This document introduces best practices for implementing machine learning (ML) on Google Cloud, with a focus on custom-trained models based on your data and code. We provide recommendations on how to develop a custom-trained model throughout the machine learning workflow, including key actions and links for further reading.
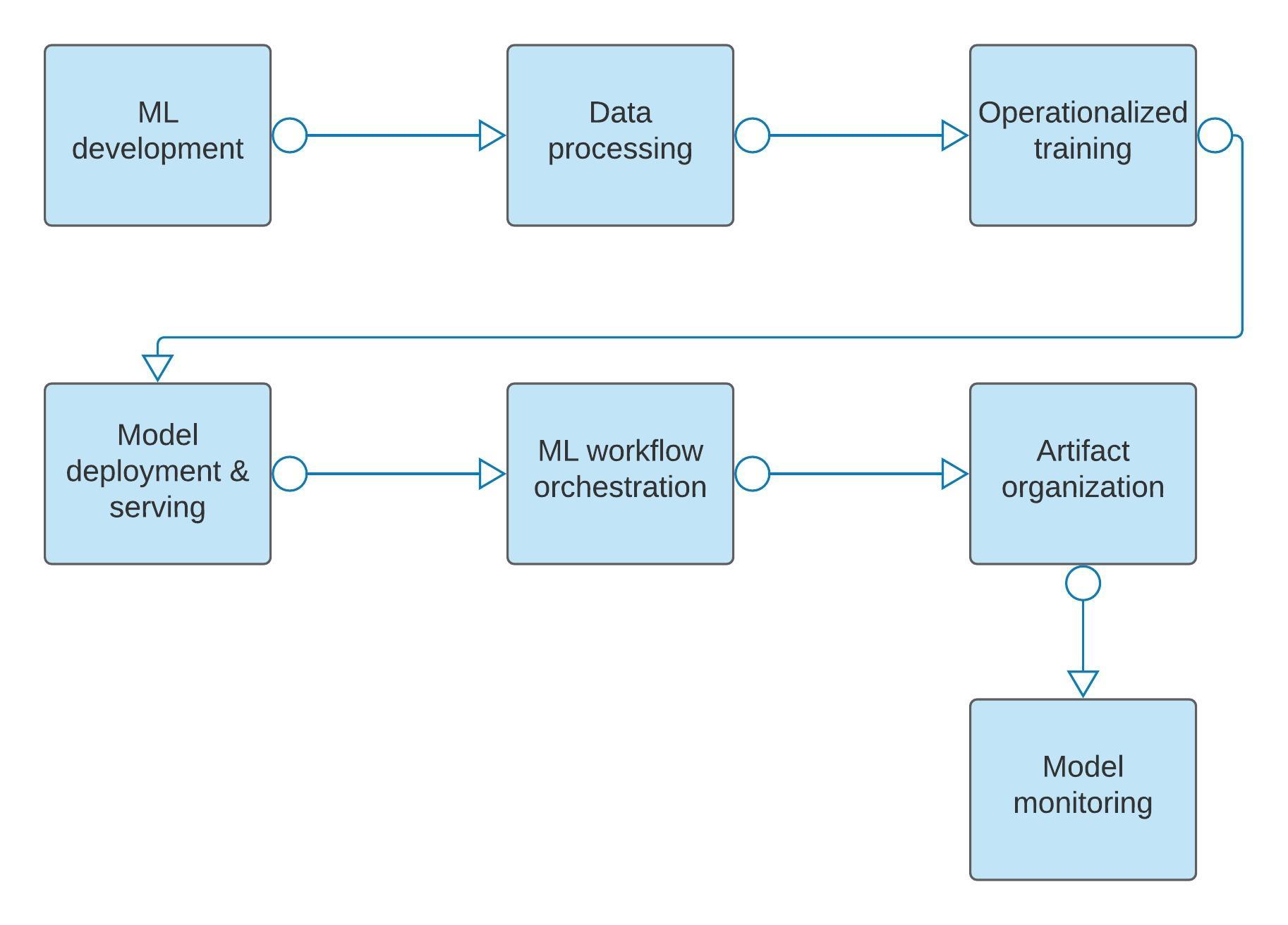
The following diagram gives a high-level overview of the stages in the ML workflow addressed in this document, which include:
- ML development
- Data processing
- Operationalized training
- Model deployment and serving
- ML workflow orchestration
- Artifact organization
- Model monitoring
The document is not an exhaustive list of recommendations; its goal is to help data scientists and machine learning architects understand the scope of activities involved in using ML on Google Cloud and plan accordingly. And while ML development alternatives like AutoML are mentioned in Use recommended tools and products, this document focuses on custom-trained models.
Before following the best practices in this document, we recommend that you read Introduction to Vertex AI.
For the purposes of this document, it is assumed that:
You are primarily using Google Cloud services; hybrid and on-premises approaches are not addressed in this document.
You plan to collect training data and store it in Google Cloud.
You have an intermediate-level knowledge of machine learning, big data tools, and data preprocessing, as well as a familiarity with Cloud Storage, BigQuery, and Google Cloud fundamentals.
If you are new to machine learning, check out Google's Machine Learning Crash Course.
Use recommended tools and products
The following table lists recommended tools and products for each phase of the ML workflow as outlined in this document:
| Machine learning workflow step | Recommended tools and products |
| ML environment setup | |
| ML development | |
| Data processing | |
| Operationalized training | |
| Model deployment and serving | |
| ML workflow orchestration | |
| Artifact organization | |
| Model monitoring |
Google offers AutoML, Vertex AI Forecasting, and BigQuery ML as pre-built training routine alternatives to Vertex AI custom-trained model solutions. The following table provides recommendations about when to use these options for Vertex AI.
| ML environment | Description | Choose this environment if... |
| BigQuery ML | BigQuery ML brings together data, infrastructure, and pre-defined model types into a single system. |
|
| AutoML (in the context of Vertex AI) | AutoML provides training routines for common problems like image classification and tabular regression. Nearly all aspects of training and serving a model, like choosing an architecture, hyperparameter tuning, and provisioning machines, are handled for you. |
|
| Vertex AI custom trained models | Vertex lets you run your own custom training routines and deploy models of any type on serverless architecture. Vertex AI offers additional services, like hyperparameter tuning and monitoring, to make it easier to develop a model. See Choosing a custom training method. |
|
Machine learning environment setup
Use Vertex AI Workbench instances for experimentation and development.
Create a Vertex AI Workbench instance for each team member.
Store your ML resources and artifacts based on your corporate policy.
Use Vertex AI SDK for Python..
Use Vertex AI Workbench instances for experimentation and development
Regardless of your tooling, we recommend that you use Vertex AI Workbench instances for experimentation and development, including writing code, starting jobs, running queries, and checking status. Vertex AI Workbench instances let you access all of Google Cloud's data and artificial intelligence (AI) services in a simple, reproducible way.
Vertex AI Workbench instances also give you a secure set of software and access patterns right out of the box. It is a common practice to customize Google Cloud properties like network and Identity and Access Management, and software (through a container) associated with a Vertex AI Workbench instance. See Introduction to Vertex AI and Introduction to Vertex AI Workbench instances for more information.
Create a Vertex AI Workbench instance for each team member
Create a Vertex AI Workbench instance for each member of your data science team. If a team member is involved in multiple projects, especially projects that have different dependencies, we recommend using multiple instances, treating each instance as a virtual workspace. Note that you can stop Vertex AI Workbench instances when they are not being used.
Store your ML resources and artifacts based on your corporate policy
The simplest access control is to store both your raw and Vertex AI resources and artifacts, such as datasets and models, in the same Google Cloud project. More typically, your corporation has policies that control access. In cases where your resources and artifacts are stored across projects, you can configure your corporate cross-project access control with Identity and Access Management (IAM).
Use Vertex AI SDK for Python
Use Vertex AI SDK for Python, a Pythonic way to use Vertex AI for your end-to-end model building workflows, which works seamlessly with your favorite ML frameworks including PyTorch, TensorFlow, XGBoost, and scikit-learn.
Alternatively, you can use the Google Cloud console, which supports the functionality of Vertex AI as a user interface through the browser.
Machine learning development
Prepare training data.
Store structured and semi-structured data in BigQuery.
Store image, video, audio and unstructured data on Cloud Storage.
Use Vertex AI Data Labeling for unstructured data.
Use Vertex AI Feature Store with structured data.
Avoid storing data in block storage.
Use Vertex AI TensorBoard and Vertex AI Experiments for analyzing experiments.
Train a model within a Vertex AI Workbench instance for small datasets.
Maximize your model's predictive accuracy with hyperparameter tuning.
Use a Vertex AI Workbench instance to understand your models.
Use feature attributions to gain insights into model predictions.
Machine learning development addresses preparing the data, experimenting, and evaluating the model. When solving a machine learning problem, it is typically necessary to build and compare many different models to figure out what works best.
Typically, data scientists train models using different architectures, input data sets, hyperparameters, and hardware. Data scientists evaluate the resulting models by looking at aggregate performance metrics like accuracy, precision, and recall on test datasets. Finally, data scientists evaluate the performance of the models against particular subsets of their data, different model versions, and different model architectures.
Prepare training data
The data used to train a model can originate from any number of systems, for example, logs from an online service system, images from a local device, or documents scraped from the web.
Regardless of your data's origin, extract data from the source systems and convert to the format and storage (separate from the operational source) optimized for ML training. For more information on preparing training data for use with Vertex AI, see Prepare training data for use with Vertex AI.
Store structured and semi-structured data in BigQuery
If you're working with structured or semi-structured data, we recommend that you store all data in BigQuery, following BigQuery's recommendation for project structure. In most cases, you can store intermediate, processed data in BigQuery as well. For maximum speed, it's better to store materialized data instead of using views or subqueries for training data.
Read data out of BigQuery using the BigQuery Storage API. For artifact tracking, consider using a managed tabular dataset. The following table lists Google Cloud tools that make it easier to use the API:
| If you're using... | Use this Google Cloud tool |
| TensorFlow or Keras | tf.data.dataset reader for BigQuery |
| TFX | BigQuery client |
| Dataflow | BigQuery I/O Connector |
| Any other framework (such as PyTorch, XGBoost, or scilearn-kit) | BigQuery Python client library |
Store image, video, audio and unstructured data on Cloud Storage
Store these data in large container formats on Cloud Storage. This applies to sharded TFRecord files if you're using TensorFlow, or Avro files if you're using any other framework.
Combine many individual images, videos, or audio clips into large files, as this will improve your read and write throughput to Cloud Storage. Aim for files of at least 100mb, and between 100 and 10,000 shards.
To enable data management, use Cloud Storage buckets and directories to group the shards. For more information, see What is Cloud Storage?
Use Vertex AI Data Labeling for unstructured data
You might need humans to provide labels to your data, especially when it comes to unstructured data. Use Vertex AI Data Labeling for this work. You can hire your own labelers and use Google Cloud's software for managing their work, or you can use Google's in-house labelers for the task. For more information, see Requesting data labeling.
Use Vertex AI Feature Store with structured data
When you're training a model with structured data, irrespective of where you're training that model, follow these steps:
Search Vertex AI Feature Store to determine if existing features satisfy your requirements.
Open Vertex AI Feature Store and do a search to see if a feature already exists that relates your use case or covers the signal that you're interested in passing to the model.
If there are features in Vertex AI Feature Store that you want to use, fetch those features for your training labels using Vertex AI Feature Store's batch serving capability.
Create a new feature. If Vertex AI Feature Store doesn't have the features you need, create a new feature using data from your data lake.
Fetch raw data from your data lake and write your scripts to perform the necessary feature processing and engineering.
Join the feature values you fetched from Vertex AI Feature Store and the new feature values that you created from the data lake. Merging those feature values produces the training data set.
Set up a periodic job to compute updated values of the new feature. Once you determine that a feature is useful and you want to put it into production, set up a regularly scheduled job with the required cadence to compute updated values of that feature and ingest it into Vertex AI Feature Store. By adding your new feature to Vertex AI Feature Store, you automatically have a solution to do online serving of the features (for online prediction use cases), and you can share your feature with others in the organization that may get value from it for their own ML models.
To learn more, see Vertex AI Feature Store.
Avoid storing data in block storage
Avoid storing data in block storage, like Network File Systems or on virtual machine (VM) hard disks. Those tools are harder to manage than Cloud Storage or BigQuery, and often come with challenges in tuning performance. Similarly, avoid reading data directly from databases like Cloud SQL. Instead, store data in BigQuery and Cloud Storage. For more information, see Cloud Storage documentation and Introduction to loading data for BigQuery.
Use Vertex AI TensorBoard and Vertex AI Experiments for analyzing experiments
When developing models, use Vertex AI TensorBoard to visualize and compare specific experiments—for example, based on hyperparameters. Vertex AI TensorBoard is an enterprise-ready managed Vertex AI TensorBoard service with a cost-effective, secure solution that lets data scientists and ML researchers collaborate easily by making it seamless to track, compare, and share their experiments. Vertex AI TensorBoard enables tracking experiment metrics like loss and accuracy over time, visualizing the model graph, projecting embeddings to a lower dimensional space, and much more.
Use Vertex AI Experiments to integrate with Vertex ML Metadata and to log and build linkage across parameters, metrics, and dataset and model artifacts.
Train a model within a Vertex AI Workbench instance for small datasets
Training a model within the Vertex AI Workbench instance may be sufficient for small datasets, or subsets of a larger dataset. It may be helpful to use the training service for larger datasets or for distributed training. Using the Vertex AI training service is also recommended to productionize training even on small datasets if the training is carried out on a schedule or in response to the arrival of additional data.
Maximize your model's predictive accuracy with hyperparameter tuning
To maximize your model's predictive accuracy use hyperparameter tuning, the automated model enhancer provided by Vertex AI Training which takes advantage of the processing infrastructure of Google Cloud and Vertex AI Vizier to test different hyperparameter configurations when training your model. Hyperparameter tuning removes the need to manually adjust hyperparameters over the course of numerous training runs to arrive at the optimal values.
To learn more about hyperparameter tuning, see Overview of hyperparameter tuning and Using hyperparameter tuning.
Use a Vertex AI Workbench instance to understand your models
Use a Vertex AI Workbench instance to evaluate and understand your models. In addition to built-in common libraries like scikit-learn, Vertex AI Workbench instances include the What-if Tool (WIT) and Language Interpretability Tool (LIT). WIT lets you interactively analyze your models for bias using multiple techniques, while LIT helps you understand natural language processing model behavior through a visual, interactive, and extensible tool.
Use feature attributions to gain insights into model predictions
Vertex Explainable AI is an integral part of the ML implementation process, offering feature attributions to provide insights into why models generate predictions. By detailing the importance of each feature that a model uses as input to make a prediction, Vertex Explainable AI helps you better understand your model's behavior and build trust in your models.
Vertex Explainable AI supports custom-trained models based on tabular and image data.
For more information about Vertex Explainable AI, see:
Data processing
Use BigQuery to process tabular data.
Use Dataflow to process data.
Use Dataproc for serverless Spark data processing.
Use managed datasets with Vertex ML Metadata.
The recommended approach for processing your data depends on the framework and data types you're using. This section provides high-level recommendations for common scenarios.
Use BigQuery to process structured and semi-structured data
Use BigQuery for storing unprocessed structured or semi-structured data. If you're building your model using BigQuery ML, use the transformations built into BigQuery for preprocessing data. If you're using AutoML, use the transformations built into AutoML for preprocessing data. If you're building a custom model, using the BigQuery transformations may be the most cost-effective method.
Use Dataflow to process data
With large volumes of data, consider using Dataflow, which uses the Apache Beam programming model. You can use Dataflow to convert the unstructured data into binary data formats like TFRecord, which can improve performance of data ingestion during the training process.
Use Dataproc for serverless Spark data processing
Alternatively, if your organization has an investment in an Apache Spark codebase and skills, consider using Dataproc. Use one-off Python scripts for smaller datasets that fit into memory.
If you need to perform transformations that are not expressible in Cloud SQL or are for streaming, you can use a combination of Dataflow and the pandas library.
Use managed datasets with ML metadata
After your data is pre-processed for ML, you may want to consider using a managed dataset in Vertex AI. Managed datasets enable you to create a clear link between your data and custom-trained models, and provide descriptive statistics and automatic or manual splitting into train, test, and validation sets.
Managed datasets are not required; you may choose not to use them if you want more control over splitting your data in your training code, or if lineage between your data and model isn't critical to your application.
For more information, see Datasets and Using a managed dataset in a custom training application.
Operationalized training
Run your code in a managed service.
Operationalize job execution with training pipelines.
Use training checkpoints to save the current state of your experiment.
Prepare model artifacts for serving in Cloud Storage.
Regularly compute new feature values.
Operationalized training refers to the process of making model training repeatable, tracking repetitions, and managing performance. While Vertex AI Workbench instances are convenient for iterative development on small datasets, we recommend that you operationalize your code to make it reproducible and scale to large datasets. In this section, we discuss tooling and best practices for operationalizing your training routines.
Run your code in a managed service
We recommend that you run your code in either Vertex AI training service or Vertex AI Pipelines.
Optionally, you can run your code directly in a Deep Learning Virtual Machine container or on Compute Engine; however, we don't recommend this approach because the Vertex AI managed services provide automatic scaling and burst capability that is more cost effective.
Operationalize job execution with training pipelines
Create training pipelines to operationalize training job execution on
Vertex AI. A training pipeline, which is different than a general
ML pipeline,
encapsulates training jobs. To learn more about training
pipelines, see Creating training pipelines
and REST Resource: projects.locations.trainingPipelines.
Use training checkpoints to save the current state of your experiment
The ML workflow in this document assumes that you're not training interactively. If your model fails and isn't checkpointed, the training job or pipeline will finish and the data will be lost because the model isn't in memory. To prevent this scenario, make it a practice to always use training checkpoints to ensure you don't lose state.
We recommend that you save training checkpoints in Cloud Storage. Create a different folder for each experiment or training run.
To learn more about checkpoints, see Training checkpoints for TensorFlow Core, Saving and loading a General Checkpoint in PyTorch, and Machine Learning Design Patterns.
Prepare model artifacts for serving in Cloud Storage
For custom-trained models or custom containers, store your model artifacts in a Cloud Storage bucket, where the bucket's region matches the regional endpoint you're using for production. See Bucket regions for more information.
Store your Cloud Storage bucket in the same Google Cloud project. If your Cloud Storage bucket is in a different Google Cloud project, you need to grant Vertex AI access to read your model artifacts.
If you're using a Vertex AI pre-built container, ensure that your model artifacts have filenames that exactly match these examples:
TensorFlow SavedModel:
saved_model.pbScikit-learn:
model.joblibormodel.pklXGBoost:
model.bstPyTorch:
model.pth
To learn how to save your model in the form of one or more model artifacts, see Exporting model artifacts for prediction.
Regularly compute new feature values
Often, a model will use a subset of features sourced from Vertex AI Feature Store. The features in Vertex AI Feature Store will already be ready for online serving. For any new features created by data scientist by sourcing data from the data lake, we recommend scheduling the corresponding data processing and feature engineering jobs (or ideally Dataflow) to regularly compute the new feature values at the required cadence, depending upon feature freshness needs, and ingesting them into Vertex AI Feature Store for online or batch serving.
Model deployment and serving
Specify the number and types of machines you need.
Plan inputs to the model.
Turn on automatic scaling.
Model deployment and serving refers to putting a model into production. The output of the training job is one or more model artifacts stored on Cloud Storage, which you can upload to Vertex AI Model Registry so the file can be used for prediction serving. There are two types of prediction serving: batch prediction is used to score batches of data at a regular cadence, and online prediction is used for near real-time scoring of data for live applications. Both approaches let you obtain predictions from trained models by passing input data to a cloud-hosted ML model and getting inferences for each data instance.To learn more, see Getting batch predictions and Get online predictions from custom-trained models.
For lower latency for peer-to-peer requests between the client and the model server, use Vertex AI private endpoints. These are particularly useful if your application that makes the prediction requests and the serving binary are within the same local network. You can avoid the overhead of internet routing and make a peer-to-peer connection using Virtual Private Cloud.
Specify the number and types of machines you need
To deploy your model for prediction, choose hardware that is appropriate for your model, like different central processing unit (CPU) virtual machine (VM) types or graphics processing unit (GPU) types. For more information, see Specifying machine types or scale tiers.
Plan inputs to the model
In addition to deploying the model, you'll need to determine how you're going to pass inputs to the model. If you're using batch prediction you can fetch data from the data lake, or from Vertex AI Feature Store batch serving API. If you are using online prediction, you can send input instances to the service and it returns your predictions in the response. For more information, see Response body details.
If you are deploying your model for online prediction, you need a low latency, scalable way to serve the inputs or features that need to be passed to the model's endpoint. You can either do this by using one of the many Database services on Google Cloud, or you can use Vertex AI Feature Store's online serving API. The clients calling the online prediction endpoint can first call the feature serving solution to fetch the feature inputs, and then call the prediction endpoint with those inputs.
Streaming ingestion lets you make real-time updates to feature values. This method is useful when having the latest available data for online serving is a priority. For example, you can ingest streaming event data and, within a few seconds, Vertex AI Feature Store streaming ingestion makes that data available for online serving scenarios.
You can additionally customize the input (request) and output (response) handling and format to and from your model server using custom prediction routines.
Turn on automatic scaling
If you use the online prediction service, in most cases we recommend that you turn on automatic scaling by setting minimum and maximum nodes. For more information, see Get predictions for a custom trained model. To ensure a high availability service level agreement (SLA), set automatic scaling with a minimum of two nodes.
To learn more about scaling options, see Scaling machine learning predictions.
Machine learning workflow orchestration
Use Vertex AI Pipelines to orchestrate the ML workflow.
Use Kubeflow Pipelines for flexible pipeline construction.
Vertex AI provides ML workflow orchestration to automate the ML workflow with Vertex AI Pipelines, a fully managed service that allows you to retrain your models as often as necessary. While retraining enables your models to adapt to changes and maintain performance over time, consider how much your data will change when choosing the optimal model retraining cadence.
ML orchestration workflows work best for customers who have already designed and built their model, put it into production, and want to determine what is and isn't working in the ML model. The code you use for experimentation will likely be useful for the rest of the ML workflow with some modification. To work with automated ML workflows, you need to be fluent in Python, understand basic infrastructure like containers, and have ML and data science knowledge.
Use Vertex AI Pipelines to orchestrate the ML workflow
While you can manually start each data process, training, evaluation, test, and deployment, we recommend that you use Vertex AI Pipelines to orchestrate the flow. For detailed information, see MLOps level 1: ML pipeline automation.
Vertex AI Pipelines supports running DAGs generated by KubeFlow, TensorFlow Extended (TFX) and Airflow.
Use Kubeflow Pipelines for flexible pipeline construction
Kubeflow Pipelines SDK is recommended for most users who want to author managed pipelines. Kubeflow Pipelines is flexible, letting you use simple code to construct pipelines; and it provides Google Cloud Pipeline Components, which lets you include Vertex AI functionality like AutoML in your pipeline. To learn more about Kubeflow Pipelines, see Kubeflow Pipelines and Vertex AI Pipelines.
Artifact organization
Organize your ML model artifacts.
Use a source control repository for pipeline definitions and training code.
Artifacts are outputs resulting from each step in the ML workflow. It is a best practice to organize them in a standardized way.
Organize your ML model artifacts
Store your artifacts in these locations:
| Storage location | Artifacts |
| Source control repo |
|
| Experiments and ML metadata |
|
| Vertex AI Model Registry |
|
| Artifact Registry |
|
| Vertex AI Prediction |
|
Use a source control repository for pipeline definitions and training code
You can use source control to version control your ML pipelines and the custom components you build for those pipelines. Use Artifact Registry to store, manage, and secure your Docker container images without making them publicly visible.
Model monitoring
Use skew and drift detection.
Fine tune alert thresholds.
Use feature attributions to detect data drift or skew.
Once you deploy your model into production, you need to monitor performance to ensure that the model is performing as expected. Vertex AI provides two ways to monitor your ML models:
Skew detection: This approach looks for the degree of distortion between your model training and production data
Drift detection: In this type of monitoring, you're looking for drift in your production data. Drift occurs when the statistical properties of the inputs and the target, which the model is trying to predict, change over time in unforeseen ways. This causes problems because the predictions could become less accurate as time passes.
Model monitoring works for structured data, like numerical and categorical features, but not for unstructured data, like images. For more information, see Monitoring models for feature skew or drift.
Use skew and drift detection
As much as possible, use skew detection because knowing that your production data has deviated from your training data is a strong indicator that your model isn't performing as expected in production. For skew detection, set up the model monitoring job by providing a pointer to the training data that you used to train your model.
If you do not have access to the training data, turn on drift detection so that you'll know when the inputs change over time.
Use drift detection to monitor whether your production data is deviating over time. For drift detection, enable the features you want to monitor and the corresponding thresholds to trigger an alert.
Fine tune alert thresholds
Tune the thresholds used for alerting so you know when skew or drift occurs in your data. Alert thresholds are determined by the use case, the user's domain expertise, and by initial model monitoring metrics. To learn how to use monitoring to create dashboards or configure alerts based on the metrics, see Cloud monitoring metrics.
Use feature attributions to detect data drift or skew
You can use feature attributions in Vertex Explainable AI to detect data drift or skew as an early indicator that model performance may be degrading. For example, if your model originally relied on five features to make predictions in your training and test data, but the model began to rely on entirely different features when it went into production, feature attributions would help you detect this degradation in model performance.
This is particularly useful for complex feature types, like embeddings and time series, which are difficult to compare using traditional skew and drift methods. With Vertex Explainable AI, feature attributions can indicate when model performance is degrading.
What's next
- Vertex AI documentation
- Practitioners guide to MLOps:A framework for continuous delivery and automation of machine learning
- Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.