Nos aplicativos de jogo para dispositivos móveis, é gerado um grande volume de dados de telemetria de jogadores e eventos. Esses dados são potencialmente úteis para fornecer insights do comportamento do jogador e do envolvimento dele com o jogo. A natureza desses jogos, que em grande parte são executados em dispositivos clientes instáveis, com conexões de Internet lentas e problemas relacionados a bateria e gerenciamento de energia, significa que a análise desses dados é um desafio único.
Essa arquitetura de referência apresenta uma abordagem de alto nível para coletar, armazenar e analisar grandes volumes de dados de telemetria dos jogadores no Google Cloud.
Para ser mais específico, você aprenderá a analisar eventos de jogos para dispositivos móveis usando dois padrões principais de arquitetura:
- processamento em tempo real de eventos individuais com um padrão de streaming
- processamento em massa de eventos agregados com um padrão de lote
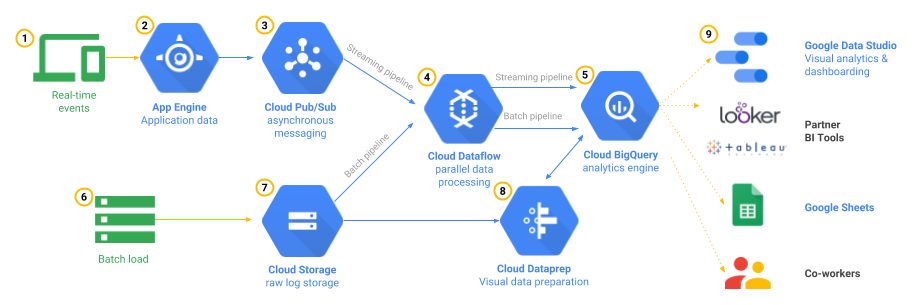
Figura 1: arquitetura de referência de telemetria de jogo
Na figura 1, os pipelines de processamento dos dois padrões são ilustrados, bem como alguns componentes opcionais para exploração, visualização e compartilhamento adicionais dos resultados. A arquitetura de referência tem alta disponibilidade e permite que você faça o escalonamento quando os volumes de dados aumentam. Observe também que essa arquitetura é composta somente de serviços gerenciados para os canais de análise de dados, ou seja, não é necessário executar máquinas virtuais ou gerenciar sistemas operacionais. Isso é especialmente evidente quando a autenticação do usuário no App Engine é processada no servidor do jogo. No artigo abaixo, você conhecerá essa arquitetura com detalhes.
Processamento de eventos em tempo real com padrão de streaming
Nesta seção, você conhecerá um padrão de arquitetura de exemplo em que um grande número de eventos de várias fontes diferentes são ingeridos, processados e analisados simultaneamente. O processamento ocorre à medida que os eventos acontecem durante o jogo, permitindo que você responda e tome decisões em tempo real.
Um grande número de mensagens de evento é gerado nos vários jogos para dispositivos móveis. Alguns são acionados pelo jogador, outros pelo horário do dia e assim por diante. Como resultado, os conjuntos de dados são desvinculados e você não tem como antecipar quantos eventos serão processados. Isso significa que a abordagem correta nesse caso é processar os dados usando um mecanismo de execução em streaming.
Imagine que o aplicativo para dispositivos móveis é um jogo de interpretação de papéis (RPG, na sigla em inglês) onde os jogadores lutam contra as forças do mal, cumprindo missões para derrotar monstros poderosos. Para rastrear o progresso do jogador, uma mensagem normal de evento inclui um identificador exclusivo para esse jogador, um carimbo de data/hora do evento, métricas indicando a missão, os pontos atuais de saúde e assim por diante. Talvez isso seja semelhante a este exemplo, que mostra uma mensagem de evento de fim de batalha com um identificador de evento playerkillednpc.
{
"eventTime":"2015-10-27T20:34:12.675362426+08:00",
"userId":"gamer@example.com",
"sessionId":"b6ff8881-0c30-9add-374c-c32052cee256",
"eventId":"playerkillednpc",
…
"attackRoll":17,
"damageRoll":13
}
Nesse exemplo, você viu um evento relacionado a batalha, mas essas mensagens podem incluir qualquer tipo de informação relevante para seu negócio, por exemplo, eventos de compra no jogo.
Como não é possível prever quais perguntas você precisará responder sobre os dados, uma boa estratégia é registrar o máximo de pontos de dados que puder. Com isso, você tem o contexto adicional necessário para as suas futuras consultas. Por exemplo, qual informação é mais útil: o fato de um jogador ter feito uma compra no jogo no valor de 50 centavos, ou aqueles que compraram um feitiço poderoso contra o chefe da missão 15, sendo que o jogador foi morto por esse chefe cinco vezes seguidas, nos 30 minutos anteriores a essa compra? A captura de dados completos do evento permite que você tenha um insight detalhado e preciso do que ocorre no seu jogo.
Origem da mensagem: dispositivo móvel ou servidor de jogo?
Independentemente dos campos de conteúdo das mensagens de evento, você precisa decidir se quer enviá-las diretamente do dispositivo do usuário final que executa o aplicativo móvel para a camada de processamento do Pub/Sub ou passar pelo servidor do jogo. O principal benefício de passar pelo servidor é que a autenticação e validação são processados pelo seu aplicativo. Uma desvantagem é que será necessário usar capacidade extra de processamento do servidor para tratar a carga de mensagens desses dispositivos.
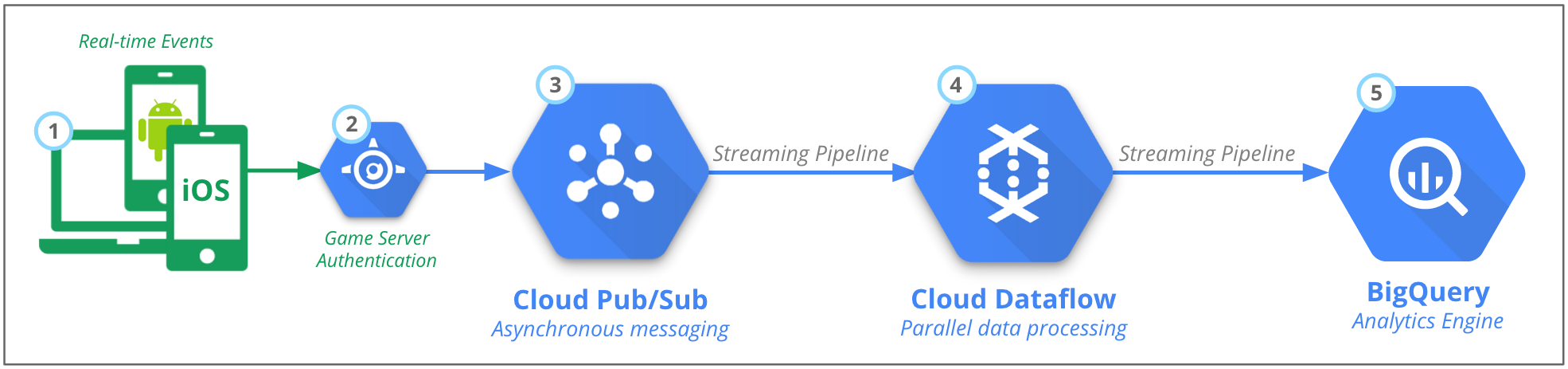
Figura 2: processamento em tempo real dos eventos dos clientes e servidores do jogo
Independentemente da origem dos dados, a arquitetura de back-end ainda é, em grande parte, a mesma. Conforme mostrado na figura 2, há cinco partes principais:
- As mensagens de evento em tempo real são enviadas por um grande número de origens, por exemplo, milhões de aplicativos para dispositivos móveis.
- A autenticação é processada no servidor do jogo.
- O Pub/Sub processa e armazena essas mensagens temporariamente.
- No Dataflow, o evento JSON é transformado em dados estruturados e baseados em esquemas.
- Os dados são carregados no mecanismo de análise do BigQuery.
Pub/Sub: ingestão de eventos escalável
Para processar essa carga, um serviço escalonável capaz de receber e armazenar temporariamente essas mensagens de evento é necessário. Como o tamanho de cada evento individual é bem pequeno, você precisa se preocupar mais com o número total de mensagens do que com os requisitos gerais de armazenamento.
Outro requisito para esse serviço de ingestão é o suporte a vários métodos de saída. Isso significa que os eventos podem ser usados por vários destinos. Por fim, é preciso haver a opção entre o serviço atuar como uma fila, em que cada destino verifica alterações para alimentar novas mensagens, e um método push, que envia eventos antecipadamente, no momento em que eles são recebidos.
Felizmente, todas essas funcionalidades são fornecidas pelo Pub/Sub. Na figura 3, a camada de ingestão recomendada é ilustrada, com capacidade de processar milhões de mensagens por segundo e mantê-las por até sete dias no armazenamento permanente. O Pub/Sub opera um padrão de publicação/assinatura em que é possível ter um ou mais editores enviando mensagens para um ou mais tópicos. Também é possível que haja vários assinantes para cada tópico.
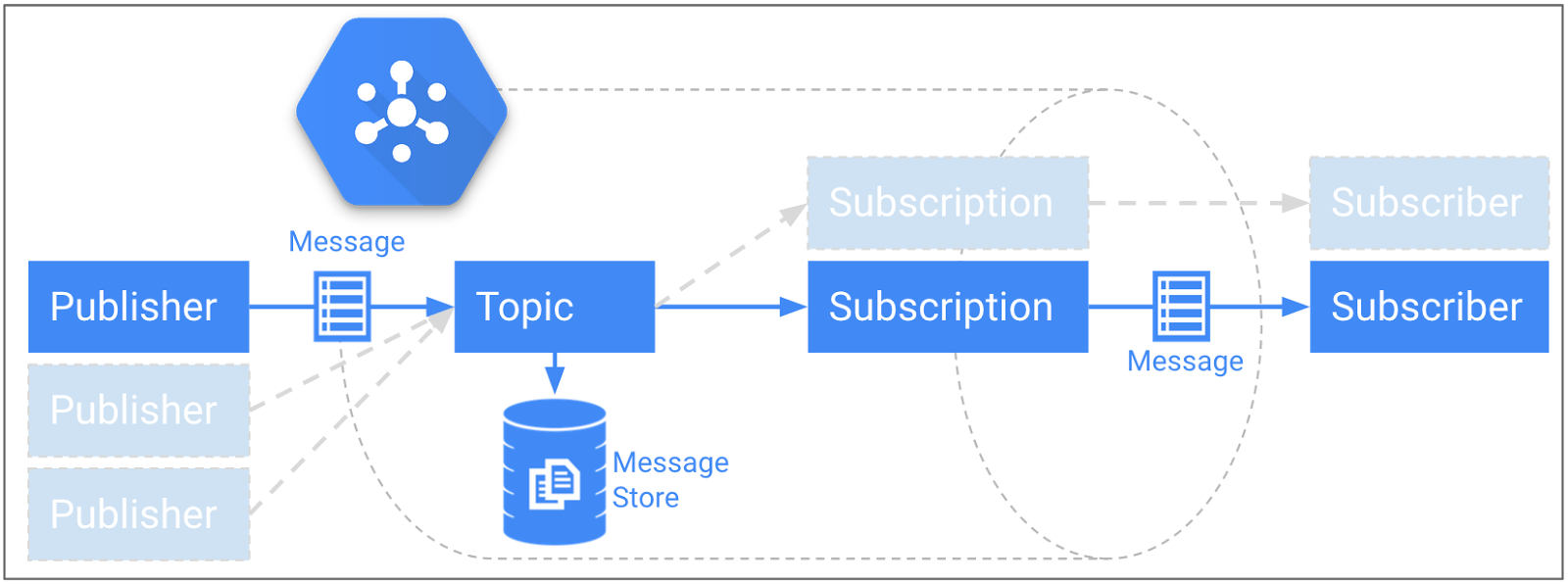
Figura 3: modelo de publicação/assinatura do Pub/Sub com armazenamento permanente
É possível escolher o número de tópicos e o agrupamento de cada um. Como há uma relação direta entre o número de tópicos e o número de pipelines do Dataflow que você cria, é melhor agrupar eventos conectados logicamente. Por exemplo, pense no editor como um dispositivo móvel individual ou um servidor de jogo com vários editores para um único tópico. Tudo o que é necessário é a capacidade de autenticar e enviar uma mensagem formatada de maneira adequada pelo HTTPS.
Depois que uma mensagem (nesse caso, um evento de telemetria do jogador) é recebida pelo serviço Pub/Sub e armazenada de forma durável no Message Store até que cada assinatura de tópico recupere essa mensagem.
Pipeline de streaming do Dataflow
Com o Dataflow, você tem uma linguagem de alto nível para descrever com facilidade os pipelines de processamento de dados. É possível executar esses pipelines usando o serviço gerenciado do Dataflow. O pipeline do Dataflow é executado no modo de streaming e recebe mensagens do tópico do Pub/Sub à medida que chegam por uma assinatura. Em seguida, o Dataflow executa o processamento necessário antes de elas serem adicionadas a uma tabela do BigQuery.
Esse processamento pode envolver simples operações de elemento como converter todos os nomes de usuário para letras minúsculas ou fazer a junção dos elementos com outras fontes de dados, por exemplo, uma tabela de nomes de usuário com as estatísticas dos jogadores.
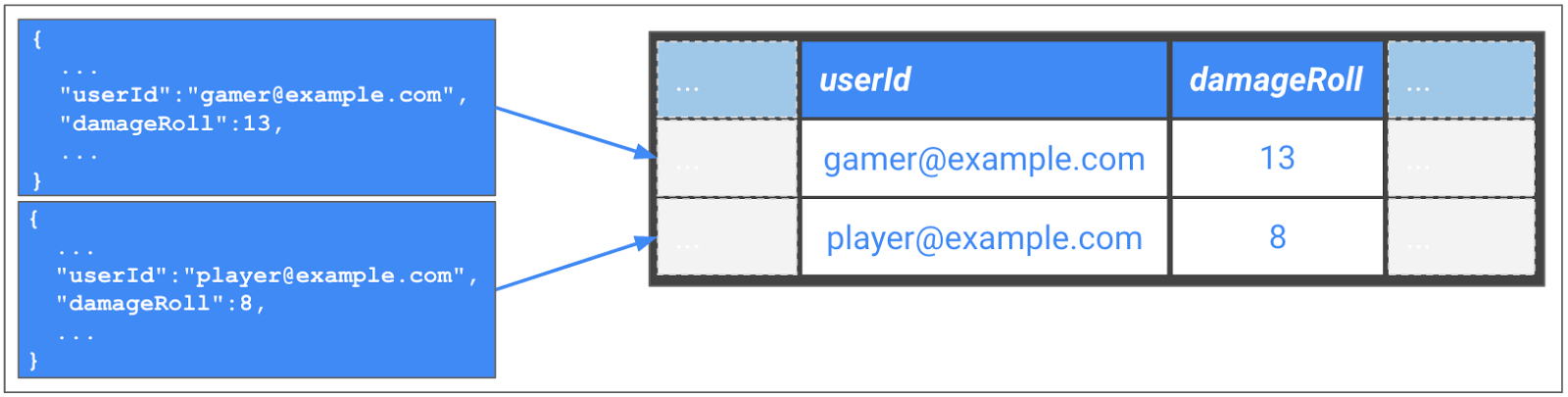
Figura 4: transformar mensagens JSON no formato de tabela do BigQuery
Com o Dataflow, você consegue executar várias tarefas de processamento de dados, incluindo a validação em tempo real dos dados de entrada. Um caso de uso é a detecção de fraudes, por exemplo, destacar um jogador com pontos máximos de acerto fora do intervalo válido. Outro caso de uso é a limpeza dos dados, por exemplo, garantir que a mensagem de evento esteja corretamente formatada e corresponda ao esquema do BigQuery.
No exemplo da figura 4, a mensagem JSON original é decodificada do servidor de jogo e convertida em um esquema do BigQuery. O principal é que você não precisa gerenciar servidores ou máquinas virtuais para executar essa ação. O Dataflow faz o trabalho de iniciar, executar e interromper recursos de computação para processar o pipeline em paralelo. Além disso, é possível reutilizar o mesmo código para os processamentos em streaming e em lote.
Com o SDK do Dataflow, você executa o pipeline separadamente do programa do Dataflow. Seu programa do Dataflow cria o pipeline e o código que você escreveu gera uma série de etapas a serem executadas por um executor de pipeline. O executor de pipeline pode ser o serviço gerenciado do Dataflow no Google Cloud, um serviço de terceiros como o Spark e o Flink ou um executor de pipeline local, que faz isso diretamente no ambiente local, o que é útil principalmente para fins de desenvolvimento e testes.
O Dataflow garante que cada elemento seja processado exatamente uma vez. Além disso, ele oferece janelas de tempo e gatilhos para agregar eventos com base na hora real em que ocorreram (hora do evento) em vez da hora em que são enviados para o Dataflow (hora de processamento). Algumas mensagens podem ficar desatualizadas em relação à origem devido a problemas na conexão móvel da Internet ou de bateria descarregada, mas ainda assim é recomendável agrupar eventos por sessão de usuário. O recurso integrado de janela de sessão do Dataflow é compatível com isso. Consulte The world beyond batch: Streaming 101 para ler uma excelente introdução sobre as estratégias de janela de dados.
Como alternativa, caso os eventos tenham um campo exclusivo de sessão como um identificador exclusivo universal (UUID, na sigla em inglês), use essa chave para agrupar os eventos relacionados. A melhor escolha depende do cenário específico.
BigQuery: armazenamento de dados totalmente gerenciado para análise de dados em grande escala
O BigQuery consiste de duas partes principais: um sistema de armazenamento que fornece persistência de dados com redundância geográfica e alta disponibilidade, e um mecanismo de análise que permite executar consultas similares a SQL em grandes conjuntos de dados. No BigQuery, os dados são organizados em conjuntos de dados que contêm várias tabelas. O BigQuery exige que um esquema seja definido para cada tabela, e a função principal do Dataflow na seção anterior era estruturar os dados brutos de eventos formatados em JSON formando uma estrutura de esquema do BigQuery que use o conector integrado do BigQuery.
Depois que esses dados são carregados em uma tabela do BigQuery, as consultas SQL interativas podem ser executadas nessa tabela para que informações valiosas seja extraídas. Ele foi desenvolvido para escalas muito grandes e permite que você execute consultas de agregação em conjuntos de dados na escala de petabytes com tempos rápidos de resposta. Isso é ótimo quando aplicado em análises interativas.
Ferramentas de visualização de dados
Com o Looker Studio, é possível criar e compartilhar painéis interativos com acesso a uma ampla variedade de fontes de dados, incluindo o BigQuery.
O BigQuery também se integra a ferramentas de visualização e BI conhecidas, como o Looker (em inglês). Por fim, é possível executar consultas do BigQuery diretamente do Planilhas Google e do Microsoft Excel.
Processamento em massa usando padrão de lote
O outro padrão principal é o processamento normal de grandes conjuntos de dados vinculados que não precisam ser processados em tempo real. Os pipelines de lote geralmente são usados para criar relatórios ou são combinados com origens em tempo real para oferecer a situação ideal: dados históricos confiáveis que incluam as informações mais recentes, provenientes dos pipelines de stream em tempo real.
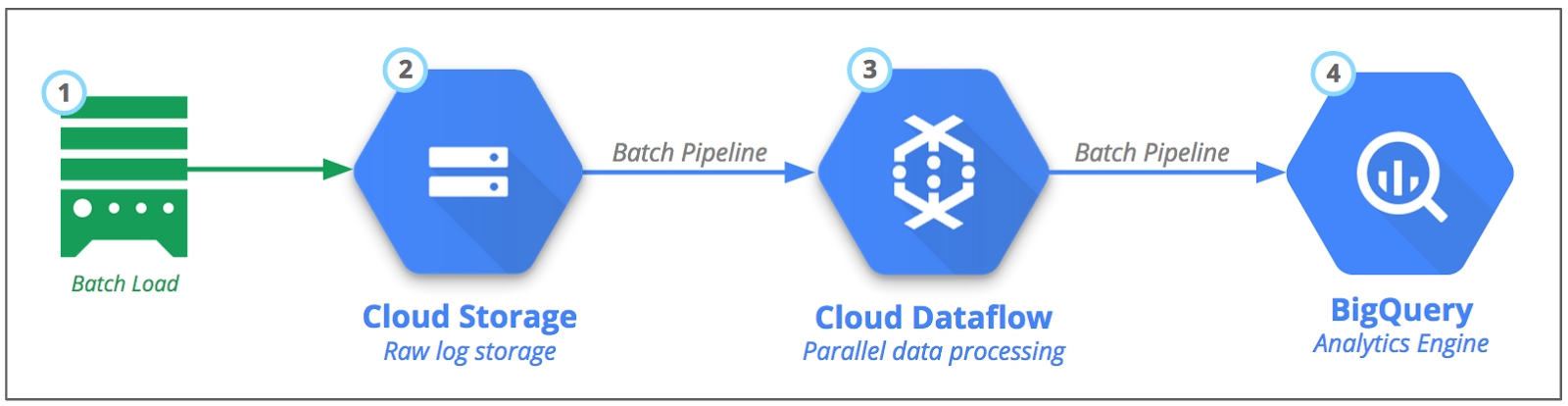
Figura 5: processamento em lote de eventos e registros dos servidores de jogo
O Cloud Storage é o local recomendado para armazenar grandes arquivos. Ele é um serviço de armazenamento de objetos durável, de alta disponibilidade e custo acessível. Mas então surge a primeira dúvida: como colocar os dados no Cloud Storage? A resposta depende das suas fontes de dados, e esse é o assunto das próximas seções. Você aprenderá sobre três cenários diferentes de fonte de dados: local, outros provedores de nuvem e o Google Cloud.
Cenário 1: transferir arquivos de servidores locais
Há vários métodos para transferir arquivos de registro do seu data center local com segurança. A maneira mais comum é usar o utilitário de linha de comando de código aberto gsutil para configurar as transferências recorrentes de arquivos. Entre os recursos disponíveis no comando gsutil, estão incluídos os uploads de vários threads em paralelo quando há muitos arquivos, a sincronização automática de um diretório local, os uploads que podem ser retomados para arquivos grandes e, para arquivos muito grandes, a divisão deles em partes menores, além do upload em paralelo. Esses recursos reduzem o tempo de upload e
maximizam o uso da conexão de rede.
Se você não tiver largura de banda suficiente para conseguir uploads em tempo hábil, pode se conectar diretamente ao Google Cloud usando peering direto ou peering de operadora. Como alternativa, se você preferir enviar mídias físicas, use o Transfer Appliance off-line.
Cenário 2: transferir arquivos de outros provedores de nuvem
Alguns arquivos de registro podem estar armazenados em outros provedores de nuvem. Talvez você execute um servidor de jogo e a saída dos registros seja enviada para o serviço de armazenamento desse provedor. Ou o serviço que você usa tem um destino de armazenamento padrão. Por exemplo, o Amazon Cloudfront, um serviço de rede de entrega de conteúdo (CDN, na sigla em inglês), armazena os registros em um bucket do Amazon S3. Felizmente, transferir os dados do Amazon S3 para o Cloud Storage é bem simples.
Se você está transferindo grandes quantidades de arquivos diariamente do Amazon S3 para o Cloud Storage, você pode usar o Serviço de transferência de armazenamento para transferir arquivos de fontes, incluindo os serviços Amazon S3 e HTTP/HTTPS. As transferências recorrentes podem ser configuradas de maneira regular e várias opções avançadas estão disponíveis nesse serviço de transferência. Ele usa a grande capacidade de largura de banda entre os provedores de nuvem e técnicas avançadas de otimização de largura de banda para proporcionar altas velocidades de transferência.
A diretriz é usar esse serviço para 1 TB a 10 TB por transferência, já que em vários servidores ele pode economizar a sobrecarga operacional da execução da ferramenta gsutil, mencionada no cenário 1. Para transferências menores ou quando é necessário mover dados várias vezes por dia, use a ferramenta gsutil, mencionada no cenário 1.
Cenário 3: os dados já estão no Google Cloud
Em alguns casos, os dados já são armazenados automaticamente no Cloud Storage, por padrão. Por exemplo, os dados da Google Play Store, incluindo revisões, relatórios financeiros, instalações, falhas e relatórios de ANR, estão disponíveis em um bucket do Cloud Storage, na conta de desenvolvedor do Google Play. Quando isso acontece, mantenha os dados no bucket original para onde foram exportados, a menos que haja razões para movê-los para outro bucket.
Padrão de serviço de transferência assíncrona
Uma abordagem escalável e de longa duração é a implementação de um padrão de serviço de transferência assíncrona, em que você usa uma ou mais filas e mensagens para iniciar as transferências com base em eventos ou acionadores. Por exemplo, quando um novo arquivo de registro é gravado no disco ou no armazenamento de arquivos de origem, uma mensagem é enviada para a fila. Os trabalhadores executam o job de transferência desse objeto para o Cloud Storage, removendo a mensagem da fila somente após a conclusão dele.
Padrão alternativo de lote: carregamento direto do Cloud Storage para o BigQuery
Talvez você se pergunte se é estritamente necessário usar o Dataflow entre o Cloud Storage e o BigQuery. Para carregar os arquivos JSON diretamente no Cloud Storage, forneça um esquema e inicie um job de carregamento Ou consulte diretamente os arquivos de backup CSV, JSON ou Datastore em um bucket do Cloud Storage. Essa pode ser uma solução aceitável para começar, mas lembre-se dos benefícios de usar o Dataflow:
Transformar os dados antes de confirmar para o armazenamento. Por exemplo, é possível agregar os dados antes de carregá-los para o BigQuery, agrupando tipos diferentes de dados em tabelas separadas. Isso ajuda a reduzir os custos do BigQuery, porque minimiza o número de linhas a serem consultadas. Em um cenário em tempo real, use o Dataflow para calcular placares em sessões individuais ou coortes, como guildas e equipes.
Outra opção é usar os pipelines de dados em lote e de streaming escritos no Dataflow. Altere a fonte e o coletor de dados, por exemplo, do Pub/Sub para o Cloud Storage, e o mesmo código funcionará nos dois cenários.
Maior flexibilidade em termos de esquema de banco de dados. Por exemplo, quando campos são adicionados aos eventos ao longo do tempo, talvez seja necessário adicionar os dados brutos JSON a um campo "pega-tudo" no esquema e usar a funcionalidade de consulta de JSON do BigQuery para consultar esse campo. Desse modo, você consegue consultar várias tabelas do BigQuery, mesmo que o evento de origem requeira esquemas diferentes. Isso é mostrado na figura 6.
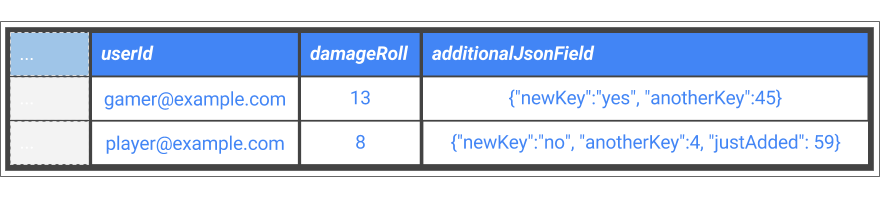
Figura 6: coluna extra para capturar novos campos de evento no JSON bruto
Considerações operacionais das arquiteturas de referência
Depois de estabelecer e criar os pipelines, é importante monitorar o desempenho e as exceções. A interface do usuário de monitoramento do Dataflow apresenta uma visualização gráfica dos jobs do pipeline de dados, além das principais métricas. Veja uma amostra disso na captura de tela da figura 7.

Figura 7: console de monitoramento integrado do Dataflow
O console do Dataflow apresenta informações sobre o gráfico de execução do pipeline, bem como estatísticas de desempenho atuais, como o número de mensagens processadas em cada etapa, o atraso estimado do sistema e a marca d'água de dados. Para informações mais detalhadas, o Dataflow é integrado ao serviço Cloud Logging, conforme mostrado no exemplo da captura de tela na Figura 8.

Figura 8: Cloud Logging integrado ao Dataflow