Neste tutorial, demonstramos como fazer streaming de novos objetos de um bucket do Cloud Storage para o BigQuery usando o Cloud Functions. O Cloud Functions é uma plataforma de computação sem servidor e orientada a eventos do Google Cloud, que fornece escalonamento automático, alta disponibilidade e tolerância a falhas sem servidores para provisionar, gerenciar, atualizar ou corrigir. Faça streaming de dados com o Cloud Functions para permitir que você se conecte e estenda outros serviços do Google Cloud pagando apenas quando o app estiver em execução.
Este artigo é voltado para analistas de dados, desenvolvedores ou operadores que precisam executar análises quase em tempo real em arquivos adicionados ao Cloud Storage. Para acompanhar este artigo, é necessário ter familiaridade com o Linux, o Cloud Storage e o BigQuery.
Arquitetura
O diagrama da arquitetura a seguir ilustra todos os componentes e todo o fluxo do pipeline de streaming deste tutorial. Para esse pipeline, você precisa fazer upload de arquivos JSON no Cloud Storage, mas pequenas mudanças no código são necessárias para oferecer suporte a outros formatos de arquivo. O processamento de outros formatos de arquivo não é abordado neste artigo.

No diagrama anterior, o pipeline consiste nas seguintes etapas:
- Os arquivos JSON são enviados para o bucket
FILES_SOURCEdo Cloud Storage. - Este evento aciona a Função do Cloud
streaming. - Os dados são analisados e inseridos no BigQuery.
- O status do processamento é registrado no Firestore e no Cloud Logging.
- Uma mensagem é publicada em um dos seguintes tópicos do
Pub/Sub:
streaming_success_topicstreaming_error_topic
- Dependendo dos resultados, o Cloud Functions move o arquivo JSON
do bucket
FILES_SOURCEpara um destes:FILES_ERRORFILES_SUCCESS
Objetivos
- Criar um bucket do Cloud Storage para armazenar os arquivos JSON.
- Criar um conjunto de dados e uma tabela do BigQuery para fazer streaming dos dados.
- Configurar uma Função do Cloud a ser acionada sempre que os arquivos forem adicionados ao bucket.
- Configurar tópicos do Pub/Sub.
- Configurar mais funções para processar a saída da função.
- Testar o pipeline de streaming.
- Configurar o Cloud Monitoring para alertar sobre comportamentos inesperados.
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
- Cloud Storage
- Cloud Functions
- Firestore
- BigQuery
- Logging
- Monitoring
- Container Registry
- Cloud Build
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Functions and Cloud Build APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Functions and Cloud Build APIs.
- No console do Google Cloud, acesse o Monitoring.
Ao concluir as tarefas descritas neste documento, é possível evitar o faturamento contínuo excluindo os recursos criados. Saiba mais em Limpeza.
Como configurar o ambiente
Neste tutorial, use o Cloud Shell para inserir comandos. O Cloud Shell fornece acesso à linha de comando no Console do Cloud e inclui a Google Cloud CLI e outras ferramentas que precisam ser desenvolvidas no Google Cloud. O Cloud Shell aparece como uma janela na parte inferior do Console do Google Cloud. A inicialização leva vários minutos, mas a janela aparece imediatamente.
Para usar o Cloud Shell a fim de configurar o ambiente e clonar o repositório git usado neste tutorial:
No Console do Google Cloud, abra o Cloud Shell.
Verifique se está trabalhando no projeto recém-criado. Substitua
[YOUR_PROJECT_ID]pelo projeto do Google Cloud recém-criado.gcloud config set project [YOUR_PROJECT_ID]Defina a zona do Compute padrão. Para os fins deste tutorial, use
us-east1. Se você estiver implantando em um ambiente de produção, implante em uma região de sua escolha.REGION=us-east1Clone o repositório que contém as funções usadas neste tutorial.
git clone https://github.com/GoogleCloudPlatform/solutions-gcs-bq-streaming-functions-python cd solutions-gcs-bq-streaming-functions-python
Como criar coletores de origem e destino de streaming
Para fazer streaming de conteúdo para o BigQuery, você precisa ter um bucket do Cloud Storage FILES_SOURCE e uma tabela de destino no BigQuery.
Criar o bucket do Cloud Storage
Crie um bucket do Cloud Storage que representa a origem do canal de streaming apresentado neste tutorial. A meta principal desse bucket é armazenar temporariamente arquivos JSON transmitidos por streaming ao BigQuery.
Crie o bucket do Cloud Storage
FILES_SOURCE, em queFILES_SOURCEé configurado como uma variável de ambiente com um nome exclusivo.FILES_SOURCE=${DEVSHELL_PROJECT_ID}-files-source-$(date +%s) gsutil mb -c regional -l ${REGION} gs://${FILES_SOURCE}
Criar a tabela do BigQuery
Esta seção cria uma tabela do BigQuery usada como o destino de conteúdo para os arquivos. O BigQuery permite especificar o esquema da tabela quando você carrega dados na tabela ou cria uma nova tabela. Nesta seção, crie a tabela e especifique o esquema simultaneamente.
Crie um conjunto de dados e uma tabela do BigQuery. O esquema definido no arquivo
schema.jsonprecisa corresponder ao esquema dos arquivos provenientes do bucketFILES_SOURCE.bq mk mydataset bq mk mydataset.mytable schema.jsonVerifique se a tabela foi criada.
bq ls --format=pretty mydatasetA saída é:
+---------+-------+--------+-------------------+ | tableId | Type | Labels | Time Partitioning | +---------+-------+--------+-------------------+ | mytable | TABLE | | | +---------+-------+--------+-------------------+
Como fazer streaming de dados para o BigQuery
Agora que você criou os coletores de origem e de destino, crie a Função do Cloud para fazer streaming de dados do Cloud Storage para o BigQuery.
Configurar a Função do Cloud de streaming
A função de streaming detecta novos arquivos adicionados ao bucket FILES_SOURCE e aciona um processo que realiza estas ações:
- Analisa e valida o arquivo.
- Verifica se há duplicações.
- Insere o conteúdo do arquivo no BigQuery.
- Registra o status de ingestão no Firestore e no Logging.
- Publica uma mensagem em um tópico de erro ou de êxito no Pub/Sub.
Para implantar a função:
Crie um bucket do Cloud Storage para organizar as funções durante a implantação, em que
FUNCTIONS_BUCKETseja configurado como variável de ambiente com um nome exclusivo.FUNCTIONS_BUCKET=${DEVSHELL_PROJECT_ID}-functions-$(date +%s) gsutil mb -c regional -l ${REGION} gs://${FUNCTIONS_BUCKET}Implante a função
streaming. O código de implementação está na pasta./functions/streaming. Isso pode demorar alguns minutos.gcloud functions deploy streaming --region=${REGION} \ --source=./functions/streaming --runtime=python37 \ --stage-bucket=${FUNCTIONS_BUCKET} \ --trigger-bucket=${FILES_SOURCE}Esse código implanta uma Função do Cloud escrita em Python, denominada
streaming. Ela é acionada sempre que um arquivo é adicionado ao bucketFILES_SOURCE.Verifique se a função foi implantada.
gcloud functions describe streaming --region=${REGION} \ --format="table[box](entryPoint, status, eventTrigger.eventType)"A saída é:
┌────────────────┬────────┬────────────────────────────────┐ │ ENTRY_POINT │ STATUS │ EVENT_TYPE │ ├────────────────┼────────┼────────────────────────────────┤ │ streaming │ ACTIVE │ google.storage.object.finalize │ └────────────────┴────────┴────────────────────────────────┘
Provisione um tópico do Pub/Sub, chamado
streaming_error_topic, para lidar com o caminho do erro.STREAMING_ERROR_TOPIC=streaming_error_topic gcloud pubsub topics create ${STREAMING_ERROR_TOPIC}Provisione um tópico do Pub/Sub, chamado
streaming_success_topic, para lidar com o caminho bem-sucedido.STREAMING_SUCCESS_TOPIC=streaming_success_topic gcloud pubsub topics create ${STREAMING_SUCCESS_TOPIC}
Configurar o banco de dados do Firestore
Durante a transmissão dos dados para o BigQuery, é importante entender o que está acontecendo com a ingestão de cada arquivo. Por exemplo, suponhamos que você tenha arquivos importados incorretamente. Nesse caso, você precisa descobrir a causa principal do problema e corrigi-lo para evitar gerar dados corrompidos e relatórios imprecisos ao final do pipeline. A função streaming, implantada na seção anterior, armazena o status de processamento de arquivos em documentos do Firestore para que seja possível consultar erros recentes para resolver problemas.
Para criar a instância do Firestore, siga estas etapas:
No Console do Google Cloud, acesse o Firestore.
Na janela Escolha um modo do Cloud Firestore, clique em Selecionar modo nativo.
Na lista Selecionar um local, selecione nam5 (Estados Unidos) e clique em Criar banco de dados. Aguarde a conclusão da inicialização do Firestore. Isso normalmente demora alguns minutos.
Manipular erros de streaming
Para provisionar um caminho que manipule arquivos de erro, implante outra Função do Cloud, que escute mensagens publicadas em streaming_error_topic. A empresa precisa determinar como você manipula esses erros em um ambiente de produção.
Para os fins deste tutorial, os arquivos problemáticos são movidos para outro bucket do Cloud Storage a fim de facilitar a solução de problemas.
Crie o bucket do Cloud Storage para armazenar arquivos problemáticos.
FILES_ERRORé configurado como uma variável de ambiente com um nome exclusivo para o bucket que armazena arquivos de erro.FILES_ERROR=${DEVSHELL_PROJECT_ID}-files-error-$(date +%s) gsutil mb -c regional -l ${REGION} gs://${FILES_ERROR}Implemente a função
streaming_errorpara manipular erros. Isso pode demorar alguns minutos.gcloud functions deploy streaming_error --region=${REGION} \ --source=./functions/move_file \ --entry-point=move_file --runtime=python37 \ --stage-bucket=${FUNCTIONS_BUCKET} \ --trigger-topic=${STREAMING_ERROR_TOPIC} \ --set-env-vars SOURCE_BUCKET=${FILES_SOURCE},DESTINATION_BUCKET=${FILES_ERROR}Esse comando é semelhante ao comando que implanta a função
streaming. A diferença principal é que, nesse comando, a função é acionada por uma mensagem publicada em um tópico e recebe duas variáveis de ambiente:SOURCE_BUCKET, de onde arquivos são copiados, eDESTINATION_BUCKET, para onde os arquivos são copiados.Verifique se a função
streaming_errorfoi criada.gcloud functions describe streaming_error --region=${REGION} \ --format="table[box](entryPoint, status, eventTrigger.eventType)"A saída é:
┌─────────────┬────────┬─────────────────────────────┐ │ ENTRY_POINT │ STATUS │ EVENT_TYPE │ ├─────────────┼────────┼─────────────────────────────┤ │ move_file │ ACTIVE │ google.pubsub.topic.publish │ └─────────────┴────────┴─────────────────────────────┘
Manipular streaming bem-sucedido
Para provisionar um caminho que manipule arquivos de sucesso, implante uma terceira Função do Cloud, que escuta mensagens publicadas em streaming_success_topic. Para os fins deste tutorial, os arquivos ingeridos com êxito são arquivados em um bucket do Coldline Cloud Storage.
Crie seu bucket do Coldline Cloud Storage.
FILES_SUCCESSé configurado como variável de ambiente com um nome exclusivo para o bloco que armazena arquivos de sucesso.FILES_SUCCESS=${DEVSHELL_PROJECT_ID}-files-success-$(date +%s) gsutil mb -c coldline -l ${REGION} gs://${FILES_SUCCESS}Implante a função
streaming_successpara manipular o sucesso. Isso pode demorar alguns minutos.gcloud functions deploy streaming_success --region=${REGION} \ --source=./functions/move_file \ --entry-point=move_file --runtime=python37 \ --stage-bucket=${FUNCTIONS_BUCKET} \ --trigger-topic=${STREAMING_SUCCESS_TOPIC} \ --set-env-vars SOURCE_BUCKET=${FILES_SOURCE},DESTINATION_BUCKET=${FILES_SUCCESS}Verifique se a função foi criada.
gcloud functions describe streaming_success --region=${REGION} \ --format="table[box](entryPoint, status, eventTrigger.eventType)"A saída é:
┌─────────────┬────────┬─────────────────────────────┐ │ ENTRY_POINT │ STATUS │ EVENT_TYPE │ ├─────────────┼────────┼─────────────────────────────┤ │ move_file │ ACTIVE │ google.pubsub.topic.publish │ └─────────────┴────────┴─────────────────────────────┘
Como testar o canal de streaming
Neste ponto, você terminou de criar o canal de streaming. Agora é hora de testar caminhos diferentes. Primeiro, você testa a ingestão de novos arquivos, depois de arquivos de duplicação e, por fim, de arquivos problemáticos.
Ingerir novos arquivos
Para testar a ingestão de novos arquivos, faça upload de um arquivo que precisa passar por todo o pipeline com êxito. Para garantir que tudo esteja funcionando corretamente, você precisa verificar todos os blocos de armazenamento: BigQuery, Firestore e buckets do Cloud Storage.
Faça upload do arquivo
data.jsonno bucketFILES_SOURCE.gsutil cp test_files/data.json gs://${FILES_SOURCE}A saída:
Operation completed over 1 objects/312.0 B.
Consulte os dados no BigQuery.
bq query 'select first_name, last_name, dob from mydataset.mytable'A resposta a este comando é o conteúdo do arquivo
data.json:+------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | +------------+-----------+------------+
No Console do Google Cloud, acesse a página Firestore.
Acesse o documento / > streaming_files > data.json para verificar se o campo success: true está lá. A função
streamingarmazena o status do arquivo em uma coleção denominada streaming_files e usa o nome do arquivo como ID do documento.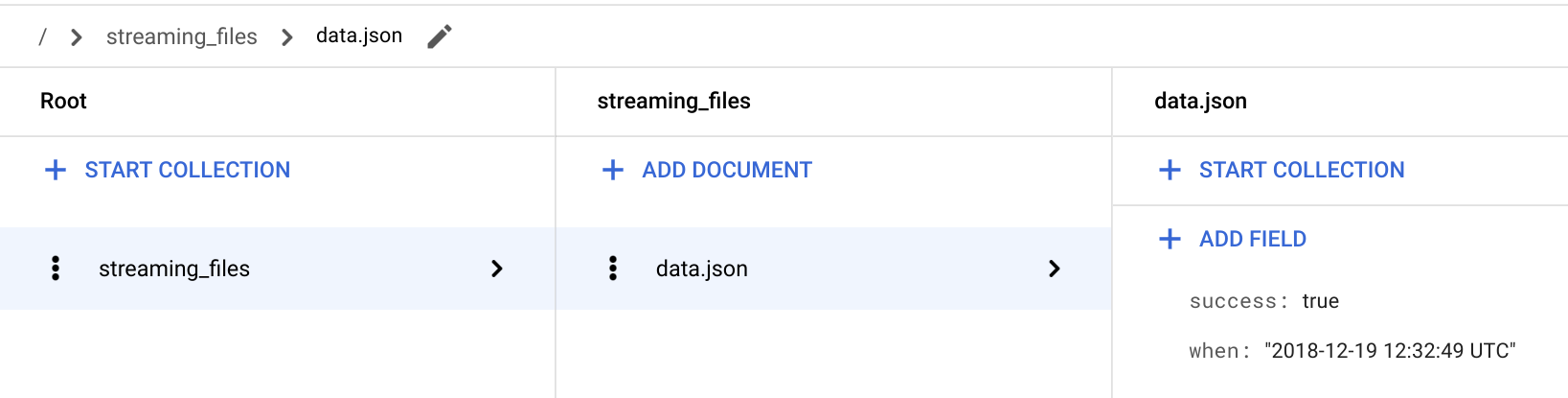
Volte para o Cloud Shell.
Verifique se o arquivo ingerido foi removido do bucket
FILES_SOURCEpela funçãostreaming_success.gsutil ls -l gs://${FILES_SOURCE}/data.jsonA saída é um
CommandExceptionporque o arquivo não existe mais no bucketFILES_SOURCE.Verifique se o arquivo ingerido agora está no bucket
FILES_SUCCESS.gsutil ls -l gs://${FILES_SUCCESS}/data.jsonA saída é:
TOTAL: 1 objects, 312 bytes.
Ingerir arquivos já processados
O nome do arquivo é usado como código do documento no Firestore. Isso facilitará a consulta da função streamingstreaming se um determinado arquivo tiver sido processado ou não.
Se um arquivo tiver sido ingerido anteriormente, todas as novas tentativas de adicioná-lo serão ignoradas porque isso duplicaria as informações no BigQuery e geraria relatórios imprecisos.
Nesta seção, você verifica se o pipeline está funcionando conforme esperado quando arquivos duplicados são enviados para o bucket FILES_SOURCE.
Faça o upload do mesmo arquivo
data.jsonpara o bucketFILES_SOURCEnovamente.gsutil cp test_files/data.json gs://${FILES_SOURCE}A saída é:
Operation completed over 1 objects/312.0 B.
A consulta ao BigQuery retorna o mesmo resultado de antes. Isso significa que o canal processou o arquivo, mas não inseriu o conteúdo no BigQuery porque ele foi ingerido antes.
bq query 'select first_name, last_name, dob from mydataset.mytable'A saída é:
+------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | +------------+-----------+------------+
No console do Google Cloud, acesse a página do Firestore.
No documento / > streaming_files > data.json, verifique se o novo campo
**duplication_attempts**foi adicionado.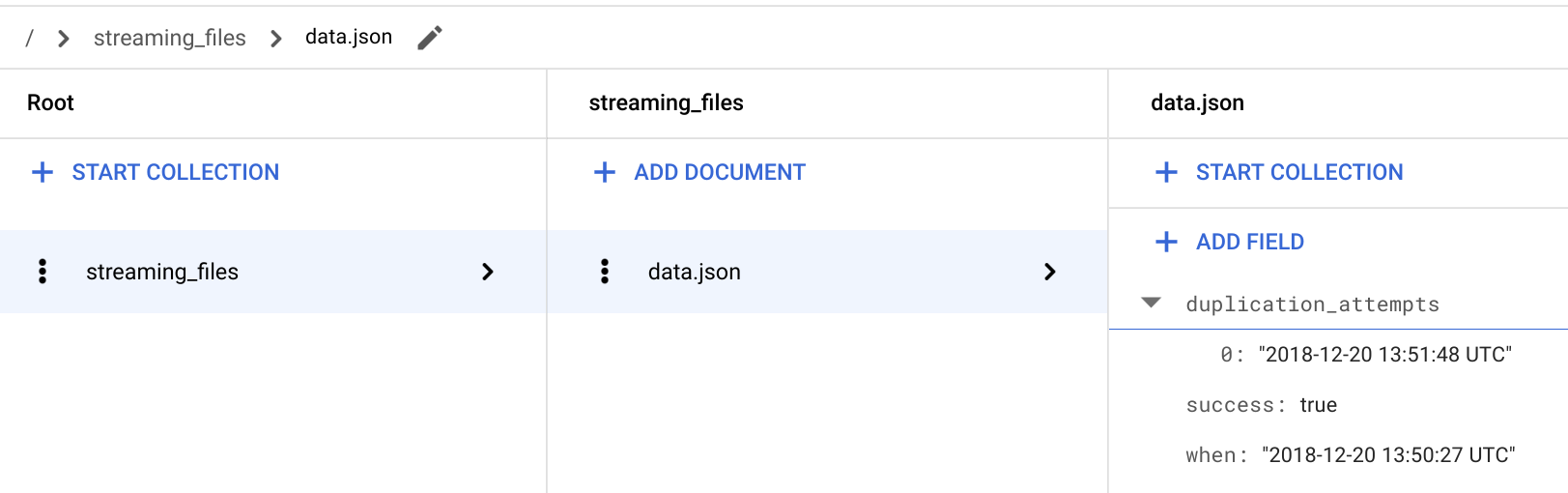
Sempre que um arquivo é adicionado ao bucket
FILES_SOURCEcom o mesmo nome de um que já foi processado, o conteúdo do arquivo é ignorado e uma nova tentativa de duplicação é anexada ao campo**duplication_attempts**no Firestore.Volte para o Cloud Shell.
Verifique se o arquivo duplicado ainda está no bucket
FILES_SOURCE.gsutil ls -l gs://${FILES_SOURCE}/data.jsonA saída é:
TOTAL: 1 objects, 312 bytes.
No cenário de duplicação, a função
streamingregistra o comportamento inesperado no Logging, ignora a ingestão e deixa o arquivo no bucketFILES_SOURCEpara análise posterior.
Ingerir arquivos com erros
Agora que você confirmou que o pipeline de streaming está funcionando e que duplicações não são ingeridas no BigQuery, é hora de verificar o caminho do erro.
Faça upload de
data_error.jsonpara o bucketFILES_SOURCE.gsutil cp test_files/data_error.json gs://${FILES_SOURCE}A saída é:
Operation completed over 1 objects/311.0 B.
A consulta ao BigQuery retorna o mesmo resultado de antes. Isso significa que o pipeline processou o arquivo, mas não inseriu o conteúdo no BigQuery porque ele não obedece ao esquema esperado.
bq query 'select first_name, last_name, dob from mydataset.mytable'A saída é:
+------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | +------------+-----------+------------+
No Console do Google Cloud, acesse a página Firestore.
No documento / > streaming_files > data_error.json, verifique se o campo success: false está adicionado.
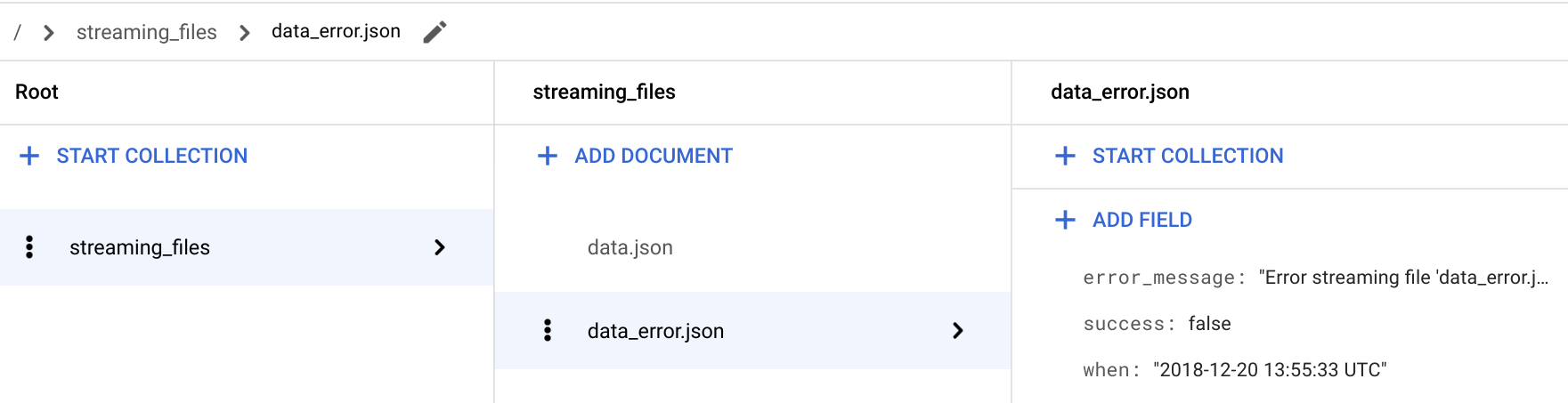
Para arquivos com erros, a função
streamingtambém armazena um campoerror_message, que fornece informações detalhadas sobre a não ingestão do arquivo.Volte para o Cloud Shell.
Verifique se o arquivo foi removido do bucket
FILES_SOURCEpela funçãostreaming_error.gsutil ls -l gs://${FILES_SOURCE}/data_error.jsonA saída é um
CommandExceptionporque o arquivo não existe mais no bucketFILES_SOURCE.Verifique se o arquivo já está no bucket
FILES_ERROR, conforme esperado.gsutil ls -l gs://${FILES_ERROR}/data_error.jsonA saída é:
TOTAL: 1 objects, 311 bytes.
Encontrar e corrigir problemas de ingestão de dados
A execução de consultas na coleção streaming_files no Cloud Firestore permite diagnosticar e corrigir problemas rapidamente. Nesta seção, você filtra todos os arquivos de erro usando a API Python padrão para Firestore(em inglês).
Para ver os resultados da consulta no ambiente:
Crie um ambiente virtual na pasta
firestore.pip install virtualenv virtualenv firestore source firestore/bin/activateInstale o módulo Python Firestore no ambiente virtual.
pip install google-cloud-firestoreVisualize os problemas de pipeline atuais.
python firestore/show_streaming_errors.pyO arquivo
show_streaming_errors.pycontém a consulta do Firestore e outro padrão para repetir o resultado e formatar o resultado. Depois que você executa o comando anterior, a saída é semelhante a:+-----------------+-------------------------+----------------------------------------------------------------------------------+ | File Name | When | Error Message | +-----------------+-------------------------+----------------------------------------------------------------------------------+ | data_error.json | 2019-01-22 11:31:58 UTC | Error streaming file 'data_error.json'. Cause: Traceback (most recent call las.. | +-----------------+-------------------------+----------------------------------------------------------------------------------+
Desative o ambiente virtual quando você terminar a análise.
deactivateDepois de encontrar e corrigir os arquivos problemáticos, refaça o upload deles no bucket
FILES_SOURCEcom o mesmo nome de arquivo. Esse processo faz com que eles passem por todo o pipeline de streaming para inserir o conteúdo no BigQuery.
Alerta sobre comportamentos inesperados
Em ambientes de produção, é importante monitorar e alertar sempre que acontece algo estranho. Um dos muitos recursos do Logging são métricas personalizadas. As métricas personalizadas permitem criar políticas de alerta para notificar você e a equipe quando a métrica atender aos critérios especificados.
Nesta seção, você configura o Monitoring para enviar alertas por e-mail sempre que uma ingestão de arquivo falhar. Para identificar uma ingestão com falha, a seguinte configuração usa as mensagens Python logging.error(..) padrão.
No console do Google Cloud, acesse a página de métricas com base em registros.
Clique em Criar métrica.
Na lista Filtro, selecione Converter em filtro avançado.
No filtro avançado, cole a configuração a seguir.
resource.type="cloud_function" resource.labels.function_name="streaming" resource.labels.region="us-east1" "Error streaming file "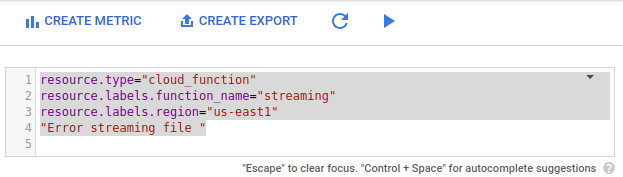
No Editor de métricas, preencha os campos a seguir e clique em Criar métrica.
- No campo Nome, use
streaming-error. - Na seção Rótulo, insira
payload_errorno campo Nome. - Na lista Tipo de rótulo, selecione String.
- Na lista Nome do campo, selecione textPayload.
- No campo Expressão regular de extração, insira
(Error streaming file '.*'.). Na lista Tipo, selecione Contador.
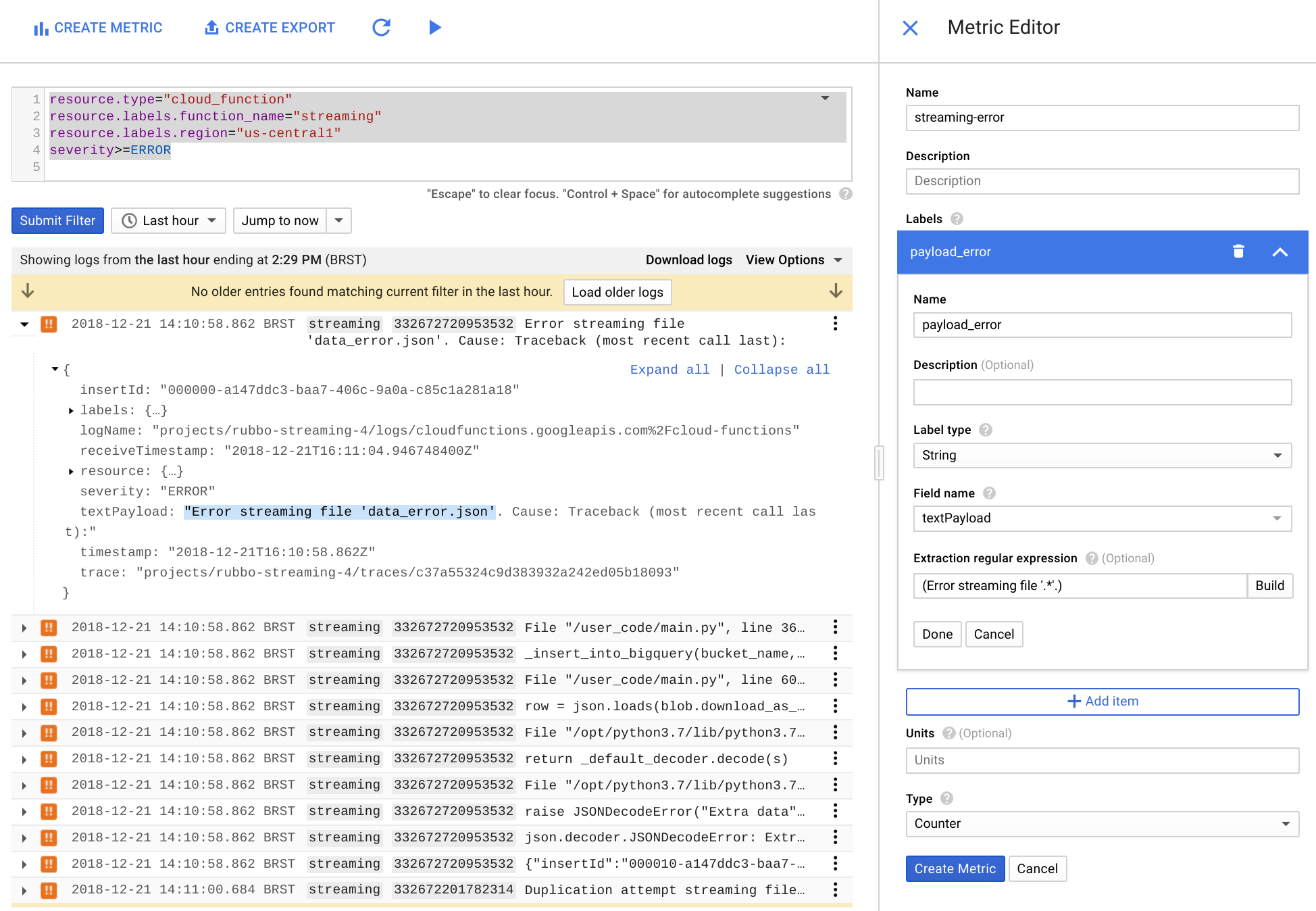
- No campo Nome, use
No Console do Google Cloud, acesse Monitoring ou use o seguinte botão:
No painel de navegação do Monitoring, selecione notificationsComo alertar e selecione Criar política.
No campo Nomear esta política, insira
streaming-error-alert.Clique em Adicionar condição:
- No campo Título, insira
streaming-error-condition. - No campo Métrica, insira
logging/user/streaming-error. - Na lista Acionador da condição, selecione Qualquer violação de série temporal.
- Na lista Condição, selecione está acima.
- No campo Limite, insira
0. - Na lista Por, selecione 1 minuto.
- No campo Título, insira
Na lista Tipo de canal de notificação, selecione E-mail, insira o endereço de e-mail e clique em Adicionar canal de notificação.
(Opcional) Clique no campo de texto em Documento e inclua as informações que você quer que estejam presentes em uma mensagem de notificação.
Clique em Salvar.
Depois que você salva a política de alertas, o Monitoring monitora os registros de erro da função streaming e envia um alerta por e-mail sempre que há erros de streaming durante um intervalo de um minuto.
Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Exclua o projeto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Revise Eventos e gatilhos para aprender outras maneiras de acionar uma função sem servidor no Google Cloud.
- Acesse a página de alertas para saber como melhorar a política de alertas definida neste tutorial.
- Acesse a documentação do Firestore para saber mais sobre essa escala global, o banco de dados NoSQL.
- Acesse a página Cota e limites do BigQuery para entender os limites de inserção de streaming durante a implementação desta solução em um ambiente de produção.
- Acesse a página Cota e limites do Cloud Functions para entender o tamanho máximo que uma função implantada pode manipular.
- Confira o conteúdo de migração de dados do Google Cloud. Confira o Centro de arquitetura do Cloud.