本指南介绍如何按照 Terraform:SAP HANA 纵向扩容部署指南运行在 Google Cloud 上部署的 SAP HANA 系统。请注意,本指南并非用于取代任何标准 SAP 文档。
在 Google Cloud上管理 SAP HANA 系统
本部分介绍如何执行 SAP HANA 系统运维工作通常所需的管理任务,包括与启动、停止和克隆系统有关的信息。
启动和停止实例
您可以随时停止一个或多个 SAP HANA 主机。停止实例会关停该实例。如果关停过程未在关停时段内完成,系统将强制停止实例。为避免数据丢失或文件系统损坏,我们建议您执行以下操作之一或两者:
先停止实例上运行的 SAP HANA,然后再停止实例。
如需延长实例的关停时段,请在实例中启用安全关停。
如需了解如何停止或重启实例,请参阅停止或重启 Compute Engine 实例。
修改虚拟机
部署虚拟机后,您可以更改虚拟机的各种特性,包括虚拟机类型。一些更改可能需要您从备份恢复 SAP 系统,而另一些更改可能只需要重启虚拟机。
如需了解详情,请参阅修改 SAP 系统的虚拟机配置。
创建 SAP HANA 的快照
如需生成永久性磁盘的时间点备份,您可以创建快照。Compute Engine 以冗余的方式在多个位置存储每个快照的多个副本,并利用自动校验和来确保数据完整性。
如需创建快照,请按照 Compute Engine 说明中的创建快照部分操作。在创建一致的快照之前,请特别注意准备步骤(例如将磁盘缓冲区刷新到磁盘),以确保快照保持一致。
快照在以下使用场景下非常有用:
| 使用场景 | 详细信息 |
|---|---|
| 提供易于使用、经济高效且独立于软件的数据备份解决方案。 | 使用快照备份数据、日志、备份和共享磁盘。为用于整个数据集的时间点备份的这些磁盘安排每日备份。 在第一个快照之后,只有增量块更改存储在后续快照中。这样有助于节省费用。 |
| 迁移到其他存储类型。 | Compute Engine 提供不同类型的永久性磁盘,包括基于标准(磁)存储的类型和基于固态硬盘存储(基于 SSD 的永久性磁盘)的类型。它们具有不同的费用和性能特征。例如,您可以将标准类型用于备份卷,将基于 SSD 的类型用于 /hana/log 和 /hana/data 卷,因为它们需要更高的性能。如需在存储类型之间进行迁移,请使用卷快照,然后再用快照创建新卷并选择其他存储类型。 |
| 将 SAP HANA 迁移到另一个地区或区域。 | 使用快照将 SAP HANA 系统从一个区域移至同一地区内的另一个区域,甚至可以移至另一个地区。您可以通过Google Cloud 在全球范围内使用快照在另一个可用区或区域中创建磁盘。如需移至另一个地区或区域,请创建磁盘(包括根磁盘)的快照,然后在所需的区域或地区中,使用根据这些快照创建的磁盘创建虚拟机。 |
更改磁盘设置
您可以更改预配的 IOPS 或吞吐量,也可以增加 Hyperdisk 卷的大小,这些操作每 4 小时可进行一次。如果您在 4 小时到期之前再次尝试修改磁盘,则会收到速率受限错误消息,例如 Cannot update provisioned throughput due to being rate limited。要解决这些错误,请在上次修改后等待 4 小时,然后才再次尝试修改磁盘。
只有在无法等待 4 小时来调整 Hyperdisk 卷的磁盘大小、预配 IOPS 或吞吐量的紧急情况下,才能使用此过程。
如需更改磁盘设置,请执行以下步骤:
运行以下命令之一停止 SAP HANA 实例:
HDB stopsapcontrol -nr INSTANCE_NUMBER -function StopSystem HDB
将
INSTANCE_NUMBER替换为您的 SAP HANA 系统的实例编号。如需了解详情,请参阅启动和停止 SAP HANA 系统。
创建现有磁盘的快照或映像:
基于快照的备份
gcloud compute snapshots create SNAPSHOT_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATION替换以下内容:
SNAPSHOT_NAME:要创建的快照的名称。PROJECT_NAME:您的 Google Cloud 项目的名称。SOURCE_DISK_NAME:用于创建快照的源磁盘。ZONE:要对其进行操作的源磁盘的可用区。LOCATION:要存储快照内容的 Cloud Storage 位置(单个区域或多个区域)。如需了解详情,请参阅创建和管理磁盘快照。
基于映像的备份
gcloud compute images create IMAGE_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATION替换以下内容:
IMAGE_NAME:要创建的磁盘映像的名称。PROJECT_NAME:您的 Google Cloud 项目的名称。SOURCE_DISK_NAME:用于创建映像的源磁盘。ZONE:要对其进行操作的源磁盘的可用区。LOCATION:要存储映像内容的 Cloud Storage 位置(单个区域或多个区域)。如需了解详情,请参阅创建自定义映像。
根据快照或映像创建新磁盘。
对于 Hyperdisk 卷,请确保指定磁盘大小、IOPS 和吞吐量,以满足工作负载要求。如需详细了解如何为 Hyperdisk 预配 IOPS 和吞吐量,请参阅 Hyperdisk 的预配性能简介。
从快照进行操作
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --source-snapshot=SOURCE_SNAPSHOT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUT替换以下内容:
NEW_DISK_NAME:要创建的磁盘的名称。PROJECT_NAME:您的 Google Cloud 项目的名称。DISK_TYPE:要创建的磁盘类型。DISK_SIZE:磁盘的大小。ZONE:要创建的磁盘的可用区。SOURCE_SNAPSHOT:用于创建磁盘的源快照。IOPS:要创建的磁盘的预配 IOPS。THROUGHPUT:要创建的磁盘的预配吞吐量。
从映像进行操作
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --image=SOURCE_IMAGE_NAME \ --image-project=IMAGE_PROJECT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUT替换以下内容:
NEW_DISK_NAME:要创建的磁盘的名称。PROJECT_NAME:您的 Google Cloud 项目的名称。DISK_TYPE:要创建的磁盘类型。DISK_SIZE:磁盘的大小。ZONE:要创建的磁盘的可用区。SOURE_IMAGE_NAME:要应用于正在创建的磁盘的源映像。IMAGE_PROJECT_NAME:要对其解析所有映像和映像系列引用的 Google Cloud 项目。IOPS:要创建的磁盘的预配 IOPS。THROUGHPUT:要创建的磁盘的预配吞吐量。
如需了解详情,请参阅
gcloud compute disks create。从 SAP HANA 系统中分离现有磁盘:
gcloud compute instances detach-disk INSTANCE_NAME \ --disk OLD_DISK_NAME \ --zone ZONE \ --project PROJECT_NAME替换以下内容:
INSTANCE_NAME:要对其进行操作的实例的名称。OLD_DISK_NAME:要按资源名称分离的磁盘。ZONE:要对其进行操作的实例的可用区。PROJECT_NAME:您的 Google Cloud 项目的名称。
如需了解详情,请参阅
gcloud compute instances detach-disk。将新磁盘挂接到 SAP HANA 系统:
gcloud compute instances attach-disk INSTANCE_NAME \ --disk NEW_DISK_NAME \ --zone ZONE \ --project PROJECT_NAME替换以下内容:
INSTANCE_NAME:要对其进行操作的实例的名称。NEW_DISK_NAME:要挂接到实例的磁盘的名称。ZONE:要对其进行操作的实例的可用区。PROJECT_NAME:您的 Google Cloud 项目的名称。
如需了解详情,请参阅
gcloud compute instances attach-disk。验证装载点是否已正确挂接:
lsblk您将看到如下所示的输出:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT ... sdd 8:48 0 1T 0 disk └─vg_hana_shared-shared 254:0 0 1024G 0 lvm /hana/shared sde 8:64 0 32G 0 disk └─vg_hana_usrsap-usrsap 254:3 0 32G 0 lvm /usr/sap sdf 8:80 0 13.8T 0 disk └─vg_hana_data-data 254:1 0 13.8T 0 lvm /hana/data sdg 8:96 0 512G 0 disk └─vg_hana_log-log 254:2 0 512G 0 lvm /hana/log运行以下命令之一启动 SAP HANA 实例:
HDB startsapcontrol -nr INSTANCE_NUMBER -function StartSystem HDB
将
INSTANCE_NUMBER替换为您的 SAP HANA 系统的实例编号。如需了解详情,请参阅启动和停止 SAP HANA 系统。
验证新的 Hyperdisk 卷的磁盘大小、IOPS 和吞吐量:
gcloud compute disks describe DISK_NAME \ --zone ZONE \ --project PROJECT_NAME替换以下内容:
DISK_NAME:要描述的磁盘的名称。ZONE:要描述的磁盘的可用区。PROJECT_NAME:您的 Google Cloud 项目的名称。
如需了解详情,请参阅
gcloud compute disks describe。
克隆 SAP HANA 系统
您可以创建 Google Cloud 上现有 SAP HANA 系统的快照,以精确克隆系统。
如需克隆单主机 SAP HANA 系统,请执行以下操作:
创建数据和备份磁盘的快照。
使用快照创建新磁盘。
在 Google Cloud 控制台中,前往虚拟机实例页面。
点击要克隆的实例,打开实例详情页面,然后点击克隆。
挂接根据快照创建的磁盘。
如需克隆多主机 SAP HANA 系统,请执行以下操作:
使用要克隆的 SAP HANA 系统所用的配置来预配新的 SAP HANA 系统。
对原始系统执行数据备份。
将原始系统的备份恢复到新系统中。
安装和更新 gcloud CLI
为 SAP HANA 部署了虚拟机并安装了操作系统之后,您需要使用最新的 Google Cloud CLI 完成各种任务,例如在 Cloud Storage 之间传输文件、与网络服务进行交互等等。
如果您按照 SAP HANA 部署指南中的说明操作,则系统会自动为您安装 gcloud CLI。
但如果您将自己的操作系统作为自定义映像引入 Google Cloud ,或使用Google Cloud提供的旧版公共映像,则可能需要自行安装或更新 gcloud CLI。
如需检查 gcloud CLI 是否已安装以及更新是否可用,请打开终端或命令提示符并输入以下内容:
gcloud version
如果系统无法识别该命令,则未安装 gcloud CLI。
如需安装 gcloud CLI,请按照安装 gcloud CLI 中的说明进行操作。
如需替换 SLES 集成的 140 版或更早版本的 gcloud CLI,请执行以下操作:
使用
ssh登录到虚拟机。切换到超级用户:
sudo su输入以下命令:
bash <(curl -s https://dl.google.com/dl/cloudsdk/channels/rapid/install_google_cloud_sdk.bash) --disable-prompts --install-dir=/usr/local update-alternatives --install /usr/bin/gsutil gsutil /usr/local/google-cloud-sdk/bin/gsutil 1 --force update-alternatives --install /usr/bin/gcloud gcloud /usr/local/google-cloud-sdk/bin/gcloud 1 --force gcloud --quiet compute instances list
启用 SAP HANA 快速重启
Google Cloud 强烈建议为每个 SAP HANA 实例(尤其是较大的实例)启用 SAP HANA 快速重启。当 SAP HANA 终止但操作系统保持运行时,SAP HANA 快速重启可以减少重启时间。
按照 Google Cloud 提供的自动化脚本配置,操作系统和内核设置已支持 SAP HANA 快速重启。您需要定义 tmpfs 文件系统并配置 SAP HANA。
如需定义 tmpfs 文件系统并配置 SAP HANA,您可以按照手动步骤进行操作,也可以使用Google Cloud 提供的自动化脚本来启用 SAP HANA 快速重启。如需了解详情,请参阅:
如需了解 SAP HANA 快速重启的完整权威说明,请参阅 SAP HANA 快速重启选项文档。
手动步骤
配置 tmpfs 文件系统
成功部署主机虚拟机和基本 SAP HANA 系统后,您需要在 tmpfs 文件系统中创建和装载 NUMA 节点的目录。
显示虚拟机的 NUMA 拓扑
在映射所需的 tmpfs 文件系统之前,您需要知道虚拟机有多少 NUMA 节点。如需显示 Compute Engine 虚拟机上的可用 NUMA 节点,请输入以下命令:
lscpu | grep NUMA
例如,m2-ultramem-208 虚拟机类型有四个 NUMA 节点(编号为 0-3),如以下示例所示:
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
创建 NUMA 节点目录
为虚拟机中的每个 NUMA 节点创建一个目录,并设置权限。
例如,对于编号为 0-3 的四个 NUMA 节点:
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SID将 NUMA 节点目录装载到 tmpfs
装载 tmpfs 文件系统目录,并使用 mpol=prefer 为每个目录指定 NUMA 节点首选设置:
SID 使用大写字母指定 SID。
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
更新/etc/fstab
为了确保装载点在操作系统重新启动后可用,请将条目添加到文件系统表 /etc/fstab 中:
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
可选:设置内存用量限制
tmpfs 文件系统可以动态扩缩。
如需限制 tmpfs 文件系统使用的内存,您可以使用 size 选项设置 NUMA 节点卷的大小限制。例如:
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
您还可以通过设置 global.ini 文件的 [memorymanager] 部分中的 persistent_memory_global_allocation_limit 参数,限制给定 SAP HANA 实例和给定服务器节点的所有 NUMA 节点的总 tmpfs 内存用量。
快速重启的 SAP HANA 配置
要配置 SAP HANA 以使用快速重启,请更新 global.ini 文件并指定要存储在永久性内存中的表。
更新 global.ini 文件中的 [persistence] 部分
配置 SAP HANA global.ini 文件中的 [persistence] 部分以引用 tmpfs 位置。用英文分号分隔每个 tmpfs 位置:
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
上述示例为 4 个 NUMA 节点指定了 4 个内存卷,对应于 m2-ultramem-208。如果您是在 m2-ultramem-416 上运行,则需要配置 8 个内存卷 (0..7)。
修改 global.ini 文件后,重启 SAP HANA。
SAP HANA 现在可以将 tmpfs 位置用作永久性内存空间。
指定要存储在永久性内存中的表
指定要存储在永久性内存中的特定列表或分区。
例如,如需为现有表启用永久性内存,请执行 SQL 查询:
ALTER TABLE exampletable persistent memory ON immediate CASCADE
如需更改新表的默认设置,请在 indexserver.ini 文件中添加参数 table_default。例如:
[persistent_memory] table_default = ON
如需详细了解如何控制列、表以及哪些监控视图提供详细信息,请参阅 SAP HANA 永久性内存。
自动步骤
Google Cloud 提供的用于启用 SAP HANA 快速重启的自动化脚本会更改目录 /hana/tmpfs*、文件 /etc/fstab 和 SAP HANA 配置。运行脚本时,您可能需要执行其他步骤,具体取决于这是 SAP HANA 系统的初始部署,还是需要将机器大小调整为其他 NUMA 大小。
对于 SAP HANA 系统的初始部署或调整机器大小以增加 NUMA 节点的数量,请确保在执行 Google Cloud提供的用于启用 SAP HANA 快速重启的自动化脚本期间正在运行 SAP HANA。
当您调整机器大小以减少 NUMA 节点的数量时,请确保在执行 Google Cloud 提供的用于启用 SAP HANA 快速重启的自动化脚本期间已停止 SAP HANA。执行脚本后,您需要手动更新 SAP HANA 配置以完成 SAP HANA 快速重启设置。如需了解详情,请参阅用于快速重启的 SAP HANA 配置。
如需启用 SAP HANA 快速重启,请按照以下步骤操作:
与主机虚拟机建立 SSH 连接。
切换到根用户:
sudo su -
下载
sap_lib_hdbfr.sh脚本:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
让该文件可执行:
chmod +x sap_lib_hdbfr.sh
验证脚本没有错误:
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
如果该命令返回错误,请与 Cloud Customer Care 团队联系。如需详细了解如何与 Customer Care 联系,请参阅获取对 SAP on Google Cloud的支持。
在替换 SAP HANA 数据库的 SYSTEM 用户的 SAP HANA 系统 ID (SID) 和密码后运行脚本。要安全地提供密码,我们建议您在 Secret Manager 中使用 Secret。
使用 Secret Manager 中的 Secret 名称运行脚本。此 Secret 必须存在于包含主机虚拟机实例的 Google Cloud 项目中。
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
替换以下内容:
SID:使用大写字母指定 SID。例如AHA。SECRET_NAME:指定与 SAP HANA 数据库的 SYSTEM 用户密码相对应的 Secret 名称。此 Secret 必须存在于包含主机虚拟机实例的 Google Cloud 项目中。
或者,您可以使用纯文本密码运行脚本。启用 SAP HANA 快速重启后,请务必更改密码。不建议使用纯文本密码,因为密码将记录在虚拟机的命令行历史记录中。
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
替换以下内容:
SID:使用大写字母指定 SID。例如AHA。PASSWORD:指定 SAP HANA 数据库的 SYSTEM 用户的密码。
如果系统成功运行了初始运行,您应该会看到如下所示的输出:
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
使用 SAProuter 设置您的 SAP 支持渠道
如果您需要允许 SAP 支持工程师访问Google Cloud上的 SAP HANA 系统,则可以使用 SAProuter 实现此目的。请按照以下步骤操作:
启动将要安装 SAProuter 软件的 Compute Engine 虚拟机实例,并分配一个外部 IP 地址,使该实例能够访问互联网。
创建一个新的静态外部 IP 地址,然后向该实例分配此 IP 地址。
在网络中创建和配置特定的 SAProuter 防火墙规则。在此规则中,仅授予 SAProuter 实例对 SAP 支持网络所需的入站和出站访问权限。
限制入站和出站访问权限,仅允许 SAP 提供给您连接的特定 IP 地址以及 TCP 端口
3299进行访问。将目标标记添加到防火墙规则,然后输入实例名称。这样可以确保防火墙规则仅适用于新实例。如需详细了解创建和配置防火墙规则的其他信息,请参阅防火墙规则文档。按照 SAP 说明 1628296 安装 SAProuter 软件,并创建一个允许从 SAP 访问 Google Cloud上的 SAP HANA 系统的
saprouttab文件。建立与 SAP 的连接。对于互联网连接,请使用安全网络通信。如需了解详情,请参阅 SAP 远程支持 - 帮助。
配置网络
您正在使用虚拟机和Google Cloud 虚拟网络来预配 SAP HANA 系统。 Google Cloud 采用先进的软件定义网络和分布式系统技术在全球范围内托管和交付您的服务。
对于 SAP HANA,请创建一个非默认子网,并为网络中的每个子网分配互不重叠的 CIDR IP 地址范围。请注意,每个子网及其内部 IP 地址范围都映射到单个地区。
子网覆盖创建它的地区中的所有区域。
但是,创建虚拟机实例时,您需要为虚拟机指定区域和子网。例如,您可以根据需要在 subnetwork1 和 region1 的 zone1 中创建一组实例,在 subnetwork2 和 region1 的 zone2 中创建另一组实例。
新网络没有防火墙规则,因此没有网络访问权限。您应该创建防火墙规则,按照最小权限模式开放对 SAP HANA 实例的访问权限。防火墙规则适用于整个网络,您也可以使用标记机制将其配置为适用于特定的目标实例。
路由是挂接到单个网络的全局资源,而非地区性资源。用户创建的路由适用于网络中的所有实例。这意味着您可以添加路由,以便在同一网络中的实例之间以及子网之间转发流量,而无需外部 IP 地址。
对于 SAP HANA 实例,请启动不具备外部 IP 地址的实例,并将另一个虚拟机配置为 NAT 网关以进行外部访问。此配置需要您将 NAT 网关添加为 SAP HANA 实例的路由。如需了解此过程,请参阅部署指南。
安全
以下部分讨论了安全运维。
最小权限模式
第一道防线是使用防火墙限制哪些用户可以访问实例。通过创建防火墙规则,您可以对通过给定的一组端口对传送到特定网络或目标机器的所有流量加以限制,仅允许来自指定源 IP 地址的流量。您应该按照最小权限模式来限制访问权限,仅允许需要访问权限的特定 IP 地址、协议和端口进行访问。例如,您应始终设置堡垒主机,并且仅允许通过该主机对 SAP HANA 系统进行 SSH 访问。
配置变更
您应该使用推荐的安全设置来配置 SAP HANA 系统和操作系统。例如,确保仅列出相关的网络端口以允许访问、对运行 SAP HANA 的操作系统进行安全强化等等。
请参阅以下 SAP 说明(需要 SAP 用户账号):
停用不需要的 SAP HANA 服务
如果您不需要 SAP HANA 扩展应用服务 (SAP HANA XS),请停用该服务。请参阅 SAP 说明 1697613:从拓扑中移除 SAP HANA XS 传统引擎服务。
停用该服务后,请移除为该服务打开的所有 TCP 端口。在 Google Cloud中,这意味着修改网络的防火墙规则,以从访问权限列表中移除这些端口。
审核日志记录
Cloud Audit Logs 包含两个日志流:管理员活动和数据访问;它们由 Google Cloud自动生成,可帮助您在Google Cloud 项目中回答“哪些用户何时在何处执行了什么操作?”这一问题。
管理活动日志包含下列日志条目:API 调用或修改服务或项目的配置或元数据的管理操作。此日志始终处于启用状态,并且对所有项目成员可见。
数据访问日志包含下列日志条目:创建、修改或读取由服务管理并由用户提供的数据(例如存储在数据库服务中的数据)的 API 调用。默认情况下,此类日志记录在您的项目中处于启用状态,您可以通过 Cloud Logging 或活动 Feed 对其进行访问。
保护 Cloud Storage 存储桶的安全
如果您使用 Cloud Storage 来托管数据和日志的备份,请确保在从实例向 Cloud Storage 发送数据时使用 TLS (HTTPS),以保护传输中的数据。Cloud Storage 会自动加密静态数据。如果您有自己的密钥管理系统,则可以自行指定加密密钥。
相关安全文档
请参阅针对 Google Cloud上的 SAP HANA 环境的以下其他安全资源:
Google Cloud上的 SAP HANA 的高可用性
Google Cloud 提供了多种用于确保 SAP HANA 系统高可用性的方案,包括 Compute Engine 实时迁移和自动重启功能。由于这些功能以及 Compute Engine 虚拟机较高的每月正常运行时间百分比,您可能无需为备用系统支付费用和提供维护。
但如果需要,您可以部署包含备用主机的多主机横向扩容系统以用于 SAP HANA 主机自动故障转移,也可以在高可用性 Linux 集群中部署具有备用 SAP HANA 实例的纵向扩容系统。
如需详细了解Google Cloud上的 SAP HANA 的高可用性选项,请参阅 SAP HANA 高可用性规划指南。
启用 SAP HANA 高可用性/灾难恢复提供商钩子
灾难恢复
SAP HANA 系统提供了多种高可用性功能,以确保您的 SAP HANA 数据库能够承受软件或基础架构级层的故障。这些功能包括 Google Cloud 支持的 SAP HANA 系统复制和 SAP HANA 备份。
如需详细了解 SAP HANA 备份,请参阅备份和恢复。
如需详细了解系统复制,请参阅 SAP HANA 灾难恢复规划指南。
备份与恢复
备份对于保护记录系统(数据库)至关重要。由于 SAP HANA 是内存中数据库,因此定期创建备份并实施适当的备份策略有助于在计划外服务中断或基础设施故障引起的数据损坏或数据丢失等情况下恢复 SAP HANA 数据库。SAP HANA 系统提供内置备份和恢复功能,可帮助您实现此目的。您可以使用 Google Cloud服务(例如 Cloud Storage)作为 SAP HANA 备份的备份目标位置。
您还可以启用 Google Cloud的 Agent for SAP 的 Backint 功能,以便能够直接使用 Cloud Storage 进行备份和恢复。
如需了解在 Compute Engine 裸金属实例(例如 X4)上运行的 SAP HANA 系统的备份和恢复建议,请参阅在裸金属实例上备份和恢复 SAP HANA。
本文档假定您熟悉 SAP HANA 备份和恢复,以及下列 SAP 服务说明:
- 1642148:常见问题解答:SAP HANA 数据库备份和恢复
- 1821207:确定所需的恢复文件
- 1869119:使用
hdbbackupcheck检查备份 - 1873247:使用
hdbbackupdiag --check检查恢复能力 - 1651055:在 Linux 中计划 SAP HANA 数据库备份
使用 Compute Engine 永久性磁盘卷和 Cloud Storage 进行备份
如果您已按照 Google Cloud 提供的基于 Terraform 的部署说明部署 SAP HANA 系统,则表示您已经安装了 SAP HANA 并在平衡永久性磁盘卷上托管了 /hanabackup 目录。
如需创建目标位置为 /hanabackup 目录的在线数据库备份,请使用标准 SAP 工具,例如 SAP HANA Studio、SAP HANA Cockpit、SAP ABAP 事务 DB13 或 SAP HANA SQL 语句。最后,将完成的备份上传到 Cloud Storage 存储桶以保存备份;当需要恢复 SAP HANA 系统时,您便可以从该存储桶下载备份。
使用 Compute Engine 创建备份和磁盘快照
您可以使用 Compute Engine 进行 SAP HANA 备份,也可以选择使用标准磁盘快照备份托管 SAP HANA 数据和日志卷的整个磁盘。
如果按照部署指南中的说明进行操作,则您将安装 SAP HANA 并创建一个 /hanabackup 目录用于备份在线数据库。您可以使用同一目录来存储 /hanabackup 卷的快照,并维护 SAP HANA 数据和日志卷的时间点备份。
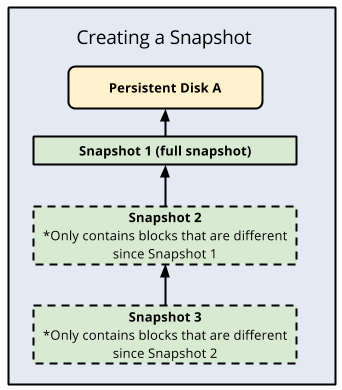
标准磁盘快照的优点在于它们是递增的,其中后续的每个备份都仅存储增量块更改,而不会创建全新的备份。Compute Engine 以冗余的方式在多个位置存储每个快照的多个副本,并利用自动校验和来确保数据完整性。
以下是增量备份的图示:
将 Cloud Storage 作为备份目标位置
Cloud Storage 非常适合用作 SAP HANA 的备份目标位置,因为它可以提供较高的数据耐用性和可用性。
Cloud Storage 是适合任何类型或格式的文件的对象存储区。它的存储空间几乎不受限制,因此您不必担心它的预配或向它增加更多容量。Cloud Storage 中的对象包含文件数据及其关联的元数据,最大可达 5 TB。Cloud Storage 存储桶可以存储任意数量的对象。
利用 Cloud Storage,您的数据可以存储在多个位置,这提供了极高的耐用性和可用性。将数据上传到 Cloud Storage 或在 Cloud Storage 中复制数据时,只有在实现对象冗余后,Cloud Storage 才会报告操作取得成功。
下表显示了 Cloud Storage 提供的存储选项:
| 数据读/写频率 | 推荐的 Cloud Storage 选项 |
|---|---|
| 读写频繁 | 为使用中的数据库选择标准存储类别,因为它们可能会经常访问 Cloud Storage 以写入和读取备份文件。 |
| 读写不频繁 | 为不经常访问的数据(例如根据组织的保留政策需要维护的归档备份)选择 Nearline 或 Coldline Storage。 Nearline 适合您计划每月最多访问一次的备份数据,而 Coldline 更适合访问概率极低(例如每年最多访问一次)的数据。 |
| 归档数据 | 为长期归档的数据选择 Archive Storage。 Archive 适合您需要长时间保留副本但不打算每年多次访问的数据。例如,为需要长期保留的备份使用 Archive Storage,以满足监管要求。 请考虑用 Archive 替代基于磁带的备份解决方案。 |
在规划这些存储方案的使用时,请从频繁访问的层级开始,并将备份数据老化到不常访问的层级。 通常,备份在变旧的过程中很少使用。需要 3 年前的备份的可能性极小,因此您可以将此类备份老化到 Archive 级存储,以节省费用。如需了解 Cloud Storage 费用,请参阅 Cloud Storage 价格。
Cloud Storage 与磁带备份的比较
传统的本地备份目标位置是磁带。与磁带相比,Cloud Storage 有很多优势,包括能够在源系统的“异地”自动存储备份,因为 Cloud Storage 中的数据来自多处设施中的复本。这也意味着存储在 Cloud Storage 中的备份具有高可用性。
另一个主要区别是当您需要使用备份时,恢复备份的速度。如果您需要根据备份创建新的 SAP HANA 系统或根据备份恢复现有系统,则 Cloud Storage 可以提供更快的数据访问速度,这有助于您更快构建系统。
Google Cloud的 Agent for SAP 的 Backint 功能
借助经 SAP 认证的 Google Cloud的 Agent for SAP 的 Backint 功能,您可以直接将 Cloud Storage 用于备份和恢复本地和云端安装。
如需详细了解此功能,请参阅适用于 SAP HANA 的基于 Backint 的备份和恢复。
使用 Backint 备份和恢复 SAP HANA
以下部分介绍了如何使用 Google Cloud的 Agent for SAP 的 Backint 功能备份和恢复 SAP HANA。
触发数据和增量备份
如需触发 SAP HANA 数据卷的备份并使用 Google Cloud的 Agent for SAP 的 Backint 功能将其发送到 Cloud Storage,您可以使用 SAP HANA Studio、SAP HANA Cockpit、SAP HANA SQL 或 DBA Cockpit。
以下是用于触发数据备份的 SAP HANA SQL 语句:
如需为系统数据库创建完整备份,请执行以下操作:
BACKUP DATA USING BACKINT ('BACKUP_NAME');将
BACKUP_NAME替换为您要为备份设置的名称。要为租户数据库创建完整备份,请执行以下操作:
BACKUP DATA FOR TENANT_SID USING BACKINT ('BACKUP_NAME');将
TENANT_SID替换为租户数据库的 SID。如需创建差分备份和增量备份,请执行以下操作:
BACKUP DATA BACKUP_TYPE USING BACKINT ('BACKUP_NAME'); BACKUP DATA BACKUP_TYPE FOR TENANT_SID USING BACKINT ('BACKUP_NAME');将
BACKUP_TYPE替换为DIFFERENTIAL或INCREMENTAL,具体取决于您要创建的备份类型。
在触发数据备份时有多个选项可用。如需了解这些选项,请参阅 SAP HANA SQL 参考指南 BACKUP DATA 语句(备份和恢复)。
如需详细了解数据和增量备份,请参阅 SAP 文档数据备份和增量备份。
触发日志备份
如需触发 SAP HANA 日志卷的备份并使用 Google Cloud的 Agent for SAP 的 Backint 功能将其发送到 Cloud Storage,请完成以下步骤:
- 创建完整的数据库备份。如需查看相关说明,请参阅 SAP HANA 版本对应的 SAP 文档。
- 在 SAP HANA
global.ini文件中,将参数catalog_backup_using_backint设置为yes。
确保 SAP HANA 系统的日志模式为 normal,这是默认值。如果日志模式设置为 overwrite,则 SAP HANA 数据库会禁止创建日志备份。
如需详细了解日志备份,请参阅 SAP 文档日志备份。
查询备份目录
SAP HANA 备份目录是备份和恢复操作的关键部分。它包含为 SAP HANA 数据库创建的备份的相关信息。
如需查询备份目录以获取有关租户数据库的备份的信息,请完成以下步骤:
- 将租户数据库离线。
在系统数据库上,运行以下 SQL 语句:
BACKUP COMPLETE LIST DATA FOR TENANT_SID;
或者,如需查询特定时间点,请运行以下 SQL 语句:
BACKUP LIST DATA FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD';
该语句会在以下目录中创建
strategyOutput.xml文件:/usr/sap/SID/HDBINSTANCE_NUMBER/HOST_NAME/trace/DB_TENANT_SID。
如需了解 BACKUP LIST DATA 语句,请参阅 SAP HANA SQL 参考指南 BACKUP DATA 语句(备份和恢复)。如需了解备份目录,请参阅 SAP 文档备份目录。
恢复数据库
使用多流数据备份执行恢复时,SAP HANA 会使用在创建备份时使用的相同数量的信道。如需了解详情,请参阅 SAP 文档前提条件:使用多流备份进行恢复。
如需恢复使用 Google Cloud的 Agent for SAP 的 Backint 功能创建的 SAP HANA 数据库备份,SAP HANA 提供了 RECOVER DATA 和 RECOVER DATABASE SQL 语句。
除非您已为 recover_bucket 参数指定了存储桶,否则这两个 SQL 语句都会从您为 PARAMETERS.json 文件中的 bucket 参数指定的 Cloud Storage 存储桶恢复备份。
以下是使用备份来恢复 SAP HANA 数据库的 SQL 语句示例(该备份使用Google Cloud的 Agent for SAP 的 Backint 功能创建):
如需通过指定备份文件名来恢复租户数据库,请执行以下操作:
RECOVER DATA FOR TENANT_SID USING BACKINT('BACKUP_NAME') CLEAR LOG;如需通过指定备份 ID 来恢复租户数据库,请执行以下操作:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID CLEAR LOG;
将
BACKUP_ID替换为所需备份的 ID。若要在需要使用 SAP HANA 备份目录的备份(该备份存储在 Cloud Storage 存储桶中)时通过指定备份 ID 来恢复租户数据库,请执行以下操作:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID USING CATALOG BACKINT CLEAR LOG;
如需将租户数据库恢复到特定时间点或特定日志位置,请执行以下操作:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CHECK ACCESS USING BACKINT;
要使用外部数据库中的备份来恢复租户数据库,请执行以下操作:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CLEAR LOG USING SOURCE 'SOURCE_TENANT_SID@SOURCE_SID' USING CATALOG BACKINT CHECK ACCESS USING BACKINT
替换以下内容:
SOURCE_TENANT_SID:源租户数据库的 SIDSOURCE_SID:存在源租户数据库的 SAP 系统的 SID
如需在 Cloud Storage 存储桶中存储的备份中没有 SAP HANA 备份目录时恢复 SAP HANA 数据库,请按照 SAP 说明3227931 - 不使用 HANA 备份目录从 Backint 中恢复 HANA 数据库中的说明操作。
管理身份和对备份的访问权限
当您使用 Cloud Storage 或 Compute Engine 备份 SAP HANA 数据时,身份和访问权限管理 (IAM) 会控制对这些备份的访问权限。借助此功能,管理员能够授权哪些人员可以对特定资源执行操作。利用 IAM,您可以获得集中控制和可见性,以便管理所有Google Cloud 资源(包括备份)。
此外,IAM 还会自动为您的管理员提供权限授权、移除和委派操作的完整审计跟踪历史记录。这样您就可以配置策略以监控对备份数据的访问权限,从而完成数据的完整访问权限控制周期。 IAM 可让您集中了解整个企业的安全政策,并提供内置审核功能来简化合规流程。
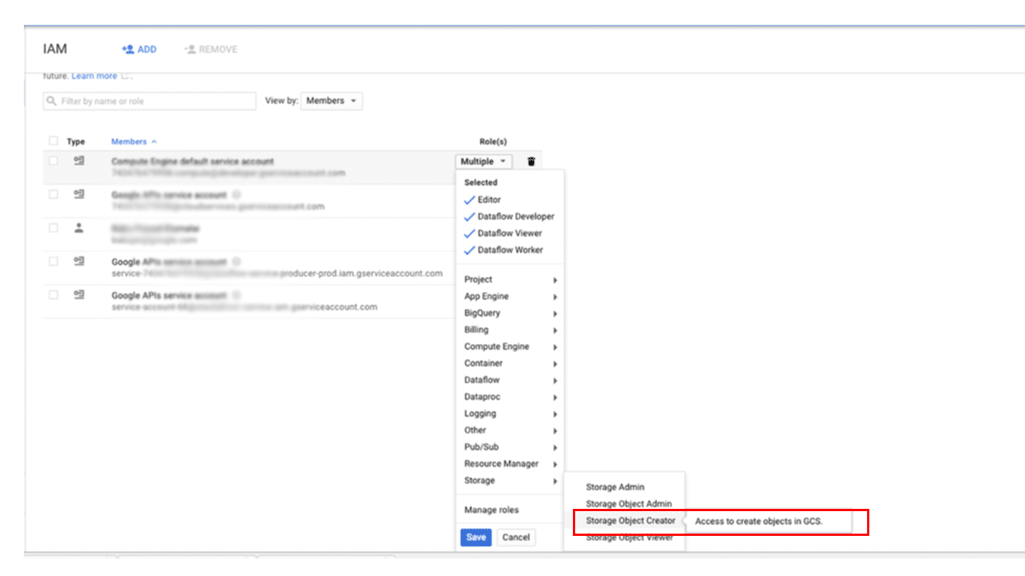
如需向主账号授予对 Cloud Storage 中的备份的访问权限,请执行以下操作:
在 Google Cloud 控制台中,前往 IAM 和管理页面:
指定您要授予访问权限的用户,然后前往 Storage > Storage Object Creator,分配此角色:
如何为 SAP HANA 创建基于文件系统的备份
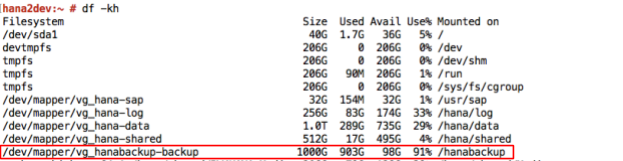
使用部署指南在 Google Cloud 上部署的 SAP HANA 系统配置了一组永久性磁盘卷或 Hyperdisk 卷,用作装载了 NFS 的备份目标位置。SAP HANA 备份首先存储在这些本地磁盘上,然后您需要将它们复制到 Cloud Storage 进行长期存储。您可以将备份手动复制到 Cloud Storage,也可以在 crontab 中安排复制到 Cloud Storage。
如果您使用 Google Cloud的 Agent for SAP 的 Backint 功能,则可以直接备份到 Cloud Storage 存储桶并从中恢复,从而无需使用永久性磁盘存储进行备份。
如需启动或安排 SAP HANA 数据备份,您可以使用 SAP HANA Studio、SQL 命令或 DBA Cockpit。除非停用,否则系统会自动写入日志备份。以下屏幕截图展示了一个示例:
配置 SAP HANA global.ini
如果按照部署指南说明进行操作,则系统将使用存储在 /hanabackup/data/ 中的数据库备份自定义 SAP HANA global.ini 配置文件,并将自动日志归档文件存储在 /hanabackup/log/ 中。global.ini 的示例如下所示:
[persistence]
basepath_datavolumes = /hana/data
basepath_logvolumes = /hana/log
basepath_databackup = /hanabackup/data
basepath_logbackup = /hanabackup/log
[system_information]
usage = production
如需为Google Cloud的 Agent for SAP 的 Backint 功能自定义 global.ini 配置文件,请参阅配置 SAP HANA 以使用 Backint 功能。
横向扩容部署说明
在实施横向扩容过程中,使用实时迁移和自动重启的高可用性解决方案的运作方式与单主机设置中的相同。它们之间的主要区别在于 /hana/shared 卷以 NFS 形式装载到所有工作器主机上并且可以在 HANA 主实例中进行控制。如果主实例主机进行实时迁移或自动重启,则 NFS 卷在短时间内不可访问。重启主实例主机后,NFS 卷将很快在所有主机上再次开始运行,并且将自动继续正常操作。
在备份和恢复操作期间,SAP HANA 备份卷 /hanabackup 必须在所有主机上都可用。如果发生故障,则必须验证 /hanabackup 是否已装载到所有主机上并在没有该备份卷的主机上重新进行装载。当您选择将备份集复制到另一个卷或 Cloud Storage 时,请在主实例主机上运行该副本,从而获得更好的 I/O 性能并减少网络使用量。为了简化备份和恢复过程,您可以使用 Cloud Storage Fuse 在每个主机上装载 Cloud Storage 存储桶。
横向扩容性能只取决于数据分布情况。数据分布得越好,查询性能就越出色。这就要求您充分了解数据,了解数据的使用情况,并相应地设计表分布和分区。如需了解详情,请参阅 SAP 说明 2081591 - 常见问题解答:SAP HANA 表分布。
Gcloud Python
Gcloud Python 是一个惯用的 Python 客户端,您可以用它来访问Google Cloud 服务。本指南使用 Gcloud Python 在 Cloud Storage 中对 SAP HANA 数据库备份执行备份和恢复操作。
如果您按照部署指南说明操作,则可以使用 Compute Engine 实例中提供的 Gcloud Python 库。
这些库都是开源的,您可以通过这些库在 Cloud Storage 存储桶上进行操作,以存储和检索备份数据。
您可以运行以下命令以列出 Cloud Storage 存储桶中的对象。您可以使用它列出可用的备份:
python 2>/dev/null - <<EOF
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("<bucket_name>")
blobs = bucket.list_blobs()
for fileblob in blobs:
print(fileblob.name)
EOF
如需了解 Gcloud Python 的完整详情,请参阅存储客户端库参考文档。
备份和恢复示例
以下部分说明了使用 SAP HANA Studio 执行典型备份和恢复任务时可能会遵循的过程。
备份创建示例
在 SAP HANA 备份编辑器中,选择打开备份向导。
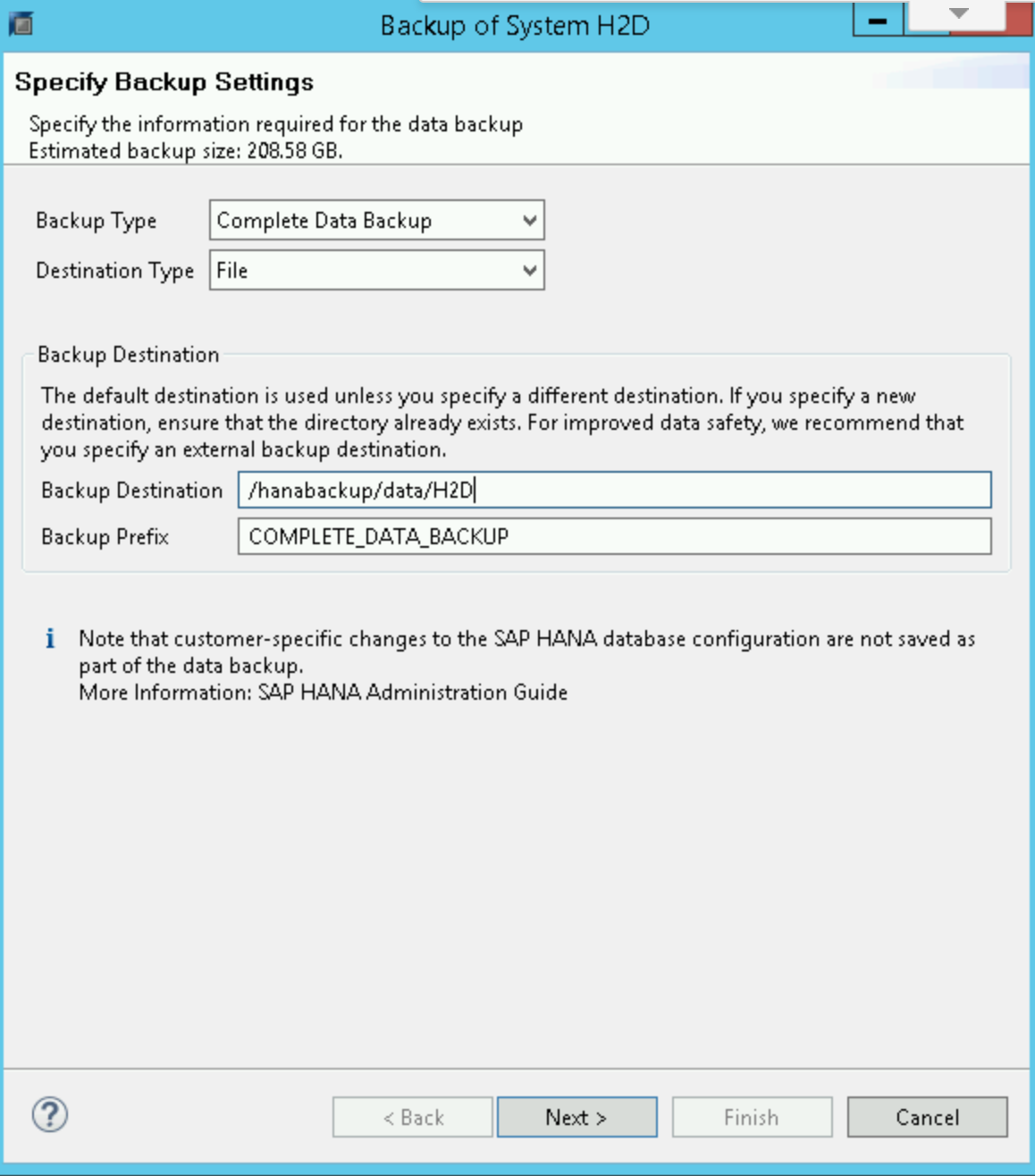
- 选择文件作为目标类型。这样数据库会备份到指定文件系统的文件中。
- 指定备份目标位置
/hanabackup/data/SID和备份前缀。 将SID替换为 SAP 系统的系统 ID。 - 点击下一步。
在确认表单中,点击完成以开始备份。
备份开始时,状态窗口将显示备份进度。 等待备份完成。
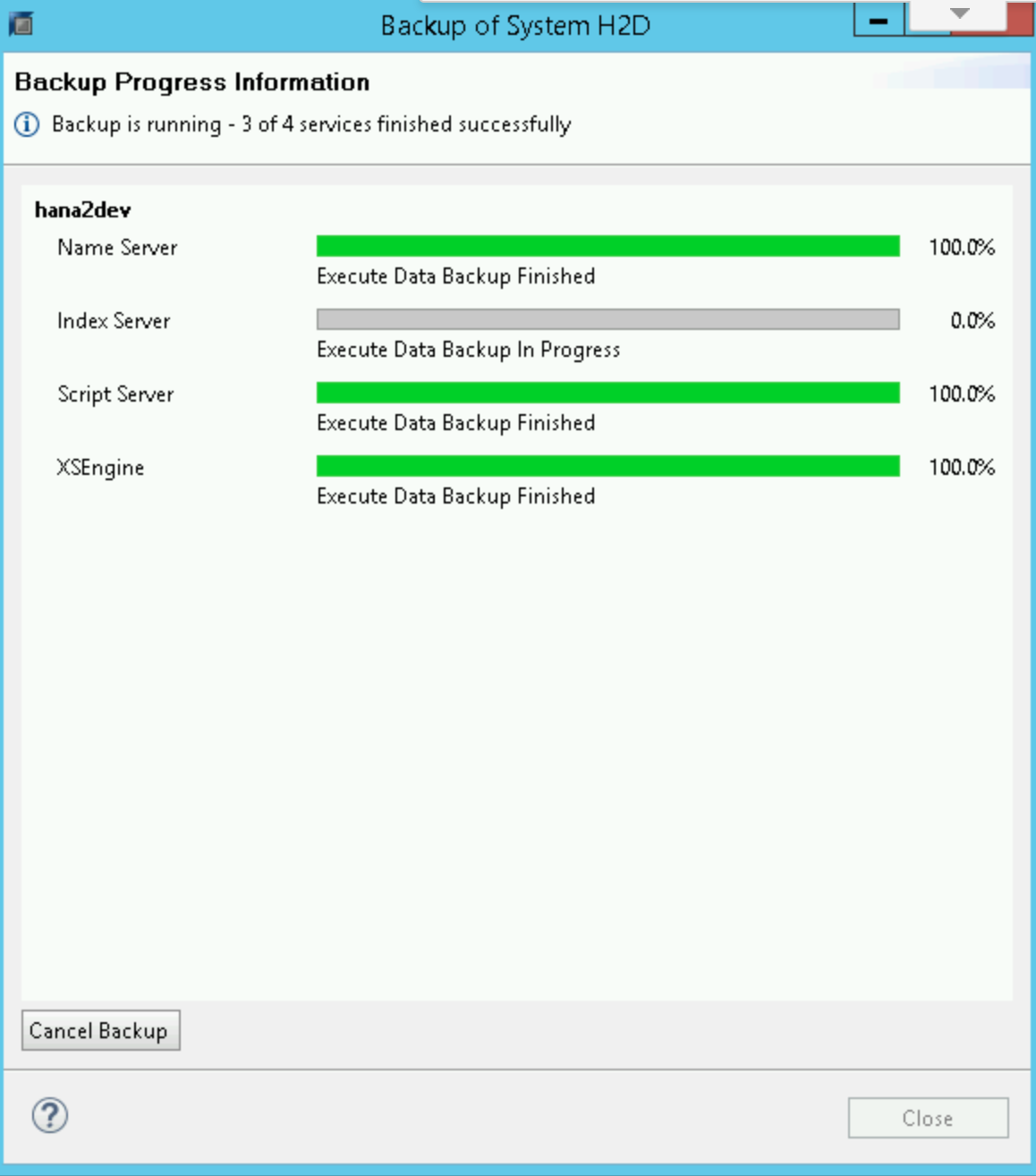
备份完成后,备份摘要将显示
Finished消息。登录到您的 SAP HANA 系统,并验证备份在文件系统中的预期位置是否可用。例如:
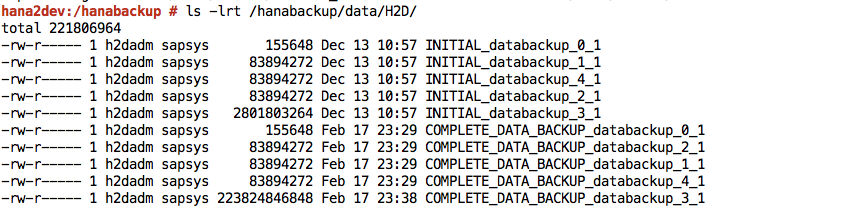

将备份文件从
/hanabackup文件系统推送或同步到 Cloud Storage。下面的 Python 脚本示例采用NODE_NAME/DATA或LOG/YYYY/MM/DD/HH/BACKUP_FILE_NAME格式,将数据从/hanabackup/data和/hanabackup/log推送到用于备份的存储桶中。这样一来,您便可以根据复制备份的时间来识别备份文件。在操作系统 bash 提示符下运行以下gcloud Python脚本:python 2>/dev/null - <<EOF import os import socket from datetime import datetime from google.cloud import storage storage_client = storage.Client() today = datetime.today() current_hour = today.strftime('%Y/%m/%d/%H') hostname = socket.gethostname() bucket = storage_client.get_bucket("hanabackup") for subdir, dirs, files in os.walk('/hanabackup/data/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/data/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) for subdir, dirs, files in os.walk('/hanabackup/log/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/log/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) EOF使用 Gcloud Python 库或 Google Cloud 控制台列出备份数据。
备份恢复示例
如果备份文件在
/hanabackup目录中不可用,但在 Cloud Storage 中可用,则在操作系统 bash 提示符下运行以下脚本,从 Cloud Storage 中下载文件:python - <<EOF from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket("hanabackup") blobs = bucket.list_blobs() for fileblob in blobs: blob = bucket.blob(fileblob.name) fname = str(fileblob.name).split('/')[-1] blob.chunk_size=1<<30 if 'log' in fname: blob.download_to_filename('/hanabackup/log/H2D/' + fname) else: blob.download_to_filename('/hanabackup/data/H2D/' + fname) EOF如需恢复 SAP HANA 数据库,请点击备份与恢复 > 恢复系统:
点击下一步。
指定备份在本地文件系统中的位置,然后点击添加。
点击下一步。
选择不使用备份目录进行恢复 (Recover without the backup catalog):
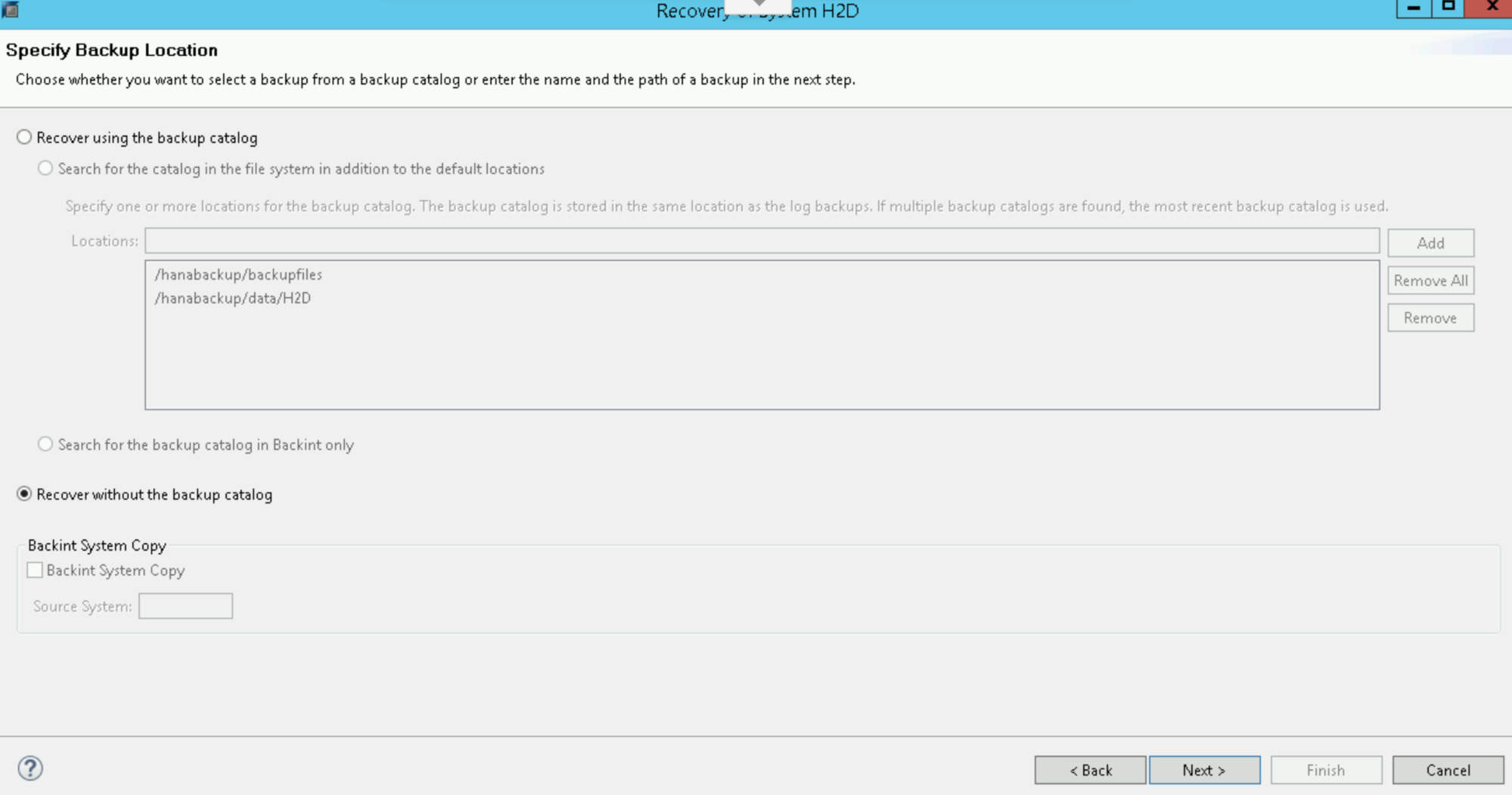
点击下一步。
选择文件作为目标类型,然后指定备份文件的位置以及正确的备份前缀。如果您已按照备份创建示例过程进行操作,请记住
COMPLETE_DATA_BACKUP已设置为前缀。点击两次下一步。
点击完成以开始恢复。
恢复完成后,恢复正常运营并从
/hanabackup/data/SID/*目录中移除备份文件。
后续步骤
以下标准 SAP 文档可能会对您有所帮助:
以下 Google Cloud 文档可能也会有所帮助: