Ce guide présente les options de reprise après sinistre pour les systèmes SAP HANA déployés sur Google Cloud.
Ce guide n'a pas pour vocation de remplacer la documentation standard de SAP.
Préparer la reprise après sinistre
Pour vous préparer à la survenue de sinistres, vous pouvez procéder à la réplication du système SAP HANA sur un système SAP HANA secondaire, effectuer des sauvegardes de SAP HANA pour permettre la récupération, ou appliquer ces deux méthodes.
Pour les charges de travail critiques nécessitant des temps de récupération rapides, utilisez la réplication du système HANA afin de minimiser les temps d'arrêt. La récupération d'un système à l'aide de sauvegardes est moins onéreuse. Cela prend toutefois plus de temps, car un système doit être créé, puis les sauvegardes doivent être restaurées sur celui-ci pour effectuer une récupération au moment souhaité.
Dans les deux cas, vous devez faire appel à la redirection basée sur le réseau pour rediriger les applications clientes utilisant le système SAP HANA vers l'adresse IP du système de remplacement, une fois celui-ci disponible. Pour en savoir plus, consultez la page SAP HANA Administration Guide.
À compter de SAP HANA SPS09, vous pouvez utiliser l'API basée sur Python incluse dans SAP HANA pour créer votre propre fournisseur de haute disponibilité/reprise après sinistre (HA/DR, High Availability/Disaster Recovery). Vous l'intégrez ensuite au processus de prise de relais de la réplication du système SAP HANA afin d'automatiser des tâches, comme la redirection des connexions de client de base de données du système principal vers le système secondaire après une prise de relais. Pour en savoir plus, consultez la page Implementing a HA/DR Provider (Mettre en œuvre un fournisseur de haute disponibilité/reprise après sinistre).
Notez que toutes les restrictions définies par SAP, y compris la limite de distance pour la réplication synchrone, sont également appliquées sur Google Cloud.
Au lieu d'options de reprise après sinistre natives, pour la reprise après sinistre active-passive interrégionale, vous pouvez utiliser la réplication asynchrone des disques persistants. La réplication asynchrone des disques persistants fournit une réplication asynchrone des données entre deux régionsGoogle Cloud .
Reprise après sinistre à l'aide de la réplication du système SAP HANA
Pour optimiser l'utilisation des ressources d'infrastructure et les coûts de votre solution de DR, vous pouvez vous servir du système secondaire pour des cas d'utilisation hors production, par exemple pour un système de développement ou de contrôle qualité. Dans ce cas, les données ne sont pas préchargées sur le système secondaire. Le temps de basculement est donc plus long que lorsqu'elles sont préchargées sur le système et que celui-ci est synchronisé avec le système principal.
HANA 2 SPS00 est compatible avec le mode de configuration "actif/actif" (activé en lecture), qui permet à la réplication du système SAP HANA de prendre en charge l'accès en lecture sur le système secondaire. Pour en savoir plus, consultez la page Active/Active (Read Enabled).
Les réplications synchrone et asynchrone sont toutes deux prises en charge en cas d'utilisation de la réplication du système SAP HANA avec Google Cloud.
Si possible, nous vous recommandons d'opter pour la réplication synchrone, dans laquelle le commit des transactions SQL n'est effectué sur l'instance de base de données principale que lorsqu'il a eu lieu sur l'instance de secours. Cela garantit une synchronisation totale de l'instance de secours et un objectif de point de récupération nul. La réplication synchrone peut être utilisée pour des instances résidant dans n'importe quelle zone d'une même région.
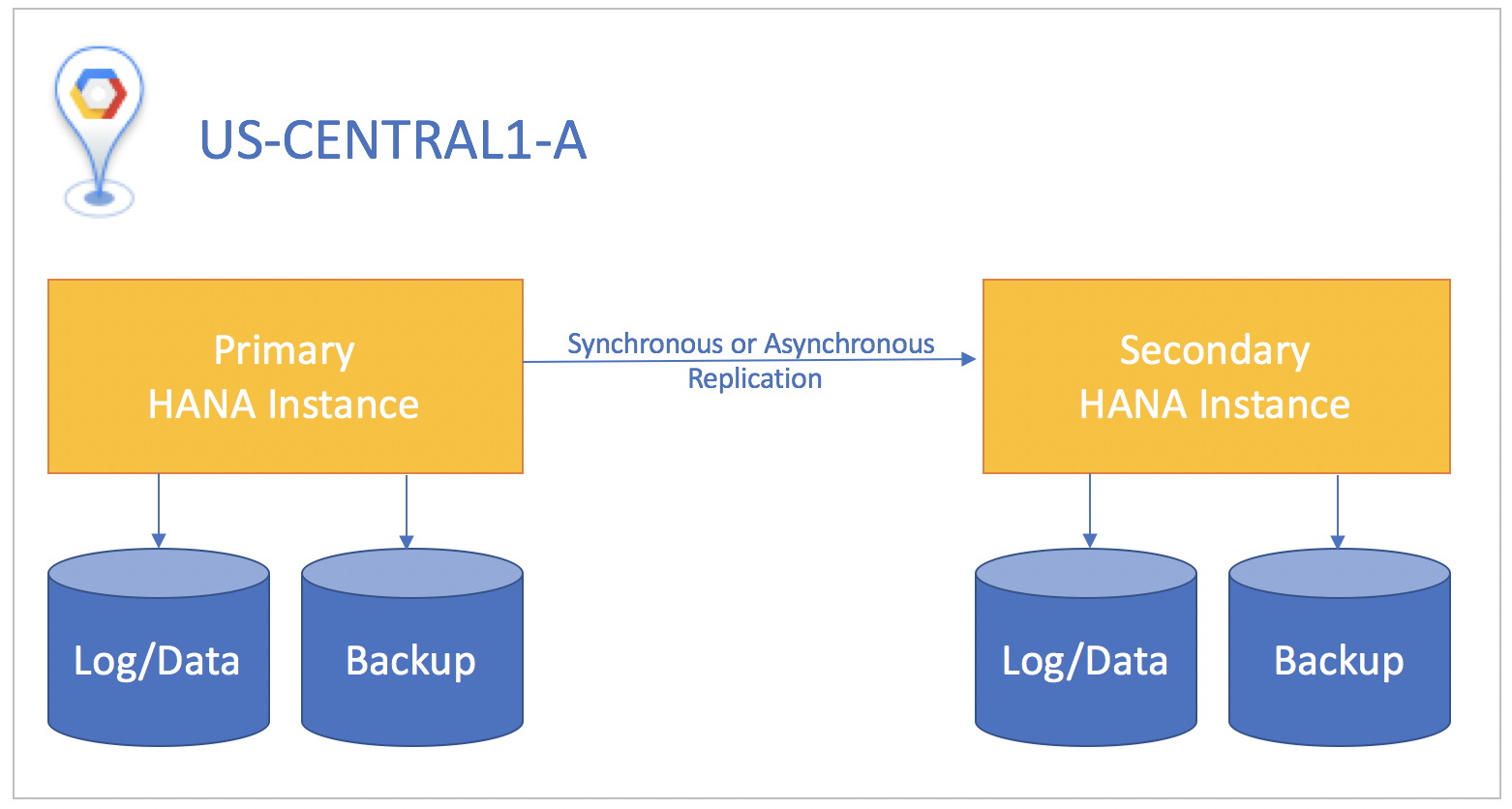
Si le système de secours se trouve dans une région différente de celle du système principal, optez pour la réplication asynchrone. Il n'est pas nécessaire d'attendre que l'instance de secours accuse réception des données avant de procéder au commit sur l'instance principale. Dans ce scénario, vous risquez de perdre de petites quantités de données en cas de sinistre. Par contre, la réplication asynchrone vous offre un objectif de point de récupération supérieur à zéro.
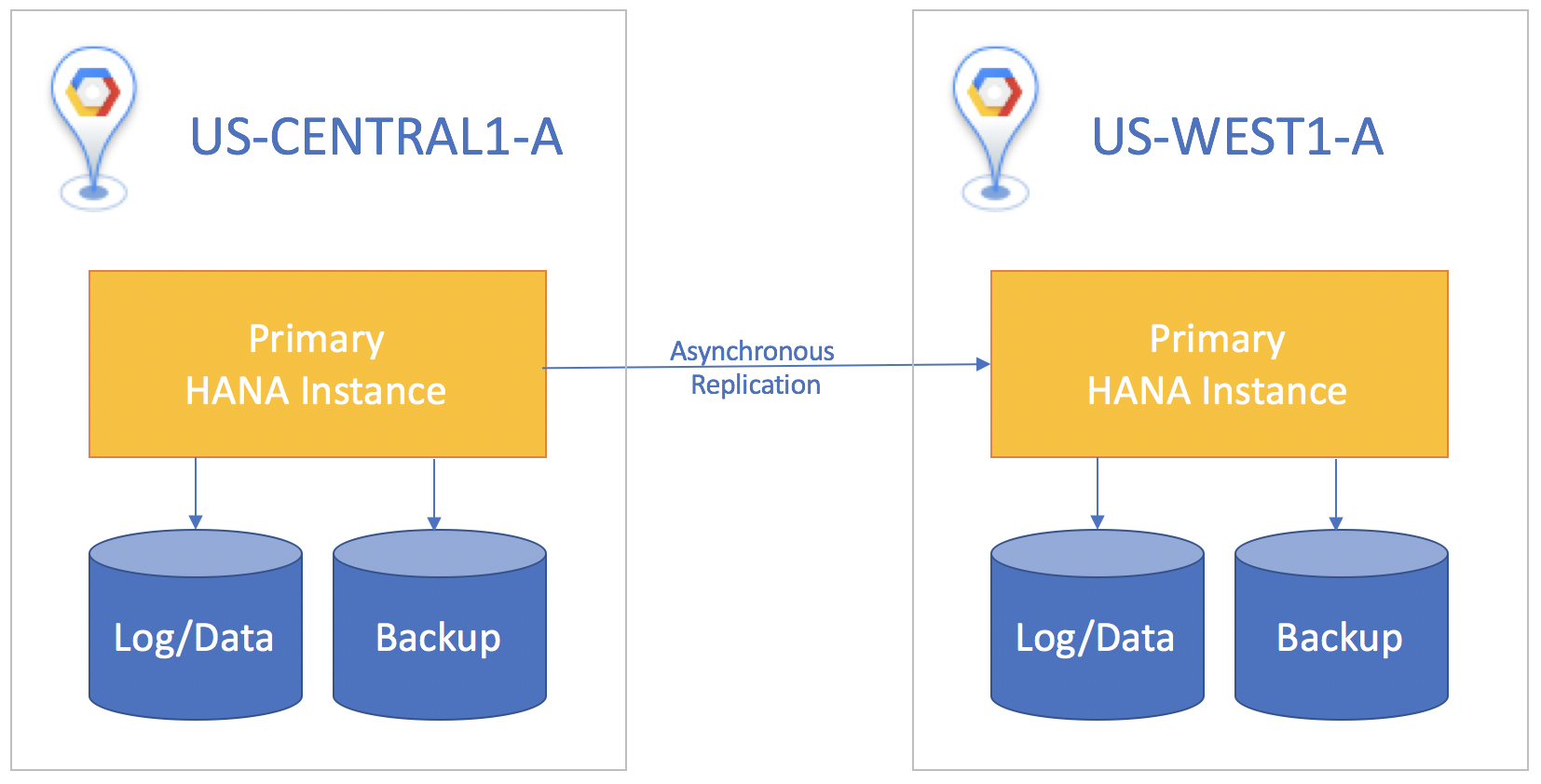
Dans tous les scénarios de réplication, vous devez lancer manuellement une prise de relais sur le système de secours pour lancer la reprise après sinistre. Vous devez également rediriger manuellement les applications utilisant la base de données SAP HANA pour cibler l'instance vers laquelle elle a basculé dans le système de secours.
Choisissez l'option de réplication du système HANA qui correspond le mieux aux besoins de votre entreprise, tels que l'objectif de temps de récupération (RTO, Recovery Time Objective) et l'objectif de point de récupération (RPO, Recovery Point Objective). Pour en savoir plus, consultez la page Replication Modes for SAP HANA System Replication.
Réplication du système SAP HANA avec précharge
Dans ce scénario, votre système SAP HANA est répliqué sur un système de secours dédié. La base de données SAP HANA est répliquée sur une VM Compute Engine dotée d'un nom d'hôte unique et de ses propres disques persistants associés. Toutes les données SAP HANA sont chargées en mémoire sur le système de secours. Si vous devez effectuer un basculement, ce dernier ne prend que 90 secondes environ, car toutes les données sont préchargées.
Pour en savoir plus sur la réplication du système SAP HANA avec précharge, consultez la section Réplication système de la page SAP HANA – Haute disponibilité.
Réplication du système SAP HANA sans précharge
Dans ce scénario, votre système SAP HANA est répliqué sur un système de secours dédié. La base de données SAP HANA est répliquée sur une VM Compute Engine dotée d'un nom d'hôte unique et de ses propres disques persistants associés. Les données SAP HANA ne sont pas chargées en mémoire sur le système de secours. Si vous devez effectuer un basculement, ce dernier peut prendre de quelques minutes à plusieurs heures, en fonction de la taille de votre ensemble de données.
Lorsque vous ne préchargez pas les données, la VM Compute Engine qui héberge la base de données SAP HANA exige bien moins de mémoire. Pour obtenir les conseils de dimensionnement les plus à jour, consultez la note SAP 1999880 – Questions fréquentes : réplication du système SAP HANA sous "Quelles règles s'appliquent à l'utilisation de la mémoire sur les sites de réplication du système secondaire ?".
Pour obtenir des informations sur l'espace mémoire utilisé par le rowstore, exécutez la requête suivante :
SELECT round (sum(USED_FIXED_PART_SIZE + USED_VARIABLE_PART_SIZE)/1024/1024) AS "Row Tables MB" FROM M_RS_TABLES;
Les exigences réduites en matière de mémoire vous permettent de réaliser des économies lorsque vous choisissez un type de machine Compute Engine.
Afin de réduire vos coûts d'exploitation, vous pouvez choisir un type de machine à faible capacité de mémoire pour héberger la base de données SAP HANA dans le système de secours. Ce type de VM, qui est moins coûteux, n'est pas pris en charge pour SAP HANA dans un système de production. Toutefois, vous pouvez l'utiliser pour lancer une prise de relais dans un scénario de reprise après sinistre, puis modifier la VM pour passer à type de machine doté d'une quantité de mémoire compatible. Pour ce faire, vous devez arrêter la VM pour effectuer la mise à niveau. Un temps d'arrêt supplémentaire est donc nécessaire avant que le système SAP HANA soit disponible.
Vous pouvez choisir un type de machine à haute capacité de mémoire pour héberger la base de données SAP HANA dans le système de secours, et le partager avec des systèmes de développement ou de test afin d'améliorer votre retour sur investissement. Vous pouvez définir la limite d'allocation globale pour la base de données SAP HANA sur 64 Go en suivant les instructions figurant sur la page Change the Global Memory Allocation Limit, et laisser le reste de la mémoire aux autres systèmes. Lorsque vous avez besoin du système de secours, arrêtez les opérations de développement et de test, lancez une prise de relais, puis supprimez la limite d'allocation globale.
Vous pouvez effectuer une réplication sans précharge tant en mode synchrone qu'asynchrone. Cependant, la réplication synchrone nécessite que les instances source et cible se trouvent dans la même Google Cloud région.
Vous pouvez recourir à un fournisseur HA/DR pour résoudre des problèmes tels que l'arrêt des systèmes de développement et/ou de test sur l'hôte secondaire.
Déclencher une prise de relais
Pour appeler la reprise après sinistre, déclenchez la procédure de prise de relais de la réplication du système SAP HANA dans votre système de secours. La note SAP 2063657 fournit des conseils afin de vous aider à déterminer si la prise de relais est votre meilleure option.
Pour déclencher la prise de relais, suivez le processus SAP HANA standard. Pour obtenir plus d'informations sur cette procédure, consultez la page How To Perform System Replication for SAP HANA 2.0.
En cas de problème lié aux données ou de défaillance logicielle, il se peut que vous ne receviez pas de notifications automatiques vous indiquant que vous pouvez lancer la prise de relais. Envisagez de créer une solution personnalisée d'envoi d'alertes à l'aide des outils de surveillance Cloud Monitoring ou HANA.
Reprise après sinistre à l'aide des sauvegardes SAP HANA
Si un RTO plus long est acceptable et que votre RPO est supérieur à 15 minutes, vous pouvez procéder à la reprise après sinistre en restaurant les données à partir d'une sauvegarde. Pour garantir la réussite de la reprise lors de l'utilisation de sauvegardes, effectuez des copies fréquentes de vos fichiers de sauvegarde, en particulier des sauvegardes de journaux, dans un bucket Cloud Storage ou dans un autre emplacement de stockage à long terme existant en dehors de la région où votre système SAP HANA est exécuté. Nous vous recommandons de documenter l'infrastructure de votre système principal et de créer des scripts vous permettant de créer rapidement un système de remplacement sur lequel restaurer vos sauvegardes.
Pour en savoir plus, consultez la page Guide d'utilisation de SAP HANA.
Reprise après sinistre à l'aide de la réplication asynchrone des disques persistants
Pour vos charges de travail SAP exécutées sur Google Cloud, la réplication asynchrone des disques persistants permet la reprise après sinistre en répliquant les données entre deux régions Google Cloud . La réplication asynchrone des disques persistants fournit une réplication de stockage de blocs à faibles RPO (objectif de point de récupération faible) et RTO (objectif de temps de récupération) conçue pour la reprise après sinistre active/passive interrégionale Dans le cas peu probable d'une panne régionale, la réplication asynchrone des disques persistants vous permet de basculer vos données SAP vers une région secondaire et de redémarrer votre charge de travail SAP dans cette région.
Vous pouvez utiliser la réplication asynchrone des disques persistants pour gérer la réplication pour les charges de travail SAP basées sur Compute Engine au niveau de l'infrastructure, plutôt que au niveau de la charge de travail SAP, comme la réplication du système SAP HANA.
La réplication asynchrone des disques persistants réplique les données SAP d'un disque principal associé à une charge de travail en cours d'exécution sur un disque vide secondaire situé dans une autre région. Pour en savoir plus, consultez la page À propos de la réplication asynchrone des disques persistants.
Limites de la réplication asynchrone des disques persistants
Pour la réplication asynchrone des disques persistants, vous ne pouvez utiliser que des volumes disques persistants avec équilibrage (pd-balanced) et disques persistants SSD (pd-ssd) dans les paires de régions compatibles.
Pour en savoir plus, consultez la section Limites.
Surveillez et évaluez le taux de variation de votre charge de travail par rapport à la fonctionnalité de réplication asynchrone des disques persistants en consultant les métriques de surveillance de votre paire d'appareils, comme décrit dans la section Examiner les performances de réplication asynchrone des disques persistants.
La métrique async_replication/sent_bytes_count ne doit pas montrer une augmentation constante de la quantité de données transférées, car elle représente le delta du nombre d'octets envoyés via le réseau interrégional.