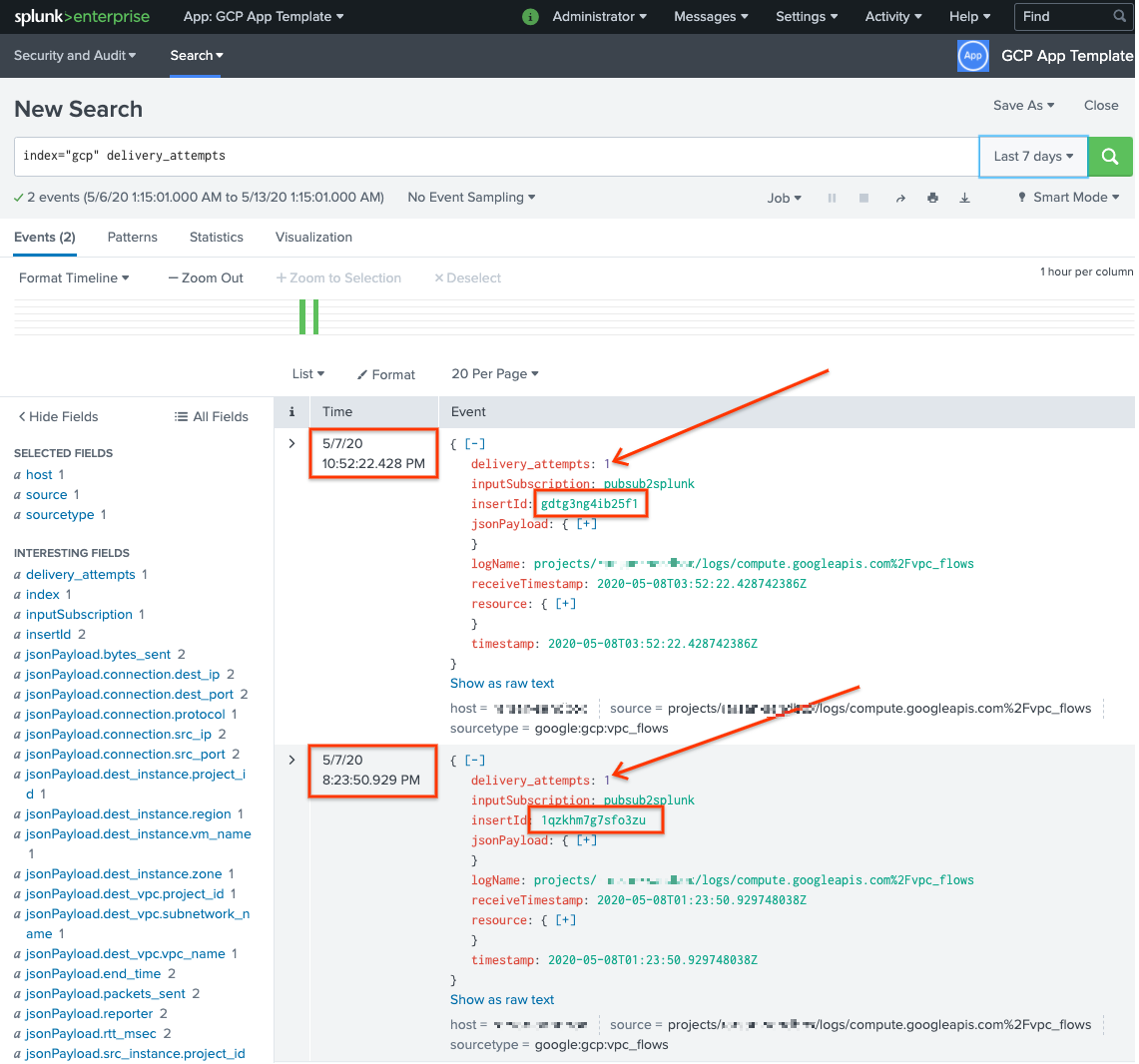
Observe que o valor do campo insertId é igual ao valor exibido nas
mensagens com falha quando você visualiza a assinatura não processada.
O campo insertId é um identificador exclusivo que o Cloud Logging atribui à
entrada de registro original. O insertId também aparece no corpo da mensagem do Pub/Sub.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados na arquitetura de referência, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Exclua o coletor no nível da organização
- Use o seguinte comando para excluir o coletor de registros no nível da organização:
gcloud logging sinks delete ORGANIZATION_SINK_NAME --organization=ORGANIZATION_ID
Excluir o projeto
Depois de excluir o coletor de registro, prossiga com a exclusão de recursos criados para receber e exportar registros. A maneira mais fácil é excluir o projeto que você criou para a arquitetura de referência.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Para acessar uma lista completa de parâmetros de modelo do Pub/Sub para o Splunk Dataflow, consulte a documentação do Pub/Sub para o Splunk Dataflow.
- Para acessar os modelos correspondentes do Terraform para ajudar você a implantar essa arquitetura
de referência, consulte o
repositório do GitHub
terraform-splunk-log-export. Ele inclui um painel pré-criado do Cloud Monitoring para monitorar o pipeline do Splunk Dataflow. - Para mais detalhes sobre as métricas personalizadas e a geração de registros do Splunk Dataflow, para monitorar e solucionar problemas dos pipelines do Splunk Dataflow, consulte este blog Novos recursos de observabilidade para os pipelines de streaming do Splunk Dataflow de dois minutos.
- Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.