
Serviço Gerenciado para Apache Spark (antigo Dataproc)
A nova maneira de usar o Spark: mais rápida, mais fácil e mais inteligente
Execute cargas de trabalho do Apache Spark com Spark sem servidor de zero-ops ou clusters gerenciados. Acelere o desenvolvimento com fluxos de trabalho de IA agêntica e aumente a performance com o Lightning Engine.
Novos clientes ganham US$ 300 em créditos para testar o serviço gerenciado para Apache Spark e outros produtos do Google Cloud.
Apache Spark é uma marca registrada da Apache Software Foundation.

Recursos
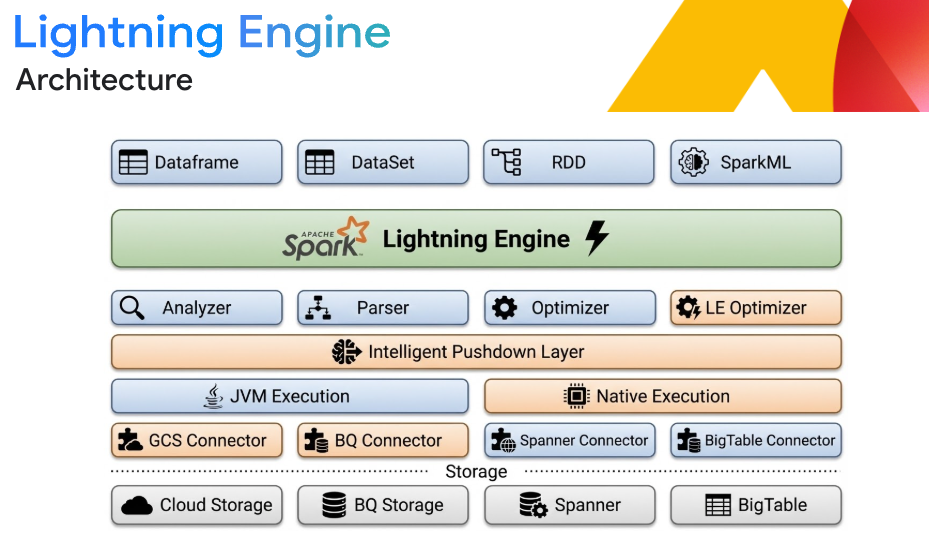
Desempenho líder do setor com o Lightning Engine
Acelere cargas de trabalho de ETL e SQL em grande escala até 4,9 vezes mais rápido do que o Apache Spark de código aberto sem nenhuma alteração no código. O Lightning Engine usa um mecanismo de execução vetorial nativo em C++, armazenamento em cache inteligente e embaralhamento colunar otimizado. Combine isso com o ajuste automático inteligente do Spark para eliminar o ônus do ajuste manual, otimizando a memória e evitando erros de memória insuficiente automaticamente.
*As consultas são derivadas do padrão TPC-DS e do padrão TPC-H
Interoperabilidade flexível do lakehouse
Crie uma arquitetura de lakehouse aberto que garanta a independência do mecanismo. Processe dados em formatos abertos como o Apache Iceberg diretamente do Google Cloud Storage. Integre-se totalmente ao BigQuery e ao Knowledge Catalog (antigo Dataplex) para ter governança e análise unificadas, garantindo a verdadeira interoperabilidade multimecanismo sem camadas de tradução.
Experiência unificada com tecnologia de IA para desenvolvedores
Acabe com o acúmulo de tarefas com agentes de dados que agem, não apenas respondem a perguntas. Acelere seu fluxo de trabalho usando o Gemini integrado à extensão agêntica do VSCode para aumentar a produtividade das cargas de trabalho do Spark desde o desenvolvimento até a produção ou use o ambiente de desenvolvimento integrado de sua preferência. Automatize a preparação de dados e a programação em PySpark com os Agentes de dados do Data Cloud prontos para uso ou use o Kit de agentes de dados para gerenciar conjuntos de dados e executar consultas diretamente do seu IDE. Resolva automaticamente problemas de jobs do Spark com o Gemini Cloud Assist. Combine SQL e Spark em um único notebook unificado com prioridade para IA.
Pronto para IA/ML empresarial
Crie e operacionalize todo o seu ciclo de vida de machine learning. Acelere o treinamento de modelo e a inferência com suporte a GPU, do NVIDIA RAPIDS, e ambientes de execução de ML pré-configurados para PyTorch e XGBoost. Integre-se ao ecossistema de IA do Google Cloud para orquestrar MLOps de ponta a ponta e gerenciar recursos com a integração do Model Registry do Gemini Enterprise Agent Platform.
Migrações seguras, escalonáveis e tranquilas
Integração total à sua postura de segurança com o IAM, o VPC Service Controls e o Kerberos. Migre facilmente cargas de trabalho legadas e na nuvem do Spark usando modelos e ferramentas do Serviço Gerenciado para Apache Spark. Faça migração lift-and-shift de cargas de trabalho com suporte ao Spark 2.x até o Spark 4.0 sem refatoração imediata de código.
Eficiência multilocatária e controles de FinOps
Maximize a utilização de recursos e reduza os custos de inatividade. Implante clusters multilocatários do Spark que permitem que até 800 usuários compartilhem recursos de computação, mantendo um isolamento rigoroso de dados e ambientes. Controle sua fatura com recursos de redução da escala a zero, faturamento por segundo e suporte a VMs spot para cargas de trabalho flexíveis.
Ecossistema aberto e flexível
Sem dependência de fornecedores. Embora sejam otimizados para o Apache Spark, nossos clusters gerenciados oferecem suporte a mais de 30 ferramentas de código aberto, como Apache Hadoop, Flink e Trino. Integre-se totalmente a orquestradores como o Serviço Gerenciado para Apache Airflow e estenda com o Kubernetes e o Docker para máxima flexibilidade.
Opções de implantação
| Opções de implantação | Escolha entre o controle detalhado dos clusters gerenciados ou a simplicidade da operação zero de uma experiência sem servidor para encontrar a melhor opção para sua carga de trabalho. | ||
|---|---|---|---|
| Modo de implantação: | O que é: | Ideal para: | Pague por: |
Sem servidor | Jobs do Spark como serviço. Spark Gerenciado, infraestrutura gerenciada. | Novos pipelines, análises interativas e cargas de trabalho com picos de uso em que um modelo de pagamento por job e operação zero é preferível. | Tempo de execução do job |
Clusters | Clusters do Spark como serviço. Spark Gerenciado, sua infraestrutura. | Migração de cargas de trabalho legadas do Spark ou de OSS, execução de clusters persistentes ou necessidade de personalização detalhada de código aberto. | Tempo de atividade do cluster |
Opções de implantação
Escolha entre o controle detalhado dos clusters gerenciados ou a simplicidade da operação zero de uma experiência sem servidor para encontrar a melhor opção para sua carga de trabalho.
Sem servidor
Jobs do Spark como serviço.
Spark Gerenciado, infraestrutura gerenciada.
Novos pipelines, análises interativas e cargas de trabalho com picos de uso em que um modelo de pagamento por job e operação zero é preferível.
Tempo de execução do job
Clusters
Clusters do Spark como serviço.
Spark Gerenciado, sua infraestrutura.
Migração de cargas de trabalho legadas do Spark ou de OSS, execução de clusters persistentes ou necessidade de personalização detalhada de código aberto.
Tempo de atividade do cluster
Como funciona
Facilite o Spark com clusters gerenciados ou sem servidor de operação zero. Trabalhe de forma mais inteligente com o Gemini no seu IDE preferido, usando IA agêntica para acelerar o desenvolvimento do PySpark. Execute jobs mais rapidamente com o Lightning Engine, mantendo a governança unificada em todo o seu lakehouse aberto com o Knowledge Catalog.
Facilite o Spark com clusters gerenciados ou sem servidor de operação zero. Trabalhe de forma mais inteligente com o Gemini no seu IDE preferido, usando IA agêntica para acelerar o desenvolvimento do PySpark. Execute jobs mais rapidamente com o Lightning Engine, mantendo a governança unificada em todo o seu lakehouse aberto com o Knowledge Catalog.
Engenharia de dados em grande escala
Pipelines de ETL automatizados
Pipelines de ETL automatizados
Crie pipelines de ETL do Spark robustos e orientados por eventos que escalonam automaticamente sob demanda. Aproveite a execução sem servidor para cargas de trabalho irregulares ou clusters gerenciados para jobs persistentes. Use modelos de fluxo de trabalho para automatizar seus jobs de processamento de dados mais críticos e de nível de produção de ponta a ponta.
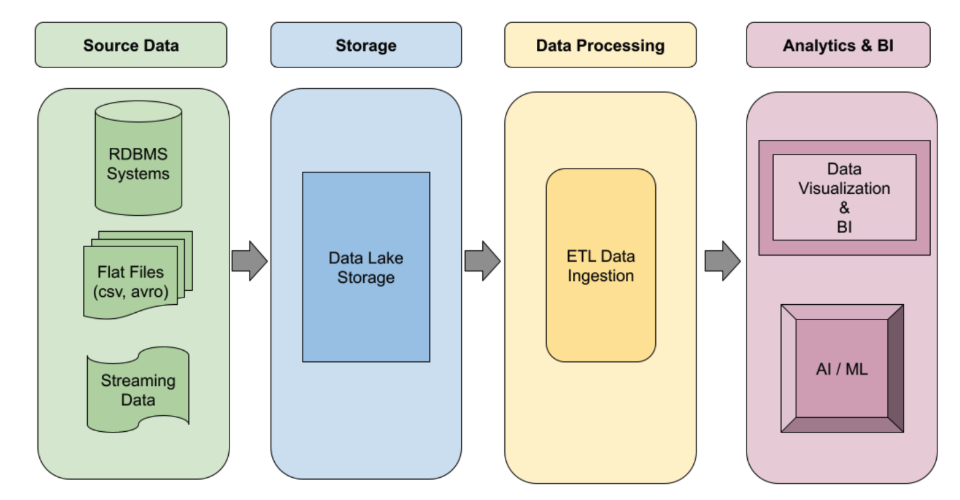


Tutoriais, guias de início rápido e laboratórios
Pipelines de ETL automatizados
Pipelines de ETL automatizados
Crie pipelines de ETL do Spark robustos e orientados por eventos que escalonam automaticamente sob demanda. Aproveite a execução sem servidor para cargas de trabalho irregulares ou clusters gerenciados para jobs persistentes. Use modelos de fluxo de trabalho para automatizar seus jobs de processamento de dados mais críticos e de nível de produção de ponta a ponta.
Ciência de dados e machine learning
Ciência de dados interativa
Ciência de dados interativa
Capacite os cientistas de dados a analisar os dados e iterar nos modelos de ML do Spark. Unifique SQL e Spark usando o Gemini com a extensão agêntica do VSCode ou seu IDE de preferência, passando da análise de dados para a criação de modelos com o PySpark usando a execução sem servidor. Anexe GPUs com um único comando.


Tutoriais, guias de início rápido e laboratórios
Ciência de dados interativa
Ciência de dados interativa
Capacite os cientistas de dados a analisar os dados e iterar nos modelos de ML do Spark. Unifique SQL e Spark usando o Gemini com a extensão agêntica do VSCode ou seu IDE de preferência, passando da análise de dados para a criação de modelos com o PySpark usando a execução sem servidor. Anexe GPUs com um único comando.
Modernização do lakehouse
Data lakehouse aberto
Data lakehouse aberto
Use o Serviço Gerenciado para Apache Spark como o mecanismo de processamento do seu data lakehouse moderno. Processe dados em formatos abertos como o Apache Iceberg diretamente do seu data lake, eliminando silos de dados. Integre-se ao BigQuery e ao Lakehouse para Apache Iceberg para ter uma plataforma de análise multimecanismo unificada.
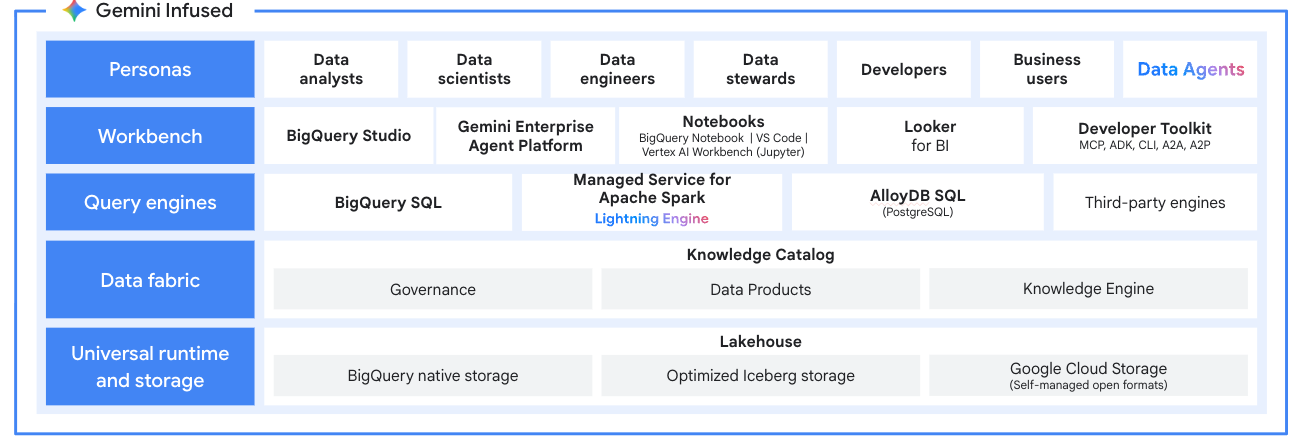

Tutoriais, guias de início rápido e laboratórios
Data lakehouse aberto
Data lakehouse aberto
Use o Serviço Gerenciado para Apache Spark como o mecanismo de processamento do seu data lakehouse moderno. Processe dados em formatos abertos como o Apache Iceberg diretamente do seu data lake, eliminando silos de dados. Integre-se ao BigQuery e ao Lakehouse para Apache Iceberg para ter uma plataforma de análise multimecanismo unificada.
Preços
| Como funciona o preço do Serviço Gerenciado para Apache Spark | O preço depende do modelo de implantação escolhido. O modelo sem servidor cobra por execução de job, enquanto os clusters cobram pela computação e pelo tempo de atividade. | |
|---|---|---|
| Modo de implantação: | O que você paga: | O que você paga: |
Sem servidor | Pague somente pelo que você usa. Cobrança por segundo de computação, GPUs e armazenamento de redistribuição. A redução da escala a zero garante que você nunca pague por capacidade ociosa. | A partir de US$ 0,06 por DCU/hora |
Nível Premium e aceleradores: Acesse o Lightning Engine para ter um desempenho até 4,9 vezes mais rápido ou anexe GPUs NVIDIA para cargas de trabalho de IA/ML. | A partir de US$ 0,089 por DCU/hora Nível Premium sem servidor | |
Clusters | Pague pelo tempo de atividade do cluster. Cobrança pelos recursos do Compute Engine subjacentes mais uma taxa de gerenciamento fixa. Aproveite as VMs spot e o escalonamento zero para otimizar os custos. | A partir de US$ 0,01 por vCPU/hora Taxa de administração |
Complemento Lightning Engine: Ofereça desempenho inovador aos seus clusters. Tenha uma execução até 4,9 vezes mais rápida do que o Spark de código aberto. | A partir de US$ 0,0025 por hora de vCPU | |
Saiba mais sobre os preços do Serviço Gerenciado para Apache Spark. Confira todos os detalhes de preços.
Como funciona o preço do Serviço Gerenciado para Apache Spark
O preço depende do modelo de implantação escolhido. O modelo sem servidor cobra por execução de job, enquanto os clusters cobram pela computação e pelo tempo de atividade.
Sem servidor
Pague somente pelo que você usa. Cobrança por segundo de computação, GPUs e armazenamento de redistribuição. A redução da escala a zero garante que você nunca pague por capacidade ociosa.
Starting at
US$ 0,06 por DCU/hora
Nível Premium e aceleradores:
Acesse o Lightning Engine para ter um desempenho até 4,9 vezes mais rápido ou anexe GPUs NVIDIA para cargas de trabalho de IA/ML.
Starting at
US$ 0,089 por DCU/hora
Nível Premium sem servidor
Clusters
Pague pelo tempo de atividade do cluster. Cobrança pelos recursos do Compute Engine subjacentes mais uma taxa de gerenciamento fixa. Aproveite as VMs spot e o escalonamento zero para otimizar os custos.
Starting at
US$ 0,01 por vCPU/hora
Taxa de administração
Complemento Lightning Engine:
Ofereça desempenho inovador aos seus clusters. Tenha uma execução até 4,9 vezes mais rápida do que o Spark de código aberto.
Starting at
US$ 0,0025 por hora de vCPU
Saiba mais sobre os preços do Serviço Gerenciado para Apache Spark. Confira todos os detalhes de preços.
Caso de negócios
Histórias de sucesso do cliente

"Algumas das nossas verificações de qualidade passaram de 11 horas para minutos."
Michael Manos, diretor de tecnologia da Dun & Bradstreet
A migração para o Google Cloud ajudou a Dun & Bradstreet a aumentar significativamente a velocidade dos fluxos de dados, reduzindo os processos de verificação de qualidade de horas para minutos e diminuindo pela metade o tempo necessário para publicar novos dados. Essa base de dados sólida também permite que a Dun & Bradstreet aproveite todo o potencial do ecossistema do Google Cloud, incluindo tecnologias de IA e dados de ponta.



A diferença do Serviço Gerenciado para Apache Spark
Produtividade sem operações com opções flexíveis de implantação. Escolha a execução sem servidor ou clusters totalmente gerenciados para eliminar a sobrecarga de infraestrutura e o ajuste manual.
Desenvolvimento de IA agêntica. Acelere seu fluxo de trabalho com o Gemini integrado à extensão agêntica do VSCode ou com seu IDE de preferência, além de agentes de dados que automatizam a programação em PySpark, a preparação de dados e a solução de problemas de jobs em um notebook unificado.
Desempenho líder do setor com tecnologia Lightning Engine. Acelere suas cargas de trabalho de ETL e ciência de dados mais exigentes em até 4,9 vezes, reduzindo significativamente o custo total de propriedade










Recursos adicionais:
Perguntas frequentes
O que aconteceu com o Dataproc e o Spark sem servidor?
Para simplificar sua experiência, unificamos o Dataproc e o Google Cloud Serverless para Apache Spark em um único produto: Serviço Gerenciado para Apache Spark. Você tem acesso às mesmas funcionalidades avançadas, mas agora basta escolher seu modelo de implantação preferido (sem servidor e sem operações ou clusters totalmente gerenciados) em uma interface única e unificada. Comparar os dois modos de implantação com mais detalhes.
Quando devo escolher a opção sem servidor em vez de clusters gerenciados?
Escolha a opção sem servidor quando quiser se concentrar apenas no código, sem gerenciamento de infraestrutura, ideal para novos pipelines e análises ad hoc. Escolha clusters gerenciados quando precisar de controle detalhado, estiver migrando cargas de trabalho legadas ou do Spark na nuvem ou de outros OSS ou precisar de clusters persistentes com diversas ferramentas de código aberto.
O que é o Lightning Engine?
O Lightning Engine é o mecanismo de execução nativo e altamente otimizado do Google Cloud. Criado com bibliotecas C++, ele otimiza todas as camadas, desde conectores de armazenamento de alta capacidade até cache inteligente. Ele oferece até 4,9 vezes melhor desempenho do que o Spark padrão e 2 vezes o custo-benefício em relação à principal alternativa de alta velocidade do Spark, integrando-se perfeitamente às suas implantações sem servidor ou de cluster sem alterações no código.
Preciso instalar minhas próprias bibliotecas de ML, como o PyTorch?
Não. Se você estiver executando cargas de trabalho de IA/ML, poderá usar nossos ambientes de execução de ML pré-configurados. Esses ambientes vêm com bibliotecas comuns como PyTorch, XGBoost e scikit-learn integradas, além de drivers de GPU NVIDIA otimizados, eliminando configurações complexas.
O Serviço Gerenciado para Apache Spark é totalmente compatível com código aberto?
Sim. Oferecemos um ambiente Apache Spark 100% compatível com código aberto. Você pode executar seu código Spark atual sem modificações, garantindo a portabilidade completa da carga de trabalho e evitando a dependência de fornecedores.
Como a IA do Gemini ajuda no desenvolvimento do Spark?
A IA do Gemini pode ser integrada diretamente ao seu IDE preferido para atuar como seu copiloto de IA. Ela ajuda você a escrever e depurar códigos PySpark com mais rapidez, enquanto o Gemini Cloud Assist fornece análises automatizadas de causa raiz e recomendações de solução de problemas para jobs com falha.
Posso usar esse serviço para criar um data lakehouse aberto?
Com certeza. O Serviço Gerenciado para Apache Spark é um mecanismo de processamento principal para o lakehouse aberto do Google Cloud. Ele permite processar dados em formatos abertos como o Apache Iceberg diretamente do Cloud Storage, integrando-se perfeitamente ao BigQuery e ao Knowledge Catalog para Apache Iceberg.
Como funcionam os níveis de preços padrão e premium?
Atualmente, os níveis Standard e Premium só se aplicam a implantações sem servidor. O Standard é ideal para ETL e processamento em lote de uso geral e econômico. O nível premium foi criado para suas cargas de trabalho mais exigentes, desbloqueando um aumento de desempenho de 4,9 vezes em relação ao Apache Spark de código aberto com o Lightning Engine e fornecendo acesso a recursos de IA/ML acelerados por GPU.


















