Neste documento, descrevemos como medir o desempenho do sistema de inferência do TensorFlow criado em Implantar um sistema de inferência escalonável do TensorFlow. Ele também mostra como aplicar o ajuste de parâmetros para melhorar a capacidade do sistema.
A implantação é baseada na arquitetura de referência descrita em Sistema de inferência escalonável do TensorFlow.
Esta série é destinada a desenvolvedores familiarizados com o Google Kubernetes Engine e os frameworks de machine learning (ML), incluindo o TensorFlow e a TensorRT.
Este documento não se destina a fornecer dados de desempenho de um sistema específico. Em vez disso, ele oferece uma orientação geral sobre o processo de medição de desempenho. As métricas de desempenho exibidas, como Total de solicitações por segundo (RPS) e Tempos de resposta (ms), variam de acordo com o modelo treinado, versões de software e configurações de hardware usadas.
Arquitetura
Para ter uma visão geral da arquitetura do sistema de inferência do TensorFlow, consulte Sistema de inferência do TensorFlow escalonável.
Objetivos
- Definir o objetivo e as métricas de desempenho
- Avaliar o desempenho da linha de base
- Realizar a otimização do gráfico
- Avaliar a conversão do FP16
- Medir a quantização INT8
- Ajustar o número de instâncias
Custos
Para saber detalhes sobre os custos associados à implantação, consulte Custos.
Ao concluir as tarefas descritas neste documento, é possível evitar o faturamento contínuo excluindo os recursos criados. Saiba mais em Limpeza.
Antes de começar
Verifique se você já concluiu as etapas em Implantar um sistema de inferência escalonável do TensorFlow.
Neste documento, você usará as seguintes ferramentas:
- Um terminal SSH da instância de trabalho que você preparou em Criar um ambiente de trabalho.
- O painel do Grafana preparado em Implantar servidores de monitoramento com o Prometheus e o Grafana.
- O console do Locust que você preparou em Implantar uma ferramenta de teste de carga.
Definir o diretório
No Console do Google Cloud, selecione Compute Engine > instâncias da VM.
Você verá a instância
working-vmque criou.Para abrir o console do terminal da instância, clique em SSH.
No terminal SSH, defina o diretório atual para o subdiretório
client:cd $HOME/gke-tensorflow-inference-system-tutorial/clientNeste documento, todos os comandos deste diretório são executados.
Definir o objetivo de performance
Ao medir o desempenho de sistemas de inferência, você precisa definir o objetivo de desempenho e as métricas de desempenho adequadas de acordo com o caso de uso do sistema. Para fins de demonstração, este documento usa os seguintes objetivos de desempenho:
- Pelo menos 95% das solicitações recebem respostas em até 100ms.
- A capacidade de processamento total, representada por solicitações por segundo (RPS), melhora sem quebrar o objetivo anterior.
Com base nessas suposições, você mede e melhora a capacidade dos seguintes modelos ResNet-50 com otimizações diferentes. Quando um cliente envia solicitações de inferência, ele especifica o modelo usando o nome do modelo na tabela.
| Nome do modelo | Otimização |
|---|---|
original |
Modelo original (sem otimização com TF-TRT) |
tftrt_fp32 |
Otimização de gráficos (tamanho do lote: 64, grupos de instâncias: 1) |
tftrt_fp16 |
Conversão para FP16, além da otimização do gráfico (tamanho do lote: 64, grupos de instâncias: 1) |
tftrt_int8 |
Quantização com INT8, além da otimização do gráfico (tamanho do lote: 64, grupos de instâncias: 1) |
tftrt_int8_bs16_count4 |
Quantização com INT8, além da otimização do gráfico (tamanho do lote: 16 grupos de instâncias: 4) |
Avaliar o desempenho da linha de base
Comece usando o TF-TRT como um valor de referência para avaliar o desempenho do modelo original e não otimizado. Você compara o desempenho de outros modelos com o original para avaliar quantitativamente a melhoria no desempenho. Quando você implantou o Locust, ele já estava configurado para enviar solicitações para o modelo original.
Abra o console do Locust preparado em Implantar uma ferramenta de teste de carga.
Confirme se o número de clientes (conhecidos como escravos) é 10.
Se o número for menor que 10, os clientes ainda estão iniciando. Nesse caso, espere alguns minutos até se tornar 10.
Avaliar o desempenho:
- No campo Número de usuários para simular, digite
3000. - No campo Hatch rate, insira
5. - Para aumentar o número de usos simulados em 5 por segundo até chegar a 3.000, clique em Start swarming.
- No campo Número de usuários para simular, digite
Clique em Gráficos.
Os gráficos mostram os resultados de desempenho. Embora o valor de Total Requests per Second (total de solicitações por segundo) aumente linearmente, o valor de Response Times (ms) (tempos de resposta) aumenta de acordo.
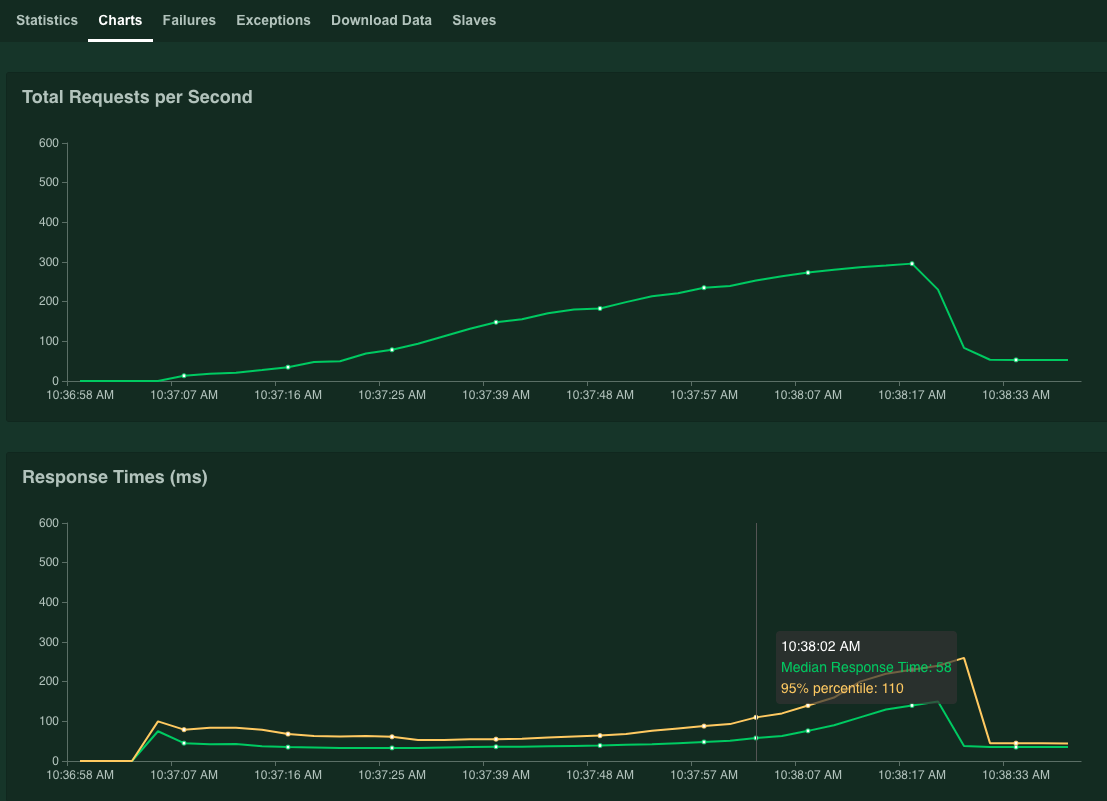
Quando o valor de percentual de 95% dos tempos de resposta exceder 100 ms, clique em Interromper para interromper a simulação.
Se você segurar o ponteiro do mouse sobre o gráfico, poderá verificar o número de solicitações por segundo correspondentes quando o valor de 95% do tempo de resposta tiver excedido 100 ms.
Por exemplo, na captura de tela a seguir, o número de solicitações por segundo é 253,1.
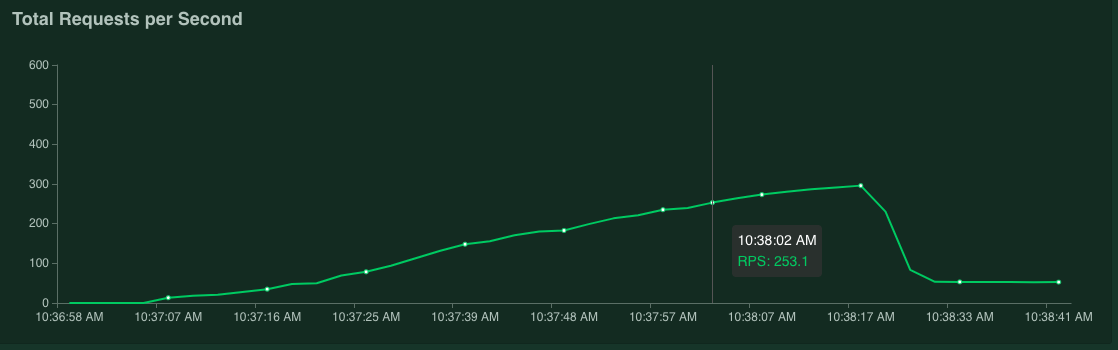
Recomendamos repetir essa medição várias vezes e calcular uma média para considerar a flutuação.
No terminal SSH, reinicie o Locust:
kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustPara repetir a medição, repita este procedimento.
Otimizar gráficos
Nesta seção, você mede o desempenho do modelo tftrt_fp32, que é
otimizado com TF-TRT para otimização de gráficos. Essa é uma otimização comum
compatível com a maioria das placas da GPU NVIDIA.
No terminal SSH, reinicie a ferramenta de teste de carga:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp32 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustO recurso
configmapespecifica o modelo comotftrt_fp32.Reinicie o servidor Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Aguarde alguns minutos até que os processos do servidor estejam prontos.
Verifique o status do servidor:
kubectl get podsA saída é semelhante à seguinte, em que a coluna
READYmostra o status do servidor:NAME READY STATUS RESTARTS AGE inference-server-74b85c8c84-r5xhm 1/1 Running 0 46sO valor
1/1na colunaREADYindica que o servidor está pronto.Avaliar o desempenho:
- No campo Número de usuários para simular, digite
3000. - No campo Hatch rate, insira
5. - Para aumentar o número de usos simulados em 5 por segundo até chegar a 3.000, clique em Start swarming.
Os gráficos mostram a melhoria de desempenho da otimização de gráficos TF-TRT.
Por exemplo, o gráfico pode mostrar que o número de solicitações por segundo agora é 381, com um tempo de resposta médio de 59 ms.
- No campo Número de usuários para simular, digite
Converter para FP16
Nesta seção, você mede o desempenho do modelo tftrt_fp16 que está
otimizado com o TF-TRT para otimização de gráficos e conversão de FP16. Essa é uma
otimização disponível para NVIDIA T4.
No terminal SSH, reinicie a ferramenta de teste de carga:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp16 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustReinicie o servidor Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Aguarde alguns minutos até que os processos do servidor estejam prontos.
Avaliar o desempenho:
- No campo Número de usuários para simular, digite
3000. - No campo Hatch rate, insira
5. - Para aumentar o número de usos simulados em 5 por segundo até chegar a 3.000, clique em Start swarming.
Os gráficos mostram a melhoria de performance da conversão do FP16, além da otimização do gráfico do TF-TRT.
Por exemplo, o gráfico pode mostrar que o número de solicitações por segundo é 1.072,5, com um tempo médio de resposta de 63 ms.+
- No campo Número de usuários para simular, digite
Quantizar com INT8
Nesta seção, você mede o desempenho do modelo tftrt_int8
otimizado para TF-TRT para otimização de gráficos e quantização INT8. Essa
otimização está disponível para NVIDIA T4.
No terminal SSH, reinicie a ferramenta de teste de carga
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustReinicie o servidor Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Aguarde alguns minutos até que os processos do servidor estejam prontos.
Avaliar o desempenho:
- No campo Número de usuários para simular, digite
3000. - No campo Hatch rate, insira
5. - Para aumentar o número de usos simulados em 5 por segundo até chegar a 3.000, clique em Start swarming.
Os gráficos mostram os resultados de desempenho.
Por exemplo, o gráfico pode mostrar que o número de solicitações por segundo é 1.085,4 com um tempo médio de resposta de 32 ms.
Neste exemplo, o resultado não é um aumento significativo na performance em comparação com a conversão do FP16. Em teoria, a GPU NVIDIA T4 pode lidar com modelos de quantização INT8 mais rapidamente do que os modelos de conversão FP16. Nesse caso, pode haver um gargalo diferente do desempenho da GPU. É possível confirmar isso usando os dados de utilização da GPU no painel do Grafana. Por exemplo, se a utilização for inferior a 40%, isso significa que o modelo não pode usar todo o desempenho da GPU.
Como na próxima seção, é possível aliviar esse gargalo aumentando o número de grupos de instâncias. Por exemplo, aumente o número de grupos de instâncias de 1 a 4 e diminua o tamanho do lote de 64 para 16. Essa abordagem mantém o número total de solicitações processadas em uma única GPU em 64.
- No campo Número de usuários para simular, digite
Ajustar o número de instâncias
Nesta seção, você mede o desempenho do modelo
tftrt_int8_bs16_count4. Esse modelo tem a mesma estrutura de tftrt_int8, mas
você altera o tamanho do lote e o número de grupos de instâncias, conforme descrito em Quantizar com INT8.
No terminal SSH, reinicie o Locust:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8_bs16_count4 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust kubectl scale deployment/locust-slave --replicas=20 -n locustNeste comando, use o recurso
configmappara especificar o modelo comotftrt_int8_bs16_count4. Você também aumenta o número de pods de cliente do Locust para gerar cargas de trabalho suficientes para medir a limitação de desempenho do modelo.Reinicie o servidor Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Aguarde alguns minutos até que os processos do servidor estejam prontos.
Avaliar o desempenho:
- No campo Número de usuários para simular, digite
3000. - No campo Hatch rate, insira
15. Nesse modelo, o limite de desempenho poderá levar muito tempo para ser atingido se a taxa de exibição estiver definida como5. - Para aumentar o número de usos simulados em 5 por segundo até chegar a 3.000, clique em Start swarming.
Os gráficos mostram os resultados de desempenho.
Por exemplo, o gráfico pode mostrar que o número de solicitações por segundo é 2.236,6 com um tempo médio de resposta de 38 ms.
Ao ajustar o número de instâncias, você quase duplica solicitações por segundo. Observe que a utilização da GPU aumentou no painel do Grafana (por exemplo, a utilização pode chegar a 75%).
- No campo Número de usuários para simular, digite
Desempenho e vários nós
Ao escalonar com vários nós, você mede o desempenho de um único pod. Como os processos de inferência são executados de maneira independente em pods diferentes de forma não compartilhada, suponha que a capacidade total seja escalonada linearmente com o número de pods. Essa suposição se aplica, desde que não haja gargalos, como largura de banda de rede entre clientes e servidores de inferência.
No entanto, é importante entender como as solicitações de inferência são balanceadas entre vários servidores de inferência. O Triton usa o protocolo gRPC para estabelecer uma conexão TCP entre um cliente e um servidor. Como o Triton reutiliza a conexão estabelecida para enviar várias solicitações de inferência, as solicitações de um único cliente são sempre enviadas para o mesmo servidor. Para distribuir solicitações para vários servidores, é preciso usar vários clientes.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados nessa série, exclua o projeto.
Excluir o projeto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Saiba mais sobre Como configurar recursos de computação para previsão.
- Saiba mais sobre o Google Kubernetes Engine (GKE)
- Saiba mais sobre o Cloud Load Balancing.
- Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.