Ce guide vous fournit des instructions pour l'exploitation des systèmes SAP HANA déployés sur Google Cloud en suivant le guide Terraform: guide de déploiement d'un scaling à la hausse SAP HANA. Sachez que ce guide n'est pas destiné à remplacer la documentation standard de SAP.
Administrer un système SAP HANA sur Google Cloud
Cette section explique comment effectuer les tâches d'administration généralement requises pour utiliser un système SAP HANA. Elle fournit également des informations sur le démarrage, l'arrêt et le clonage des systèmes.
Démarrer et arrêter des instances
Vous pouvez arrêter un ou plusieurs hôtes SAP HANA à tout moment. L'arrêt d'une instance entraîne aussi l'arrêt de l'instance. Si l'arrêt n'est pas terminé au cours de la période d'arrêt, l'instance doit obligatoirement s'interrompre. Pour éviter la perte de données ou la corruption des systèmes de fichiers, nous vous recommandons d'effectuer l'une des opérations suivantes, voire les deux:
Arrêtez SAP HANA en cours d'exécution sur l'instance avant d'arrêter l'instance.
Pour prolonger la période d'arrêt d'une instance, activez l'arrêt correct dans l'instance.
Pour savoir comment arrêter ou redémarrer une instance, consultez la section Arrêter ou redémarrer une instance Compute Engine.
Modifier une VM
Une fois le déploiement d'une VM terminé, vous pouvez modifier divers attributs, y compris son type. Certaines modifications peuvent nécessiter la restauration de votre système SAP à partir de sauvegardes, tandis que d'autres ne nécessitent que le redémarrage de la VM.
Pour en savoir plus, consultez la section Modifier la configuration des VM pour les systèmes SAP.
Créer un instantané de SAP HANA
Pour générer une sauvegarde de votre disque persistant à un moment précis, vous pouvez créer un instantané. Compute Engine stocke de manière redondante plusieurs copies de chaque instantané sur plusieurs emplacements et se sert de sommes de contrôle automatiques pour garantir l'intégrité des données.
Pour créer un instantané, suivez les instructions de Compute Engine pour créer des instantanés. Avant de créer un instantané, apportez une attention particulière aux étapes de préparation, telles que le vidage des tampons de disque sur disque afin de garantir un instantané cohérent.
Les instantanés sont utiles dans les cas d'utilisation suivants :
| Cas d'utilisation | Détails |
|---|---|
| Fournir une solution de sauvegarde de données simple, économique et indépendante du logiciel | Sauvegardez vos données, vos journaux, vos sauvegardes et vos disques partagés à l'aide d'instantanés. Programmez une sauvegarde quotidienne de ces disques pour sauvegarder l'intégralité de votre ensemble de données à un moment précis. Après le premier instantané, seules les modifications de bloc incrémentielles sont stockées dans les instantanés suivants afin de réduire les coûts. |
| Effectuer une migration vers un autre type de stockage | Compute Engine propose différents types de disques persistants, y compris les types sauvegardés par un stockage standard (magnétique) et les types sauvegardés par un disque SSD (disques persistants basés sur SSD). Chacun présente des caractéristiques de coûts et de performances différentes. Vous pouvez par exemple utiliser un type standard pour votre volume de sauvegarde et un type basé sur SSD pour les volumes /hana/log et /hana/data, car ils nécessitent des performances plus élevées. Pour effectuer une migration entre ces deux types de stockage, créez un volume à l'aide de l'instantané du volume, puis sélectionnez un autre type de stockage. |
| Effectuer une migration de SAP HANA vers une autre région ou une autre zone. | Vous pouvez utiliser des instantanés pour déplacer votre système SAP HANA d'une zone à une autre dans la même région, voire d'une région à une autre. DansGoogle Cloud , vous pouvez utiliser des instantanés dans le monde entier pour créer des disques dans une autre zone ou une autre région. Pour effectuer une migration vers une autre zone ou une autre région, créez un instantané de vos disques incluant le disque racine, puis créez les machines virtuelles dans la zone ou la région souhaitée avec les disques créés à partir des instantanés en question. |
Modifier les paramètres du disque
Vous pouvez modifier les IOPS ou le débit provisionnés, ou augmenter la taille des volumes Hyperdisk une fois toutes les quatre heures.
Si vous essayez de modifier à nouveau le disque avant l'expiration des quatre heures, vous recevez un message d'erreur de limitation du débit tel que Cannot update provisioned throughput due to being rate limited.
Pour résoudre ces erreurs, attendez quatre heures à compter de la dernière modification avant d'essayer de modifier à nouveau le disque.
N'utilisez cette procédure qu'en cas d'urgence dans laquelle vous ne pouvez pas attendre quatre heures pour ajuster la taille du disque, les IOPS provisionnées ou le débit des volumes Hyperdisk.
Pour modifier les paramètres du disque, procédez comme suit :
Arrêtez votre instance SAP HANA en exécutant l'une des commandes suivantes :
HDB stopsapcontrol -nr INSTANCE_NUMBER -function StopSystem HDB
Remplacez
INSTANCE_NUMBERpar le numéro d'instance de votre système SAP HANA.Pour en savoir plus, consultez la section Démarrer et arrêter des systèmes SAP HANA.
Créez un instantané ou une image de votre disque existant :
Sauvegarde basée sur des instantanés
gcloud compute snapshots create SNAPSHOT_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATIONRemplacez les éléments suivants :
SNAPSHOT_NAME: nom de l'instantané que vous souhaitez créerPROJECT_NAME: nom de votre Google Cloud projet.SOURCE_DISK_NAME: disque source utilisé pour créer l'instantanéZONE: zone du disque source dans laquelle effectuer des opérationsLOCATION: emplacement Cloud Storage, régional ou multirégional, où le contenu de l'instantané doit être stockéPour en savoir plus, consultez la page Créer et gérer des instantanés de disque.
Sauvegarde basée sur des images
gcloud compute images create IMAGE_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATIONRemplacez les éléments suivants :
IMAGE_NAME: nom de l'image disque que vous souhaitez créerPROJECT_NAME: nom de votre Google Cloud projet.SOURCE_DISK_NAME: disque source utilisé pour créer l'imageZONE: zone du disque source dans laquelle effectuer des opérationsLOCATION: emplacement Cloud Storage, régional ou multirégional, où le contenu de l'image doit être stockéPour en savoir plus, consultez la section Créer des images personnalisées.
Créez un disque à partir de l'instantané ou de l'image.
Pour les volumes Hyperdisk, veillez à spécifier la taille du disque, les IOPS et le débit pour répondre aux exigences de votre charge de travail. Pour en savoir plus sur le provisionnement des IOPS et du débit pour Hyperdisk, consultez la section À propos des performances provisionnées pour Hyperdisk.
À partir d'un instantané
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --source-snapshot=SOURCE_SNAPSHOT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUTRemplacez les éléments suivants :
NEW_DISK_NAME: nom du disque que vous souhaitez créerPROJECT_NAME: nom de votre Google Cloud projet.DISK_TYPE: type de disque à créerDISK_SIZE: taille du disqueZONE: zone des disques à créerSOURCE_SNAPSHOT: instantané source utilisé pour créer les disquesIOPS: IOPS provisionnées du disque à créerTHROUGHPUT: débit provisionné du disque à créer
À partir d'une image
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --image=SOURCE_IMAGE_NAME \ --image-project=IMAGE_PROJECT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUTRemplacez les éléments suivants :
NEW_DISK_NAME: nom du disque que vous souhaitez créerPROJECT_NAME: nom de votre Google Cloud projet.DISK_TYPE: type de disque à créerDISK_SIZE: taille du disqueZONE: zone des disques à créerSOURE_IMAGE_NAME: image source à appliquer aux disques en cours de créationIMAGE_PROJECT_NAME: Google Cloud projet par rapport auquel toutes les références d'images et de familles d'images seront résolues.IOPS: IOPS provisionnées du disque à créerTHROUGHPUT: débit provisionné du disque à créer
Pour en savoir plus, consultez la page
gcloud compute disks create.Dissociez le disque existant de votre système SAP HANA :
gcloud compute instances detach-disk INSTANCE_NAME \ --disk OLD_DISK_NAME \ --zone ZONE \ --project PROJECT_NAMERemplacez les éléments suivants :
INSTANCE_NAME: nom de l'instance sur laquelle effectuer des opérationsOLD_DISK_NAME: disque à dissocier par son nom de ressourceZONE: zone de l'instance sur laquelle effectuer des opérationsPROJECT_NAME: nom de votre Google Cloud projet.
Pour en savoir plus, consultez la page
gcloud compute instances detach-disk.Associez le nouveau disque à votre système SAP HANA :
gcloud compute instances attach-disk INSTANCE_NAME \ --disk NEW_DISK_NAME \ --zone ZONE \ --project PROJECT_NAMERemplacez les éléments suivants :
INSTANCE_NAME: nom de l'instance sur laquelle effectuer des opérationsNEW_DISK_NAME: nom du disque à associer à l'instanceZONE: zone de l'instance sur laquelle effectuer des opérationsPROJECT_NAME: nom de votre Google Cloud projet.
Pour en savoir plus, consultez la page
gcloud compute instances attach-disk.Vérifiez si les points d'installation sont correctement associés :
lsblkLe résultat obtenu doit ressembler à ceci :
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT ... sdd 8:48 0 1T 0 disk └─vg_hana_shared-shared 254:0 0 1024G 0 lvm /hana/shared sde 8:64 0 32G 0 disk └─vg_hana_usrsap-usrsap 254:3 0 32G 0 lvm /usr/sap sdf 8:80 0 13.8T 0 disk └─vg_hana_data-data 254:1 0 13.8T 0 lvm /hana/data sdg 8:96 0 512G 0 disk └─vg_hana_log-log 254:2 0 512G 0 lvm /hana/logDémarrez votre instance SAP HANA en exécutant l'une des commandes suivantes :
HDB startsapcontrol -nr INSTANCE_NUMBER -function StartSystem HDB
Remplacez
INSTANCE_NUMBERpar le numéro d'instance de votre système SAP HANA.Pour en savoir plus, consultez la section Démarrer et arrêter des systèmes SAP HANA.
Validez la taille du disque, les IOPS et le débit de votre nouveau volume Hyperdisk :
gcloud compute disks describe DISK_NAME \ --zone ZONE \ --project PROJECT_NAMERemplacez les éléments suivants :
DISK_NAME: nom du disque à décrireZONE: zone du disque à décrirePROJECT_NAME: nom de votre Google Cloud projet.
Pour en savoir plus, consultez la page
gcloud compute disks describe.
Cloner un système SAP HANA
Vous pouvez créer des instantanés d'un système SAP HANA existant sur Google Cloud pour créer un clone exact du système.
Pour cloner un système SAP HANA à hôte unique, procédez comme suit :
Créez un instantané de vos disques de données et de sauvegarde.
Créez des disques à l'aide des instantanés.
Dans la console Google Cloud , accédez à la page Instances de VM.
Cliquez sur l'instance à cloner pour ouvrir la page des détails de l'instance, puis cliquez sur Cloner.
Associez les disques créés à partir des instantanés.
Pour cloner un système SAP HANA à plusieurs hôtes, procédez comme suit :
Provisionnez un nouveau système SAP HANA avec la même configuration que le système SAP HANA que vous souhaitez cloner.
Effectuez une sauvegarde des données du système d'origine.
Restaurez la sauvegarde du système d'origine dans le nouveau système.
Installer et mettre à jour la CLI gcloud
Après le déploiement d'une VM pour SAP HANA et l'installation du système d'exploitation, Google Cloud CLI doit être à jour pour diverses raisons (transfert de fichiers depuis et vers Cloud Storage, interaction avec les services réseau, etc.).
Si vous suivez les instructions du guide de déploiement de SAP HANA, la CLI gcloud est installée automatiquement.
Toutefois, si vous installez votre propre système d'exploitation sur Google Cloud en tant qu'image personnalisée ou si vous utilisez une image publique plus ancienne fournie parGoogle Cloud, vous devrez probablement installer ou mettre à jour gcloud CLI vous-même.
Pour vérifier si la CLI gcloud est installée et si des mises à jour sont disponibles, ouvrez un terminal ou une invite de commande, puis saisissez :
gcloud version
Si la commande n'est pas reconnue, la CLI gcloud n'est pas installée.
Pour installer la CLI gcloud, suivez les instructions de la section Installer la CLI gcloud.
Pour remplacer la version 140 ou une version plus ancienne de la CLI gcloud intégrée à SLES, procédez comme suit :
Connectez-vous à la VM à l'aide de
ssh.Passez au super utilisateur :
sudo suSaisissez les commandes suivantes :
bash <(curl -s https://dl.google.com/dl/cloudsdk/channels/rapid/install_google_cloud_sdk.bash) --disable-prompts --install-dir=/usr/local update-alternatives --install /usr/bin/gsutil gsutil /usr/local/google-cloud-sdk/bin/gsutil 1 --force update-alternatives --install /usr/bin/gcloud gcloud /usr/local/google-cloud-sdk/bin/gcloud 1 --force gcloud --quiet compute instances list
Activer le redémarrage rapide de SAP HANA
Google Cloud Nous vous recommandons vivement d'activer le redémarrage rapide SAP HANA pour chaque instance de SAP HANA, en particulier pour les instances de grande capacité. Le redémarrage rapide de SAP HANA réduit le temps de redémarrage en cas d'arrêt de SAP HANA, mais le système d'exploitation reste en cours d'exécution.
Comme configuré par les scripts d'automatisation fournis par Google Cloud , les paramètres du système d'exploitation et du noyau sont déjà compatibles avec le redémarrage rapide de SAP HANA.
Vous devez définir le système de fichiers tmpfs et configurer SAP HANA.
Pour définir le système de fichiers tmpfs et configurer SAP HANA, vous pouvez suivre les étapes manuelles ou utiliser le script d'automatisation fourni parGoogle Cloud pour activer le redémarrage rapide de SAP HANA. Pour en savoir plus, consultez les pages suivantes :
- Étapes manuelles : Activer le redémarrage rapide de SAP HANA
- Étapes automatisées : Activer le redémarrage rapide de SAP HANA
Pour obtenir des instructions faisant autorité sur la fonction de redémarrage rapide SAP HANA, consultez la documentation sur les options de redémarrage rapide de SAP HANA.
Étapes manuelles
Configurer le système de fichiers tmpfs
Une fois les VM hôtes et les systèmes SAP HANA de base déployés, vous devez créer et installer des répertoires pour les nœuds NUMA du système de fichiers tmpfs.
Afficher la topologie NUMA de votre VM
Pour pouvoir mapper le système de fichiers tmpfs requis, vous devez connaître la quantité de nœuds NUMA dont dispose votre VM. Pour afficher les nœuds NUMA disponibles sur une VM Compute Engine, saisissez la commande suivante :
lscpu | grep NUMA
Par exemple, un type de VM m2-ultramem-208 comporte quatre nœuds NUMA, numérotés de 0 à 3, comme illustré dans l'exemple suivant :
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
Créer les répertoires de nœuds NUMA
Créez un répertoire pour chaque nœud NUMA de votre VM et définissez les autorisations.
Par exemple, pour quatre nœuds NUMA numérotés de 0 à 3 :
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SIDInstaller les répertoires de nœuds NUMA dans tmpfs
Montez les répertoires du système de fichiers tmpfs et spécifiez une préférence de nœud NUMA pour chacun avec mpol=prefer :
SID : spécifiez le SID en majuscules.
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
Mettre à jour /etc/fstab
Pour vous assurer que les points d'installation sont disponibles après un redémarrage du système d'exploitation, ajoutez des entrées dans la table du système de fichiers, /etc/fstab :
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
Facultatif : définir des limites à l'utilisation de la mémoire
Le système de fichiers tmpfs peut augmenter ou diminuer de manière dynamique.
Pour limiter la mémoire utilisée par le système de fichiers tmpfs, vous pouvez définir une limite de taille pour un volume de nœuds NUMA en utilisant l'option size.
Exemple :
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
Vous pouvez également limiter l'utilisation globale de la mémoire tmpfs pour tous les nœuds NUMA d'une instance SAP HANA donnée et d'un nœud de serveur donné en définissant le paramètre persistent_memory_global_allocation_limit dans la section [memorymanager] du fichier global.ini.
Configuration de SAP HANA pour le redémarrage rapide
Pour configurer SAP HANA pour le redémarrage rapide, mettez à jour le fichier global.ini et spécifiez les tables à stocker dans la mémoire persistante.
Mettre à jour la section [persistence] du fichier global.ini
Configurez la section [persistence] du fichier SAP HANA global.ini de manière à référencer les emplacements tmpfs. Séparez chaque emplacement tmpfs par un point-virgule :
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
L'exemple précédent spécifie quatre volumes de mémoire pour quatre nœuds NUMA, ce qui correspond à m2-ultramem-208. Si vous l'exécutez sur m2-ultramem-416, vous devez configurer huit volumes de mémoire (de 0 à 7).
Redémarrez SAP HANA après avoir modifié le fichier global.ini.
SAP HANA peut désormais utiliser l'emplacement tmpfs comme espace de mémoire persistant.
Spécifier les tables à stocker en mémoire persistante
Spécifiez des tables ou partitions de colonne spécifiques à stocker en mémoire persistante.
Par exemple, pour activer la mémoire persistante pour une table existante, exécutez la requête SQL :
ALTER TABLE exampletable persistent memory ON immediate CASCADE
Pour modifier la valeur par défaut des nouvelles tables, ajoutez le paramètre table_default dans le fichier indexserver.ini. Exemple :
[persistent_memory] table_default = ON
Pour en savoir plus sur le contrôle des colonnes et des tables ainsi que sur les vues de surveillance qui fournissent des informations détaillées, consultez la page Mémoire persistante SAP HANA.
Étapes automatisées
Le script d'automatisation fourni par Google Cloud pour activer le redémarrage rapide de SAP HANA apporte des modifications aux répertoires /hana/tmpfs*, au fichier /etc/fstab et à la configuration de SAP HANA. Lorsque vous exécuterez le script, vous devrez peut-être effectuer des étapes supplémentaires selon qu'il s'agit du déploiement initial de votre système SAP HANA ou que vous redimensionnez votre machine sur une autre taille NUMA.
Pour le déploiement initial de votre système SAP HANA ou le redimensionnement de la machine pour augmenter le nombre de nœuds NUMA, assurez-vous que SAP HANA est en cours d'exécution pendant l'exécution du script d'automatisation fourni par Google Cloudpour activer le redémarrage rapide de SAP HANA.
Lorsque vous redimensionnez votre machine pour réduire le nombre de nœuds NUMA, assurez-vous que SAP HANA est arrêté pendant l'exécution du script d'automatisation fourni par Google Cloud pour activer le redémarrage rapide de SAP HANA. Une fois le script exécuté, vous devez mettre à jour manuellement la configuration SAP HANA pour terminer la configuration du redémarrage rapide de SAP HANA. Pour en savoir plus, consultez la section Configuration de SAP HANA pour le redémarrage rapide.
Pour activer le redémarrage rapide de SAP HANA, procédez comme suit :
Établissez une connexion SSH avec votre VM hôte.
Passez en mode root :
sudo su -
Téléchargez le script
sap_lib_hdbfr.sh:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
Rendez le fichier exécutable :
chmod +x sap_lib_hdbfr.sh
Vérifiez que le script ne comporte aucune erreur :
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
Si la commande renvoie une erreur, contactez le Cloud Customer Care. Pour savoir comment contacter le service client, consultez la page Obtenir de l'aide pour SAP sur Google Cloud.
Exécutez le script après avoir remplacé l'ID système (SID) et le mot de passe SAP HANA de l'utilisateur système de la base de données SAP HANA. Pour fournir le mot de passe en toute sécurité, nous vous recommandons d'utiliser un secret dans Secret Manager.
Exécutez le script en utilisant le nom d'un secret dans Secret Manager. Ce secret doit exister dans le projet Google Cloud qui contient votre instance de VM hôte.
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
Remplacez les éléments suivants :
SID: spécifiez le SID en majuscules. Par exemple,AHA.SECRET_NAME: spécifiez le nom du secret correspondant au mot de passe de l'utilisateur système de la base de données SAP HANA. Ce secret doit exister dans le projet Google Cloud qui contient votre instance de VM hôte.
Vous pouvez également exécuter le script en utilisant un mot de passe en texte brut. Une fois le redémarrage rapide de SAP HANA activé, veillez à modifier votre mot de passe. L'utilisation d'un mot de passe en texte brut n'est pas recommandée, car celui-ci serait enregistré dans l'historique de ligne de commande de votre VM.
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
Remplacez les éléments suivants :
SID: spécifiez le SID en majuscules. Par exemple,AHA.PASSWORD: spécifiez le mot de passe de l'utilisateur système de la base de données SAP HANA.
Dans le cas d'une exécution initiale réussie, vous devez obtenir une sortie semblable à celle-ci :
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
Configurer le canal d'assistance SAP avec SAProuter
Pour permettre à un ingénieur de l'assistance SAP d'accéder à vos systèmes SAP HANA surGoogle Cloud, vous pouvez utiliser SAProuter. Procédez comme suit :
Démarrez l'instance de VM Compute Engine sur laquelle le logiciel SAProuter sera installé et attribuez une adresse IP externe pour que l'instance ait accès à Internet.
Créez une adresse IP externe statique, puis attribuez-la à l'instance.
Créez et configurez une règle de pare-feu SAProuter spécifique sur votre réseau. Dans cette règle, autorisez seulement l'accès entrant et sortant requis sur le réseau d'assistance SAP, pour l'instance SAProuter.
Limitez l'accès entrant et sortant à une adresse IP précise que SAP vous fournit pour vous y connecter, avec le port TCP
3299. Ajoutez un tag cible à votre règle de pare-feu, puis saisissez le nom de l'instance, afin que la règle de pare-feu ne s'applique qu'à la nouvelle instance. Pour en savoir plus sur la création et la configuration de règles de pare-feu, consultez la documentation sur les règles de pare-feu.Installez le logiciel SAProuter en vous référant à la Note SAP 1628296, puis créez un fichier
saprouttabqui autorise l'accès depuis SAP à vos systèmes SAP HANA sur Google Cloud.Configurez la connexion avec SAP. Pour la connexion Internet, utilisez Secure Network Communication. Pour en savoir plus, consultez la page relative à l'aide pour l'assistance à distance SAP.
Configurer le réseau
Vous provisionnez votre système SAP HANA en utilisant des VM avec leGoogle Cloud réseau virtuel Google Cloud .Celui-ci exploite des technologies de pointe de réseau défini par logiciel et de systèmes distribués pour héberger et diffuser vos services à travers le monde.
Pour SAP HANA, créez un réseau de sous-réseaux autre que celui par défaut avec des plages d'adresses IP CIDR qui ne se chevauchent pas pour chacun des sous-réseaux du réseau. Notez que chaque sous-réseau et ses plages d'adresses IP internes sont mappés sur une seule région.
Un sous-réseau couvre toutes les zones de la région dans laquelle il est créé.
Cependant, lorsque vous créez une instance de VM, vous spécifiez une zone et un sous-réseau pour la VM en question. Par exemple, vous pouvez créer un ensemble d'instances sur le sous-réseau subnetwork1 et dans la zone zone1 de la région region1, et un autre ensemble d'instances sur le sous-réseau subnetwork2 et dans la zone zone2 de la région region1, en fonction de vos besoins.
Un nouveau réseau n'a pas de règles de pare-feu et donc pas d'accès au réseau. Vous devez créer des règles de pare-feu qui autorisent l'accès à vos instances SAP HANA selon un modèle de privilège minimum. Les règles de pare-feu s'appliquent à tout le réseau. Elles peuvent également être configurées de sorte à s'appliquer à des instances cibles spécifiques à l'aide du mécanisme de marquage.
Les routes sont des ressources globales, et non régionales, associées à un seul réseau. Les routes créées par l'utilisateur s'appliquent à toutes les instances d'un réseau. Cela signifie que vous pouvez ajouter une route qui transfère le trafic d'une instance à une autre au sein du même réseau et entre sous-réseaux sans requérir d'adresses IP externes.
Pour votre instance SAP HANA, lancez l'instance sans adresse IP externe et configurez une autre VM en tant que passerelle NAT pour un accès externe. Cette configuration nécessite que vous ajoutiez votre passerelle NAT en tant que route pour votre instance SAP HANA. Cette procédure est décrite dans le guide de déploiement.
Sécurité
Les sections suivantes expliquent les opérations de sécurité.
Modèle de privilège minimum
Votre première ligne de défense consiste à limiter les droits d'accès à l'instance à l'aide de pare-feu. En créant des règles de pare-feu, vous pouvez limiter à des adresses IP sources spécifiques tout le trafic vers un réseau ou des machines cibles sur un ensemble de ports donné. Vous devez suivre le modèle de privilège minimum pour limiter l'accès aux adresses IP, protocoles et ports spécifiques qui nécessitent un accès. Par exemple, vous devez toujours configurer un hôte bastion et autoriser les connexions SSH dans votre système SAP HANA seulement à partir de cet hôte.
Modifications de configuration
Vous devez configurer votre système SAP HANA et le système d'exploitation à l'aide des paramètres de sécurité recommandés. Par exemple, assurez-vous que seuls les ports réseau pertinents disposent de l'autorisation d'accès, renforcez le système d'exploitation sur lequel vous exécutez SAP HANA, etc.
Reportez-vous aux notes SAP suivantes (compte utilisateur SAP requis) :
- 1944799 : Directives pour l'installation de SAP HANA sur SLES
- 1730999 : Modifications de configuration recommandées
- 1731000 : Modifications de configuration déconseillées
Désactiver les services SAP HANA inutiles
Si vous n'avez pas besoin du service Extended Application Services de SAP HANA (SAP HANA XS), désactivez-le. Consultez la note SAP 1697613 : Supprimer le service de moteur classique SAP HANA XS de la topologie.
Une fois le service désactivé, supprimez tous les ports TCP qui ont été ouverts pour le service. Dans Google Cloud, cela revient à modifier les règles de pare-feu de votre réseau de sorte à supprimer ces ports de la liste d'accès.
Journaux d'audit
Cloud Audit Logs comprennent deux flux de journaux : les activités d'administration et l'accès aux données. Ils sont automatiquement générés par Google Cloud. Ils peuvent vous aider à répondre aux questions suivantes : "Qui a fait quoi, où et quand ?" dans votre projetGoogle Cloud .
Les journaux des activités d'administration contiennent des entrées relatives aux appels d'API et aux autres opérations d'administration qui modifient la configuration ou les métadonnées d'un service ou projet. Ils sont toujours activés et visibles par tous les membres du projet.
Les journaux d'accès aux données contiennent des entrées de journal pour les appels d'API qui créent, modifient ou lisent les données fournies par l'utilisateur et gérées par un service, telles que les données stockées dans un service de base de données. Ce type de journaux est activé par défaut dans votre projet et accessible via Cloud Logging ou via votre flux d'activités.
Sécuriser un bucket Cloud Storage
Si vous utilisez Cloud Storage pour héberger les sauvegardes de vos données et journaux, assurez-vous d'utiliser TLS (HTTPS) lors de l'envoi de données à Cloud Storage à partir de vos instances afin de protéger les données en transit. Cloud Storage chiffre automatiquement les données au repos. Vous pouvez spécifier vos propres clés de chiffrement si vous disposez de votre propre système de gestion de clés.
Documents de sécurité associés
Reportez-vous aux ressources de sécurité supplémentaires ci-dessous pour votre environnement SAP HANA sur Google Cloud:
- Centre de sécurité
- Conformité dans Google Cloud
- Livre blanc sur la sécurité dans Google Cloud
- Conception de la sécurité dans l'infrastructure de Google
Haute disponibilité pour SAP HANA sur Google Cloud
Google Cloud offre plusieurs possibilités pour garantir la haute disponibilité pour votre système SAP HANA, y compris des fonctionnalités de migration à chaud de Compute Engine et de redémarrage automatique. Grâce à ces fonctionnalités ainsi qu'au pourcentage de temps d'activité mensuel élevé des VM Compute Engine, le paiement et le maintien de systèmes de secours peuvent être inutiles.
Cependant, vous pouvez au besoin déployer un système de scaling horizontal à plusieurs hôtes qui inclut des hôtes de secours pour le basculement automatique des hôtes SAP HANA, ou vous pouvez déployer un système de scaling vertical avec une instance SAP HANA de secours dans un cluster Linux à haute disponibilité.
Pour en savoir plus sur les options de haute disponibilité pour SAP HANA surGoogle Cloud, consultez le guide de planification de la haute disponibilité SAP HANA.
Activer le hook de fournisseur HA/DR SAP HANA
SUSE vous recommande d'activer les hooks de fournisseur HA/DR (haute disponibilité/reprise après sinistre) SAP HANA, qui permettent à SAP HANA d'envoyer des notifications pour certains événements et améliorent la détection des défaillances.
Les hooks de fournisseur HA/DR SAP HANA nécessitent SAP HANA 2.0 SPS 03 ou une version ultérieure pour le hook SAPHanaSR, et SAP HANA 2.0 SPS 05 ou une version ultérieure pour le hook SAPHanaSR-angi.
Sur le site principal et le site secondaire, procédez comme suit :
En tant qu'utilisateur racine ou
SID_LCadm, ouvrez le fichierglobal.inipour le modifier :>vi /hana/shared/SID/global/hdb/custom/config/global.iniAjoutez les définitions suivantes au fichier
global.ini:Scaling à la hausse
Pour SLES pour SAP 15 SP5 ou version antérieure:
[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR/ execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR/ execution_order = 3 action_on_lost = stop [trace] ha_dr_saphanasr = info
Pour SLES pour SAP 15 SP6 ou version ultérieure:
[ha_dr_provider_susHanaSR] provider = susHanaSR path = /usr/share/SAPHanaSR-angi execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-angi execution_order = 3 action_on_lost = stop [ha_dr_provider_susTkOver] provider = susTkOver path = /usr/share/SAPHanaSR-angi execution_order = 1 sustkover_timeout = 30 [trace] ha_dr_sushanasr = info ha_dr_suschksrv = info ha_dr_sustkover = info
Effectuer un scaling horizontal
Pour SLES pour SAP 15 SP5 ou version antérieure:
[ha_dr_provider_saphanasrmultitarget] provider = SAPHanaSrMultiTarget path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 1 [ha_dr_provider_sustkover] provider = susTkOver path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 2 sustkover_timeout = 30 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 3 action_on_lost = stop [trace] ha_dr_saphanasrmultitarget = info ha_dr_sustkover = info
Pour SLES pour SAP 15 SP6 ou version ultérieure:
[ha_dr_provider_susHanaSR] provider = susHanaSR path = /usr/share/SAPHanaSR-angi execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-angi execution_order = 3 action_on_lost = stop [ha_dr_provider_susTkOver] provider = susTkOver path = /usr/share/SAPHanaSR-angi execution_order = 1 sustkover_timeout = 30 [trace] ha_dr_sushanasr = info ha_dr_suschksrv = info ha_dr_sustkover = info
En tant qu'utilisateur racine, créez un fichier de configuration personnalisé dans le répertoire
/etc/sudoers.den exécutant la commande suivante. Ce nouveau fichier de configuration permet à l'utilisateurSID_LCadmd'accéder aux attributs de nœud du cluster lorsque la méthode de hooksrConnectionChanged()est appelée.>visudo -f /etc/sudoers.d/SAPHanaSRDans le fichier
/etc/sudoers.d/SAPHanaSR, ajoutez le texte suivant :Scaling à la hausse
Pour SLES pour SAP 15 SP5 ou version antérieure:
Remplacez les éléments suivants :
SITE_A: nom du site du serveur SAP HANA principalSITE_B: nom du site du serveur SAP HANA secondaireSID_LC: SID, spécifié à l'aide de lettres minuscules
crm_mon -A1 | grep siteen tant qu'utilisateur racine, sur le serveur principal SAP HANA ou sur le serveur secondaire.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
Pour SLES pour SAP 15 SP6 ou version ultérieure:
Remplacez les éléments suivants :
SITE_A: nom du site du serveur SAP HANA principalSITE_B: nom du site du serveur SAP HANA secondaireSID_LC: SID, spécifié à l'aide de lettres minuscules
crm_mon -A1 | grep siteen tant qu'utilisateur racine, sur le serveur principal SAP HANA ou sur le serveur secondaire.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HOOK_HELPER = /usr/bin/SAPHanaSR-hookHelper --sid=SID --case=* SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
Effectuer un scaling horizontal
Pour SLES pour SAP 15 SP5 ou version antérieure:
Remplacez
SID_LCpar le SID, en lettres minuscules.SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_* SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_SID_LC_gsh * SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/SAPHanaSR-hookHelper --sid=SID_LC *
Pour SLES pour SAP 15 SP6 ou version ultérieure:
Remplacez les éléments suivants :
SITE_A: nom du site du serveur SAP HANA principalSITE_B: nom du site du serveur SAP HANA secondaireSID_LC: SID, spécifié à l'aide de lettres minuscules
crm_mon -A1 | grep siteen tant qu'utilisateur racine, sur le serveur principal SAP HANA ou sur le serveur secondaire.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR SID_LCadm ALL=(ALL) NOPASSWD: /usr/bin/SAPHanaSR-hookHelper --sid=SID --case=* SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
Dans votre fichier
/etc/sudoers, assurez-vous que le texte suivant est inclus :Pour SLES pour SAP 15 SP3 ou version ultérieure:
@includedir /etc/sudoers.d
Pour les versions jusqu'à SLES pour SAP 15 SP2 :
#includedir /etc/sudoers.d
Notez que
#dans ce texte fait partie de la syntaxe et ne signifie pas que la ligne est un commentaire.
Passez Pacemaker en mode maintenance :
>crm configure property maintenance-mode=trueAppliquez les modifications :
HANA SPS4 et versions ultérieures
En tant que SID_LCadm, chargez les modifications sur le nœud maître SAP HANA principal et secondaire.
>hdbnsutil -reloadHADRProvidersUtilisez l'une des options suivantes pour éviter ou minimiser le temps d'arrêt de votre site principal :
Option 1
En tant que SID_LCadm, redémarrez le site secondaire.
>HDB restartOption 2
Effectuez un basculement contrôlé de la base de données principale à la version secondaire
HANA SPS3
En tant que SID_LCadm, redémarrez les systèmes SAP HANA principal et secondaire :
>HDB restartSortez Pacemaker du mode maintenance :
>crm configure property maintenance-mode=falseUne fois la configuration du cluster SAP HANA terminée, vous pouvez vérifier que le hook fonctionne correctement lors d'un test de basculement, comme décrit dans les sections Dépannage du hook Python SAPHanaSR et La reprise du cluster à haute disponibilité prend trop de temps en cas de défaillance du serveur d'index HANA.
Reprise après sinistre
Le système SAP HANA offre plusieurs fonctionnalités de haute disponibilité afin que votre base de données SAP HANA puisse supporter les défaillances au niveau du logiciel ou de l'infrastructure. Parmi ces fonctionnalités figurent la réplication du système SAP HANA et les sauvegardes SAP HANA, toutes deux compatibles avec Google Cloud .
Pour en savoir plus sur les sauvegardes SAP HANA, consultez la page relative à la sauvegarde et la récupération.
Pour plus d'informations sur la réplication du système, consultez la page Guide de planification de reprise après sinistre pour SAP HANA.
Sauvegarde et récupération
Les sauvegardes sont essentielles pour protéger votre système d'enregistrement (votre base de données). SAP HANA étant une base de données en mémoire, la création régulière de sauvegardes et la mise en œuvre d'une stratégie de sauvegarde appropriée vous aident à récupérer votre base de données SAP HANA en cas de corruption ou de perte de données due à une panne imprévue ou à une défaillance de votre infrastructure. Pour vous y aider, le système SAP HANA offre des fonctionnalités de sauvegarde et de récupération intégrées. Vous pouvez utiliser des services Google Cloud comme Cloud Storage en tant que destination de sauvegarde de SAP HANA.
Vous pouvez également activer la fonctionnalité Backint de l'agent Google Cloudpour SAP afin de pouvoir utiliser directement Cloud Storage pour les sauvegardes et les récupérations.
Pour en savoir plus sur les recommandations de sauvegarde et de récupération pour les systèmes SAP HANA exécutés sur des instances bare metal Compute Engine telles que X4, consultez la section Sauvegarde et récupération pour SAP HANA sur des instances bare metal.
Ce document part du principe que vous connaissez bien la sauvegarde et la récupération de SAP HANA, ainsi que les notes de service SAP suivantes :
- 1642148 : FAQ : Sauvegarde et récupération de la base de données SAP HANA
- 1821207 : Déterminer les fichiers de récupération nécessaires
- 1869119 : Vérifier les sauvegardes à l'aide de
hdbbackupcheck - 1873247 : Vérifier la possibilité de récupération à l'aide de
hdbbackupdiag --check - 1651055 : Programmer des sauvegardes de la base de données SAP HANA dans Linux
Utiliser des volumes Persistent Disk Compute Engine et Cloud Storage pour les sauvegardes
Si vous avez suivi les instructions de déploiement basées sur Terraform fournies par Google Cloud pour déployer votre système SAP HANA, vous disposez alors d'une installation SAP HANA avec un répertoire /hanabackup hébergé sur un volume Balanced Persistent Disk (disque persistant avec équilibrage).
Pour créer vos sauvegardes de base de données en ligne dans le répertoire /hanabackup, vous utilisez les outils SAP standards tels que SAP HANA Studio, SAP HANA Cockpit, la transaction SAP ABAP DB13 ou les instructions SQL SAP HANA. Enfin, vous enregistrez la sauvegarde terminée en l'important dans un bucket Cloud Storage, à partir duquel vous pouvez télécharger la sauvegarde si vous avez besoin de récupérer votre système SAP HANA.
Utiliser Compute Engine pour créer des sauvegardes et des instantanés de disque
Vous pouvez utiliser Compute Engine pour les sauvegardes SAP HANA. Vous avez aussi la possibilité de sauvegarder l'ensemble du disque qui héberge vos volumes de données et de journaux SAP HANA à l'aide d'instantanés de disque standards.
Si vous avez suivi les instructions du guide de déploiement, vous disposez alors d'une installation SAP HANA avec un répertoire /hanabackup pour les sauvegardes de votre base de données en ligne. Vous pouvez utiliser ce même répertoire pour stocker des instantanés du volume /hanabackup et conserver une sauvegarde de vos volumes de données et de journaux SAP HANA à un moment précis.
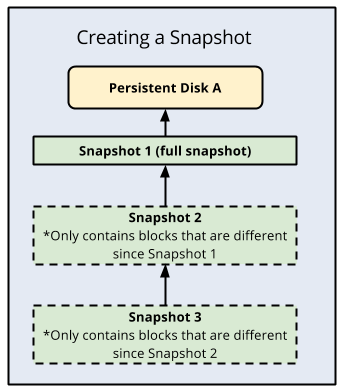
Les instantanés de disque standards ont l'avantage d'être incrémentiels, chaque sauvegarde successive ne stockant que les modifications incrémentielles de bloc plutôt que de créer une sauvegarde entièrement nouvelle. Compute Engine stocke de manière redondante plusieurs copies de chaque instantané sur plusieurs emplacements et se sert de sommes de contrôle automatiques pour garantir l'intégrité des données.
Voici une illustration des sauvegardes incrémentielles :
Cloud Storage en tant que destination de sauvegarde
Cloud Storage est un très bon choix de destination de sauvegarde pour SAP HANA, car il offre une grande durabilité et une haute disponibilité des données.
Cloud Storage est un store d'objets pour des fichiers de n'importe quel type et n'importe quel format. Il propose un espace de stockage quasiment illimité, ce qui signifie que vous n'avez pas à vous soucier de son provisionnement ni de l'ajout de capacité. Un objet Cloud Storage contient des données de fichier et les métadonnées qui y sont associées, et sa taille peut atteindre 5 To. Un bucket Cloud Storage peut stocker un nombre illimité d'objets.
Cloud Storage permet de stocker des données sur plusieurs emplacements, ce qui permet une grande durabilité et une haute disponibilité. Lorsque vous importez ou copiez des données dans Cloud Storage, Cloud Storage ne signale l'aboutissement de l'action que si la redondance des objets est réalisée.
Le tableau suivant présente les options de stockage proposées par Cloud Storage :
| Fréquence de lecture/écriture des données | Option Cloud Storage recommandée |
|---|---|
| Lectures ou écritures fréquentes | Choisissez la classe de stockage Standard pour les bases de données en cours d'utilisation, car elles peuvent fréquemment accéder à Cloud Storage pour écrire et lire des fichiers de sauvegarde. |
| Lectures ou écritures peu fréquentes | Choisissez le stockage Nearline ou Coldline pour les données auxquelles l'accès est peu fréquent, telles que les sauvegardes archivées qui doivent être conservées conformément aux règles de conservation de votre organisation. Le stockage Nearline offre une bonne solution pour les données sauvegardées auxquelles vous prévoyez d'accéder une fois par mois tout au plus, alors que le stockage Coldline est préférable pour les données dont la probabilité d'accès est très faible, par exemple une fois par an au maximum. |
| Données d'archives | Sélectionnez le stockage de type Archive pour vos données d'archivage à long terme. Le stockage Archive est un bon choix pour les données dont vous devez conserver une copie pendant une période prolongée, mais auxquelles vous n'avez pas l'intention d'accéder plus d'une fois par an. Par exemple, utilisez le stockage Archive pour les sauvegardes que vous devez conserver à long terme pour satisfaire aux exigences réglementaires. Envisagez de remplacer votre solution de sauvegarde sur bande par le stockage de type Archive. |
Lorsque vous planifiez l'utilisation de ces options de stockage, commencez par le niveau le plus utilisé, puis affectez vos données de sauvegarde aux niveaux d'accès peu fréquents. En règle générale, les sauvegardes les plus anciennes sont rarement utilisées. En effet, il est très peu probable que vous ayez besoin d'une sauvegarde vieille de 3 ans. Vous pouvez donc l'affecter au niveau Archive pour réduire les coûts. Pour en savoir plus sur les coûts de Cloud Storage, consultez la page Tarifs de Cloud Storage.
Comparaison entre la sauvegarde dans Cloud Storage et la sauvegarde sur bande
La destination conventionnelle des sauvegardes sur site est la bande. Cloud Storage présente de nombreux avantages par rapport à la bande. Il permet en particulier de stocker automatiquement les sauvegardes hors site à partir du système source, car les données hébergées dans Cloud Storage sont répliquées sur plusieurs installations. De plus, les sauvegardes stockées dans Cloud Storage bénéficient d'une disponibilité élevée.
Les deux solutions de sauvegarde se différencient également par la vitesse de restauration des sauvegardes si vous avez besoin de les utiliser. Si vous devez créer un nouveau système SAP HANA à partir d'une sauvegarde ou restaurer un système existant à partir d'une sauvegarde, Cloud Storage vous permet d'accéder à vos données et de créer le système plus rapidement.
Fonctionnalité Backint de l'agent Google Cloudpour SAP
Vous pouvez directement utiliser Cloud Storage pour les sauvegardes et les récupérations des installations sur site et dans le cloud en utilisant la fonctionnalité Backint certifiée SAP de l'agent Google Cloudpour SAP.
Pour en savoir plus sur cette fonctionnalité, consultez la page Sauvegarde et récupération basées sur Backint pour SAP HANA.
Sauvegarder et récupérer SAP HANA à l'aide de Backint
Les sections suivantes expliquent comment sauvegarder et récupérer SAP HANA à l'aide de la fonctionnalité Backint de l'agent Google Cloudpour SAP.
- Déclencher des sauvegardes de données et delta
- Déclencher des sauvegardes de journaux
- Interroger le catalogue de sauvegarde
- Récupérer une base de données
Déclencher des sauvegardes de données et delta
Pour déclencher une sauvegarde pour le volume de données SAP HANA et l'envoyer à Cloud Storage à l'aide de la fonctionnalité Backint de l'agent Google Cloudpour SAP, vous pouvez utiliser SAP HANA Studio, SAP HANA Cockpit, SAP HANA SQL ou l'outil DBA Cockpit.
Voici des instructions SQL SAP HANA pour déclencher des sauvegardes de données :
Pour créer une sauvegarde complète pour la base de données système :
BACKUP DATA USING BACKINT ('BACKUP_NAME');Remplacez
BACKUP_NAMEpar le nom que vous souhaitez définir pour la sauvegarde.Pour créer une sauvegarde complète pour une base de données locataire :
BACKUP DATA FOR TENANT_SID USING BACKINT ('BACKUP_NAME');Remplacez
TENANT_SIDpar le SID de la base de données locataire.Pour créer des sauvegardes différentielles et incrémentielles :
BACKUP DATA BACKUP_TYPE USING BACKINT ('BACKUP_NAME'); BACKUP DATA BACKUP_TYPE FOR TENANT_SID USING BACKINT ('BACKUP_NAME');Remplacez
BACKUP_TYPEparDIFFERENTIALouINCREMENTAL, selon le type de sauvegarde que vous souhaitez créer.
De nombreuses options sont disponibles lorsque vous déclenchez des sauvegardes de données. Pour en savoir plus sur ces options, consultez la page Instruction BACKUP DATA (sauvegarde et récupération) du guide de référence SQL de SAP HANA.
Pour en savoir plus sur les sauvegardes de données et delta, consultez les documents SAP Sauvegardes de données et Sauvegardes Delta.
Déclencher des sauvegardes de journaux
Pour déclencher une sauvegarde pour le volume de journaux SAP HANA et l'envoyer à Cloud Storage à l'aide de la fonctionnalité Backint de l'agent Google Cloudpour SAP, procédez comme suit:
- Créez une sauvegarde complète de la base de données. Pour obtenir des instructions, consultez la documentation SAP correspondant à votre version de SAP HANA.
- Dans le fichier SAP HANA
global.ini, définissez le paramètrecatalog_backup_using_backintsuryes.
Assurez-vous que le mode de journal de votre système SAP HANA est défini sur normal, qui est la valeur par défaut. Si le mode de journal est défini sur overwrite, la base de données SAP HANA désactive la création de sauvegardes de journaux.
Pour en savoir plus sur les sauvegardes de journaux, consultez le document SAP Sauvegardes de journaux.
Interroger le catalogue de sauvegarde
Le catalogue de sauvegarde SAP HANA est un élément essentiel des opérations de sauvegarde et de récupération. Il contient des informations sur les sauvegardes créées pour la base de données SAP HANA.
Pour interroger le catalogue de sauvegarde afin d'obtenir des informations concernant les sauvegardes d'une base de données locataire, procédez comme suit :
- Mettez la base de données locataire hors connexion.
Sur la base de données système, exécutez l'instruction SQL suivante :
BACKUP COMPLETE LIST DATA FOR TENANT_SID;
Si vous souhaitez interroger le catalogue à un moment précis, vous pouvez également exécuter l'instruction SQL suivante :
BACKUP LIST DATA FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD';
L'instruction crée le fichier
strategyOutput.xmldans le répertoire suivant :/usr/sap/SID/HDBINSTANCE_NUMBER/HOST_NAME/trace/DB_TENANT_SID.
Pour en savoir plus sur l'instruction BACKUP LIST DATA, consultez la page Instruction BACKUP DATA (sauvegarde et récupération) du guide de référence SQL de SAP HANA.
Pour plus d'informations concernant le catalogue de sauvegarde, consultez le document SAP Catalogue de sauvegarde.
Récupérer une base de données
Lorsque vous effectuez une récupération à l'aide d'une sauvegarde de données multiflux, SAP HANA utilise le même nombre de canaux que celui utilisé lors de la création de la sauvegarde. Pour en savoir plus, consultez le document SAP Prérequis : Récupération à l'aide de sauvegardes multiflux.
Pour restaurer une sauvegarde de base de données SAP HANA créée à l'aide de la fonctionnalité Backint de l'agent Google Cloudpour SAP, SAP HANA fournit les instructions SQL RECOVER DATA et RECOVER DATABASE.
Les deux instructions SQL restaurent les sauvegardes à partir du bucket Cloud Storage que vous avez spécifié pour le paramètre bucket dans votre fichier PARAMETERS.json, sauf si vous avez spécifié un bucket pour le paramètre recover_bucket.
Voici des exemples d'instructions SQL pour récupérer une base de données SAP HANA à l'aide d'une sauvegarde que vous avez créée à l'aide de la fonctionnalité Backint de l'agentGoogle Cloudpour SAP:
Pour récupérer une base de données locataire en spécifiant le nom du fichier de sauvegarde :
RECOVER DATA FOR TENANT_SID USING BACKINT('BACKUP_NAME') CLEAR LOG;Pour récupérer une base de données locataire en spécifiant l'ID de sauvegarde :
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID CLEAR LOG;
Remplacez
BACKUP_IDpar l'ID de la sauvegarde requise.Pour récupérer une base de données locataire en spécifiant l'ID de sauvegarde lorsque vous devez utiliser la sauvegarde du catalogue de sauvegarde SAP HANA, qui est stocké dans votre bucket Cloud Storage :
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID USING CATALOG BACKINT CLEAR LOG;
Pour récupérer une base de données locataire à un moment précis ou à une position de journal spécifique :
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CHECK ACCESS USING BACKINT;
Pour récupérer une base de données locataire à l'aide d'une sauvegarde à partir d'une base de données externe :
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CLEAR LOG USING SOURCE 'SOURCE_TENANT_SID@SOURCE_SID' USING CATALOG BACKINT CHECK ACCESS USING BACKINT
Remplacez les éléments suivants :
SOURCE_TENANT_SID: SID de la base de données locataire sourceSOURCE_SID: SID du système SAP où se trouve la base de données locataire source
Si vous devez récupérer une base de données SAP HANA lorsque le catalogue de sauvegarde SAP HANA n'est pas disponible dans la sauvegarde stockée dans votre bucket Cloud Storage, suivez les instructions fournies dans la note SAP 3227931 - Recover a HANA DB From Backint Without a HANA Backup Catalog (3227931 - Récupérer une base de données HANA à partir de Backint sans catalogue de sauvegarde HANA).
Gérer l'identité et l'accès aux sauvegardes
Si vous utilisez Cloud Storage ou Compute Engine pour sauvegarder vos données SAP HANA, l'accès à ces sauvegardes est contrôlé par Identity and Access Management (IAM). Cette fonctionnalité permet aux administrateurs d'autoriser certaines personnes à effectuer des opérations sur des ressources spécifiques. IAM vous offre un contrôle et une visibilité centralisés pour la gestion de toutes vos ressourcesGoogle Cloud , y compris vos sauvegardes.
IAM propose également un historique complet des attributions, suppressions et délégations des autorisations qui est automatiquement mis à la disposition de vos administrateurs. Cette fonctionnalité vous permet de configurer les stratégies qui surveillent l'accès à vos données dans les sauvegardes afin de clore le cycle complet du contrôle d'accès avec vos données. IAM offre une vue unifiée des règles de sécurité pour l'ensemble de l'organisation, avec un système d'audit intégré qui simplifie les processus de conformité.
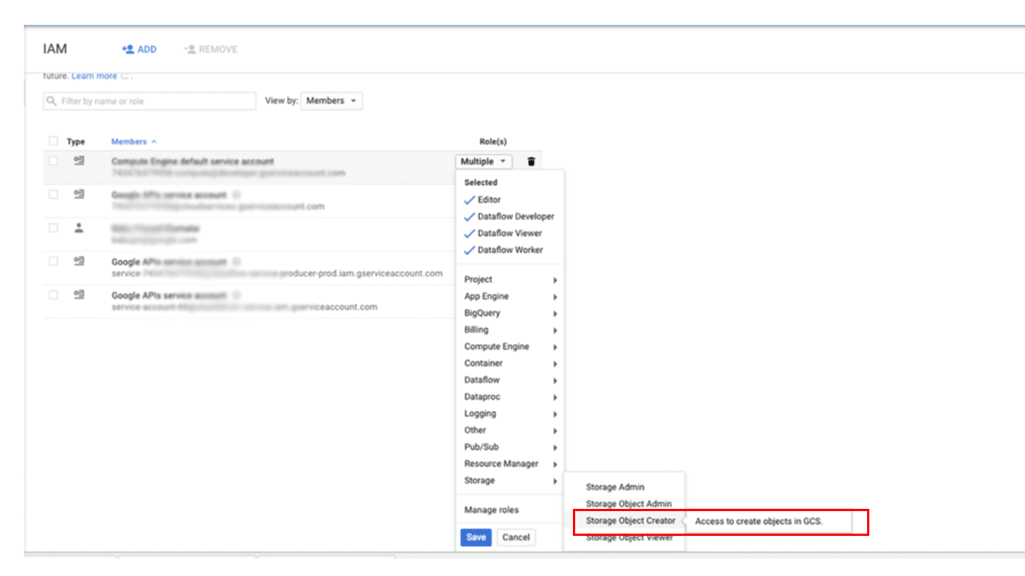
Pour autoriser un compte principal à accéder à vos sauvegardes dans Cloud Storage :
Dans la console Google Cloud , accédez à la page IAM et Administration:
Spécifiez l'utilisateur auquel vous souhaitez accorder l'accès, puis attribuez le rôle Storage > Créateur d'objets Storage :
Comment créer des sauvegardes basées sur le système de fichiers pour SAP HANA
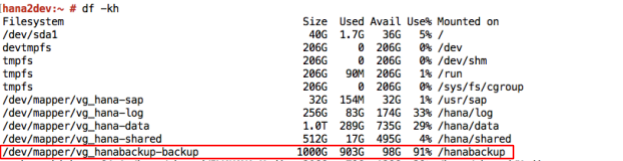
Les systèmes SAP HANA déployés sur Google Cloud à l'aide du guide de déploiement sont configurés avec un ensemble de volumes Persistent Disk ou Hyperdisk à utiliser en tant que destination de sauvegarde installée sur NFS. Les sauvegardes SAP HANA sont d'abord stockées sur ces disques locaux, puis vous devez ensuite les copier dans Cloud Storage pour un stockage à long terme. Vous pouvez copier manuellement les sauvegardes dans Cloud Storage ou programmer la copie dans Cloud Storage dans un crontab.
Si vous utilisez la fonctionnalité Backint de l'agent Google Cloudpour SAP, les sauvegardes et récupérations sont effectuées directement vers et à partir d'un bucket Cloud Storage, ce qui élimine le besoin de stockage sur disque persistant pour les sauvegardes.
Pour démarrer ou programmer les sauvegardes de données SAP HANA, vous pouvez utiliser SAP HANA Studio, les commandes SQL ou DBA Cockpit. À moins d'être désactivées, les sauvegardes de journaux sont écrites automatiquement. La capture d'écran suivante en est un exemple :
Configurer le fichier global.ini de SAP HANA
Si vous avez suivi les instructions du guide de déploiement, le fichier de configuration global.ini de SAP HANA est personnalisé avec les sauvegardes de base de données stockées dans /hanabackup/data/, et les fichiers d'archives de journaux automatiques sont stockés dans /hanabackup/log/. Voici un exemple de ce à quoi ressemble le fichier global.ini :
[persistence]
basepath_datavolumes = /hana/data
basepath_logvolumes = /hana/log
basepath_databackup = /hanabackup/data
basepath_logbackup = /hanabackup/log
[system_information]
usage = production
Pour personnaliser le fichier de configuration global.ini pour la fonctionnalité Backint de l'agentGoogle Cloudpour SAP, consultez la section Configurer SAP HANA pour la fonctionnalité Backint.
Notes concernant les déploiements en scaling horizontal
Dans une mise en œuvre de scaling horizontal, une solution de haute disponibilité qui utilise la migration à chaud et le redémarrage automatique fonctionne de la même manière que dans une configuration à hôte unique. La principale différence réside dans le fait que le volume /hana/shared est installé sur NFS sur tous les hôtes de calcul et maîtrisé sur le maître HANA. Le volume NFS est inaccessible pendant un bref instant en cas de migration à chaud ou de redémarrage automatique de l'hôte maître. Lorsque l'hôte maître redémarre, le volume NFS se remet à fonctionner rapidement sur tous les hôtes, et les opérations normales reprennent automatiquement.
Le volume de sauvegarde SAP HANA, /hanabackup, doit être disponible sur tous les hôtes lors d'opérations de sauvegarde et de récupération. En cas d'échec, vous devez vérifier que le volume /hanabackup est installé sur tous les hôtes. Si ce n'est pas le cas, réinstallez-le sur les hôtes concernés. Si vous décidez de copier l'ensemble de sauvegardes sur un autre volume ou sur Cloud Storage, exécutez la copie sur l'hôte maître pour obtenir de meilleures performances d'E/S et réduire l'utilisation du réseau. Afin de simplifier le processus de sauvegarde et de récupération, vous pouvez utiliser Cloud Storage Fuse pour installer le bucket Cloud Storage sur chaque hôte.
Les performances de scaling horizontal dépendent de la distribution des données. Plus les données sont bien distribuées, meilleures sont les performances de requête. Vous devez donc bien connaître vos données, comprendre comment les données sont consommées, et concevoir la distribution et le partitionnement des tables en conséquence. Pour plus d'informations, consultez la note SAP 2081591 - FAQ: SAP HANA Table Distribution (2081591 - FAQ : Distribution de table SAP HANA).
Gcloud Python
Gcloud Python est un client Python idiomatique permettant d'accéder aux servicesGoogle Cloud . Ce guide se sert de Gcloud Python pour effectuer des opérations de sauvegarde et de restauration depuis et vers Cloud Storage pour vos sauvegardes de bases de données SAP HANA.
Si vous avez suivi les instructions du guide de déploiement, les bibliothèques Gcloud Python sont déjà disponibles dans les instances Compute Engine.
Les bibliothèques sont Open Source et vous permettent d'utiliser votre bucket Cloud Storage pour stocker et récupérer les données de sauvegarde.
Vous pouvez exécuter la commande suivante pour obtenir la liste des objets de votre bucket Cloud Storage. Elle peut vous servir à lister les sauvegardes disponibles :
python 2>/dev/null - <<EOF
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("<bucket_name>")
blobs = bucket.list_blobs()
for fileblob in blobs:
print(fileblob.name)
EOF
Pour plus d'informations sur Gcloud Python, consultez la documentation de référence sur les bibliothèques clientes de stockage.
Exemple de sauvegarde et restauration
Les sections suivantes illustrent la procédure à suivre pour les tâches de sauvegarde et de restauration typiques à l'aide de SAP HANA Studio.
Exemple de création d'une sauvegarde
Dans l'éditeur de sauvegarde de SAP HANA, sélectionnez Open Backup Wizard (Ouvrir l'assistant de sauvegarde).
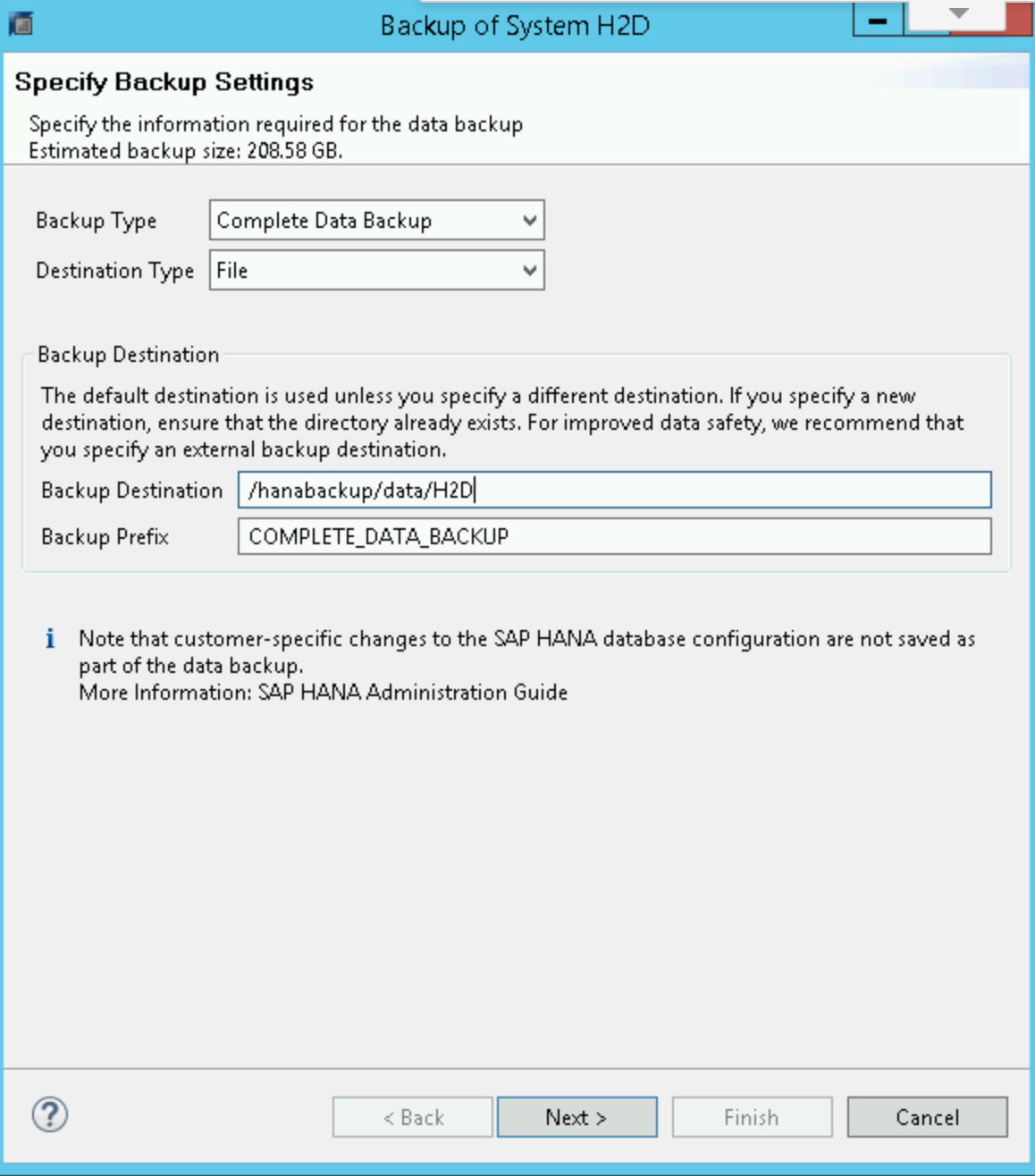
- Sélectionnez File (Fichier) pour le type de destination. Vous sauvegarderez ainsi la base de données dans des fichiers du système de fichiers spécifié.
- Indiquez la destination de la sauvegarde (
/hanabackup/data/SID) et le préfixe de la sauvegarde. RemplacezSIDpar l'ID système de votre système SAP. - Cliquez sur Suivant.
Cliquez sur Finish (Terminer) dans le formulaire de confirmation pour démarrer la sauvegarde.
Au démarrage de la sauvegarde, une fenêtre d'état affiche la progression. Attendez la fin de la sauvegarde.
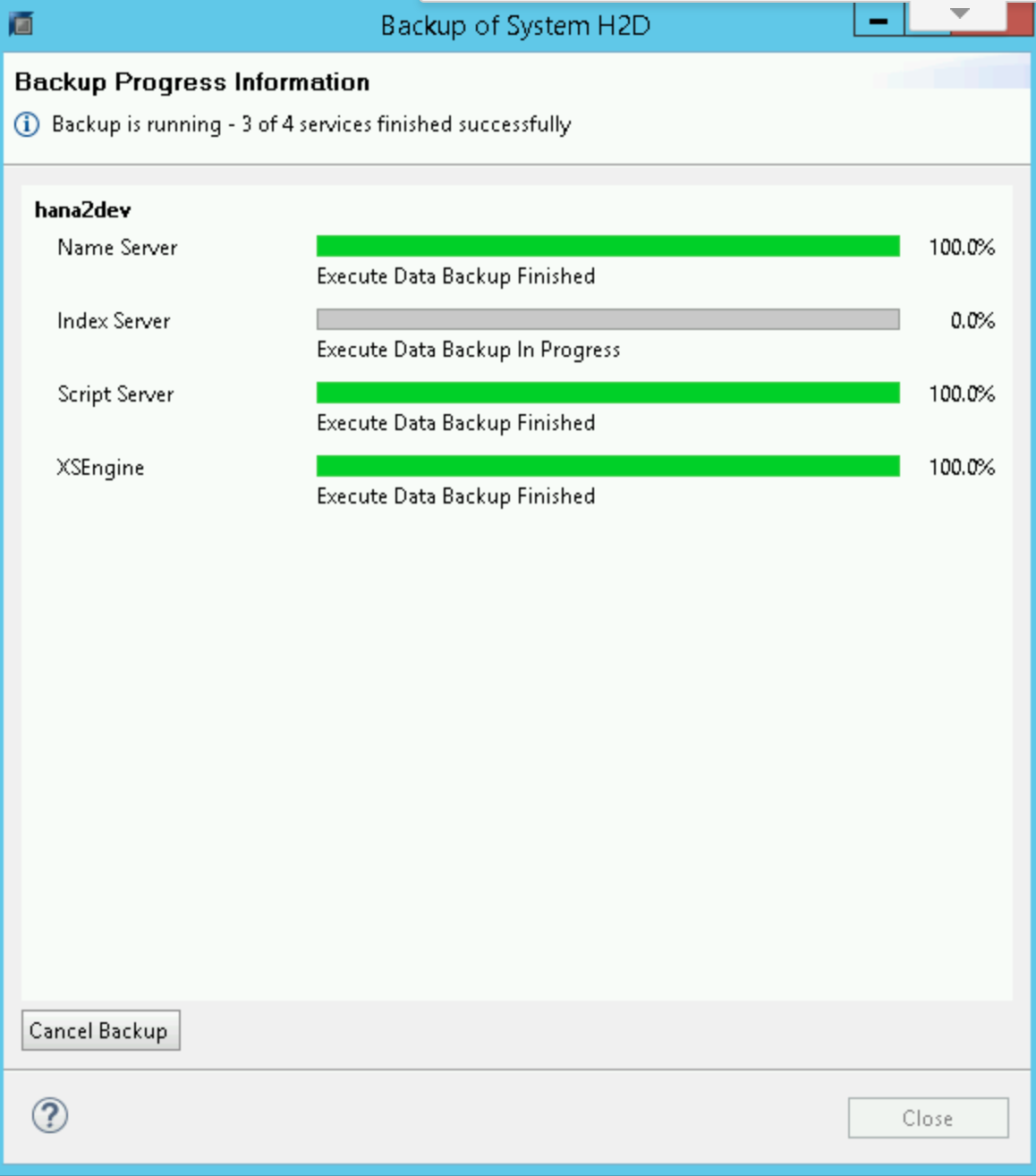
Une fois la sauvegarde terminée, le résumé de la sauvegarde affiche le message
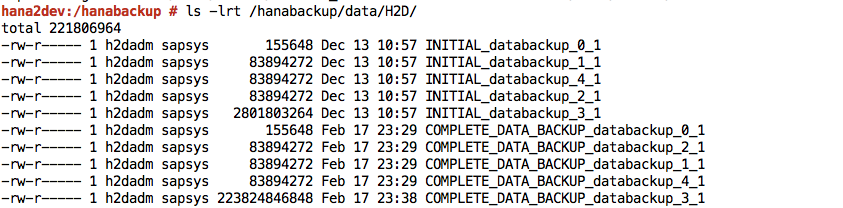
Finished.Connectez-vous à votre système SAP HANA et vérifiez que les sauvegardes sont disponibles aux emplacements prévus dans le système de fichiers. Exemple :

Transférez ou synchronisez les fichiers de sauvegarde du système de fichiers
/hanabackupvers Cloud Storage. L'exemple de script Python suivant transfère les données de/hanabackup/dataet de/hanabackup/logau bucket utilisé pour les sauvegardes, sous la formeNODE_NAME/DATAouLOG/YYYY/MM/DD/HH/BACKUP_FILE_NAME. Vous pouvez ainsi identifier les fichiers de sauvegarde selon la durée de copie de la sauvegarde. Exécutez le scriptgcloud Pythonsuivant sur l'invite bash de votre système d'exploitation :python 2>/dev/null - <<EOF import os import socket from datetime import datetime from google.cloud import storage storage_client = storage.Client() today = datetime.today() current_hour = today.strftime('%Y/%m/%d/%H') hostname = socket.gethostname() bucket = storage_client.get_bucket("hanabackup") for subdir, dirs, files in os.walk('/hanabackup/data/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/data/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) for subdir, dirs, files in os.walk('/hanabackup/log/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/log/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) EOFPour obtenir la liste des données de sauvegarde, utilisez les bibliothèques Gcloud Python ou la console Google Cloud .
Exemple de restauration d'une sauvegarde
Si les fichiers de sauvegarde ne sont pas disponibles dans le répertoire
/hanabackupmais sont disponibles dans Cloud Storage, téléchargez-les à partir de Cloud Storage en exécutant le script suivant depuis l'invite bash du système d'exploitation :python - <<EOF from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket("hanabackup") blobs = bucket.list_blobs() for fileblob in blobs: blob = bucket.blob(fileblob.name) fname = str(fileblob.name).split('/')[-1] blob.chunk_size=1<<30 if 'log' in fname: blob.download_to_filename('/hanabackup/log/H2D/' + fname) else: blob.download_to_filename('/hanabackup/data/H2D/' + fname) EOFPour récupérer la base de données SAP HANA, cliquez sur Sauvegarde et récupération > Récupérer le système :
Cliquez sur Suivant.
Spécifiez l'emplacement de vos sauvegardes dans votre système de fichiers local, puis cliquez sur Ajouter.
Cliquez sur Suivant.
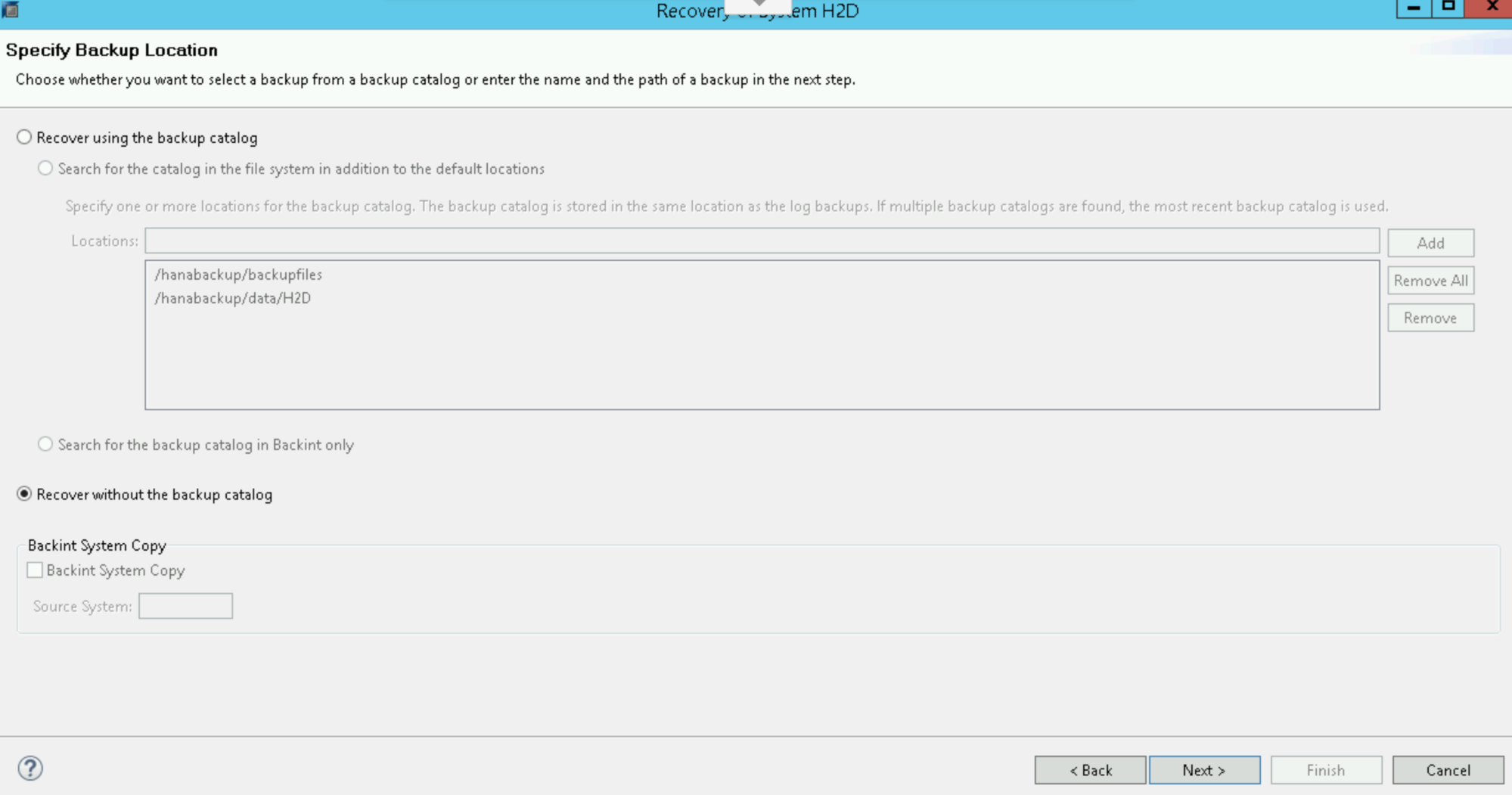
Sélectionnez Recover without the backup catalog (Récupérer sans le catalogue de sauvegarde) :
Cliquez sur Suivant.
Sélectionnez File (Fichier) pour le type de destination, puis spécifiez l'emplacement des fichiers de sauvegarde et le préfixe correspondant à votre sauvegarde. Si vous avez suivi la procédure de la section Exemple de création d'une sauvegarde, n'oubliez pas que
COMPLETE_DATA_BACKUPa été défini comme préfixe.Cliquez deux fois sur Next (Suivant).
Cliquez sur Finish (Terminer) pour démarrer la récupération.
Une fois la récupération achevée, reprenez les opérations normales et supprimez les fichiers de sauvegarde des répertoires
/hanabackup/data/SID/*.
Étapes suivantes
Les documents standards suivants relatifs à SAP pourraient vous être utiles :
Les documents suivants Google Cloud peuvent également vous être utiles:
- Fonctionnalités cloud et offre d'essai sans frais
- Premiers pas avec Google Cloud
- Compute Engine
- Persistent Disk