本指南介绍如何在 Google Cloud上的 SUSE Linux Enterprise Server (SLES) 高可用性 (HA) 集群中自动部署 SAP HANA 横向扩容系统。
本指南使用 Terraform 部署多主机 SAP HANA 横向扩容系统、具有内部直通式网络负载均衡器实现的虚拟 IP 地址 (VIP),以及基于操作系统的高可用性集群,全部符合 Google Cloud、SAP 和 SUSE 的最佳实践。
其中一个 SAP HANA 系统用作活跃主系统,另一个用作辅助备用系统。可以在同一区域中部署两个 SAP HANA 系统,最好位于不同可用区。
部署的集群包括以下功能和特性:
- Pacemaker 高可用性集群资源管理器。
- Google Cloud 防护机制。
- 使用 4 级 TCP 内部负载均衡器实现的虚拟 IP (VIP),包括:
- 预留为 VIP 选择的 IP 地址。
- 两个 Compute Engine 实例组。
- TCP 内部负载均衡器。
- Compute Engine 健康检查。
- SUSE 高可用性模式。
- SUSE SAPHanaSR 资源代理软件包。
- 同步系统复制。
- 内存预加载。
- 自动重启失败的实例,将其用作新的辅助实例。
如果您需要包含备用主机的横向扩容系统,以实现 SAP HANA 主机自动故障切换,则必须参阅 Terraform:具备主机自动故障切换功能的 SAP HANA 横向扩容系统部署指南。
如需部署不包含 Linux 高可用性集群或备用主机的 SAP HANA 系统,请参阅 Terraform:SAP HANA 部署指南。
本指南适用于熟悉 SAP HANA 的 Linux 高可用性配置的 SAP HANA 高级用户。
前提条件
在创建 SAP HANA 高可用性集群之前,请确保满足以下前提条件:
- 您已阅读 SAP HANA 规划指南和 SAP HANA 高可用性规划指南。
- 您或您的组织已有一个 Google Cloud 账号,并且您已为 SAP HANA 部署创建了一个项目。如需了解如何创建Google Cloud 账号和项目,请参阅设置 Google 账号。
- 如果您需要 SAP 工作负载根据数据驻留、访问权限控制、支持人员或监管要求运行,则必须创建所需的 Assured Workloads 文件夹。如需了解详情,请参阅 Google Cloud上的 SAP 的合规性和主权控制。
SAP HANA 安装媒体存储在可用于您的部署项目和区域的 Cloud Storage 存储桶中。如需了解如何将 SAP HANA 安装媒体上传到 Cloud Storage 存储桶,请参阅为 SAP HANA 安装文件创建 Cloud Storage 存储桶。
如果在项目元数据中启用了 OS Login,则需要暂时停用 OS Login,直到部署完成。出于部署目的,此过程会在实例元数据中配置 SSH 密钥。启用 OS Login 后,基于元数据的 SSH 密钥配置会停用,并且此部署将失败。部署完成后,您可以再次启用 OS Login。
如需了解详情,请参阅以下主题:
如果您使用的是 VPC 内部 DNS,则 Google Cloud 项目元数据中
vmDnsSetting变量的值必须为GlobalDefault或ZonalPreferred,才能支持跨可用区解析节点名称。vmDnsSetting的默认设置为ZonalOnly。如需了解详情,请参阅以下主题:
创建网络
出于安全考虑,建议您创建一个新的网络。您可以通过添加防火墙规则或使用其他访问权限控制方法来控制哪些人有权访问该网络。
如果您的项目具有默认 VPC 网络,请勿使用。 请创建自己的 VPC 网络,以保证只有您明确创建的防火墙规则在起作用。
在部署期间,Compute Engine 实例通常需要访问互联网来下载 Google Cloud的 Agent for SAP。如果您使用的是由 Google Cloud提供的某个经 SAP 认证的 Linux 映像,那么计算实例还需要访问互联网来注册许可以及访问操作系统供应商仓库。具有 NAT 网关和虚拟机网络标记的配置支持这种访问,即使目标计算实例没有外部 IP 也是如此。
如需为您的项目创建 VPC 网络,请完成以下步骤:
设置 NAT 网关
如果您需要创建一个或多个没有公共 IP 地址的虚拟机,则需要使用网络地址转换 (NAT) 以使虚拟机能够访问互联网。使用 Cloud NAT,这是 Google Cloud 提供的一项软件定义的托管式服务,可让虚拟机将出站数据包发送到互联网,并接收任何对应的已建立入站响应数据包。或者,您可以将单独的虚拟机设置为 NAT 网关。
如需为项目创建 Cloud NAT 实例,请参阅使用 Cloud NAT。
为项目配置 Cloud NAT 后,虚拟机实例可以在没有公共 IP 地址的情况下安全地访问互联网。
添加防火墙规则
默认情况下,隐式防火墙规则会阻止从 Virtual Private Cloud (VPC) 网络外部传入的连接。如需允许传入的连接,请为您的虚拟机设置防火墙规则。在与虚拟机建立传入的连接后,防火墙会允许通过此连接的双向流量。
您还可以创建防火墙规则,允许对指定端口进行外部访问,或限制同一网络中各虚拟机之间的访问。如果使用 default VPC 网络类型,则系统还会应用一些其他默认规则(例如 default-allow-internal 规则),以允许在同一网络中所有端口上的各虚拟机之间建立连接。
您可能需要通过创建防火墙规则来隔离或限制与数据库主机的连接,具体取决于适用于您的环境的 IT 政策。
根据您的使用场景,您可以创建防火墙规则来允许下列各项中的访问:
- 所有 SAP 产品的 TCP/IP 中列出的默认 SAP 端口。
- 从您的计算机或公司网络环境到 Compute Engine 虚拟机实例的连接。如果您不确定使用哪个 IP 地址,请与您公司的网络管理员联系。
如需为您的项目创建防火墙规则,请参阅创建防火墙规则。
创建安装了 SAP HANA 的高可用性 Linux 集群
以下说明使用 Terraform 配置文件创建具有两个 SAP HANA 系统的 SLES 集群,其中一个 SAP HANA 系统为主系统,辅助或备用 SAP HANA 系统位于同一 Compute Engine 区域。SAP HANA 系统使用同步系统复制,备用系统会预加载复制的数据。
您可以在 Terraform 配置文件中定义 SAP HANA 高可用性集群的配置选项。
以下说明使用的是 Cloud Shell,但一般也适用于安装了 Terraform 并使用 Google 提供方配置的本地终端。
确认资源(例如永久性磁盘和 CPU)的当前配额是否满足您要安装的 SAP HANA 系统的要求。如果配额不足,则部署将失败。
如需了解 SAP HANA 配额要求,请参阅有关 SAP HANA 的价格和配额考虑因素。
打开 Cloud Shell 或本地终端。
在 Cloud Shell 或终端中运行以下命令,将
sap_hana_ha.tf配置文件下载到您的工作目录:$wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/terraform/sap_hana_ha.tf在 Cloud Shell 代码编辑器中打开
sap_hana_ha.tf文件,如果您使用的是终端,请在您选择的文本编辑器中打开该文件。如需打开 Cloud Shell 代码编辑器,请点击 Cloud Shell 终端窗口右上角的铅笔图标。
在
sap_hana_ha.tf文件中,更新参数值,方法是将双引号中的内容替换为安装所需的值。下表介绍了这些参数。参数 数据类型 说明 source字符串 指定部署期间要使用的 Terraform 模块的位置和版本。
sap_hana_ha.tf配置文件包含source参数的两个实例:一个实例是当前活跃对象,另一个实例则作为注释包含在文件内。默认处于活跃状态的source参数会指定latest作为模块版本。source参数的第二个实例(默认通过前导#字符停用)会指定一个时间戳,用于标识特定模块版本。如果您需要所有部署使用同一模块版本,则从指定版本时间戳的
source参数移除前导#字符,并将该字符添加到指定latest的source参数。project_id字符串 指定要在其中部署此系统的 Google Cloud 项目的 ID。例如 my-project-x。machine_type字符串 指定要在其上运行 SAP 系统的 Compute Engine 虚拟机 (VM) 的类型。如果您需要自定义虚拟机类型,请指定一个预定义虚拟机类型,其中 vCPU 的数量最接近但仍大于所需的数量。部署完成后,修改 vCPU 数量和内存量。 例如
n1-highmem-32。sole_tenant_deployment布尔值 可选。如果您想为 SAP HANA 部署配置单租户节点,请指定值
true。默认值为
false。此参数在
sap_hana_ha版本1.3.704310921或更高版本中可用。sole_tenant_name_prefix字符串 可选。如果您要为 SAP HANA 部署配置单租户节点,则可以使用此参数指定 Terraform 为相应单租户模板和单租户组的名称设置的前缀。
默认值为
st-SID_LC。如需了解单租户模板和单租户组,请参阅单租户概览。
此参数在
sap_hana_ha版本1.3.704310921或更高版本中可用。sole_tenant_node_type字符串 可选。如果您想为 SAP HANA 部署配置单租户节点,请指定要为相应节点模板设置的节点类型。
此参数在
sap_hana_ha版本1.3.704310921或更高版本中可用。network字符串 指定网络的名称,您需要在其中创建管理 VIP 的负载均衡器。 如果您使用的是共享 VPC 网络,则必须将宿主项目的 ID 添加为网络名称的父目录部分。例如
HOST_PROJECT_ID/NETWORK_NAME。subnetwork字符串 指定您在先前步骤中创建的子网的名称。如果您要部署到共享 VPC,请以 SHARED_VPC_PROJECT_ID/SUBNETWORK形式指定该值。例如myproject/network1。linux_image字符串 指定要在其中部署 SAP 系统的 Linux 操作系统映像的名称。 例如 sles-15-sp5-sap。 如需查看可用操作系统映像的列表,请参阅 Google Cloud 控制台中的映像页面。linux_image_project字符串 指定包含您为 linux_image参数指定的映像的 Google Cloud 项目。此项目可以是您自己的项目,也可以是某个 Google Cloud 映像项目。 对于 Compute Engine 映像,请指定suse-sap-cloud。 如需查找操作系统的映像项目,请参阅操作系统详细信息。primary_instance_name字符串 指定主要 SAP HANA 系统的虚拟机实例的名称。该名称可以包含小写字母、数字或连字符。 primary_zone字符串 指定要在其中部署主要 SAP HANA 系统的可用区。主要可用区和次要可用区必须位于同一区域。 例如: us-east1-c。secondary_instance_name字符串 指定辅助 SAP HANA 系统的虚拟机实例的名称。该名称可以包含小写字母、数字或连字符。 secondary_zone字符串 指定要在其中部署辅助 SAP HANA 系统的可用区。主要可用区和辅助可用区必须位于同一区域。 例如: us-east1-b。majority_maker_instance_name字符串 指定充当决胜者的 Compute Engine 虚拟机实例的名称。
此参数在
sap_hana_ha模块202307270727或更高版本中可用。majority_maker_instance_type字符串 指定要用于决胜者实例的 Compute Engine 虚拟机 (VM) 的类型。例如, n1-highmem-32。如果您需要自定义虚拟机类型,请指定一个预定义虚拟机类型,其中 vCPU 的数量最接近但仍大于所需的数量。部署完成后,修改 vCPU 数量和内存量。
此参数在
sap_hana_ha模块202307270727或更高版本中可用。majority_maker_zone字符串 指定要在其中部署决胜者虚拟机实例的可用区。此可用区必须与主要可用区和次要可用区位于同一区域。 例如 us-east1-d。Google Cloud 建议将决胜者虚拟机实例部署在与主要和辅助 SAP HANA 系统不同的可用区。
此参数在
sap_hana_ha模块202307270727或更高版本中可用。sap_hana_deployment_bucket字符串 如需在部署的虚拟机上自动安装 SAP HANA,请指定包含 SAP HANA 安装文件的 Cloud Storage 存储桶路径。请勿在路径中包含 gs://;仅包含存储桶名称和任何文件夹的名称。例如,my-bucket-name/my-folder。Cloud Storage 存储桶必须存在于您为
project_id参数指定的 Google Cloud 项目中。sap_hana_scaleout_nodes整数 指定在横向扩容系统中所需的工作器主机的数量。如需部署横向扩容系统,您至少需要一个工作器主机。 除了 SAP HANA 主实例之外,Terraform 还会创建工作器主机。比方说,如果指定为
3,则系统会在主要和次要可用区的横向扩容系统中部署 4 个 SAP HANA 实例。primary_sap_hana_shared_nfs字符串 可选。如需使用 NFS 解决方案与横向扩容高可用性部署主节点中的工作器主机共享
/hana/shared卷,请指定 NFS 解决方案的装载点。例如,10.151.90.120:/hana_shared_nfs。如需了解详情,请参阅多主机横向扩容部署的文件共享解决方案。
此参数在
sap_hana_ha模块1.3.730053050或更高版本中可用。secondary_sap_hana_shared_nfs字符串 可选。如需使用 NFS 解决方案与横向扩容高可用性部署辅助节点中的工作器主机共享
/hana/shared卷,请指定 NFS 解决方案的装载点。例如10.151.90.110:/hana_shared_nfs。如需了解详情,请参阅多主机横向扩容部署的文件共享解决方案。
此参数在
sap_hana_ha模块1.3.730053050或更高版本中可用。primary_sap_hana_backup_nfs字符串 可选。如需使用 NFS 解决方案与横向扩容高可用性部署主节点中的工作器主机共享
/hanabackup卷,请指定 NFS 解决方案的装载点。例如,10.151.90.130:/hana_backup_nfs。如需了解详情,请参阅多主机横向扩容部署的文件共享解决方案。
此参数在
sap_hana_ha模块1.3.730053050或更高版本中可用。secondary_sap_hana_backup_nfs字符串 可选。如需使用 NFS 解决方案与横向扩容高可用性部署辅助节点中的工作器主机共享
/hanabackup卷,请指定 NFS 解决方案的装载点。例如,10.151.90.140:/hana_backup_nfs。如需了解详情,请参阅多主机横向扩容部署的文件共享解决方案。
此参数在
sap_hana_ha模块1.3.730053050或更高版本中可用。sap_hana_sid字符串 如需在部署的虚拟机上自动安装 SAP HANA,请指定 SAP HANA 系统的 ID。此 ID 必须由 3 个字母数字字符组成,并以字母开头。所有字母必须大写。 例如 ED1。sap_hana_instance_number整数 可选。指定 SAP HANA 系统的实例编号(0 到 99)。默认值为 0。sap_hana_sidadm_password字符串 如需在部署的虚拟机上自动安装 SAP HANA,请为安装脚本指定一个临时 SIDadm密码,以便在部署期间使用。该密码必须至少包含 8 个字符,并且至少包含 1 个大写字母、1 个小写字母和 1 个数字。我们建议您使用密文,而不是以纯文本形式指定密码。如需了解详情,请参阅密码管理。
sap_hana_sidadm_password_secret字符串 可选。如果您使用 Secret Manager 存储 SIDadm密码,请指定与此密码对应的密文的名称。在 Secret Manager 中,请确保密文值(即密码)至少包含 8 个字符,并且至少包含 1 个大写字母、1 个小写字母和 1 个数字。
如需了解详情,请参阅密码管理。
sap_hana_system_password字符串 如需在部署的虚拟机上自动安装 SAP HANA,请为安装脚本指定一个临时数据库超级用户密码,以便在部署期间使用。该密码必须至少包含 8 个字符,并且至少包含 1 个大写字母、1 个小写字母和 1 个数字。 我们建议您使用密文,而不是以纯文本形式指定密码。如需了解详情,请参阅密码管理。
sap_hana_system_password_secret字符串 可选。如果您使用 Secret Manager 存储数据库超级用户密码,请指定与此密码对应的密文的名称。 在 Secret Manager 中,请确保密文值(即密码)至少包含 8 个字符,并且至少包含 1 个大写字母、1 个小写字母和 1 个数字。
如需了解详情,请参阅密码管理。
sap_hana_double_volume_size布尔值 可选。如需将 HANA 卷大小翻倍,请指定 true。如果要在同一虚拟机上部署多个 SAP HANA 实例或要部署灾难恢复 SAP HANA 实例,此参数会非常有用。默认情况下,卷大小会根据虚拟机大小自动计算为所需的最小大小,同时仍满足 SAP 认证和支持要求。默认值为false。sap_hana_backup_size整数 可选。指定 /hanabackup卷的大小(以 GB 为单位)。如果未指定此参数或将其设置为0,则安装脚本会为 Compute Engine 实例预配大小为总内存两倍的 HANA 备份卷。sap_hana_sidadm_uid整数 可选。指定一个值来替换 SID_LCadm 用户 ID 的默认值。默认值为 900。您可以将此值更改为其他值,以便在 SAP 环境中保持一致性。sap_hana_sapsys_gid整数 可选。替换 sapsys的默认组 ID。默认值为79。sap_vip字符串 可选。指定要用于 VIP 的 IP 地址。此 IP 地址必须在分配给子网的 IP 地址范围内。Terraform 配置文件会为您预留此 IP 地址。
从
sap_hana_ha模块的1.3.730053050版本开始,sap_vip参数是可选的。如果您未指定,Terraform 会自动从您为subnetwork参数指定的子网中分配可用的 IP 地址。primary_instance_group_name字符串 可选。指定主节点的非代管式实例组的名称。默认名称是 ig-PRIMARY_INSTANCE_NAME。secondary_instance_group_name字符串 可选。指定辅助节点的非代管式实例组的名称。默认名称是 ig-SECONDARY_INSTANCE_NAME。loadbalancer_name字符串 可选。指定内部直通式网络负载均衡器的名称。 默认名称是 lb-SAP_HANA_SID-ilb。network_tags字符串 可选。指定要与虚拟机实例关联的一个或多个网络标记(以英文逗号分隔),用于防火墙或路由。 如果您指定
public_ip = false而不指定网络标记,请务必另外提供一种访问互联网的方法。nic_type字符串 可选。指定要用于虚拟机实例的网络接口。您可以指定值 GVNIC或VIRTIO_NET。如需使用 Google 虚拟 NIC (gVNIC),您需要指定一个支持 gVNIC 的操作系统映像作为linux_image参数的值。如需查看操作系统映像列表,请参阅操作系统详细信息。如果您没有为此参数指定值,则系统会根据您为
此参数在machine_type参数指定的机器类型自动选择网络接口。sap_hana模块202302060649或更高版本中可用。disk_type字符串 可选。指定您要为部署中的 SAP 数据和日志卷部署的永久性磁盘或 Hyperdisk 卷的默认类型。如需了解通过 Google Cloud提供的 Terraform 配置执行的默认磁盘部署,请参阅通过 Terraform 执行磁盘部署。 以下是此参数的有效值:
pd-ssd、pd-balanced、hyperdisk-extreme、hyperdisk-balanced和pd-extreme。 在 SAP HANA 纵向扩容部署中,系统还会为/hana/shared目录部署一个单独的平衡永久性磁盘。您可以使用一些高级参数替换此默认磁盘类型以及关联的默认磁盘大小和默认 IOPS。如需了解详情,请转到您的工作目录,运行
terraform init命令,然后查看/.terraform/modules/sap_hana_ha/variables.tf文件。在生产环境中使用这些参数之前,请务必在非生产环境中对其进行测试。如果您想使用 SAP HANA 原生存储扩展 (NSE),则需要使用高级参数预配更大的磁盘。
use_single_shared_data_log_disk布尔值 可选。默认值为 false,指示 Terraform 为以下每个 SAP 卷部署单独的永久性磁盘或超磁盘:/hana/data、/hana/log、/hana/shared和/usr/sap。如需将这些 SAP 卷装载到同一永久性磁盘或超磁盘上,请指定true。enable_data_striping布尔值 可选。借助此参数,您可以在两个磁盘上部署 /hana/data卷。默认值为false,这会指示 Terraform 部署单个磁盘以托管/hana/data卷。此参数在
sap_hana_ha模块版本1.3.674800406或更高版本中可用。include_backup_disk布尔值 可选。此参数适用于 SAP HANA 纵向扩容部署。默认值为 true,它会指示 Terraform 部署单独的磁盘以托管/hanabackup目录。磁盘类型由
backup_disk_type参数决定。此磁盘的大小由sap_hana_backup_size参数决定。如果将
include_backup_disk的值设置为false,则不会为/hanabackup目录部署任何磁盘。enable_fast_restart布尔值 可选。此参数用于确定是否为部署启用了 SAP HANA 快速重启选项。默认值为 true。 Google Cloud 强烈建议启用“SAP HANA 快速重启”选项。此参数在
sap_hana_ha模块版本202309280828或更高版本中提供。public_ip布尔值 可选。决定是否为虚拟机实例添加一个公共 IP 地址。默认值为 true。service_account字符串 可选。指定主机虚拟机以及主机虚拟机上运行的程序将要使用的用户管理的服务账号的电子邮件地址。例如 svc-acct-name@project-id.。如果您指定此参数而不指定值,或者直接省略此参数,则安装脚本会使用 Compute Engine 默认服务账号。如需了解详情,请参阅 Google Cloud上的 SAP 程序的身份和访问权限管理。
sap_deployment_debug布尔值 可选。仅当 Cloud Customer Care 要求您为部署启用调试时才指定为 true,这会使部署生成详细的部署日志。默认值为false。primary_reservation_name字符串 可选。如需使用特定的 Compute Engine 虚拟机预留来预配托管高可用性集群的主要 SAP HANA 实例的虚拟机实例,请指定预留的名称。 默认情况下,安装脚本会根据以下条件选择任何可用的 Compute Engine 预留。 无论是您指定预留名称还是安装脚本自动选择预留,都必须对预留进行如下设置才能使用该预留:
-
将
specificReservationRequired选项设置为true;或在 Google Cloud 控制台中,选中选择特定预留选项。 -
某些 Compute Engine 机器类型支持的 CPU 平台尚未涵盖在该机器类型的 SAP 认证范围内。如果目标预留要用于以下任何机器类型,则必须按如下所示为该预留指定最低要求 CPU 平台:
n1-highmem-32:Intel Broadwelln1-highmem-64:Intel Broadwelln1-highmem-96:Intel Skylakem1-megamem-96:Intel Skylake
对于经过 SAP 认证在 Google Cloud 上使用的所有其他机器类型,最低要求 CPU 平台应符合 SAP 最低 CPU 要求。
secondary_reservation_name字符串 可选。如需使用特定的 Compute Engine 虚拟机预留来预配托管高可用性集群的辅助 SAP HANA 实例的虚拟机实例,请指定预留的名称。 默认情况下,安装脚本会根据以下条件选择任何可用的 Compute Engine 预留。 无论是您指定预留名称还是安装脚本自动选择预留,都必须对预留进行如下设置才能使用该预留:
-
将
specificReservationRequired选项设置为true;或在 Google Cloud 控制台中,选中选择特定预留选项。 -
某些 Compute Engine 机器类型支持的 CPU 平台尚未涵盖在该机器类型的 SAP 认证范围内。如果目标预留要用于以下任何机器类型,则必须按如下所示为该预留指定最低要求 CPU 平台:
n1-highmem-32:Intel Broadwelln1-highmem-64:Intel Broadwelln1-highmem-96:Intel Skylakem1-megamem-96:Intel Skylake
对于经过 SAP 认证在 Google Cloud 上使用的所有其他机器类型,最低要求 CPU 平台应符合 SAP 最低 CPU 要求。
primary_static_ip字符串 可选。为高可用性集群中的主虚拟机实例指定有效的静态 IP 地址。如果未指定,系统会自动为您的虚拟机实例生成 IP 地址。 例如 128.10.10.10。此参数在
sap_hana_ha模块202306120959或更高版本中可用。secondary_static_ip字符串 可选。为高可用性集群中的辅助虚拟机实例指定有效的静态 IP 地址。如果未指定,系统会自动为您的虚拟机实例生成 IP 地址。 例如 128.11.11.11。此参数在
sap_hana_ha模块202306120959或更高版本中可用。primary_worker_static_ips列表(字符串) 可选。为 SAP HANA 横向扩容高可用性系统的主实例中的工作器实例指定一组有效的静态 IP 地址。如果未指定此参数的值,系统会自动为每个工作器虚拟机实例生成一个 IP 地址。例如: [ "1.0.0.1", "2.3.3.4" ]。静态 IP 地址按实例创建顺序分配。例如,如果您选择部署 3 个工作器实例,但仅为参数指定 2 个 IP 地址
primary_worker_static_ips,则这些 IP 地址将分配给 Terraform 配置部署的前两个虚拟机实例。对于第三个工作器虚拟机实例,系统会自动生成 IP 地址。此参数在
sap_hana_ha模块202307270727或更高版本中可用。secondary_worker_static_ips列表(字符串) 可选。为 SAP HANA 横向扩容高可用性系统的辅助实例中的工作器实例指定一组有效的静态 IP 地址。如果未指定此参数的值,系统会自动为每个工作器虚拟机实例生成一个 IP 地址。 例如: [ "1.0.0.2", "2.3.3.5" ]。静态 IP 地址按实例创建顺序分配。例如,如果您选择部署 3 个工作器实例,但仅为参数指定 2 个 IP 地址
secondary_worker_static_ips,则这些 IP 地址将分配给 Terraform 配置部署的前两个虚拟机实例。对于第三个工作器虚拟机实例,系统会自动生成 IP 地址。此参数在
sap_hana_ha模块202307270727或更高版本中可用。can_ip_forward布尔值 指定是否允许发送和接收来源 IP 或目标 IP 不匹配的数据包,从而使虚拟机能够充当路由器。默认值为
true。如果您只打算使用 Google 的内部负载均衡器来管理已部署虚拟机的虚拟 IP,请将值设置为
false。系统会在高可用性模板中自动部署内部负载均衡器。以下示例展示了一个已完成的配置文件,该文件定义了 SLES 上的 SAP HANA 横向扩容系统的高可用性集群。该集群使用内部直通式网络负载均衡器来管理 VIP。
Terraform 会部署配置文件中定义的 Google Cloud 资源,然后脚本接管以配置操作系统、安装 SAP HANA、配置复制并配置 Linux 高可用性集群。
为清晰起见,以下示例配置中的注释被省略。
# ... module "sap_hana_ha" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source argument above and uncomment the source argument below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_ha/sap_hana_ha_module.zip" # ... project_id = "example-project-123456" machine_type = "n2-highmem-32" network = "example-network" subnetwork = "example-subnet-us-central1" linux_image = "sles-15-sp4-sap" linux_image_project = "suse-sap-cloud" primary_instance_name = "example-ha-vm1" primary_zone = "us-central1-a" secondary_instance_name = "example-ha-vm2" secondary_zone = "us-central1-b" majority_maker_instance_name = "example-ha-mj" majority_maker_instance_type = "n2-highmem-32" majority_maker_zone = "us-central1-c" sap_hana_scaleout_nodes = 2 primary_sap_hana_shared_nfs = "10.74.146.58:/hana_shared_nfs" secondary_sap_hana_shared_nfs = "10.74.146.68:/hana_shared_nfs" primary_sap_hana_backup_nfs = "10.188.249.180:/hana_backup_nfs" secondary_sap_hana_backup_nfs = "10.188.249.190:/hana_backup_nfs" # ... sap_hana_deployment_bucket = "my-hana-bucket" sap_hana_sid = "HA1" sap_hana_instance_number = 00 sap_hana_sidadm_password_secret = "hana_sid_adm_pwd" sap_hana_system_password_secret = "hana_sys_pwd" # ... sap_vip = "10.0.0.100" primary_instance_group_name = "ig-example-ha-vm1" secondary_instance_group_name = "ig-example-ha-vm2" loadbalancer_name = "lb-ha1" # ... network_tags = \["hana-ha-ntwk-tag"\] service_account = "sap-deploy-example@example-project-123456." primary_static_ip = "10.0.0.1" secondary_static_ip = "10.0.0.2" primary_worker_static_ips = \["10.0.0.3", "10.0.0.4"\] secondary_worker_static_ips = \["10.0.0.5", "10.0.0.6"\] enable_fast_restart = true # ... }-
将
初始化当前工作目录并下载适用于 Google Cloud的 Terraform 提供程序插件和模块文件:
terraform init
terraform init命令会为其他 Terraform 命令准备该工作目录。如需强制刷新工作目录中的提供程序插件和配置文件,请指定
--upgrade标志。如果省略--upgrade标志,并且您未对工作目录进行任何更改,则 Terraform 会使用本地缓存的副本,即使在source网址中指定了latest也是如此。terraform init --upgrade
(可选)创建 Terraform 执行计划:
terraform plan
terraform plan命令会显示当前配置所需的更改。如果您跳过此步骤,则terraform apply命令会自动创建新计划并提示您批准该计划。应用执行计划:
terraform apply
当系统提示您批准操作时,请输入
yes。terraform apply命令会设置 Google Cloud 基础架构,然后将控制权转交给脚本,脚本会根据 Terraform 配置文件中定义的参数配置高可用性集群并安装 SAP HANA。当 Terraform 拥有控制权时,状态消息将写入 Cloud Shell。调用脚本后,状态消息将写入 Logging,并可在 Google Cloud 控制台中查看,如查看日志中所述。
验证 HANA 高可用性系统的部署
验证 SAP HANA 高可用性集群涉及多个不同的流程,包括:
- 检查日志记录
- 检查虚拟机和 SAP HANA 安装的配置
- 检查集群配置
- 检查负载均衡器和实例组的运行状况
- 使用 SAP HANA Studio 检查 SAP HANA 系统
- 执行故障切换测试
查看日志
在 Google Cloud 控制台中,打开 Cloud Logging 以监控安装进度并检查是否存在错误。
过滤日志:
日志浏览器
在日志浏览器页面中,转到查询窗格。
从资源下拉菜单中选择全局,然后点击添加。
如果您没有看到全局选项,请在查询编辑器中输入以下查询:
resource.type="global" "Deployment"点击运行查询。
旧式日志查看器
- 在旧版日志查看器页面中,从基本选择器菜单选择全局作为日志记录资源。
分析过滤后的日志:
- 如果显示
"--- Finished",则表示部署已完成处理,您可以继续执行下一步。 如果出现配额错误,请执行以下步骤:
对于任何不符合 SAP HANA 规划指南中列出的 SAP HANA 要求的配额,请在“IAM 和管理”的配额页面上提高配额。
打开 Cloud Shell。
转到工作目录,然后删除部署以清理失败安装产生的虚拟机和永久性磁盘:
terraform destroy
当系统提示您批准该操作时,请输入
yes。重新运行部署。
- 如果显示
检查虚拟机和 SAP HANA 安装的配置
部署 SAP HANA 系统后(没有出现错误),使用 SSH 连接到每个虚拟机。您可以在 Compute Engine 虚拟机实例页面中点击每个虚拟机实例对应的 SSH 按钮,也可以使用自己偏好的 SSH 方法。

切换到根用户:
sudo su -
在命令提示符处,输入:
df -h
输出类似于以下示例。确保您的输出包含
/hana目录,例如/hana/data。example-ha-vm1:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 4.0M 8.0K 4.0M 1% /dev tmpfs 189G 48M 189G 1% /dev/shm tmpfs 51G 26M 51G 1% /run tmpfs 4.0M 0 4.0M 0% /sys/fs/cgroup /dev/sda3 30G 6.2G 24G 21% / /dev/sda2 20M 3.0M 17M 15% /boot/efi /dev/mapper/vg_hana_shared-shared 256G 41G 215G 16% /hana/shared /dev/mapper/vg_hana_data-data 308G 12G 297G 4% /hana/data /dev/mapper/vg_hana_log-log 128G 8.8G 120G 7% /hana/log /dev/mapper/vg_hana_usrsap-usrsap 32G 265M 32G 1% /usr/sap /dev/mapper/vg_hanabackup-backup 512G 8.5G 504G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/174 tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/0 tmpfs 26G 0 26G 0% /run/user/1000
通过输入特定于您的操作系统的状态命令,检查新集群的状态:
crm status您应该会看到类似于以下示例的输出,其中 SAP HANA 主系统中的虚拟机实例和辅助 SAP HANA 系统中的虚拟机实例已启动。
example-ha-vm1是活跃的主实例。example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.1.2+20211124.ada5c3b36-150400.4.9.2-2.1.2+20211124.ada5c3b36) - partition with quorum * Last updated: Sat Jul 15 19:42:56 2023 * Last change: Sat Jul 15 19:42:21 2023 by root via crm_attribute on example-ha-vm1 * 7 nodes configured * 23 resource instances configured Node List: * Online: \[ example-ha-mj example-ha-vm1 example-ha-vm1w1 example-ha-vm1w2 example-ha-vm2 example-ha-vm2w1 example-ha-vm2w2 \] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-mj * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * STONITH-example-ha-mj (stonith:fence_gce): Started example-ha-vm1w1 * STONITH-example-ha-vm1w1 (stonith:fence_gce): Started example-ha-vm1w2 * STONITH-example-ha-vm2w1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm1w2 (stonith:fence_gce): Started example-ha-vm2w1 * STONITH-example-ha-vm2w2 (stonith:fence_gce): Started example-ha-mj * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 \[rsc_SAPHanaTopology_HA1_HDB00\]: * Started: \[ example-ha-vm1 example-ha-vm1w1 example-ha-vm1w2 example-ha-vm2 example-ha-vm2w1 example-ha-vm2w2 \] * Stopped: \[ example-ha-mj \] * Clone Set: msl_SAPHana_HA1_HDB00 \[rsc_SAPHana_HA1_HDB00\] (promotable): * Masters: \[ example-ha-vm1 \] * Slaves: \[ example-ha-vm1w1 example-ha-vm1w2 example-ha-vm2 example-ha-vm2w1 example-ha-vm2w2 \] * Stopped: \[ example-ha-mj \]在以下命令中,将 SID_LC 替换为您在
sap_hana_ha.tf文件中指定的sap_hana_sid值,以切换到 SAP 管理员用户。SID_LC 值必须采用小写字母。su - SID_LCadm输入以下命令,确保 SAP HANA 服务(例如
hdbnameserver、hdbindexserver及其他服务)正在实例上运行:HDB info
检查集群配置
成功部署集群后,您必须检查集群的参数设置。检查集群软件显示的设置以及集群配置文件中的参数设置。将您的设置与以下示例中的设置进行比较,以下示例由本指南中使用的自动化脚本创建。
显示集群资源配置:
crm config show
本指南使用的自动化脚本会创建资源配置,如以下示例所示:
node 1: example-ha-vm1 \ attributes hana_ha1_site=example-ha-vm1 hana_ha1_gra=2.0 node 2: example-ha-vm2 \ attributes hana_ha1_site=example-ha-vm2 hana_ha1_gra=2.0 node 3: example-ha-mj node 4: example-ha-vm1w1 \ attributes hana_ha1_site=example-ha-vm1 hana_ha1_gra=2.0 node 5: example-ha-vm2w1 \ attributes hana_ha1_site=example-ha-vm2 hana_ha1_gra=2.0 node 6: example-ha-vm1w2 \ attributes hana_ha1_site=example-ha-vm1 hana_ha1_gra=2.0 node 7: example-ha-vm2w2 \ attributes hana_ha1_site=example-ha-vm2 hana_ha1_gra=2.0 primitive STONITH-example-ha-mj stonith:fence_gce \ params port=example-ha-mj zone="us-central1-c" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive STONITH-example-ha-vm1 stonith:fence_gce \ params port=example-ha-vm1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive STONITH-example-ha-vm1w1 stonith:fence_gce \ params port=example-ha-vm1w1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive STONITH-example-ha-vm1w2 stonith:fence_gce \ params port=example-ha-vm1w2 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive STONITH-example-ha-vm2 stonith:fence_gce \ params port=example-ha-vm2 zone="us-central1-b" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive STONITH-example-ha-vm2w1 stonith:fence_gce \ params port=example-ha-vm2w1 zone="us-central1-b" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive STONITH-example-ha-vm2w2 stonith:fence_gce \ params port=example-ha-vm2w2 zone="us-central1-b" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ op stop timeout=15 interval=0s primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHanaController \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Master timeout=700 \ op monitor interval=61 role=Slave timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 \ op start timeout=20s interval=0s \ op stop timeout=20s interval=0s primitive rsc_vip_int-primary IPaddr2 \ params ip=10.1.0.23 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s \ op start timeout=20s interval=0s \ op stop timeout=20s interval=0s group g-primary rsc_vip_int-primary rsc_vip_hc-primary \ meta resource-stickiness=0 ms msl_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta clone-node-max=1 master-max=1 interleave=true target-role=Started interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 target-role=Started interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm1w1 STONITH-example-ha-vm1w1 -inf: example-ha-vm1w1 location LOC_STONITH_example-ha-vm1w2 STONITH-example-ha-vm1w2 -inf: example-ha-vm1w2 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 location LOC_STONITH_example-ha-vm2w1 STONITH-example-ha-vm2w1 -inf: example-ha-vm2w1 location LOC_STONITH_example-ha-vm2w2 STONITH-example-ha-vm2w2 -inf: example-ha-vm2w2 location SAPHanaCon_not_on_mm msl_SAPHana_HA1_HDB00 -inf: example-ha-mj location SAPHanaTop_not_on_mm cln_SAPHanaTopology_HA1_HDB00 -inf: example-ha-mj colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started msl_SAPHana_HA1_HDB00:Master order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 msl_SAPHana_HA1_HDB00 property SAPHanaSR: \ hana_ha1_glob_mts=true \ hana_ha1_site_srHook_example-ha-vm2=SOK \ hana_ha1_site_lss_example-ha-vm1=4 \ hana_ha1_site_srr_example-ha-vm1=P \ hana_ha1_site_lss_example-ha-vm2=4 \ hana_ha1_site_srr_example-ha-vm2=S \ hana_ha1_glob_srmode=syncmem \ hana_ha1_glob_upd=ok \ hana_ha1_site_mns_example-ha-vm1=example-ha-vm1 \ hana_ha1_site_mns_example-ha-vm2=example-ha-vm2 \ hana_ha1_site_lpt_example-ha-vm2=30 \ hana_ha1_site_srHook_example-ha-vm1=PRIM \ hana_ha1_site_lpt_example-ha-vm1=1689450463 \ hana_ha1_glob_sync_state=SOK \ hana_ha1_glob_prim=example-ha-vm1 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="2.1.2+20211124.ada5c3b36-150400.4.9.2-2.1.2+20211124.ada5c3b36" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true \ concurrent-fencing=true rsc_defaults build-resource-defaults: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600显示集群配置文件
corosync.conf:cat /etc/corosync/corosync.conf
本指南使用的自动化脚本在
corosync.conf文件中指定参数设置,如以下示例所示:totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: "10.1.0.7" mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } quorum { provider: corosync_votequorum } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } node { ring0_addr: example-ha-mj nodeid: 3 } node { ring0_addr: example-ha-vm1w1 nodeid: 4 } node { ring0_addr: example-ha-vm2w1 nodeid: 5 } node { ring0_addr: example-ha-vm1w2 nodeid: 6 } node { ring0_addr: example-ha-vm2w2 nodeid: 7 } }
检查负载均衡器和实例组的运行状况
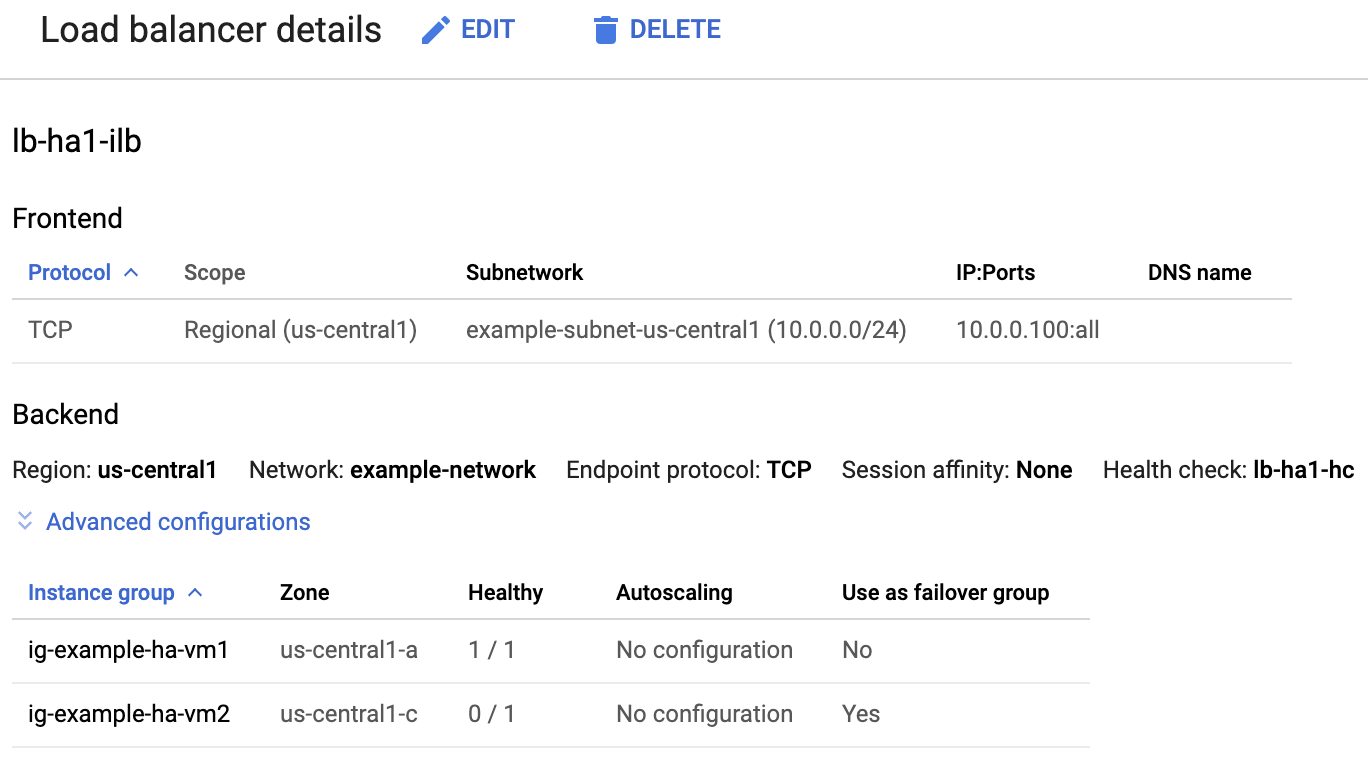
如需确认负载均衡器和健康检查是否已正确设置,请检查 Google Cloud 控制台中的负载均衡器和实例组。
在 Google Cloud 控制台中,打开负载均衡页面。
在负载均衡器列表中,确认已经为您的高可用性集群创建负载均衡器。
访问负载均衡器详情页面的后端部分,转到健康状况良好列,确认其中一个实例组显示 1/1,而另一个实例组显示 0/1。在故障切换后,健康状况良好指标 (1/1) 会切换到新的活跃实例组。
使用 SAP HANA Studio 检查 SAP HANA 系统
您可以使用 SAP HANA Cockpit 或 SAP HANA Studio 来监控和管理高可用性集群中的 SAP HANA 系统。
使用 SAP HANA Studio 连接到 HANA 系统。定义连接时,请指定以下值:
- 在“Specify System”面板上,将浮动 IP 地址指定为主机名。
- 在“连接属性”面板上,对于数据库用户身份验证,请指定数据库超级用户名和密码(该密码是您在
sap_hana_ha.tf文件中为sap_hana_system_password参数指定的密码)。
如需了解 SAP 提供的关于安装 SAP HANA Studio 的信息,请参阅 SAP HANA Studio 安装和更新指南。
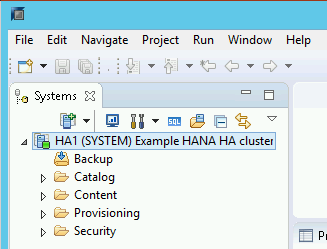
将 SAP HANA Studio 连接到您的 HANA 高可用性系统后,双击窗口左侧导航窗格中的系统名称以显示系统概览。
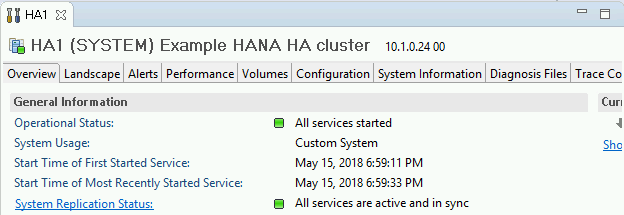
在概览标签页的常规信息下,确认以下内容:
- 操作状态会显示
All services started。 - 系统复制状态会显示
All services are active and in sync。
- 操作状态会显示
点击一般信息下的系统复制状态链接,确认复制模式。REPLICATION_MODE标签页上的 REPLICATION_MODE 列中的
SYNCMEM表示同步复制。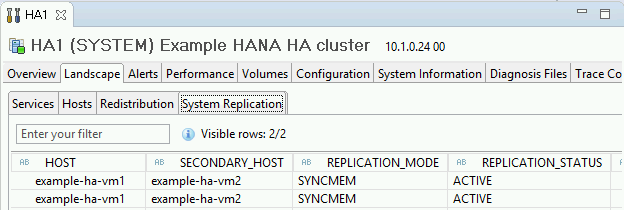
清理并重试部署
如果上述各部分中的任何部署验证步骤显示安装失败,则必须撤消部署并通过完成以下步骤重试:
解决所有错误以确保您的部署不会因同一原因再次失败。如需了解如何检查日志或解决配额相关错误,请参阅检查日志。
打开 Cloud Shell;如果已在本地工作站上安装了 Google Cloud CLI,则打开一个终端。
转到包含用于此部署的 Terraform 配置文件的目录。
通过运行以下命令删除属于部署的所有资源:
terraform destroy
当系统提示您批准该操作时,请输入
yes。按照本指南前面的说明重试部署。
执行故障切换测试
验证 SAP HANA 系统已成功部署后,您必须测试故障切换功能。
以下说明使用 ip link set eth0 down 命令将网络接口设为离线。此命令会验证故障切换和防护。
如需执行故障切换测试,请完成以下步骤:
在 SAP HANA 主实例中,使用 SSH 连接到主节点。您可以在 Compute Engine 虚拟机实例页面中通过点击每个虚拟机实例对应的 SSH 按钮进行连接,也可以使用自己偏好的 SSH 方法。
在命令提示符处,输入以下命令:
ip link set eth0 down
ip link set eth0 down命令断开与 SAP HANA 主实例的通信,从而触发故障切换。使用 SSH 连接到集群中的任何其他节点并切换到根用户。
通过运行以下命令,确认您的 SAP HANA 主实例目前在用于包含辅助实例的虚拟机上处于活动状态。
crm status由于集群中启用了自动重启,因此已停止的实例会重启并作为辅助实例角色。以下示例展示了每个 SAP HANA 实例上的角色已切换:
example-ha-vm2:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.1.2+20211124.ada5c3b36-150400.4.9.2-2.1.2+20211124.ada5c3b36) - partition with quorum * Last updated: Mon Jul 17 19:47:11 2023 * Last change: Mon Jul 17 19:46:56 2023 by root via crm_attribute on example-ha-vm2 * 7 nodes configured * 23 resource instances configured Node List: * Online: \[ example-ha-mj example-ha-vm1 example-ha-vm1w1 example-ha-vm1w2 example-ha-vm2 example-ha-vm2w1 example-ha-vm2w2 \] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-mj * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1w1 * STONITH-example-ha-mj (stonith:fence_gce): Started example-ha-vm1w1 * STONITH-example-ha-vm1w1 (stonith:fence_gce): Started example-ha-vm1w2 * STONITH-example-ha-vm2w1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm1w2 (stonith:fence_gce): Started example-ha-vm2w1 * STONITH-example-ha-vm2w2 (stonith:fence_gce): Started example-ha-mj * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 \[rsc_SAPHanaTopology_HA1_HDB00\]: * Started: \[ example-ha-vm1 example-ha-vm1w1 example-ha-vm1w2 example-ha-vm2 example-ha-vm2w1 example-ha-vm2w2 \] * Stopped: \[ example-ha-mj \] * Clone Set: msl_SAPHana_HA1_HDB00 \[rsc_SAPHana_HA1_HDB00\] (promotable): * Masters: \[ example-ha-vm2 \] * Slaves: \[ example-ha-vm1 example-ha-vm1w1 example-ha-vm1w2 example-ha-vm2w1 example-ha-vm2w2 \] * Stopped: \[ example-ha-mj \]在 Google Cloud 控制台的负载均衡器详细信息页面上,确认新的活跃主实例在运行状况良好列中显示 1/1。如有必要,请刷新页面。
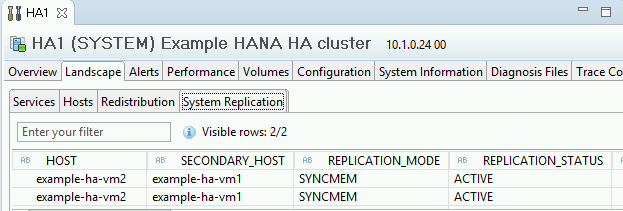
例如,请参阅下图:

在 SAP HANA Studio 中,双击导航窗格中的系统条目以刷新系统信息,确认您与系统仍处于连接状态。
点击 System Replication Status 链接以确认主要主机和辅助主机已交换主机,并且均处于活跃状态。
验证 Google Cloud的 Agent for SAP 的安装
部署基础架构并安装 SAP HANA 系统后,验证 Google Cloud的 Agent for SAP 是否正常运行。
验证 Google Cloud的 Agent for SAP 是否正在运行
如需验证代理是否正在运行,请按照以下步骤操作:
与您的 Compute Engine 实例建立 SSH 连接。
运行以下命令:
systemctl status google-cloud-sap-agent
如果代理正常运行,则输出包含
active (running)。例如:google-cloud-sap-agent.service - Google Cloud Agent for SAP Loaded: loaded (/usr/lib/systemd/system/google-cloud-sap-agent.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2022-12-02 07:21:42 UTC; 4 days ago Main PID: 1337673 (google-cloud-sa) Tasks: 9 (limit: 100427) Memory: 22.4 M (max: 1.0G limit: 1.0G) CGroup: /system.slice/google-cloud-sap-agent.service └─1337673 /usr/bin/google-cloud-sap-agent
如果代理未在运行,请重启代理。
验证 SAP Host Agent 正在接收指标
如需验证基础设施指标是否由Google Cloud的 Agent for SAP 收集并正确发送到 SAP Host Agent,请按照以下步骤操作:
- 在您的 SAP 系统中,输入事务
ST06。 在概览窗格中,检查以下字段的可用性和内容,以确保 SAP 与 Google 监控基础架构的端到端设置正确无误:
- Cloud Provider:
Google Cloud Platform - Enhanced Monitoring Access:
TRUE - Enhanced Monitoring Details:
ACTIVE
- Cloud Provider:
为 SAP HANA 设置监控
(可选)您可以使用Google Cloud的 Agent for SAP 来监控 SAP HANA 实例。从 2.0 版开始,您可以将代理配置为收集 SAP HANA 监控指标并将其发送到 Cloud Monitoring。借助 Cloud Monitoring,您可以创建信息中心以直观呈现这些指标,并根据指标阈值设置提醒等。
如需详细了解如何使用Google Cloud的 Agent for SAP 收集 SAP HANA 监控指标,请参阅 SAP HANA 监控指标收集。
连接到 SAP HANA
请注意,由于此处的说明不使用 SAP HANA 的外部 IP 地址,因此您只能使用 SSH 通过堡垒实例连接到 SAP HANA 实例,或使用 SAP HANA Studio 通过 Windows 服务器进行连接。
如需通过堡垒实例连接到 SAP HANA,请使用您选择的 SSH 客户端连接到堡垒主机,然后再连接到 SAP HANA 实例。
如需通过 SAP HANA Studio 连接到 SAP HANA 数据库,请使用远程桌面客户端连接到 Windows Server 实例。连接后,手动安装 SAP HANA Studio 并访问 SAP HANA 数据库。
配置 HANA 主动/主动(启用读取)
从 SAP HANA 2.0 SPS1 开始,您可以在 Pacemaker 集群中配置 HANA 主动/主动(启用读取)。如需了解相关说明,请参阅在 SUSE Pacemaker 集群中配置 HANA 主动/主动(启用读取)。
执行部署后任务
在使用 SAP HANA 实例之前,我们建议您执行以下几个部署后步骤。如需了解详情,请参阅 SAP HANA 安装和更新指南。
更改 SAP HANA 系统管理员和数据库超级用户的临时密码。
使用最新补丁程序更新 SAP HANA 软件。
如果 SAP HANA 系统部署在 VirtIO 网络接口上,我们建议您确保 TCP 参数
/proc/sys/net/ipv4/tcp_limit_output_bytes的值设置为1048576。此修改有助于提高 VirtIO 网络接口上的总体网络吞吐量,而不会影响网络延迟时间。安装任何其他组件,如应用函数库 (AFL) 或智能数据访问 (SDA)。
配置和备份新的 SAP HANA 数据库。如需了解详情,请参阅 SAP HANA 操作指南。
评估 SAP HANA 工作负载
如需对 Google Cloud上运行的 SAP HANA 高可用性工作负载自动执行持续验证检查,您可以使用 Workload Manager。
借助 Workload Manager,您可以根据 SAP、 Google Cloud和操作系统供应商的最佳实践自动扫描和评估 SAP HANA 高可用性工作负载。这有助于提高工作负载的质量、性能和可靠性。
如需了解 Workload Manager 支持用于评估 Google Cloud上运行的 SAP HANA 高可用性工作负载的最佳实践,请参阅适用于 SAP 的 Workload Manager 最佳实践。如需了解如何使用 Workload Manager 创建和运行评估,请参阅创建和运行评估。
问题排查
如需排查 SLES 上的 SAP HANA 高可用性配置问题,请参阅排查 SAP 高可用性配置。
获取支持
如果您在解决 SLES 上的 SAP HANA 高可用性集群问题时需要帮助,则必须收集所需的诊断信息并与 Cloud Customer Care 联系。如需了解详情,请参阅 SLES 上的高可用性集群诊断信息。
后续步骤
- 如果您需要使用 Google Cloud NetApp Volumes(而不是 Persistent Disk 卷或 Hyperdisk 卷)来托管 SAP HANA 目录(例如
/hana/shared或/hanabackup),请参阅 SAP HANA 规划指南中的 NetApp Volumes 部署信息。 - 如需详细了解虚拟机管理和监控,请参阅 SAP HANA 操作指南。