Diese Seite gilt für Apigee und Apigee Hybrid.
Apigee Edge-Dokumentation aufrufen

Übersicht zu Vorgangsanomalien
Vorgangsanomalien erkennt anhand aktueller Datenmuster ungewöhnliche oder unerwartete API-Datenmuster in Ihren APIs. In diesem Diagramm der API-Fehlerrate steigt die Fehlerrate beispielsweise plötzlich um 7:00 Uhr an. Im Vergleich zu den Daten bis zu diesem Zeitpunkt ist dieser Anstieg ungewöhnlich genug, um als Anomalie eingestuft zu werden.
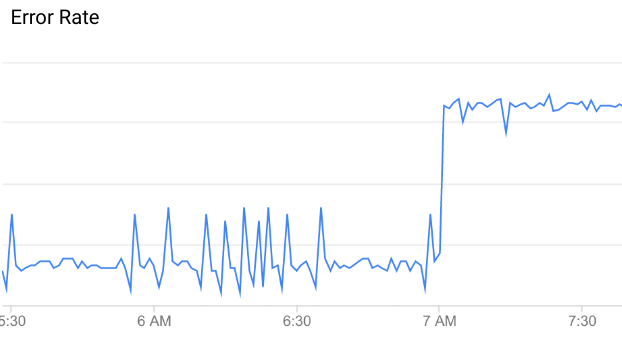
Nicht alle Abweichungen in API-Daten sind Anomalien. Die meisten sind zufällige Schwankungen. Sie können beispielsweise einige geringfügige Schwankungen der Fehlerrate vor der Anomalie erkennen, diese sind jedoch nicht groß genug, um sie als Anomalie zu bezeichnen.
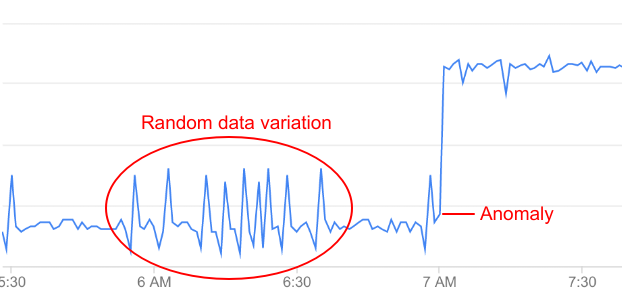
Vorgangsanomalien überwacht API-Daten kontinuierlich und führt statistische Analysen durch, um echte Anomalien von zufälligen Schwankungen in den Daten zu unterscheiden.
Vorgangsanomalien erkennt folgende Anomalietypen automatisch:
- Zunahme von HTTP 503-Fehlern auf Organisations-, Umgebungs- und Regionsebene
- Zunahme von HTTP 504-Fehlern auf Organisations-, Umgebungs- und Regionsebene
- Zunahme aller HTTP 4xx- oder 5xx-Fehler auf Organisations-, Umgebungs- und Regionsebene
- Zunahme der Gesamtantwortlatenz für das 90. Perzentil (p90) auf Organisations-, Umgebungs- und Regionsebene
Eine erkannte Anomalie enthält folgende Informationen:
- Den Messwert, der die Anomalie verursacht hat, z. B. Proxy-Latenz oder einen HTTP-Fehlercode.
- Den Schweregrad der Anomalie. Je nach Konfidenzgrad im Modell kann der Schweregrad leicht, moderat oder gravierend sein. Ein niedriger Konfidenzwert verweist auf einen leichten Schweregrad, ein hoher Konfidenzwert hingegen auf einen gravierenden Schweregrad.
Voraussetzungen für die Verwendung von Vorgangsanomalien
So verwenden Sie Vorgangsanomalien:
- Das AAPI Ops-Add‑on muss für Ihre Organisation aktiviert sein. Weitere Informationen finden Sie unter AAPI Ops in einer Organisation aktivieren.
- Nutzer von Vorgangsanomalien müssen die erforderlichen Rollen für AAPI Ops haben.
- Nutzer, die Anomalien im Dashboard untersuchen, benötigen außerdem die Rolle
roles/logging.viewer.
Erkannte Anomalien im Betrieb ansehen
Wenn „Vorgangsanomalien“ eine Anomalie erkennt, werden die Details dazu im Dashboard „Vorgangsanomalien“ angezeigt. Sie können die Anomalie in den API Monitoring-Dashboards untersuchen und gegebenenfalls entsprechende Maßnahmen ergreifen. Außerdem haben Sie die Möglichkeit, eine Benachrichtigung zu erstellen, um bei zukünftigen Anomalieereignissen informiert zu werden.
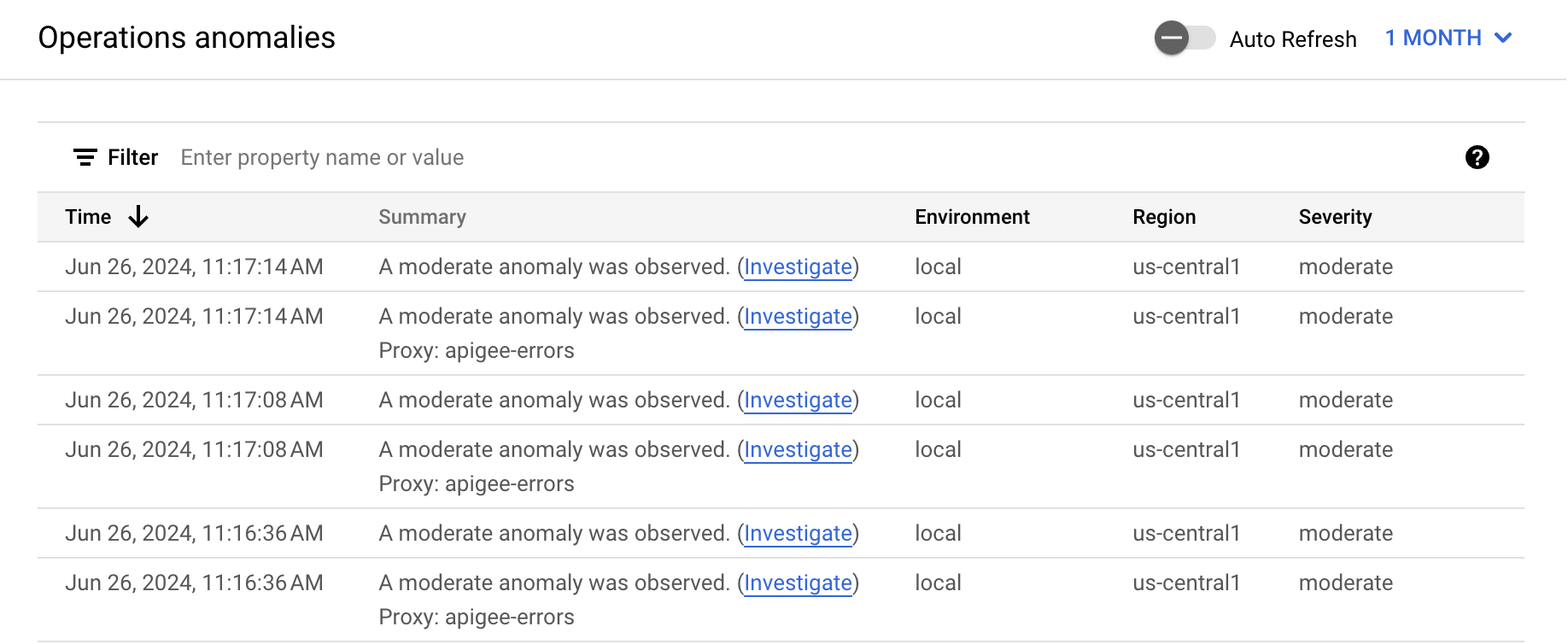
Das Dashboard "Vorgangsanomalien" in der Apigee-UI ist Ihre primäre Informationsquelle zu erkannten Vorgangsanomalien. Das Dashboard zeigt eine Liste der aktuellen Anomalien an.
So öffnen Sie das Vorgangsanomalien-Dashboard:
Rufen Sie in der Google Cloud Console die Seite Analytics > Vorgangsanomalien auf.
- Wechseln Sie zu der zu überwachenden Organisation.
Das Dashboard „Vorgangsanomalien“ wird angezeigt.
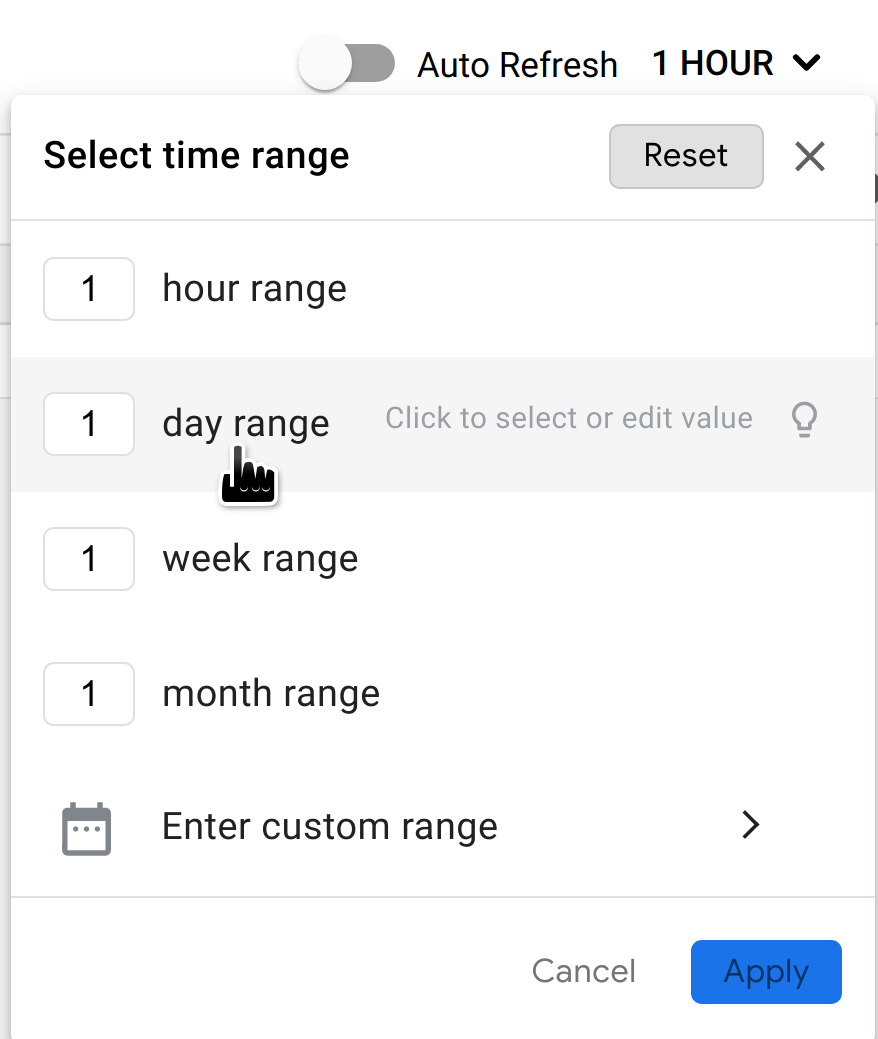
Standardmäßig werden im Dashboard Anomalien angezeigt, die in der letzten Stunde aufgetreten sind. Wenn in diesem Zeitraum keine Anomalien festgestellt wurden, werden im Dashboard keine Zeilen angezeigt. Oben rechts im Dashboard können Sie im Menü „Zeitraum“ einen größeren Zeitraum auswählen.
Jede Zeile in der Tabelle entspricht einer erkannten Anomalie und zeigt die folgenden Informationen an:
- Datum und Uhrzeit der Anomalie.
- Eine kurze Zusammenfassung der Anomalie, einschließlich des Proxys, in dem sie aufgetreten ist, und des Fehlercodes, der sie ausgelöst hat.
- Die Umgebung, in der die Anomalie aufgetreten ist.
- Die Region, in der die Anomalie aufgetreten ist.
- Der Schweregrad des Anomalieereignisses: leicht, moderat oder schwer. Der Schweregrad basiert auf einer statistischen Messung (p-Wert) dafür, wie unwahrscheinlich es ist, dass das Ereignis zufällig passiert (je unwahrscheinlicher das Ereignis, desto stärkerer Schweregrad).
Sie können eine Anomalie auch in den API Monitoring-Dashboards untersuchen. Dort werden verschiedene Diagramme aktueller API-Traffic-Daten angezeigt.
Funktionsweise der Anomalieerkennung
Die Anomalieerkennung umfasst die folgenden Phasen:
Modelle trainieren
Bei Vorgangsanomalien wird ein Modell des Verhaltens Ihrer API-Proxys aus historischen Verlaufsdaten der Zeitachse trainiert. Sie müssen nichts weiter tun, um das Modell zu trainieren. Apigee erstellt und trainiert automatisch Modelle aus den API-Daten der letzten sechs Stunden. Daher benötigt Apigee mindestens sechs Stunden an Daten für einen API-Proxy, um das Modell zu trainieren, bevor eine Anomalie protokolliert werden kann.
Das Ziel des Trainings besteht darin, die Genauigkeit des Modells zu verbessern, das dann an Verlaufsdaten getestet werden kann. Die Genauigkeit eines Modells lässt sich am einfachsten mit der Fehlerrate (der Summe von falsch positiven und falsch negativen Ergebnissen) geteilt durch die Gesamtzahl der vorhergesagten Ereignisse messen.
Anomalieereignisse loggen
Während der Laufzeit vergleicht „Vorgangsanomalien“ das aktuelle Verhalten Ihrer API-Proxys mit dem vom Modell vorhergesagten Verhalten. Mit Vorgangsanomalien kann dann ein bestimmter Konfidenzwert festgelegt werden, wenn ein Betriebswert den vorhergesagten Wert überschreitet. Das gilt zum Beispiel, wenn die Rate von 5xx-Fehlern die vom Modell vorhergesagte Rate überschreitet.
Wenn Apigee eine Anomalie erkennt, wird das Ereignis automatisch im Dashboard für Vorgangsanomalien protokolliert. Die im Dashboard angezeigte Liste der Ereignisse enthält alle erkannten Anomalien sowie ausgelöste Benachrichtigungen.