이 페이지는 Apigee 및 Apigee Hybrid에 적용됩니다.
Apigee Edge 문서 보기

이상이란 무엇인가요?
이상은 비정상적이거나 예상치 못한 API 데이터 패턴입니다. 예를 들어 아래에서 API 오류율을 그래프를 살펴봅니다.
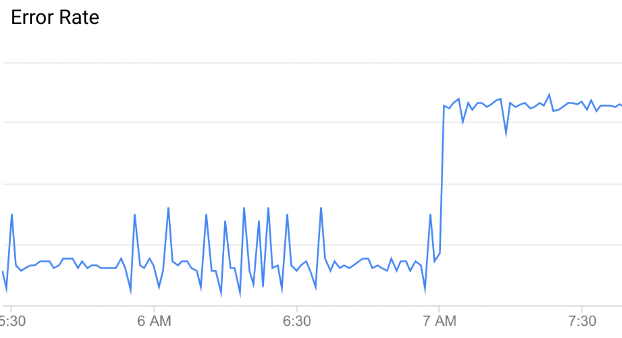
보시다시피 오류율은 오전 7시에 갑자기 증가합니다. 이 시점까지의 데이터와 비교했을 때 이러한 증가는 이상으로 분류하기에 충분할 정도로 비정상적입니다.
하지만 API 데이터의 모든 편차가 이상을 반영하는 것은 아닙니다. 대부분 무작위 변동입니다. 예를 들어 오류율에서 최대한의 경우 이상으로 여겨질 수 있는 비교적 사소한 편차가 나타나더라도 이것만으로는 실제로 이상이라고 부르기에 충분하지 않습니다.
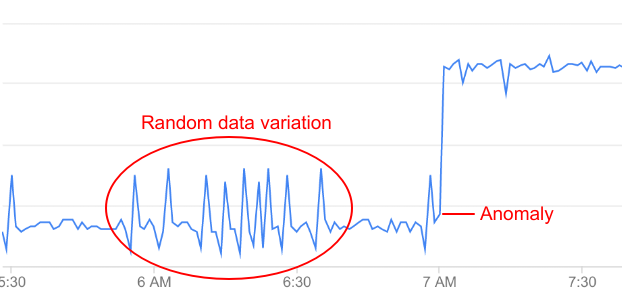
AAPI Ops에서는 API 데이터를 지속적으로 모니터링하고 통계 분석을 수행하여 실제 이상을 데이터의 무작위 변동과 구분합니다.
이상 감지가 없으면 각 이상을 직접 감지하도록 기준을 선택해야 합니다. 기준은 이상을 트리거하기 위해 오류율과 같은 수량이 도달해야 하는 값입니다. 또한 최신 데이터를 기반으로 기준 값을 최신 상태로 유지해야 합니다. 이와 반대로 AAPI-Ops는 최신 데이터 패턴을 기반으로 최적의 이상 기준을 선택합니다.
AAPI가 위에 표시된 것과 같은 이상을 감지하면 이상 이벤트 대시보드에 이상 세부정보가 표시됩니다. 이 시점에서 API Monitoring 대시보드의 이상을 조사하고 필요한 경우 적절한 조치를 취할 수 있습니다. 또한 나중에 비슷한 이벤트가 발생하면 이를 알리도록 알림을 만들 수도 있습니다.
감지된 이상은 다음 정보를 포함합니다.
- 프록시 지연 시간이나 HTTP 오류 코드와 같은 이상을 일으킨 측정항목입니다.
- 이상의 심각도입니다. 심각도는 모델의 신뢰도 수준에 따라 적음, 보통, 심각일 수 있습니다. 신뢰도 수준이 낮으면 심각도가 적음을 나타내고 높은 신뢰도 수준은 심각함을 나타냅니다.
이상 유형
Apigee는 다음 유형의 이상을 자동으로 감지합니다.
- 조직, 환경, 리전 수준에서 HTTP 503 오류 증가
- 조직, 환경, 리전 수준에서 HTTP 504 오류 증가
- 조직, 환경, 리전 수준에서 모든 HTTP 4xx 또는 5xx 오류 증가
- 조직, 환경, 리전 수준에서 90번째 백분위수(p90)에 대한 총 응답 지연 시간 증가
이상 감지 작동 방식
이상 감지 단계는 다음과 같습니다.
모델 학습
이상 감지는 이전 시계열 데이터에서 API 프록시 동작의 모델을 학습하는 방식으로 작동합니다. 모델 학습을 위해 개발자가 별도로 취해야 할 조치는 없습니다. Apigee는 지난 6시간 동안의 API 데이터에서 자동으로 모델을 만들고 학습합니다. 따라서 Apigee는 이상치를 로깅하기 전에 모델을 학습하기 위해 API 프록시에 대한 최소 6시간의 데이터가 필요합니다.
학습의 목표는 모델의 정확성을 개선하는 것이며 그런 다음 과거 데이터에서 테스트할 수 있습니다. 모델의 정확성을 테스트하는 가장 간단한 방법은 오류율(거짓양성 및 거짓음성의 합계를 총 예측 이벤트 수로 나눈 값)을 계산하는 것입니다.
이상 이벤트 로깅
런타임에 Apigee 이상 감지는 API 프록시의 현재 동작을 모델에서 예측한 동작과 비교합니다. 이상 감지는 특정 신뢰도 수준을 사용하여 운영 측정항목이 예측 값을 초과하는 시기를 확인할 수 있습니다. 예를 들어 5xx 오류 비율이 모델이 예측하는 비율을 초과할 때입니다.
Apigee는 이상을 감지하면 이상 이벤트 대시보드에 이벤트를 자동으로 로깅합니다. 대시보드에 표시되는 이벤트 목록에는 감지된 모든 이상과 트리거된 알림이 포함됩니다.