Este guia fornece uma visão geral das opções, recomendações e conceitos gerais que você precisa conhecer antes de implantar um sistema SAP HANA de alta disponibilidade (HA) no Google Cloud.
Presume-se que você já tenha uma compreensão dos conceitos e práticas geralmente necessários para implementar um sistema de alta disponibilidade do SAP HANA. Portanto, o guia se concentra principalmente no que você precisa saber para implementar esse sistema no Google Cloud.
Para saber mais sobre os conceitos e práticas gerais necessários para implementar um sistema de alta disponibilidade do SAP HANA, consulte:
- O documento de práticas recomendadas da SAP sobre Como criar alta disponibilidade para SAP NetWeaver e SAP HANA no Linux
- A documentação do SAP HANA
Este guia de planejamento é voltado exclusivamente à alta disponibilidade do SAP HANA e não de sistemas de banco de dados. Para informações sobre alta disponibilidade do SAP NetWeaver, consulte o Guia de planejamento de alta disponibilidade para SAP NetWeaver no Google Cloud.
Este guia não substitui nenhuma documentação fornecida pela SAP.
Opções de alta disponibilidade para SAP HANA no Google Cloud
É possível usar uma combinação de recursos do Google Cloud e do SAP no design de uma configuração de alta disponibilidade para SAP HANA que possa lidar com falhas nos níveis de infraestrutura ou de software. A tabela a seguir descreve os recursos do SAP e do Google Cloud usados para fornecer alta disponibilidade.
| Recurso | Descrição |
|---|---|
| Migração em tempo real do Compute Engine |
O Compute Engine monitora o estado da infraestrutura subjacente e migra automaticamente a instância para longe de um evento de manutenção da infraestrutura. Nenhuma intervenção do usuário é necessária. O Compute Engine mantém a instância em execução durante a migração, se possível. No caso de interrupções maiores, pode haver um pequeno atraso entre o momento em que a instância cai e quando ela está disponível. Em sistemas com vários hosts, os volumes compartilhados, como o volume `/hana/shared` usado no guia de implantação, são discos permanentes conectados à VM que hospeda o host mestre e montados em NFS nos hosts de trabalho. O volume NFS fica inacessível por até alguns segundos no caso de migração do host mestre em tempo real. Quando o host mestre é reiniciado, o volume NFS funciona novamente em todos os hosts e a operação normal é retomada automaticamente. Uma instância recuperada é idêntica à instância original, incluindo o ID da instância, o endereço IP particular e todos os metadados e armazenamentos dela. Por padrão, as instâncias padrão são configuradas para migrar em tempo real. Recomendamos não alterar essa configuração. Para mais informações, consulte Migração em tempo real. |
| Reinicialização automática do Compute Engine |
Se a instância estiver definida para encerrar quando houver um evento de manutenção ou se a instância falhar devido a um problema de hardware subjacente, configure o Compute Engine para reiniciar a instância automaticamente. Por padrão, as instâncias são definidas para reiniciar automaticamente. Recomendamos não alterar essa configuração. |
| Reinicialização automática do serviço SAP HANA |
A reinicialização automática do serviço SAP HANA é uma solução de recuperação de falhas fornecida pelo SAP. O SAP HANA tem muitos serviços configurados em execução o tempo todo para várias atividades. Quando algum desses serviços é desativado devido a uma falha de software ou erro humano, a função guardiã de reinicialização automática do serviço SAP HANA o reinicia automaticamente. Quando o serviço é reiniciado, ele carrega todos os dados necessários de volta na memória e retoma a operação. |
| Backups do SAP HANA |
Os backups do SAP HANA criam cópias do seu banco de dados que podem ser usadas para reconstruí-lo em um determinado momento. Para mais informações sobre o uso de backups do SAP HANA no Google Cloud, consulte o Guia de operações do SAP HANA. |
| Replicação de armazenamento do SAP HANA |
A replicação de armazenamento do SAP HANA fornece suporte à recuperação de desastres no nível de armazenamento por meio de determinados parceiros de hardware. A replicação de armazenamento do SAP HANA não é compatível com Google Cloud. Você pode considerar o uso de snapshots de disco permanente do Compute Engine. Para mais informações sobre como usar snapshots disco permanente para fazer backup de sistemas SAP HANA no Google Cloud, consulte o Guia de operações do SAP HANA. |
| Failover automático de host do SAP HANA |
O failover automático de host do SAP HANA é uma solução local de recuperação de falhas que requer um ou mais hosts do SAP HANA em modo de espera em um sistema de escalonamento horizontal. Se um dos hosts principais falhar, o failover automático do host coloca o host em espera on-line automaticamente e reinicia o host com falha como host em espera. Veja mais informações em: |
| Replicação do sistema SAP HANA |
A replicação do sistema SAP HANA permite configurar um ou mais sistemas para assumir o controle do sistema principal em cenários de alta disponibilidade ou recuperação de desastres. Ajuste a replicação para atender às suas necessidades em termos de desempenho e tempo de failover. |
| Opção de reinicialização rápida do SAP HANA (recomendado) |
Se o SAP HANA for encerrado, a reinicialização rápida do SAP HANA reduzirá os tempos de reinicialização e
manterá o sistema operacional em execução. O SAP HANA reduz
o tempo de reinicialização por meio de sua funcionalidade de memória permanente,
que preserva fragmentos de dados MAIN das tabelas de armazenamento de coluna
na DRAM que é mapeada para o sistema de arquivos Para mais informações sobre como usar a opção de reinicialização rápida do SAP HANA, consulte os guias de implantação de alta disponibilidade: |
| Ganchos do provedor de alta disponibilidade/DR do SAP HANA (recomendado) |
Os ganchos do provedor de alta disponibilidade/DR do SAP HANA permitem que ele envie ao cluster do Pacemaker
notificações com relação a determinados eventos, a fim de melhorar
a detecção de falhas. Os ganchos do provedor de alta disponibilidade/DR do SAP HANA exigem
Para mais informações sobre como usar os ganchos do provedor de alta disponibilidade/DR do SAP HANA, consulte os guias de implantação de alta disponibilidade: |
Clusters de alta disponibilidade nativos do SO para SAP HANA no Google Cloud
O cluster do sistema operacional Linux fornece reconhecimento de aplicativo e convidado para o estado do aplicativo e automatiza ações de recuperação em caso de falha.
Os princípios de cluster de alta disponibilidade que se aplicam a ambientes que não são de nuvem geralmente se aplicam ao Google Cloud, mas existem diferenças na implementação de alguns elementos, como IPs de isolamento e virtuais.
É possível usar as distribuições Linux de alta disponibilidade de Red Hat ou SUSE para seu cluster de alta disponibilidade para SAP HANA no Google Cloud.
Para instruções sobre como implantar e configurar manualmente um cluster de alta disponibilidade no Google Cloud para SAP HANA, consulte:
- Configuração manual do cluster de escalonamento vertical de alta disponibilidade no RHEL
- Configuração manual do cluster de alta disponibilidade no SLES:
Para as opções de implantação automatizada fornecidas pelo Google Cloud, consulte Opções de implantação automatizada para configurações de alta disponibilidade do SAP HANA.
Agentes de recursos de cluster
O Red Hat e o SUSE fornecem agentes de recursos para Google Cloud com as implementações de alta disponibilidade do software de cluster do Pacemaker. Os agentes de recursos do Google Cloud gerenciam isolamentos, VIPs que são implementados com rotas ou IPs de alias e ações de armazenamento.
Para disponibilizar atualizações que ainda não estão incluídas nos agentes de recursos do SO de base, oGoogle Cloud fornece periodicamente agentes de recursos complementares para clusters de alta disponibilidade para SAP. Quando esses agentes de recursos complementares são necessários, os procedimentos de implantação doGoogle Cloud incluem uma etapa de download deles.
Agentes de isolamento
O Isolamento, no contexto do Google Cloud clustering do SO do Compute Engine, assume a forma de STONITH, que permite que cada membro em um cluster de dois nós reinicie o outro nó.
OGoogle Cloud fornece dois agentes de isolamento para uso com SAP em sistemas operacionais
Linux: o agente fence_gce, incluído nas distribuições
Red Hat e SUSE Linux certificadas, e o agente gcpstonith legado, que também pode ser
feito o download para uso com distribuições Linux que não incluem o
agente fence_gce. Recomendamos o uso do agente fence_gce, se
disponível.
Permissões do IAM necessárias para agentes de isolamento
Os agentes de isolamento reiniciam as VMs fazendo uma chamada de redefinição para a API Compute Engine. Para autenticação e autorização para acessar a API, os agentes de isolamento usam a conta de serviço da VM. A conta de serviço que um agente de isolamento usa precisa receber um papel que inclua as seguintes permissões:
- compute.instances.get
- compute.instances.list
- compute.instances.reset
- compute.instances.start
- compute.instances.stop
- compute.zoneOperations.get
- logging.logEntries.create
- compute.zoneOperations.list
O papel predefinido de Administrador da instância da computação contém todas as permissões necessárias.
Para limitar o escopo da permissão de reinicialização do agente ao nó de destino, configure o acesso baseado em recursos. Para mais informações, consulte Como configurar o acesso baseado em recursos.
Endereço IP virtual
Os clusters de alta disponibilidade para SAP no Google Cloud usam um endereço IP virtual ou flutuante (VIP) para redirecionar o tráfego de rede de um host para outro no caso de um failover.
Implantações comuns fora da nuvem usam uma solicitação gratuita do protocolo de resolução de endereços (ARP, na sigla em inglês) para anunciar o movimento e a realocação de um VIP para um novo endereço MAC.
No Google Cloud, em vez de usar solicitações ARP gratuitas, use um dos vários métodos diferentes para mover e realocar um VIP em um cluster de alta disponibilidade. Recomenda-se usar um balanceador de carga TCP/UDP interno, mas, dependendo das suas necessidades, também é possível usar uma implementação de VIP baseada em rota ou uma implementação de VIP baseada em IP de alias.
Para mais informações sobre a implementação de VIP no Google Cloud, consulte Implementação de IP virtual no Google Cloud.
Armazenamento e replicação
Uma configuração de cluster de alta disponibilidade do SAP HANA usa a replicação síncrona do sistema SAP HANA para manter os bancos de dados primário e secundário do SAP HANA sincronizados. Os agentes de recursos padrão fornecidos pelo SO para SAP HANA gerenciam a replicação do sistema durante um failover, iniciando e interrompendo a replicação e alternando quais instâncias estão sendo veiculadas como instâncias ativas e em espera no processo de replicação.
Para armazenamento de arquivos compartilhado, os arquivadores baseados em NFS ou SMB poderão fornecer a funcionalidade necessária.
Para uma solução de armazenamento compartilhado de alta disponibilidade, use o Filestore, o nível de serviço Premium ou Extreme do Google Cloud NetApp Volumes ou uma solução de compartilhamento de arquivos de terceiros. O nível de serviço regional (anteriormente Enterprise) do Filestore pode ser usado para implantações em várias zonas, e o nível Básico do Filestore pode ser usado para implantações em zona única.
Os discos permanentes regionais do Compute Engine oferecem armazenamento em blocos replicado de forma síncrona nas zonas. Os discos permanentes regionais não são compatíveis com o armazenamento do banco de dados em sistemas de alta disponibilidade do SAP, mas é possível usá-los com servidores de arquivos NFS.
Para mais informações sobre as opções de armazenamento em Google Cloud, consulte:
Configurações de clusters de alta disponibilidade em Google Cloud
OGoogle Cloud recomenda alterar os valores padrão de determinados parâmetros de configuração de cluster para valores mais adequados a sistemas SAP no ambiente Google Cloud . Se você usa os scripts de automação fornecidos por Google Cloud, os valores recomendados são definidos para você.
Considere os valores recomendados como um ponto de partida para ajustar as configurações do Corosync no seu cluster de HA. Confirme se a sensibilidade da detecção de falhas e do acionamento de failover é apropriada para seus sistemas e cargas de trabalho no ambiente Google Cloud .
Valores do parâmetro de configuração do Corosync
Nos guias de configuração do cluster de alta disponibilidade para SAP HANA,o Google Cloud
recomenda valores para vários parâmetros
na seção totem do arquivo de configuração corosync.conf que são
diferentes dos valores padrão definidos pelo Corosync ou pelo distribuidor
do Linux.
totem para os quais o Google Cloud
recomenda valores, além do impacto da alteração dos valores. Para os valores padrão
desses parâmetros, que podem diferir entre as distribuições do Linux, consulte a documentação da distribuição do Linux.
| Parâmetro | Valor recomendado | Impacto da alteração do valor |
|---|---|---|
secauth |
off |
Desativa a autenticação e a criptografia de todas as mensagens totem. |
join |
60 (ms) | Aumenta o tempo que o nó aguarda as mensagens join no
protocolo de associação. |
max_messages |
20 | Aumenta o número máximo de mensagens que podem ser enviadas pelo nó após o recebimento do token. |
token |
20000 (ms) |
Aumenta o tempo de espera do nó para um token de protocolo
Aumentar o valor do parâmetro
O valor do parâmetro |
consensus |
N/A | Especifica, em milissegundos, quanto tempo esperar pelo consenso antes de iniciar uma nova rodada de configuração de assinatura.
Recomendamos que você omita esse parâmetro. Quando o parâmetro consensus,
verifique se ele é 24000
ou 1.2*token, o que for maior.
|
token_retransmits_before_loss_const |
10 | Aumenta o número de retransmissões de token que o nó tenta antes de concluir que o nó do destinatário falhou e entrar em ação. |
transport |
|
Especifica o mecanismo de transporte usado pelo corosync. |
Para mais informações sobre como configurar o arquivo corosync.conf, consulte
o guia de configuração para sua distribuição do Linux:
- RHEL: editar as configurações padrão corosync.conf
- SLES: crie os arquivos de configuração do Corosync
Configurações de tempo limite e intervalo para recursos de cluster
Ao definir um recurso de cluster, você define valores
interval e timeout (em segundos) para várias operações de recurso (op).
Por exemplo:
primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations \$id="rsc_sap2_HA1_HDB00-operations" \ op monitor interval="10" timeout="600" \ op start interval="0" timeout="600" \ op stop interval="0" timeout="300" \ params SID="HA1" InstanceNumber="00" clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta is-managed="true" clone-node-max="1" target-role="Started" interleave="true"
Os valores de timeout afetam cada uma das operações de recursos de maneira diferente,
conforme explicado na tabela a seguir.
| Operação do recurso | Ação para tempo limite |
|---|---|
monitor |
Se o tempo limite for excedido, o status de monitoramento normalmente irá relatar um erro, e o recurso associado será considerado em estado de falha. O cluster tenta opções de recuperação, o que pode incluir um failover. O cluster não repete uma operação de monitoramento com falha. |
start |
Se um recurso não for iniciado antes que o tempo limite seja atingido, o cluster tentará reiniciar o recurso. O comportamento é determinado pela ação na falha que está associada a um recurso. |
stop |
Se um recurso não responde a uma operação de interrupção antes que o tempo limite seja atingido, isso aciona um evento de isolamento. |
Além de outras configurações de cluster, as definições de interval e timeout
dos recursos do cluster afetam a rapidez com que o software do cluster
detecta uma falha e aciona um failover.
Os valores timeout e interval sugeridos por Google Cloud nos
guias de configuração de cluster para a conta SAP HANA do Compute Engine para eventos de manutenção de
migração em tempo real.
Independentemente dos valores timeout e interval usados, você precisa
avaliá-los ao testar o cluster, especialmente durante os testes
de migração em tempo real, porque a duração desses eventos pode variar um pouco,
dependendo do tipo de máquina que você está usando e de outros fatores, como a utilização
do sistema.
Configurações de recursos de isolamento
Nos guias de configuração de cluster de alta disponibilidade do SAP HANA, Google Cloud recomenda vários parâmetros ao configurar os recursos de isolamento do cluster de alta disponibilidade. Os valores recomendados são diferentes dos valores padrão definidos pelo Corosync ou pelo distribuidor do Linux.
A tabela a seguir mostra os parâmetros de isolamento que Google Cloud recomenda, além dos valores recomendados e dos detalhes dos parâmetros. Para os valores padrão dos parâmetros, que podem diferir entre as distribuições do Linux, consulte a documentação da distribuição do Linux.
| Parâmetro | Valor recomendado | Detalhes |
|---|---|---|
pcmk_reboot_timeout |
300 (segundos) | Especifica o valor do tempo limite a ser usado para ações de reinicialização.
O valor
|
pcmk_monitor_retries |
4 | Especifica o número máximo de vezes que o comando monitor
é repetido no período do tempo limite. |
pcmk_delay_max |
30 (segundos) | Especifica um atraso aleatório para as ações de isolamento, a fim de impedir que os nós do cluster isolem uns aos outros ao mesmo tempo. Para evitar diversas ações de isolamento e garantir que apenas uma instância receba um atraso aleatório, esse parâmetro só deve ser ativado em um dos recursos de isolamento em um cluster de alta disponibilidade do HANA de dois nós (escalonamento vertical). Em um cluster de alta disponibilidade do HANA de escalonamento horizontal, esse parâmetro precisa ser ativado em todos os nós que fazem parte de um site (primário ou secundário). |
Como testar o cluster de alta disponibilidade no Google Cloud
Depois que o cluster for configurado e os sistemas do cluster e do SAP HANA forem implantados no ambiente de teste, será preciso testar o cluster para confirmar se o sistema de HA está configurado corretamente e funcionando conforme o esperado.
Para confirmar que o failover está funcionando como esperado, simule vários cenários de falha com as ações a seguir:
- Encerre a VM
- Crie um pânico do kernel
- Encerre o aplicativo
- Interrompa a rede entre as instâncias
Além disso, simule um evento de migração em tempo real do Compute Engine no host
primário para confirmar que ele não aciona um failover. É possível simular um
evento de manutenção usando o comando gcloud compute instances
simulate-maintenance-event da Google Cloud CLI.
Geração de registros e monitoramento
Os agentes de recursos podem incluir recursos de geração de registros que propagam registros para
a observabilidade do Google Cloud para análise. Cada agente de recurso inclui informações de configuração
que identificam as opções de geração de registros. No caso de implementações
bash, a opção de geração de registros é gcloud logging.
Também é possível instalar o agente do Cloud Logging para capturar a saída do registro de processos do sistema operacional e correlacionar a utilização de recursos com eventos do sistema. O agente do Logging captura registros do sistema padrão, que incluem dados de registro do Pacemaker e dos serviços de clustering. Para mais informações, consulte Sobre o agente do Logging.
Para informações sobre como usar o Cloud Monitoring para configurar verificações de serviço que monitoram a disponibilidade de endpoints de serviço, consulte Como gerenciar verificações de tempo de atividade.
Contas de serviço e clusters de alta disponibilidade
As ações que o software de cluster pode realizar no ambiente Google Cloud são protegidas pelas permissões concedidas à conta de serviço de cada VM de host. Para ambientes de alta segurança, é possível limitar as permissões nas contas de serviço das VMs de host para obedecer ao princípio do menor privilégio.
Ao limitar as permissões da conta de serviço, lembre-se de que o sistema pode interagir com serviços Google Cloud , como o Cloud Storage. Portanto, talvez seja necessário incluir permissões para essas interações de serviço na conta de serviço da VM do host.
Para as permissões mais restritivas, crie um papel personalizado com as permissões mínimas necessárias. Para informações sobre papéis personalizados, consulte Como criar e gerenciar papéis personalizados. É possível restringir ainda mais as permissões limitando-as a instâncias específicas de um recurso, como as instâncias de VM no cluster de alta disponibilidade, adicionando condições nas vinculações de papel da política de IAM de um recurso.
As permissões mínimas necessárias dependem dos recursosGoogle Cloud que os sistemas acessam e das ações que eles executam. Consequentemente, determinar as permissões mínimas necessárias para as VMs do host no cluster de alta disponibilidade pode exigir que você investigue exatamente quais recursos os sistemas acessam na VM do host e as ações que esses sistemas executam com tais recursos.
Como ponto de partida, a lista a seguir mostra alguns recursos do cluster de alta disponibilidade e as permissões associadas exigidas:
- Isolamento
- compute.instances.list
- compute.instances.get
- compute.instances.reset
- compute.instances.stop
- compute.instances.start
- logging.logEntries.create
- compute.zones.list
- VIP implementado usando um IP de alias
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.instances.updateNetworkInterface
- compute.zoneOperations.get
- logging.logEntries.create
- VIP implementado usando rotas estáticas
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.routes.get
- compute.routes.create
- compute.routes.delete
- compute.routes.update
- compute.routes.list
- compute.networks.updatePolicy
- compute.networks.get
- compute.globalOperations.get
- logging.logEntries.create
- VIP implementado usando um balanceador de carga interno
- Nenhuma permissão específica é necessária. O balanceador de carga opera em status de verificação de integridade que não exige que o cluster interaja ou mude recursos no Google Cloud
Implementação de IP virtual em Google Cloud
Um cluster de alta disponibilidade usa um endereço IP flutuante ou virtual (VIP, na sigla em inglês) para mover a carga de trabalho de um nó do cluster para outro no caso de falha inesperada ou para manutenção programada. O endereço IP do VIP não muda. Portanto, os aplicativos cliente não sabem que o trabalho está sendo atendido por um nó diferente.
Um VIP também é chamado de endereço IP flutuante.
No Google Cloud, os VIPs são implementados de maneira um pouco diferente do que nas instalações locais, porque, quando ocorre um failover, não é possível usar solicitações ARP gratuitas para anunciar a alteração. Em vez disso, é possível implementar um endereço VIP para um cluster de alta disponibilidade do SAP usando um dos seguintes métodos:
- Compatibilidade com failover de balanceador de carga de rede interno de passagem (recomendado).
- Google Cloud Rotas estáticas.
- EndereçosGoogle Cloud IP de alias.
Implementações de VIP do balanceador de carga de rede interno
Um balanceador de carga normalmente distribui o tráfego do usuário em várias instâncias dos aplicativos, tanto para distribuir a carga de trabalho em vários sistemas ativos quanto para proteger contra uma lentidão ou falha de processamento em qualquer instância.
O balanceador de carga de rede interno também oferece suporte de failover que pode ser usado com as verificações de integridade do Compute Engine para detectar falhas, acionar o failover e redirecionar o tráfego para um novo sistema SAP principal em um cluster de alta disponibilidade nativo do SO.
O suporte de failover é a implementação VIP recomendada por vários motivos, incluindo:
- O balanceamento de carga do Compute Engine oferece um SLA com 99,99% de disponibilidade.
- O balanceamento de carga é compatível com clusters de alta disponibilidade em várias zonas, o que protege contra falhas de zona com tempos previsíveis de failover entre zonas.
- O uso do balanceamento de carga reduz o tempo necessário para detectar e acionar um failover, geralmente em segundos após a falha. Os tempos gerais de failover dependem dos tempos de failover de cada um dos componentes no sistema de alta disponibilidade, que podem incluir os hosts, sistemas de banco de dados, sistemas de aplicativos, entre outros.
- O uso do balanceamento de carga simplifica a configuração do cluster e reduz as dependências.
- Ao contrário de uma implementação de VIP que usa rotas, com o balanceamento de carga, é possível usar intervalos de IP da sua própria rede VPC, permitindo reservar e configurar esses intervalos conforme necessário.
- O balanceamento de carga pode ser facilmente usado no redirecionamento do tráfego para um sistema secundário para interrupções planejadas de manutenção.
Ao criar uma verificação de integridade para uma implementação de balanceador de carga de um VIP, especifique a porta do host sondada pela verificação de integridade para determinar a integridade do host. Para um cluster de alta disponibilidade do SAP, especifique uma porta de host de destino que esteja no intervalo particular 49152-65535, evitando, assim, conflitos com outros serviços. Na VM do host, configure a porta de destino com um serviço auxiliar secundário, como o utilitário socat ou o HAProxy.
Para clusters de banco de dados em que o sistema secundário em espera permanece on-line, o serviço auxiliar de verificação de integridade permite que o balanceamento de carga direcione o tráfego para o sistema on-line que está atuando como o sistema principal no cluster.
Com o uso do serviço auxiliar e do redirecionamento de porta, é possível acionar um failover de manutenção planejada de software nos sistemas SAP.
Para mais informações sobre suporte a failover, consulte Como configurar failover para balanceadores de carga de rede de passagem interna.
Para implantar um cluster de alta disponibilidade com uma implementação de VIP do balanceador de carga, consulte:
- Terraform: guia de configuração do cluster de alta disponibilidade do SAP HANA
- Guia de configuração de cluster de alta disponibilidade para SAP HANA no RHEL
- Guia de configuração de cluster de alta disponibilidade para SAP HANA no SLES
Implementações de VIP de rota estática
A implementação de rota estática também fornece proteção contra falhas de zona, mas exige o uso de um VIP fora dos intervalos de IP das sub-redes VPC existentes em que as VMs residem. Consequentemente, também é necessário garantir que o VIP não entre em conflito com nenhum endereço IP externo na sua rede expandida.
As implementações de rota estática também podem gerar complexidade quando usadas com configurações de VPC compartilhada, que se destinam a separar a configuração de rede em um projeto host.
Para usar uma implementação de rota estática para seu VIP, consulte o administrador da rede para determinar um endereço IP adequado para uma implementação de rota estática.
Implementações de VIP do IP de alias
As implementações de VIP do IP de alias não são recomendadas para implantações de alta disponibilidade em várias zonas porque, em caso de falha da zona, pode haver atraso na realocação do IP de alias para um nó em uma zona diferente. Implemente seu VIP com um balanceador de carga de rede de passagem interna compatível com failover.
Se você estiver implantando todos os nós do cluster de alta disponibilidade do SAP na mesma zona, use um IP de alias para implementar um VIP no cluster de alta disponibilidade.
Para clusters de alta disponibilidade do SAP de várias zonas que usam uma implementação de IP de alias para o VIP, é possível migrar para uma implementação de balanceador de carga de rede interno de passagem sem precisar alterar seu endereço VIP. Os endereços IP de alias e os balanceadores de carga de rede de passagem internos usam intervalos de IP da sua rede VPC.
Embora os endereços IP de alias não sejam recomendados para implementações de VIP em clusters de alta disponibilidade em várias zonas, eles têm outros casos de uso em implantações do SAP. Por exemplo, eles podem ser usados para fornecer um nome de host e atribuições de IP lógicos para implantações flexíveis do SAP, como as gerenciadas pelo SAP Landscape Management.
Práticas recomendadas gerais para VIPs no Google Cloud
Para mais informações sobre VIPs no Google Cloud, consulte Práticas recomendadas para endereços IP flutuantes.
Failover automático de host do SAP HANA em Google Cloud
Google Cloud é compatível com o failover automático de host do SAP HANA, a solução local de recuperação de falhas fornecida pelo SAP HANA. A solução de failover automático do host usa um ou mais hosts em espera que são mantidos em reserva para assumir o trabalho do host mestre ou worker em caso de falha no host. Os hosts em espera não têm dados nem processam trabalhos.
Após concluir um failover, o host com falha é reiniciado como um host em espera.
O SAP é compatível com até três hosts em espera em sistemas de escalonamento horizontal no Google Cloud. Os hosts em espera não contam para o máximo de 16 hosts ativos que o SAP suporta em sistemas de escalonamento horizontal noGoogle Cloud.
Para mais informações da SAP sobre a solução de failover automático de hosts, consulte Failover automático de hosts.
Quando usar o failover automático de host do SAP HANA em Google Cloud
O failover automático de host do SAP HANA protege contra falhas que afetam um único nó em um sistema de escalonamento horizontal do SAP HANA, incluindo falhas dos seguintes itens:
- A instância do SAP HANA
- O sistema operacional do host
- A VM do host
Em relação a falhas da VM do host, no Google Cloud, a reinicialização automática, que normalmente restaura a VM do host do SAP HANA mais rápido que o failover automático do host, e a migração em tempo real, protegem contra interrupções em VMs planejadas e não planejadas. Então, para proteção da VM, a solução de failover automático de host do SAP HANA não é necessária.
O failover automático de host do SAP HANA não protege contra falhas zonais, porque todos os nós de um sistema de escalonamento horizontal do SAP HANA são implantados em uma única zona.
O failover automático de host do SAP HANA não pré-carrega dados do SAP HANA na memória dos nós de espera. Então, quando um nó de espera assume o controle, o tempo total de recuperação do nó é determinado principalmente pelo tempo que leva para carregar os dados na memória do nó de espera.
Use o failover automático de host do SAP HANA nos cenários a seguir:
- Falhas no software ou no sistema operacional do host de um nó do SAP HANA que pode não ser detectada por Google Cloud.
- Migrações lift-and-shift, em que você precisa reproduzir a configuração do SAP HANA no local até otimizar o SAP HANA paraGoogle Cloud.
- Quando uma configuração totalmente replicada entre zonas e de alta disponibilidade é proibitiva de custo e sua empresa pode tolerar:
- Um tempo de recuperação de nó mais longo devido à necessidade de carregar dados do SAP HANA na memória de um nó de espera.
- Risco de falha zonal.
O gerenciador de armazenamento do SAP HANA
Os volumes /hana/data e /hana/log são ativados apenas nos hosts mestre e de trabalho. Quando ocorre uma transferência, a solução de failover automático do host
usa a API do conector de armazenamento do SAP HANA e o
gerenciador de armazenamentoGoogle Cloud para que os nós de espera do SAP HANA movam as montagens de volume do
host com falha para o host em espera.
No Google Cloud, o gerenciador de armazenamento do SAP HANA é necessário para sistemas SAP HANA que usam o failover automático de host do SAP HANA.
Versões com suporte do gerenciador de armazenamento para SAP HANA
As versões 2.0 e posteriores do gerenciador de armazenamento do SAP HANA recebem suporte. Todas as versões anteriores à 2.0 foram descontinuadas e não recebem mais suporte. Se você estiver usando uma versão anterior, atualize o sistema HANA da SAP para usar a versão mais recente do gerenciador de armazenamento do SAP HANA. Consulte Como atualizar o gerenciador de armazenamento do SAP HANA.
Para determinar se a sua versão foi suspensa, abra o arquivo gceStorageClient.py.
O diretório de instalação padrão é: /hana/shared/gceStorageClient
A partir da versão 2.0, o número da versão é listado nos comentários na parte superior do arquivo gceStorageClient.py, conforme mostrado no exemplo a seguir. Se
o número da versão estiver ausente, você está vendo uma versão descontinuada
do gerenciador de armazenamento para SAP HANA.
"""Google Cloud Storage Manager for SAP HANA Standby Nodes. The Storage Manager for SAP HANA implements the API from the SAP provided StorageConnectorClient to allow attaching and detaching of disks when running in Compute Engine. Build Date: Wed Jan 27 06:39:49 PST 2021 Version: 2.0.20210127.00-00 """
Como instalar o gerenciador de armazenamento para SAP HANA
O método recomendado para instalar o gerenciador de armazenamento do SAP HANA é usar um método de implantação automatizado para implantar um sistema SAP HANA de escalonamento horizontal que inclui o gerenciador de armazenamento mais recente do SAP HANA.
Se você precisar adicionar o failover automático do host do SAP HANA a um sistema de escalonamento horizontal do SAP HANA existente no Google Cloud, a abordagem recomendada é semelhante: use o arquivo de configuração do Terraform fornecido pelo Google Cloud para implantar um novo sistema de escalonamento horizontal do SAP HANA e, em seguida, carregue os dados do sistema atual para o novo. Para carregar os dados, use procedimentos padrão de backup e restauração do SAP HANA ou a replicação do sistema SAP HANA, o que pode limitar a inatividade. Para mais informações sobre a replicação do sistema, consulte a Observação SAP 2473002: como usar a replicação do sistema HANA para migrar o sistema escalonar horizontalmente horizontal.
Se você não conseguir usar um método de implantação automatizado, entre em contato com um consultor de soluções SAP, que pode ser encontrado por meio dos Google Cloud serviços de consultoria, para receber ajuda para instalar manualmente o gerenciador de armazenamento para o SAP HANA.
No momento, a instalação manual do gerenciador de armazenamento do SAP HANA em um sistema de escalonamento horizontal SAP HANA novo ou atual não está documentada.
Para mais informações sobre as opções de implantação automatizadas para failover automático de hosts do SAP HANA, consulte Implantação automatizada de sistemas de escalonamento horizontal do SAP HANA com failover automático de hosts do SAP HANA.
Como atualizar o gerenciador de armazenamento do SAP HANA
Para atualizar o gerenciador de armazenamento para SAP HANA, primeiro faça o download do pacote de instalação e execute um script de instalação, que atualiza o gerenciador de armazenamento para o executável do SAP HANA na unidade /shared do SAP HANA.
O procedimento a seguir é apenas para a versão 2 do gerenciador de armazenamento do SAP HANA. Se você estiver usando uma versão do gerenciador de armazenamento para SAP HANA que foi baixada antes de 1 de fevereiro de 2021, instale a versão 2 antes de tentar atualizar o gerenciador de armazenamento para o SAP HANA.
Para atualizar o gerenciador de armazenamento do SAP HANA:
Verifique a versão do gerenciador de armazenamento para SAP HANA atual:
RHEL
sudo yum check-update google-sapgcestorageclient
SLES
sudo zypper list-updates -r google-sapgcestorageclient
Se houver uma atualização, instale a atualização:
RHEL
sudo yum update google-sapgcestorageclient
SLES
sudo zypper update
O gerenciador de armazenamento atualizado do SAP HANA está instalado em
/usr/sap/google-sapgcestorageclient/gceStorageClient.py.Substitua o
gceStorageClient.pyatual pelo arquivogceStorageClient.pyatualizado:Se seu arquivo
gceStorageClient.pyatual estiver em/hana/shared/gceStorageClient, o local de instalação padrão, use o script de instalação para atualizar o arquivo:sudo /usr/sap/google-sapgcestorageclient/install.sh
Se o arquivo
gceStorageClient.pyatual não estiver em/hana/shared/gceStorageClient, copie o arquivo atualizado para o mesmo local que o arquivo existente, substituindo o arquivo atual.
Parâmetros de configuração no arquivo global.ini
Alguns parâmetros de configuração do gerenciador de armazenamento do SAP HANA,
incluindo se o isolamento está ativado ou desativado, são armazenados na
seção de armazenamento do arquivo global.ini do SAP HANA. Quando você usa o arquivo de configuração do Terraform
fornecido por Google Cloud para implantar um sistema SAP HANA
com a função de failover automático do host, o processo de implantação adiciona os
parâmetros de configuração ao arquivo global.ini para você.
O exemplo a seguir mostra o conteúdo de um global.ini criado para o gerenciador de armazenamento do SAP HANA:
[persistence] basepath_datavolumes = %BASEPATH_DATAVOLUMES% basepath_logvolumes = %BASEPATH_LOGVOLUMES% use_mountpoints = %USE_MOUNTPOINTS% basepath_shared = %BASEPATH_SHARED% [storage] ha_provider = gceStorageClient ha_provider_path = %STORAGE_CONNECTOR_PATH% # # Example configuration for 2+1 setup # # partition_1_*__pd = node-mnt00001 # partition_2_*__pd = node-mnt00002 # partition_3_*__pd = node-mnt00003 # partition_*_data__dev = /dev/hana/data # partition_*_log__dev = /dev/hana/log # partition_*_*__gcloudAccount = svc-acct-name@project-id. # partition_*_data__mountOptions = -t xfs -o logbsize=256k # partition_*_log__mountOptions = -t xfs -o logbsize=256k # partition_*_*__fencing = disabled [trace] ha_gcestorageclient = info
Acesso sudo para o gerenciador de armazenamento do SAP HANA
Para gerenciar os serviços e o armazenamento do SAP HANA, o
gerenciador de armazenamento do SAP HANA usa a conta de usuário
SID_LCadm e exige acesso sudo para determinados binários do
sistema.
Se você usar os scripts de automação que Google Cloud fornecem para implantar o SAP HANA com failover automático do host, o acesso sudo necessário vai ser configurado para você.
Se você instalar manualmente o gerenciador de armazenamento do SAP HANA, use o
comando visudo para editar o arquivo /etc/sudoers e conceder
para a conta de usuário SID_LCadm acesso sudo aos seguintes
binários necessários.
Clique na guia do seu sistema operacional:
RHEL
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof /usr/sbin/xfs_repair
SLES
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /sbin/xfs_repair /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof
O exemplo a seguir mostra uma entrada no arquivo /etc/sudoers. No
exemplo, o ID do sistema do sistema SAP HANA associado é substituído por
SID_LC. A entrada de exemplo foi criada pela
configuração do Terraform fornecida por Google Cloud para escalonamento horizontal do SAP HANA
com failover automático do host.
A entrada criada pela configuração do Terraform
inclui binários que não são mais necessários, mas que são retidos para
compatibilidade com versões anteriores. Você deve incluir apenas os binários que
estão na lista anterior.
SID_LCadm ALL=NOPASSWD: /sbin/multipath,/sbin/multipathd,/etc/init.d/multipathd,/usr/bin/sg_persist,/bin/mount,/bin/umount,/bin/kill,/usr/bin/lsof,/usr/bin/systemctl,/usr/sbin/lsof,/usr/sbin/xfs_repair,/sbin/xfs_repair,/usr/bin/mkdir,/sbin/vgscan,/sbin/pvscan,/sbin/lvscan,/sbin/vgchange,/sbin/lvdisplay,/usr/bin/gcloud,/sbin/dmsetup
Como configurar a conta de serviço para o gerenciador de armazenamento do SAP HANA
Para ativar o failover automático de host para o sistema de escalonamento horizontal do SAP HANA em Google Cloud, o gerenciador de armazenamento do SAP HANA exige uma conta de serviço. É possível criar uma conta de serviço dedicada e conceder a ela as permissões necessárias para realizar ações nas VMs do SAP HANA, como desconectar e conectar discos durante uma failover. Para mais informações sobre como criar uma conta de serviço, consulte Criar uma conta de serviço.
Permissões do IAM obrigatórias
Para a conta de serviço usada pelo gerenciador de armazenamento do SAP HANA, é necessário conceder um papel que inclua as seguintes permissões do IAM:
Para redefinir uma instância de VM usando o comando
gcloud compute instances reset, conceda a permissãocompute.instances.reset.Para receber informações sobre um volume do Persistent Disk ou Hyperdisk usando o comando
gcloud compute disks describe, conceda a permissãocompute.disks.get.Para anexar um disco a uma instância de VM usando o comando
gcloud compute instances attach-disk, conceda a permissãocompute.instances.attachDisk.Para remover um disco de uma instância de VM usando o comando
gcloud compute instances detach-disk, conceda a permissãocompute.instances.detachDisk.Para listar instâncias de VM usando o comando
gcloud compute instances list, conceda a permissãocompute.instances.list.Para listar os volumes do Persistent Disk ou do Hyperdisk usando o comando
gcloud compute disks list, conceda a permissãocompute.disks.list.
É possível conceder as permissões necessárias com papéis personalizados ou outros papéis predefinidos.
Além disso, defina o escopo de acesso da VM como cloud-platform para que as
permissões do IAM da VM sejam completamente determinadas
pelos papéis do IAM que você concede à conta de serviço.
Por padrão, o gerenciador de armazenamento do SAP HANA usa a conta de usuário ou de serviço ativa que a CLI gcloud tem autorização para usar nos hosts no sistema SAP HANA de escalonamento.
Para verificar a conta ativa usada pelo gerenciador de armazenamento para SAP HANA, use o seguinte comando:
gcloud auth list
Para mais informações sobre esse comando, consulte gcloud auth list.
Para mudar a conta usada pelo gerenciador de armazenamento do SAP HANA, siga estas etapas:
Verifique se a conta de serviço está disponível em cada um dos hosts no sistema SAP HANA de escalonamento horizontal:
gcloud auth listNo arquivo
global.ini, atualize a seção[storage]com a conta de serviço:[storage] ha_provider = gceStorageClient ... partition_*_*__gcloudAccount = SERVICE_ACCOUNTSubstitua
SERVICE_ACCOUNTpelo nome da conta de serviço, no formato de endereço de e-mail, usada pelo gerenciador de armazenamento do SAP HANA. Essa conta de serviço é usada ao emitir comandosgclouddo gerenciador de armazenamento do SAP HANA.
Armazenamento NFS para failover automático de host do SAP HANA
Um sistema de escalonamento horizontal do SAP HANA com failover automático de host requer uma solução NFS, como o Filestore, para compartilhar os volumes /hana/shared e /hanabackup entre todos os hosts. Você mesmo precisa configurar a solução de NFS.
Ao usar um método de implantação automatizada, você fornece informações sobre o servidor NFS no arquivo de implantação para montar os diretórios NFS durante a implantação.
O volume NFS usado precisa estar vazio. Qualquer arquivo existente pode entrar em conflito com os scripts do processo de implantação, especialmente se os arquivos ou pastas fizerem referência ao ID do sistema SAP (SID). O processo de implantação não pode determinar se os arquivos podem ser substituídos.
O processo de implantação armazena os volumes /hana/shared e /hanabackup
no servidor NFS e monta o servidor NFS em todos os hosts, incluindo
os hosts em espera. O host mestre gerencia o servidor NFS.
Se você estiver implementando uma solução de backup, como o agente Backint do Cloud Storage para SAP HANA, será possível
remover o volume /hanabackup do servidor NFS após a conclusão da implantação.
Para mais informações sobre as soluções de arquivos compartilhados disponíveis no Google Cloud, consulte Soluções de compartilhamento de arquivos para SAP no Google Cloud.
Suporte ao sistema operacional
Google Cloud é compatível com o failover automático de host do SAP HANA apenas nos seguintes sistemas operacionais:
- RHEL para SAP 7.7 ou posterior
- RHEL para SAP 8.1 ou posterior
- RHEL para SAP 9.0 ou posterior
-
Antes de instalar qualquer software SAP no RHEL para SAP 9.x, é preciso instalar outros pacotes nas
máquinas host, especialmente
chkconfigecompat-openssl11. Se você usar uma imagem fornecida pelo Compute Engine, esses pacotes serão instalados automaticamente. Para mais informações da SAP, consulte a Nota SAP 3108316 – Red Hat Enterprise Linux 9.x: instalação e configuração .
-
Antes de instalar qualquer software SAP no RHEL para SAP 9.x, é preciso instalar outros pacotes nas
máquinas host, especialmente
- GiB para SAP 12 SP5
- SLES para SAP 15 SP1 ou posterior
Para ver as imagens públicas disponíveis pelo Compute Engine, consulte Imagens.
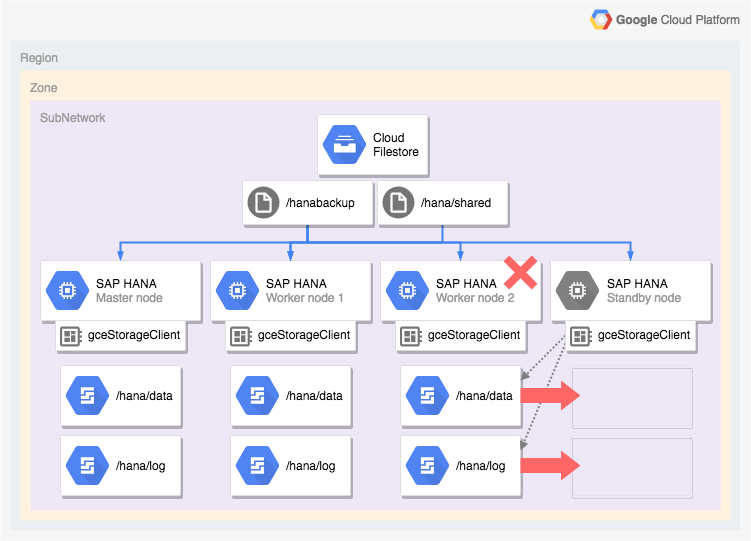
Arquitetura de um sistema SAP HANA com failover automático de host
O diagrama a seguir mostra uma arquitetura de escalonamento horizontal no Google Cloud que
inclui o recurso de failover automático de host do SAP HANA. No diagrama,
o gerenciador de armazenamento do SAP HANA é representado pelo nome do
executável dele, gceStorageClient.
O diagrama mostra o nó de trabalho 2 falhando e o nó em espera assumindo o controle.
O gerenciador de armazenamento do SAP HANA funciona com a API SAP Storage Connector (não exibida) para remover os discos que contêm os volumes /hana/data e /hana/logs do nó de trabalho com falha e para montá-los novamente no nó de espera, que se torna o nó de trabalho 2 enquanto o nó com falha se torna o nó de espera.
Opções de implantação automatizadas para configurações de alta disponibilidade do SAP HANA
OGoogle Cloud fornece configurações do Terraform que podem ser usadas para automatizar a implantação de sistemas de alta disponibilidade do SAP HANA ou é possível implantar e configurar seus sistemas de alta disponibilidade do SAP HANA manualmente.
OGoogle Cloud fornece arquivos de configuração do Terraform específicos da implantação que você preenche. Use os comandos padrão do Terraform para inicializar o diretório de trabalho atual e fazer o download do plug-in do provedor do Terraform e dos arquivos do módulo para Google Cloude aplique a configuração para implantar um sistema SAP HANA.
Esse método de implantação automatizada implanta um sistema SAP HANA para você que tem suporte total do SAP e que segue as práticas recomendadas do SAP e do Google Cloud.
Implantação automatizada de clusters de alta disponibilidade do Linux para SAP HANA
Para o SAP HANA, o método de implantação automatizada implanta um cluster do Linux de alta disponibilidade e otimizado para desempenho que inclui:
- Failover automático
- Reinicialização automática
- Uma reserva do endereço IP virtual (VIP) especificado.
- Compatibilidade com o failover fornecido pelo balanceamento de carga TCP/UDP interno, que gerencia o roteamento do endereço IP virtual (VIP) para os nós do cluster de alta disponibilidade.
- Uma regra de firewall que permite que as verificações de integridade do Compute Engine monitorem as instâncias de VM no cluster.
- O gerenciador de recursos do cluster de alta disponibilidade do Pacemaker
- Um Google Cloud mecanismo de isolamento.
- Uma VM com discos permanentes necessários para cada instância do SAP HANA.
- Opcionalmente, um nó de locatário individual.
- Instâncias do SAP HANA configuradas para replicação síncrona e pré-carregamento de memória.
Para usar o Terraform para automatizar a implantação de um cluster de alta disponibilidade para o SAP HANA, consulte:
- Terraform: guia de configuração de cluster de alta disponibilidade do SAP HANA de escalonamento vertical.
- Terraform: guia de configuração de cluster de alta disponibilidade para escalonamento horizontal do SAP HANA.
Implantação automatizada de sistemas de escalonamento horizontal do SAP HANA com failover automático de host do SAP HANA
É possível usar o Terraform para automatizar a implantação de um sistema de escalonamento horizontal com hosts em espera. Para mais informações, consulte Terraform: sistema de escalonamento horizontal do SAP HANA com guia de implantação de failover automático do host.
Para um sistema de escalonamento horizontal do SAP HANA que inclui o recurso de failover automático do host do SAP HANA, a configuração do Terraform fornecida por Google Cloud implanta o seguinte:
- Uma instância mestre do SAP HANA
- 1 a 15 hosts worker
- 1 a 3 hosts em espera
- Uma VM para cada host do SAP HANA
- Volumes de Persistent Disk ou Hyperdisk baseados em SSD para os hosts mestre e worker
- O gerenciador de armazenamento Google Cloud para nós de espera do SAP HANA
Um sistema de escalonamento horizontal do SAP HANA com failover automático de host requer uma solução NFS,
como o Filestore, para compartilhar os
volumes /hana/shared e /hanabackup entre todos os hosts. Para que o Terraform
possa montar os diretórios NFS durante a
implantação, configure a solução NFS antes de implantar o sistema
SAP HANA.
É possível configurar as instâncias do servidor NFS do Filestore rapidamente, seguindo as instruções em Como criar instâncias.
Opção ativo/ativo (ativado para leitura) para SAP HANA
A partir do SAP HANA 2.0 SPS1, o SAP fornece a configuração Active/Active (Read Enabled) para cenários de replicação do sistema SAP HANA. Em um sistema de replicação configurado para Ativo/Ativo (ativado para leitura), as portas SQL no sistema secundário estão abertas para acesso de leitura. Isso permite que você use o sistema secundário para tarefas de leitura intensa e tenha um melhor equilíbrio de cargas de trabalho nos recursos de computação, melhorando o desempenho geral do banco de dados SAP HANA. Para mais informações sobre o recurso "Ativo/Ativo" (ativado para leitura), consulte o Guia de administração do SAP HANA específico da versão do SAP HANA e a Nota SAP 1999880.
Para configurar uma replicação de sistema que permita o acesso de leitura no sistema secundário, use o modo de operação logreplay_readaccess. No entanto, para usar esse modo de operação, os sistemas principal e secundário precisam executar a mesma versão do SAP HANA. Consequentemente, o acesso somente leitura ao sistema secundário não poderá ser feito durante o upgrade gradual até que os dois sistemas executem a mesma versão do SAP HANA.
Para se conectar a um sistema secundário ativo/ativo (ativado para leitura), o SAP oferece as seguintes opções:
- Conecte-se diretamente abrindo uma conexão explícita com o sistema secundário.
- Conecte-se indiretamente executando uma instrução SQL no sistema principal com uma dica, que, na avaliação, redireciona a consulta para o sistema secundário.
O diagrama a seguir mostra a primeira opção, em que os aplicativos acessam o sistema secundário diretamente em um cluster do Pacemaker implantado no Google Cloud. Um endereço IP flutuante ou IP virtual (VIP, na sigla em inglês) adicional é usado para segmentar a instância de VM que está servindo como o sistema secundário como parte do cluster do SAP HANA Pacemaker. O VIP segue o sistema secundário e pode mover a carga de trabalho de leitura de um nó de cluster para outro em caso de falha inesperada ou para manutenção programada. Saiba mais sobre os métodos de implementação de VIP disponíveis em Implementação de IP virtual no Google Cloud.

Para instruções sobre como configurar a replicação do sistema SAP HANA Ativo/Ativo (ativado para leitura) em um cluster do Pacemaker:
- Configurar o HANA ativo/ativo (ativado para leitura) em um cluster do Pacemaker do SUSE
- Configurar o HANA ativo/ativo (ativado para leitura) em um cluster do Red Hat Pacemaker
A seguir
O Google Cloud e o SAP fornecem mais informações sobre alta disponibilidade.
Mais informações do Google Cloud sobre alta disponibilidade
Para mais informações sobre a alta disponibilidade do SAP HANA no Google Cloud, consulte o Guia de operações do SAP HANA.
Para informações gerais sobre como proteger sistemas no Google Cloud contra vários cenários de falha, consulte Como projetar sistemas robustos.
Mais informações da SAP sobre os recursos de alta disponibilidade do SAP HANA
Para mais informações do SAP sobre os recursos de alta disponibilidade do SAP HANA, consulte os documentos a seguir:
- Alta disponibilidade para SAP HANA
- Nota SAP 2057595 - Perguntas frequentes: alta disponibilidade do SAP HANA
- Como executar uma replicação de sistema para SAP HANA 2.0
- Recomendações de rede para replicação de sistema para SAP HANA