Este artigo é a segunda parte de uma série de quatro partes que discute como prever o valor de vida útil do cliente (CLV, na sigla em inglês) usando o AI Platform no Google Cloud.
Os artigos desta série incluem:
- Parte 1: Introdução. Apresenta o conceito de valor de vida útil do cliente (CLV) e duas técnicas de modelagem para prever o CLV.
- Parte 2: Como treinar o modelo (este artigo). Discute como preparar os dados e treinar os modelos.
- Parte 3: Como implantar em produção. Descreve como implantar os modelos discutidos na parte 2 em um sistema de produção.
- Parte 4: como usar as tabelas do AutoML. Mostra como usar tabelas do AutoML para criar e implantar um modelo.
O código para implementar o sistema está em um repositório do GitHub. Nesta série, discutimos para que serve o código e como ele é usado.
Introdução
Este artigo é a continuação da parte 1, que ensina sobre dois modelos diferentes para prever o valor de vida útil do cliente (CLV):
- modelos probabilísticos
- Modelos de rede neural profunda (DNN, na sigla em inglês), um tipo de modelo de aprendizado de máquina
Conforme observado na parte 1, um dos objetivos desta série é comparar esses modelos de previsão do CLV. Neste artigo, veja como preparar os dados, além de criar e treinar ambos os tipos de modelo. Também fornecemos algumas informações para fins de comparação.
Como instalar o código
Se você quiser seguir o processo descrito neste artigo, precisará instalar a amostra de código no GitHub.
Se a CLI gcloud estiver instalada, abra uma janela de terminal no computador para executar estes comandos. Se a CLI gcloud não estiver instalada, abra uma instância do Cloud Shel.
Clone o repositório do código de amostra:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Siga as instruções de instalação na seção Install do arquivo README para configurar o ambiente.
Preparação de dados
Veja nesta seção como conseguir e apurar os dados.
Como conseguir e apurar o conjunto de dados de origem
Antes de calcular o CLV, verifique se os dados de origem contêm pelo menos:
- o ID de cliente usado para diferenciar clientes individuais;
- o valor de compra por cliente, que mostra quanto cada cliente gastou em um horário específico;
- Data de cada compra
Neste artigo, discutimos como treinar modelos usando dados históricos de vendas do Conjunto de dados de varejo on-line disponível publicamente no repositório de aprendizado de máquina da UCI.[1]
A primeira etapa é copiar o conjunto de dados como um arquivo CSV para o Cloud Storage.
Use uma das ferramentas de carregamento do BigQuery para criar uma tabela chamada data_source. Esse nome é facultativo, mas é o mesmo utilizado pelo código no repositório do GitHub. O conjunto de dados está disponível em um bucket público associado a essa série e já foi convertido para o formato CSV.
- No seu computador ou no Cloud Shell, execute os comandos documentados na seção "Configuração" do arquivo README no repositório do GitHub.
O conjunto de dados de exemplo do Kaggle contém os campos listados na tabela a seguir. Para a abordagem que descrevemos neste artigo, você usa apenas os campos em que a coluna Usado está definida como Sim. Alguns campos não são usados diretamente, mas ajudam a criar novos campos. Por exemplo, UnitPrice e Quantity criam order_value.
| Usado | Campo | Tipo | Descrição |
|---|---|---|---|
| Não | InvoiceNo |
STRING |
Nominal. Um número inteiro de seis dígitos atribuído exclusivamente a cada transação.
Se esse código começar com a letra c, ele indica um cancelamento. |
| Não | StockCode |
STRING |
Código do produto (item). Nominal, um número integral de 5 dígitos atribuído exclusivamente a cada produto distinto. |
| Não | Description |
STRING |
Nome do produto (item). Nominal. |
| Sim | Quantity |
INTEGER |
As quantidades de cada produto (item) por transação. Numérico. |
| Sim | InvoiceDate |
STRING |
Data e hora da fatura no formato mm/dd/aa hh:mm. O dia e a hora em que cada transação foi gerada. |
| Sim | UnitPrice |
FLOAT |
Preço unitário. Numérico. O preço do produto por unidade em libras esterlinas. |
| Sim | CustomerID |
STRING |
Número do cliente. Nominal. Um número integral de 5 dígitos atribuído exclusivamente a cada cliente. |
| Não | Country |
STRING |
Nome do país. Nominal. O nome do país em que cada cliente reside. |
Como apurar os dados
Independentemente do modelo usado, é necessário executar as mesmas etapas de preparação e apuração em todos os modelos. As operações a seguir são obrigatórias para ter um conjunto de campos e registros viáveis:
- Agrupe os pedidos por dia em vez de usar
InvoiceNo, porque a unidade tempo mínimo usada pelos modelos probabilísticos nesta solução é um dia. - Mantenha apenas os campos que são úteis para modelos probabilísticos.
- Mantenha apenas os registros com quantidades de pedidos e valores monetários em número positivo, como compras.
- Mantenha apenas registros com quantidades de pedido negativas, como devoluções.
- Mantenha apenas os registros com um ID de cliente.
- Mantenha apenas os clientes que compraram algo nos últimos 90 dias.
- Mantenha apenas os clientes que compraram pelo menos duas vezes no período usado para criar atributos.
É possível realizar todas essas operações usando a consulta do BigQuery a seguir. Como nos comandos anteriores, execute o código onde você clonou o repositório do GitHub. Como os dados são antigos, a data de 12 de dezembro de 2011 é considerada a data de hoje para os fins deste artigo.
Essa consulta realiza duas tarefas. Primeiro, se o conjunto de dados em funcionamento for grande, a consulta o reduzirá. O conjunto de dados em funcionamento desta solução é muito pequeno, mas essa consulta pode reduzir um conjunto de dados extremamente grande em duas ordens de magnitude em alguns segundos.
Depois, a consulta cria um conjunto de dados de base com que você vai trabalhar, semelhante a este:
customer_id
|
order_date
|
order_value
|
order_qty_articles
|
|---|---|---|---|
| 16915 | 2011-08-04 | 173.7 | 6 |
| 15349 | 2011-07-04 | 107.7 | 77 |
| 14794 | 30/03/2011 | -33.9 | -2 |
O conjunto de dados apurado também contém o campo order_qty_articles. Esse campo é incluído apenas para ser usado pela rede neural profunda (DNN), descrita na próxima seção.
Como definir os intervalos desejados e de treinamento
Para se preparar para treinar os modelos, escolha uma data limite. Essa data dividirá os pedidos em duas partes:
- Os pedidos antes da data limite serão usados para treinar o modelo.
- Os pedidos após a data limite serão usados para calcular o valor desejado.

A biblioteca Lifetimes inclui métodos para o pré-processamento dos dados. No entanto, os conjuntos de dados utilizados para o CLV podem ser muito grandes. Isso torna praticamente impossível realizar o pré-processamento dos dados em uma única máquina. A abordagem que descrevemos neste artigo usa consultas executadas diretamente no BigQuery para dividir os pedidos em dois conjuntos. Os modelos probabilísticos e de ML usam as mesmas consultas, garantindo que ambos os tipos operem com os mesmos dados.
A data limite ideal pode ser diferente em modelos probabilísticos e de ML. É possível atualizar o valor da data diretamente na instrução SQL. Pense na data limite ideal como um hiperparâmetro. Para encontrar o valor mais adequado, explore os dados e execute alguns treinamentos de teste.
A data limite é usada na cláusula WHERE da consulta SQL que seleciona os dados de treinamento na tabela de dados apurados, conforme mostrado no exemplo a seguir:
Como agregar os dados
Depois de dividir os dados em intervalos desejados e de treinamento, agregue-os para criar os verdadeiros atributos e valores desejados para cada cliente. No caso dos modelos probabilísticos, a agregação é limitada aos campos de tempo transcorrido desde a última visita, frequência e valor monetário (RFM, na sigla em inglês). Já no caso dos modelos de DNN, os atributos RFM também são utilizados, mas é possível usar atributos adicionais para fazer previsões melhores.
A consulta a seguir mostra como criar atributos para modelos probabilísticos e de DNN ao mesmo tempo:
A tabela a seguir lista os atributos criados pela consulta.
| Nome do recurso | Descrição | Probabilístico | DNN |
|---|---|---|---|
monetary_dnn
|
A soma dos valores monetários de todos os pedidos por cliente durante o período dos atributos. | x | |
monetary_btyd
|
A média dos valores monetários de todos os pedidos de cada cliente durante o período dos atributos. Os modelos probabilísticos presumem que o valor do primeiro pedido é zero. Isso é imposto pela consulta. | x | |
recency
|
O tempo decorrido entre o primeiro e o último pedido feito por um cliente durante o período dos atributos. | x | |
frequency_dnn
|
O número de pedidos feitos por um cliente durante o período dos atributos. | x | |
frequency_btyd
|
O número de pedidos feitos por um cliente durante o período dos tributos, exceto o primeiro. | x | |
T
|
O tempo decorrido entre o primeiro pedido feito por um cliente e o fim do período dos atributos. | x | x |
time_between
|
O tempo médio entre pedidos de um cliente durante o período dos atributos. | x | |
avg_basket_value
|
O valor monetário médio da cesta de compras do cliente durante o período dos atributos. | x | |
avg_basket_size
|
O número de itens em média que o cliente tem na cesta de compras durante o período dos atributos. | x | |
cnt_returns
|
O número de pedidos que o cliente devolveu durante o período dos atributos. | x | |
has_returned
|
Se o cliente devolveu pelo menos um pedido durante o período dos atributos. | x | |
frequency_btyd_clipped
|
O mesmo que frequency_btyd, mas recortado por outliers de limite. |
x | |
monetary_btyd_clipped
|
O mesmo que monetary_btyd, mas recortado por outliers de limite. |
x | |
target_monetary_clipped
|
O mesmo que target_monetary, mas recortado por outliers de limite. |
x | |
target_monetary
|
O valor total gasto por um cliente, incluindo o período desejado e o de treinamento. | x |
Essas colunas são selecionadas no código. No caso dos modelos probabilísticos, use um DataFrame do Pandas para selecionar as colunas:
Para os modelos DNN, os atributos do TensorFlow são definidos no arquivo context.py. Nesses modelos, os itens a seguir são ignorados como atributos:
customer_id. É um valor exclusivo que não é útil como atributo.target_monetary. É o valor de predição desejado para o modelo e, portanto, não é usado como entrada.
Como criar conjuntos de treinamento, avaliação e teste para DNN
Esta seção se aplica apenas aos modelos de DNN. Para treinar um modelo ML, é necessário usar três conjuntos de dados não coincidentes:
O conjunto de dados de treinamento (70% a 80%) é usado no aprendizado dos pesos para reduzir uma função de perda. O treinamento continua até que a função de perda não seja mais reduzida.
O conjunto de dados de avaliação (10% a 15%) é usado durante a fase de treinamento para evitar o overfitting, que é quando um modelo tem um bom desempenho com os dados de treinamento, mas não generaliza bem.
O conjunto de dados de teste (10 a 15%) será usado apenas uma vez, após a conclusão do treinamento e da avaliação, para medir o desempenho do modelo pela última vez. Trata-se de um conjunto de dados não visto pelo modelo durante o processo de treinamento e, portanto, fornece uma medida estatisticamente válida da precisão do modelo.
A consulta a seguir cria um conjunto de treinamento com cerca de 70% dos dados. Ela separa os dados usando a técnica a seguir:
- Um hash de ID do cliente é calculado, produzindo um número inteiro.
- Uma operação módulo é usada para selecionar os valores de hash que estão abaixo de um determinado limite.
O mesmo conceito é usado para os conjuntos de avaliação e de teste, mantendo os dados acima do limite.
Treinamento
Como você viu na seção anterior, é possível usar modelos diferentes para tentar prever o CLV. O código usado neste artigo foi criado para permitir que você decida qual modelo usar. Você escolhe o modelo usando o parâmetro model_type que passa para o script de shell de treinamento seguinte. O código cuida do resto.
O primeiro objetivo do treinamento é que ambos os modelos consigam superar um comparativo ingênuo, que definimos abaixo. Se ambos os tipos de modelos puderem superar esse comparativo (como deveriam), será possível comparar o desempenho de cada um.
Como fazer a comparação dos modelos
Para fins desta série, o comparativo ingênuo é definido com os seguintes parâmetros:
- Valor médio da cesta de compras. Esse valor é calculado em todos os pedidos feitos antes da data limite.
- Contagem de pedidos. Esse valor é calculado para o intervalo de treinamento em todos os pedidos feitos antes da data limite.
- Multiplicador da contagem. Esse valor é calculado com base na razão entre o número de dias antes da data limite e o número de dias entre a data limite e a data atual.
De maneira simplista, o comparativo presume que a taxa de compras estabelecida por um cliente durante o intervalo de treinamento permanece constante durante o intervalo desejado. Portanto, se um cliente comprou seis vezes em 40 dias, a pressuposição é que ele comprará nove vezes em 60 dias (60/40 * 6 = 9). Multiplicar o multiplicador da contagem, a contagem de pedidos e o valor médio da cesta de compras de cada cliente fornece um valor desejado previsto ingênuo para esse cliente.
O erro do comparativo é a raiz do erro médio quadrado (REMQ): a média entre todos os clientes da diferença absoluta entre o valor desejado previsto e o valor desejado real. O REMQ é calculado por meio da consulta a seguir no BigQuery:
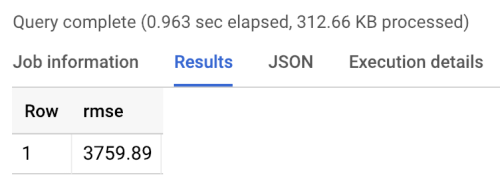
O comparativo retorna um valor de REMQ de aproximadamente 3.760, como mostrado abaixo nos resultados da execução do benchmark. Os modelos devem superar esse valor.
Modelos probabilísticos
Como mencionado na parte 1, esta série usa uma biblioteca Python denominada Lifetimes que é compatível com vários modelos, incluindo os modelos de distribuição de Pareto/distribuição binominal negativa (NBD, na sigla em inglês) e de distribuição binomial negativa beta-geométrica (BG/NBD, na sigla em inglês). A amostra de código a seguir mostra como usar a biblioteca Lifetimes para executar previsões sobre o valor de vida útil com modelos probabilísticos.
Para gerar resultados CLV usando o modelo probabilístico no ambiente local, execute o script mltrain.sh a seguir. Forneça os parâmetros para as datas de início e término da divisão de treinamento e para o término do período de previsão.
./mltrain.sh local data --model_type paretonbd_model --threshold_date [YOUR_THRESHOLD_DATE] --predict_end [YOUR_END_DATE]
Modelos de DNN
O código de amostra inclui implementações no TensorFlow de DNN usando a classe Estimator DNNRegressor predefinida e também um modelo de Estimator personalizado. O DNNRegressor e o Estimador personalizado usam o mesmo número de camadas e o número de neurônios em cada camada. Esses valores são hiperparâmetros que precisam ser ajustados. No arquivo task.py seguinte, você encontra uma lista de alguns dos hiperparâmetros que foram definidos como valores que foram testados manualmente e deram bons resultados.
Se você estiver usando o AI Platform, será possível usar o recurso de ajuste do hiperparâmetro, que será testado em vários parâmetros definidos em um arquivo yaml. O AI Platform usa a otimização bayesiana para pesquisar sobre o espaço dos hiperparâmetros.
Resultados da comparação entre modelos
A tabela a seguir mostra os valores de REMQ de cada modelo treinado com a amostra de conjunto de dados. Todos os modelos são treinados com dados de RFM. Os valores de REMQ variam ligeiramente entre as execuções, devido à inicialização aleatória de parâmetros. O modelo de DNN usa atributos adicionais, como valor médio da cesta de compras e contagem de devoluções.
| Modelo | REMQ |
|---|---|
| DNN | 947.9 |
| BG/NBD | 1557 |
| Pareto/NBD | 1558 |
Os resultados mostram que, nesse conjunto de dados, o modelo de DNN supera os modelos probabilísticos ao predizer o valor monetário. No entanto, o tamanho relativamente pequeno do conjunto de dados da UCI limita a validade estatística desses resultados. É preciso tentar cada uma das técnicas em seu conjunto de dados para ver qual oferece os melhores resultados. Todos os modelos foram treinados com os mesmos dados originais (incluindo ID do cliente, data do pedido e valor do pedido), usando valores de RFM extraídos desses dados. Os dados de treinamento do modelo de DNN incluíram alguns outros atributos, como tamanho médio da cesta de compras e contagem de devoluções.
O modelo de DNN produz como resultado apenas o valor monetário global do cliente. Se você quiser prever a frequência ou o desligamento de usuários, precisará realizar algumas outras tarefas:
- Prepare os dados de maneira diferente para alterar o valor desejado e, possivelmente, a data limite.
- Treine novamente um modelo regressor para predizer o valor desejado que você quer.
- Ajuste os hiperparâmetros.
A nossa intenção era realizar uma comparação entre os dois tipos de modelos usando os mesmos atributos de entrada. Uma vantagem de usar modelos de DNN é que você pode melhorar os resultados adicionando mais atributos do que os utilizados no nosso exemplo. Com os modelos de DNN, é possível aproveitar os dados de fontes como eventos de sequência de cliques, perfis de usuário ou atributos de produtos.
Agradecimentos
Dua, D. e Karra Taniskidou, E. (2017). Repositório de aprendizado de máquina da UCI http://archive.ics.uci.edu/ml (em inglês). Irvine, CA: University of California, School of Information and Computer Science.
A seguir
- Leia a parte 3: Como implantar na produção desta série para entender como implantar esses modelos.
- Saiba mais sobre outras soluções de previsão preditiva.
- Conheça arquiteturas de referência, diagramas, tutoriais e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.