Questo documento descrive vari modi per implementare il multitenancy in Spanner. Vengono inoltre descritti i modelli di gestione dei dati e la gestione del ciclo di vita degli utenti.
La multiproprietà si verifica quando una singola istanza o alcune istanze di un'applicazione software servono più tenant o clienti. Questo pattern software può essere scalato da un singolo tenant o cliente a centinaia o migliaia. Questo approccio è fondamentale per le piattaforme di cloud computing in cui l'infrastruttura di base è condivisa tra più organizzazioni.
Pensa alla multi-tenancy come a una forma di partizionamento basata su risorse di calcolo condivise, come i database. Un'analogia sono gli inquilini di un condominio: infrastruttura condivisa, ma spazio dedicato per gli inquilini. La multitenancy fa parte della maggior parte, se non di tutte, le applicazioni SaaS (Software as a Service).
Questo documento è rivolto ad architetti di database, architetti di dati e ingegneri che implementano applicazioni multi-tenant su Spanner come database relazionale. In questo contesto, illustra vari approcci per archiviare i dati multi-tenant. I termini "tenant", "cliente" e "organizzazione" vengono utilizzati in modo intercambiabile nell'articolo per indicare l'entità che accede all'applicazione multi-tenant.
Questo articolo utilizza un fornitore SaaS di risorse umane (HR) che implementa la propria applicazione multi-tenant su Google Cloud come esempio. Nell'esempio, diversi clienti del fornitore SaaS HR devono accedere all'applicazione multi-tenant. Questi clienti sono chiamati tenant.
Spanner è il database di Google Cloudcompletamente gestito, di livello enterprise, distribuito e coerente che combina i vantaggi del modello di database relazionale con la scalabilità orizzontale non relazionale. Spanner ha una semantica relazionale, con schemi, tipi di dati forzati, elevata coerenza, transazioni ACID con più istruzioni e un linguaggio di query SQL che implementa SQL ANSI 2011.
Spanner offre tempi di inattività pari a zero per la manutenzione pianificata o i guasti regionali, con uno SLA (accordo sul livello del servizio) di disponibilità del 99,999%. Supporta applicazioni multi-tenant moderne, offrendo alta disponibilità e scalabilità. Questo articolo illustra i diversi approcci di architettura per implementare il multitenancy con Spanner.
Criteri per la mappatura dei dati del tenant
In un'applicazione multi-tenant, i dati di ogni tenant sono isolati in uno dei diversi approcci di architettura nel database Spanner sottostante. Il seguente elenco illustra i diversi approcci di architettura utilizzati per mappare i dati di un tenant a Spanner:
- Istanzia:un tenant risiede esclusivamente in un'istanza Spanner, con esattamente un database per quel tenant.
- Database:un tenant si trova in un database in un'unica istanza Spanner contenente più database.
- Schema: un tenant si trova in tabelle esclusive all'interno di un database e diversi tenant possono trovarsi nello stesso database.
- Tabella: i dati dell'utente sono righe nelle tabelle del database. Queste tabelle sono condivise con altri tenant.
I criteri precedenti sono chiamati pattern di gestione dei dati e sono descritti in dettaglio nella sezione Pattern di gestione dei dati multi-tenancy. Questa discussione si basa sui seguenti criteri:
- Isolamento: il grado di isolamento dei dati tra più tenant è un fattore determinante per il multitenancy. L'isolamento è determinato dalle scelte fatte per i criteri in altre categorie. Ad esempio, alcuni requisiti normativi e di conformità possono richiedere un grado maggiore di isolamento.
- Agilità: la facilità di onboarding e offboarding per un tenant rispetto alla creazione di un'istanza, un database o una tabella.
- Operazioni: la disponibilità o la complessità di implementazione di attività di amministrazione e operazioni di database specifiche per i tenant, ad esempio manutenzione regolare, registrazione, backup o operazioni di disaster recovery.
- Scalabilità:la capacità di scalare senza problemi per consentire la crescita futura. La descrizione di ogni pattern contiene il numero di tenant che il pattern può supportare.
- Rendimento: la possibilità di allocare risorse esclusive a ogni tenant, risolvere il fenomeno del vicino rumoroso e consentire prestazioni di lettura e scrittura prevedibili per ogni tenant.
- Regolamenti e conformità:la capacità di soddisfare i requisiti di settori e paesi altamente regolamentati che richiedono l'isolamento completo delle risorse e delle operazioni di manutenzione. Ad esempio, i requisiti di residenza dei dati per la Francia richiedono che le informazioni di identificazione personale vengano archiviate fisicamente esclusivamente in Francia.
Ogni modello di gestione dei dati in relazione a questi criteri è descritto in dettaglio nella sezione successiva. Utilizza gli stessi criteri quando selezioni un modello di gestione dei dati per un insieme specifico di tenant.
Pattern di gestione dei dati multi-tenancy
Le sezioni seguenti descrivono i quattro principali pattern di gestione dei dati: istanza, database, schema e tabella.
Istanza
Per garantire un isolamento completo, il pattern di gestione dei dati dell'istanza archivia i dati di ogni tenant nella propria istanza e nel proprio database Spanner. Un'istanza Spanner può avere uno o più database. In questo pattern viene creato un solo database. Per l'applicazione HR discussa in precedenza, viene creata un'istanza Spanner distinta con un database per ogni organizzazione del cliente.
Come mostrato nel seguente diagramma, il pattern di gestione dei dati ha un tenant per istanza.
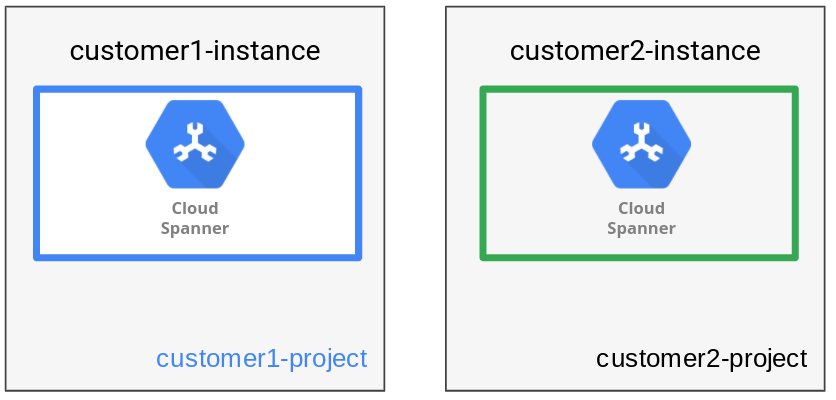
Avere istanze separate per ogni tenant consente di utilizzare progetti Google Cloud distinti per ottenere confini di attendibilità distinti per tenant diversi. Un altro vantaggio è che ogni configurazione dell'istanza può essere scelta in base alla località di ciascun tenant (a livello regionale o multiregionale), ottimizzando la località, la flessibilità e le prestazioni.
L'architettura può essere facilmente scalata a qualsiasi numero di tenant. I fornitori di servizi SaaS possono creare un numero illimitato di istanze nelle regioni desiderate, senza limiti rigidi.
La tabella seguente illustra in che modo il pattern di gestione dei dati delle istanze influisce su diversi criteri.
| Criteri | Istituzione: un modello di gestione dei dati per istanza e tenant |
|---|---|
| Isolamento |
|
| Agilità |
|
| Operazioni |
|
| Scala |
|
| Prestazioni |
|
| Requisiti normativi e di conformità |
|
In sintesi, i punti chiave sono:
- Vantaggio: massimo livello di isolamento
- Svantaggio: maggiore costo operativo
Il pattern di gestione dei dati delle istanze è più adatto per i seguenti scenari:
- Utenti diversi sono distribuiti in una vasta gamma di regioni e richiedono una soluzione localizzata.
- I requisiti normativi e di conformità per alcuni tenant richiedono livelli superiori di sicurezza e protocolli di controllo.
- Le dimensioni degli utenti variano notevolmente, pertanto la condivisione delle risorse tra gli utenti con volumi e traffico elevati potrebbe causare conflitti e un degrado reciproco.
Database
Nel pattern di gestione dei dati del database, ogni tenant risiede in un database all'interno di un'unica istanza Spanner. Più database possono trovarsi in una singola istanza. Se un'istanza non è sufficiente per il numero di tenant, crea più istanze. Questo pattern implica che una singola istanza Spanner sia condivisa tra più tenant.
Spanner ha un limite massimo di 100 database per istanza. Questo limite significa che se il fornitore SaaS deve gestire più di 100 clienti, deve creare e utilizzare più istanze Spanner.
Per l'applicazione RU, il fornitore SaaS crea e gestisce ogni tenant con un database separato in un'istanza Spanner.
Come mostrato nel seguente diagramma, il pattern di gestione dei dati ha un tenant per database.
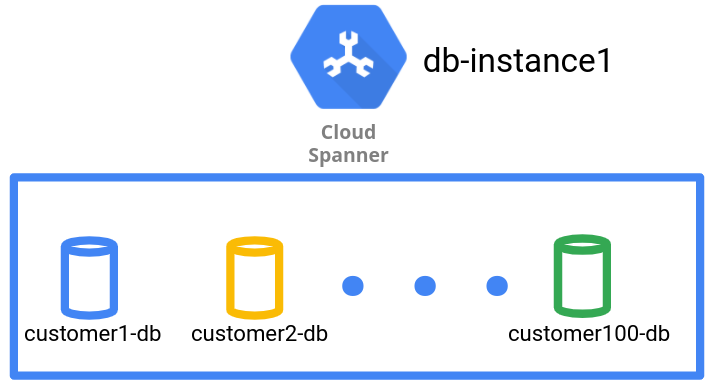
Il pattern di gestione dei dati del database consente di ottenere l'isolamento logico a livello di database per i dati di diversi tenant. Tuttavia, poiché si tratta di un'unica istanza Spanner, tutti i database dei tenant condividono la stessa configurazione regionale e la stessa configurazione di calcolo e archiviazione sottostanti.
La tabella seguente illustra in che modo il pattern di gestione dei dati del database influisce su diversi criteri.
| Criteri | Database: un tenant per ogni pattern di gestione dei dati del database |
|---|---|
| Isolamento |
|
| Agilità |
|
| Operazioni |
|
| Scala |
|
| Prestazioni |
|
| Requisiti normativi e di conformità |
|
In sintesi, i punti chiave sono:
- Vantaggio: livello di isolamento più elevato
- Svantaggio: numero limitato di tenant per istanza; riluttanza a cambiare sede
Il pattern di gestione dei dati del database è più adatto per i seguenti scenari:
- Più clienti si trovano nella stessa residenza dei dati, ad esempio in Francia o nel Regno Unito, e/o sono soggetti alla stessa autorità di regolamentazione.
- Gli utenti richiedono la separazione dei dati in base al sistema e il backup/ripristino, ma accettano la condivisione delle risorse di infrastruttura.
Schema
Nel pattern di gestione dei dati dello schema, un singolo database, che implementa un singolo schema, viene utilizzato per più tenant e un insieme separato di tabelle viene utilizzato per i dati di ciascun tenant. Queste tabelle possono essere differenziate includendo tenant ID nei nomi delle tabelle come prefisso o suffisso.
Questo pattern di gestione dei dati che utilizza un insieme separato di tabelle per ogni tenant offre un livello di isolamento molto più basso rispetto alle opzioni precedenti (i pattern di gestione di istanze e database). Il pattern semplifica anche l'onboarding: richiede la creazione di nuove tabelle e di indici e integrità referenziale associati.
Un'importante limitazione è che le autorizzazioni di accesso per Spanner tramite Identity and Access Management (IAM) vengono fornite solo a livello di istanza o database. Non è possibile fornire autorizzazioni di accesso a livello di tabella. Esiste anche un limite di 5000 tabelle per database. Per molti clienti, questo limite limita l'utilizzo dell'applicazione.
Inoltre, l'utilizzo di tabelle separate per ogni cliente può comportare un elevato backlog di operazioni di aggiornamento dello schema. Risolvere un backlog di questo tipo richiede molto tempo.
Per l'applicazione HR, il fornitore SaaS può creare un insieme di tabelle per ogni
cliente con tenant ID come prefisso nei nomi delle tabelle, ad esempio
customer1_employee, customer1_payroll, customer1_department.
Come mostrato nel seguente diagramma, il pattern di gestione dei dati dello schema ha un insieme di tabelle per ogni tenant.
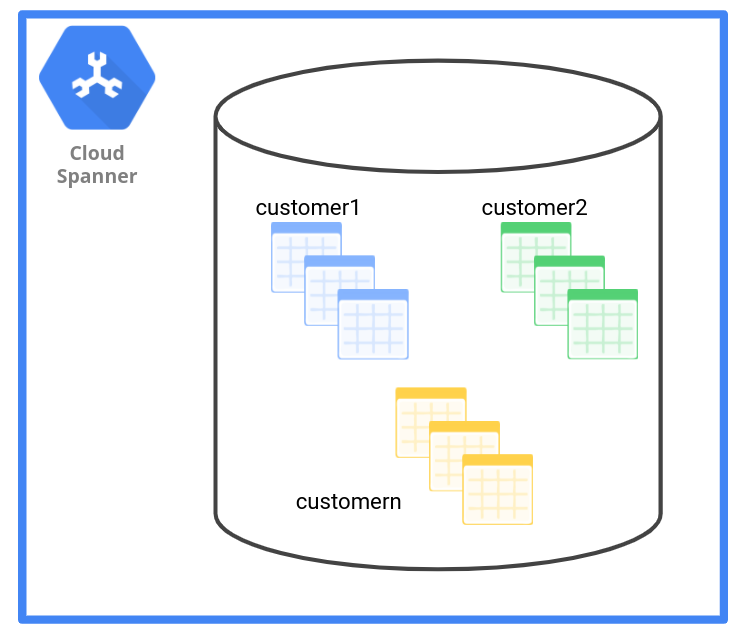
La tabella seguente illustra in che modo il pattern di gestione dei dati dello schema influisce su diversi criteri.
| Criteri | Schema: un insieme di tabelle per ogni pattern di gestione dei dati del tenant |
|---|---|
| Isolamento |
|
| Agilità |
|
| Operazioni |
|
| Scala |
|
| Prestazioni |
|
| Requisiti normativi e di conformità |
|
In sintesi, i punti chiave sono:
- Vantaggio: l'onboarding è semplice
- Svantaggio: maggiore overhead operativo; nessun controllo di sicurezza a livello di tabella
Il pattern di gestione dei dati dello schema è più adatto per i seguenti scenari:
- Applicazioni interne che si rivolgono a diversi reparti in cui l'isolamento rigoroso della sicurezza dei dati non è una preoccupazione importante rispetto alla facilità di manutenzione.
- Applicazioni multi-tenant in cui i dati non richiedono una separazione rigorosa in base a requisiti legali o normativi.
Sebbene sia possibile creare diversi insiemi di tabelle (ogni insieme rappresenta un tenant) in un database, questo è il pattern meno ideale dal punto di vista del database. Il motivo principale è che le tabelle devono rispettare le convenzioni di denominazione. L'applicazione e qualsiasi strumento di database (ad esempio IDE e strumenti di migrazione dello schema) devono comprendere la convenzione di denominazione. Inoltre, se il numero di tabelle è ragionevolmente elevato per tenant, il pattern di gestione dei dati dello schema non offre una scalabilità significativa.
Un approccio migliore consiste nel passare a un database per tenant e aumentare il numero di istanze oppure passare al pattern di gestione dei dati delle tabelle.
Tabella
Il pattern di gestione dei dati finale serve più tenant con un insieme comune di tabelle. Ogni tabella contiene dati per più tenant. Questo pattern di gestione dei dati rappresenta un livello estremo di multitenancy in cui tutto, dall'infrastruttura allo schema al modello di dati, è condiviso tra più tenant. All'interno di una tabella, le righe vengono partizionate in base alle chiavi primarie, con tenant ID come primo elemento della chiave. Dal punto di vista della scalabilità, Spanner supporta al meglio questo pattern perché può scalare le tabelle senza limitazioni.
Per l'applicazione HR, la chiave primaria della tabella del payroll può essere una combinazione di customerID e payrollID.
Come mostrato nel seguente diagramma, il pattern di gestione dei dati della tabella ha una tabella per più tenant.

Come per il pattern dello schema, l'accesso ai dati nel pattern della tabella non può essere controllato separatamente per tenant diversi. Se utilizzi meno tabelle, le operazioni di aggiornamento dello schema vengono completate più rapidamente quando ogni tenant ha le proprie tabelle di database. In larga misura, questo approccio semplifica le operazioni preliminari, di offboarding e di gestione.
La tabella seguente illustra in che modo il pattern di gestione dei dati della tabella influisce su diversi criteri.
| Criteri | Tabella: una tabella per un pattern di gestione dei dati di più tenant |
|---|---|
| Isolamento |
|
| Agilità |
|
| Operazioni |
|
| Scala |
|
| Prestazioni |
|
| Requisiti normativi e di conformità |
|
In sintesi, i punti chiave sono:
- Vantaggio: elevata scalabilità; basso overhead operativo
- Svantaggio: contesa elevata delle risorse; mancanza di controlli di sicurezza per ogni tenant
Questo pattern è più adatto per i seguenti scenari:
- Applicazioni interne destinate a diversi reparti in cui l'isolamento rigoroso della sicurezza dei dati non è una preoccupazione importante rispetto alla facilità di manutenzione.
- Condivisione massima delle risorse per gli utenti che utilizzano la funzionalità dell'applicazione del livello gratuito riducendo al minimo il provisioning delle risorse.
Pattern di gestione dei dati e gestione del ciclo di vita degli utenti
La tabella seguente mette a confronto i vari modelli di gestione dei dati per tutti i criteri a un livello generale.
| Istanza | Database | Schema | Tabella | |
|---|---|---|---|---|
| Isolamento | Completa | Completa | Bassa | Più basso |
| Agilità | Bassa | Moderata | Moderata | Più alto |
| Facilità di utilizzo | Alta | Alta | Bassa | Bassa |
| Scala | Alta | Limited | Potenzialmente molto limitato | Alta |
| Prestazioni* | Alta | Moderata | Moderata | Potenzialmente elevato |
| Regolamenti e conformità | Più alto | Alta | Bassa | Bassa |
* Le prestazioni dipendono molto dalla progettazione dello schema e dalle best practice per le query. I valori riportati sono solo una previsione media.
I modelli di gestione dei dati migliori per un'applicazione multi-tenant specifica sono quelli che soddisfano la maggior parte dei requisiti in base ai criteri. Se un criterio specifico non è obbligatorio, puoi ignorare la riga in cui si trova.
Pattern di gestione dei dati combinati
Spesso, un singolo pattern di gestione dei dati è sufficiente per soddisfare i requisiti di un'applicazione multi-tenant. In questo caso, il design può assumere un unico modello di gestione dei dati.
Tuttavia, alcune applicazioni multi-tenant richiedono contemporaneamente diversi pattern di gestione dei dati, ad esempio un'applicazione multi-tenant che supporta un livello gratuito, un livello standard e un livello enterprise.
Livello gratuito:
- Deve essere conveniente
- Deve avere un limite massimo di volume di dati
- Di solito supporta funzionalità limitate
- Il pattern di gestione dei dati della tabella è un buon candidato per il livello gratuito
- La gestione degli inquilini è semplice
- Non è necessario creare risorse del tenant specifiche o esclusive
Livello normale:
- Ideale per i clienti paganti che non hanno requisiti di isolamento o scalabilità particolarmente stringenti
- Il pattern di gestione dei dati dello schema o il pattern di gestione dei dati del database è un buon candidato per il livello normale
- Le tabelle e gli indici sono esclusivi per l'utente proprietario
- Il backup è facile nel pattern di gestione dei dati del database
- Il backup non è supportato per il pattern di gestione dei dati dello schema
- Il backup del tenant deve essere implementato come utilità al di fuori di Spanner
Livello Enterprise:
- Di solito un livello di fascia alta con piena autonomia in tutti gli aspetti
- L'utente dispone di risorse dedicate che includono l'isolamento completo e la scalabilità dedicata
- Il pattern di gestione dei dati delle istanze è adatto al livello enterprise
Una best practice consiste nel mantenere pattern di gestione dei dati diversi in database diversi. Sebbene sia possibile combinare diversi pattern di gestione dei dati in un database Spanner, questa operazione rende difficile implementare la logica di accesso e le operazioni del ciclo di vita dell'applicazione.
La sezione Design dell'applicazione illustra alcune considerazioni sul design delle applicazioni multi-tenant che si applicano quando si utilizza un singolo pattern di gestione dei dati o più pattern di gestione dei dati.
Gestire il ciclo di vita del tenant
Gli utenti hanno un ciclo di vita. Pertanto, devi implementare le operazioni di gestione corrispondenti all'interno della tua applicazione multi-tenant. Oltre alle operazioni di base di creazione, aggiornamento ed eliminazione degli tenant, prendi in considerazione le seguenti operazioni aggiuntive relative ai dati:
Esportare i dati del tenant:
- Quando elimini un tenant, è buona prassi esportarne prima i dati ed eventualmente renderli disponibili per l'utente.
- Quando utilizzi il pattern di gestione dei dati della tabella o dello schema, il sistema di applicazioni multi-tenant deve implementare l'esportazione o mapparla alla funzionalità del database (esportazione del database).
Esegui il backup dei dati del tenant:
- Quando utilizzi il pattern di gestione dei dati dell'istanza o del database e esegui il backup dei dati per i singoli tenant, utilizza le funzioni di esportazione o di backup del database.
- Quando utilizzi il pattern di gestione dei dati dello schema o della tabella e esegui il backup dei dati per i singoli tenant, l'applicazione multi-tenant deve implementare questa operazione. Il database Spanner non è in grado di determinare quali dati appartengono a quale tenant.
Sposta i dati del tenant:
Lo spostamento di un tenant da un pattern di gestione dei dati a un altro (o lo spostamento di un tenant all'interno dello stesso pattern di gestione dei dati tra istanze o database) richiede l'estrazione dei dati dal pattern di gestione dei dati della tabella e il loro inserimento nel pattern di gestione dei dati del database.
- Quando è possibile un tempo di riposo dell'applicazione, esegui un'esportazione/importazione.
- Quando non è possibile il tempo di riposo, esegui una migrazione del database senza tempi di riposo.
Risolvere una situazione di vicini rumorosi è un altro motivo per cambiare inquilino.
Progettazione dell'applicazione
Quando progetti un'applicazione multi-tenant, implementa la logica di business consapevole del tenant. Ciò significa che ogni volta che l'applicazione esegue la logica di business, deve sempre essere nel contesto di un tenant noto.
Dal punto di vista del database, la progettazione dell'applicazione significa che ogni query deve essere eseguita in base al modello di gestione dei dati in cui risiede il tenant. Le sezioni seguenti mettono in evidenza alcuni dei concetti centrali della progettazione di applicazioni multi-tenant.
Connessione e configurazione delle query dei tenant dinamici
La mappatura dinamica dei dati del tenant alle richieste dell'applicazione del tenant utilizza una configurazione di mappatura:
- Per i pattern di gestione dei dati di database o di gestione dei dati delle istanze, è sufficiente una stringa di connessione per accedere ai dati di un tenant.
- Per i pattern di gestione dei dati dello schema, devono essere determinati i nomi delle tabelle corretti.
- Per i pattern di gestione dei dati delle tabelle, le query devono essere eseguite sul database. Utilizza i predicati appropriati per recuperare i dati di un tenant specifico.
Un tenant può trovarsi in uno dei quattro pattern di gestione dei dati. La seguente implementazione di mappatura riguarda una configurazione di connessione per il caso generale di un'applicazione multi-tenant che utilizza contemporaneamente tutti i pattern di gestione dei dati. Quando un determinato tenant si trova in un pattern, alcune applicazioni multi-tenant utilizzano un pattern di gestione dei dati per tutti i tenant. Questo caso è covered implicitly dalla seguente mappatura.
Se un tenant esegue la logica di business (ad esempio, un dipendente che accede con il proprio ID tenant), la logica di applicazione deve determinare il pattern di gestione dei dati del tenant, la posizione dei dati per un determinato ID tenant e, facoltativamente, la convenzione di denominazione delle tabelle (per il pattern dello schema).
Questa logica di applicazione richiede la mappatura dei pattern di gestione dei dati per tenant. Nel
seguente esempio di codice, connection string fa riferimento al database in cui si trovano
i dati del tenant. Il sample identifica l'istanza Spanner e il database. Per l'istanza e il database del pattern di gestione dei dati, il seguente codice è sufficiente per consentire all'applicazione di connettersi ed eseguire query:
tenant id -> (data management pattern,
database connection string,
[table_prefix])
È necessaria una progettazione aggiuntiva per i pattern di gestione dei dati dello schema e delle tabelle.
Pattern di gestione dei dati dello schema
Per il pattern di gestione dei dati dello schema, esistono diversi tenant all'interno dello stesso database. Ogni tenant ha il proprio set di tabelle. Le tabelle sono distintae dal nome. L'appartenenza di una tabella a un tenant è deterministica.
Un approccio è anteporre ai nomi delle tabelle l'ID tenant. Ad esempio, la tabella EMPLOYEE si chiama T356_EMPLOYEE per il tenant con ID 356. L'applicazione deve anteporre a ogni tabella il prefissoTtenant ID prima di inviare la query al database restituito dalla mappatura.
Un altro approccio consiste nell'anteporre un table_prefix alla mappatura utilizzata dalla query in modo da trovare le tabelle corrette per un tenant.
È possibile anche un approccio misto: se il pattern di gestione dei dati è il pattern dello schema e il prefisso della tabella è vuoto, viene eseguita la mappatura predefinita (precede i nomi delle tabelle con gli ID tenant).
Pattern di gestione dei dati delle tabelle
È necessario un design simile per il pattern di gestione dei dati della tabella. In questo pattern, è presente un unico schema. I dati dell'utente vengono archiviati come righe. Per accedere correttamente ai dati, aggiungi un predicato a ogni query per selezionare il tenant appropriato.
Un approccio per trovare il tenant appropriato è avere una colonna denominata TENANT
in ogni tabella. Il valore della colonna è tenant ID. Ogni query deve aggiungere un
predicato AND TENANT = tenant ID a una clausola WHERE esistente o aggiungere una
clausola WHERE con il predicato AND TENANT = tenant ID.
Per connetterti al database e creare le query appropriate, l'identificatore del tenant deve essere disponibile nella logica dell'applicazione. Può essere passato come parametro o memorizzato come contesto del thread.
Alcune operazioni del ciclo di vita richiedono la modifica della configurazione della mappatura del tenant al pattern di gestione dei dati. Ad esempio, quando sposti un tenant da un pattern di gestione dei dati a un altro, devi aggiornare il pattern di gestione dei dati e la stringa di connessione al database. Potresti anche dover aggiornare il prefisso della tabella.
Generazione di query e attribuzione
Un principio fondamentale alla base delle applicazioni multi-tenant è che diversi tenant possono condividere una singola risorsa cloud. I pattern di gestione dei dati precedenti rientrano in questa categoria, tranne nel caso in cui un singolo tenant sia allocato a una singola istanza Spanner.
La condivisione delle risorse va oltre la condivisione dei dati. Anche il monitoraggio e la registrazione sono condivisi: ad esempio, nel pattern di gestione dei dati delle tabelle e nel pattern di gestione dei dati dello schema, tutte le query per tutti gli tenant vengono registrate nello stesso log di controllo.
Se viene registrato un log di una query, il testo della query deve essere esaminato per determinare per quale tenant è stata eseguita. Nel pattern di gestione dei dati della tabella, devi analizzare il predicato. Nel pattern di gestione dei dati dello schema, devi analizzare uno dei nomi delle tabelle.
Nel pattern di gestione dei dati del database o nel pattern di gestione dei dati dell'istanza, il testo della query non contiene informazioni sull'utente. Per ottenere informazioni sul tenant per questi pattern, devi eseguire una query sulla tabella di mappatura dei pattern di gestione dei dati per tenant.
Sarebbe più facile analizzare i log e le query determinando l'tenant per una determinata query senza analizzare il testo della query. Un modo per identificare in modo uniforme un tenant per una query in tutti i pattern di gestione dei dati è aggiungere un commento al testo della query contenente tenant ID e, facoltativamente, label.
La seguente query seleziona tutti i dati dei dipendenti per il tenant identificato da
TENANT 356. Per evitare di analizzare la sintassi SQL ed estrarre l'ID tenant dal
predicato, l'ID tenant viene aggiunto come commento. Un commento può essere estratto
senza dover analizzare la sintassi SQL.
select * from EMPLOYEE
-- TENANT 356
where TENANT = 'T356';
o
select * from T356_EMPLOYEE;
-- TENANT 356
Con questo design, ogni query eseguita per un tenant viene attribuita a quel tenant indipendente dal pattern di gestione dei dati. Se un tenant viene spostato da un modello di gestione dei dati a un altro, il testo della query potrebbe cambiare, ma l'attribuzione rimane invariata nel testo della query.
L'esempio di codice precedente è solo un metodo. Un altro metodo consiste nell'inserire un oggetto JSON come commento anziché come etichetta e valore:
select * from T356_EMPLOYEE;
-- {"TENANT": 356}
Operazioni del ciclo di vita dell'accesso dei tenant
A seconda della filosofia di progettazione, un'applicazione multi-tenant può implementare direttamente le operazioni del ciclo di vita dei dati descritte in precedenza oppure creare uno strumento di amministrazione del tenant separato.
Indipendentemente dalla strategia di implementazione, le operazioni del ciclo di vita potrebbero dover essere eseguite senza l'esecuzione simultanea della logica di applicazione. Ad esempio, durante lo spostamento di un tenant da un modello di gestione dei dati a un altro, la logica di applicazione non può essere eseguita perché i dati non si trovano in un unico database. Quando i dati non si trovano in un unico database, richiedono due operazioni aggiuntive dal punto di vista dell'applicazione:
- Arrestare un tenant:disattiva tutto l'accesso alla logica dell'applicazione, consentendo al contempo le operazioni del ciclo di vita dei dati.
- Avvio di un tenant: la logica dell'applicazione può accedere ai dati di un tenant mentre le operazioni di ciclo di vita che potrebbero interferire con la logica dell'applicazione sono disattivate.
Sebbene non venga utilizzata spesso, un'interruzione del tenant di emergenza potrebbe essere un'altra importante operazione di ciclo di vita. Utilizza questa interruzione quando sospetti una violazione e devi vietare tutto l'accesso ai dati di un tenant, non solo alla logica dell'applicazione, ma anche alle operazioni del ciclo di vita. Una violazione può provenire dall'interno o dall'esterno del database.
Deve essere disponibile anche un'operazione del ciclo di vita corrispondente che rimuove lo stato di emergenza. Un'operazione di questo tipo può richiedere l'accesso contemporaneamente di due o più amministratori per implementare il controllo reciproco.
Isolamento delle applicazioni
I vari pattern di gestione dei dati supportano diversi gradi di isolamento dei dati del tenant. Dal livello più isolato (istanza) al livello meno isolato (tabella), sono possibili diversi gradi di isolamento.
Nel contesto di un'applicazione multi-tenant, deve essere presa una decisione di implementazione simile: tutti i tenant accedono ai propri dati (in modelli di gestione dei dati eventualmente diversi) utilizzando lo stesso deployment dell'applicazione? Ad esempio, un singolo cluster Kubernetes potrebbe supportare tutti i tenant e, quando un tenant accede ai propri dati, lo stesso cluster esegue la logica di business.
In alternativa, come nel caso dei pattern di gestione dei dati, diversi tenant potrebbero essere indirizzati a diversi deployment delle applicazioni. I tenant di grandi dimensioni potrebbero avere accesso a un deployment dell'applicazione esclusivo, mentre i tenant più piccoli o quelli del livello gratuito condividono un deployment dell'applicazione.
Anziché associare direttamente gli schemi di gestione dei dati discussi in questo articolo a schemi di gestione dei dati delle applicazioni equivalenti, puoi utilizzare lo schema di gestione dei dati del database in modo che tutti i tenant condividano un unico deployment dell'applicazione. È possibile avere il pattern di gestione dei dati del database e tutti questi tenant condividono un singolo deployment dell'applicazione.
La multitenancy è un importante pattern di gestione dei dati e del design delle applicazioni, soprattutto quando l'efficienza delle risorse svolge un ruolo fondamentale. Spanner supporta diversi pattern di gestione dei dati. Utilizzalo per implementare applicazioni multi-tenant. Grazie alla scalabilità estrema e agli SLA rigorosi di Spanner, si tratta di un database ideale per i deployment di applicazioni multi-tenant di grandi dimensioni.
Passaggi successivi
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.